Dit artikel behandelt de basisprincipes van Semantic Search, inclusief een compleet overzicht van Semantic Search:helemaal opnieuw beginnen en eindigen met een kant-en-klare functie.
Bovendien zullen de lezers leren over enkele van de zeer nuttige maar niet algemeen bekende zoekfuncties die beschikbaar zijn in SQL Server, zoals Semantic Search, die we zullen demonstreren met enkele basisvoorbeelden.
Dit artikel benadrukt ook het belang van Semantic Search voor een specifieke vorm van analyse die niet kan worden uitgevoerd met een gewone zoekopdracht.
Wat is semantisch zoeken
Laten we eerst uitzoeken wat semantisch zoeken precies is en hoe het verschilt van zoeken in volledige tekst.
Microsoft-definitie
Volgens Microsoft-documentatie biedt Semantic Search diepgaand inzicht in ongestructureerde documenten.
Alternatieve definitie
Semantisch zoeken is een speciale zoektechnologie of -functie die wordt gebruikt om een uitgebreide zoekopdracht of een vergelijkende analyse uit te voeren, voornamelijk in ongestructureerde gegevens of documenten, zoals MS Word-documenten, op voorwaarde dat de ongestructureerde gegevens zijn opgeslagen in de SQL Server-database.
Compatibiliteit
Semantic Search is alleen compatibel met SQL Server 2012 en latere versies.
Houd er rekening mee dat Semantic Search niet compatibel is met Azure SQL-database of Azure datawarehouse-cloudoplossingen.
Dit betekent dat u ofwel met een VM op Azure of op een on-premises SQL Server-instantie moet werken om deze krachtige functie te gebruiken.
Semantisch zoeken versus zoeken in volledige tekst
Volgens Microsoft-documentatie kunt u met Full-Text Search de woorden in een document opvragen; Met semantisch zoeken kunt u de betekenis van het document opvragen.
Semantisch zoeken vormt samen met Zoeken in volledige tekst een gezamenlijke functie die wordt aangeboden door Microsoft SQL Server, en u kunt ervoor kiezen om ze te installeren tijdens de installatie van uw SQL Server-instantie of later, door nieuwe functies toe te voegen aan uw bestaande SQL-instantie.
Vereisten
Laten we de vereisten voor het algemene gebruik van Semantic Search doornemen, samen met enkele dingen die nodig zijn om de stappen in dit artikel te volgen.
Zoeken in volledige tekst geïnstalleerd
Het is verplicht om te weten hoe u zoeken in volledige tekst moet instellen, aangezien zoeken in volledige tekst en semantisch zoeken beide als een gezamenlijke functie worden aangeboden.
Raadpleeg het artikel Full-Text Search implementeren in SQL Server 2016 voor beginners om Full-Text Search in te stellen, wat een vereiste is voor het installeren van Semantic Search in SQL Server.
In dit artikel wordt verwacht dat u Full-Text Search op uw SQL Server-instantie hebt geïnstalleerd.
dbForge Studio voor SQL Server
Het gebruik van Semantic Search (in het overzicht van dit artikel) vereist dat ongestructureerde gegevens worden opgeslagen in de SQL Server-database, en in dit artikel hebben we dit gedaan met dbForge Studio voor SQL Server in plaats van direct ongestructureerde gegevens op te slaan in SQL Server.
SQL Server 2016
We gebruiken SQL Server 2016 in dit artikel, maar de stappen zouden bijna hetzelfde moeten zijn voor elke andere compatibele versie.
Semantisch zoeken instellen
Om semantisch zoeken of statistisch semantisch zoeken te gebruiken, kunt u het installeren tijdens de installatie van zoeken in volledige tekst of daarna, door zoeken in volledige tekst en semantisch zoeken als nieuwe functie toe te voegen.
Controle voor zoeken in volledige tekst
Controleer de installatiestatus van Full-Text Search en Semantic Search door het volgende script uit te voeren op de hoofddatabase:
-- Full-Text Search and Semantic Search status
SELECT SERVERPROPERTY('IsFullTextInstalled') as [Full-Text-Search-and-Semantic-Search-Installed];
GO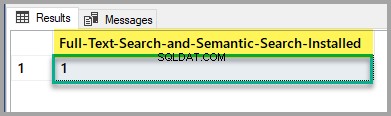
Als de uitvoer 1 is, bent u klaar om te gaan, maar als het 0 is, raadpleeg dan het hierboven genoemde artikel om de functie Full-Text Search en Semantic Search te installeren met behulp van de SQL Server-setup.
Installeer database met semantische taalstatistieken
Installeer Semantic Language Statistics Database door te zoeken in Microsoft® SQL Server® 2016 Semantic Language Statistics op internet of door op de volgende link te klikken.
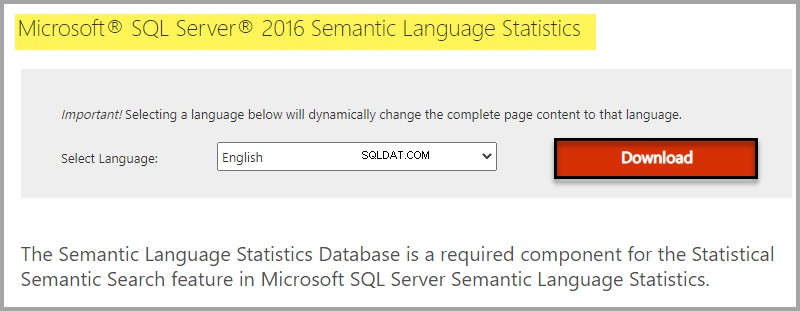
Download selecteren op basis van uw Windows-editie:
Installeer de taaldatabase:
Klik op Volgende om verder te gaan als u akkoord gaat met de voorwaarden in de licentieovereenkomst:
Laat de standaardopties zoals ze zijn, maar het wordt aanbevolen om de schijfkosten te controleren zoals hieronder weergegeven:
Hoewel het bestand slechts ongeveer 747 MB ruimte in beslag neemt (op het moment van schrijven van dit artikel), moet u de schijfkosten controleren om er zeker van te zijn dat u voldoende ruimte beschikbaar heeft:
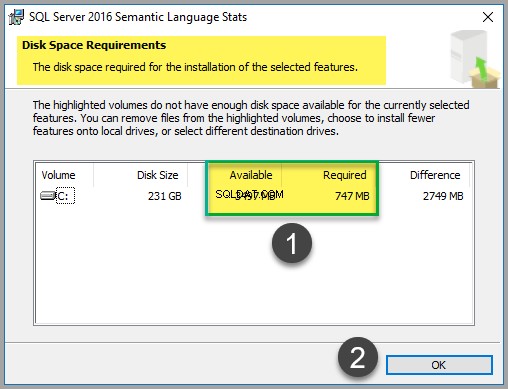
Als u klaar bent met de schijfkostencontrole, klikt u op OK en klik vervolgens op Volgende .
U wordt gevraagd om het bestand te installeren. Klik op Installeren (indien geïnteresseerd om dit te doen):
Klik op Voltooien zodra de installatie met succes is voltooid, zou dit eruit moeten zien als de onderstaande schermafbeelding:
Zoek de map waarin de Semantic Language Database standaard is geïnstalleerd (C:\Program Files\Microsoft Semantic Language Database):
Alles ziet er goed uit, dus kopieer het gegevens- en logbestand naar de gegevensmap van uw SQL-instantie, zoals hieronder weergegeven:
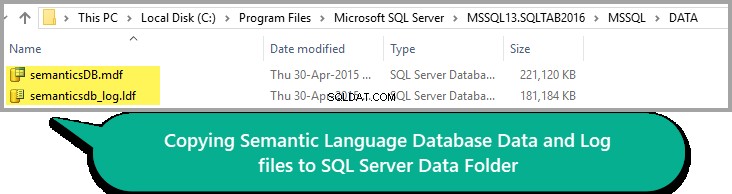
Houd er rekening mee dat het pad van de DATA-map kan verschillen op basis van uw SQL Server-versie.
Semantische taaldatabase aan SQL-instantie koppelen
Klik met de rechtermuisknop op de Databases knooppunt onder Objectverkenner in SSMS (SQL Server Management Studio) en klik op Bijvoegen :
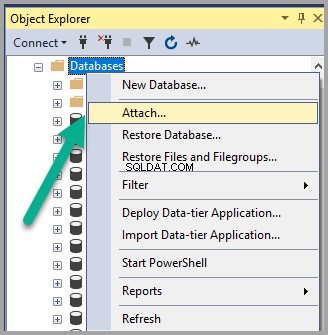
Semanticsdb.mdf toevoegen en klik op OK :
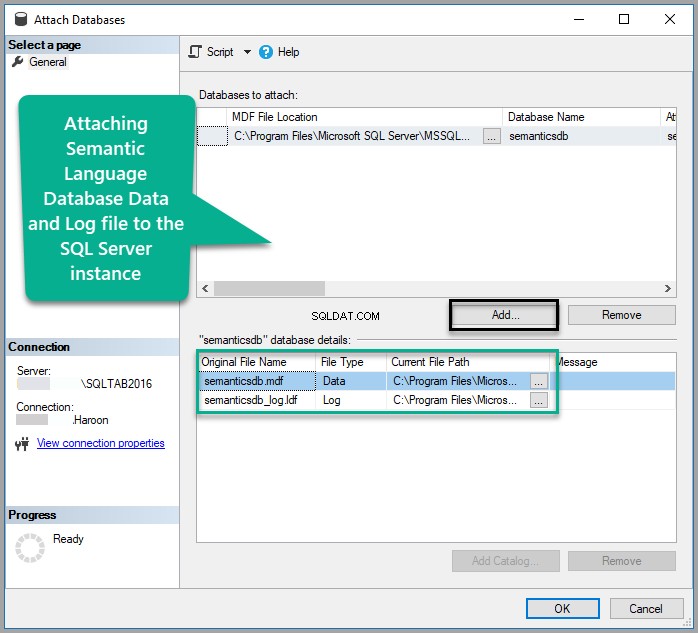
Bekijk de database:
Semantische database registreren
Typ het volgende script in de hoofddatabase om de Semantische taalstatistiekendatabase te registreren:
-- Register Semantic Language Statistics Database
EXEC sp_fulltext_semantic_register_language_statistics_db @dbname = N'semanticsdb';
GOControleer de semantische databasestatus
Controleer de status van de Semantische taalstatistiekendatabase door het volgende script uit te voeren tegen de hoofddatabase:
-- Check Semantic Language Statistics Database status
SELECT * FROM sys.fulltext_semantic_language_statistics_database;
GODe uitvoer mag niet leeg zijn en zou als volgt zijn:

Houd er rekening mee dat de bovenstaande waarden op uw computer kunnen verschillen, wat normaal is zolang u een rij ziet. Dit betekent dat de database met semantische taalstatistieken met succes is geïnstalleerd op uw SQL-instantie.
Semantisch zoeken gebruiken
Zodra Semantic Search helemaal is ingesteld, zijn we klaar om het in SQL Server te gebruiken.
Semantisch zoekscenario
We gaan de documenten (voorbeelden) van medewerkers opslaan in rich text-indeling in de SQL Server-database om later te doorzoeken en te vergelijken met Semantic Search.
Een EmployeesSample Database opzetten
Maak een voorbeelddatabase met een enkele tabel door het T-SQL-script als volgt uit te voeren op de hoofddatabase:
-- (1) Setup sample database
Create DATABASE EmployeesSample;
GO
USE EmployeesSample
-- (2) Create EmployeesForSemanticSearch table
CREATE TABLE [dbo].[EmployeesForSemanticSearch](
[EmpID] [int] NOT NULL,
[DocumentName] [varchar](200) NULL,
[EmpDocument] [varbinary](max) NULL,
[EmpDocumentType] [varchar](200) NULL,
CONSTRAINT [PK_EmployeesForSemanticSearch_EmpID] PRIMARY KEY CLUSTERED
(
[EmpID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]
GOControleer de voorbeelddatabase
Voer het volgende script uit om de voorbeelddatabasetabel te controleren:
-- View all the employees
SELECT efss.EmpID
,efss.DocumentName
,efss.EmpDocument
,efss.EmpDocumentType FROM dbo.EmployeesForSemanticSearch efssDe uitvoer is als volgt:
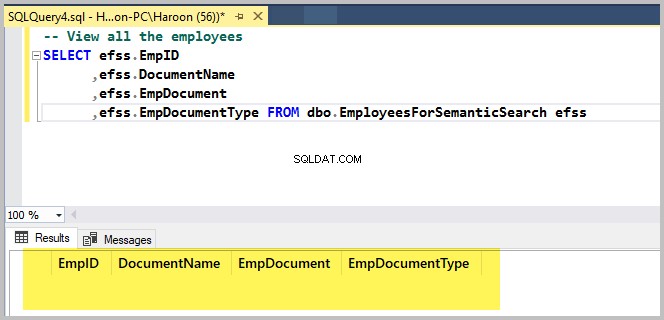
Voeg het eerste rich-text-bestand toe met dbForge Studio voor SQL Server
We gaan binaire gegevens aan de tabellen toevoegen, die wordt weergegeven door RTF-bestanden, met behulp van dbForge Studio voor SQL Server .
Open de voorbeelddatabase EmployeesSample in dbForge Studio voor SQL Server.
Klik met de rechtermuisknop op de EmployeesForSemanticSearch tabel en klik op Gegevens ophalen:
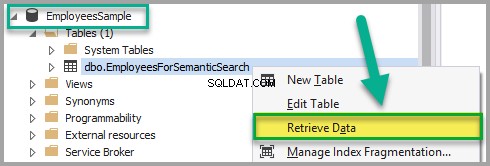
Voeg de volgende gegevens toe aan de EmployeesForSemanticSearch tabel behalve de EmpDocument kolom nadat u zeker weet dat de tabel niet in de alleen-lezen modus staat:
EmpID:1
Documentnaam:Medewerker1Document
EmpDocument:(null)
EmpDocumentType:.rtf
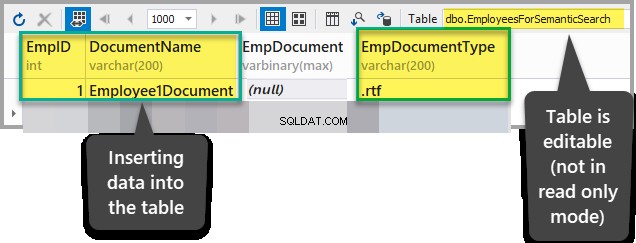
Voeg een RTF-document in in het EmpDocument kolom door de volgende tekst aan de tabel toe te voegen (door op ellipsen te klikken en de gegevens toe te voegen):
This is a research based article and it is a new research which is in process but this is superb in the field of research.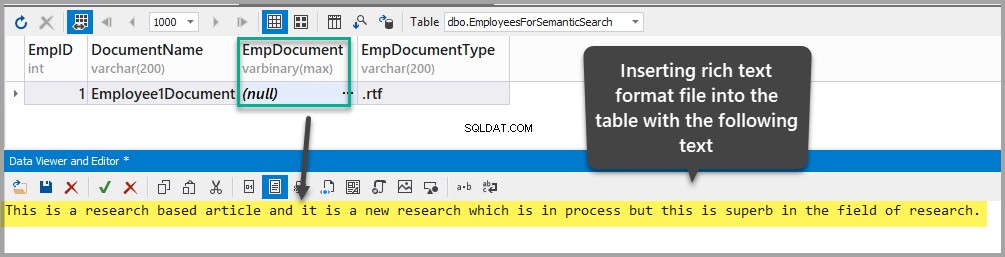
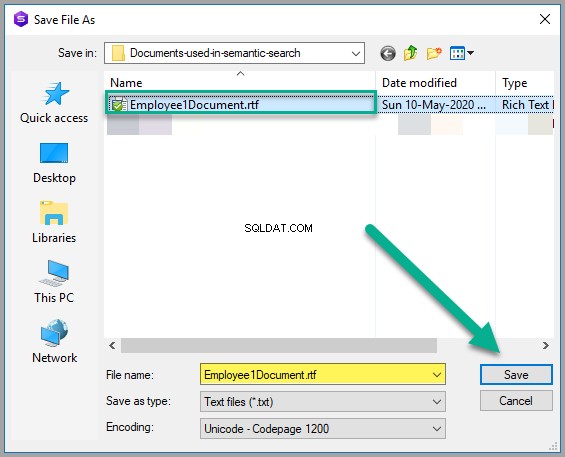
Sla het document op als Employee1Document.rtf in elke geschikte Windows-map:
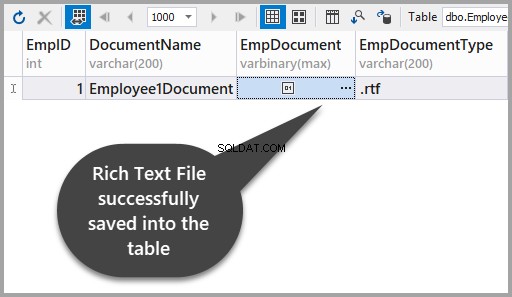
Pas de wijzigingen toe om te zien of u met succes een RTF-bestand in de tabel hebt opgeslagen:
Voeg het tweede rich-text-bestand toe met dbForge Studio voor SQL Server
Voeg vervolgens nog een RTF-bestand toe aan de EmployeesForSemanticSearch tabel op dezelfde manier als hierboven met behulp van de volgende informatie:
EmpID:2
Documentnaam:Medewerker2Document
EmpDocument:(null)
EmpDocumentType:.rtf
Voeg nog een Rich Text-bestand toe met de volgende tekst:
This is an article which is about facts and figures with little research in it it talks about fact and figures just facts and figures.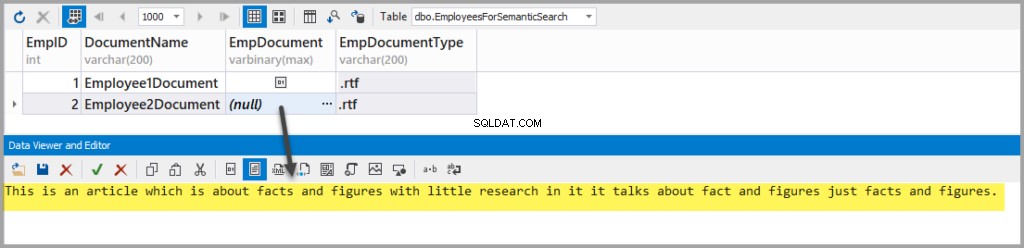
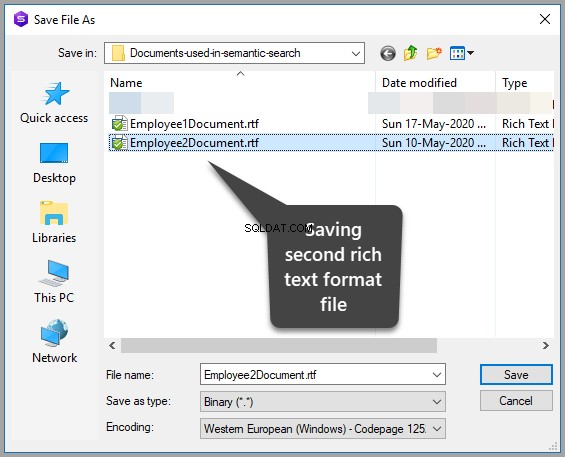
Sla het document als volgt op in dezelfde map:
Sla de gegevens op door de tabel te vernieuwen en vervolgens de wijzigingen die u zojuist hebt aangebracht te bevestigen door op ja te klikken:
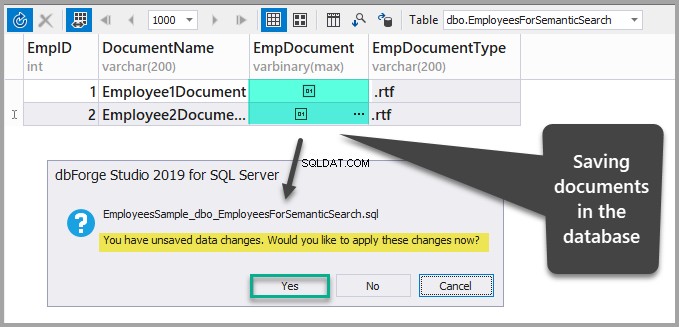
Maak een unieke index, full-text index en semantische index met behulp van Wizard
Terug in SSMS (SQL Server Management Studio), klik met de rechtermuisknop op de tabel en klik op Full-Text index en klik vervolgens opDefinieer Full-Text index… zoals hieronder weergegeven:
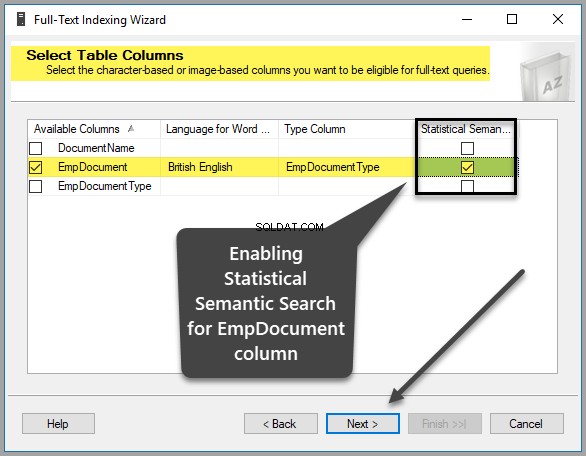
Vervolgens moet u een unieke index selecteren, die in feite standaard is geselecteerd, omdat we EmpID hebben gemaakt primaire sleutelkolom eerder, zoals hieronder weergegeven, klik daarom op Volgende om door te gaan:
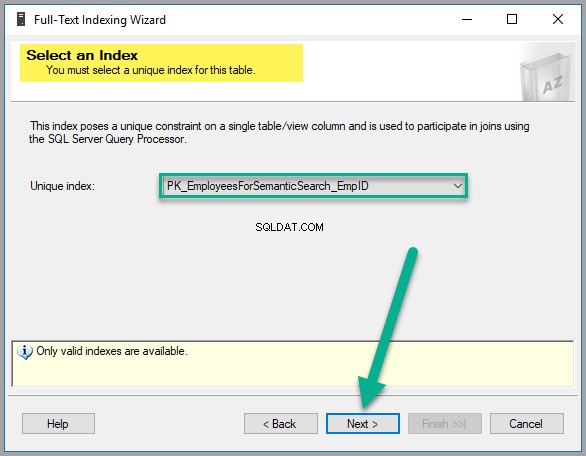
Selecteer EmpDocument van Beschikbare kolommen , Brits Engels als Taal voor Woordbreker , EmpDocumentType als Kolom typen en controleer de Statistische semantische zoekopdracht in dezelfde rij als volgt:
Selecteer de optie voor het bijhouden van wijzigingen door deze als standaardinstellingen te laten staan, tenzij u een goede reden hebt om deze instellingen te wijzigen:
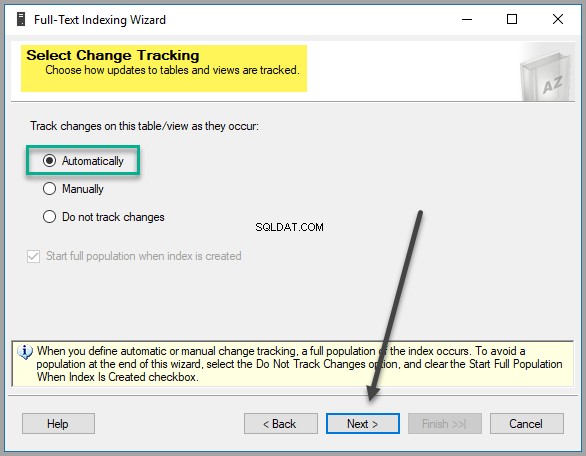
Maak een nieuwe catalogus als EmployeeCatalog :
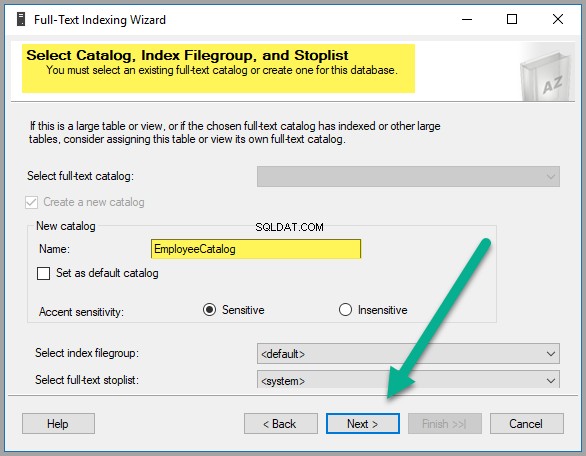
Klik op Volgende nogmaals:
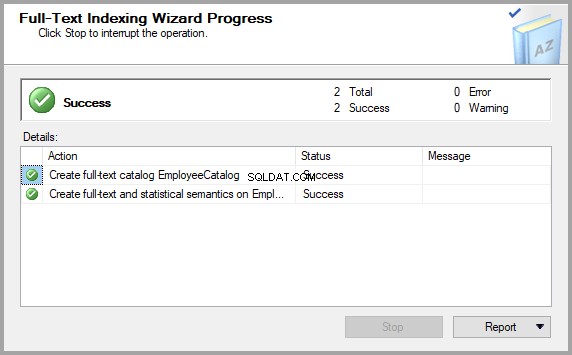
Eindelijk, na nog een paar klikken (Klik op Volgende ), is de vereiste tabel klaar om te worden opgevraagd door Semantic Search:
Controleer of semantisch zoeken is ingeschakeld voor een tabel
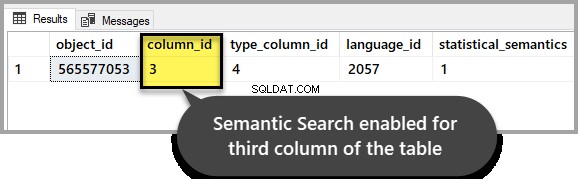
Controleer of Semantic Search intact blijft voor de tabel van interesse door het volgende script uit te voeren op de voorbeelddatabase:
-- Check if Semantic Search is enabled for a database, table, and column
SELECT * FROM sys.fulltext_index_columns WHERE object_id = OBJECT_ID('EmployeesForSemanticSearch')
GODe uitvoer moet aangeven dat deze is ingeschakeld voor de derde kolom zoals we deze aan het begin van de walkthrough hebben ingesteld:
Voorbeeld 1:Semantische zoekscore gebruiken om een relevant document te vinden
We kunnen nu Semantic Search gebruiken om twee documenten te vergelijken om een trefwoord van belang en de relatieve score te vinden, wat ons helpt om naar meer relevante documenten te verwijzen.
Als we geïnteresseerd zijn om het document te bekijken waarin het woord "onderzoek ” vaker wordt genoemd in vergelijking met het andere document, dan moeten we de score voor elk van de documenten in de gaten houden wanneer we het volgende T-SQL-script uitvoeren:
-- Using Semantic Search to find the score for the word research in both documents
SELECT TOP (100) DOC_TBL.EmpID, DOC_TBL.EmpDocumentType,KEYP_TBL.keyphrase,
KEYP_TBL.score
FROM
EmployeesForSemanticSearch AS DOC_TBL
INNER JOIN SEMANTICKEYPHRASETABLE
(
EmployeesForSemanticSearch,
EmpDocument
) AS KEYP_TBL
ON DOC_TBL.EmpID = KEYP_TBL.document_key
WHERE KEYP_TBL.keyphrase = 'research'
ORDER BY KEYP_TBL.Score DESC;Het resultaat van de bovenstaande zoekopdracht is als volgt:
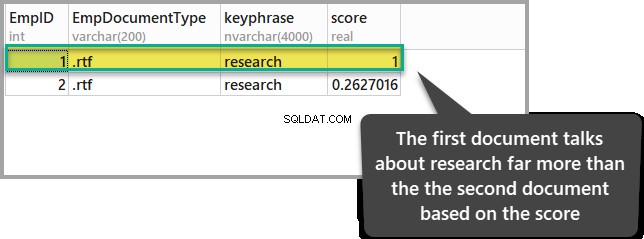
Het document met de hoogste score laat zien dat het relevanter is in vergelijking met het andere document wat ons aandachtspunt (onderzoek) betreft.
Voorbeeld 2:Semantische zoekscore gebruiken om een relevant document te vinden
We kunnen ook het document vinden waar het woord 'feit' domineert in vergelijking met elk ander document door het onderstaande script uit te voeren:
-- Using Semantic Search to find the score for the word fact in both documents
SELECT TOP (100) DOC_TBL.EmpID, DOC_TBL.EmpDocumentType,KEYP_TBL.keyphrase,
KEYP_TBL.score
FROM
EmployeesForSemanticSearch AS DOC_TBL
INNER JOIN SEMANTICKEYPHRASETABLE
(
EmployeesForSemanticSearch,
EmpDocument
) AS KEYP_TBL
ON DOC_TBL.EmpID = KEYP_TBL.document_key
WHERE KEYP_TBL.keyphrase = 'fact'
ORDER BY KEYP_TBL.Score DESC;De resultaten zijn als volgt:
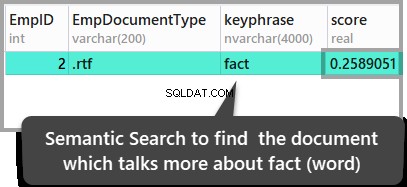
Bovenstaande resultaten leiden tot de conclusie dat het tweede opgeslagen document het enige document is waar het woord feit wordt genoemd, maar als u deze resultaten wilt controleren, opent u de opgeslagen documenten om ze te bekijken.
Gefeliciteerd! Je hebt met succes geleerd om niet alleen Semantic Search in SQL Server in te stellen, maar hebt ook wat praktische ervaring opgedaan met het gebruik van Semantic Search.
Dingen om te doen
Nu u enkele basisquery's voor semantisch zoeken kunt instellen en schrijven, kunt u het volgende proberen om uw vaardigheden verder te verbeteren:
- Probeer nog een document toe te voegen dat vertelt over onderzoek en voer vervolgens het script in het eerste voorbeeld uit om te zien welk document het meest relevante document is door hun scores te vergelijken.
- Houd dit artikel in gedachten en voeg een ander document toe met het woord feit wordt een paar keer genoemd en voer vervolgens de T-SQL uit in voorbeeld 2 van dit artikel om te zien of de resultaten hetzelfde blijven of veranderen.
- Probeer Semantic Search te gebruiken door meer documenten en meer tekst toe te voegen aan zowel bestaande als nieuwe documenten en vervolgens de documenten te vinden die overeenkomen met uw woorden die u interesseren.
- Bekijk de voorbeelden verderop om er zelf achter te komen of Semantisch zoeken hoofdlettergevoelig of hoofdletterongevoelig is (Hint:u kunt de voorbeelden enigszins aanpassen).