Aan dit bericht zijn "strings gehecht:voor een goede reden. We gaan dieper in op SQL VARCHAR, het gegevenstype dat zich bezighoudt met strings.
Dit is ook "alleen voor uw ogen", want zonder verplichtingen zijn er geen blogposts, webpagina's, spelinstructies, recepten met bladwijzers en nog veel meer voor onze ogen om te lezen en van te genieten. We hebben elke dag te maken met een triljoen snaren. Dus als ontwikkelaars zijn jij en ik verantwoordelijk voor het efficiënt opslaan en openen van dit soort gegevens.
Met dit in gedachten zullen we bespreken wat het beste is voor opslag en prestaties. Voer de do's en don'ts in voor dit gegevenstype.
Maar daarvoor is VARCHAR slechts een van de tekenreekstypen in SQL. Wat maakt het anders?
Wat is VARCHAR in SQL? (Met voorbeelden)
VARCHAR is een gegevenstype voor tekenreeksen of tekens van verschillende grootte. U kunt er letters, cijfers en symbolen mee opslaan. Vanaf SQL Server 2019 kunt u het volledige scala aan Unicode-tekens gebruiken wanneer u een sortering met UTF-8-ondersteuning gebruikt.
U kunt VARCHAR-kolommen of -variabelen declareren met VARCHAR[(n)], waarbij n staat voor de tekenreeksgrootte in bytes. Het waardenbereik voor n is 1 tot 8000. Dat zijn veel karaktergegevens. Maar meer nog, je kunt het declareren met VARCHAR(MAX) als je een gigantische reeks van maximaal 2 GB nodig hebt. Dat is groot genoeg voor je lijst met geheimen en privédingen in je dagboek! Houd er echter rekening mee dat u het ook zonder de grootte kunt declareren en dat het standaard op 1 staat als u dat doet.
Laten we een voorbeeld nemen.
DECLARE @actor VARCHAR(20) = 'Robert Downey Jr.';
DECLARE @movieCharacter VARCHAR(10) = 'Iron Man';
DECLARE @movie VARCHAR = 'Avengers';
SELECT @actor, @movieCharacter, @movie
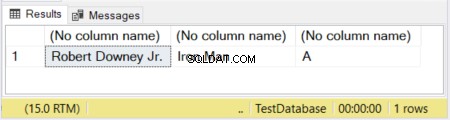
In figuur 1 hebben de eerste 2 kolommen hun afmetingen gedefinieerd. De derde kolom wordt gelaten zonder een maat. Het woord "Avengers" wordt dus afgekapt omdat een VARCHAR zonder een opgegeven grootte standaard 1 teken is.
Laten we nu iets groots proberen. Maar houd er rekening mee dat het even duurt voordat deze query wordt uitgevoerd - 23 seconden op mijn laptop.
-- This will take a while
DECLARE @giganticString VARCHAR(MAX);
SET @giganticString = REPLICATE(CAST('kage bunshin no jutsu' AS VARCHAR(MAX)),100000000)
SELECT DATALENGTH(@giganticString)
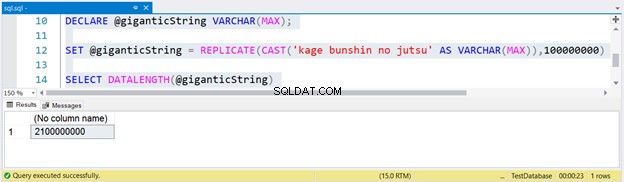
Om een enorme reeks te genereren, hebben we kage bunshin no jutsu 100 miljoen keer gerepliceerd. Let op de CAST in REPLICATE. Als u de tekenreeksexpressie niet CAST naar VARCHAR(MAX), wordt het resultaat afgekapt tot maximaal 8000 tekens.
Maar hoe verhoudt SQL VARCHAR zich tot andere typen stringgegevens?
Verschil tussen CHAR en VARCHAR in SQL
In vergelijking met VARCHAR is CHAR een gegevenstype met een vaste lengte. Het maakt niet uit hoe klein of groot een waarde is die u aan een CHAR-variabele geeft, de uiteindelijke grootte is de grootte van de variabele. Bekijk de vergelijkingen hieronder.
DECLARE @tvSeriesTitle1 VARCHAR(20) = 'The Mandalorian';
DECLARE @tvSeriesTitle2 CHAR(20) = 'The Mandalorian';
SELECT DATALENGTH(@tvSeriesTitle1) AS VarcharValue,
DATALENGTH(@tvSeriesTitle2) AS CharValue
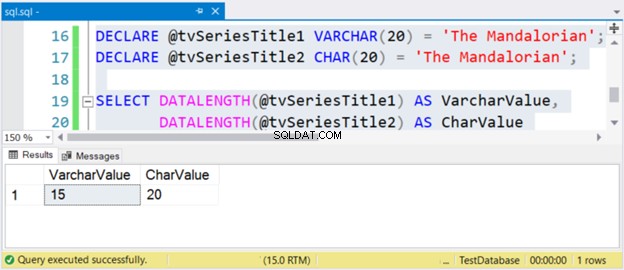
De grootte van de string "The Mandalorian" is 15 tekens. Dus de VarcharValue kolom geeft het correct weer. Echter, CharValue behoudt de grootte van 20 - het is opgevuld met 5 spaties aan de rechterkant.
SQL VARCHAR versus NVARCHAR
Bij het vergelijken van deze gegevenstypen komen twee fundamentele dingen in je op.
Ten eerste is het de grootte in bytes. Elk teken in NVARCHAR is twee keer zo groot als VARCHAR. NVARCHAR(n) is alleen van 1 tot 4000.
Vervolgens de tekens die het kan opslaan. NVARCHAR kan meertalige karakters opslaan, zoals Koreaans, Japans, Arabisch, enz. Als u van plan bent Koreaanse K-Pop-teksten in uw database op te slaan, is dit gegevenstype een van uw opties.
Laten we een voorbeeld hebben. We gaan de K-popgroep 세븐틴 of Seventeen in het Engels gebruiken.
DECLARE @kpopGroupKorean NVARCHAR(5) = N'세븐틴';
SELECT @kpopGroupKorean AS KPopGroup,
DATALENGTH(@kpopGroupKorean) AS SizeInBytes,
LEN(@kpopGroupKorean) AS [NoOfChars]
De bovenstaande code geeft de tekenreekswaarde, de grootte in bytes en het aantal tekens weer. Als dit niet-Unicode-tekens zijn, is het aantal tekens gelijk aan de grootte in bytes. Maar dit is niet het geval. Bekijk figuur 4 hieronder.
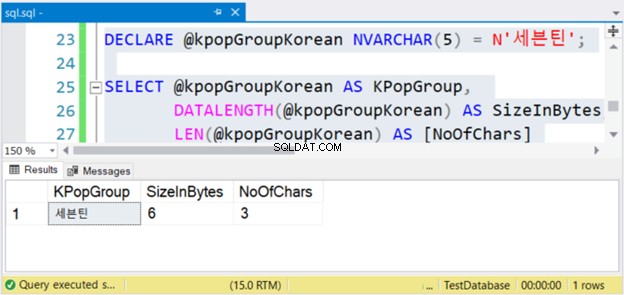
Zie je wel? Als NVARCHAR 3 tekens heeft, is de grootte in bytes twee keer. Maar niet met VARCHAR. Hetzelfde geldt ook als je Engelse karakters gebruikt.
Maar hoe zit het met NCHAR? NCHAR is de tegenhanger van CHAR voor Unicode-tekens.
SQL Server VARCHAR met UTF-8-ondersteuning
VARCHAR met UTF-8-ondersteuning is mogelijk op serverniveau, databaseniveau of tabelkolomniveau door de sorteerinformatie te wijzigen. De te gebruiken sortering moet UTF-8 ondersteunen.
SQL SERVER COLLATIE
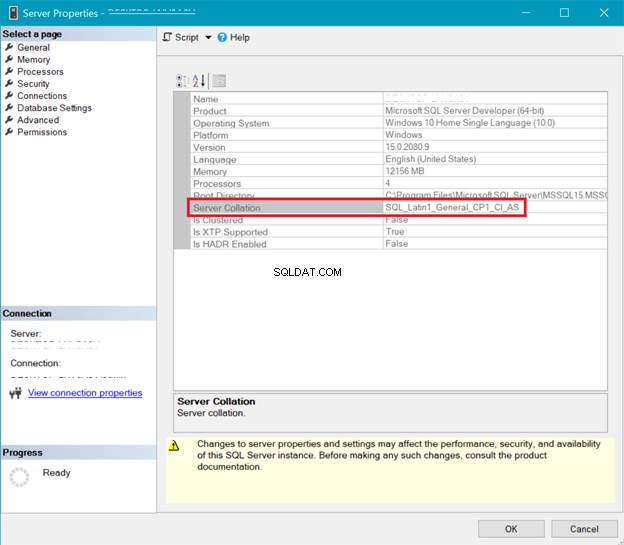
Afbeelding 5 toont het venster in SQL Server Management Studio waarin de serversortering wordt weergegeven.
DATABASE COLLATIE
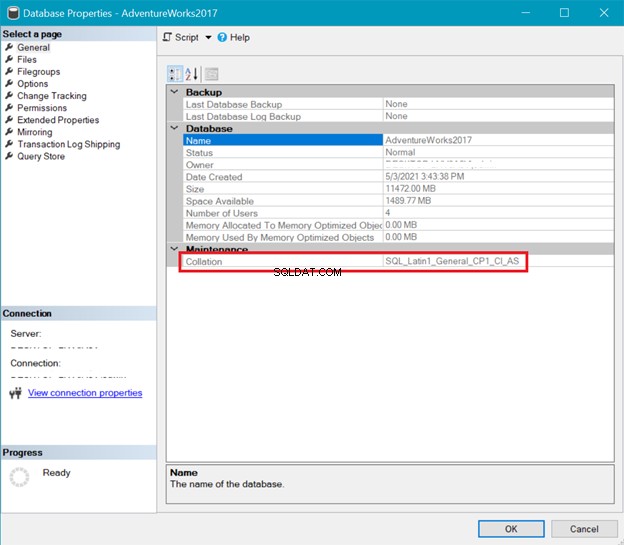
Ondertussen toont figuur 6 de verzameling van de AdventureWorks database.
TABELKOLOM COLLATIE
Zowel de server- als databasesortering hierboven laat zien dat UTF-8 niet wordt ondersteund. De sorteerreeks moet een _UTF8 bevatten voor de UTF-8-ondersteuning. Maar u kunt nog steeds UTF-8-ondersteuning gebruiken op kolomniveau van een tabel. Zie het voorbeeld.
CREATE TABLE SeventeenMemberList
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
KoreanName VARCHAR(20) COLLATE Latin1_General_100_BIN2_UTF8 NOT NULL,
EnglishName VARCHAR(20) NOT NULL
)
De bovenstaande code heeft Latin1_General_100_BIN2_UTF8 sortering voor de KoreaanseNaam kolom. Hoewel VARCHAR en niet NVARCHAR, accepteert deze kolom Koreaanse tekens. Laten we wat records invoegen en ze dan bekijken.
INSERT INTO SeventeenMemberList
(KoreanName, EnglishName)
VALUES
(N'에스쿱스','S.Coups')
,(N'원우','Wonwoo')
,(N'민규','Mingyu')
,(N'버논','Vernon')
,(N'우지','Woozi')
,(N'정한','Jeonghan')
,(N'조슈아','Joshua')
,(N'도겸','DK')
,(N'승관','Seungkwan')
,(N'호시','Hoshi')
,(N'준','Jun')
,(N'디에잇','The8')
,(N'디노','Dino')
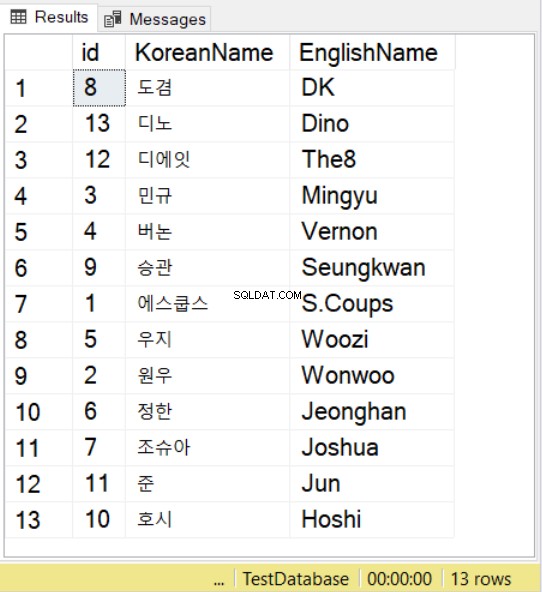
SELECT * FROM SeventeenMemberList
ORDER BY KoreanName
COLLATE Latin1_General_100_BIN2_UTF8
We gebruiken namen van de Seventeen K-pop-groep met Koreaanse en Engelse tegenhangers. Voor Koreaanse tekens moet u er rekening mee houden dat u de waarde nog steeds moet laten voorafgaan door N , net als wat u doet met NVARCHAR-waarden.
Wanneer u vervolgens SELECT gebruikt met ORDER BY, kunt u ook sortering gebruiken. Dat zie je in bovenstaand voorbeeld. Dit zal de sorteerregels volgen voor de gespecificeerde sortering.
OPSLAG VAN VARCHAR MET UTF-8-ONDERSTEUNING
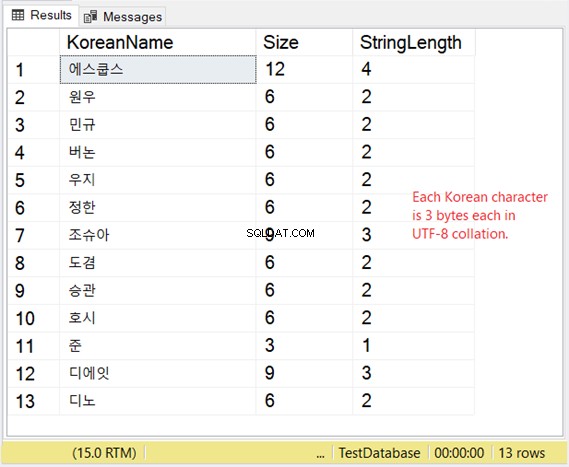
Maar hoe is de opslag van deze karakters? Als u 2 bytes per teken verwacht, staat u een verrassing te wachten. Bekijk figuur 8.
Dus als opslag belangrijk voor u is, overweeg dan de onderstaande tabel wanneer u VARCHAR gebruikt met de UTF-8-ondersteuning.
| Tekens | Grootte in bytes |
| Ascii 0 – 127 | 1 |
| Het Latijnse schrift, en Grieks, Cyrillisch, Koptisch, Armeens, Hebreeuws, Arabisch, Syrisch, Tāna en N'Ko | 2 |
| Oost-Aziatisch schrift zoals Chinees, Koreaans en Japans | 3 |
| Tekens in het bereik 010000–10FFFF | 4 |
Ons Koreaanse voorbeeld is een Oost-Aziatisch schrift, dus het is 3 bytes per teken.
Nu we klaar zijn met het beschrijven en vergelijken van VARCHAR met andere stringtypes, gaan we nu de do's en don'ts bespreken
Do's bij het gebruik van VARCHAR in SQL Server
1. Specificeer de Maat
Wat kan er mis gaan zonder de maat op te geven?
STRING TRUNCATIE
Als je lui wordt door de grootte op te geven, zal de tekenreeks worden afgekapt. Je hebt hier al eerder een voorbeeld van gezien.
OPSLAG EN PRESTATIE-IMPACT
Een andere overweging is opslag en prestaties. U hoeft alleen de juiste maat voor uw gegevens in te stellen, niet meer. Maar hoe kon je dat weten? Om in de toekomst afknotten te voorkomen, kunt u het misschien gewoon op de grootste maat instellen. Dat is VARCHAR(8000) of zelfs VARCHAR(MAX). En 2 bytes worden opgeslagen zoals het is. Zelfde verhaal met 2GB. Maakt het uit?
Als we dat beantwoorden, komen we bij het concept van hoe SQL Server gegevens opslaat. Ik heb nog een artikel waarin dit in detail wordt uitgelegd met voorbeelden en illustraties.
Kortom, data wordt opgeslagen in 8KB-pagina's. Wanneer een rij met gegevens deze grootte overschrijdt, verplaatst SQL Server deze naar een andere pagina-toewijzingseenheid met de naam ROW_OVERFLOW_DATA.
Stel dat u 2-byte VARCHAR-gegevens hebt die in de oorspronkelijke paginatoewijzingseenheid passen. Wanneer u een string opslaat die groter is dan 8000 bytes, worden de gegevens verplaatst naar de row-overflow-pagina. Verklein het vervolgens weer naar een kleiner formaat en het wordt teruggezet naar de oorspronkelijke pagina. De heen-en-weer beweging veroorzaakt veel I/O en een prestatie knelpunt. Dit ophalen van 2 pagina's in plaats van 1 heeft ook extra I/O nodig.
Een andere reden is indexering. VARCHAR(MAX) is een grote NEE als indexsleutel. Ondertussen zal VARCHAR(8000) de maximale grootte van de indexsleutel overschrijden. Dat is 1700 bytes voor niet-geclusterde indexen en 900 bytes voor geclusterde indexen.
IMPACT GEGEVENSCONVERSIE
Maar er is nog een andere overweging:dataconversie. Probeer het met een CAST zonder de maat zoals de onderstaande code.
SELECT
SYSDATETIMEOFFSET() AS DateTimeInput
,CAST(SYSDATETIMEOFFSET() AS VARCHAR) AS ConvertedDateTime
,DATALENGTH(CAST(SYSDATETIMEOFFSET() AS VARCHAR)) AS ConvertedLength
Deze code converteert een datum/tijd met tijdzone-informatie naar VARCHAR.
Dus als we lui worden bij het specificeren van de grootte tijdens CAST of CONVERT, is het resultaat beperkt tot slechts 30 tekens.
Hoe zit het met het converteren van NVARCHAR naar VARCHAR met UTF-8-ondersteuning? Hier volgt later een gedetailleerde uitleg, dus lees verder.
2. Gebruik VARCHAR als stringgrootte aanzienlijk varieert
Namen uit de AdventureWorks database variëren in grootte. Een van de kortste namen is Min Su, terwijl de langste naam Osarumwense Uwaifiokun Agbonile is. Dat is tussen de 6 en 31 tekens inclusief de spaties. Laten we deze namen in 2 tabellen importeren en vergelijken tussen VARCHAR en CHAR.
-- Table using VARCHAR
CREATE TABLE VarcharAsIndexKey
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
varcharName VARCHAR(50) NOT NULL
)
GO
CREATE INDEX IX_VarcharAsIndexKey_varcharName ON VarcharAsIndexKey(varcharName)
GO
-- Table using CHAR
CREATE TABLE CharAsIndexKey
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
charName CHAR(50) NOT NULL
)
GO
CREATE INDEX IX_CharAsIndexKey_charName ON CharAsIndexKey(charName)
GO
INSERT INTO VarcharAsIndexKey (varcharName)
SELECT DISTINCT
LastName + ', ' + FirstName + ' ' + ISNULL(MiddleName,'')
FROM AdventureWorks.Person.Person
INSERT INTO CharAsIndexKey (charName)
SELECT DISTINCT
LastName + ', ' + FirstName + ' ' + ISNULL(MiddleName,'')
FROM AdventureWorks.Person.Person
GO
Welke van de 2 is beter? Laten we de logische waarden controleren door de onderstaande code te gebruiken en de uitvoer van STATISTICS IO te inspecteren.
SET NOCOUNT ON
SET STATISTICS IO ON
SELECT id, varcharName
FROM VarcharAsIndexKey
SELECT id, charName
FROM CharAsIndexKey
SET STATISTICS IO OFF
Logische leest:
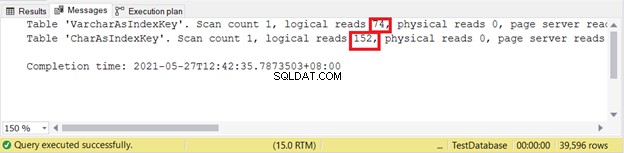
Hoe minder logisch, hoe beter. Hier gebruikte de CHAR-kolom meer dan het dubbele van de VARCHAR-tegenhanger. Dus VARCHAR wint in dit voorbeeld.
3. Gebruik VARCHAR als indexsleutel in plaats van CHAR wanneer waarden variëren in grootte
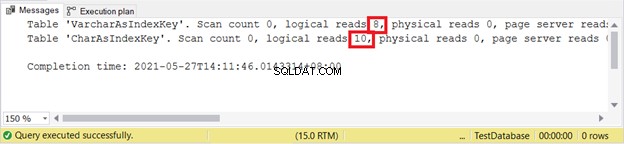
Wat gebeurde er bij gebruik als indexsleutels? Zal CHAR het beter doen dan VARCHAR? Laten we dezelfde gegevens uit de vorige sectie gebruiken en deze vraag beantwoorden.
We zullen enkele gegevens opvragen en de logische waarden controleren. In dit voorbeeld gebruikt het filter de indexsleutel.
SET NOCOUNT ON
SET STATISTICS IO ON
SELECT varcharName FROM VarcharAsIndexKey
WHERE varcharName = 'Sai, Adriana A'
OR varcharName = 'Rogers, Caitlin D'
SELECT charName FROM CharAsIndexKey
WHERE charName = 'Sai, Adriana A'
OR charName = 'Rogers, Caitlin D'
SET STATISTICS IO OFF
Logische leest:
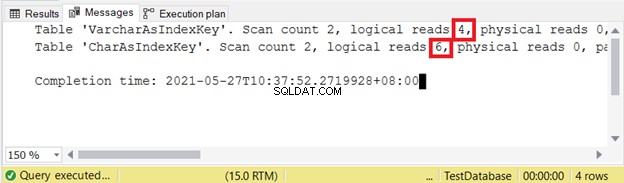
Daarom zijn VARCHAR-indexsleutels beter dan CHAR-indexsleutels wanneer de sleutel verschillende groottes heeft. Maar hoe zit het met INSERT en UPDATE die de indexitems zullen veranderen?
BIJ GEBRUIK VAN INSERT EN UPDATE
Laten we 2 gevallen testen en dan de logische waarden controleren zoals we gewoonlijk doen.
SET STATISTICS IO ON
INSERT INTO VarcharAsIndexKey (varcharName)
VALUES ('Ruffalo, Mark'), ('Johansson, Scarlett')
INSERT INTO CharAsIndexKey (charName)
VALUES ('Ruffalo, Mark'), ('Johansson, Scarlett')
SET STATISTICS IO OFF
Logische leest:
VARCHAR is nog steeds beter bij het invoegen van records. Hoe zit het met UPDATE?
SET STATISTICS IO ON
UPDATE VarcharAsIndexKey
SET varcharName = 'Hulk'
WHERE varcharName = 'Ruffalo, Mark'
UPDATE CharAsIndexKey
SET charName = 'Hulk'
WHERE charName = 'Ruffalo, Mark'
SET STATISTICS IO OFF
Logische leest:
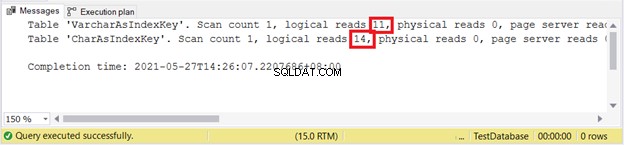
Het lijkt erop dat VARCHAR opnieuw wint.
Uiteindelijk wint het onze test, hoewel het misschien klein is. Heb je een grotere testcase die het tegendeel bewijst?
4. Overweeg VARCHAR met UTF-8-ondersteuning voor meertalige gegevens (SQL Server 2019+)
Als er een combinatie van Unicode- en niet-Unicode-tekens in uw tabel staat, kunt u VARCHAR met UTF-8-ondersteuning in plaats van NVARCHAR overwegen. Als de meeste tekens binnen het bereik van ASCII 0 tot 127 liggen, kan dit ruimtebesparing opleveren in vergelijking met NVARCHAR.
Laten we een vergelijking maken om te zien wat ik bedoel.
NVARCHAR NAAR VARCHAR MET UTF-8-ONDERSTEUNING
Heeft u uw databases al gemigreerd naar SQL Server 2019? Bent u van plan uw stringgegevens te migreren naar UTF-8-sortering? We hebben een voorbeeld van een gemengde waarde van Japanse en niet-Japanse karakters om je een idee te geven.
CREATE TABLE NVarcharToVarcharUTF8
(
NVarcharValue NVARCHAR(20) NOT NULL,
VarcharUTF8 VARCHAR(45) COLLATE Latin1_General_100_BIN2_UTF8 NOT NULL
)
GO
INSERT INTO NVarcharToVarcharUTF8
(NVarcharValue, VarcharUTF8)
VALUES
(N'NARUTO-ナルト- 疾風伝',N'NARUTO-ナルト- 疾風伝'); -- NARUTO Shippûden
SELECT
NVarcharValue
,LEN(NVarcharValue) AS nvarcharNoOfChars
,DATALENGTH(NVarcharValue) AS nvarcharSizeInBytes
,VarcharUTF8
,LEN(VarcharUTF8) AS varcharNoOfChars
,DATALENGTH(VarcharUTF8) AS varcharSizeInBytes
FROM NVarcharToVarcharUTF8
Nu de gegevens zijn ingesteld, inspecteren we de grootte in bytes van de 2 waarden:

Verrassing! Met NVARCHAR is de grootte 30 bytes. Dat is 15 keer meer dan 2 tekens. Maar wanneer geconverteerd naar VARCHAR met UTF-8-ondersteuning, is de grootte slechts 27 bytes. Waarom 27? Controleer hoe dit wordt berekend.

Dus 9 van de karakters zijn elk 1 byte. Dat is interessant, want met NVARCHAR zijn Engelse letters ook 2 bytes. De rest van de Japanse karakters zijn elk 3 bytes.
Als dit allemaal Japanse tekens zijn, zou de tekenreeks van 15 tekens 45 bytes zijn en ook de maximale grootte van de VarcharUTF8 gebruiken kolom. Merk op dat de grootte van de NVarcharValue kolom is kleiner dan VarcharUTF8 .
De formaten kunnen niet gelijk zijn bij het converteren van NVARCHAR, of de gegevens passen mogelijk niet. U kunt verwijzen naar de vorige tabel 1.
Houd rekening met de impact op de grootte bij het converteren van NVARCHAR naar VARCHAR met UTF-8-ondersteuning.
Don'ts bij het gebruik van VARCHAR in SQL Server
1. Als de tekenreeksgrootte vast en niet-nullbaar is, gebruik dan in plaats daarvan CHAR.
De algemene vuistregel wanneer een string met een vaste grootte vereist is, is om CHAR te gebruiken. Ik volg dit wanneer ik een gegevensvereiste heb die rechts opgevulde spaties nodig heeft. Anders gebruik ik VARCHAR. Ik had een paar gevallen waarin ik strings met een vaste lengte zonder scheidingstekens in een tekstbestand voor een klant moest dumpen.
Verder gebruik ik CHAR-kolommen alleen als de kolommen niet-nullable zijn. Waarom? Omdat de grootte in bytes van CHAR-kolommen wanneer NULL gelijk is aan de gedefinieerde grootte van de kolom. Toch heeft VARCHAR wanneer NULL een grootte van 1 heeft, ongeacht hoeveel de gedefinieerde grootte is. Voer de onderstaande code uit en zie het zelf.
DECLARE @charValue CHAR(50) = NULL;
DECLARE @varcharValue VARCHAR(1000) = NULL;
SELECT
DATALENGTH(ISNULL(@charvalue,0)) AS CharSize
,DATALENGTH(ISNULL(@varcharvalue,0)) AS VarcharSize
2. Gebruik VARCHAR(n) niet als n Zal de 8000 bytes overschrijden. Gebruik in plaats daarvan VARCHAR(MAX).
Heb je een string die groter is dan 8000 bytes? Dit is het moment om VARCHAR(MAX) te gebruiken. Maar voor de meest voorkomende vormen van gegevens, zoals namen en adressen, is VARCHAR(MAX) overdreven en zal het de prestaties beïnvloeden. In mijn persoonlijke ervaring kan ik me niet herinneren dat ik VARCHAR(MAX) nodig had.
3. Bij gebruik van meertalige tekens met SQL Server 2017 en lager. Gebruik in plaats daarvan NVARCHAR.
Dit is een voor de hand liggende keuze als je nog steeds SQL Server 2017 en lager gebruikt.
De bottomline
Het VARCHAR-gegevenstype heeft ons voor zoveel aspecten goed gediend. Dat deed het voor mij sinds SQL Server 7. Toch maken we soms nog steeds slechte keuzes. In dit bericht wordt SQL VARCHAR gedefinieerd en vergeleken met andere typen stringgegevens met voorbeelden. En nogmaals, hier zijn de do's en don'ts voor een snellere database:
Do's:
- Geef de maat op n in VARCHAR[(n)], zelfs als het optioneel is.
- Gebruik het als de tekenreeks aanzienlijk varieert.
- Beschouw VARCHAR-kolommen als indexsleutels in plaats van CHAR.
- En als je nu SQL Server 2019 gebruikt, overweeg dan VARCHAR voor meertalige strings met UTF-8-ondersteuning.
Niet doen:
- Gebruik VARCHAR niet wanneer de tekenreeksgrootte vast en niet-nullable is.
- Gebruik VARCHAR(n) niet als de tekenreeks groter is dan 8000 bytes.
- En gebruik VARCHAR niet voor meertalige gegevens bij gebruik van SQL Server 2017 en eerder.
Heb je nog iets toe te voegen? Laat het ons weten in het gedeelte Opmerkingen. Als je denkt dat dit je ontwikkelaarsvrienden zal helpen, deel dit dan op je favoriete sociale-mediaplatforms.