SQL Server biedt ons een aantal vensterfuncties die ons helpen om berekeningen over een reeks rijen uit te voeren, zonder de noodzaak om de aanroepen naar de database te herhalen. In tegenstelling tot de standaard aggregatiefuncties, groeperen de vensterfuncties de rijen niet in een enkele uitvoerrij, maar retourneren ze een enkele geaggregeerde waarde voor elke rij, waarbij de afzonderlijke identiteiten voor die rijen behouden blijven. De term Window is hier niet gerelateerd aan het Microsoft Windows-besturingssysteem, het beschrijft de reeks rijen die de functie zal verwerken.
Een van de handigste typen vensterfuncties is Rangschikkingsvensterfuncties die worden gebruikt om specifieke veldwaarden te rangschikken en deze te categoriseren volgens de rangorde van elke rij, wat resulteert in een enkele geaggregeerde waarde voor elke deelnemende rij. Er worden vier rangschikkingsvensterfuncties ondersteund in SQL Server; ROW_NUMBER(), RANK(), DENSE_RANK() en NTILE(). Al deze functies worden gebruikt om op hun eigen manier ROWID te berekenen voor het gegeven rijenvenster.
Vier rangschikkingsvensterfuncties gebruiken de OVER()-clausule die een door de gebruiker opgegeven reeks rijen definieert binnen een reeks met queryresultaten. Door de clausule OVER() te definiëren, kunt u ook de clausule PARTITION BY opnemen die de reeks rijen bepaalt die de vensterfunctie zal verwerken, door kolommen of door komma's gescheiden kolommen op te geven om de partitie te definiëren. Bovendien kan de ORDER BY-component worden opgenomen, die de sorteercriteria binnen de partities definieert die de functie tijdens de verwerking door de rijen zal gaan.
In dit artikel bespreken we hoe je vier rangschikkingsvensterfuncties kunt gebruiken:ROW_NUMBER(), RANK(), DENSE_RANK() en NTILE() in de praktijk, en het verschil daartussen.
Om onze demo te dienen, zullen we een nieuwe eenvoudige tabel maken en enkele records in de tabel invoegen met behulp van het onderstaande T-SQL-script:
CREATE TABLE StudentScore
(
Student_ID INT PRIMARY KEY,
Student_Name NVARCHAR (50),
Student_Score INT
)
GO
INSERT INTO StudentScore VALUES (1,'Ali', 978)
INSERT INTO StudentScore VALUES (2,'Zaid', 770)
INSERT INTO StudentScore VALUES (3,'Mohd', 1140)
INSERT INTO StudentScore VALUES (4,'Jack', 770)
INSERT INTO StudentScore VALUES (5,'John', 1240)
INSERT INTO StudentScore VALUES (6,'Mike', 1140)
INSERT INTO StudentScore VALUES (7,'Goerge', 885)
U kunt controleren of de gegevens met succes zijn ingevoegd met behulp van de volgende SELECT-instructie:
SELECT * FROM StudentScore ORDER BY Student_ScoreAls het gesorteerde resultaat is toegepast, ziet de resultaatset er als volgt uit:

ROW_NUMBER()
De ROW_NUMBER() rangschikkingsvensterfunctie retourneert een uniek volgnummer voor elke rij binnen de partitie van het opgegeven venster, beginnend bij 1 voor de eerste rij in elke partitie en zonder herhalingen of overslaan van nummers in het rangschikkingsresultaat van elke partitie. Als er dubbele waarden in de rijenset zijn, worden de rangorde-ID-nummers willekeurig toegewezen. Als de clausule PARTITION BY is opgegeven, wordt het rangschikkingsrijnummer voor elke partitie opnieuw ingesteld. In de eerder gemaakte tabel laat de onderstaande query zien hoe u de ROW_NUMBER rangschikkingsvensterfunctie kunt gebruiken om de StudentScore-tabelrijen te rangschikken volgens de score van elke student:
SELECT *, ROW_NUMBER() OVER( ORDER BY Student_Score) AS RowNumberRank
FROM StudentScore
Het is duidelijk uit de onderstaande resultatenset dat de ROW_NUMBER-vensterfunctie de tabelrijen rangschikt volgens de Student_Score-kolomwaarden voor elke rij, door een uniek nummer van elke rij te genereren dat de Student_Score-rangschikking weerspiegelt, beginnend bij nummer 1 zonder duplicaten of hiaten en alle rijen als één partitie behandelen. Je kunt ook zien dat de dubbele scores willekeurig aan verschillende rangen worden toegewezen:
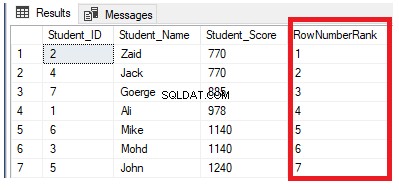
Als we de vorige query wijzigen door de clausule PARTITION BY op te nemen om meer dan één partitie te hebben, zoals weergegeven in de T-SQL-query hieronder:
SELECT *, ROW_NUMBER() OVER(PARTITION BY Student_Score ORDER BY Student_Score) AS RowNumberRank
FROM StudentScore
Het resultaat zal laten zien dat de ROW_NUMBER vensterfunctie de tabelrijen rangschikt volgens de Student_Score kolomwaarden voor elke rij, maar het zal de rijen behandelen die dezelfde Student_Score waarde hebben als één partitie. Je zult zien dat voor elke rij een uniek nummer wordt gegenereerd dat de Student_Score-rangschikking weerspiegelt, beginnend bij nummer 1 zonder duplicaten of gaten binnen dezelfde partitie, waarbij het rangnummer opnieuw wordt ingesteld wanneer naar een andere Student_Score-waarde wordt gegaan.
De studenten met score 770 worden bijvoorbeeld binnen die score gerangschikt door er een rangnummer aan toe te kennen. Wanneer het echter wordt verplaatst naar de student met score 885, wordt het startnummer van de rang opnieuw ingesteld om opnieuw te beginnen bij 1, zoals hieronder weergegeven:
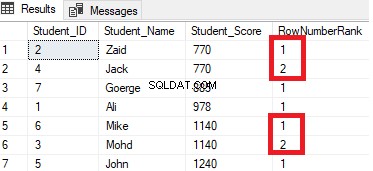
RANK()
De rangschikkingsvensterfunctie RANK() retourneert een uniek rangnummer voor elke afzonderlijke rij binnen de partitie volgens een opgegeven kolomwaarde, beginnend bij 1 voor de eerste rij in elke partitie, met dezelfde rangorde voor dubbele waarden en laat gaten tussen de rangschikkingen; deze opening verschijnt in de reeks na de dubbele waarden. Met andere woorden, de functie van het rangschikkingsvenster RANK() gedraagt zich als de functie ROW_NUMBER() behalve de rijen met gelijke waarden, waar het zal rangschikken met dezelfde rangorde-ID en een hiaat erna genereert. Als we de vorige rangschikkingsquery wijzigen om de rangschikkingsfunctie RANK() te gebruiken:
SELECT *, RANK () OVER( ORDER BY Student_Score) AS RankRank
FROM StudentScoreU zult aan het resultaat zien dat de RANK-vensterfunctie de tabelrijen rangschikt volgens de Student_Score-kolomwaarden voor elke rij, met een rangordewaarde die de Student_Score weerspiegelt vanaf het nummer 1, en de rijen met dezelfde Student_Score rangschikt met de dezelfde rangwaarde. Je kunt ook zien dat twee rijen met Student_Score gelijk aan 770 met dezelfde waarde worden gerangschikt, waardoor er een gat overblijft, het gemiste nummer 2, na de tweede rij. Hetzelfde gebeurt met de rijen waar Student_Score gelijk is aan 1140 die gerangschikt zijn met dezelfde waarde, waardoor er een gat overblijft, het ontbrekende getal 6, na de tweede rij, zoals hieronder weergegeven:
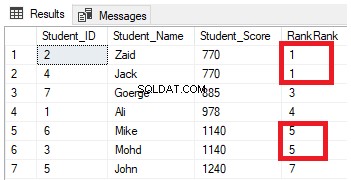
De vorige query wijzigen door de clausule PARTITION BY op te nemen om meer dan één partitie te hebben, zoals weergegeven in de onderstaande T-SQL-query:
SELECT *, RANK() OVER(PARTITION BY Student_Score ORDER BY Student_Score) AS RowNumberRank
FROM StudentScoreHet resultaat van de rangschikking heeft geen betekenis, omdat de rangschikking wordt bepaald op basis van Student_Score-waarden per partitie, en de gegevens worden gepartitioneerd volgens de Student_Score-waarden. En vanwege het feit dat elke partitie rijen heeft met dezelfde Student_Score-waarden, worden de rijen met dezelfde Student_Score-waarden in dezelfde partitie gerangschikt met een waarde gelijk aan 1. Dus wanneer u naar de tweede partitie gaat, zal de rangorde worden gereset, opnieuw beginnend met het nummer 1, waarbij alle rangordewaarden gelijk zijn aan 1 zoals hieronder weergegeven:
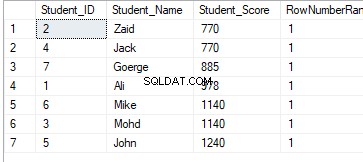
DENSE_RANK()
De rangschikkingsvensterfunctie DENSE_RANK() is vergelijkbaar met de functie RANK() door een uniek rangnummer te genereren voor elke afzonderlijke rij binnen de partitie volgens een gespecificeerde kolomwaarde, beginnend bij 1 voor de eerste rij in elke partitie, waarbij de rijen worden gerangschikt met gelijke waarden met hetzelfde rangnummer, behalve dat het geen rang overslaat, waardoor er geen gaten tussen de ranglijsten ontstaan.
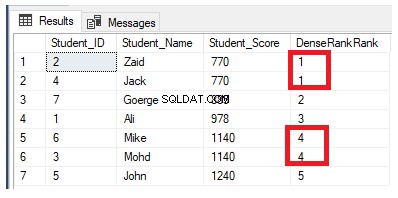
Als we de vorige rangschikkingsquery herschrijven om de DENSE_RANK() rangschikkingsfunctie te gebruiken:
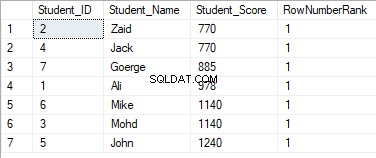
Wijzig opnieuw de vorige query door de clausule PARTITION BY op te nemen om meer dan één partitie te hebben, zoals weergegeven in de onderstaande T-SQL-query:
SELECT *, DENSE_RANK() OVER(PARTITION BY Student_Score ORDER BY Student_Score) AS RowNumberRank
FROM StudentScore
De rangordewaarden hebben geen betekenis, waarbij alle rijen worden gerangschikt met de waarde 1, vanwege het toewijzen van de dubbele waarden aan dezelfde rangschikkingswaarde en het opnieuw instellen van de rangstart-id bij het verwerken van een nieuwe partitie, zoals hieronder weergegeven:
NTILE(N)
De NTILE(N)-rangschikkingsvensterfunctie wordt gebruikt om de rijen in de rijenset in een bepaald aantal groepen te verdelen, waarbij elke rij in de rijenset een uniek groepsnummer krijgt, te beginnen met het nummer 1 dat de groep aangeeft waartoe deze rij behoort to, waarbij N een positief getal is, dat het aantal groepen definieert waarin je de rijen moet verdelen.
Met andere woorden, als u specifieke gegevensrijen van de tabel in 3 groepen moet verdelen, gebaseerd op bepaalde kolomwaarden, zal de NTILE(3) rangschikkingsvensterfunctie u helpen om dit gemakkelijk te bereiken.
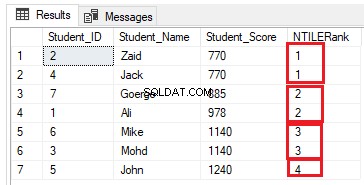
Het aantal rijen in elke groep kan worden berekend door het aantal rijen te delen in het vereiste aantal groepen. Als we de vorige rangschikkingsquery wijzigen om de NTILE(4) rangschikkingsvensterfunctie te gebruiken om zeven tabelrijen in vier groepen te rangschikken zoals de T-SQL-query hieronder:
SELECT *, NTILE(4) OVER( ORDER BY Student_Score) AS NTILERank
FROM StudentScore
Het aantal rijen moet (7/4=1,75) rijen in elke groep zijn. Met behulp van de functie NTILE() wijst SQL Server Engine 2 rijen toe aan de eerste drie groepen en één rij aan de laatste groep, zodat alle rijen in de groepen worden opgenomen, zoals weergegeven in de onderstaande resultatenset:
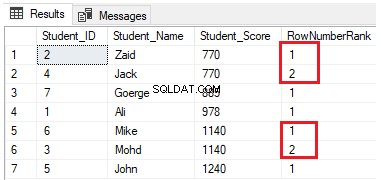
De vorige query wijzigen door de clausule PARTITION BY op te nemen om meer dan één partitie te hebben, zoals weergegeven in de onderstaande T-SQL-query:
SELECT *, NTILE(4) OVER(PARTITION BY Student_Score ORDER BY Student_Score) AS RowNumberRank
FROM StudentScoreDe rijen worden verdeeld in vier groepen op elke partitie. De eerste twee rijen met Student_Score gelijk aan 770 bevinden zich bijvoorbeeld in dezelfde partitie en worden verdeeld binnen de groepen die elk een uniek nummer hebben, zoals weergegeven in de onderstaande resultatenset:
Alles samenvoegen
Laten we voor een duidelijker vergelijkingsscenario de vorige tabel afkappen, een ander classificatiecriterium toevoegen, namelijk de klas van de studenten, en tenslotte nieuwe zeven rijen invoegen met behulp van het onderstaande T-SQL-script:
TRUNCATE TABLE StudentScore
GO
ALTER TABLE StudentScore ADD CLASS CHAR(1)
GO
INSERT INTO StudentScore VALUES (1,'Ali', 978,'A')
INSERT INTO StudentScore VALUES (2,'Zaid', 770,'B')
INSERT INTO StudentScore VALUES (3,'Mohd', 1140,'A')
INSERT INTO StudentScore VALUES (4,'Jack', 879,'B')
INSERT INTO StudentScore VALUES (5,'John', 1240,'C')
INSERT INTO StudentScore VALUES (6,'Mike', 1100,'B')
INSERT INTO StudentScore VALUES (7,'Goerge', 885,'C')Daarna zullen we zeven rijen rangschikken op basis van de score van elke student, waarbij we de studenten indelen op basis van hun klasse. Met andere woorden, elke partitie bevat één klas en elke klas van studenten wordt gerangschikt op basis van hun scores binnen dezelfde klas, met behulp van vier eerder beschreven rangschikkingsvensterfuncties, zoals weergegeven in het T-SQL-script hieronder:
SELECT *, ROW_NUMBER() OVER(PARTITION BY CLASS ORDER BY Student_Score) AS RowNumberRank,
RANK () OVER(PARTITION BY CLASS ORDER BY Student_Score) AS RankRank,
DENSE_RANK () OVER(PARTITION BY CLASS ORDER BY Student_Score) AS DenseRankRank,
NTILE(7) OVER(PARTITION BY CLASS ORDER BY Student_Score) AS NTILERank
FROM StudentScore
GOOmdat er geen dubbele waarden zijn, werken vier rangschikkingsvensterfuncties op dezelfde manier, met hetzelfde resultaat, zoals weergegeven in de onderstaande resultatenset:
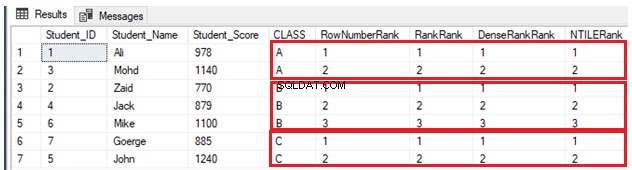
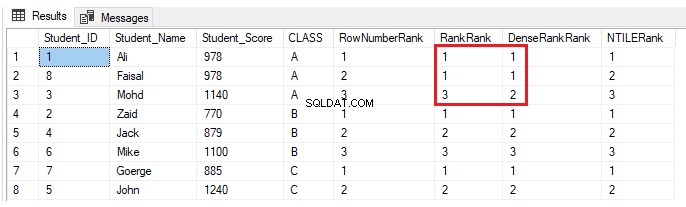
Als een andere leerling is opgenomen in klas A met een score die een andere leerling in dezelfde klas al heeft, gebruik dan de onderstaande INSERT-verklaring:
INSERT INTO StudentScore VALUES (8,'Faisal', 978,'A')Er verandert niets voor de ROW_NUMBER() en NTILE() rangschikkingsvensterfuncties. De RANK- en DENSE_RANK()-functies zullen dezelfde rangorde toewijzen aan de studenten met dezelfde score, met een gat in de rangen na de dubbele rangen bij gebruik van de RANK-functie en geen hiaat in de rangen na de dubbele rangen bij gebruik van de DENSE_RANK( ), zoals weergegeven in het onderstaande resultaat:
Praktisch scenario
De functies van het rangschikkingsvenster worden veel gebruikt door SQL Server-ontwikkelaars. Een van de gebruikelijke scenario's voor het gebruik van rangschikfuncties, wanneer u specifieke rijen wilt ophalen en andere wilt overslaan, met behulp van de ROW_NUMBER(,) rangschikkingsvensterfunctie binnen een CTE, zoals in het T-SQL-script hieronder dat de studenten retourneert met rangen tussen 2 en 5 en sla de andere over:
WITH ClassRanks AS
(
SELECT *, ROW_NUMBER() OVER( ORDER BY Student_Score) AS RowNumberRank
FROM StudentScore
)
SELECT Student_Name , Student_Score
FROM ClassRanks
WHERE RowNumberRank >= 2 and RowNumberRank <=5
ORDER BY RowNumberRank
Het resultaat zal laten zien dat alleen studenten met rangen tussen 2 en 5 worden geretourneerd:
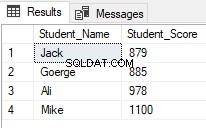
Vanaf SQL Server 2012 is er een nieuw nuttig commando, OFFSET FETCH is geïntroduceerd die kan worden gebruikt om dezelfde vorige taak uit te voeren door specifieke records op te halen en de andere over te slaan, met behulp van het onderstaande T-SQL-script:
WITH ClassRanks AS
(
SELECT *, ROW_NUMBER() OVER( ORDER BY Student_Score) AS RowNumberRank
FROM StudentScore
)
SELECT Student_Name , Student_Score
FROM ClassRanks
ORDER BY
RowNumberRank OFFSET 1 ROWS FETCH NEXT 4 ROWS ONLY;Het ophalen van hetzelfde vorige resultaat zoals hieronder getoond:
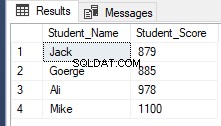
Conclusie
SQL Server biedt ons vier rangschikkingsvensterfuncties die ons helpen de verstrekte rijen te rangschikken volgens specifieke kolomwaarden. Deze functies zijn:ROW_NUMBER(), RANK(), DENSE_RANK() en NTILE(). Al deze classificatiefuncties voeren de classificatietaak op hun eigen manier uit, waarbij hetzelfde resultaat wordt geretourneerd als er geen dubbele waarden in de rijen zijn. Als er een dubbele waarde in de rijenset is, zal de RANK-functie dezelfde rangorde-ID toewijzen aan alle rijen met dezelfde waarde, waardoor er gaten tussen de rangen ontstaan na de duplicaten. De functie DENSE_RANK wijst ook dezelfde rangorde-ID toe aan alle rijen met dezelfde waarde, maar laat geen ruimte tussen de rangschikkingen na de duplicaten. We doorlopen verschillende scenario's in dit artikel om alle mogelijke gevallen te behandelen die u helpen om de functies van het rangschikkingsvenster praktisch te begrijpen.
Referenties:
- ROW_NUMBER (Transact-SQL)
- RANG (Transact-SQL)
- DENSE_RANK (Transact-SQL)
- NTILE (Transact-SQL)
- OFFSET FETCH-clausule (SQL Server Compact)