Dit is het tweede deel van het materiaal gewijd aan SQL Server Semantic Search . In het vorige artikel hebben we de basis verkend. Nu gaan we ons concentreren op het vergelijken van documenten die zijn opgeslagen op Windows File System en de vergelijkende analyse met Semantic Search in SQL Server.
Op naam gebaseerde documenten vergelijkende analyse uitvoeren
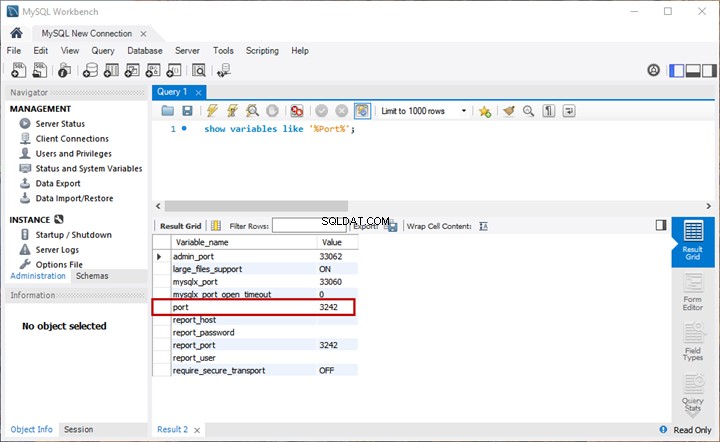
We gaan een vergelijkende analyse van documenten uitvoeren op basis van hun standaard naamgeving. Laten we nu een snelle controle uitvoeren door de EmployeesFilestreamSample op te vragen. database die we eerder hebben opgezet:
-- View stored documents managed by File Table to check
SELECT stream_id
,[name]
,file_type
,creation_time
FROM EmployeesFilestreamSample.dbo.EmployeesDocumentStore
De resultaten moeten ons opgeslagen documenten tonen:
Semantische zoekchecklist
We hebben al de database en twee voorbeelden van MS Word-documenten op het bestandssysteem met behulp van de bestandstabel (u kunt deel 1 raadplegen om de kennis indien nodig op te frissen). Maar dat niet kwalificeren onze documenten automatisch voor het Semantic Search-scenario.
Semantisch zoeken kan op een van de volgende manieren worden ingeschakeld:
- Als u de Full-Text Search . al heeft ingesteld , kunt u semantisch zoeken in één stap inschakelen.
- U kunt de semantische zoekopdracht rechtstreeks instellen, maar daarvoor moet u ook de volledige tekstzoekopdracht instellen.
Full-Text Search-test voor het instellen van semantisch zoeken
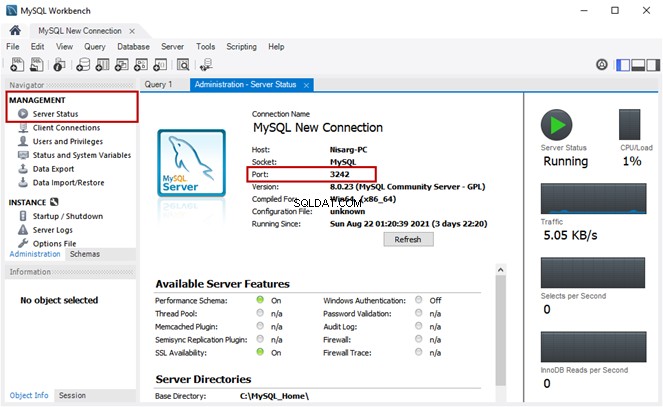
Als een Full-Text-query werkt, hoeven we alleen Semantic Search in te schakelen. Om dat te controleren, voert u een Full-Text-query uit op de gewenste tabel:
-- Searching word Employee using Full-Text search against EmployeesDocumentStore File Table
SELECT [name]
FROM [EmployeesFilestreamSample].[dbo].[EmployeesDocumentStore]
WHERE CONTAINS(name,'Employee')
De uitvoer:
We moeten dus eerst voldoen aan de vereisten voor zoeken in volledige tekst en vervolgens Semantisch zoeken inschakelen.
Semantisch zoeken inschakelen voor gebruik
Ten minste twee van de volgende punten zijn nodig om Semantisch zoeken te gebruiken:
- Unieke index
- Een full-text catalogus
- Een full-text index
Voer het volgende T-SQL-script uit om een unieke index te maken:
-- Create unique index required for Semantic Search
CREATE UNIQUE INDEX UQ_Stream_Id
ON EmployeesDocumentStore(stream_id)
GO
Maak een Full-Text-catalogus op basis van de nieuw gecreëerde unieke index. En maak dan een Full-Text index zoals hieronder getoond:
-- Getting Semantic Search ready to be used with File Table
CREATE FULLTEXT CATALOG EmployeesFileTableCatalog WITH ACCENT_SENSITIVITY = ON;
CREATE FULLTEXT INDEX ON EmployeesDocumentStore
(
name LANGUAGE 1033 STATISTICAL_SEMANTICS,
file_type LANGUAGE 1033 STATISTICAL_SEMANTICS,
file_stream TYPE COLUMN file_type LANGUAGE 1033 STATISTICAL_SEMANTICS
)
KEY INDEX UQ_Stream_Id
ON EmployeesFileTableCatalog WITH CHANGE_TRACKING AUTO, STOPLIST=SYSTEM;
De resultaten:
Full-Text Search Test na semantisch zoeken instellen
Laten we dezelfde Full-Text-query uitvoeren om te zoeken naar het woord Werknemer in de opgeslagen documenten:
-- Searching (after Semantic Search setup) word Employee using Full-Text search against EmployeesDocumentStore File Table
SELECT [name]
FROM [EmployeesFilestreamSample].[dbo].[EmployeesDocumentStore]
WHERE CONTAINS(name,'Employee')
De uitvoer:
Het is prima dat Full-Text-query's werken tegen de Bestandstabel terwijl we deze klaar maken voor Semantisch Zoeken.
Meer MS Word-documenten toevoegen
We gaan naar de EmployeesDocumentStore Bestandstabel en klik op Bestandstabelmap verkennen :
Maak en bewaar een nieuw document met de naam Sadaf Contract Employee :
Voeg vervolgens de volgende tekst toe aan het nieuw gemaakte document. De eerste regel moet de titel van het document zijn!
Sadaf Contractmedewerker (titel)
Sadaf is een zeer efficiënte bedrijfsanalist die op contact gebaseerd werk doet. Ze is volledig in staat om met zakelijke vereisten om te gaan en deze om te zetten in technische specificaties waaraan de ontwikkelaars kunnen werken. Ze is een zeer ervaren bedrijfsanalist.
Voeg nog een document toe met de naam Mike Vaste Werknemer :
Werk het document bij met de volgende tekst:
Mike Vaste Werknemer (Titel van het document)
Mike is een nieuwe programmeur wiens expertise ook webontwikkeling omvat. Hij leert snel en werkt graag aan elk project. Hij heeft een sterk probleemoplossend vermogen, maar hij heeft minder kennis van zaken. Hij heeft hulp nodig van andere ontwikkelaars of bedrijfsanalisten om het probleem te begrijpen en aan de vereisten te voldoen.
Hij is goed als hij aan kleine projecten werkt, maar hij worstelt als hij een groot of complex project krijgt.
We hebben vier documenten opgeslagen op het Windows-bestandssysteem dat wordt beheerd door File Table. Deze documenten moeten worden gebruikt door Semantic Search (inclusief Full-Text Search).
Belangrijk:hoewel we zojuist vier MS Word-documenten als voorbeeld in de map hebben opgeslagen, kunt u zich het belang voorstellen van het gebruik van Semantic Search wanneer honderden van dergelijke documenten worden onderhouden door een SQL Server-database en u die documenten moet opvragen om waardevolle informatie te vinden.
De standaard naamgeving van documenten is van groot belang voor de succesvolle implementatie van deze aanpak.
Eenvoudig tellen van documenten
We kunnen deze documenten vergelijken en de verschillen en overeenkomsten definiëren op basis van hun standaardnaamgeving met behulp van Semantic Search. Een eenvoudige zoekopdracht kan ons bijvoorbeeld het totale aantal documenten vertellen dat is opgeslagen in de Windows-map:
-- Getting total number of stored documents
SELECT COUNT(*) AS Total_Documents FROM EmployeesDocumentStore

Vergelijking van vaste versus contractgebaseerde werknemers
Deze keer gebruiken we Semantic Search om het aantal vaste en contractuele medewerkers in onze organisatie te vergelijken:
-- Creating a summary table variable
DECLARE @Documents TABLE
(DocumentType VARCHAR(100),
DocumentsCount INT)
INSERT INTO @Documents -- Storing total number of stored documents into summary table
SELECT 'Total Documents',COUNT(*) AS Total_Documents FROM EmployeesDocumentStore
INSERT INTO @Documents -- Storing total number of permanent employees documents stored into summary table
SELECT 'Total Permanent Employees',COUNT(*)
FROM semantickeyphrasetable (EmployeesDocumentStore, *)
WHERE keyphrase = 'Permanent'
INSERT INTO @Documents --Storing total number of permanent employees documents stored
SELECT 'Total Contract Employees',COUNT(*)
FROM semantickeyphrasetable (EmployeesDocumentStore, *)
WHERE keyphrase = 'Contract'
SELECT DocumentType,DocumentsCount FROM @Documents
De uitvoer:
Laten we een eenvoudige (op documentnaam gebaseerde) semantische zoekopdracht uitvoeren om de sleutelzin te bekijken en de relatieve score voor elk document:
-- Getting keyphrase and relative score for all the documents
SELECT * FROM semantickeyphrasetable(EmployeesDocumentStore, NAME)
ORDER BY score
De uitvoer:
Laten we meer details toevoegen aan de documentnamen. We zullen ze als volgt hernoemen:
- Asif Vaste Medewerker – Ervaren Projectmanager
- Mike Vaste Medewerker – Nieuwe Programmeur
- Peter Vaste Medewerker – Fresh Project Manager
- Sadaf Contractmedewerker – Ervaren Business Analist
Nieuwe werknemers vinden (documenten)
Vind de documenten met betrekking tot nieuwe werknemers op basis van hun titels (standaard naamgeving):
-- Getting document name-based scoring to find fresh employees for a new project
SELECT (SELECT name from EmployeesDocumentStore where path_locator=document_key) as DocumentName
,keyphrase,score FROM semantickeyphrasetable(EmployeesDocumentStore, NAME) where keyphrase='fresh'
order by DocumentName desc
De resultaten:
Ervaren medewerkers vinden (documenten)
Stel dat we snel alle details van ervaren medewerkers willen doornemen voor het complexe project dat voor ons ligt. Gebruik de volgende semantische zoekopdracht:
-- Getting document name-based scoring to find all experienced employees
SELECT (SELECT name from EmployeesDocumentStore where path_locator=document_key) as DocumentName ,keyphrase,score FROM semantickeyphrasetable(EmployeesDocumentStore, NAME)
where keyphrase='experienced' order by DocumentName
De uitvoer:
Alle projectmanagers vinden (documenten)
Als we ten slotte snel de documenten voor alle projectmanagers willen doornemen, hebben we de volgende semantische zoekopdracht nodig:
-- Getting document name-based scoring to find all project managers
SELECT (SELECT name from EmployeesDocumentStore where path_locator=document_key) as DocumentName ,keyphrase,score FROM semantickeyphrasetable(EmployeesDocumentStore, NAME)
where keyphrase='Project'
De resultaten:
Na het implementeren van de walkthrough, kunt u met succes ongestructureerde gegevens, zoals MS Word-documenten, opslaan in een Windows-map met behulp van Bestandstabel.
Review op naam gebaseerde analyse
Tot nu toe hebben we geleerd hoe we een op naam gebaseerde analyse kunnen uitvoeren van documenten die zijn opgeslagen in een bestandstabel met behulp van semantisch zoeken. We moeten echter aan de volgende voorwaarden voldoen:
- Standaard naamgeving moet aanwezig zijn.
- Namen moeten de informatie bevatten die nodig is voor analyse.
Deze voorwaarden zijn ook beperkingen van de op naam gebaseerde analyse. Maar dit betekent niet dat we er niet veel mee kunnen doen.
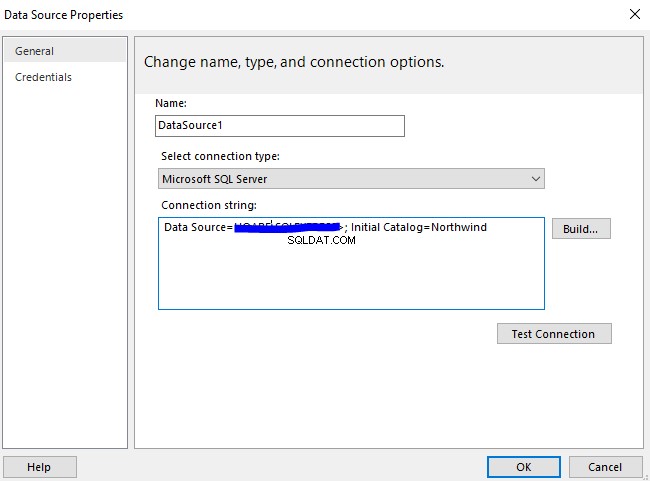
Onze focus blijft op de naam/kolom-gebaseerde Semantic Search-aanpak.
Bekijk de naamkolommen van de documenten
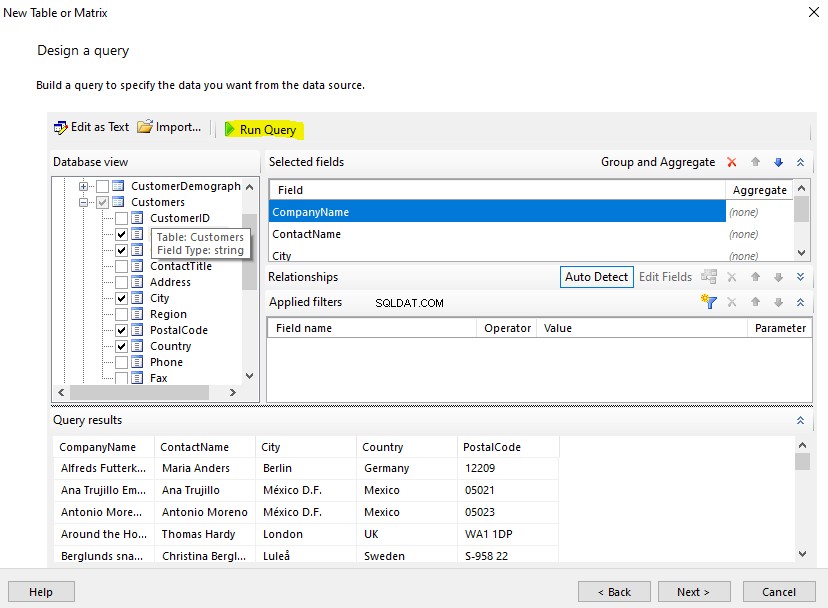
Laten we enkele van de hoofdkolommen van de tabel Documenten bekijken, inclusief de Naam kolom:
USE EmployeesFilestreamSample
-- View name column with the file types of the stored documents in File Table for analysis
SELECT name,file_type
FROM dbo.EmployeesDocumentStore
De uitvoer:
De SEMANTICKEYPHRASETABLE-functie begrijpen
SQL Server biedt de SEMANTICKEYPHRASETABLE functie om het document te analyseren met Semantic Search. De syntaxis is als volgt:
SEMANTICKEYPHRASETABLE
(
table,
{ column | (column_list) | * }
[ , source_key ]
)
Deze functie geeft ons sleutelzinnen die bij het document horen. We kunnen ze gebruiken om documenten te analyseren op basis van hun naam of inhoud. In ons geval moeten we niet alleen deze functie gebruiken, maar ook begrijpen hoe we deze op de juiste manier kunnen gebruiken.
De functie vereist de volgende gegevens:
- Naam van de bestandstabel die moet worden gebruikt voor semantische zoekanalyse.
- Naam van de kolom die moet worden gebruikt voor analyse van semantisch zoeken.
Vervolgens retourneert het de volgende gegevens:
- Kolom_id – het kolomnummer
- Document_Key – de standaard primaire sleutel voor het File Table-document
- Sleutelzin – is een zin die Semantic Search besluit te indexeren voor analyse. Het is van toepassing op zowel de naam als de inhoud van het document, afhankelijk van de kolom waarvoor we de sleutelzinnen willen zien
- Score – bepaalt de sterkte van een sleutelzin die aan een document is gekoppeld, zoals hoe een document het best wordt herkend aan de sleutelzin. De score kan tussen 0,0 en 1,0 liggen.
Alle documenten analyseren met behulp van de functie SEMANTICKEYPHRASETABLE
We gebruiken de SEMANTICKEYPHRASETABLE functie voor de op naam gebaseerde analyse van de documenten die zijn opgeslagen in de Windows-map die wordt beheerd door de Bestandstabel.
Voer het volgende T-SQL-script uit:
USE EmployeesFilestreamSample
-- View key phrases and their score for the name column
SELECT * FROM SEMANTICKEYPHRASETABLE(EmployeesDocumentStore,name)
order by score desc
De uitvoer:
We hebben een lijst met alle sleutelzinnen die bij alle documenten zijn gevoegd en hun scores. De column_id 3 in de bovenste rij staat de naam kolom. Bovendien hebben we de functie ook aangeroepen door deze kolom (naam) op te geven:
U kunt de document_key . vinden : 0xFD89E1811D4F3B2FEB1012DF0C8016F9ACEB2F3260 met het volgende script (hoewel het duidelijk is dat dit document het document is waarvan de naam de sleutelzin sadaf bevat ):
USE EmployeesFilestreamSample
-- Finding document name by its key (path_locator)
SELECT name,path_locator FROM dbo.EmployeesDocumentStore
WHERE path_locator=0xFD89E1811D4F3B2FEB1012DF0C8016F9ACEB2F3260
De uitvoer:
De sleutelzin sadaf heeft de beste score gekregen :1.0 .
Dus, in het geval van de standaard documentnaamgeving met voldoende informatie voor de Semantic Search-analyse, is onze sleutelzin sadaf is de beste match voor die specifieke documentnaam.
Specifiek document analyseren met behulp van de functie SEMANTICKEYPHRASETABLE
We kunnen onze Semantic Search-analyse verfijnen op basis van de naam kolom. We hoeven bijvoorbeeld alleen de naam kolom- gebaseerde sleutelzinnen van een bepaald document. We kunnen de documentsleutel specificeren in de SEMANTICKEYPHRASETABLE Functie.
Eerst identificeren we de documentsleutel voor dat document waar we alle sleutelzinnen willen zien. Voer het volgende T-SQL-script uit:
-- Find document_key of the document where the name contains Peter
SELECT name,path_locator as document_key From EmployeesDocumentStore
WHERE name like '%Peter%'
De documentsleutel is 0xFF6A92952500812FF013376870181CFA6D7C070220
Laten we nu dit document bekijken met betrekking tot alle sleutelzinnen die de documentnaam kunnen definiëren:
-- View all the key phrases and their score for a document related to Peter permanent employee
SELECT column_id,name,keyphrase,score FROM SEMANTICKEYPHRASETABLE(EmployeesDocumentStore,name,0xFF6A92952500812FF013376870181CFA6D7C070220)
INNER JOIN dbo.EmployeesDocumentStore on path_locator=document_key
order by score desc
De resultaten:
De sleutelzin werknemer krijgt de hoogste score in dit document. We kunnen zien dat alle woorden van de kolom sleutelzinnen zijn die de betekenis van het document bepalen.
De functie SEMANTICSIMILARITYTABLE begrijpen
Deze functie helpt ons een document te vergelijken met alle andere documenten op basis van sleutelzinnen. De syntaxis van deze functie is als volgt:
SEMANTICSIMILARITYTABLE
(
table,
{ column | (column_list) | * },
source_key
)
Het vereist dat de naam van de tabel, de kolom en de documentsleutel overeenkomen met andere documenten. We kunnen bijvoorbeeld stellen dat twee documenten vergelijkbaar zijn als ze een goede matchscore voor trefwoorden hebben.
Documenten vergelijken met de functie SEMANTICSIMILARITYTABLE
Laten we een document vergelijken met andere documenten met behulp van de SEMANTICSIMILARITYTABLE Functie.
Alle documenten van projectmanagers vergelijken
We moeten alle documenten zien die betrekking hebben op projectmanagers. Uit de bovenstaande voorbeelden weten we dat de documentsleutel voor het opgegeven document is 0xFF6A92952500812FF013376870181CFA6D7C070220 . Daarom kunnen we deze sleutel gebruiken om andere overeenkomsten te vinden, inclusief projectmanagers:
USE EmployeesFilestreamSample
-- View all the documents closely related to Peter project manager
SELECT SST.source_column_id,SST.matched_column_id,EDS.name,SCORE FROM SEMANTICSIMILARITYTABLE(EmployeesDocumentStore,name,0xFF6A92952500812FF013376870181CFA6D7C070220) SST
INNER JOIN dbo.EmployeesDocumentStore EDS on EDS.path_locator=SST.matched_document_key
order by score desc
De uitvoer:
Het meest verwante document is Asif Vaste Medewerker – Ervaren Projectmanager.docx
Documenten van ervaren bedrijfsanalisten vergelijken
Nu gaan we de documenten vergelijken met betrekking tot ervaren bedrijfsanalist s en vind de dichtstbijzijnde overeenkomst met Semantic Search. We zijn beperkt tot de op documentnaam gebaseerde analyse:
USE EmployeesFilestreamSample
-- Finding document_key for experienced business analyst
select name,path_locator as document_key from EmployeesDocumentStore
where name like '%experienced business analyst%'
-- View all the documents closely related to experienced business analyst
SELECT SST.source_column_id,SST.matched_column_id,EDS.name,SCORE FROM SEMANTICSIMILARITYTABLE(EmployeesDocumentStore,name,0xFD89E1811D4F3B2FEB1012DF0C8016F9ACEB2F3260) SST
INNER JOIN dbo.EmployeesDocumentStore EDS on EDS.path_locator=SST.matched_document_key
order by score desc
De uitvoer:
Zoals we kunnen zien aan de hand van de resultaten hierboven, komt het beste overeen met het document met betrekking tot de ervaren bedrijfsanalist is het document van de ervaren projectmanager omdat ze allebei ervaren . zijn . Desalniettemin geeft de score van 0,3 aan dat er niet veel overeenkomst is tussen deze twee documenten.
Conclusie
Gefeliciteerd! We hebben met succes geleerd hoe we documenten in Windows-mappen kunnen opslaan en analyseren met behulp van Semantic Search. We verkenden ook de functies die we in de praktijk kunnen gebruiken. Nu kunt u de nieuwe kennis toepassen en de volgende oefeningen proberen om
Blijf op de hoogte voor meer materialen!