Het belang van failover
Failover is een van de belangrijkste databasepraktijken voor databasebeheer. Het is niet alleen handig bij het beheren van grote databases in productie, maar ook als u er zeker van wilt zijn dat uw systeem altijd beschikbaar is wanneer u het opent, vooral op applicatieniveau.
Voordat een failover kan plaatsvinden, moeten uw database-instances aan bepaalde vereisten voldoen. Deze eisen zijn namelijk erg belangrijk voor een hoge beschikbaarheid. Een van de vereisten waaraan uw database-instances moeten voldoen, is redundantie. Redundantie zorgt ervoor dat de failover kan doorgaan, waarbij de redundantie is ingesteld om een failover-kandidaat te hebben die een replica (secundair) knooppunt kan zijn of uit een pool van replica's die fungeren als stand-by- of hot-standby-knooppunten. De kandidaat wordt handmatig of automatisch geselecteerd op basis van de meest geavanceerde of actuele node. Gewoonlijk zou u een hot-standby-replica willen, omdat deze uw database kan behoeden voor het ophalen van indexen van schijf, aangezien een hot-standby vaak indexen in de databasebufferpool vult.
Failover is de term die wordt gebruikt om te beschrijven dat er een herstelproces heeft plaatsgevonden. Voorafgaand aan het herstelproces vindt dit plaats wanneer een primair (of hoofd) databaseknooppunt faalt na een crash, na natuurrampen, na een hardwarestoring, of als het netwerkpartitionering heeft ondergaan; dit zijn de meest voorkomende gevallen waarin een failover kan plaatsvinden. Het herstelproces verloopt meestal automatisch en zoekt vervolgens naar de meest gewenste en actuele secundaire (replica) zoals eerder vermeld.
Geavanceerde failover
Hoewel het herstelproces tijdens een failover automatisch is, zijn er bepaalde gevallen waarin het niet nodig is om het proces te automatiseren en een handmatig proces het moet overnemen. Complexiteit is vaak de belangrijkste overweging bij de technologieën die de hele stack van uw database vormen - automatische failover kan ook worden gecombineerd met handmatige failover.
In de meeste dagelijkse overwegingen bij het beheren van databases, zijn de meeste zorgen rond de automatische failover echt niet triviaal. Het is vaak handig om een automatische failover te implementeren en in te stellen voor het geval er zich problemen voordoen. Hoewel dat veelbelovend klinkt omdat het de complexiteit dekt, komen er de geavanceerde failover-mechanismen en dat omvat "pre"-gebeurtenissen en de "post"-gebeurtenissen die als haken zijn verbonden in een failover-software of -technologie.
Deze pre- en postgebeurtenissen komen met controles of bepaalde acties die moeten worden uitgevoerd voordat de failover definitief kan worden uitgevoerd, en nadat een failover is voltooid, enkele opschoningen om ervoor te zorgen dat de failover eindelijk een succes is een. Gelukkig zijn er tools beschikbaar die niet alleen automatische failover mogelijk maken, maar ook de mogelijkheid bieden om pre- en post-script hooks toe te passen.
In deze blog gebruiken we de automatische failover van ClusterControl (CC) en leggen we uit hoe je de pre- en postscript-hooks gebruikt en op welke cluster ze van toepassing zijn.
ClusterControl-replicatiefailover
Het ClusterControl-failovermechanisme is efficiënt toepasbaar via asynchrone replicatie die van toepassing is op MySQL-varianten (MySQL/Percona Server/MariaDB). Het is ook van toepassing op PostgreSQL/TimescaleDB-clusters - ClusterControl ondersteunt streaming-replicatie. MongoDB- en Galera-clusters hebben hun eigen mechanisme voor automatische failover ingebouwd in hun eigen databasetechnologie. Lees meer over hoe ClusterControl automatisch databaseherstel en failover uitvoert.
ClusterControl-failover werkt niet tenzij het herstel van knooppunten en clusters (Automatisch herstel is ingeschakeld). Dat betekent dat deze knoppen groen moeten zijn.

In de documentatie staat dat deze configuratie-opties ook kunnen worden gebruikt om / schakel het volgende uit:
enable_cluster_autorecovery=
-
Indien niet gedefinieerd, wordt CMON standaard ingesteld op 0 (false) en zal het GEEN automatisch herstel uitvoeren als het clusterfout detecteert. De ondersteunde waarde is 1 (clusterherstel is ingeschakeld) of 0 (clusterherstel is uitgeschakeld).
enable_node_autorecovery=
-
Indien niet gedefinieerd, wordt CMON standaard ingesteld op 0 (false) en zal het GEEN automatisch herstel uitvoeren als het een node-fout detecteert. De ondersteunde waarde is 1 (knooppuntherstel is ingeschakeld) of 0 (knooppuntherstel is uitgeschakeld).
$ systemctl restart cmon
Voor deze blog richten we ons voornamelijk op het gebruik van de pre/post script hooks, wat in wezen een groot voordeel is voor geavanceerde replicatie-failover.
Cluster failover-replicatie pre/post scriptondersteuning
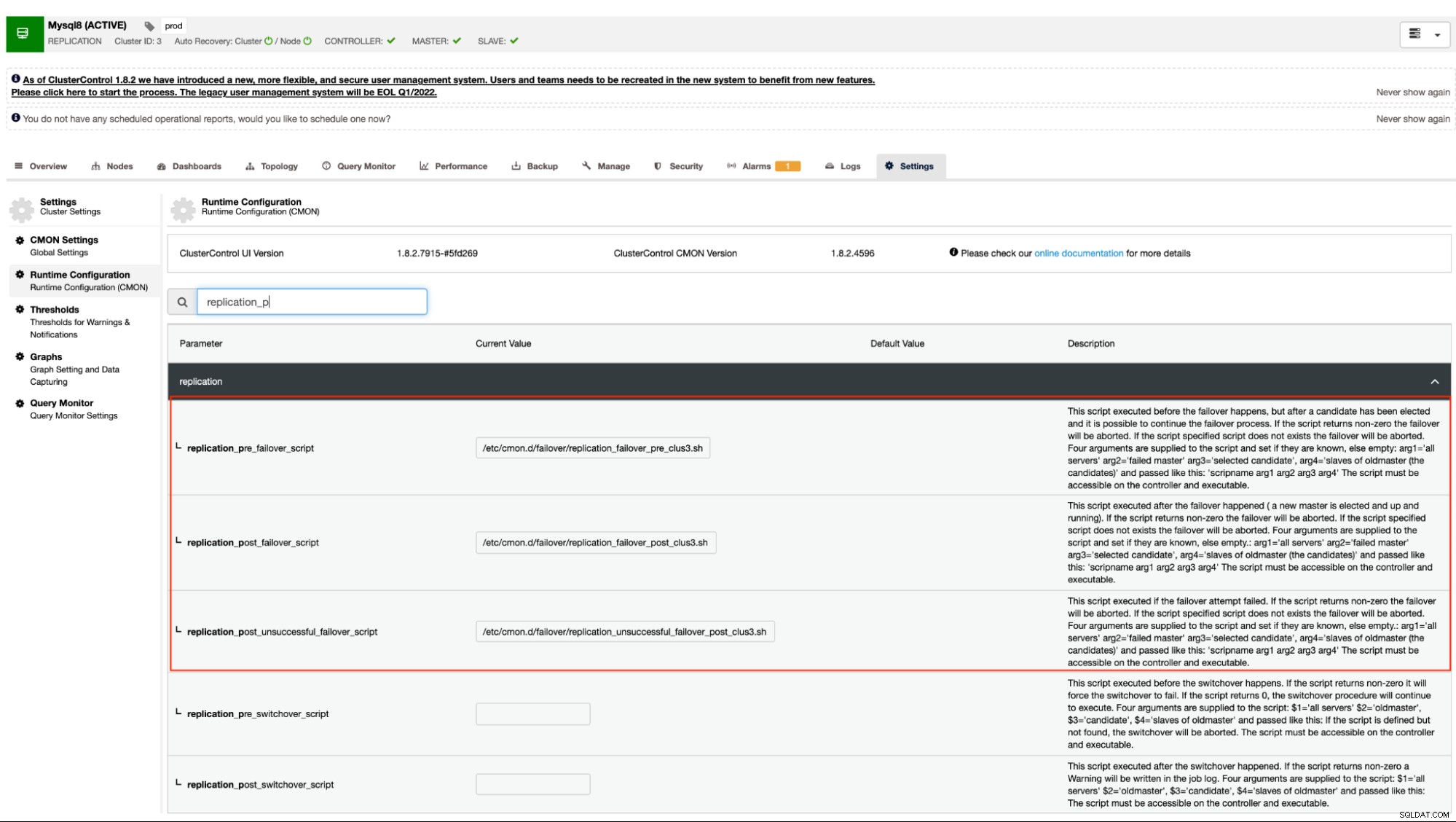
Zoals eerder vermeld, ondersteunen MySQL-varianten die asynchrone (inclusief semi-synchrone) replicatie en streamingreplicatie voor PostgreSQL/TimescaleDB gebruiken dit mechanisme. ClusterControl heeft de volgende configuratie-opties die kunnen worden gebruikt voor pre- en postscript-hooks. In principe kunnen deze configuratie-opties worden ingesteld via hun configuratiebestanden of kunnen ze worden ingesteld via de web-UI (we zullen dit later behandelen).
In onze documentatie staat dat dit de volgende configuratie-opties zijn die het failover-mechanisme kunnen wijzigen door gebruik te maken van de pre/post-scripthaken:
replication_pre_failover_script=
-
Pad naar het failoverscript op ClusterControl-knooppunt. Dit script wordt uitgevoerd voordat de failover plaatsvindt, maar nadat een kandidaat is gekozen en het mogelijk is om het failoverproces voort te zetten. Als het script niet-nul retourneert, wordt de failover geforceerd om af te breken. Als het script is gedefinieerd maar niet wordt gevonden, wordt de failover afgebroken.
-
4 argumenten worden aan het script toegevoegd:
-
arg1=”Alle servers in de replicatie”
-
arg2=”De mislukte master”
-
arg3=”Geselecteerde kandidaat”
-
arg4=”Slaven van de oude meester”
-
-
De argumenten worden als volgt doorgegeven:pre_failover_script.sh "arg1" "arg2" "arg3" "arg4 ". Het script moet toegankelijk zijn op de controller en uitvoerbaar zijn.
-
Voorbeeld:replication_pre_failover_script=/usr/local/bin/pre_failover_script.sh
replication_post_failover_script=
-
Pad naar het failoverscript op het ClusterControl-knooppunt. Dit script wordt uitgevoerd nadat de failover heeft plaatsgevonden. Als het script niet-nul retourneert, wordt er een waarschuwing in het taaklogboek geschreven. Het script moet toegankelijk en uitvoerbaar zijn op de controller.
-
4 argumenten worden aan het script toegevoegd:
-
arg1=”Alle servers in de replicatie”
-
arg2=”De mislukte master”
-
arg3=”Geselecteerde kandidaat”
-
arg4=”Slaven van de oude meester”
-
-
De argumenten worden als volgt doorgegeven:post_failover_script.sh "arg1" "arg2" "arg3" "arg4 ". Het script moet toegankelijk zijn op de controller en uitvoerbaar zijn.
-
Voorbeeld:replication_post_failover_script=/usr/local/bin/post_failover_script.sh
replication_post_unsuccessful_failover_script=
-
Pad naar het script op het ClusterControl-knooppunt. Dit script wordt uitgevoerd nadat de failoverpoging is mislukt. Als het script niet-nul retourneert, wordt er een waarschuwing in het taaklogboek geschreven. Het script moet toegankelijk zijn op de controller en uitvoerbaar zijn.
-
4 argumenten worden aan het script toegevoegd:
-
arg1=”Alle servers in de replicatie”
-
arg2=”De mislukte master”
-
arg3=”Geselecteerde kandidaat”
-
arg4=”Slaven van de oude meester”
-
-
De argumenten worden als volgt doorgegeven:post_fail_failover_script.sh "arg1" "arg2" "arg3" "arg4 ". Het script moet toegankelijk zijn op de controller en uitvoerbaar zijn.
-
Voorbeeld:replication_post_unsuccessful_failover_script=post_fail_failover_script.sh
Technisch gezien, als je eenmaal de volgende configuratie-opties in je /etc/cmon.d/cmon_
$ systemctl restart cmonAls alternatief kunt u de configuratie-opties ook instellen door naar
Voor deze benadering is nog steeds een herstart van de cmon-service vereist voordat deze de wijzigingen aangebracht voor deze configuratie-opties voor pre/post script hooks.
Voorbeeld van pre/post script hooks
Idealiter zijn de pre/post-scripthooks speciaal bedoeld als u een geavanceerde failover nodig hebt waarvoor ClusterControl de complexiteit van uw databaseconfiguratie niet kon beheren. Als u bijvoorbeeld verschillende datacenters heeft met verscherpte beveiliging en u wilt bepalen of de waarschuwing van het netwerk dat onbereikbaar is, geen vals positief alarm is. Het moet controleren of de primaire en de slave elkaar kunnen bereiken en vice versa en het kan ook bereiken vanaf de databaseknooppunten die naar de ClusterControl-host gaan.
Laten we dat in ons voorbeeld doen en laten zien hoe u hiervan kunt profiteren.
Serverdetails en de scripts
In dit voorbeeld gebruik ik een MariaDB-replicatiecluster met alleen een primaire en een replica. Beheerd door ClusterControl om de failover te beheren.
ClusterControl =192.168.40.110
primair (debnode5) =192.168.30.50
replica (debnode9) =192.168.30.90
Maak in het primaire knooppunt het script zoals hieronder vermeld,
example@sqldat.com:~# cat /opt/pre_failover.sh
#!/bin/bash
date -u +%s | ssh -i /home/vagrant/.ssh/id_rsa example@sqldat.com -T "cat >> /tmp/debnode5.tmp"Zorg ervoor dat /opt/pre_failover.sh uitvoerbaar is, d.w.z.
$ chmod +x /opt/pre_failover.shGebruik dan dit script om betrokken te zijn via cron. In dit voorbeeld heb ik een bestand /etc/cron.d/ccfailover gemaakt en heb ik de volgende inhoud:
example@sqldat.com:~# cat /etc/cron.d/ccfailover
#!/bin/bash
* * * * * vagrant /opt/pre_failover.shGebruik in je replica gewoon de volgende stappen die we voor de primaire hebben gedaan, behalve de hostnaam wijzigen. Zie het volgende van wat ik hieronder in mijn replica heb:
example@sqldat.com:~# tail -n+1 /etc/cron.d/ccfailover /opt/pre_failover.sh
==> /etc/cron.d/ccfailover <==
#!/bin/bash
* * * * * vagrant /opt/pre_failover.sh
==> /opt/pre_failover.sh <==
#!/bin/bash
date -u +%s | ssh -i /home/vagrant/.ssh/id_rsa example@sqldat.com -T "cat > /tmp/debnode9.tmp"en zorg ervoor dat het script dat in onze cron wordt aangeroepen, uitvoerbaar is,
example@sqldat.com:~# ls -alth /opt/pre_failover.sh
-rwxr-xr-x 1 root root 104 Jun 14 05:09 /opt/pre_failover.shClusterControl pre/post scripts
In deze demonstratie is mijn cluster_id 3. Zoals eerder vermeld in onze documentatie, moeten deze scripts zich in onze CC-controllerhost bevinden. Dus in mijn /etc/cmon.d/cmon_3.cnf heb ik het volgende:
[example@sqldat.com cmon.d]# tail -n3 /etc/cmon.d/cmon_3.cnf
replication_pre_failover_script = /etc/cmon.d/failover/replication_failover_pre_clus3.sh
replication_post_failover_script = /etc/cmon.d/failover/replication_failover_post_clus3.sh
replication_post_unsuccessful_failover_script = /etc/cmon.d/failover/replication_unsuccessful_failover_post_clus3.shTerwijl het volgende "pre"-failoverscript bepaalt of beide knooppunten de CC-controllerhost konden bereiken. Zie het volgende:
[example@sqldat.com cmon.d]# tail -n+1 /etc/cmon.d/failover/replication_failover_pre_clus3.sh
#!/bin/bash
arg1=$1
debnode5_tstamp=$(tail /tmp/debnode5.tmp)
debnode9_tstamp=$(tail /tmp/debnode9.tmp)
cc_tstamp=$(date -u +%s)
diff_debnode5=$(expr $cc_tstamp - $debnode5_tstamp)
diff_debnode9=$(expr $cc_tstamp - $debnode5_tstamp)
if [[ "$diff_debnode5" -le 60 && "$diff_debnode9" -le 60 ]]; then
echo "failover cannot proceed. It's just a false alarm. Checkout the firewall in your CC host";
exit 1;
elif [[ "$diff_debnode5" -gt 60 || "$diff_debnode9" -gt 60 ]]; then
echo "Either both nodes ($arg1) or one of them were not able to connect the CC host. One can be unreachable. Failover proceed!";
exit 0;
else
echo "false alarm. Failover discarded!"
exit 1;
fi
Whereas my post scripts just simply echoes and redirects the output to a file, just for the test.
[example@sqldat.com failover]# tail -n+1 replication_*_post*3.sh
==> replication_failover_post_clus3.sh <==
#!/bin/bash
echo "post failover script on cluster 3 with args: example@sqldat.com" > /tmp/post_failover_script_cid3.txt
==> replication_unsuccessful_failover_post_clus3.sh <==
#!/bin/bash
echo "post unsuccessful failover script on cluster 3 with args: example@sqldat.com" > /tmp/post_unsuccessful_failover_script_cid3.txt
Demo van de failover
Laten we nu een netwerkstoring op het primaire knooppunt proberen te simuleren en kijken hoe het zal reageren. In mijn primaire node verwijder ik de netwerkinterface die wordt gebruikt om te communiceren met de replica en de CC-controller.
example@sqldat.com:~# ip link set enp0s8 downTijdens de eerste poging tot failover kon CC mijn pre-script uitvoeren dat zich bevindt op /etc/cmon.d/failover/replication_failover_pre_clus3.sh. Zie hieronder hoe het werkt:
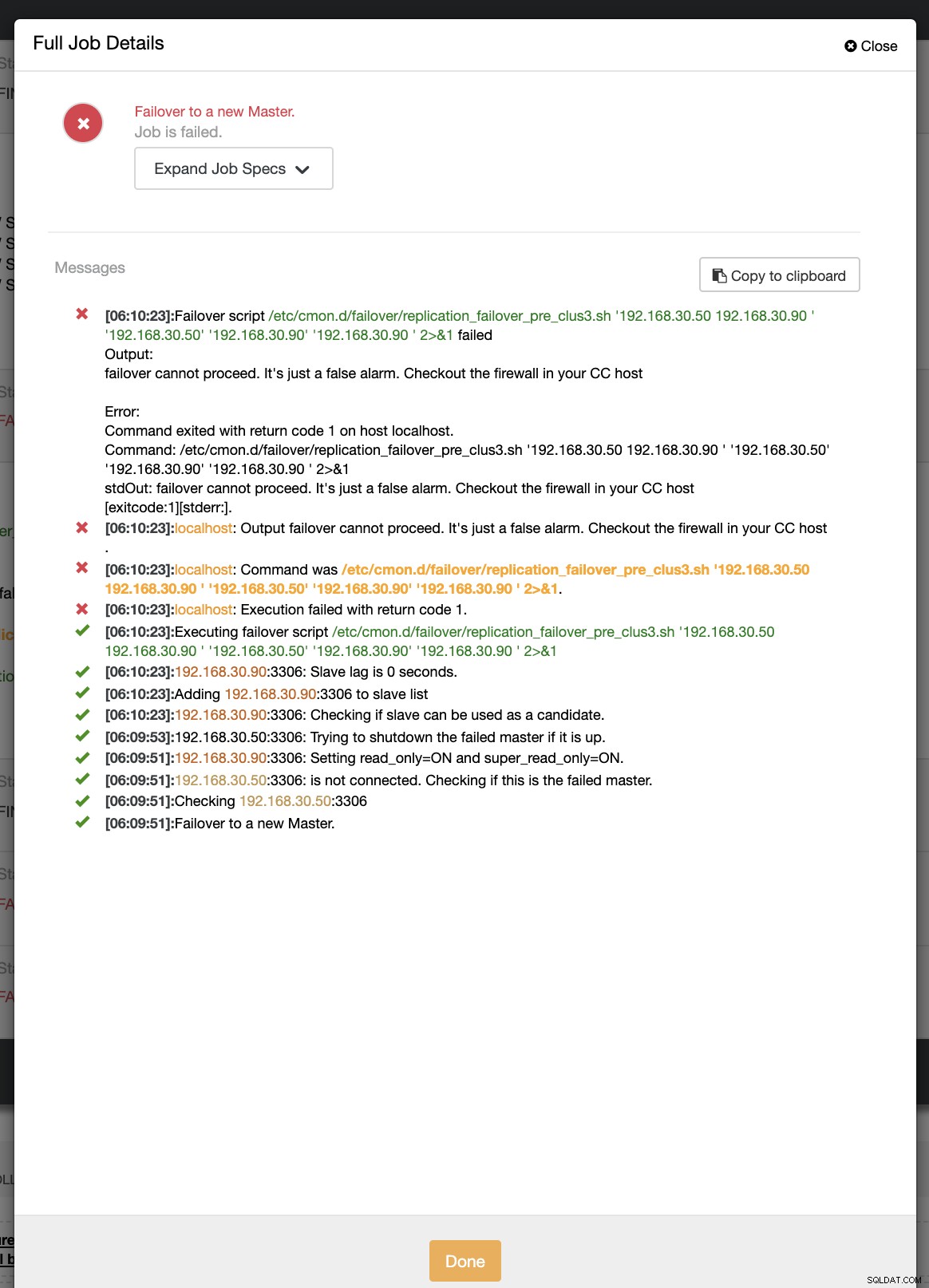
Het is duidelijk dat het niet lukt omdat de tijdstempel die is vastgelegd nog niet meer dan een minuut is of het slechts een paar seconden geleden was dat de primaire nog steeds verbinding kon maken met de CC-controller. Dat is natuurlijk niet de perfecte aanpak als je met een echt scenario te maken hebt. ClusterControl kon het script echter perfect aanroepen en uitvoeren zoals verwacht. Nu, hoe zit het als het inderdaad meer dan een minuut bereikt (d.w.z.> 60 seconden)?
Bij onze tweede poging tot failover, aangezien de tijdstempel meer dan 60 seconden bereikt, wordt dit als een echt positief beschouwd, en dat betekent dat we de failover moeten uitvoeren zoals bedoeld. CC heeft het perfect kunnen uitvoeren en zelfs het postscript kunnen uitvoeren zoals bedoeld. Dit is te zien in het takenlogboek. Zie de onderstaande schermafbeelding:
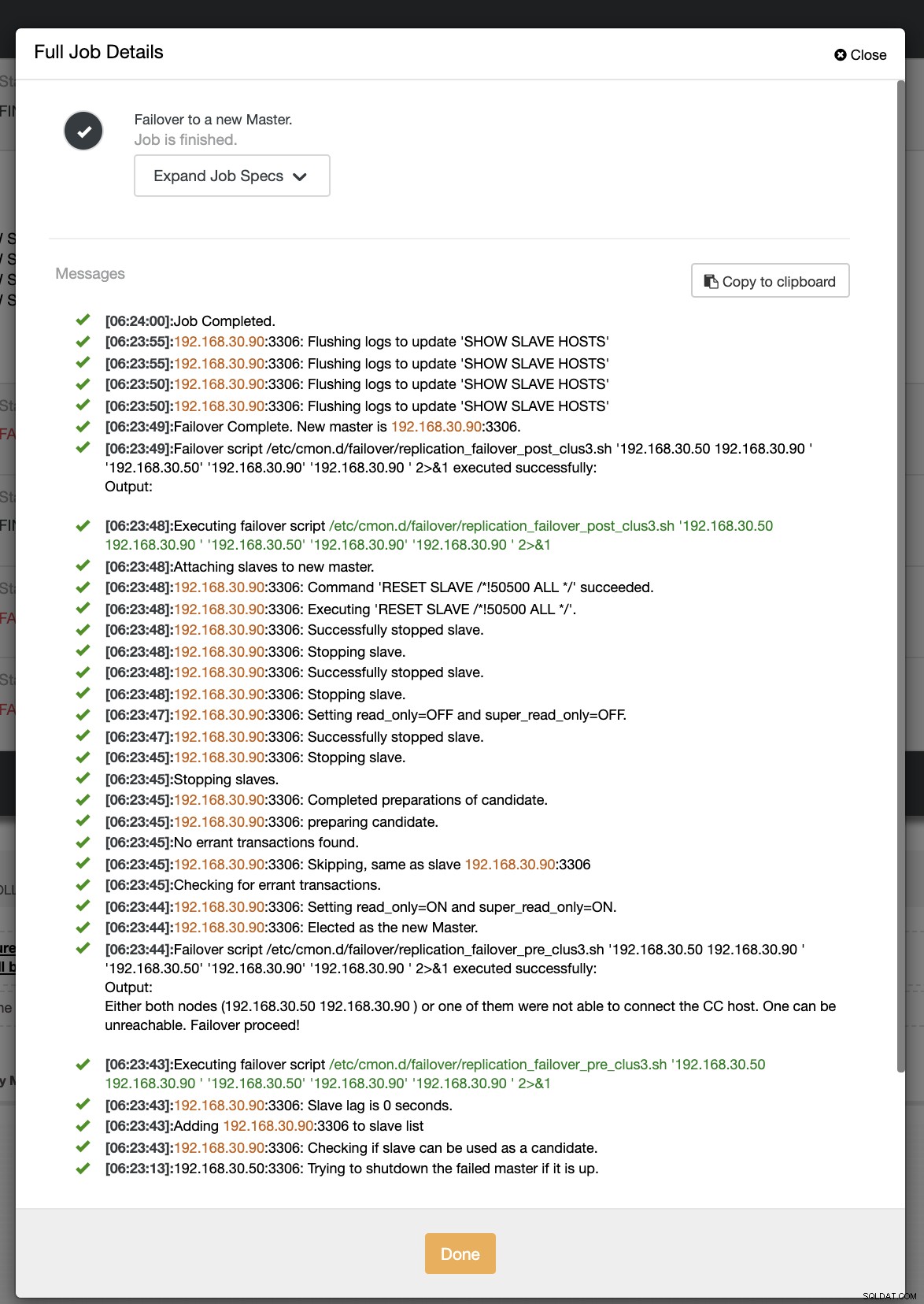
Controleer of mijn postscript werd uitgevoerd, het was in staat om het logboek te maken bestand in de map CC /tmp zoals verwacht,
[example@sqldat.com tmp]# cat /tmp/post_failover_script_cid3.txtpost failover-script op cluster 3 met args:192.168.30.50 192.168.30.90 192.168.30.50 192.168.30.90 192.168.30.90
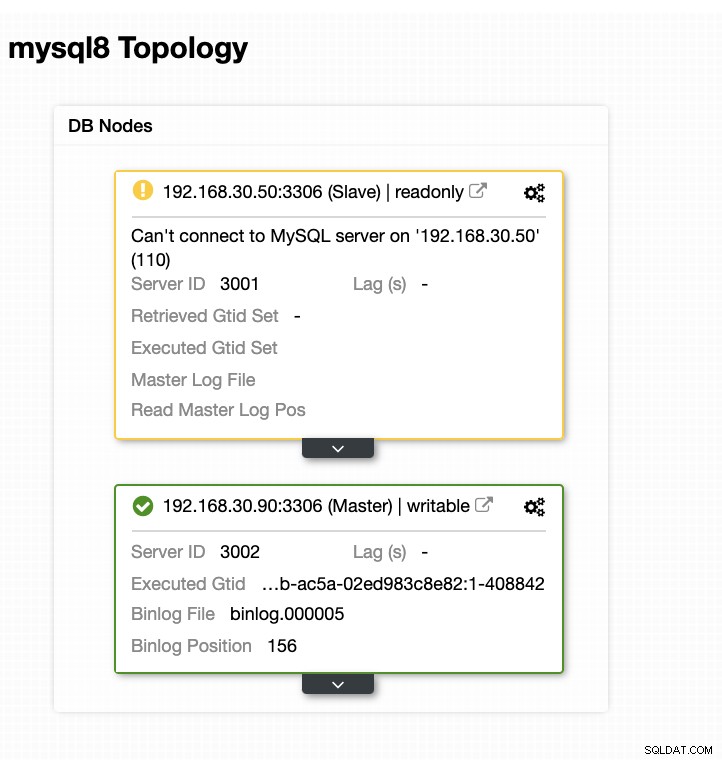
Nu is mijn topologie gewijzigd en is de failover gelukt!
Conclusie
Voor elke gecompliceerde database-configuratie die je hebt, wanneer een geavanceerde failover vereist is, kunnen pre/post-scripts erg handig zijn om dingen haalbaar te maken. Omdat ClusterControl deze functies ondersteunt, hebben we aangetoond hoe krachtig en nuttig het is. Zelfs met zijn beperkingen zijn er altijd manieren om dingen haalbaar en nuttig te maken, vooral in productieomgevingen.