Er is een regressiebug in SQL Server 2012 en SQL Server 2014 waarbij, als u parallel online een index opnieuw opbouwt, en u ook een fatale fout ervaart, zoals een time-out voor vergrendeling, u gegevensverlies of corruptie . Dit zou een relatief zeldzaam scenario moeten zijn (Phil Brammer heeft een eenvoudige repro in Connect #795134), maar gegevensverlies is gegevensverlies en ik ben niet bereid te gokken. De oplossing wordt beschreven in KB #2969896:FIX:gegevensverlies in geclusterde index treedt op wanneer u online build-index uitvoert in SQL Server 2012.
Niet iedereen hoeft zich zorgen te maken over dit probleem. Als u geen Enterprise (of een gelijkwaardige) editie gebruikt, kunt u in de eerste plaats geen parallelle of online-reconstructies uitvoeren (en er zijn waarschijnlijk mensen op Enterprise die niet of niet online reconstrueren). Als u voor de hele instantie MAXDOP . heeft ingesteld op 1, kunnen ze niet parallel gaan tenzij u het op instructieniveau overschrijft. Maar als u in 2012 of 2014 een adequate editie gebruikt en uw online-reconstructies parallel zouden kunnen gaan, bent u kwetsbaar voor dit probleem.
Zoals ik hierboven al zei, kan dit probleem zich manifesteren in SQL Server 2012 RTM, Service Pack 1 en zelfs Service Pack 2, dat op 10 juni werd uitgebracht. De bug werd pas verholpen lang nadat de SP2-code was vastgelopen, dus SP2 doet dat ook. deze fix of een van de fixes van SP1 CU #10 of #11 niet bevatten. Hier heb ik over geblogd. De RTM-tak wordt officieel niet meer ondersteund, dus je zult daar geen oplossing zien. Het probleem kan ook optreden in SQL Server 2014.
Er zijn nu cumulatieve updates beschikbaar voor SQL Server 2012 Service Pack 1 &2 en voor SQL Server 2014. Een korte samenvatting van de opties die ik aanbeveel:
Als uw branch / @@VERSION is…
| ...je moet... | ||||
|---|---|---|---|---|---|
| |||||
| |||||
| Niets doen; je hebt de oplossing al. | |||||
| |||||
| Niets doen; je hebt de oplossing al. | |||||
| SQL Server 2014 RTM |
| ||||
| Niets doen; je hebt de oplossing al. | |||||
| * Als u de SP1-hotfix of cumulatieve update #11 installeert en vervolgens SP2 installeert, maakt u deze wijzigingen ongedaan, inclusief deze oplossing. | |||||
Oplossingen voor de hotfix/CU aversie
Aangezien alle betrokken branches (nou ja, behalve 2012 RTM) een on-demand hotfix en/of een cumulatieve update hebben die het probleem verhelpt, is het gemakkelijke antwoord om gewoon de relevante update te installeren. U bevindt zich echter mogelijk in een scenario waarin uw bedrijfsbeleid of testcycli ervoor zorgen dat u deze updates niet snel of misschien ooit implementeert. Dus welke andere opties heb je?
- U kunt stoppen met het uitvoeren van rebuilds totdat er een nieuw servicepack beschikbaar is voor uw branch (misschien kunt u gewoon bij
REORGANIZEblijven voor nu). Helaas, als u in een "servicepack only"-bedrijf zit, zijn uw opties zeer beperkt:u kunt harder vechten om dat beleid te veranderen, of u kunt wachten op SQL Server 2012 Service Pack 3 (wat lang kan duren, of kom gewoon nooit - zie FAQ #21 hier) of SQL Server 2014 Service Pack 1 (wat we waarschijnlijk niet zullen zien voordat 2015 rond rolt). - U kunt de instantie-brede
max degree of parallelismop 1, maar dit kan een negatief effect hebben op de rest van uw werklast - denk aan zaken als multi-threaded DBCC, parallelle query's tegen of tussen gepartitioneerde tabellen en andere bewerkingen waarbij u misschien parallellisme wilt verminderen, maar niet helemaal wilt elimineren. Deze instelling heeft ook geen invloed op een online-rebuild met bijvoorbeeld een explicieteMAXDOP = 8hard gecodeerd in de opdracht, omdat dit desp_configure. overschrijft instelling.
- Je kunt de
WITH (MAXDOP = 1). toevoegen optie handmatig toe aan al uw herbouwcommando's. (Opmerking:je hoeft dit niet te doen voor XML-indexen, omdat ze inherent single-threaded draaien, maar ik zou het gewoon toepassen op alle rebuilds voor consistentie en om onnodige voorwaardelijke logica te vermijden.)
- U kunt uw indexonderhoudstaken instellen om als een specifieke login te worden uitgevoerd en vervolgens Resource Governor gebruiken om een Workload Group te maken die de
MAX_DOPvan die login beperkt tot 1, ongeacht wat ze doen. Ik heb hier een voorbeeld van in het witboek van 2008 dat ik schreef met Boris Baryshnikov, Using the Resource Governor, in de sectie getiteld "Beperking van parallellisme voor intensieve achtergrondtaken."
- Als u de indexonderhoudsoplossing van Ola Hallengren gebruikt, kunt u de
@MaxDoptoevoegen parameter voor uw aanroepen naardbo.IndexOptimize:
EXEC dbo.IndexOptimize /* other parameters */ @MaxDop = 1; - Als u SQL Sentry Fragmentation Manager gebruikt, kunt u het niveau van
MAXDOPdicteren te gebruiken onder Instellingen - en u kunt dit bedrijfsbreed doen, per instantie, per database of zelfs per individuele index (in dit geval zou u dit waarschijnlijk per instantie willen instellen, voor alle instanties zonder een beschikbare fix):
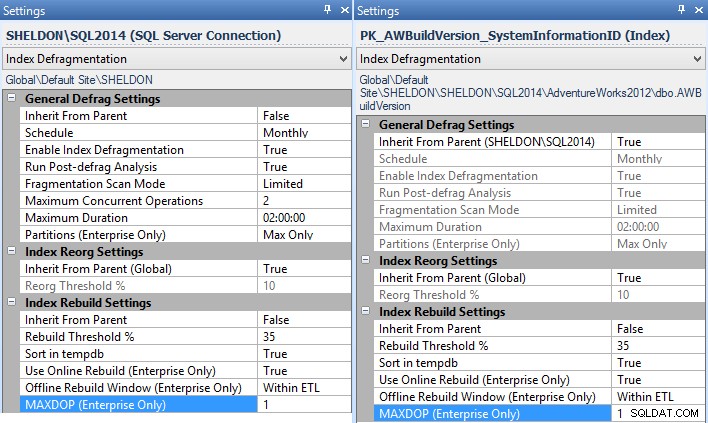
Fragmentation Manager-instellingen voor de instantie (links) en een individuele index (rechts). - Als u onderhoudsplannen gebruikt voor het opnieuw opbouwen van uw index, moet u deze wijzigen om T-SQL-instructietaken uitvoeren te gebruiken en uw
ALTER INDEX ... WITH (ONLINE = ON, MAXDOP = 1);commando's handmatig uit te voeren (je kunt dus net zo goed overschakelen naar een geautomatiseerde oplossing). Kijk, de Index Rebuild Task heeft geen zichtbare eigenschap voorMAXDOP, ook al is er meerdere keren om gevraagd (meest recentelijk in 2012, door Alberto Morillo, en al in 2006 door Linchi Shea). En kijk eens naar al deze andere nuttige eigenschappen die ze blootleggen, zoalsAdvSortInTempdb,ObjectTypeSelection, enTaskAllowesDatbaseSelection[sic!]:
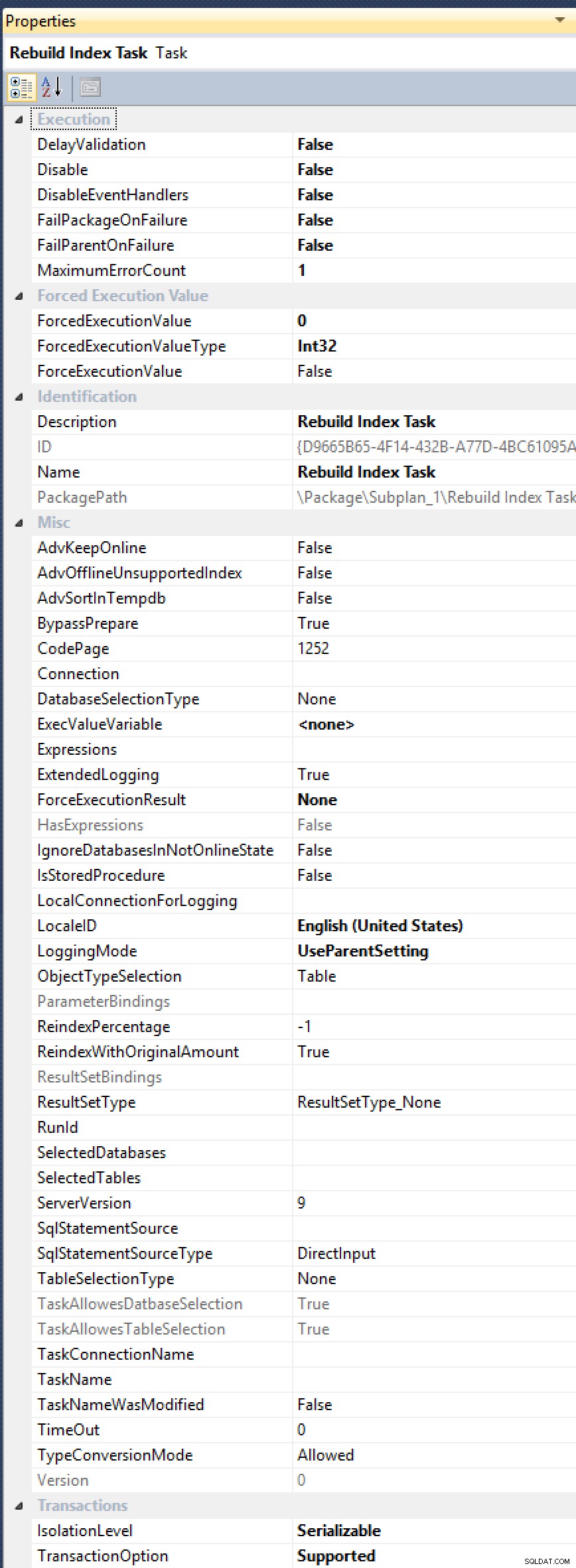
Al die opties, maar nog steeds geen remedie voor MAXDOP.