Een van de meest populaire manieren om hoge beschikbaarheid voor MySQL te bereiken, is replicatie. Replicatie bestaat al vele jaren en werd veel stabieler met de introductie van GTID's. Maar zelfs met deze verbeteringen kan het replicatieproces om verschillende redenen kapot gaan, bijvoorbeeld wanneer master en slave niet synchroon lopen omdat schrijfbewerkingen rechtstreeks naar de slave zijn verzonden. Hoe los je replicatieproblemen op en hoe los je ze op?
In deze blogpost bespreken we enkele veelvoorkomende problemen met replicatie en hoe u deze kunt oplossen met ClusterControl. Laten we beginnen met de eerste.
Replicatie gestopt met een fout
De meeste MySQL DBA's zullen dit soort problemen doorgaans minstens één keer in hun carrière tegenkomen. Om verschillende redenen kan een slave beschadigd raken of misschien niet meer synchroniseren met de master. Wanneer dit gebeurt, is het eerste wat u moet doen om de probleemoplossing te starten, het foutenlogboek controleren op berichten. Meestal is de foutmelding gemakkelijk te traceren in het foutenlogboek of door de SHOW SLAVE STATUS-query uit te voeren.
Laten we eens kijken naar het volgende voorbeeld van de SHOW STATUS SLAVE:
********** 0. row **********
Slave_IO_State:
Master_Host: 10.2.9.71
Master_User: cmon_replication
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000111
Read_Master_Log_Pos: 255477362
Relay_Log_File: relay-bin.000001
Relay_Log_Pos: 4
Relay_Master_Log_File: binlog.000111
Slave_IO_Running: No
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 255477362
Relay_Log_Space: 256
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master:
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 1236
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'Could not find GTID state requested by slave in any binlog files. Probably the slave state is too old and required binlog files have been purged.'
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1000
Master_SSL_Crl:
Master_SSL_Crlpath:
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 1000-1000-2268440
Replicate_Do_Domain_Ids:
Replicate_Ignore_Domain_Ids:
Parallel_Mode: optimistic
SQL_Delay: 0
SQL_Remaining_Delay:
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Slave_DDL_Groups: 0
Slave_Non_Transactional_Groups: 0
Slave_Transactional_Groups: 0We kunnen duidelijk zien dat de fout gerelateerd is aan Got fatale fout 1236 van master bij het lezen van gegevens uit binaire log:'Kon de door slave gevraagde GTID-status niet vinden in binlog-bestanden. Waarschijnlijk is de slave-status te oud en zijn de vereiste binlog-bestanden verwijderd.'. Met andere woorden, wat de fout ons in wezen vertelt, is dat er inconsistenties zijn in de gegevens en dat de vereiste binaire logbestanden al zijn verwijderd.
Dit is een goed voorbeeld waarbij het replicatieproces niet meer werkt. Naast SHOW SLAVE STATUS kun je de status ook volgen op het tabblad “Overview” van het cluster in ClusterControl. Dus hoe dit op te lossen met ClusterControl? Je hebt twee opties om te proberen:
-
U kunt proberen de slave opnieuw te starten vanaf de "Node Action"
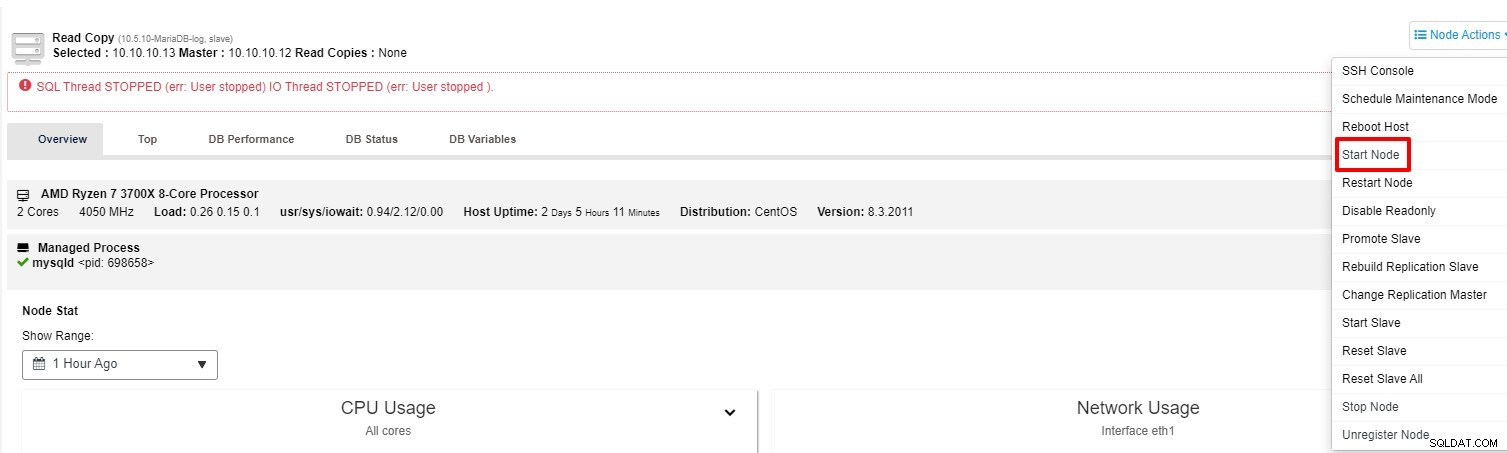
-
Als de slave nog steeds niet werkt, kunt u de taak "Rebuild Replication Slave" uitvoeren van de "Knooppuntactie"
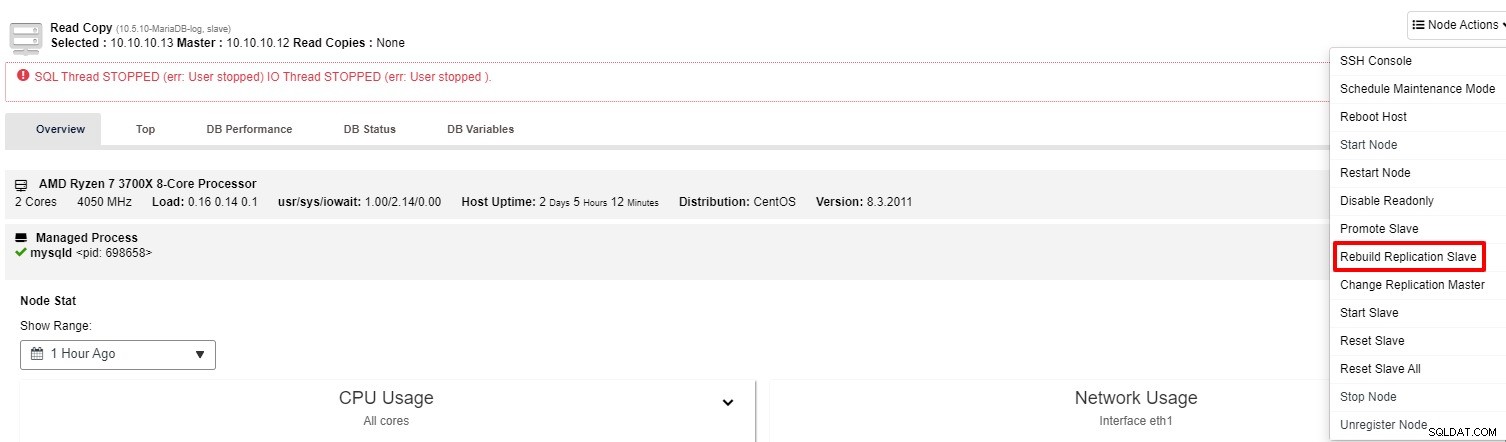
Meestal lost de tweede optie het probleem op. ClusterControl maakt een back-up van de master en herbouwt de kapotte slave door de gegevens te herstellen. Zodra de gegevens zijn hersteld, wordt de slave verbonden met de master zodat deze kan inhalen.
Er zijn ook meerdere handmatige manieren om de slave opnieuw op te bouwen, zoals hieronder vermeld. U kunt ook deze link raadplegen voor meer informatie:
-
Mysqldump gebruiken om een inconsistente MySQL-slave opnieuw op te bouwen
-
Mydumper gebruiken om een inconsistente MySQL-slave opnieuw op te bouwen
-
Een momentopname gebruiken om een inconsistente MySQL-slave opnieuw op te bouwen
-
Een Xtrabackup of Mariabackup gebruiken om een inconsistente MySQL-slave opnieuw op te bouwen
Promoot een slaaf om een meester te worden
Na verloop van tijd moet het besturingssysteem of de database worden gepatcht of geüpgraded om de stabiliteit en veiligheid te behouden. Een van de beste praktijken om de downtime te minimaliseren, vooral voor een grote upgrade, is het promoveren van een van de slaven tot master nadat de upgrade met succes is uitgevoerd op dat specifieke knooppunt.
Door dit uit te voeren, kunt u uw toepassing naar de nieuwe master verwijzen en blijft de master-slave-replicatie werken. In de tussentijd kunt u ook met een gerust hart doorgaan met de upgrade van de oude master. Met ClusterControl kan dit met een paar klikken worden uitgevoerd, alleen als de replicatie is geconfigureerd als Global Transaction ID-gebaseerd of kortweg GTID-gebaseerd. Om gegevensverlies te voorkomen, is het de moeite waard om applicatiequery's te stoppen voor het geval de oude master correct werkt. Dit is niet de enige situatie waarin je de slaaf zou kunnen promoten. In het geval dat het hoofdknooppunt niet beschikbaar is, kunt u deze actie ook uitvoeren.
Zonder ClusterControl zijn er een paar stappen om de slave te promoten. Voor elk van de stappen zijn ook enkele query's vereist:
-
De master handmatig uitschakelen
-
Selecteer de meest geavanceerde slave om master te worden en bereid deze voor
-
Verbind andere slaves opnieuw met de nieuwe master
-
De oude meester veranderen in een slaaf
Niettemin zijn de stappen om Slave te promoten met ClusterControl slechts een paar klikken:Cluster> Nodes> kies slave node> Promoot Slave zoals in de onderstaande schermafbeelding:
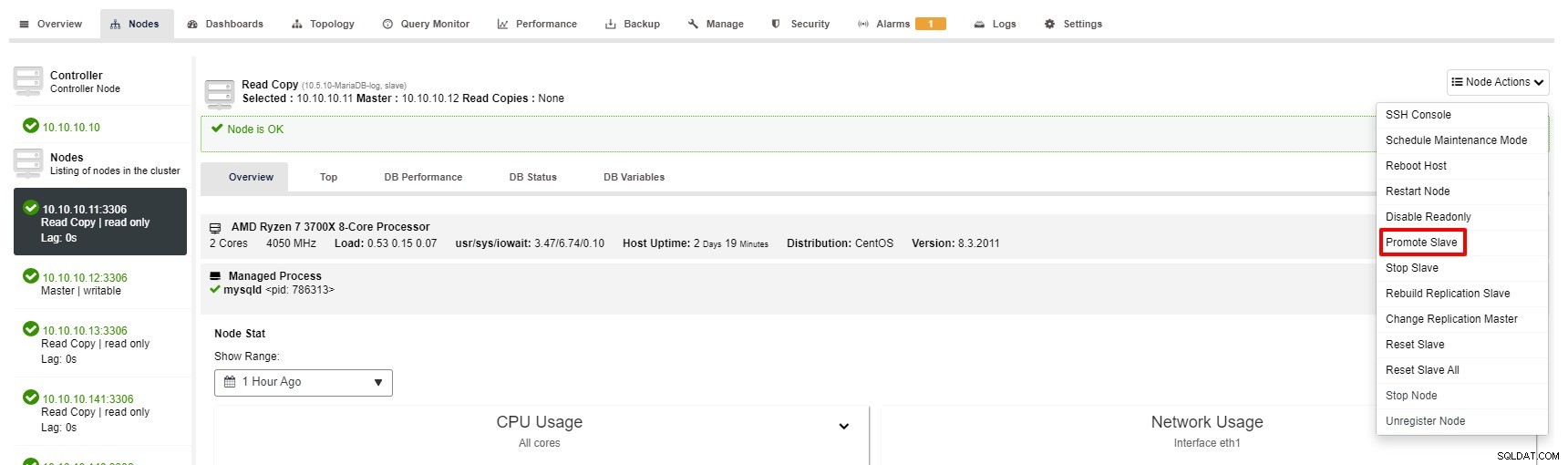
Master wordt niet beschikbaar
Stel je voor dat je grote transacties moet uitvoeren, maar dat de database niet werkt. Het maakt niet uit hoe voorzichtig u bent, dit is waarschijnlijk de meest ernstige of kritieke situatie voor een replicatie-installatie. Wanneer dit gebeurt, kan uw database geen enkele keer schrijven accepteren, wat slecht is. Bovendien werken je applicatie(s) natuurlijk niet goed.
Er zijn een paar redenen of oorzaken die tot dit probleem leiden. Enkele voorbeelden zijn hardwarestoringen, corruptie van het besturingssysteem, databasecorruptie enzovoort. Als DBA moet u snel handelen om de hoofddatabase te herstellen.
Dankzij de clusterfunctie “Auto Recovery” die beschikbaar is in ClusterControl, kan het failoverproces worden geautomatiseerd. Het kan met een enkele klik worden in- of uitgeschakeld. Zoals de naam al zegt, zal het de hele clustertopologie oproepen wanneer dat nodig is. Een master-slave-replicatie moet bijvoorbeeld op elk moment ten minste één master in leven hebben, ongeacht het aantal beschikbare slaves. Wanneer de master niet beschikbaar is, zal deze automatisch een van de slaven promoten.
Laten we de onderstaande schermafbeelding eens bekijken:
In de bovenstaande schermafbeelding kunnen we zien dat "Auto Recovery" is ingeschakeld voor zowel Cluster als Node. Merk in de topologie op dat het huidige master-IP-adres 10.10.10.11 is. Wat gebeurt er als we het hoofdknooppunt verwijderen voor testdoeleinden?
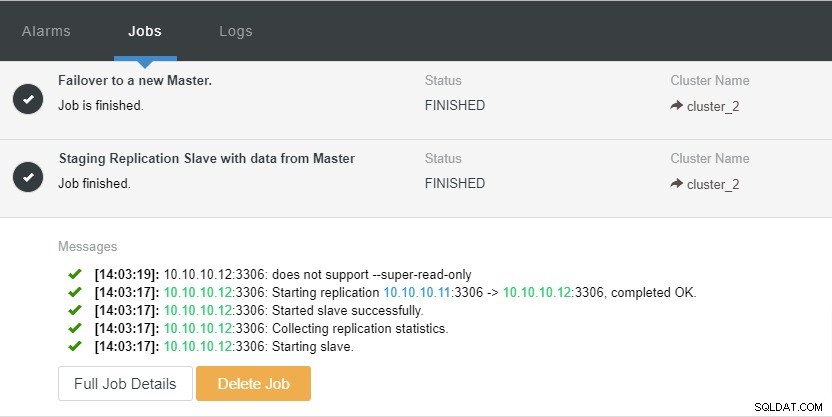
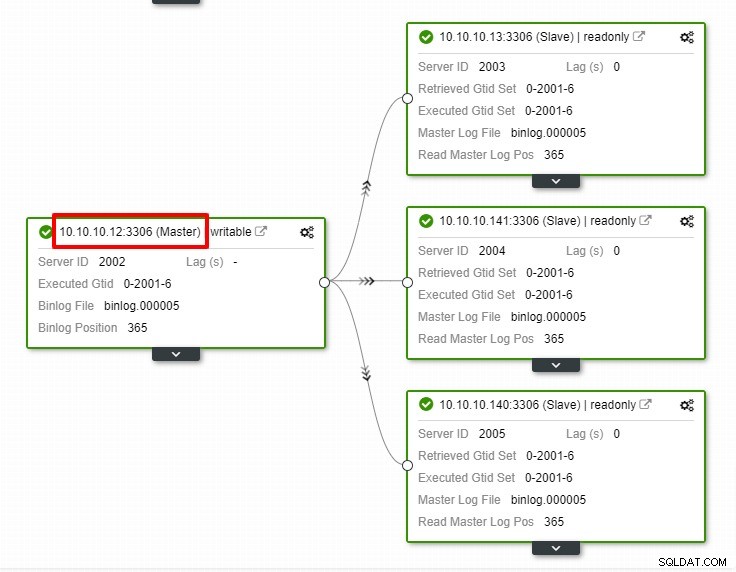
Zoals u kunt zien, wordt de slave-node met IP 10.10.10.12 automatisch gepromoveerd tot master, zodat de replicatietopologie opnieuw wordt geconfigureerd. In plaats van dit handmatig te doen, wat natuurlijk veel stappen met zich meebrengt, helpt ClusterControl u bij het onderhouden van uw replicatie-instellingen door u de rompslomp uit handen te nemen.
Conclusie
In elk ongelukkig geval met uw replicatie, is de oplossing heel eenvoudig en minder gedoe met ClusterControl. ClusterControl helpt u uw replicatieproblemen snel te herstellen, waardoor de uptime van uw databases toeneemt.