Transactiereplicatie van SQL Server is een van de meest voorkomende replicatietechnieken die wordt gebruikt om gegevens over meerdere bestemmingen te kopiëren of te distribueren.
In de vorige artikelen hebben we SQL Server-replicatie besproken, hoe het intern werkt en hoe replicatie kan worden geconfigureerd via de replicatiewizard of T-SQL-aanpak. Nu concentreren we ons op problemen met SQL-replicatie en het correct oplossen ervan.
SQL-replicatieproblemen
De meeste klanten die SQL Server Transactional Replication gebruiken, richten zich voornamelijk op het verkrijgen van bijna realtime gegevens die beschikbaar zijn in de abonneedatabase-instanties. Daarom moet de DBA die de replicatie beheert, op de hoogte zijn van verschillende mogelijke problemen met betrekking tot SQL-replicatie die zich kunnen voordoen. Ook moet de DBA deze problemen binnen korte tijd kunnen oplossen.
We kunnen alle problemen met SQL-replicatie in de onderstaande categorieën indelen (op basis van mijn ervaring):
Configuratieproblemen
- Maximale tekstreplicatiegrootte
- SQL Server Agent Service is niet ingesteld om de automatische modus te starten
- Niet-gecontroleerde replicatie-instanties krijgen een niet-geïnitialiseerde abonnementsstatus
- Bekende problemen binnen SQL Server
Toestemmingsproblemen
- SQL Server Agent-taaktoestemmingsproblemen
- Snapshot Agent-taakreferentie heeft geen toegang tot het pad van de Snapshot-map
- Log Reader Agent-taakreferentie kan geen verbinding maken met Publisher/distributiedatabase
- Functiegegevens van distributieagent kunnen geen verbinding maken met de distributie-/abonneedatabase
Connectiviteitsproblemen
- Uitgeversserver is niet gevonden of was niet toegankelijk
- Distributieserver niet gevonden of niet toegankelijk
- De abonneeserver is niet gevonden of was niet toegankelijk
Kwesties met betrekking tot gegevensintegriteit
- Fouten bij schending van primaire sleutel of unieke sleutel
- Rij niet gevonden fouten
- Fouten met buitenlandse sleutel of andere beperkingsschendingen
Prestatieproblemen
- Langlopende actieve transacties in uitgeversdatabase
- Bulk INSERT/UPDATE/DELETE bewerkingen op artikelen
- Enorme gegevenswijzigingen binnen een enkele transactie
- Blokkeringen in de distributiedatabase
Corruptiegerelateerde problemen
- Beschadigingen in de uitgeversdatabase
- Beschadigingen in het transactielogboek van uitgever
- Beschadigingen in de distributiedatabase
- Beschadigingen in de database van abonnees
DEMO-omgeving voorbereiding
Voordat we ingaan op details over de SQL-replicatieproblemen, moeten we onze omgeving voorbereiden op de demo. Zoals besproken in mijn vorige artikelen, zijn alle gegevenswijzigingen die plaatsvinden in de abonneedatabase in Transactionele replicatie niet rechtstreeks zichtbaar voor de uitgeversdatabase. Daarom gaan we bepaalde wijzigingen rechtstreeks in de abonneedatabase aanbrengen voor leerdoeleinden.
Wees uiterst voorzichtig en wijzig niets in de productiedatabases. Het heeft invloed op de gegevensintegriteit van de abonneedatabases. Ik neem de back-upscripts voor elke uitgevoerde wijziging en zal die scripts gebruiken om de SQL-replicatieproblemen op te lossen.
Wijziging 1 – Records invoegen in de Person.ContactType-tabel
Voordat u records invoegt in het Person.ContacType tabel, laten we eens kijken naar die tabelstructuur, een paar standaardbeperkingen en uitgebreide eigenschappen die in het onderstaande script zijn geredigeerd:
CREATE TABLE [Person].[ContactType](
[ContactTypeID] [int] IDENTITY(1,1) NOT FOR REPLICATION NOT NULL,
[Name] [dbo].[Name] NOT NULL,
[ModifiedDate] [datetime] NOT NULL,
CONSTRAINT [PK_ContactType_ContactTypeID] PRIMARY KEY CLUSTERED
(
[ContactTypeID] ASC
) ON [PRIMARY]
) ON [PRIMARY]
GO
Ik heb deze tabel gekozen omdat deze minder kolommen heeft. Het is handiger voor testdoeleinden. Laten we nu eens kijken wat we hebben over de structuur:
- ContactTypeId wordt gedefinieerd als een IDENTITEITSKOLOM – het genereert automatisch de primaire sleutelwaarden en NIET VOOR REPLICATIE.
- NIET VOOR REPLICATIE is een speciale eigenschap die kan worden gebruikt voor verschillende objecttypen, zoals tabellen, beperkingen zoals beperkingen voor externe sleutels, controlebeperkingen, triggers en identiteitskolommen op uitgever of abonnee, terwijl alleen een van de replicatiemethoden wordt gebruikt. Hiermee kan de DBA Replicatie plannen of implementeren om ervoor te zorgen dat bepaalde functionaliteiten zich anders gedragen in Publisher/Abonnee tijdens het gebruik van Replicatie.
- In ons geval geven we SQL Server de opdracht om de IDENTITY-waarden te gebruiken die alleen in de Publisher-database zijn gegenereerd. De eigenschap IDENTITY mag niet worden gebruikt voor het Person.ContactType tabel in de abonneedatabase. Op dezelfde manier kunnen we de beperkingen of triggers wijzigen zodat ze zich anders gedragen terwijl replicatie met deze optie is geconfigureerd.
- 2 andere NOT NULL-kolommen zijn beschikbaar in de tabel.
- De tabel heeft een primaire sleutel gedefinieerd op ContactTypeId . Ter herinnering:de primaire sleutel is een verplichte vereiste voor replicatie. Zonder het op een tafel zouden we geen tafelartikel kunnen repliceren.
Laten we nu een voorbeeldrecord INVOEGEN aan Persoon .Contacttype tabel in de AdventureWorks_REPL databank:
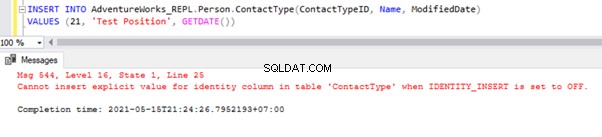
De directe INSERT op de tabel zal mislukken in de abonneedatabase omdat de identiteitseigenschap alleen is uitgeschakeld voor replicatie door de NIET VOOR REPLICATIE optie. Telkens wanneer we de INSERT-bewerking handmatig uitvoeren, moeten we nog steeds de SET IDENTITY_INSERT-optie als volgt gebruiken:
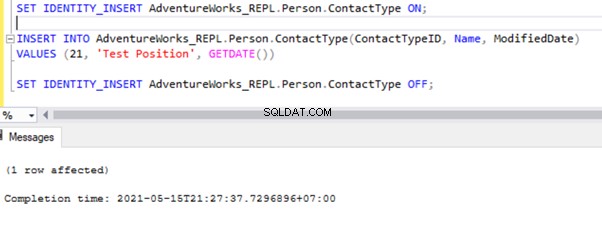
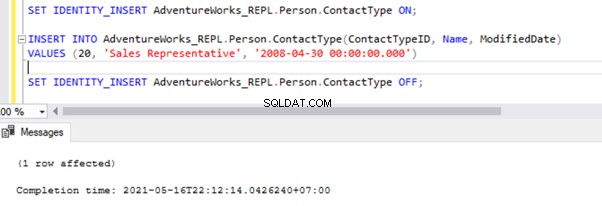
SET IDENTITY_INSERT AdventureWorks_REPL.Person.ContactType ON;
INSERT INTO AdventureWorks_REPL.Person.ContactType(ContactTypeID, Name, ModifiedDate)
VALUES (21, 'Test Position', GETDATE())
SET IDENTITY_INSERT AdventureWorks_REPL.Person.ContactType OFF;
Nadat we de optie SET IDENTITY_INSERT hebben toegevoegd, kunnen we de record met succes INSERT in het Person.ContactType tafel.
Het uitvoeren van de SELECT op de tafel toont het nieuw ingevoegde record:
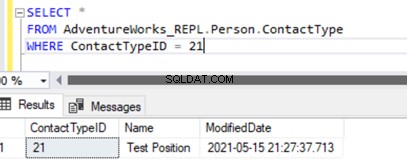
We hebben alleen een nieuw record toegevoegd aan de abonneedatabase die niet beschikbaar is in de uitgeversdatabase op het Person.ContactType tafel.
Het uitvoeren van een SELECT op dezelfde tabel van de Publisher-database toont geen records. Wijzigingen in de abonneedatabase worden dus niet gerepliceerd naar de uitgeversdatabase.
Wijzigen 2 – Verwijderen van 2 records uit de Person.ContactType-tabel
We houden vast aan ons vertrouwde Person.ContactType tafel. Voordat we records uit de abonneedatabase verwijderen, moeten we controleren of deze records bestaan voor zowel de uitgever als de abonnee. Zie hieronder:
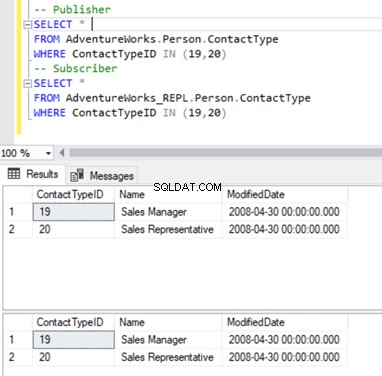
Nu kunnen we deze 2 ContactTypeId verwijderen met behulp van de volgende verklaring:
DELETE FROM AdventureWorks_REPL.Person.ContactType
WHERE ContactTypeID IN (19,20)
Met het bovenstaande script kunnen we 2 records verwijderen uit het Person.ContactType tabel in de abonneedatabase:
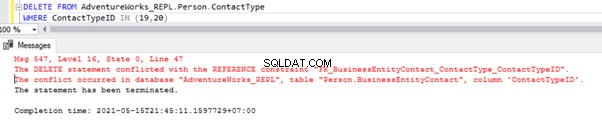
We hebben de referentie voor de externe sleutel die voorkomt dat deze 2 records worden verwijderd uit het Person.ContactType tafel. We kunnen dit scenario afhandelen door de Foreign key-beperking tijdelijk uit te schakelen op de onderliggende tabel. Het script staat hieronder:
ALTER TABLE [Person].[BusinessEntityContact] NOCHECK CONSTRAINT [FK_BusinessEntityContact_ContactType_ContactTypeID];
Zodra de Foreign-sleutels zijn uitgeschakeld, kunnen we records met succes verwijderen uit het Person.ContactType tafel:
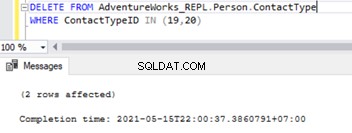
Dit heeft ook de referentiële beperking van de referentiële sleutel in de 2 tabellen gewijzigd. We kunnen proberen SQL-replicatieproblemen te simuleren op basis van dit scenario.
In ons huidige scenario weten we dat het Person.ContactType tabel had geen gesynchroniseerde gegevens tussen de uitgever en de abonnee.
Geloof me, in weinig productieomgevingen doen ontwikkelaars of DBA's wat gegevensreparaties in de abonneedatabase. zoals alle wijzigingen die we eerder hebben uitgevoerd, veroorzaakten de problemen met de gegevensintegriteit in de Publisher- en de Subscriber-databases in dezelfde tabel. Als DBA heb ik een eenvoudiger mechanisme nodig om dit soort discrepanties te verifiëren. Anders zou het het leven van de DBA zielig maken.
Hier komt de oplossing van Microsoft waarmee we de gegevensverschillen tussen tabellen in de uitgever en de abonnee kunnen verifiëren. Ja, je raadt het goed. Het is het hulpprogramma TableDiff dat we in eerdere artikelen hebben besproken.
TableDiff-hulpprogramma
Het hulpprogramma TableDiff wordt voornamelijk gebruikt in replicatieomgevingen. We kunnen het ook gebruiken voor andere gevallen waarin we 2 SQL Server-tabellen moeten vergelijken voor niet-convergentie. We kunnen ze vergelijken en de verschillen tussen deze 2 tabellen identificeren. Dan helpt het hulpprogramma bij het synchroniseren van de Bestemming tafel naar de Bron tafel door de nodige INSERT/UPDATE/DELETE-scripts te genereren.
TableDiff is een op zichzelf staand programma tablediff.exe dat standaard wordt geïnstalleerd in C:\Program Files\Microsoft SQL Server\130\COM zodra we de replicatiecomponenten hebben geïnstalleerd. Houd er rekening mee dat het standaardpad kan variëren afhankelijk van de SQL Server-installatieparameters. Het getal 130 in het pad geeft de SQL Server-versie aan (SQL Server 2016). Daarom zal het variëren voor elke verschillende versie van de SQL Server-installatie.
U hebt alleen toegang tot het TableDiff-hulpprogramma via de opdrachtprompt of vanuit batchbestanden. Het hulpprogramma heeft geen fancy Wizard of GUI om te gebruiken. De gedetailleerde syntaxis van het hulpprogramma TableDiff staat in het MSDN-artikel. Ons huidige artikel richt zich alleen op enkele noodzakelijke opties.
Om 2 tabellen te vergelijken met behulp van het hulpprogramma TableDiff, moeten we verplichte details opgeven voor de bron- en bestemmingstabellen, zoals de naam van de bronserver, de naam van de brondatabase, de naam van het bronschema, de naam van de brontabel, de naam van de bestemmingsserver, de naam van de bestemmingsdatabase, de bestemming Schemanaam en naam van de bestemmingstabel.
Laten we proberen TableDiff te testen met het Person.ContactType tabel met verschillen tussen de uitgever en de abonnee.
Open de opdrachtprompt en navigeer naar het TableDiff-hulpprogrammapad (als dat pad niet is toegevoegd aan de omgevingsvariabelen).
Om de lijst met alle beschikbare parameters te bekijken, typt u de opdracht "tablediff-?" om alle beschikbare opties en parameters op te sommen. De resultaten staan hieronder:
Laten we de Persoon controleren.ContactType tabel in onze databases voor uitgevers en abonnees door de onderstaande opdracht uit te voeren:
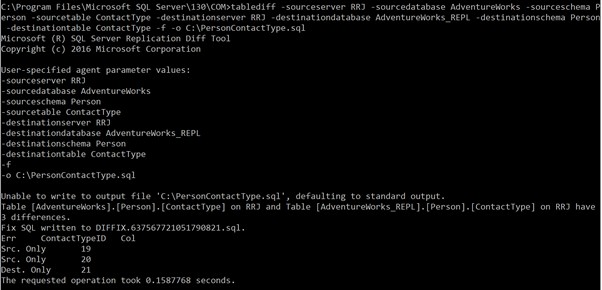
tablediff -sourceserver RRJ -sourcedatabase AdventureWorks -sourceschema Person -sourcetable ContactType -destinationserver RRJ -destinationdatabase AdventureWorks_REPL -destinationschema Person -destinationtable ContactTypeMerk op dat ik de brongebruiker niet heb opgegeven , bronwachtwoord , bestemmingsgebruiker , en bestemmingswachtwoord omdat mijn Windows-login toegang heeft tot de tabellen. Als u SQL-referenties wilt gebruiken in plaats van Windows-verificatie, de bovenstaande parameters zijn verplicht om toegang te krijgen tot de tabellen voor vergelijking . Anders krijg je fouten.
De resultaten van de juiste uitvoering van de opdracht:
Het laat zien dat we 3 discrepanties hebben. Een daarvan is een nieuw record in de Bestemmingsdatabase en twee records zijn niet beschikbaar in de Bestemmingsdatabase.
Laten we nu eens kijken naar de Diversen beschikbare opties voor het hulpprogramma TableDiff.
- -et - logt de resultatensamenvatting in de bestemmingstabel
- -dt - laat de resultaatbestemmingstabel vallen als deze al bestaat
- -f – genereert een T-SQL DML-script met INSERT/UPDATE/DELETE-instructies om de Destination-tabel te laten convergeren met de Source-tabel.
- -o – uitvoer bestandsnaam indien optie -f wordt gebruikt om het convergentiebestand te genereren.
We maken een convergentiebestand met de -f en -o opties voor onze eerdere opdracht:
tablediff -sourceserver RRJ -sourcedatabase AdventureWorks -sourceschema Person -sourcetable ContactType -destinationserver RRJ -destinationdatabase AdventureWorks_REPL -destinationschema Person -destinationtable ContactType -f -o C:\PersonContactType.sqlHet convergentiebestand is succesvol aangemaakt:
Zoals u kunt zien, is het maken van een nieuw bestand in de hoofdmap van de C:-schijf om veiligheidsredenen niet toegestaan. Daarom wordt een foutmelding weergegeven en wordt het uitvoerbestand DIFFIX.*.sql-bestand gemaakt in de TableDiff-hulpprogrammamap. Wanneer we dat bestand openen, kunnen we de onderstaande details zien:

De INSERT-scripts zijn gemaakt voor de 2 verwijderde records en de DELETE-scripts zijn gemaakt voor de records die nieuw zijn ingevoegd in de abonneedatabase. De tool geeft ook om het gebruik van de IDENTITY_INSERT-opties zoals vereist voor de Bestemming tafel. Daarom zal deze tool van groot nut zijn wanneer een DBA twee tabellen moet synchroniseren.
In ons geval zal ik de scripts niet uitvoeren, omdat we deze varianties nodig hebben om onze SQL-replicatieproblemen te simuleren.
Voordelen van TableDiff Utility
- TableDiff is een gratis hulpprogramma dat wordt geleverd als onderdeel van de installatie van SQL Server Replication-componenten om te worden gebruikt voor tabelvergelijking of convergentie.
- De scripts voor het maken van convergentie kunnen worden gemaakt zonder handmatige tussenkomst.
Beperkingen van TableDiff Utility
- Het hulpprogramma TableDiff kan alleen worden uitgevoerd vanaf de opdrachtprompt of het batchbestand.
- Vanaf de opdrachtprompt kun je slechts één tabelvergelijking tegelijk uitvoeren, tenzij je meerdere opdrachtprompts parallel hebt geopend om meerdere tabellen te vergelijken.
- Voor de brontabel die u met het hulpprogramma TableDiff moet vergelijken, is een primaire sleutel of een identiteitskolom vereist, of de ROWGUID-kolom die beschikbaar is om de rij-voor-rij vergelijking uit te voeren. Als de -strikte optie wordt gebruikt, vereist de Bestemmingstabel ook een Primaire sleutel, of een Identiteitskolom, of de ROWGUID-kolom die beschikbaar is.
- Als de bron- of doeltabel de sql_variant bevat datatype-kolom, kunt u het hulpprogramma TableDiff niet gebruiken om het te vergelijken.
- Prestatieproblemen kunnen worden opgemerkt tijdens het uitvoeren van het hulpprogramma TableDiff op tabellen met enorme records, omdat het de rij-voor-rij vergelijking op deze tabellen uitvoert.
- Convergentiescripts die door het hulpprogramma TableDiff zijn gemaakt, bevatten geen kolommen met BLOB-tekengegevenstypes, zoals varchar(max) , nvarchar(max) , varbinair(max) , tekst , ntekst , of afbeelding kolommen, en xml of tijdstempel kolommen. Daarom hebt u alternatieve benaderingen nodig om de tabellen met deze gegevenstypekolommen te behandelen.
Maar zelfs met deze beperkingen kan het hulpprogramma TableDiff in elke SQL Server-tabel worden gebruikt voor snelle gegevensverificatie of convergentiecontrole. U kunt echter ook een goede tool van derden aanschaffen.
Laten we nu de verschillende SQL-replicatieproblemen in detail bekijken.
Configuratieproblemen
Vanuit mijn ervaring heb ik de vaak gemiste replicatieconfiguratie-opties gecategoriseerd die kunnen leiden tot kritieke SQL-replicatieproblemen als Configuratie problemen. Sommige staan hieronder.
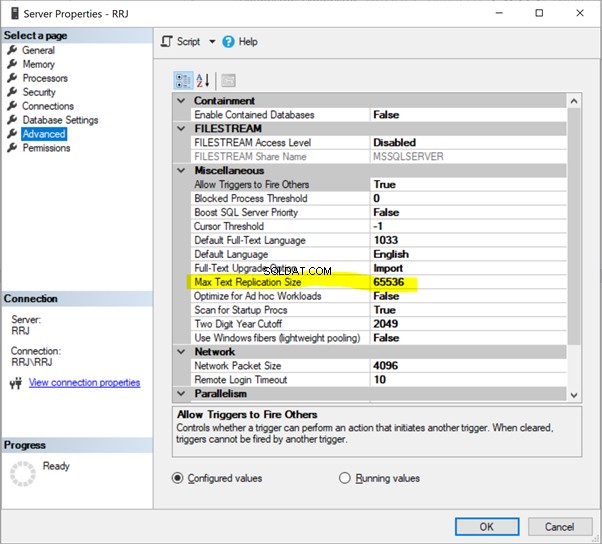
Maximale tekstreplicatiegrootte
Maximale tekstvervangingsgrootte verwijst naar de Maximale tekstreplicatiegrootte in bytes . Het is van toepassing op alle datatypes zoals char(max), nvarchar(max), varbinary(max), text, ntext, varbinary, xml, en afbeelding .
SQL Server heeft een standaardoptie om de maximale kolomlengte van het gegevenstype string (in bytes) te beperken die moet worden gerepliceerd als 65536 bytes.
We moeten de Max Text Repl Size zorgvuldig evalueren wanneer Replicatie is geconfigureerd voor een database. Daarvoor moeten we alle bovenstaande gegevenstypekolommen controleren en de maximaal mogelijke bytes identificeren die via replicatie worden overgedragen.
Het wijzigen van de waarde naar -1 geeft aan dat er geen limieten zijn. We raden u echter aan de maximale tekenreekslengte te evalueren en die waarde te configureren.
We kunnen Max Text Repl Size configureren met SSMS of T-SQL.
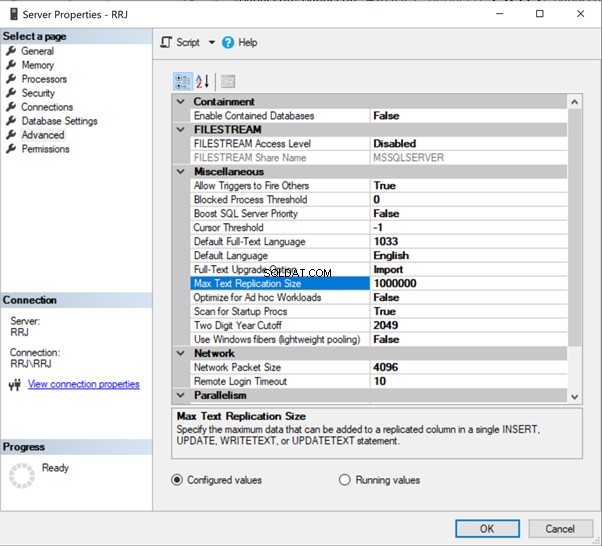
Klik in SSMS met de rechtermuisknop op de servernaam> Eigenschappen > Geavanceerd :
Klik gewoon op 65536 om het te wijzigen. Voor tests heb ik 65536 gewijzigd in 1000000 en op OK . geklikt :
Om de optie Max Text Repl Size via T-SQL te configureren, opent u een nieuw queryvenster en voert u het onderstaande script uit op de hoofddatabase:
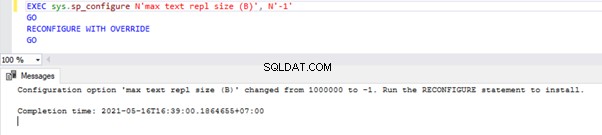
EXEC sys.sp_configure N'max text repl size (B)', N'-1'
GO
RECONFIGURE WITH OVERRIDE
GO
Met deze query kan Replicatie de grootte van de bovenstaande gegevenstypekolommen niet beperken.
Om dit te verifiëren, kunnen we een SELECT uitvoeren op sys.configurations DMV en controleer de value_in_use kolom zoals hieronder:

SQL Server Agent-service niet ingesteld om automatische modus te starten
Replicatie is afhankelijk van replicatieagenten die worden uitgevoerd als SQL Server Agent-taken. Elk probleem met een of andere SQL Server Agent-service heeft dus een directe invloed op de replicatiefunctionaliteit.
We moeten ervoor zorgen dat de startmodus van SQL Server en SQL Server Agent Services zijn ingesteld op Automatisch. Indien ingesteld op Handmatig, moeten we enkele waarschuwingen configureren. Ze zouden de DBA of serverbeheerders op de hoogte stellen om de SQL Server Agent-service te starten wanneer de server geplande of ongeplande herstart.
Als u dit niet doet, wordt de replicatie mogelijk lange tijd niet uitgevoerd, wat ook van invloed is op andere SQL Server Agent-taken.
Ongecontroleerde replicatie-instanties krijgen een niet-geïnitialiseerde abonnementsstatus
Net als bij het bewaken van SQL Server Agent Service, speelt het configureren van Database Mail Service in een SQL Server-instantie een cruciale rol bij het tijdig waarschuwen van DBA of de geconfigureerde persoon. Voor eventuele taakfouten of problemen kunnen SQL Server Agent-taken zoals Log Reader Agent of Distribution Agent worden geconfigureerd om waarschuwingen naar DBA of het respectieve teamlid via e-mail te sturen. Het mislukken van de taakuitvoering van de Replicatieagent kan leiden tot de onderstaande scenario's:
Niet-uitvoering van de Log Reader Agent-taak . Het transactielogbestand van de Publisher-database wordt pas opnieuw gebruikt na het commando gemarkeerd voor replicatie wordt gelezen door de Log Reader Agent en succesvol verzonden naar de distributiedatabase. Anders, de log_reuse_wait_desc kolom van sys.databases toont de waarde als Replicatie, wat aangeeft dat het databaselogboek niet opnieuw kan worden gebruikt totdat het met succes wijzigingen naar de distributiedatabase heeft overgebracht. Daarom zal het niet uitvoeren van de Log Reader-agent de grootte van het transactielogboekbestand van de Publisher-database blijven vergroten en zullen we prestatieproblemen ondervinden tijdens de volledige back-up of schijfruimteproblemen op de Publisher-database-instantie.
Niet-uitvoering van taak distributieagent. De taak Distributieagent leest de gegevens uit de distributiedatabase en verzendt deze naar de abonneedatabase. Vervolgens markeert het die records voor verwijdering in de distributiedatabase. Als de taak Distributieagent niet wordt uitgevoerd, wordt de distributiedatabase groter en ontstaan er prestatieproblemen voor de algehele replicatieprestaties. Standaard is de distributiedatabase zo geconfigureerd dat records maximaal 0-72 uur kunnen worden bewaard, zoals weergegeven in de eigenschap Transactiebehoud hieronder. Als de replicatie meer dan 72 uur niet werkt, wordt het bijbehorende abonnement gemarkeerd als niet-geïnitialiseerd, waardoor we ofwel het abonnement opnieuw moeten configureren of een nieuwe momentopname moeten maken om de replicatie weer te laten werken.
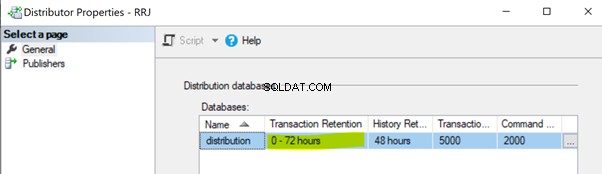
Niet-uitvoering van het opschonen van de distributie:distributietaak . De taak Distributie opschonen is verantwoordelijk voor het verwijderen van alle gerepliceerde records uit de distributiedatabase om de grootte van de distributiedatabase onder controle te houden. Het niet uitvoeren van deze taak leidt tot een grotere omvang van de distributiedatabase, wat resulteert in prestatieproblemen bij de replicatie.
Om ervoor te zorgen dat we geen van deze niet-gecontroleerde problemen tegenkomen, moet de Database Mail worden geconfigureerd om alle mislukte taken of nieuwe pogingen aan de respectieve teamleden te melden voor snelle actie.
Bekende problemen binnen SQL Server
Bepaalde SQL Server-versies hadden bekende replicatieproblemen in de RTM-versie of eerdere versies. Deze problemen zijn opgelost in de daaropvolgende Service Packs of CU-packs. Daarom wordt aanbevolen om de nieuwste Servicepacks of CU-packs toe te passen zodra ze beschikbaar zijn voor alle SQL Server, nadat ze zijn getest in de QA-omgeving. Hoewel dit een algemene aanbeveling is voor servers met SQL Server, is het ook van toepassing op replicatie.
Toestemmingsproblemen
In een omgeving waarin de SQL Server-transactiereplicatie is geconfigureerd, kunnen we de machtigingsproblemen vaak waarnemen. We kunnen ze tegenkomen tijdens de replicatieconfiguratie of onderhoudsactiviteiten op de uitgever of distributeur of de database-instanties van de abonnee. Het resulteert in verloren inloggegevens of machtigingen. Laten we nu eens kijken naar enkele veelvoorkomende toestemmingsproblemen met betrekking tot replicatie.
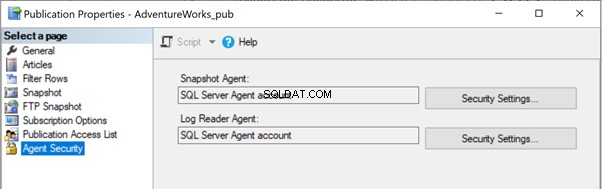
SQL Server Agent-taaktoestemmingsproblemen
Alle replicatieagenten gebruiken SQL Server Agent-taken. Elke SQL Server Agent-taak met betrekking tot de Snapshot of de Log Reader Agent, of Distributie wordt uitgevoerd onder bepaalde Windows- of SQL-aanmeldingsreferenties, zoals hieronder weergegeven:
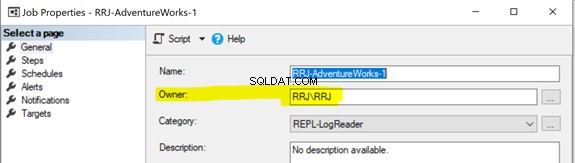
Om een SQL Server Agent-taak te starten, moet u beschikken over de SQLAgentOperatorRole om alle taken te starten of SQLAgentUserRole of de SQLAgentReaderRole om banen te starten die u bezit. Als een taak niet goed kon starten, controleer dan of de taakeigenaar de benodigde rechten heeft om die taak uit te voeren.
Snapshot Agent Taakreferentie heeft geen toegang tot pad van snapshotmap
In onze vorige artikelen hebben we gemerkt dat de uitvoering van de Snapshot-agent de momentopname van de artikelen in een lokaal of gedeeld mappad zou creëren om via de distributieagent naar de abonneedatabase te worden gepropageerd. De locatie van het Snapshot-pad kan worden geïdentificeerd onder de Publicatie-eigenschappen > Momentopname :
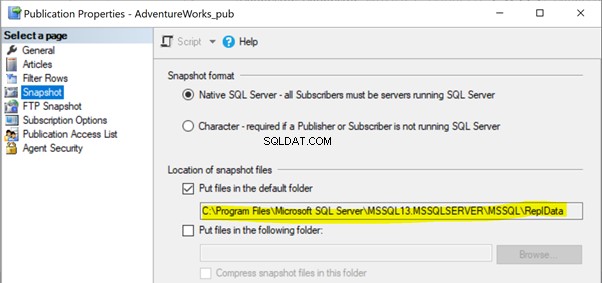
Als de Snapshot-agent geen toegang heeft tot de locatie van deze Snapshot-bestanden, kunnen we de foutmelding krijgen:
Toegang tot het pad 'C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\repldata\unc\XXXX\YYYYMMDDHHMISS\' wordt geweigerd.
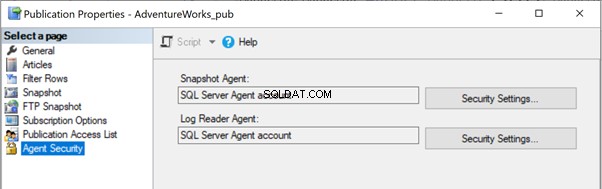
Om het probleem op te lossen, is het beter om volledige toegang te verlenen tot het mappad C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\repldata\unc\ voor het account waaronder de Snapshot Agent uitvoert. In onze configuratie gebruiken we het SQL Server Agent-account en de SQL Server Agent-service wordt uitgevoerd onder het RRJ\RRJ-account.
De taakreferentie van Log Reader Agent kan geen verbinding maken met de uitgevers-/distributiedatabase
Log Reader Agent maakt verbinding met de Publisher-database om de sp_replcmds . uit te voeren procedure om te scannen naar de transacties die zijn gemarkeerd voor replicatie vanuit de transactielogboeken van de uitgeversdatabase.
Als de database-eigenaar van de Publisher-database niet correct is ingesteld, kunnen we de volgende fouten ontvangen:
Het proces kon 'sp_replcmds' niet uitvoeren op 'RRJ.
Of
Kan niet worden uitgevoerd als de database-principal omdat de principal "dbo" niet bestaat, dit type principal niet kan worden nagebootst of u geen toestemming hebt.
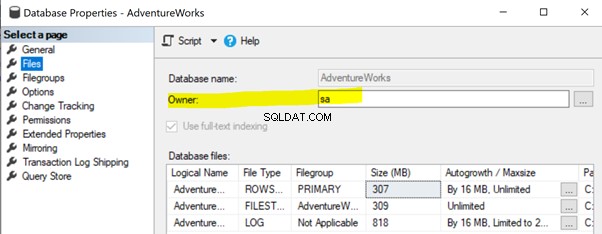
Om dit probleem op te lossen, moet u ervoor zorgen dat de eigenschap van de database-eigenaar van de Publisher-database is ingesteld op sa of een ander geldig account (zie hieronder).
Klik met de rechtermuisknop op de Uitgever database (AdventureWorks )> Eigenschappen > Bestanden . Zorg ervoor dat de Eigenaar veld is ingesteld op sa of een geldige login en niet leeg .
Als er toestemmingsproblemen optreden wanneer we verbinding maken met de uitgever- of distributiedatabase, controleer dan de inloggegevens die voor de Log Reader Agent zijn gebruikt en verleen ze toestemming om toegang te krijgen tot die databases.
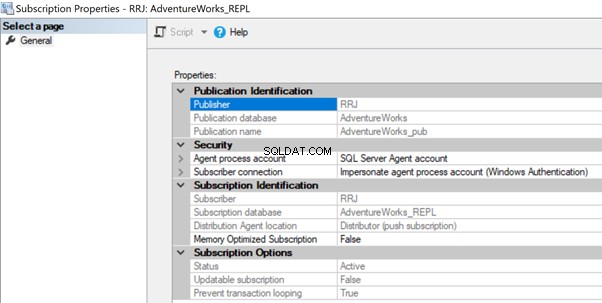
De taakreferentie van de distributieagent kan geen verbinding maken met de distributie-/abonneedatabase
De distributieagent heeft mogelijk machtigingsproblemen als het account geen toegang heeft tot de distributiedatabase of geen verbinding mag maken met de abonneedatabase. In dit geval kunnen we de volgende fouten krijgen:
Kan uitvoering van stap 2 niet starten (reden:fout bij authenticatie proxy RRJ\RRJ, systeemfout:gebruikersnaam of wachtwoord is onjuist.)
Het proces kan geen verbinding maken met abonnee 'RRJ.
Aanmelden mislukt voor gebruiker 'RRJ\RRJ'.
Om dit op te lossen, controleert u het account dat wordt gebruikt in de Abonnementseigenschappen en zorgt u ervoor dat het de nodige machtigingen heeft om verbinding te maken met de distributie- of abonneedatabase.
Connectiviteitsproblemen
We configureren de Transactionele Replicatie meestal over servers binnen hetzelfde netwerk of over geografisch verspreide locaties. Als de distributiedatabase zich op een speciale server bevindt, los van de uitgever of abonnee, wordt deze vatbaar voor verlies van netwerkpakketten - verbindingsproblemen.
In het geval van dergelijke problemen kunnen replicatieagenten (logboeklezer of distributieagent) de onderstaande fouten melden:
Uitgeversserver is niet gevonden of was niet toegankelijk
Distributieserver niet gevonden of niet toegankelijk
Abonneeserver niet gevonden of niet toegankelijk
Om deze problemen op te lossen, kunnen we proberen verbinding te maken met de uitgever-, distributeur- of abonneedatabase in SSMS om te controleren of we zonder problemen verbinding kunnen maken met deze SQL Server-instanties.
Als verbindingsproblemen vaak optreden, kunnen we proberen de server continu te pingen om eventuele pakketverliezen te identificeren. We moeten ook samenwerken met de nodige teamleden om deze problemen op te lossen en de server in gebruik te nemen zodat Replicatie de overdracht van gegevens kan hervatten.
Kwesties met betrekking tot gegevensintegriteit
Aangezien Transactionele Replicatie een eenrichtingsmechanisme is, worden eventuele gegevenswijzigingen die plaatsvinden op de Abonnee (handmatig of vanuit de applicatie) niet weergegeven op de Uitgever. Dit kan leiden tot gegevensverschillen tussen de uitgever en de abonnee.
Laten we de problemen met betrekking tot gegevensintegriteit eens bekijken en kijken hoe we ze kunnen oplossen. Merk op dat we een record hebben ingevoegd in het Person.ContactType tabel en verwijderde 2 records uit het Person.ContactType tabel in de abonneedatabase. We gaan deze 3 records gebruiken om fouten te vinden.
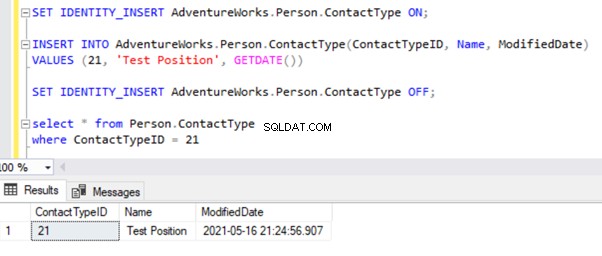
De primaire sleutel of unieke sleutelovertredingen
Ik ga het INSERT-record testen op het Person.ContactType tafel. Laten we dat record in de Publisher-database invoegen en kijken wat er gebeurt:
Start de Replicatiemonitor om te zien hoe het gaat. We krijgen de foutmelding:
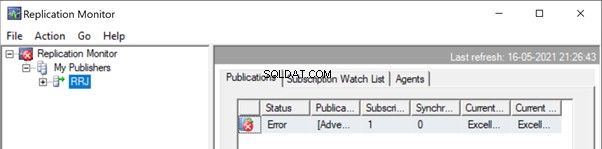
Uitgever uitvouwen en Publicatie , krijgen we de volgende details:
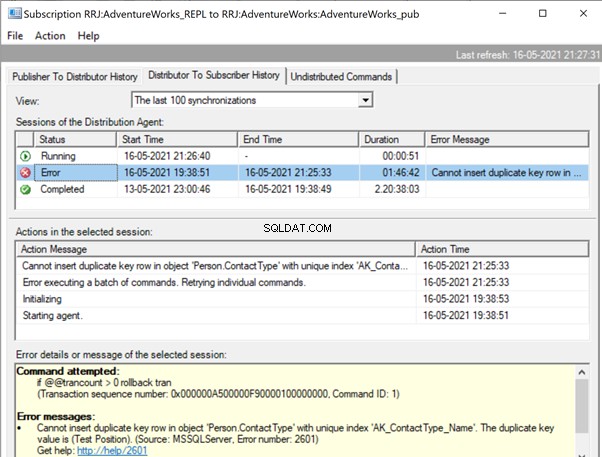
Als we de replicatiewaarschuwingen hebben geconfigureerd en respectieve personen hebben toegewezen om hun e-mailwaarschuwing te ontvangen, ontvangen we de juiste e-mailmeldingen met de foutmelding:Kan geen dubbele sleutelrij invoegen in object 'Person.ContactType' met unieke index 'AK_ContactType_Name ' . De dubbele sleutelwaarde is (Testpositie). (Bron:MSSQLServer, Foutnummer:2601)
Om het probleem met betrekking tot schendingen van unieke sleutels of problemen met primaire sleutels op te lossen, hebben we verschillende opties:
- Analyseer waarom deze fout is opgetreden, hoe het record beschikbaar was in de abonneedatabase en wie het om welke redenen heeft ingevoegd. Bepaal of het nodig was of niet.
- Voeg de schippers toe parameter naar het Distribution Agent-profiel om Foutnummer 2601 over te slaan of Foutnummer 2627 in geval van schending van de primaire sleutel.
In ons geval hebben we doelbewust gegevens ingevoegd om deze fout te ontvangen. Om dit probleem op te lossen, verwijdert u dat handmatig ingevoegde record om door te gaan met het repliceren van wijzigingen die zijn ontvangen van de uitgever.
DELETE from Person.ContactType
where ContactTypeID = 21
Om andere opties te bestuderen en de verschillen tussen deze twee benaderingen te vergelijken, sla ik de eerste optie over (die efficiënt en aanbevolen is) en ga ik verder met de tweede optie door de -skiperrors toe te voegen. parameter toe aan de taak Distributieagent.
We kunnen het implementeren door de Distributieagent-taak te bewerken > Stappen > klik op 2 taakstappen met de naam Agent uitvoeren > klik op Bewerken om de beschikbare opdracht te bekijken:
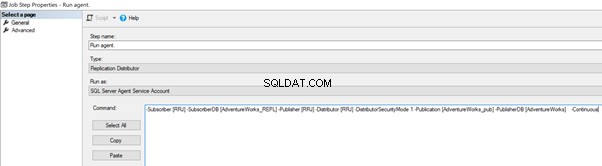
Voeg nu de -SkipErrors 2601 . toe zoekwoord aan het eind (2601 is het foutnummer - we kunnen elk foutnummer dat we ontvangen als onderdeel van Replicatie overslaan) en klik op OK .
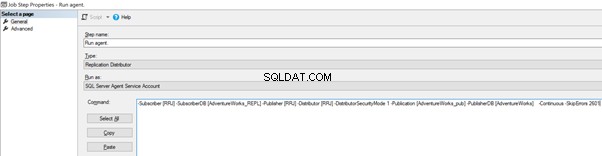
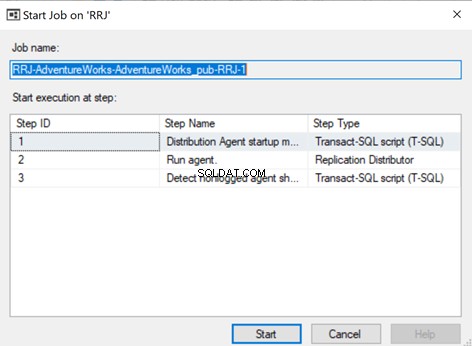
To make sure that the Distribution job is aware of this configuration change, we need to restart the Distribution agent job. For that, stop it and start again from Step 1 as shown below:
The Replication Monitor displays that one of the error records is skipped from the Replication, that started working fine.
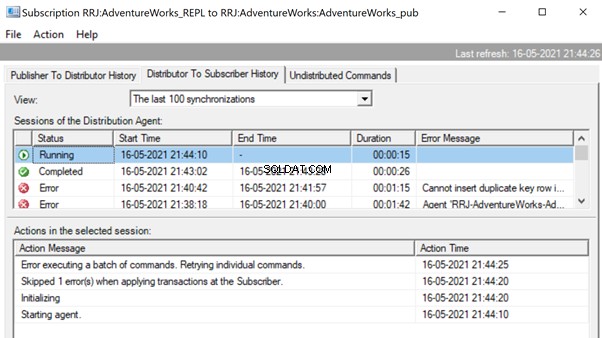
Since the Replication issue is resolved successfully, we’d recommend removing the -SkipErrors parameter from the Distribution Agent job. Then, restart the job to get the changes reflected.
Thus, we’ve fixed the replication issue, but let’s compare the data across the same Person.ContactType in the Publisher and Subscriber databases. The results show the data variance, or the data integrity issue :
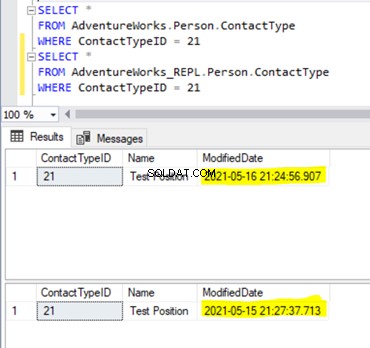
ModifiedDate is different across the Publisher and Subscriber databases. It happens because the data in the Subscriber database was inserted earlier (when we were preparing the test data), and the data in the Publisher database has just been inserted.
If we deleted the record from the Subscriber database, the record from the Publisher would have been inserted to match the data across the Publisher and the Subscriber databases.
Most of the newbie DBAs simply add the -SkipErrors option to get the replication working immediately without detailed investigations of the issue. Hence, it is recommended not to use the -SkipErrors option as a primary solution without proper examination of the problem. The Person.ContactType table had only 3 columns. Assume that the table has over 20 columns. Then, we have just screwed up the Data integrity of this table with that -SkipErrors commando.
We used this approach just to illustrate the usage of that option. The best way is to examine and clarify the reason for variance and then perform the appropriate DELETE statements on the Subscriber database to maintain the Data Integrity across the Publisher and Subscriber databases.
Row Not Found Errors
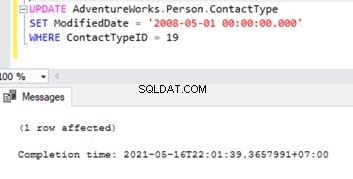
Let’s try to perform an UPDATE on one of the records that were deleted from the Subscriber database:
Let’s check the Replication Monitor to see the performance. We have the following error:
The row was not found at the Subscriber when applying the replicated UPDATE command for Table ‘[Person].[ContactType]’ with Primary Key(s):[ContactTypeID] =19 (Source:MSSQLServer, Error number:20598).
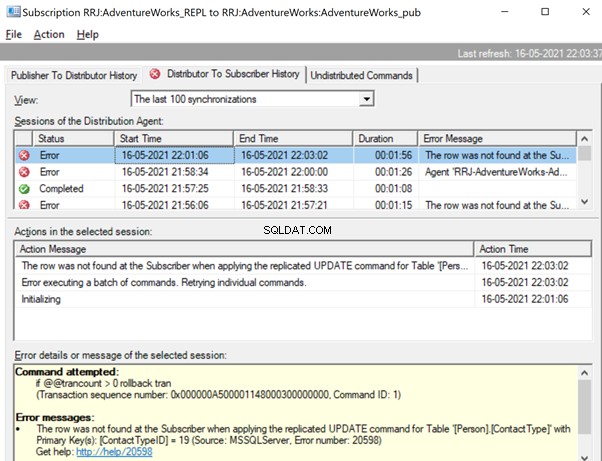
There are two ways to resolve this error. First, we can use -SkipErrors for Error Number 20598 . Or, we can INSERT the record with ContactTypeID =19 (shown in the error message) to get the data changes reflected.
If we skip this error, we’ll lose the record with ContactTypeId =19 from the Subscriber database permanently. It can cause data inconsistency issues. Hence, we aren’t going to use the -SkipErrors optie. Instead, we’ll apply the INSERT approach.
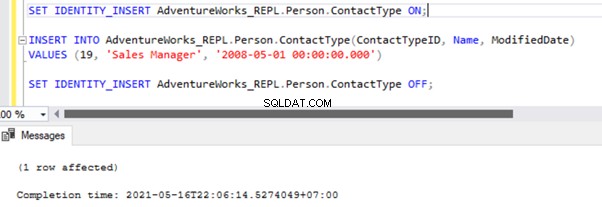
The Replication resumes correctly by sending the UPDATE to the Subscriber database.
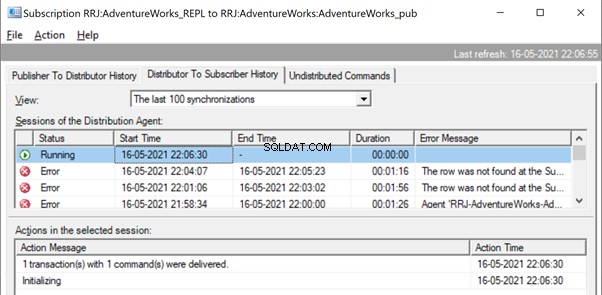
It is the same when we try to delete the ContactTypeId =20 from the Publisher database and see the error popping up in the Replication Monitor.
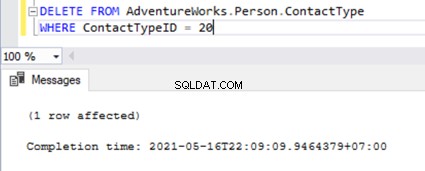
The Replication Monitor shows us a message similar to the one we already noticed:
The row was not found at the Subscriber when applying the replicated DELETE command for Table ‘[Person].[ContactType]’ with Primary Key(s):[ContactTypeID] =20 (Source:MSSQLServer, Error number:20598)
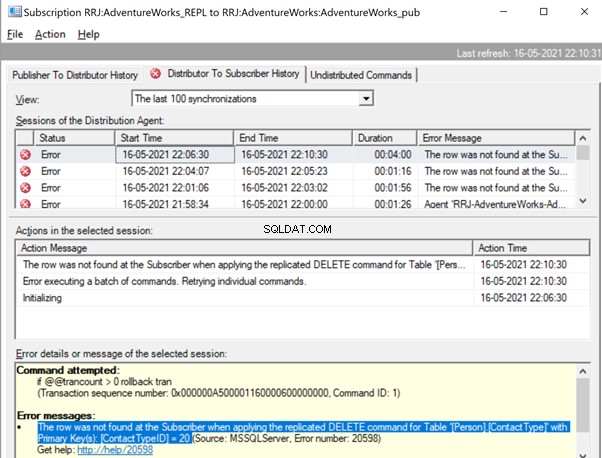
Similar to the previous error, we need to identify the missing record and insert it back to the Subscriber database for the DELETE statement to get replicated properly. For DELETE scenario, using -SkipErrors doesn’t have any issues but can’t be considered as a safe option, as both missing UPDATE or missing DELETE record are captured with the same error number 20598 and adding -SkipErrors 20598 will skip applying all records from the Subscriber database.
We can also get more details about the problematic command by using the sp_browsereplcmds stored procedure which we have discussed earlier as well. Let’s try to use sp_browsereplcmds stored procedure for the previous error we have received out as shown below.

exec sp_browsereplcmds @xact_seqno_start = '0x000000A500001160000600000000'
, @xact_seqno_end = '0x000000A500001160000600000000'
, @publisher_database_id = 1
, @command_id = 1
@xact_seqno_start and @xact_seqno_end will be the same value. We can fetch that value from the Transaction Sequence number in the Replication Monitor along with Command ID.
@publisher_database_id can be fetched from the id column of the distribution..MSPublisher_databases DMV.
select * from MSpublisher_databases Foreign Key or Other Constraint Violation Errors
The error messages related to Foreign keys or any other data issues are slightly different. Microsoft has made these error messages detailed and self-explanatory for anyone to understand what the issue is about.
To identify the exact command that was executed on the Publisher and resolve it efficiently, we can use the sp_browsereplcmds procedure explained above and identify the root cause of the issue.
Once the commands are identified as INSERT/UPDATE/DELETE which caused the errors, we can take corresponding actions to resolve the problems correctly which is more efficient compared to simply adding -SkipErrors approach. Once corrective measures are taken, Replication will start resuming fine immediately.
Word of Caution Using -SkipErrors Option
Those who are comfortable using -SkipErrors option to resolve error quickly should remember that -SkipErrors option is added at the Distribution agent level and applies to all Published articles in that Publication. Command -SkipErrors will result in skipping any number of commands related to that particular error across all published articles any number of times resulting in discrepancies we have seen in demo resulting in data discrepancies across Publisher and Subscriber without knowing how many tables are having discrepancies and would require efforts to compare the tables and fix it out.
Conclusion
Thanks for going through another robust article. I hope it was helpful for you to understand the SQL Server Transactional Replication issues and methods of troubleshooting them. In our next article, we’ll continue the discussion about the SQL Transaction Replication issues, examine other types, such as Corruption-related issues, and learn the best methods of handling them.