Sinds de release van SQL Server 2017 voor Linux heeft Microsoft het hele spel vrijwel veranderd. Het zorgde voor een hele nieuwe wereld van mogelijkheden voor hun beroemde relationele database, met wat tot dan toe alleen beschikbaar was in de Windows-ruimte.
Ik weet dat een puristische DBA me meteen zou vertellen dat de kant-en-klare SQL Server 2019 Linux-versie verschillende verschillen heeft, in termen van functies, met betrekking tot zijn Windows-tegenhanger, zoals:
- Geen SQL Server-agent
- Geen FileStream
- Geen systeemuitbreiding opgeslagen procedures (bijv. xp_cmdshell)
Ik werd echter nieuwsgierig genoeg om te denken "wat als ze kunnen worden vergeleken, althans tot op zekere hoogte, met dingen die beide kunnen doen?" Dus ik haalde de trekker over op een paar VM's, bereidde enkele eenvoudige tests voor en verzamelde gegevens om aan u te presenteren. Laten we eens kijken hoe het afloopt!
Eerste overwegingen
Dit zijn de specificaties van elke VM:
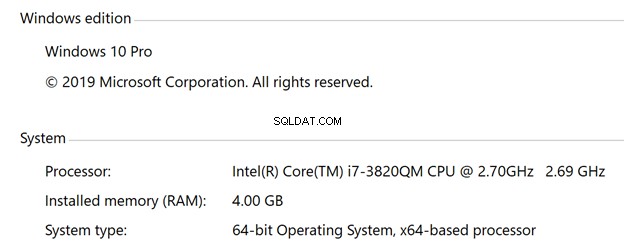
- Windows
- Windows 10 besturingssysteem
- 4 vCPU's
- 4 GB RAM
- 30 GB SSD
- Linux
- Ubuntu Server 20.04 LTS
- 4 vCPU's
- 4 GB RAM
- 30 GB SSD


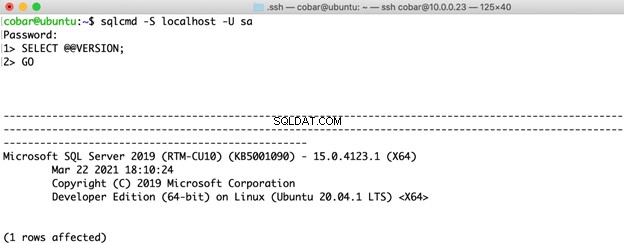
Voor de SQL Server-versie heb ik de allernieuwste gekozen voor beide besturingssystemen:SQL Server 2019 Developer Edition CU10
Bij elke implementatie was het enige dat was ingeschakeld Instant File Initialization (standaard ingeschakeld op Linux, handmatig ingeschakeld op Windows). Verder bleven de standaardwaarden voor de rest van de instellingen.
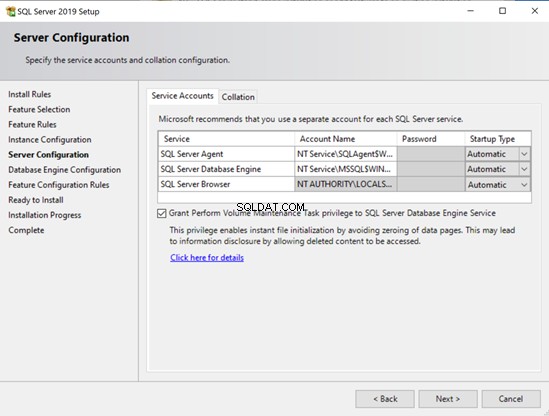
- In Windows kunt u ervoor kiezen om Instant File Initialization in te schakelen met de installatiewizard.
Dit bericht behandelt niet de specificiteit van het Instant File Initialization-werk in Linux. Ik laat je echter een link achter naar het speciale artikel dat je later kunt lezen (houd er rekening mee dat het een beetje zwaar wordt aan de technische kant).
Wat houdt de test in?
- In elke SQL Server 2019-instantie heb ik een testdatabase geïmplementeerd en één tabel gemaakt met slechts één veld (een NVARCHAR(MAX)).
- Met behulp van een willekeurig gegenereerde reeks van 1.000.000 tekens, heb ik de volgende stappen uitgevoerd:
- *Voeg X aantal rijen in de testtabel in.
- Meet hoeveel tijd het kostte om de INSERT-instructie in te vullen.
- Meet de grootte van de MDF- en LDF-bestanden.
- Verwijder alle rijen in de testtabel.
- **Meet hoeveel tijd het kostte om de DELETE-instructie in te vullen.
- Meet de grootte van het LDF-bestand.
- Laat de testdatabase vallen.
- Maak de testdatabase opnieuw.
- Herhaal dezelfde cyclus.
*X is uitgevoerd voor 1.000, 5.000, 10.000, 25.000 en 50.000 rijen.
**Ik weet dat een TRUNCATE-instructie het werk veel efficiënter doet, maar mijn punt hier is om te bewijzen hoe goed elk transactielogboek wordt beheerd voor de verwijderingsbewerking in elk besturingssysteem.
Je kunt doorgaan naar de website die ik heb gebruikt om de willekeurige reeks te genereren als je dieper wilt graven.
Dit zijn de secties van de TSQL-code die ik heb gebruikt voor tests in elk besturingssysteem:
Linux TSQL-codes
Database en tabellen maken
DROP DATABASE IF EXISTS test
CREATE DATABASE test
ON
(FILENAME= '/var/opt/mssql/data/test.mdf', NAME = test, FILEGROWTH = 128MB)
LOG ON
(FILENAME= '/var/opt/mssql/data/test_log.ldf',NAME = test_log, FILEGROWTH = 64MB);
CREATE TABLE test.dbo.ubuntu(
long_string NVARCHAR(MAX) NOT NULL
)
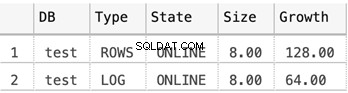
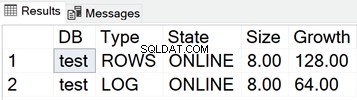
Grootte van de MDF- en LDF-bestanden voor de testdatabase
SELECT
DB_NAME(database_id) AS 'DB',
type_desc AS 'Type',
state_desc AS 'State',
CONVERT(DECIMAL(10,2),size*8/1024) AS 'Size',
CONVERT(DECIMAL(10,2),growth*8/1024) AS 'Growth'
FROM sys.master_files
WHERE DB_NAME(database_id) = 'test'
De onderstaande schermafbeelding toont de grootte van de gegevensbestanden wanneer er niets in de database is opgeslagen:
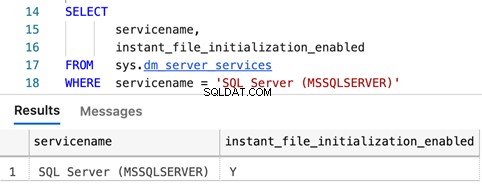
Vragen om te bepalen of Instant File Initialization is ingeschakeld
SELECT
servicename,
instant_file_initialization_enabled
FROM sys.dm_server_services
WHERE servicename = 'SQL Server (MSSQLSERVER)'

Windows TSQL-codes
Database en tabellen maken
DROP DATABASE IF EXISTS test
CREATE DATABASE test
ON
(FILENAME= 'S:\Program Files\Microsoft SQL Server\MSSQL15.WINDOWS\MSSQL\DATA\test.mdf', NAME = test, FILEGROWTH = 128MB)
LOG ON
(FILENAME= ''S:\Program Files\Microsoft SQL Server\MSSQL15.WINDOWS\MSSQL\DATA\test_log.ldf',NAME = test_log, FILEGROWTH = 64MB);
CREATE TABLE test.dbo.windows(
long_string NVARCHAR(MAX) NOT NULL
)
Grootte van de MDF- en LDF-bestanden voor de testdatabase
SELECT
DB_NAME(database_id) AS 'DB',
type_desc AS 'Type',
state_desc AS 'State',
CONVERT(DECIMAL(10,2),size*8/1024) AS 'Size',
CONVERT(DECIMAL(10,2),growth*8/1024) AS 'Growth'
FROM sys.master_files
WHERE DB_NAME(database_id) = 'test'
De volgende schermafbeelding toont de grootte van gegevensbestanden als er niets in de database is opgeslagen:
Query om te bepalen of Instant File Initialization is ingeschakeld
SELECT
servicename,
instant_file_initialization_enabled
FROM sys.dm_server_services
WHERE servicename = 'SQL Server (MSSQLSERVER)'
Script om de INSERT-instructie uit te voeren:
@limit -> hier heb ik het aantal rijen gespecificeerd dat in de testtabel moet worden ingevoegd
Voor Linux, aangezien ik het script met SQLCMD heb uitgevoerd, heb ik de DATEDIFF-functie helemaal aan het einde geplaatst. Het laat me weten hoeveel seconden de hele uitvoering duurt (voor de Windows-variant had ik gewoon een glimp kunnen opvangen van de timer in SQL Server Management Studio).
De hele reeks van 1.000.000 tekens gaat in plaats van 'XXXX'. Ik zeg het zo alleen om het mooi te presenteren in dit bericht.
SET NOCOUNT ON
GO
DECLARE @StartTime DATETIME;
DECLARE @i INT;
DECLARE @limit INT;
SET @StartTime = GETDATE();
SET @i = 0;
SET @limit = 1000;
WHILE(@i < @limit)
BEGIN
INSERT INTO test.dbo.ubuntu VALUES('XXXX');
SET @i = @i + 1
END
SELECT DATEDIFF(SECOND,@StartTime,GETDATE()) AS 'Elapsed Seconds';
Script om de DELETE-instructie uit te voeren
SET NOCOUNT ON
GO
DECLARE @StartTime DATETIME;
SET @StartTime = GETDATE();
DELETE FROM test.dbo.ubuntu;
SELECT DATEDIFF(SECOND,@StartTime,GETDATE()) AS 'Elapsed Seconds';
De behaalde resultaten
Alle formaten zijn uitgedrukt in MB. Alle timingmetingen worden uitgedrukt in seconden.
| TIJD INVOEREN | 1.000 records | 5,000 records | 10.000 records | 25.000 records | 50.000 records |
| Linux | 4 | 23 | 43 | 104 | 212 |
| Vensters | 4 | 28 | 172 | 531 | 186 |
| Formaat (MDF) | 1.000 records | 5,000 records | 10.000 records | 25.000 records | 50.000 records |
| Linux | 264 | 1032 | 2056 | 5128 | 10184 |
| Vensters | 264 | 1032 | 2056 | 5128 | 10248 |
| Grootte (LDF) | 1.000 records | 5,000 records | 10.000 records | 25.000 records | 50.000 records |
| Linux | 104 | 264 | 360 | 552 | 148 |
| Vensters | 136 | 328 | 392 | 456 | 584 |
| Tijd VERWIJDEREN | 1.000 records | 5,000 records | 10.000 records | 25.000 records | 50.000 records |
| Linux | 1 | 1 | 74 | 215 | 469 |
| Vensters | 1 | 63 | 126 | 357 | 396 |
| Grootte VERWIJDEREN (LDF) | 1.000 records | 5,000 records | 10.000 records | 25.000 records | 50.000 records |
| Linux | 136 | 264 | 392 | 584 | 680 |
| Vensters | 200 | 328 | 392 | 456 | 712 |
Belangrijke inzichten
- De grootte van de MDF was vrijwel consistent gedurende de hele test, en varieerde enigszins aan het einde (maar niets te gek).
- De timings voor INSERT's waren voor het grootste deel beter in Linux, behalve het einde toen Windows "de ronde won".
- De grootte van het transactielogbestand kon in Linux beter worden afgehandeld na elke ronde van INSERT's.
- De timings voor DELETE's waren voor het grootste deel beter in Linux, behalve het einde waar Windows "de ronde won" (ik vind het merkwaardig dat Windows ook de laatste INSERT-ronde won).
- De grootte van de transactielogbestanden na elke ronde van VERWIJDEREN was vrijwel gelijk in termen van ups en downs tussen de twee.
- Ik had graag met 100.000 rijen getest, maar ik had een beetje weinig schijfruimte, dus heb ik het beperkt tot 50.000.
Conclusie
Op basis van de resultaten van deze test zou ik zeggen dat er geen sterke reden is om te beweren dat de Linux-variant exponentieel beter presteert dan zijn Windows-tegenhanger. Dit is natuurlijk geenszins een formele test waarop u zich kunt baseren om een dergelijke beslissing te nemen. De oefening zelf was echter interessant genoeg voor mij.
Ik vermoed dat SQL Server 2019 voor Windows soms een beetje achterloopt (niet veel) vanwege de GUI-weergave op de achtergrond, wat niet gebeurt aan de Ubuntu Server-kant van het hek.
Als u sterk afhankelijk bent van functies en mogelijkheden die exclusief zijn voor Windows (tenminste op het moment van schrijven), ga er dan zeker voor. Anders maak je nauwelijks een slechte keuze door voor de een boven de ander te gaan.