In dit artikel bespreken we typische fouten waarmee beginnende ontwikkelaars te maken kunnen krijgen bij het ontwerpen van T-SQL-code. Daarnaast zullen we de best practices en enkele handige tips bekijken die u kunnen helpen bij het werken met SQL Server, evenals tijdelijke oplossingen om de prestaties te verbeteren.
Inhoud:
1. Gegevenstypen
2. *
3. Alias
4. Kolomvolgorde
5. NIET IN vs NULL
6. Datumnotatie
7. Datumfilter
8. berekening
9. Converteer impliciet
10. LIKE &onderdrukte index
11. Unicode versus ANSI
12. VERZAMELEN
13. BINAIRE SAMENSTELLING
14. Codestijl
15. [var]char
16. Gegevenslengte
17. ISNULL vs COALESCE
18. Wiskunde
19. UNION vs UNION ALL
20. Herlees
21. Subquery
22. GEVAL WANNEER
23. Scalaire functie
24. VIEWs
25. CURSOR's
26. STRING_CONCAT
27. SQL-injectie
Gegevenstypen
Het belangrijkste probleem waarmee we worden geconfronteerd wanneer we met SQL Server werken, is een onjuiste keuze van gegevenstypen.
Stel dat we twee identieke tabellen hebben:
DECLARE @Employees1 TABLE ( EmployeeID BIGINT PRIMARY KEY , IsMale VARCHAR(3) , Geboortedatum VARCHAR(20))INSERT INTO @Employees1VALUES (123, 'YES', '2012-09-01')DECLARE @Employees2 TABEL ( EmployeeID INT PRIMAIRE SLEUTEL , IsMale BIT , Geboortedatum DATUM)INSERT INTO @Employees2VALUES (123, 1, '2012-09-01')
Laten we een query uitvoeren om te controleren wat het verschil is:
DECLARE @BirthDate DATE ='2012-09-01'SELECT * FROM @Employees1 WHERE BirthDate =@BirthDateSELECT * FROM @Employees2 WHERE BirthDate =@BirthDate
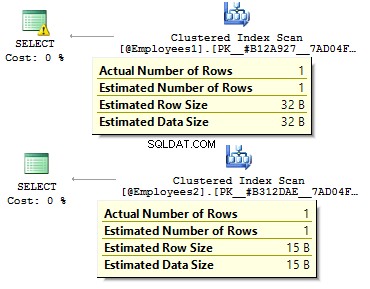
In het eerste geval zijn de gegevenstypen meer redundant dan ze zouden kunnen zijn. Waarom zouden we een bitwaarde opslaan als YES/NO rij? Waarom moeten we een datum als een rij opslaan? Waarom zouden we BIGINT gebruiken? voor werknemers in de tabel, in plaats van INT ?
Het leidt tot de volgende nadelen:
- Tabellen kunnen veel ruimte op de schijf in beslag nemen;
- We moeten meer pagina's lezen en meer gegevens in BufferPool plaatsen om gegevens te verwerken.
- Slechte prestatie.
*
Ik heb te maken gehad met de situatie waarin ontwikkelaars alle gegevens uit een tabel halen en vervolgens aan de clientzijde DataReader gebruiken om alleen verplichte velden te selecteren. Ik raad het gebruik van deze aanpak niet aan:
GEBRUIK AdventureWorks2014GOSET STATISTIEKEN TIJD, IO ONSELECT *FROM Person.PersonSELECT BusinessEntityID , FirstName , MiddleName , LastNameFROM Person.PersonSTEL STATISTIEKEN TIJD, IO UIT
Er zal een aanzienlijk verschil zijn in de uitvoeringstijd van de query. Bovendien kan de dekkingsindex een aantal logische uitlezingen verminderen.
Tabel 'Persoon'. Scan count 1, logische leest 3819, fysieke leest 3, ... SQL Server uitvoeringstijden:CPU-tijd =31 ms, verstreken tijd =1235 ms. Tabel 'Persoon'. Scantelling 1, logische leest 109, fysieke leest 1, ... Uitvoeringstijden SQL Server:CPU-tijd =0 ms, verstreken tijd =227 ms.
Alias
Laten we een tabel maken:
GEBRUIK AdventureWorks2014GOIF OBJECT_ID('Sales.UserCurrency') IS NOT NULL DROP TABLE Sales.UserCurrencyGOCREATE TABLE Sales.UserCurrency ( CurrencyCode NCHAR (3) PRIMARY KEY)INSERT INTO Sales.UserCurrencyVALUES ('USD') Stel dat we een query hebben die het aantal identieke rijen in beide tabellen retourneert:
SELECT COUNT_BIG(*)FROM Sales.CurrencyWHERE CurrencyCode IN (SELECT CurrencyCode FROM Sales.UserCurrency)
Alles werkt zoals verwacht, totdat iemand een kolom hernoemt in de Sales.UserCurrency tafel:
EXEC sys.sp_rename 'Sales.UserCurrency.CurrencyCode', 'Code', 'COLUMN'
Vervolgens zullen we een query uitvoeren en zien dat we alle rijen in de Sales.Currency krijgen tabel, in plaats van 1 rij. Bij het bouwen van een uitvoeringsplan zou SQL Server in de bindingsfase de kolommen van Sales.UserCurrency, controleren het zal CurrencyCode niet vinden daar en besluit dat deze kolom behoort tot de Sales.Currency tafel. Daarna zal een optimizer de CurrencyCode =CurrencyCode . laten vallen staat.
Daarom raad ik aan aliassen te gebruiken:
SELECT COUNT_BIG(*)FROM Sales.Currency cWHERE c.CurrencyCode IN ( SELECT u.CurrencyCode FROM Sales.UserCurrency u )
Kolomvolgorde
Stel dat we een tafel hebben:
IF OBJECT_ID('dbo.DatePeriod') IS NIET NULL DROP TABEL dbo.DatePeriodGOCREATE TABEL dbo.DatePeriod ( StartDate DATE , EndDate DATE) We voegen daar altijd gegevens in op basis van de informatie over de kolomvolgorde.
INSERT INTO dbo.DatePeriodSELECT '2015-01-01', '2015-01-31'
Stel dat iemand de volgorde van kolommen verandert:
MAAK TABEL dbo.DatePeriod ( EndDate DATE , StartDate DATE)
Gegevens worden in een andere volgorde ingevoegd. In dit geval is het een goed idee om expliciet kolommen te specificeren in de INSERT-instructie:
INSERT INTO dbo.DatePeriod (StartDate, EndDate)SELECT '2015-01-01', '2015-01-31'
Hier is nog een voorbeeld:
SELECTEER TOP(1) *VAN dbo.DatumPeriodeBESTEL DOOR 2 DESC
Op welke kolom gaan we data bestellen? Het hangt af van de kolomvolgorde in een tabel. Als iemand de volgorde verandert, krijgen we verkeerde resultaten.
NIET IN vs NULL
Laten we het hebben over de NIET IN verklaring.
U moet bijvoorbeeld een aantal query's schrijven:retourneer de records van de eerste tabel, die niet bestaan in de tweede tabel en visa versa. Meestal gebruiken junior ontwikkelaars IN en NIET IN :
DECLARE @t1 TABEL (t1 INT, UNIEK GECLUSTERD(t1))INSERT INTO @t1 VALUES (1), (2)DECLARE @t2 TABEL (t2 INT, UNIEK GECLUSTERD(t2))INSERT INTO @t2 VALUES (1 )SELECT *FROM @t1WHERE t1 NOT IN (SELECT t2 FROM @t2)SELECT *FROM @t1WHERE t1 IN (SELECT t2 FROM @t2)
De eerste query heeft 2 geretourneerd, de tweede - 1. Verder zullen we nog een waarde toevoegen in de tweede tabel - NULL :
INSERT INTO @t2 VALUES (1), (NULL)
Bij het uitvoeren van de zoekopdracht met NOT IN , krijgen we geen resultaten. Waarom IN werkt en NOT In niet? De reden is dat SQL Server TRUE . gebruikt , FALSE , en ONBEKEND logica bij het vergelijken van gegevens.
Bij het uitvoeren van een query interpreteert SQL Server de IN-voorwaarde op de volgende manier:
a IN (1, NULL) ==a=1 OR a=NULL
NIET IN :
a NOT IN (1, NULL) ==a<>1 AND a<>NULL
Bij het vergelijken van een waarde met NULL, SQL Server retourneert ONBEKEND. Ofwel 1=NULL of NULL=NULL – beide resulteren in ONBEKEND. Voor zover we AND in de uitdrukking hebben, retourneren beide zijden UNKNOWN.
Ik wil erop wijzen dat dit geval niet zeldzaam is. U markeert bijvoorbeeld een kolom als NIET NULL. Na een tijdje besluit een andere ontwikkelaar NULL's toe te staan voor die kolom. Dit kan ertoe leiden dat een klantrapport niet meer werkt zodra een NULL-waarde in de tabel is ingevoegd.
In dit geval raad ik aan om NULL-waarden uit te sluiten:
SELECTEER *FROM @t1WHERE t1 NOT IN (SELECT t2 FROM @t2 WHERE t2 IS NOT NULL)
Daarnaast is het mogelijk om BEHALVE . te gebruiken :
SELECT * FROM @t1EXCEPTSELECT * FROM @t2
U kunt ook NIET BESTAAT . gebruiken :
SELECTEER *FROM @t1WHERE NOT EXISTS( SELECT 1 FROM @t2 WHERE t1 =t2 )
Welke optie heeft meer de voorkeur? De laatste optie met NIET BESTAAT lijkt het meest productief te zijn omdat het de meer optimale predikaat pushdown genereert operator om toegang te krijgen tot gegevens uit de tweede tabel.
In feite kunnen de NULL-waarden een onverwacht resultaat opleveren.
Overweeg het bij dit specifieke voorbeeld:
GEBRUIK AdventureWorks2014GOSELECT COUNT_BIG(*)FROM Production.ProductSELECT COUNT_BIG(*)FROM Production.ProductWHERE Color ='Grey'SELECT COUNT_BIG(*)FROM Production.ProductWHERE Color <> 'Grijs'
Zoals u kunt zien, heeft u niet het verwachte resultaat omdat NULL-waarden afzonderlijke vergelijkingsoperatoren hebben:
SELECT COUNT_BIG(*)FROM Production.ProductWHERE Color IS NULLSELECT COUNT_BIG(*)FROM Production.ProductWHERE Color IS NOT NULL
Hier is nog een voorbeeld met CHECK beperkingen:
IF OBJECT_ID('tempdb.dbo.#temp') IS NIET NULL DROP TABLE #tempGOCREATE TABLE #temp ( Kleur VARCHAR (15) --NULL , CONSTRAINT CK CHECK (Kleur IN ('Zwart', 'Wit') )) We maken een tabel met toestemming om alleen witte en zwarte kleuren in te voegen:
INSERT INTO #temp VALUES ('Black')(1 rij(en) aangetast) Alles werkt zoals verwacht.
INSERT INTO #temp VALUES ('Rood')De INSERT-instructie is in strijd met de CHECK-beperking... De instructie is beëindigd. Laten we nu NULL toevoegen:
INSERT INTO #temp VALUES (NULL)(1 rij(en) aangetast)
Waarom heeft de beperking CHECK de NULL-waarde doorgegeven? Welnu, de reden is dat er genoeg NIET FALSE . is voorwaarde om een record te maken. De tijdelijke oplossing is om een kolom expliciet te definiëren als NIET NULL of gebruik NULL in de beperking.
Datumnotatie
U kunt heel vaak problemen hebben met gegevenstypen.
U moet bijvoorbeeld de huidige datum krijgen. Om dit te doen, kunt u de GETDATE-functie gebruiken:
SELECTEER GETDATUM()
Kopieer vervolgens het geretourneerde resultaat in een vereiste query en verwijder de tijd:
SELECTEER *FROM sys.objectsWHERE create_date <'2016-11-14'
Klopt dat?
De datum wordt gespecificeerd door een stringconstante:
TAAL INSTELLEN DutchSET DATEFORMAT DMYDECLARE @d1 DATETIME ='05/12/2016' , @d2 DATETIME ='2016/12/05' , @d3 DATETIME ='2016-12-05' , @d4 DATETIME ='05 -dec-2016'SELECT @d1, @d2, @d3, @d4
Alle waarden hebben een interpretatie van één waarde:
----------- ----------- ----------- -----------2016-12 -05 2016-05-12 2016-05-12 2016-12-05
Het zal geen problemen veroorzaken totdat de query met deze bedrijfslogica wordt uitgevoerd op een andere server waar de instellingen kunnen verschillen:
SET DATEFORMAT MDYDECLARE @d1 DATETIME ='05/12/2016' , @d2 DATETIME ='2016/12/05' , @d3 DATETIME ='2016-12-05' , @d4 DATETIME ='05-dec -2016'SELECT @d1, @d2, @d3, @d4
Deze opties kunnen echter leiden tot een onjuiste interpretatie van de datum:
----------- ----------- ----------- -----------2016-05 -12 2016-12-05 2016-12-05 2016-12-05
Bovendien kan deze code zowel tot een zichtbare als een latente bug leiden.
Beschouw het volgende voorbeeld. We moeten gegevens invoegen in een testtabel. Op een testserver werkt alles perfect:
DECLARE @t TABLE (a DATETIME)INSERT INTO @t VALUES ('05/13/2016') Aan de kant van de klant zal deze vraag echter problemen opleveren omdat onze serverinstellingen verschillen:
DECLARE @t TABLE (a DATETIME)SET DATEFORMAT DMYINSERT INTO @t VALUES ('05/13/2016') Msg 242, Level 16, State 3, Line 28De conversie van een varchar-gegevenstype naar een datetime-gegevenstype resulteerde in een waarde die buiten het bereik ligt.
Dus, welk formaat moeten we gebruiken om datumconstanten te declareren? Voer deze vraag uit om deze vraag te beantwoorden:
SET DATEFORMAT YMDSET TAAL EnglishDECLARE @d1 DATETIME ='2016/01/12' , @d2 DATETIME ='2016-01-12' , @d3 DATETIME ='12-jan-2016' , @d4 DATETIME ='20160112 'SELECT @d1, @d2, @d3, @d4GOSET LANGUAGE DeutschDECLARE @d1 DATETIME ='2016/01/12' , @d2 DATETIME ='2016-01-12' , @d3 DATETIME ='12-jan-2016' , @d4 DATETIME ='20160112'SELECT @d1, @d2, @d3, @d4
De interpretatie van constanten kan verschillen afhankelijk van de geïnstalleerde taal:
----------- ----------- ----------- -----------2016-01 -12 2016-01-12 2016-01-12 2016-01-12 ----------- ----------- ----------- -----------2016-12-01 2016-12-01 2016-01-12 2016-01-12
Het is dus beter om de laatste twee opties te gebruiken. Ik zou ook willen toevoegen dat het geen goed idee is om de datum expliciet te specificeren:
TAAL STELLEN FrenchDECLARE @d DATETIME ='12-jan-2016'Msg 241, Level 16, State 1, Line 29Echec de la conversie de la date et/ou de l'heure à partir d'une chaîne de caractères.
Als u wilt dat constanten met de datums correct worden geïnterpreteerd, moet u ze daarom specificeren in het volgende formaat JJJJMMDD.
Daarnaast wil ik uw aandacht vestigen op het gedrag van sommige gegevenstypen:
TAAL INSTELLEN DutchSET DATEFORMAT YMDDECLARE @d1 DATE ='2016-01-12' , @d2 DATETIME ='2016-01-12'SELECT @d1, @d2GOSET TAAL DeutschSET DATEFORMAT DMYDECLARE @d1 DATE ='2016-01- 12' , @d2 DATETIME ='2016-01-12'SELECT @d1, @d2
In tegenstelling tot DATETIME, is de DATE type correct wordt geïnterpreteerd met verschillende instellingen op een server:
---------- ----------2016-01-12 2016-01-12---------- ------- ---2016-01-12 2016-12-01
Datumfilter
Om verder te gaan, zullen we bekijken hoe gegevens effectief kunnen worden gefilterd. Laten we beginnen met hen DATETIME/DATE:
GEBRUIK AdventureWorks2014GOUPDATE TOP(1) dbo.DatabaseLogSET PostTime ='20140716 12:12:12'
Nu zullen we proberen uit te vinden hoeveel rijen de zoekopdracht retourneert voor een bepaalde dag:
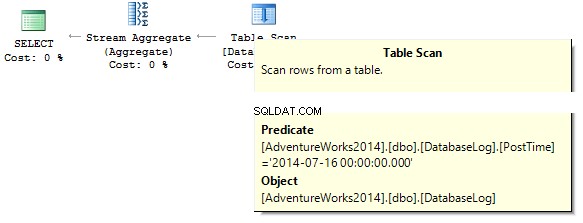
SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE PostTime ='20140716'
De query retourneert 0. Bij het bouwen van een uitvoeringsplan probeert SQL-server een stringconstante te casten naar het gegevenstype van de kolom die we moeten filteren:
Maak een index:
MAAK NIET-GECLUSTERDE INDEX IX_PostTime OP dbo.DatabaseLog (PostTime)
Er zijn juiste en onjuiste opties om gegevens uit te voeren. U moet bijvoorbeeld de tijdkolom verwijderen:
SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE CONVERT(CHAR(8), PostTime, 112) ='20140716'SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE CAST(PostTime AS DATE) ='20140716'
Of we moeten een bereik specificeren:
SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE PostTime TUSSEN '20140716' EN '20140716 23:59:59.997'SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE PostTime>='20140716' AND PostTime <'20140717'
Rekening houdend met optimalisatie, kan ik zeggen dat deze twee vragen de meest correcte zijn. Het punt is dat alle conversies en berekeningen van indexkolommen die worden uitgefilterd de prestaties drastisch kunnen verminderen en de tijd van logische uitlezingen kunnen verhogen:
Tabel 'DatabaseLog'. Scantelling 1, logische leest 7, ...Tabel 'DatabaseLog'. Scan telling 1, logische leest 2, ...
De PostTime veld was nog niet eerder in de index opgenomen en we konden geen efficiëntie zien bij het gebruik van deze juiste benadering bij het filteren. Een ander ding is wanneer we gegevens voor een maand moeten uitvoeren:
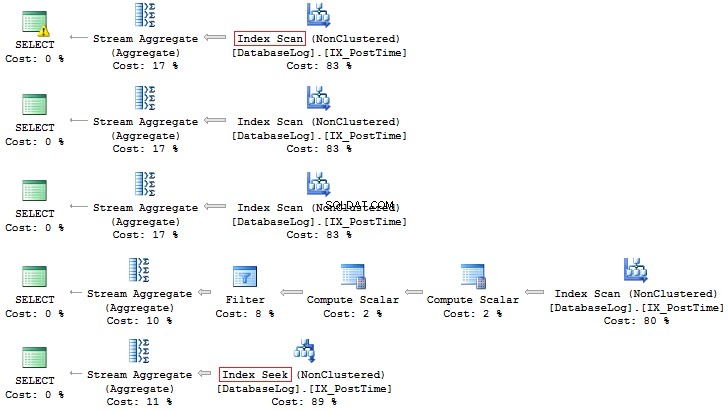
SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE CONVERT(CHAR(8), PostTime, 112) LIKE '201407%'SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE DATEPART(YEAR, PostTime) =2014 AND DATEPART(MONTH, PostTime) =7SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE YEAR(PostTime) =2014 AND MONTH(PostTime) =7SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE EOMONTH(PostTime) ='20140731'SELECT COUNT_BIG(*)FROM Log WHERE.Database PostTime>='20140701' EN PostTime <'20140801'
Nogmaals, de laatste optie heeft meer de voorkeur:
Bovendien kunt u altijd een index maken op basis van een berekend veld:
IF COL_LENGTH('dbo.DatabaseLog', 'MonthLastDay') IS NIET NULL WIJZIGINGSTABEL dbo.DatabaseLog DROP COLUMN MonthLastDayGOALTER TABLE dbo.DatabaseLog ADD MonthLastDay AS EOMONTH(PostTime) --PERSISTEDGOCREATE INDLAST INDLEXData In vergelijking met de vorige zoekopdracht kan het verschil in logische waarden aanzienlijk zijn (als het om grote tabellen gaat):
STEL STATISTIEKEN IN IO ONSELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE PostTime>='20140701' AND PostTime <'20140801'SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE MonthLastDay ='20140731'STEL STATISTIEKEN IN IO OFFTable 'DatabaseLog'. Scantelling 1, logische leest 7, ...Tabel 'DatabaseLog'. Scan telling 1, logische leest 3, ...
Berekening
Zoals al is besproken, verminderen alle berekeningen op indexkolommen de prestaties en verhogen ze de tijd van logische uitlezingen:
GEBRUIK AdventureWorks2014GOSET STATISTIEKEN IO ONSELECT BusinessEntityIDFROM Person.PersonWHERE BusinessEntityID * 2 =10000SELECT BusinessEntityIDFROM Person.PersonWHERE BusinessEntityID =2500 * 2SELECT BusinessEntityIDFROM Person.PersonWHERE BusinessEntityID =5000Tabel 'Persoon'. Scantelling 1, logische leest 67, ...Tabel 'Persoon'. Scan telling 0, logische leest 3, ...
Als we naar de uitvoeringsplannen kijken, dan voert SQL Server in de eerste IndexScan uit :
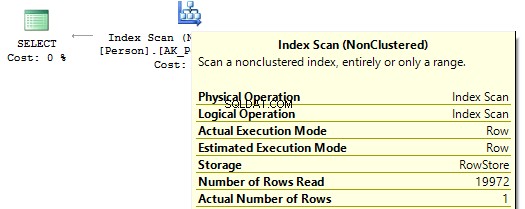
Als er dan geen berekeningen op de indexkolommen staan, zien we IndexSeek :

Impliciet converteren
Laten we eens kijken naar deze twee zoekopdrachten die op dezelfde waarde filteren:
GEBRUIK AdventureWorks2014GOSELECT BusinessEntityID, NationalIDNumberFROM HumanResources.EmployeeWHERE NationalIDNumber =30845SELECT BusinessEntityID, NationalIDNumberFROM HumanResources.EmployeeWHERE NationalIDNumber ='30845'
De uitvoeringsplannen geven de volgende informatie:
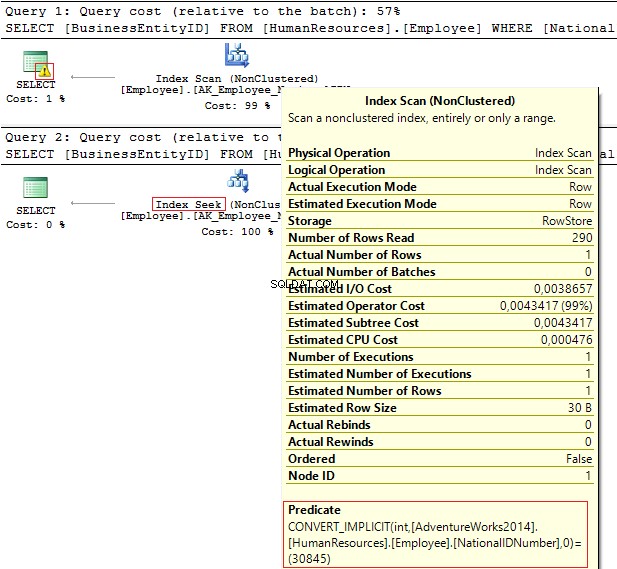
- Waarschuwing en IndexScan op het eerste plan
- IndexSeek – op de tweede.
Tabel 'Werknemer'. Scantelling 1, logische leest 4, ...Tabel 'Medewerker'. Scan telling 0, logische leest 2, ...
Het NationalIDNumber kolom heeft de NVARCHAR(15) data type. De constante die we gebruiken om gegevens uit te filteren is ingesteld als INT wat ons naar een impliciete conversie van het gegevenstype leidt. Op zijn beurt kan het de prestaties verminderen. U kunt het controleren wanneer iemand het gegevenstype in de kolom wijzigt, maar de zoekopdrachten worden niet gewijzigd.
Het is belangrijk om te begrijpen dat een impliciete conversie van gegevenstypes tijdens runtime tot fouten kan leiden. Voordat het veld Postcode bijvoorbeeld numeriek was, bleek een postcode letters te kunnen bevatten. Het gegevenstype is dus bijgewerkt. Als we echter een alfabetische postcode invoeren, werkt de oude zoekopdracht niet meer:
SELECT AddressIDFROM Person.[Address]WHERE PostalCode =92700SELECT AddressIDFROM Person.[Address]WHERE PostalCode ='92700'Msg 245, Level 16, State 1, Line 16Conversie mislukt bij het converteren van de nvarchar-waarde 'K4B 1S2' naar gegevenstype int.
Een ander voorbeeld is wanneer u EntityFramework . moet gebruiken op het project, dat standaard alle rijvelden als Unicode interpreteert:
SELECT CustomerID, AccountNumberFROM Sales.CustomerWHERE AccountNumber =N'AW00000009'SELECT CustomerID, AccountNumberFROM Sales.CustomerWHERE AccountNumber ='AW00000009'
Daarom worden er onjuiste zoekopdrachten gegenereerd:

Zorg ervoor dat de gegevenstypen overeenkomen om dit probleem op te lossen.
LIKE &Onderdrukte index
In feite betekent het hebben van een dekkingsindex niet dat u deze ook effectief zult gebruiken.
Laten we eens kijken naar dit specifieke voorbeeld. Stel dat we alle rijen moeten uitvoeren die beginnen met...
GEBRUIK AdventureWorks2014GOSET STATISTICS IO ONSELECT AddressLine1FROM Person.[Address]WHERE SUBSTRING(AddressLine1, 1, 3) ='100'SELECT AddressLine1FROM Person.[Address]WHERE LEFT(AddressLine1, 3) ='100'SELECT AddressLine1FROM Person.[ Address]WHERE CAST(AddressLine1 AS CHAR(3)) ='100'SELECT AddressLine1FROM Person.[Address]WHERE AddressLine1 LIKE '100%'
We krijgen de volgende logische metingen en uitvoeringsplannen:
Tabel 'Adres'. Scantelling 1, logische leest 216, ...Tabel 'Adres'. Scantelling 1, logische leest 216, ...Tabel 'Adres'. Scantelling 1, logische leest 216, ...Tabel 'Adres'. Scan telling 1, logische leest 4, ...
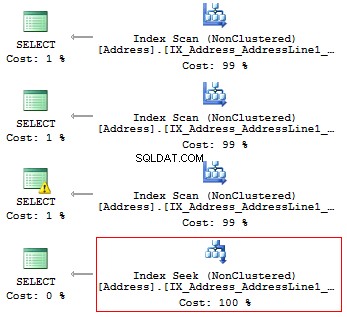
Dus als er een index is, mag deze geen berekeningen of conversies van typen, functies, enz. bevatten.
Maar wat doe je als je het voorkomen van een subtekenreeks in een tekenreeks moet vinden?
SELECT AddressLine1FROM Person.[Address]WHERE AddressLine1 LIKE '%100%'v
We komen later op deze vraag terug.
Unicode versus ANSI
Het is belangrijk om te onthouden dat er de UNICODE en ANSI snaren. Het UNICODE-type omvat NVARCHAR/NCHAR (2 bytes tot één symbool). ANSI opslaan strings, is het mogelijk om VARCHAR/CHAR . te gebruiken (1 byte naar 1 symbool). Er is ook TEXT/NTEXT , maar ik raad het gebruik ervan niet aan, omdat ze de prestaties kunnen verminderen.
Als u een Unicode-constante in een query opgeeft, moet u deze vooraf laten gaan door het N-symbool. Voer de volgende vraag uit om het te controleren:
SELECTEER '文本 ANSI' , N'文本 UNICODE'------- ------------?? ANSI 文本 UNICODE
Als N niet voorafgaat aan de constante, zal SQL Server proberen een geschikt symbool te vinden in de ANSI-codering. Als het niet kan worden gevonden, wordt er een vraagteken weergegeven.
VERZAMELEN
Heel vaak stelt een interviewer, wanneer hij wordt geïnterviewd voor de functie Middle/Senior DB Developer, vaak de volgende vraag:Levert deze zoekopdracht de gegevens op?
DECLARE @a NCHAR(1) ='Ё' , @b NCHAR(1) ='Ф'SELECT @a, @bWHERE @a =@b
Het hangt er van af. Ten eerste gaat het N-symbool niet vooraf aan een stringconstante en wordt het dus geïnterpreteerd als ANSI. Ten tweede hangt er veel af van de huidige COLLATE-waarde, een set regels, bij het selecteren en vergelijken van stringgegevens.
GEBRUIK [master]GOIF DB_ID('test') IS NIET NULL BEGIN ALTER DATABASE test SET SINGLE_USER WITH ROLLBACK ONMIDDELLIJKE DATABASE testENDGOCREATE DATABASE test COLLATE Latin1_General_100_CI_ASGOUSE testGODECLARE @a NCHAR(1) ='Ё' CHAR ) ='Ф'SELECT @a, @bWHERE @a =@b Deze COLLATE-instructie retourneert vraagtekens omdat hun symbolen gelijk zijn:
---- ----? ?
Als we de COLLATE-instructie voor een andere verklaring wijzigen:
ALTER DATABASE-test COLLATE Cyrillic_General_100_CI_AS
In dit geval levert de zoekopdracht niets op, omdat Cyrillische tekens correct worden geïnterpreteerd.
Daarom, als een stringconstante UNICODE inneemt, is het noodzakelijk om N in te stellen voorafgaand aan een stringconstante. Toch zou ik het niet aanraden om het overal in te stellen om de redenen die we hierboven hebben besproken.
Een andere vraag die tijdens het interview moet worden gesteld, heeft betrekking op het vergelijken van rijen.
Beschouw het volgende voorbeeld:
DECLARE @a VARCHAR(10) ='TEXT' , @b VARCHAR(10) ='text'SELECT IIF(@a =@b, 'TRUE', 'FALSE')
Zijn deze rijen gelijk? Om dit te controleren, moeten we COLLATE expliciet specificeren:
DECLARE @a VARCHAR(10) ='TEXT' , @b VARCHAR(10) ='text'SELECT IIF(@a COLLATE Latin1_General_CS_AS =@b COLLATE Latin1_General_CS_AS, 'TRUE', 'FALSE')
Omdat er hoofdlettergevoelige (CS) en hoofdletterongevoelige (CI) COLLATE's zijn bij het vergelijken en selecteren van rijen, kunnen we niet met zekerheid zeggen of ze gelijk zijn. Daarnaast zijn er verschillende VERZAMELINGEN zowel aan een testserver als aan een clientzijde.
Er is een geval waarin COLLATEs van een doelbasis en tempdb komen niet overeen.
Maak een database met COLLATE:
GEBRUIK [master]GOIF DB_ID('test') IS NIET NULL BEGIN WIJZIG DATABASE-test SET SINGLE_USER WITH ROLLBACK ONMIDDELLIJKE DROP DATABASE-testENDGOCREATE DATABASE-test COLLATE Albanees_100_CS_ASGOUSE testGOCREATE TABLE t (c TO CHAR(1) INSERT) ')GOIF OBJECT_ID('tempdb.dbo.#t1') IS GEEN NULL DROP TABLE #t1IF OBJECT_ID('tempdb.dbo.#t2') IS GEEN NULL DROP TABLE #t2IF OBJECT_ID('tempdb.dbo.#t3') IS GEEN NULL DROP TABLE #t3GOCREATE TABLE #t1 (c CHAR(1))INSERT INTO #t1 VALUES ('a')CREATE TABLE #t2 (c CHAR(1) COLLATE database_default)INSERT INTO #t2 VALUES ('a') SELECT c =CAST('a' AS CHAR(1))INTO #t3DECLARE @t TABLE (c VARCHAR(100))INSERT INTO @t VALUES ('a')SELECT 'tempdb', DATABASEPROPERTYEX('tempdb', 'collatie ')UNION ALLSELECT 'test', DATABASEPROPERTYEX(DB_NAME(), 'collation')UNION ALLSELECT 't', SQL_VARIANT_PROPERTY(c, 'collation') FROM tUNION ALLSELECT '#t1', SQL_VARIANT_PROPERTY(c, 'collation') FROM # t1UNION ALLSELECT '#t2', SQL_VARIANT_PROPERTY(c, 'sortering') FROM # t2UNION ALLSELECT '#t3', SQL_VARIANT_PROPERTY(c, 'sorteren') FROM #t3UNION ALLSELECT '@t', SQL_VARIANT_PROPERTY(c, 'sorteren') VAN @t Bij het maken van een tabel neemt deze COLLATE over van een database. Het enige verschil voor de eerste tijdelijke tabel, waarvoor we expliciet een structuur bepalen zonder COLLATE, is dat deze COLLATE erft van de tempdb database.
------ --------------------------tempdb Cyrillic_General_CI_AStest Albanees_100_CS_ASt Albanees_100_CS_AS#t1 Cyrillisch_General_CI_AS#t2 Albanees_100_CS_AS#t3 Albanees@t_100_CS Albanees_100_CS_AS
Ik zal het geval beschrijven waarin VERZAMELINGEN niet overeenkomen met het specifieke voorbeeld met #t1.
Gegevens worden bijvoorbeeld niet correct uitgefilterd, omdat COLLATE mogelijk geen rekening houdt met een zaak:
SELECTEER *FROM #t1WHERE c ='A'
Als alternatief kunnen we een conflict hebben om tabellen met verschillende COLLATEs te verbinden:
SELECTEER *FROM #t1JOIN t ON [#t1].c =t.c
Alles lijkt perfect te werken op een testserver, terwijl we op een clientserver een foutmelding krijgen:
Msg 468, Level 16, State 9, Line 93Kan het sorteerconflict tussen "Albanian_100_CS_AS" en "Cyrillic_General_CI_AS" niet oplossen in de gelijk aan bewerking.
Om dit te omzeilen, moeten we overal hacks instellen:
SELECT *FROM #t1JOIN t ON [#t1].c =t.c COLLATE database_default
BINAIRE SAMENSTELLING
Nu gaan we ontdekken hoe u COLLATE in uw voordeel kunt gebruiken.
Beschouw het voorbeeld met het voorkomen van een subtekenreeks in een tekenreeks:
SELECTEER AddressLine1FROM Person.[Address]WHERE AddressLine1 LIKE '%100%'
Het is mogelijk om deze zoekopdracht te optimaliseren en de uitvoeringstijd te verkorten.
Eerst moeten we een grote tabel genereren:
GEBRUIK [master]GOIF DB_ID('test') IS NIET NULL BEGIN WIJZIG DATABASE-test SET SINGLE_USER WITH ROLLBACK ONMIDDELLIJKE DATABASE-test DROPENDGOCREATE DATABASE-test COLLATE Latin1_General_100_CS_ASGOALTER DATABASE-test MODIFY N' FILE =' 64 DATABASE test BESTAND WIJZIGEN (NAME =N'test_log', SIZE =64MB)GOUSE testGOCREATE TABLE t ( ansi VARCHAR(100) NOT NULL , unicod NVARCHAR(100) NOT NULL)GO;MET E1(N) AS ( SELECT * FROM ( WAARDEN (1),(1),(1),(1),(1), (1),(1),(1),(1),(1) ) t(N) ), E2(N ) AS (SELECTEER 1 VAN E1 a, E1 b), E4(N) AS (SELECTEER 1 VAN E2 a, E2 b), E8(N) AS (SELECTEER 1 VAN E4 a, E4 b)PLAATS IN tSELECT v, vFROM ( SELECTEER TOP(50000) v =REPLACE(CAST(NEWID() AS VARCHAR(36)) + CAST(NEWID() AS VARCHAR(36)), '-', '') FROM E8) t Maak berekende kolommen met binaire COLLATE's en indexen:
ALTER TABLE t ADD ansi_bin AS UPPER(ansi) COLLATE Latin1_General_100_Bin2ALTER TABLE t ADD unicod_bin AS UPPER(unicod) COLLATE Latin1_General_100_BIN2CREATE NONCLUSTERED INDEX ansi ON t (ansi)CREATE ON INDEX ansi_bin)MAAK NIET-GECLUSTERDE INDEX unicod_bin ON t (unicod_bin)
Voer het filtratieproces uit:
STEL STATISTIEKEN TIJD IN, IO ONSELECT COUNT_BIG(*)FROM tWHERE ansi LIKE '%AB%'SELECT COUNT_BIG(*)FROM tWHERE unicod LIKE '%AB%'SELECT COUNT_BIG(*)FROM tWHERE ansi_bin LIKE '%AB%' --COLLATE Latin1_General_100_BIN2SELECT COUNT_BIG(*)FROM tWHERE unicod_bin LIKE '%AB%' --COLLATE Latin1_General_100_BIN2SET STATISTIEKEN TIJD, IO UIT
Zoals u kunt zien, geeft deze zoekopdracht het volgende resultaat:
SQL Server Uitvoeringstijden:CPU-tijd =350 ms, verstreken tijd =354 ms.SQL Server Uitvoeringstijden:CPU-tijd =335 ms, verstreken tijd =355 ms.SQL Server Uitvoeringstijden:CPU-tijd =16 ms, verstreken tijd =18 ms. Uitvoeringstijden SQL-server:CPU-tijd =17 ms, verstreken tijd =18 ms.
Het punt is dat filteren op basis van de binaire vergelijking minder tijd kost. Dus als u het voorkomen van strings vaak en snel moet filteren, is het mogelijk om gegevens op te slaan met COLLATE eindigend op BIN. Houd er echter rekening mee dat alle binaire COLLATE's hoofdlettergevoelig zijn.
Codestijl
Een stijl van coderen is strikt individueel. Toch moet deze code gewoon door andere ontwikkelaars worden onderhouden en aan bepaalde regels voldoen.
Maak een aparte database en een tabel erin:
GEBRUIK [master]GOIF DB_ID('test') IS NIET NULL BEGIN WIJZIG DATABASE-test SET SINGLE_USER WITH ROLLBACK ONMIDDELLIJKE DROP DATABASE-testENDGOCREATE DATABASE-test COLLATE Latin1_General_CI_ASGOUSE testGOCREATE TABEL dbo.EmployeeID (preEmployeeID)
Schrijf vervolgens de vraag:
selecteer werknemer-ID van werknemer
Verander nu COLLATE in een hoofdlettergevoelige:
ALTER DATABASE-test COLLATE Latin1_General_CS_AI
Probeer vervolgens de query opnieuw uit te voeren:
Bericht 208, niveau 16, staat 1, regel 19Ongeldige objectnaam 'werknemer'.
Een optimalisatieprogramma gebruikt regels voor de huidige COLLATE bij de bindingsstap wanneer het controleert op tabellen, kolommen en andere objecten en het vergelijkt elk object van de syntaxisboom met een echt object van een systeemcatalogus.
Als u zoekopdrachten handmatig wilt genereren, moet u altijd de juiste hoofdlettergebruik in objectnamen gebruiken.
Wat variabelen betreft, COLLATE's worden overgenomen van de hoofddatabase. Je moet dus ook de juiste case gebruiken om ermee te werken:
SELECT DATABASEPROPERTYEX('master', 'collation')DECLARE @EmpID INT =1SELECT @empid
In dit geval krijgt u geen foutmelding:
-----------------------Cyrillic_General_CI_AS-----------1
Toch kan er een case-fout verschijnen op een andere server:
--------------------------Latin1_General_CS_ASMsg 137, Level 15, State 2, Line 4Moet de scalaire variabele "@empid" declareren.
[var]char
Zoals u weet, zijn er vaste (CHAR , NCHAR ) en variabele (VARCHAR , NVARCHAR ) gegevenstypen:
DECLARE @a CHAR(20) ='text' , @b VARCHAR(20) ='text'SELECT LEN(@a) , LEN(@b) , DATALENGTH(@a) , DATALENGTH(@b) , '"' + @a + '"' , '"' + @b + '"'SELECT [a =b] =IIF(@a =@b, 'TRUE', 'FALSE') , [b =a] =IIF(@b =@a, 'TRUE', 'FALSE') , [a LIKE b] =IIF(@a LIKE @b, 'TRUE', 'FALSE') , [b LIKE a] =IIF(@ b LIKE @a, 'TRUE', 'FALSE')
Als een rij een vaste lengte heeft, zeg 20 symbolen, maar je hebt maar 4 symbolen geschreven, dan voegt SQL Server standaard 16 spaties aan de rechterkant toe:
--- --- ---- ---- ---------------------- ----------- -----------4 4 20 4 "tekst " "tekst"
In addition, it is important to understand that when comparing rows with =, blanks on the right are not taken into account:
a =b b =a a LIKE b b LIKE a----- ----- -------- --------TRUE TRUE TRUE FALSE
As for the LIKE operator, blanks will be always inserted.
SELECT 1WHERE 'a ' LIKE 'a'SELECT 1WHERE 'a' LIKE 'a ' -- !!!SELECT 1WHERE 'a' LIKE 'a'SELECT 1WHERE 'a' LIKE 'a%'
Data length
It is always necessary to specify type length.
Beschouw het volgende voorbeeld:
DECLARE @a DECIMAL , @b VARCHAR(10) ='0.1' , @c SQL_VARIANTSELECT @a =@b , @c =@aSELECT @a , @c , SQL_VARIANT_PROPERTY(@c,'BaseType') , SQL_VARIANT_PROPERTY(@c,'Precision') , SQL_VARIANT_PROPERTY(@c,'Scale')
As you can see, the type length was not specified explicitly. Thus, the query returned an integer instead of a decimal value:
---- ---- ---------- ----- -----0 0 decimal 18 0
As for rows, if you do not specify a row length explicitly, then its length will contain only 1 symbol:
----- ------------------------------------------ ---- ---- ---- ----40 123456789_123456789_123456789_123456789_ 1 1 30 30
In addition, if you do not need to specify a length for CAST/CONVERT, then only 30 symbols will be used.
ISNULL vs COALESCE
There are two functions:ISNULL and COALESCE. On the one hand, everything seems to be simple. If the first operator is NULL, then it will return the second or the next operator, if we talk about COALESCE. On the other hand, there is a difference – what will these functions return?
DECLARE @a CHAR(1) =NULLSELECT ISNULL(@a, 'NULL'), COALESCE(@a, 'NULL')DECLARE @i INT =NULLSELECT ISNULL(@i, 7.1), COALESCE(@i, 7.1)
The answer is not obvious, as the ISNULL function converts to the smallest type of two operands, whereas COALESCE converts to the largest type.
---- ----N NULL---- ----7 7.1
As for performance, ISNULL will process a query faster, COALESCE is split into the CASE WHEN operator.
Math
Math seems to be a trivial thing in SQL Server.
SELECT 1 / 3SELECT 1.0 / 3
Dat is het echter niet. Everything depends on the fact what data is used in a query. If it is an integer, then it returns the integer result.
-----------0-----------0.333333
Also, let’s consider this particular example:
SELECT COUNT(*) , COUNT(1) , COUNT(val) , COUNT(DISTINCT val) , SUM(val) , SUM(DISTINCT val)FROM ( VALUES (1), (2), (2), (NULL), (NULL)) t (val)SELECT AVG(val) , SUM(val) / COUNT(val) , AVG(val * 1.) , AVG(CAST(val AS FLOAT))FROM ( VALUES (1), (2), (2), (NULL), (NULL)) t (val)
This query COUNT(*)/COUNT(1) will return the total amount of rows. COUNT on the column will return the amount of non-NULL rows. If we add DISTINCT, then it will return the amount of non-NULL unique values.
The AVG operation is divided into SUM and COUNT. Thus, when calculating an average value, NULL is not applicable.
UNION vs UNION ALL
When the data is not overridden, then it is better to use UNION ALL to improve performance. In order to avoid replication, you may use UNION.
Still, if there is no replication, it is preferable to use UNION ALL:
SELECT [object_id]FROM sys.system_objectsUNIONSELECT [object_id]FROM sys.objectsSELECT [object_id]FROM sys.system_objectsUNION ALLSELECT [object_id]FROM sys.objects
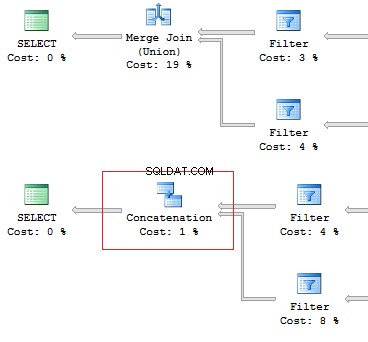
Also, I would like to point out the difference of these operators:the UNION operator is executed in a parallel way, the UNION ALL operator – in a sequential way.
Assume, we need to retrieve 1 row on the following conditions:
DECLARE @AddressLine NVARCHAR(60)SET @AddressLine ='4775 Kentucky Dr.'SELECT TOP(1) AddressIDFROM Person.[Address]WHERE AddressLine1 =@AddressLine OR AddressLine2 =@AddressLine
As we have OR in the statement, we will receive IndexScan:
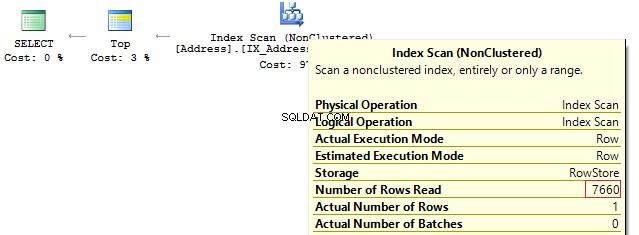
Table 'Address'. Scan count 1, logical reads 90, ...
Now, we will re-write the query using UNION ALL:
SELECT TOP(1) AddressIDFROM ( SELECT TOP(1) AddressID FROM Person.[Address] WHERE AddressLine1 =@AddressLine UNION ALL SELECT TOP(1) AddressID FROM Person.[Address] WHERE AddressLine2 =@AddressLine) t
When the first subquery had been executed, it returned 1 row. Thus, we have received the required result, and SQL Server stopped looking for, using the second subquery:
Tabel 'Werktafel'. Scan count 0, logical reads 0, ...Table 'Address'. Scan count 1, logical reads 3, ...
Re-read
Very often, I faced the situation when the data can be retrieved with one JOIN. In addition, a lot of subqueries are created in this query:
USE AdventureWorks2014GOSET STATISTICS IO ONSELECT e.BusinessEntityID , ( SELECT p.LastName FROM Person.Person p WHERE e.BusinessEntityID =p.BusinessEntityID ) , ( SELECT p.FirstName FROM Person.Person p WHERE e.BusinessEntityID =p.BusinessEntityID )FROM HumanResources.Employee eSELECT e.BusinessEntityID , p.LastName , p.FirstNameFROM HumanResources.Employee eJOIN Person.Person p ON e.BusinessEntityID =p.BusinessEntityID
The fewer there are unnecessary table lookups, the fewer logical readings we have:
Table 'Person'. Scan count 0, logical reads 1776, ...Table 'Employee'. Scan count 1, logical reads 2, ...Table 'Person'. Scan count 0, logical reads 888, ...Table 'Employee'. Scan count 1, logical reads 2, ...
SubQuery
The previous example works only if there is a one-to-one connection between tables.
Assume tables Person.Person and Sales.SalesPersonQuotaHistory were directly connected. Thus, one employee had only one record for a share size.
USE AdventureWorks2014GOSET STATISTICS IO ONSELECT p.BusinessEntityID , ( SELECT s.SalesQuota FROM Sales.SalesPersonQuotaHistory s WHERE s.BusinessEntityID =p.BusinessEntityID )FROM Person.Person p
However, as settings on the client server may differ, this query may lead to the following error:
Msg 512, Level 16, State 1, Line 6Subquery returned more than 1 value. This is not permitted when the subquery follows =, !=, <, <=,>,>=or when the subquery is used as an expression.
It is possible to solve such issues by adding TOP(1) and ORDER BY. Using the TOP operation makes an optimizer force using IndexSeek. The same refers to using OUTER/CROSS APPLY with TOP:
SELECT p.BusinessEntityID , ( SELECT TOP(1) s.SalesQuota FROM Sales.SalesPersonQuotaHistory s WHERE s.BusinessEntityID =p.BusinessEntityID ORDER BY s.QuotaDate DESC )FROM Person.Person pSELECT p.BusinessEntityID , t.SalesQuotaFROM Person.Person pOUTER APPLY ( SELECT TOP(1) s.SalesQuota FROM Sales.SalesPersonQuotaHistory s WHERE s.BusinessEntityID =p.BusinessEntityID ORDER BY s.QuotaDate DESC) t
When executing these queries, we will get the same issue – multiple IndexSeek operators:
Table 'SalesPersonQuotaHistory'. Scan count 19972, logical reads 39944, ...Table 'Person'. Scan count 1, logical reads 67, ...
Re-write this query with a window function:
SELECT p.BusinessEntityID , t.SalesQuotaFROM Person.Person pLEFT JOIN ( SELECT s.BusinessEntityID , s.SalesQuota , RowNum =ROW_NUMBER() OVER (PARTITION BY s.BusinessEntityID ORDER BY s.QuotaDate DESC) FROM Sales.SalesPersonQuotaHistory s) t ON p.BusinessEntityID =t.BusinessEntityID AND t.RowNum =1
We get the following result:
Table 'Person'. Scan count 1, logical reads 67, ...Table 'SalesPersonQuotaHistory'. Scan count 1, logical reads 4, ...
CASE WHEN
Since this operator is used very often, I would like to specify its features. Regardless, how we wrote the CASE WHEN operator:
USE AdventureWorks2014GOSELECT BusinessEntityID , Gender , Gender =CASE Gender WHEN 'M' THEN 'Male' WHEN 'F' THEN 'Female' ELSE 'Unknown' ENDFROM HumanResources.Employee
SQL Server will decompose the statement to the following:
SELECT BusinessEntityID , Gender , Gender =CASE WHEN Gender ='M' THEN 'Male' WHEN Gender ='F' THEN 'Female' ELSE 'Unknown' ENDFROM HumanResources.Employee
Thus, this will lead to the main issue:each condition will be executed in a sequential order until one of them returns TRUE or ELSE.
Consider this issue on a particular example. To do this, we will create a scalar-valued function which will return the right part of a postal code:
IF OBJECT_ID('dbo.GetMailUrl') IS NOT NULL DROP FUNCTION dbo.GetMailUrlGOCREATE FUNCTION dbo.GetMailUrl( @Email NVARCHAR(50))RETURNS NVARCHAR(50)AS BEGIN RETURN SUBSTRING(@Email, CHARINDEX('@', @Email) + 1, LEN(@Email))END
Then, configure SQL Profiler to build SQL events:StmtStarting / SP:StmtCompleted (if you want to do this with XEvents :sp_statement_starting / sp_statement_completed ).
Execute the query:
SELECT TOP(10) EmailAddressID , EmailAddress , CASE dbo.GetMailUrl(EmailAddress) --WHEN 'microsoft.com' THEN 'Microsoft' WHEN 'adventure-works.com' THEN 'AdventureWorks' ENDFROM Person.EmailAddress
The function will be executed for 10 times. Now, delete a comment from the condition:
SELECT TOP(10) EmailAddressID , EmailAddress , CASE dbo.GetMailUrl(EmailAddress) WHEN 'microsoft.com' THEN 'Microsoft' WHEN 'adventure-works.com' THEN 'AdventureWorks' ENDFROM Person.EmailAddress
In this case, the function will be executed for 20 times. The thing is that it is not necessary for a statement to be a must function in CASE. It may be a complicated calculation. As it is possible to decompose CASE, it may lead to multiple calculations of the same operators.
You may avoid it by using subqueries:
SELECT EmailAddressID , EmailAddress , CASE MailUrl WHEN 'microsoft.com' THEN 'Microsoft' WHEN 'adventure-works.com' THEN 'AdventureWorks' ENDFROM ( SELECT TOP(10) EmailAddressID , EmailAddress , MailUrl =dbo.GetMailUrl(EmailAddress) FROM Person.EmailAddress) t
In this case, the function will be executed 10 times.
In addition, we need to avoid replication in the CASE operator:
SELECT DISTINCT CASE WHEN Gender ='M' THEN 'Male' WHEN Gender ='M' THEN '...' WHEN Gender ='M' THEN '......' WHEN Gender ='F' THEN 'Female' WHEN Gender ='F' THEN '...' ELSE 'Unknown' ENDFROM HumanResources.Employee
Though statements in CASE are executed in a sequential order, in some cases, SQL Server may execute this operator with aggregate functions:
DECLARE @i INT =1SELECT CASE WHEN @i =1 THEN 1 ELSE 1/0 ENDGODECLARE @i INT =1SELECT CASE WHEN @i =1 THEN 1 ELSE MIN(1/0) END
Scalar func
It is not recommended to use scalar functions in T-SQL queries.
Beschouw het volgende voorbeeld:
USE AdventureWorks2014GOUPDATE TOP(1) Person.[Address]SET AddressLine2 =AddressLine1GOIF OBJECT_ID('dbo.isEqual') IS NOT NULL DROP FUNCTION dbo.isEqualGOCREATE FUNCTION dbo.isEqual( @val1 NVARCHAR(100), @val2 NVARCHAR(100))RETURNS BITAS BEGIN RETURN CASE WHEN (@val1 IS NULL AND @val2 IS NULL) OR @val1 =@val2 THEN 1 ELSE 0 ENDEND
The queries return the identical data:
SET STATISTICS TIME ONSELECT AddressID, AddressLine1, AddressLine2FROM Person.[Address]WHERE dbo.IsEqual(AddressLine1, AddressLine2) =1SELECT AddressID, AddressLine1, AddressLine2FROM Person.[Address]WHERE (AddressLine1 IS NULL AND AddressLine2 IS NULL) OR AddressLine1 =AddressLine2SELECT AddressID, AddressLine1, AddressLine2FROM Person.[Address]WHERE AddressLine1 =ISNULL(AddressLine2, '')SET STATISTICS TIME OFF
However, as each call of the scalar function is a resource-intensive process, we can monitor this difference:
SQL Server Execution Times:CPU time =63 ms, elapsed time =57 ms.SQL Server Execution Times:CPU time =0 ms, elapsed time =1 ms.SQL Server Execution Times:CPU time =0 ms, elapsed time =1 ms.
In addition, when using a scalar function, it is not possible for SQL Server to build parallel execution plans, which may lead to poor performance in a huge volume of data.
Sometimes scalar functions may have a positive effect. For example, when we have SCHEMABINDING in the statement:
IF OBJECT_ID('dbo.GetPI') IS NOT NULL DROP FUNCTION dbo.GetPIGOCREATE FUNCTION dbo.GetPI ()RETURNS FLOATWITH SCHEMABINDINGAS BEGIN RETURN PI()ENDGOSELECT dbo.GetPI()FROM Sales.Currency
In this case, the function will be considered as deterministic and executed 1 time.
VIEWs
Here I would like to talk about features of views.
Create a test table and view on its base:
IF OBJECT_ID('dbo.tbl', 'U') IS NOT NULL DROP TABLE dbo.tblGOCREATE TABLE dbo.tbl (a INT, b INT)GOINSERT INTO dbo.tbl VALUES (0, 1)GOIF OBJECT_ID('dbo.vw_tbl', 'V') IS NOT NULL DROP VIEW dbo.vw_tblGOCREATE VIEW dbo.vw_tblAS SELECT * FROM dbo.tblGOSELECT * FROM dbo.vw_tbl
As you can see, we get the correct result:
a b----------- -----------0 1
Now, add a new column in the table and retrieve data from the view:
ALTER TABLE dbo.tbl ADD c INT NOT NULL DEFAULT 2GOSELECT * FROM dbo.vw_tbl
We receive the same result:
a b----------- -----------0 1
Thus, we need either to explicitly set columns or recompile a script object to get the correct result:
EXEC sys.sp_refreshview @viewname =N'dbo.vw_tbl'GOSELECT * FROM dbo.vw_tbl
Resultaat:
a b c----------- ----------- -----------0 1 2
When you directly refer to the table, this issue will not take place.
Now, I would like to discuss a situation when all the data is combined in one query as well as wrapped in one view. I will do it on this particular example:
ALTER VIEW HumanResources.vEmployeeAS SELECT e.BusinessEntityID , p.Title , p.FirstName , p.MiddleName , p.LastName , p.Suffix , e.JobTitle , pp.PhoneNumber , pnt.[Name] AS PhoneNumberType , ea.EmailAddress , p.EmailPromotion , a.AddressLine1 , a.AddressLine2 , a.City , sp.[Name] AS StateProvinceName , a.PostalCode , cr.[Name] AS CountryRegionName , p.AdditionalContactInfo FROM HumanResources.Employee e JOIN Person.Person p ON p.BusinessEntityID =e.BusinessEntityID JOIN Person.BusinessEntityAddress bea ON bea.BusinessEntityID =e.BusinessEntityID JOIN Person.[Address] a ON a.AddressID =bea.AddressID JOIN Person.StateProvince sp ON sp.StateProvinceID =a.StateProvinceID JOIN Person.CountryRegion cr ON cr.CountryRegionCode =sp.CountryRegionCode LEFT JOIN Person.PersonPhone pp ON pp.BusinessEntityID =p.BusinessEntityID LEFT JOIN Person.PhoneNumberType pnt ON pp.PhoneNumberTypeID =pnt.PhoneNumberTypeID LEFT JOIN Person.EmailAddress ea ON p.BusinessEntityID =ea.BusinessEntityID
What should you do if you need to get only a part of information? For example, you need to get Fist Name and Last Name of employees:
SELECT BusinessEntityID , FirstName , LastNameFROM HumanResources.vEmployeeSELECT p.BusinessEntityID , p.FirstName , p.LastNameFROM Person.Person pWHERE p.BusinessEntityID IN ( SELECT e.BusinessEntityID FROM HumanResources.Employee e )
Look at the execution plan in the case of using a view:
Table 'EmailAddress'. Scan count 290, logical reads 640, ...Table 'PersonPhone'. Scan count 290, logical reads 636, ...Table 'BusinessEntityAddress'. Scan count 290, logical reads 636, ...Table 'Person'. Scan count 0, logical reads 897, ...Table 'Employee'. Scan count 1, logical reads 2, ...
Now, we will compare it with the query we have written manually:
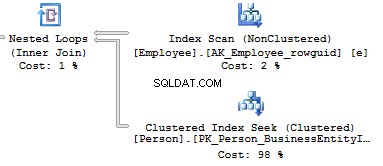
Table 'Person'. Scan count 0, logical reads 897, ...Table 'Employee'. Scan count 1, logical reads 2, ...
When creating an execution plan, an optimizer in SQL Server drops unused connections.
However, sometimes when there is no valid foreign key between tables, it is not possible to check whether a connection will impact the sample result. It may also be applied to the situation when tables are connecteCURSORs
I recommend that you do not use cursors for iteration data modification.
You can see the following code with a cursor:
DECLARE @BusinessEntityID INTDECLARE cur CURSOR FOR SELECT BusinessEntityID FROM HumanResources.EmployeeOPEN curFETCH NEXT FROM cur INTO @BusinessEntityIDWHILE @@FETCH_STATUS =0 BEGIN UPDATE HumanResources.Employee SET VacationHours =0 WHERE BusinessEntityID =@BusinessEntityID FETCH NEXT FROM cur INTO @BusinessEntityIDENDCLOSE curDEALLOCATE cur
Though, it is possible to re-write the code by dropping the cursor:
UPDATE HumanResources.EmployeeSET VacationHours =0WHERE VacationHours <> 0
In this case, it will improve performance and decrease the time to execute a query.
STRING_CONCAT
To concatenate rows, the STRING_CONCAT could be used. However, as there is no such a function in the SQL Server, we will do this by assigning a value to the variable.
To do this, create a test table:
IF OBJECT_ID('tempdb.dbo.#t') IS NOT NULL DROP TABLE #tGOCREATE TABLE #t (i CHAR(1))INSERT INTO #tVALUES ('1'), ('2'), ('3')
Then, assign values to the variable:
DECLARE @txt VARCHAR(50) =''SELECT @txt +=iFROM #tSELECT @txt--------123
Everything seems to be working fine. However, MS hints that this way is not documented and you may get this result:
DECLARE @txt VARCHAR(50) =''SELECT @txt +=iFROM #tORDER BY LEN(i)SELECT @txt--------3
Alternatively, it is a good idea to use XML as a workaround:
SELECT [text()] =iFROM #tFOR XML PATH('')--------123
It should be noted that it is necessary to concatenate rows per each data, rather than into a single set of data:
SELECT [name], STUFF(( SELECT ', ' + c.[name] FROM sys.columns c WHERE c.[object_id] =t.[object_id] FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)'), 1, 2, '')FROM sys.objects tWHERE t.[type] ='U'------------------------ ------------------------------------ScrapReason ScrapReasonID, Name, ModifiedDateShift ShiftID, Name, StartTime, EndTime
In addition, it is recommended that you should avoid using the XML method for parsing as it is a high-runner process:
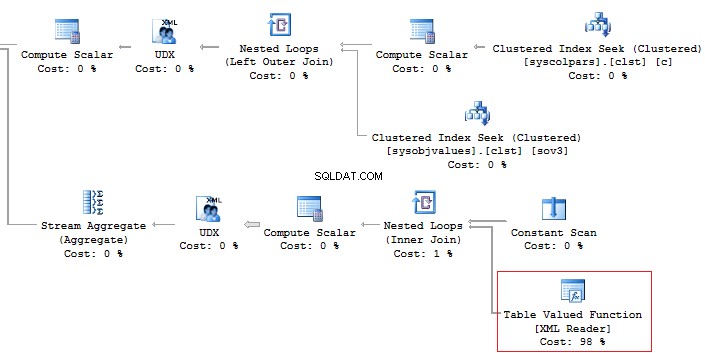
Alternatively, it is possible to do this less time-consuming:
SELECT [name], STUFF(( SELECT ', ' + c.[name] FROM sys.columns c WHERE c.[object_id] =t.[object_id] FOR XML PATH(''), TYPE).value('(./text())[1]', 'NVARCHAR(MAX)'), 1, 2, '')FROM sys.objects tWHERE t.[type] ='U'
But, it does not change the main point.
Now, execute the query without using the value method:
SELECT t.name , STUFF(( SELECT ', ' + c.name FROM sys.columns c WHERE c.[object_id] =t.[object_id] FOR XML PATH('')), 1, 2, '')FROM sys.objects tWHERE t.[type] ='U'
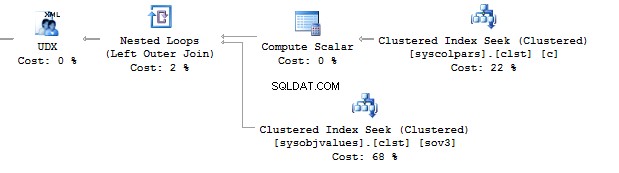
This option would work perfect. However, it may fail. If you want to check it, execute the following query:
SELECT t.name , STUFF(( SELECT ', ' + CHAR(13) + c.name FROM sys.columns c WHERE c.[object_id] =t.[object_id] FOR XML PATH('')), 1, 2, '')FROM sys.objects tWHERE t.[type] ='U'
If there are special symbols in rows, such as tabulation, line break, etc., then we will get incorrect results.
Thus, if there are no special symbols, you can create a query without the value method, otherwise, use value(‘(./text())[1]’… .
SQL Injection
Assume we have a code:
DECLARE @param VARCHAR(MAX)SET @param =1DECLARE @SQL NVARCHAR(MAX)SET @SQL ='SELECT TOP(5) name FROM sys.objects WHERE schema_id =' + @paramPRINT @SQLEXEC (@SQL)
Create the query:
SELECT TOP(5) name FROM sys.objects WHERE schema_id =1
If we add any additional value to the property,
SET @param ='1; select ''hack'''
Then our query will be changed to the following construction:
SELECT TOP(5) name FROM sys.objects WHERE schema_id =1; select 'hack'
This is called SQL injection when it is possible to execute a query with any additional information.
If the query is formed with String.Format (or manually) in the code, then you may get SQL injection:
using (SqlConnection conn =new SqlConnection()){ conn.ConnectionString =@"Server=.;Database=AdventureWorks2014;Trusted_Connection=true"; conn.Open(); SqlCommand command =new SqlCommand( string.Format("SELECT TOP(5) name FROM sys.objects WHERE schema_id ={0}", value), conn); using (SqlDataReader reader =command.ExecuteReader()) { while (reader.Read()) {} }}
When you use sp_executesql and properties as shown in this code:
DECLARE @param VARCHAR(MAX)SET @param ='1; select ''hack'''DECLARE @SQL NVARCHAR(MAX)SET @SQL ='SELECT TOP(5) name FROM sys.objects WHERE schema_id =@schema_id'PRINT @SQLEXEC sys.sp_executesql @SQL , N'@schema_id INT' , @schema_id =@param
It is not possible to add some information to the property.
In the code, you may see the following interpretation of the code:
using (SqlConnection conn =new SqlConnection()){ conn.ConnectionString =@"Server=.;Database=AdventureWorks2014;Trusted_Connection=true"; conn.Open(); SqlCommand command =new SqlCommand( "SELECT TOP(5) name FROM sys.objects WHERE schema_id =@schema_id", conn); command.Parameters.Add(new SqlParameter("schema_id", value)); ...} Samenvatting
Working with databases is not as simple as it may seem. There are a lot of points you should keep in mind when writing T-SQL queries.
Of course, it is not the whole list of pitfalls when working with SQL Server. Still, I hope that this article will be useful for newbies.