We begonnen eerder te praten over problemen met de transactiereplicatie van SQL Server. Nu gaan we verder met nog een paar praktische demo's om inzicht te krijgen in vaak voorkomende prestatieproblemen met replicatie en hoe u deze op de juiste manier kunt oplossen.
We hebben al problemen besproken als configuratieproblemen, machtigingsproblemen, connectiviteitsproblemen en problemen met gegevensintegriteit, samen met het oplossen van problemen en het oplossen ervan. Nu gaan we ons concentreren op verschillende prestatieproblemen en corruptieproblemen die van invloed zijn op SQL Server-replicatie.
Aangezien corruptiekwesties een enorm onderwerp zijn, zullen we de gevolgen ervan alleen in dit artikel bespreken en niet in detail treden. Ik heb op basis van mijn ervaring verschillende scenario's gekozen die onder prestatie- en corruptieproblemen kunnen vallen:
- Prestatieproblemen
- Langlopende actieve transacties in uitgeversdatabase
- Bulk INSERT/UPDATE/DELETE bewerkingen op artikelen
- Enorme gegevenswijzigingen binnen een enkele transactie
- Blokkeringen in de distributiedatabase
- Corruptiegerelateerde problemen
- Corrupties in de uitgeversdatabase
- Beschadigingen in de distributiedatabase
- Beschadigingen in de database van abonnees
- MSDB-databasecorrupties
Prestatieproblemen
SQL Server Transactionele Replicatie is een gecompliceerde architectuur die verschillende parameters omvat, zoals de Publisher-database, de Distributor (distributie)-database, de Abonnee-database en verschillende Replication Agents die als SQL Server Agent-taken worden uitgevoerd.
Omdat we al deze items in detail hebben besproken in onze vorige artikelen, weten we hoe belangrijk elk item is voor de replicatiefunctionaliteit. Alles wat van invloed is op deze componenten kan de prestaties van de SQL Server-replicatie beïnvloeden.
Het Publisher-database-exemplaar bevat bijvoorbeeld een kritieke database met veel transacties per seconde. De serverbronnen hebben echter een knelpunt, zoals het consistente CPU-gebruik boven de 90% of het geheugengebruik boven de 90%. Het zal zeker een impact hebben op de prestaties van de Log Reader Agent Job, die de wijzigingsgegevens leest uit de transactielogboeken van de Publisher-database.
Evenzo kunnen dergelijke scenario's in database-instanties van Distributeur of Abonnee van invloed zijn op Snapshot Agent of Distribution Agent. Als DBA moet u er dus voor zorgen dat de serverbronnen zoals CPU, fysiek geheugen en netwerkbandbreedte efficiënt zijn geconfigureerd voor de database-instanties van uitgever, distributeur en abonnee.
Ervan uitgaande dat de databaseservers voor uitgevers, abonnees en distributeurs correct zijn geconfigureerd, kunnen we nog steeds problemen hebben met de replicatieprestaties wanneer we de onderstaande scenario's tegenkomen.
Langlopende actieve transacties in de uitgeversdatabase
Zoals de naam al aangeeft, laten langlopende actieve transacties zien dat er gedurende lange tijd een applicatie-aanroep of een gebruikersbewerking binnen het transactiebereik wordt uitgevoerd.
Het vinden van een langlopende actieve transactie betekent dat de transactie nog niet is vastgelegd en kan worden teruggedraaid of door de toepassing wordt vastgelegd. Dit voorkomt dat het transactielogboek wordt afgekapt, waardoor de bestandsgrootte van het transactielogboek voortdurend toeneemt.
Log Reader Agent scant op alle vastgelegde records die zijn gemarkeerd voor replicatie vanuit transactielogboeken in een geserialiseerde volgorde op basis van het logboekvolgnummer (LSN), waarbij alle andere wijzigingen worden overgeslagen voor artikelen die niet worden gerepliceerd. Als de langlopende actieve transactieopdrachten nog niet zijn vastgelegd, zal Replicatie het verzenden van die opdrachten overslaan en alle andere vastgelegde transacties naar de distributiedatabase sturen. Zodra de langlopende actieve transactie is vastgelegd, worden records naar de distributiedatabase verzonden en tot die tijd wordt het inactieve gedeelte van het transactielogboekbestand van Publisher DB niet gewist, waardoor het transactielogboekbestand van de Publisher-database groter wordt.
We kunnen het Long-Running Active Transaction-scenario testen door de onderstaande stappen uit te voeren:
Standaard ruimt Distribution Agent alle vastgelegde wijzigingen in de abonneedatabase op, waarbij de laatste record wordt bewaard om de nieuwe wijzigingen te controleren op basis van Log Sequence Number (LSN).
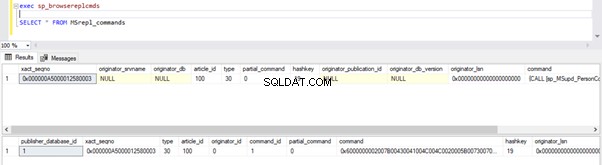
We kunnen de onderstaande query's uitvoeren om de status te controleren van de records die beschikbaar zijn in MSRepl_Commands tabellen of met behulp van de sp_browsereplcmds procedure in de distributiedatabase:
exec sp_browsereplcmds
GO
SELECT * FROM MSrepl_commands
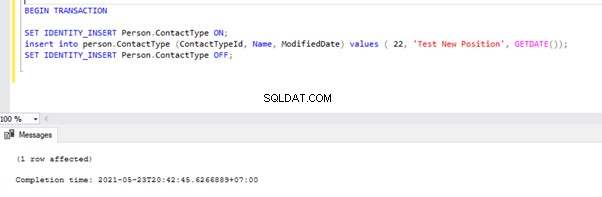
Open nu een nieuw queryvenster en voer het onderstaande script uit om een langlopende actieve transactie te maken op de AdventureWorks databank. Merk op dat het onderstaande script geen ROLLBACK- of COMMIT TRANSACTION-opdrachten bevat. Daarom raden we aan om dit soort commando's niet uit te voeren op de productiedatabase.
BEGIN TRANSACTION
SET IDENTITY_INSERT Person.ContactType ON;
insert into person.ContactType (ContactTypeId, Name, ModifiedDate) values ( 22, 'Test New Position', GETDATE());
SET IDENTITY_INSERT Person.ContactType OFF;
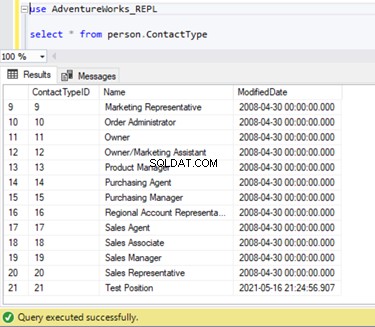
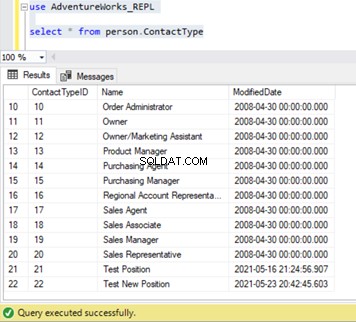
We kunnen verifiëren dat dit nieuwe record niet is gerepliceerd naar de abonneedatabase. Daarvoor voeren we de SELECT-instructie uit op het Person.ContactType tabel in de abonneedatabase:
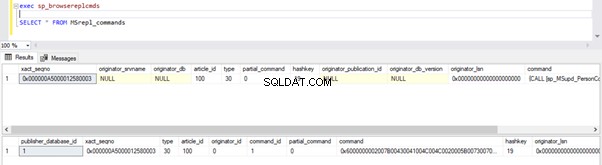
Laten we controleren of het bovenstaande INSERT-commando is gelezen door Log Reader Agent en in de Distributiedatabase is geschreven.
Voer de scripts uit het deel van stap 1 opnieuw uit. Resultaten tonen nog steeds dezelfde oude status, wat bevestigt dat het record niet is gelezen uit de transactielogboeken van de uitgeversdatabase.
Open nu een Nieuwe zoekopdracht venster en voer het onderstaande UPDATE-script uit om te zien of de Log Reader Agent de langlopende actieve transactie kon overslaan en de wijzigingen kon lezen die door deze UPDATE-instructie zijn aangebracht.
UPDATE AdventureWorks.dbo.AWBuildVersion
SET ModifiedDate = GETDATE()
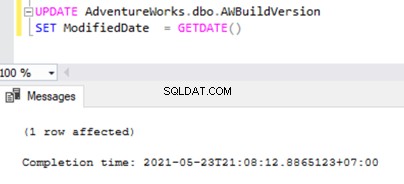
Controleer in de Distributiedatabase of de Log Reader Agent deze wijziging kan vastleggen. Voer het script uit als onderdeel van stap 1:
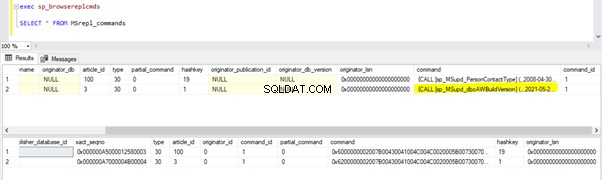
Aangezien de bovenstaande UPDATE-instructie is vastgelegd in de Publisher-database, kan Log Reader Agent deze wijziging scannen en in de Distributie-database invoegen. Vervolgens heeft het deze wijziging toegepast op de abonneedatabase, zoals hieronder weergegeven:
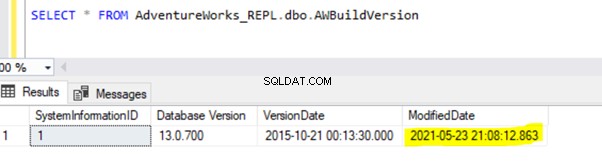
INSERT op Person.ContactType wordt alleen gerepliceerd naar de abonneedatabase nadat de INSERT-transactie is vastgelegd in de uitgeversdatabase. Voordat we ons committeren, kunnen we snel controleren hoe we een langlopende actieve transactie kunnen identificeren, begrijpen en efficiënt kunnen afhandelen.
Identificeer een langlopende actieve transactie
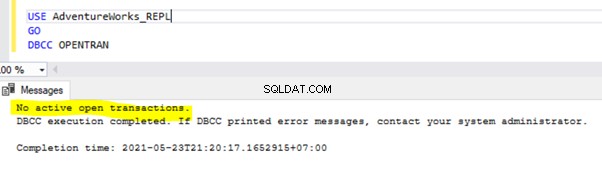
Om te controleren op langlopende actieve transacties in een database, opent u een nieuw queryvenster en maak verbinding met de respectieve database die we moeten controleren. Voer de DBCC OPENTRAN . uit console-opdracht – het is een Database Console-opdracht om de transacties te bekijken die op het moment van uitvoering in de database zijn geopend.
USE AdventureWorks
GO
DBCC OPENTRAN
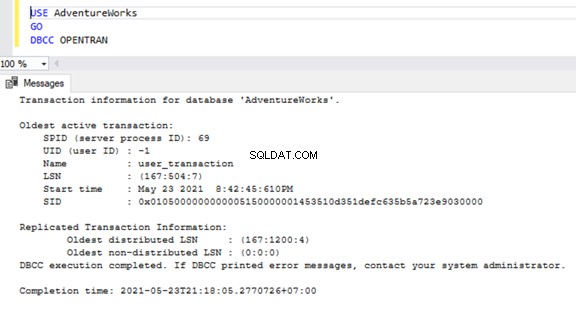
Nu weten we dat er een SPID . was (serverproces-ID ) 69 lange tijd loopt. Laten we nagaan welke opdracht op die transactie is uitgevoerd met behulp van de DBCC INPUTBUFFER console-opdracht (een Database Console-opdracht die wordt gebruikt om de opdracht of bewerking te identificeren die plaatsvindt op de geselecteerde Serverproces-ID).
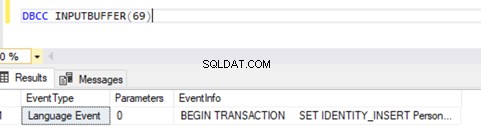
Voor de leesbaarheid kopieer ik de EventInfo veldwaarde en formatteren om de opdracht te tonen die we eerder hebben uitgevoerd.
Als er geen langlopende actieve transacties zijn in de geselecteerde database, krijgen we het onderstaande bericht:
Gelijk aan de DBCC OPENTRAN console-commando, kunnen we SELECT van DMV genaamd sys.dm_tran_database_transactions om meer gedetailleerde resultaten te krijgen (raadpleeg het MSDN-artikel voor meer gegevens).
Nu weten we hoe we de langlopende transactie kunnen identificeren. We kunnen de transactie vastleggen en zien hoe de INSERT-instructie wordt gerepliceerd.
Ga naar het venster waar we het record hebben ingevoegd in het Person.ContactType tabel binnen het Transactiebereik en voer COMMIT TRANSACTIE uit zoals hieronder weergegeven:
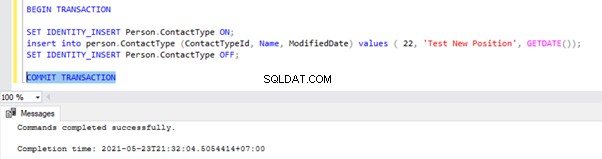
Uitvoering van COMMIT TRANSACTION heeft de record vastgelegd in de Publisher-database. Daarom zou het zichtbaar moeten zijn in de Distributiedatabase en de Abonneedatabase:
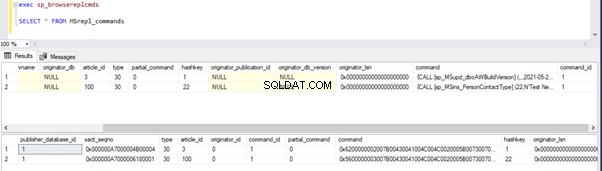
Als het je is opgevallen, zijn de oudere records uit de distributiedatabase opgeschoond door de taak Distributieagent opschonen. Het nieuwe record voor INSERT op Person.ContactType tabel was zichtbaar in de MSRepl_cmds tafel.
Uit onze tests hebben we de volgende dingen geleerd:
- De Log Reader Agent-taak van SQL Server Transactionele Replicatie scant alleen naar toegewezen records vanuit de Transactielogboeken van de Publisher-database en INSERT in de Abonnee-database.
- De volgorde van gewijzigde gegevens in de Publisher-database die naar de Abonnee wordt verzonden, is gebaseerd op de status Toegewijd en de tijd in de Publisher-database, ook al hebben de gerepliceerde gegevens dezelfde tijd als in de Publisher-database.
- Het identificeren van langlopende actieve transacties kan helpen bij het oplossen van de groei van transactielogboekbestanden van uitgever of distributeur of abonnee of welke database dan ook.
Bulk SQL INSERT/UPDATE/DELETE-bewerkingen op artikelen
Met enorme gegevens in de Publisher-database, eindigen we vaak met vereisten om enorme records in gerepliceerde tabellen INSERT of BIJWERKEN of VERWIJDEREN.
Als de INSERT-, UPDATE- of DELETE-bewerkingen worden uitgevoerd in een enkele transactie, zal deze zeker lang in de replicatie blijven steken.
Laten we zeggen dat we 10 miljoen records moeten INVOEGEN in een gerepliceerde tabel. Als u die records in één keer invoegt, ontstaan er prestatieproblemen.
INSERT INTO REplicated_table
SELECT * FROM Source_table
In plaats daarvan kunnen we records INVOEGEN in batches van 0,1 of 0,5 miljoen records in een WHILE lus of CURSOR-lus , en het zorgt voor een snellere replicatie. We ontvangen mogelijk geen grote problemen voor INSERT-instructies, tenzij de betreffende tabel anders veel indexen heeft. Dit zal echter een enorme prestatiehit hebben voor de UPDATE- of DELETE-instructies.
Stel dat we een nieuwe kolom hebben toegevoegd aan de tabel Gerepliceerd met ongeveer 10 miljoen records. We willen deze nieuwe kolom bijwerken met een standaardwaarde.
In het ideale geval werkt de onderstaande opdracht prima om alle 10 miljoen records met standaardwaarde als Abc te BIJWERKEN :
-- UPDATE 10 Million records on Replicated Table with some DEFAULT values
UPDATE Replicated_table
SET new_column = 'Abc'
Om effecten op replicatie te voorkomen, moeten we de bovenstaande UPDATE-bewerking echter uitvoeren in batches van 0,1 of 0,5 miljoen records om prestatieproblemen te voorkomen.
-- UPDATE in batches to avoid performance impacts on Replication
WHILE 1 = 1
BEGIN
UPDATE TOP(100000) Replicated_Table
SET new_Column = 'Abc'
WHERE new_column is NULL
IF @@ROWCOUNT = 0
BREAK
END
Evenzo, als we ongeveer 10 miljoen records uit een gerepliceerde tabel moeten VERWIJDEREN, kunnen we dit in batches doen:
-- DELETE 10 Million records on Replicated Table with some DEFAULT values
DELETE FROM Replicated_table
-- UPDATE in batches to avoid performance impacts on Replication
WHILE 1 = 1
BEGIN
DELETE TOP(100000) Replicated_Table
IF @@ROWCOUNT = 0
BREAK
END
Het efficiënt afhandelen van BULK INSERT, of UPDATE of DELETE kan de replicatieproblemen helpen oplossen.
Pro-tip :Als u enorme gegevens wilt INVOEGEN in een gerepliceerde tabel in de Publisher-database, gebruikt u de IMPORT/EXPORT-wizard in SSMS, omdat deze records in batches van 10000 of gebaseerd op de recordgrootte die sneller door SQL Server wordt berekend, zal invoegen.
Enorme gegevenswijzigingen binnen een enkele transactie
Om de gegevensintegriteit te behouden vanuit het perspectief van de applicatie of ontwikkeling, hebben veel applicaties expliciete transacties gedefinieerd voor kritieke operaties. Als er echter veel bewerkingen (INSERT, UPDATE of DELETE) worden uitgevoerd binnen één transactiebereik, wacht de Log Reader Agent eerst tot de transactie is voltooid, zoals we eerder hebben gezien.
Zodra de transactie door de toepassing is vastgelegd, moet de Log Reader Agent die enorme gegevenswijzigingen scannen die zijn uitgevoerd in de transactielogboeken van de Publisher-database. Tijdens die scan kunnen we de waarschuwingen of informatieve berichten in de Log Reader Agent zien, zoals
De Log Reader Agent scant het transactielogboek op opdrachten die moeten worden gerepliceerd. Ongeveer xxxxxx logrecords zijn gescand in pass # xxxx waarvan gemarkeerd voor replicatie, verstreken tijd xxxxxxxxx (ms)
Voordat we de oplossing voor dit scenario identificeren, moeten we begrijpen hoe de Log Reader Agent records scant uit de transactielogboeken en records invoegt in de distributiedatabase MSrepl_transactions en MSrepl_cmds tabellen.
SQL Server heeft intern een Log Sequence Number (LSN) in de transactielogboeken. De Log Reader Agent maakt gebruik van de LSN-waarden om de wijzigingen die zijn gemarkeerd voor SQL Server-replicatie in volgorde te scannen.
Log Reader Agent voert de sp_replcmds . uit uitgebreide opgeslagen procedure om de opdrachten die zijn gemarkeerd voor replicatie op te halen uit de transactielogboeken van de Publisher-database.
Sp_replcmds accepteert een invoerparameter met de naam @maxtrans om het maximale aantal transacties op te halen. De standaardwaarde zou 1 zijn, wat betekent dat het een willekeurig aantal beschikbare transacties uit logs zal scannen om naar de distributiedatabase te worden verzonden. Als er 10 INSERT-bewerkingen worden uitgevoerd via een enkele transactie en vastgelegd in de Publisher-database, kan een enkele batch 1 transactie met 10 opdrachten bevatten.
Als er veel transacties met minder commando's worden geïdentificeerd, zal de Log Reader Agent meerdere transacties combineren of de XACT volgnummer naar een enkele replicatiebatch. Maar het wordt opgeslagen als een andere XACT Volgorde nummer in de MSRepl_transactions tafel. Individuele opdrachten die bij die transactie horen, worden vastgelegd in de MSRepl_commands tafel.
Om de dingen die we hierboven hebben besproken te verifiëren, update ik de ModifiedDate kolom van de dbo.AWBuildVersion tabel naar de datum van vandaag en kijk wat er gebeurt:
UPDATE AdventureWorks.dbo.AWBuildVersion
SET ModifiedDate = GETDATE()
Voordat we de UPDATE uitvoeren, verifiëren we de records die aanwezig zijn in de MSrepl_commands en MSrepl_transactions tabellen:
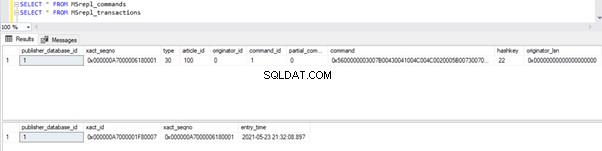
Voer nu het bovenstaande UPDATE-script uit en verifieer de records die aanwezig zijn in die 2 tabellen:
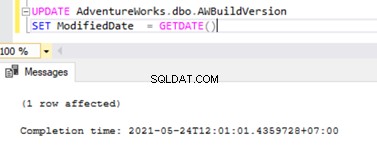
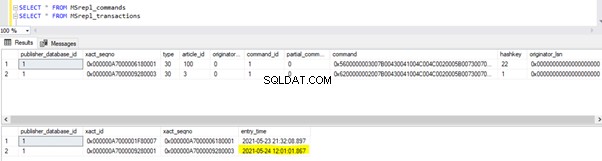
Er is een nieuw record met de UPDATE-tijd ingevoegd in de MSrepl_transactions tafel met de nabijgelegen entry_time . De opdracht controleren op deze xact_seqno toont de lijst met logisch gegroepeerde opdrachten met behulp van de sp_browsereplcmds procedure.

In de Replicatiemonitor kunnen we een enkele UPDATE-instructie zien die is vastgelegd onder 1 transactie(s) met 1 opdracht(en) van de uitgever naar de distributeur.
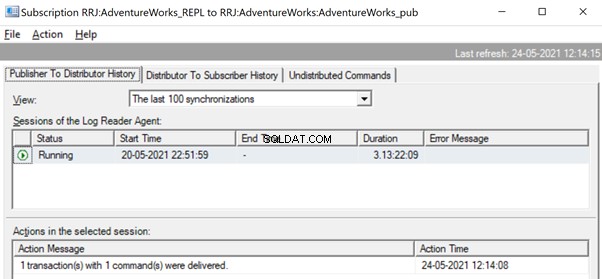
En we kunnen zien dat hetzelfde commando in een fractie van een seconde wordt afgeleverd van de distributeur naar de abonnee. Het geeft aan dat de replicatie correct verloopt.
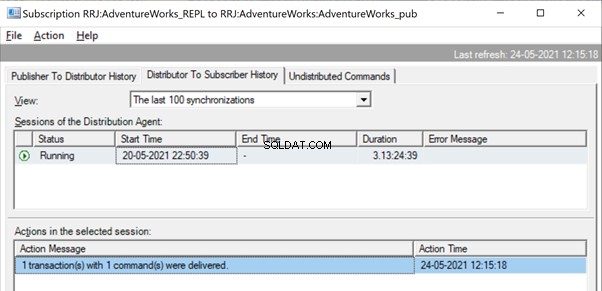
Als er nu een enorm aantal transacties is gecombineerd in één xact_seqno , kunnen we berichten zien zoals 10 transactie(s) met 5000 commando(s) werden afgeleverd .
Laten we dit controleren door UPDATE op 2 verschillende tafels tegelijk uit te voeren:
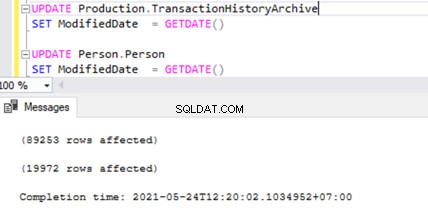
We kunnen twee transactierecords zien in de MSrepl_transactions tabel die overeenkomt met de twee UPDATE-bewerkingen en vervolgens de nr. van records in die tabel die overeenkomen met de nr. van records bijgewerkt.
Het resultaat van deMSrepl_transactions tafel:
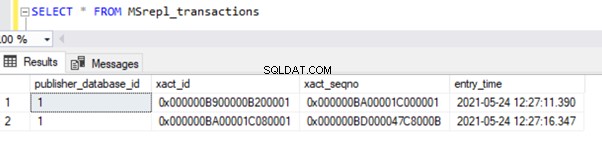
Het resultaat van de MSrepl_commands tafel:
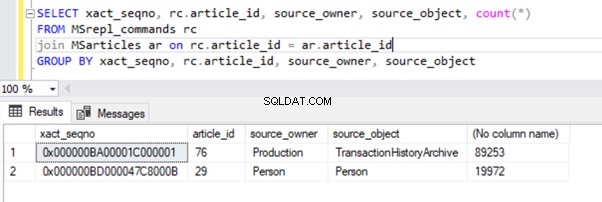
We hebben echter gemerkt dat deze 2 transacties logisch worden gegroepeerd door de Log Reader Agent en in een enkele batch worden gecombineerd als 2 transacties met 109225-opdrachten.
Maar daarvoor kunnen we berichten zien zoals Gerepliceerde transacties leveren, xact count:1, command count 46601 .
Dit gebeurt totdat de Log Reader Agent de volledige reeks wijzigingen scant en identificeert dat 2 UPDATE-transacties volledig uit de transactielogboeken zijn gelezen.
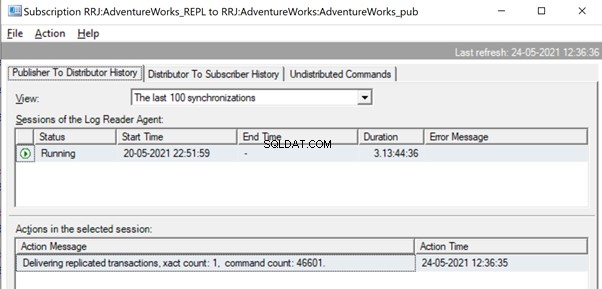
Zodra de opdrachten volledig uit de transactielogboeken zijn gelezen, zien we dat 2 transacties met 109225-opdrachten zijn afgeleverd door de Log Reader-agent:
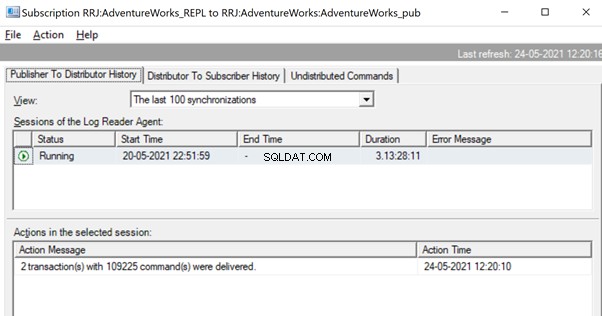
Aangezien de distributieagent wacht tot een enorme transactie wordt gerepliceerd, zien we mogelijk een bericht als Gerepliceerde transacties leveren wat aangeeft dat er een enorme transactie werd gerepliceerd en dat we moeten wachten tot deze volledig is gerepliceerd.
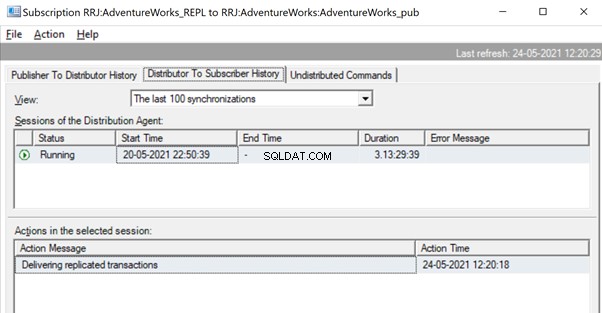
Eenmaal gerepliceerd, kunnen we het onderstaande bericht ook in de distributieagent zien:
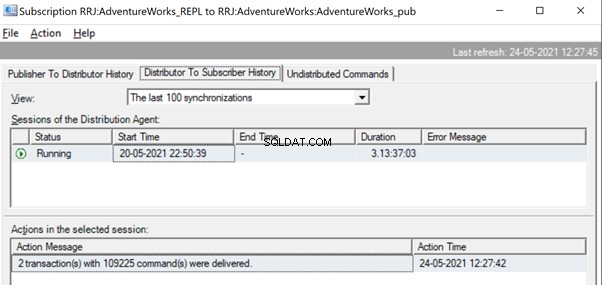
Er zijn verschillende manieren om deze problemen op te lossen.
Manier 1:CREER Nieuwe SQL Stored Procedure
U moet een nieuwe opgeslagen procedure maken en de toepassingslogica erin inkapselen onder het bereik van Transactie.
Nadat het is gemaakt, voegt u dat Stored Procedure-artikel toe aan Replication en wijzigt u de artikeleigenschap Replicate naar Execution of the Stored Procedure optie.
Het zal helpen om het artikel over de opgeslagen procedure op de abonnee uit te voeren in plaats van alle individuele gegevenswijzigingen die plaatsvonden te repliceren.
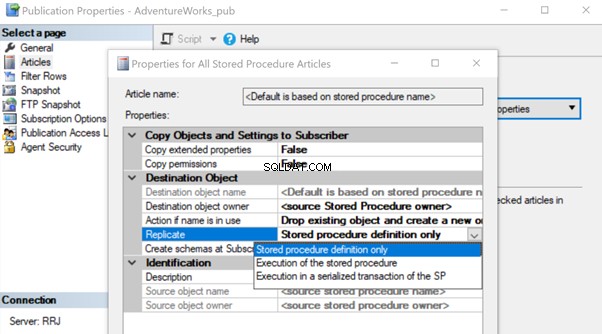
Laten we eens kijken hoe de uitvoering van de opgeslagen procedure optie voor Repliceren vermindert de belasting op Replicatie. Om dat te doen, kunnen we een opgeslagen testprocedure maken, zoals hieronder weergegeven:
CREATE procedure test_proc
AS
BEGIN
UPDATE AdventureWorks.dbo.AWBuildVersion
SET ModifiedDate = GETDATE()
UPDATE TOP(10) Production.TransactionHistoryArchive
SET ModifiedDate = GETDATE()
UPDATE TOP(10) Person.Person
SET ModifiedDate = GETDATE()
END
De bovenstaande procedure zal een enkele record BIJWERKEN op de AWBuildVersion tabel en 10 records elk op de Production.TransactionHistoryArchive en Persoon.Persoon tabellen met in totaal 21 recordwijzigingen.
Nadat u deze nieuwe procedure voor zowel de uitgever als de abonnee hebt gemaakt, voegt u deze toe aan replicatie. Klik daarvoor met de rechtermuisknop op Publicatie en kies het procedure-artikel voor Replicatie met de standaard Alleen opgeslagen procedure-definitie optie.
Als we klaar zijn, kunnen we de records verifiëren die beschikbaar zijn in de MSrepl_transactions en MSrepl_commands tabellen.
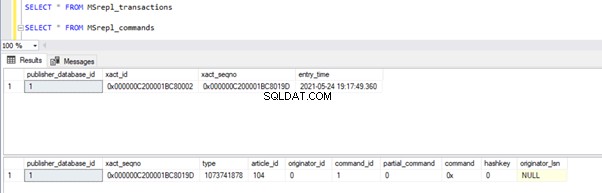
Laten we nu de procedure in de Publisher-database uitvoeren om te zien hoeveel records zijn getraceerd.
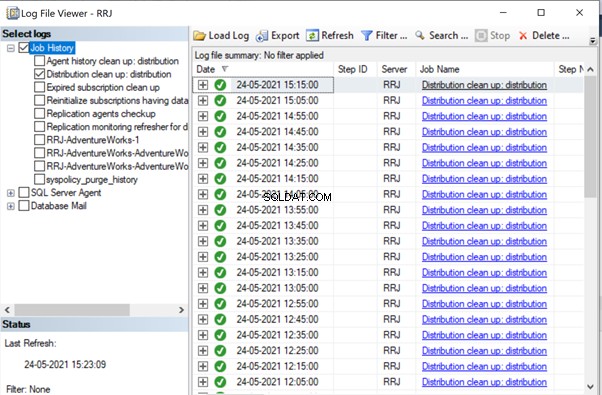
We kunnen het volgende zien in de distributietabellen MSrepl_transactions en MSrepl_commands :
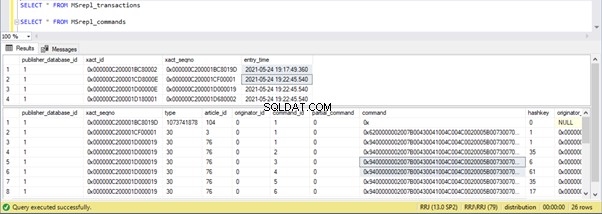
Drie xact_seqno zijn gemaakt voor drie UPDATE-bewerkingen in de MSrepl_transactions tabel, en 21 opdrachten zijn ingevoegd in de MSrepl_commands tafel.
Open Replication Monitor en kijk of ze worden verzonden als 3 verschillende Replicatiebatches of als een enkele batch met 3 transacties samen.
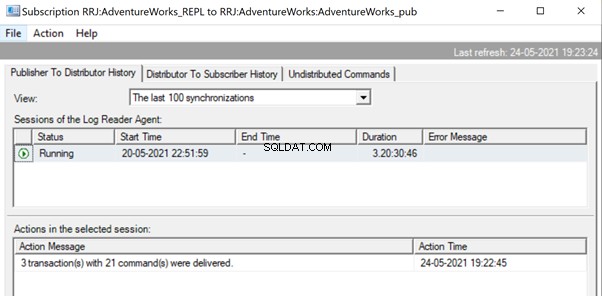
We kunnen zien dat drie xact_seqno werd geconsolideerd als een enkele replicatiebatch. We kunnen dus zien dat 3 transacties met 21 opdrachten succesvol zijn afgeleverd.
Laten we de procedure verwijderen uit Replicatie en deze weer toevoegen met de tweede Uitvoering van de opgeslagen procedure optie. Voer nu de procedure uit en kijk hoe de records worden gerepliceerd.
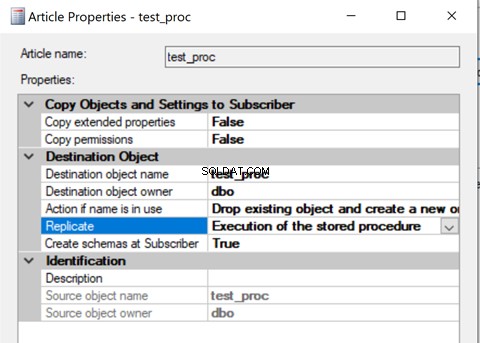
Het controleren van records uit Distributietabellen toont de onderstaande details:
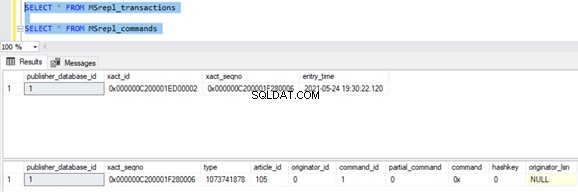
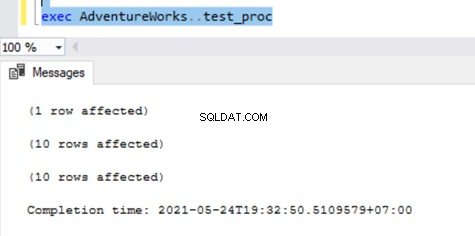
Voer nu de procedure uit op de Publisher-database en kijk hoeveel records worden geregistreerd in Distributietabellen. Uitvoering van een procedure heeft 21 records bijgewerkt (1 record, 10 records en 10 records) zoals eerder.
Verifiëren van distributietabellen toont de onderstaande gegevens:
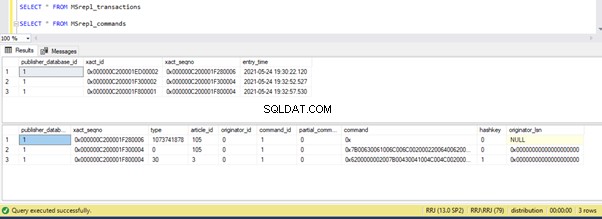
Laten we snel naar sp_browsereplcmds kijken om de daadwerkelijk ontvangen opdracht te zien:

Het commando is “{call “dbo”.”test_proc” }” die wordt uitgevoerd in de abonneedatabase.
In de Replicatiemonitor kunnen we zien dat er slechts 1 transactie(s) met 1 opdracht(en) is afgeleverd via Replicatie:
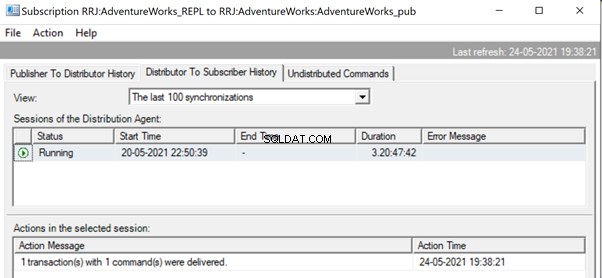
In onze testcase hebben we een procedure gebruikt met slechts 21 gegevenswijzigingen. Als we dat echter doen voor een gecompliceerde procedure met miljoenen wijzigingen, dan is de Stored Procedure-aanpak met de Uitvoering van de Stored Procedure optie zal efficiënt zijn in het verminderen van de replicatiebelasting.
We moeten deze aanpak valideren door te controleren of de procedure de logica heeft om alleen dezelfde set records in de Publisher- en Subscriber-databases bij te werken. Anders leidt dit tot inconsistentie in de gegevens tussen de uitgever en de abonnee.
Manier 2:MaxCmdsInTran, ReadBatchSize en ReadBatchThreshold Log Reader Agent-parameters configureren
MaxCmdsInTran – geeft het maximale aantal opdrachten aan dat logisch kan worden gegroepeerd binnen een transactie tijdens het lezen van gegevens uit de transactielogboeken van de Publisher-database en geschreven naar de distributiedatabase.
In onze eerdere tests merkten we dat ongeveer 109225 opdrachten werden verzameld in een enkele exacte replicatiereeks, wat resulteerde in een lichte traagheid of latentie. Als we de MaxCmdsInTran parameter tot 10000, de enkele xact-reeks nummer wordt opgesplitst in 11 xact-reeksen resulterend in snellere levering van opdrachten van uitgever naar distributeur . Hoewel deze optie helpt om de twist van de distributiedatabase te verminderen en de gegevens sneller te repliceren van de uitgever naar de abonneedatabase, moet u voorzichtig zijn bij het gebruik van deze optie. Het kan zijn dat het de gegevens aan de abonneedatabase levert en deze opent vanuit de databasetabellen van de abonnee vóór het einde van de oorspronkelijke transactieomvang.
ReadBatchSize – Deze parameter is mogelijk niet handig voor een enkel groot transactiescenario. Het helpt echter als er heel veel kleinere transacties plaatsvinden in de Publisher-database.
Als het aantal opdrachten per transactie kleiner is, zal de Log Reader Agent meerdere wijzigingen combineren tot een enkel transactiebereik van de Replicatieopdracht. De Read Batch-grootte geeft aan hoeveel Transacties in het Transactielogboek kunnen worden gelezen voordat wijzigingen naar de Distributiedatabase worden verzonden. De waarden kunnen tussen 500 en 10000 liggen.
ReadBatchThreshold – geeft het aantal opdrachten aan dat moet worden gelezen uit het transactielogboek van de Publisher-database voordat het naar de abonnee wordt verzonden met een standaardwaarde van 0 om het volledige logbestand te scannen. We kunnen deze waarde echter verlagen om gegevens sneller te verzenden door deze te beperken tot 10000 of 100000 dergelijke opdrachten.
Manier 3:De beste waarden configureren voor SubscriptionStreams-parameter
AbonnementStreams – geeft het aantal verbindingen aan dat een distributieagent parallel kan uitvoeren om gegevens op te halen uit de distributiedatabase en deze door te geven aan de abonneedatabase. De standaardwaarde is 1, wat suggereert dat er slechts één stream of verbinding is van de distributie naar de abonneedatabase. Waarden kunnen variëren van 1 tot 64. Als er meer abonnementsstromen worden toegevoegd, kan dit leiden tot CXPACKET-congestie (met andere woorden, parallellisme). Wees dus voorzichtig bij het configureren van deze optie in Productie.
Om samen te vatten, probeer enorme INSERT, UPDATE of DELETE in een enkele transactie te vermijden. Als het onmogelijk is om deze bewerkingen te elimineren, is het de beste optie om de bovenstaande manieren te testen en degene te kiezen die het beste bij uw specifieke omstandigheden past.
Blokkeringen in distributiedatabase
De distributiedatabase is het hart van de transactiereplicatie van SQL Server en als deze niet goed wordt onderhouden, zullen er veel prestatieproblemen zijn.
Om alle aanbevolen werkwijzen voor de configuratie van de distributiedatabase samen te vatten, moeten we ervoor zorgen dat de onderstaande configuraties correct worden uitgevoerd:
- Gegevensbestanden van de distributiedatabases moeten op hoge IOPS-schijven worden geplaatst. Als de Publisher-database veel gegevenswijzigingen zal hebben, moeten we ervoor zorgen dat de distributiedatabase op een schijf met hoge IOPS wordt geplaatst. Het ontvangt continu gegevens van de Log Reader-agent en verzendt gegevens naar de abonneedatabase via de distributieagent. Alle gerepliceerde gegevens worden elke 10 minuten verwijderd uit de distributiedatabase via de taak Distributie opschonen.
- Configureer de eigenschappen Initiële bestandsgrootte en Autogrowth van de distributiedatabase met de aanbevolen waarden op basis van de activiteitsniveaus van de Publisher-database. Anders leidt dit tot fragmentatie van gegevens en logbestanden, waardoor prestatieproblemen ontstaan.
- Distributiedatabases opnemen in de reguliere indexonderhoudstaken die zijn geconfigureerd op de servers waarop de distributiedatabase zich bevindt.
- Neem distributiedatabases op in het schema voor volledige back-uptaken om eventuele specifieke problemen op te lossen.
- Zorg ervoor dat de Distributie opschonen:distributie taak wordt elke 10 minuten uitgevoerd volgens het standaardschema. Anders blijft de omvang van de distributiedatabase toenemen en leidt dit tot prestatieproblemen.
Zoals we tot nu toe hebben opgemerkt, zijn de belangrijkste tabellen in de distributiedatabase MSrepl_transactions en MSrepl_commands . De records worden daar ingevoegd door de taak Logboeklezer-agent, geselecteerd door de taak Distributieagent, toegepast op de abonneedatabase en vervolgens verwijderd of opgeschoond door de taak Distributieopschoningsagent.
Als de distributiedatabase niet correct is geconfigureerd, kunnen we sessieblokkeringen tegenkomen in deze 2 tabellen, wat zal resulteren in prestatieproblemen met SQL Server-replicatie.
We kunnen de onderstaande query uitvoeren in elke database om de blokkeringssessies te bekijken die beschikbaar zijn in het huidige exemplaar van SQL Server:
SELECT *
FROM sys.sysprocesses
where blocked > 0
order by waittime desc
Als de bovenstaande query resultaten oplevert, kunnen we opdrachten op die geblokkeerde sessies identificeren door de DBCC INPUTBUFFER(spid) uit te voeren console-commando en onderneem acties dienovereenkomstig.
Corruptiegerelateerde problemen
Een SQL Server-database gebruikt zijn algoritme of logica om gegevens op te slaan in tabellen en deze in begrenzingen of pagina's te bewaren. Databasecorruptie is een proces waarbij de fysieke toestand van de databasegerelateerde bestanden/omvang/pagina's verandert van normaal naar onstabiel of niet-ophaalbaar, waardoor het ophalen van gegevens moeilijker of onmogelijk wordt.
Alle SQL Server-databases zijn gevoelig voor databasecorrupties. De oorzaken kunnen zijn:
- Hardwarestoringen zoals schijf-, opslag- of controllerproblemen;
- Server OS-storingen zoals patchproblemen;
- Stroomstoringen resulterend in een abrupte afsluiting van servers of onjuiste afsluiting van de database.
Als we databases kunnen herstellen of repareren zonder enig gegevensverlies, heeft dit geen invloed op de SQL Server-replicatie. Als er echter gegevens verloren gaan tijdens het herstellen of repareren van corrupte databases, zullen we veel problemen met gegevensintegriteit krijgen die we in ons eerdere artikel hebben besproken.
Corrupties kunnen optreden op verschillende onderdelen, zoals:
- Beschadigingen van uitgeversgegevens/logbestand
- Beschadigingen van abonneegegevens/logbestand
- Beschadigingen van distributiedatabasegegevens/logbestanden
- Msdb-databasegegevens/logbestanden beschadigd
Als we veel problemen met de gegevensintegriteit krijgen na het oplossen van corruptieproblemen, wordt aanbevolen om de replicatie volledig te verwijderen, alle corruptieproblemen in de uitgevers-, abonnee- of distributeurdatabase op te lossen en vervolgens de replicatie opnieuw te configureren om het probleem op te lossen. Otherwise, data integrity issues will persist and lead to data inconsistency across the Publisher and Subscriber. The time required to fix the Data integrity issues in case of Corrupted databases will be much more compared to configuring Replication from scratch. Hence identify the level of Corruption encountered and take optimal decisions to resolve the Replication issues faster.
Wondering why msdb database corruption can harm Replication? Since msdb database hold all details related to SQL Server Agent Jobs including Replication Agent jobs, any corruption on msdb database will harm Replication. To recover quickly from msdb database corruptions, it is recommended to restore msdb database from the last Full Backup of msdb database. This also signifies the importance of taking Full Backups of all system databases including msdb database.
Conclusie
Thanks for successfully going through the final power-packed article about the Performance issues in the SQL Server Transactional Replication. If you have gone through all articles carefully, you should be able to troubleshoot almost any Transactional Replication-based issues and fix them out efficiently.
If you need any further guidance or have any Transactional Replication-related issues in your environment, you can reach out to me for consultation. And if I missed anything essential in this article, you are welcome to point to that in the Comments section.