Vertraagde duurzaamheid is een nieuwe, maar interessante functie in SQL Server 2014; de hoge elevator-pitch van de functie is heel eenvoudig:
- "Verruil duurzaamheid voor prestaties."
Eerst wat achtergrond. Standaard gebruikt SQL Server een write-ahead log (WAL), wat betekent dat wijzigingen naar het logboek worden geschreven voordat ze mogen worden doorgevoerd. In systemen waar het schrijven van transactielogboeken de bottleneck wordt en waar een matige tolerantie voor gegevensverlies is , hebt u nu de mogelijkheid om de vereiste om te wachten op het doorspoelen en bevestigen van het logboek tijdelijk op te schorten. Dit haalt letterlijk de D uit ACID, althans voor een klein deel van de gegevens (hierover later meer).
Je brengt dit offer nu al min of meer. In de volledige herstelmodus is er altijd enig risico op gegevensverlies, het wordt alleen gemeten in termen van tijd in plaats van grootte. Als u bijvoorbeeld elke vijf minuten een back-up van het transactielogboek maakt, kunt u tot iets minder dan 5 minuten aan gegevens verliezen als er iets rampzaligs gebeurt. Ik heb het hier niet over een eenvoudige failover, maar laten we zeggen dat de server letterlijk in brand vliegt of dat iemand over het netsnoer struikelt - de database kan heel goed onherstelbaar zijn en het kan zijn dat u terug moet gaan naar het tijdstip van de laatste logback-up . En in de veronderstelling dat u zelfs uw back-ups test door ze ergens te herstellen - in het geval van een kritieke storing heeft u misschien niet het herstelpunt dat u denkt te hebben. We hebben de neiging om niet aan dit scenario te denken, natuurlijk, omdat we nooit slechte dingen™ verwachten gebeuren.
Hoe het werkt
Door de vertraagde duurzaamheid kunnen schrijftransacties blijven lopen alsof het logboek naar schijf is gewist; in werkelijkheid zijn de schrijfbewerkingen naar schijf gegroepeerd en uitgesteld, om op de achtergrond te worden afgehandeld. De transactie is optimistisch; het gaat ervan uit dat de log-flush zal gebeuren. Het systeem gebruikt een stuk logbuffer van 60 KB en probeert het log naar schijf te spoelen wanneer dit blok van 60 KB vol is (uiterlijk - het kan en zal vaak eerder gebeuren). U kunt deze optie instellen op databaseniveau, op individueel transactieniveau of - in het geval van native gecompileerde procedures in In-Memory OLTP - op procedureniveau. De database-instelling wint in het geval van een conflict; als de database bijvoorbeeld is uitgeschakeld, wordt het proberen om een transactie door te voeren met behulp van de vertraagde optie gewoon genegeerd, zonder foutmelding. Sommige transacties zijn ook altijd volledig duurzaam, ongeacht de database-instellingen of commit-instellingen; bijvoorbeeld systeemtransacties, transacties tussen databases en bewerkingen met betrekking tot FileTable, het bijhouden van wijzigingen, het vastleggen van wijzigingsgegevens en replicatie.
Op databaseniveau kunt u het volgende gebruiken:
ALTER DATABASE dbname SET DELAYED_DURABILITY = DISABLED | ALLOWED | FORCED;
Als je het instelt op ALLOWED , dit betekent dat elke individuele transactie Delayed Durability kan gebruiken; FORCED betekent dat alle transacties die Delayed Durability kunnen gebruiken dat ook zullen doen (de uitzonderingen hierboven zijn in dit geval nog steeds relevant). U zult waarschijnlijk ALLOWED . willen gebruiken in plaats van FORCED – maar dit laatste kan handig zijn in het geval van een bestaande applicatie waar je deze optie overal wilt gebruiken en ook de hoeveelheid code die moet worden aangeraakt minimaliseren. Een belangrijk ding om op te merken over ALLOWED is dat volledig duurzame transacties mogelijk langer moeten wachten, omdat ze de uitgestelde duurzame transacties eerst zullen wissen.
Op transactieniveau kunt u zeggen:
COMMIT TRANSACTION WITH (DELAYED_DURABILITY = ON);
En in een native gecompileerde In-Memory OLTP-procedure kunt u de volgende optie toevoegen aan de BEGIN ATOMIC blok:
BEGIN ATOMIC WITH (DELAYED_DURABILITY = ON, ...)
Een veel voorkomende vraag is wat er gebeurt met semantiek voor vergrendelen en isoleren. Er verandert eigenlijk niets. Vergrendelen en blokkeren gebeurt nog steeds en transacties worden op dezelfde manier en met dezelfde regels uitgevoerd. Het enige verschil is dat, door de commit te laten plaatsvinden zonder te wachten tot het log naar de schijf is leeggemaakt, alle gerelateerde vergrendelingen veel eerder worden vrijgegeven.
Wanneer u het zou moeten gebruiken
Naast het voordeel dat u krijgt door de transacties door te laten gaan zonder te wachten tot het schrijven van de log plaatsvindt, krijgt u ook minder log schrijfbewerkingen van grotere omvang. Dit kan heel goed uitpakken als je systeem een hoog percentage transacties heeft dat in werkelijkheid kleiner is dan 60 KB, en vooral wanneer de logschijf traag is (hoewel ik vergelijkbare voordelen vond op SSD en traditionele HDD). Het werkt niet zo goed als uw transacties voor het grootste deel groter zijn dan 60 KB, als ze doorgaans langlopend zijn, of als u een hoge doorvoer en hoge gelijktijdigheid heeft. Wat hier kan gebeuren, is dat u de volledige logbuffer kunt vullen voordat het doorspoelen is voltooid, wat betekent dat u uw wachttijden naar een andere bron moet overdragen en uiteindelijk de waargenomen prestaties van de gebruikers van de toepassing niet verbetert.
Met andere woorden, als uw transactielogboek momenteel geen knelpunt is, schakel deze functie dan niet in. Hoe kunt u zien of uw transactielogboek momenteel een knelpunt is? De eerste indicator zou hoog zijn WRITELOG wacht, vooral in combinatie met PAGEIOLATCH_** . Paul Randal (@PaulRandal) heeft een geweldige vierdelige serie over het identificeren van transactielogboekproblemen en het configureren voor optimale prestaties:
- Het transactielogboekvet bijsnijden
- Meer transactielogvet bijsnijden
- Problemen met de configuratie van transactielogboeken
- Bewaking van transactielogboeken
Zie ook deze blogpost van Kimberly Tripp (@KimberlyLTripp), 8 stappen naar een betere doorvoer van transactielogboeken en de blogpost van het SQL CAT-team, Diagnose van prestatieproblemen en limieten van transactielogboeken van de Log Manager.
Dit onderzoek kan u tot de conclusie leiden dat vertraagde duurzaamheid het onderzoeken waard is; het mag niet. Het testen van uw werklast is de meest betrouwbare manier om het zeker te weten. Net als veel andere toevoegingen in recente versies van SQL Server (*cough* Hekaton ), is deze functie NIET ontworpen om elke afzonderlijke werklast te verbeteren - en zoals hierboven vermeld, kan het sommige werklasten zelfs verergeren. Zie deze blogpost van Simon Harvey voor een aantal andere vragen die je jezelf moet stellen over je werklast om te bepalen of het haalbaar is om wat duurzaamheid op te offeren om betere prestaties te bereiken.
Potentieel voor gegevensverlies
Ik ga dit verschillende keren noemen, en elke keer dat ik dat doe, zal ik de nadruk leggen op:Je moet tolerant zijn voor gegevensverlies . Onder een goed presterende schijf is het maximale dat u mag verwachten te verliezen bij een catastrofe - of zelfs een geplande en soepele afsluiting - maximaal één volledig blok (60 KB). In het geval dat uw I/O-subsysteem het niet kan bijhouden, is het echter mogelijk dat u zoveel als de volledige logbuffer (~7 MB) verliest.
Ter verduidelijking, uit de documentatie (nadruk van mij):
Voor vertraagde duurzaamheid er is geen verschil tussen een onverwachte afsluiting en een verwachte afsluiting/herstart van SQL Server . Net als catastrofale gebeurtenissen, moet je plannen voor gegevensverlies . Bij een geplande uitschakeling/herstart kunnen sommige transacties die niet naar schijf zijn geschreven eerst op schijf worden opgeslagen, maar u moet dit niet plannen. Plan alsof een shutdown/herstart, gepland of ongepland, de gegevens op dezelfde manier verliest als een catastrofale gebeurtenis.Het is dus erg belangrijk dat u uw risico op gegevensverlies afweegt tegen uw behoefte om prestatieproblemen met transactielogboeken te verminderen. Als u een bank runt of iets dat met geld te maken heeft, kan het voor u veel veiliger en geschikter zijn om uw log naar een snellere schijf te verplaatsen dan om de dobbelstenen te gooien met deze functie. Als u de responstijd in uw Web Gamerz Chat Room-toepassing probeert te verbeteren, is het risico misschien minder groot.
U kunt dit gedrag tot op zekere hoogte beheersen om het risico op gegevensverlies te minimaliseren. U kunt op twee manieren forceren dat alle vertraagde duurzame transacties naar de schijf worden gewist:
- Voer een volledig duurzame transactie uit.
- Bel
sys.sp_flush_loghandmatig.
Dit stelt u in staat om terug te keren naar het beheersen van gegevensverlies in termen van tijd in plaats van grootte; u kunt bijvoorbeeld de spoeling om de 5 seconden plannen. Maar je zult hier je goede plek willen vinden; te vaak doorspoelen kan het voordeel van vertraagde duurzaamheid in de eerste plaats compenseren. Hoe dan ook, u moet nog steeds tolerant zijn voor gegevensverlies , zelfs als het maar
Je zou denken dat CHECKPOINT zou hier kunnen helpen, maar deze operatie garandeert eigenlijk niet dat het logboek naar de schijf wordt gewist.
Interactie met HA/DR
U vraagt zich misschien af hoe Delayed Durablity werkt met HA/DR-functies zoals verzending van logbestanden, replicatie en beschikbaarheidsgroepen. Bij de meeste werkt het ongewijzigd. Logboekverzending en -replicatie zullen de logrecords opnieuw afspelen die zijn gehard, dus daar bestaat hetzelfde potentieel voor gegevensverlies. Met AG's in asynchrone modus wachten we sowieso niet op de secundaire bevestiging, dus het zal zich hetzelfde gedragen als vandaag. Met synchroon kunnen we echter niet vastleggen op de primaire totdat de transactie is vastgelegd en gehard naar het externe logboek. Zelfs in dat scenario kunnen we lokaal enig voordeel hebben door niet te hoeven wachten tot het lokale logboek is geschreven, we moeten nog steeds wachten op de externe activiteit. Dus in dat scenario is er minder voordeel, en mogelijk geen; behalve misschien in het zeldzame scenario waar de primaire logboekschijf erg traag is en de secundaire logboekschijf erg snel. Ik vermoed dat dezelfde voorwaarden gelden voor sync/async mirroring, maar je krijgt van mij geen officiële toezegging over hoe een glanzende nieuwe functie werkt met een verouderde. :-)
Prestatiewaarnemingen
Dit zou hier niet echt een post zijn als ik niet wat feitelijke prestatie-observaties zou laten zien. Ik heb 8 databases opgezet om de effecten van twee verschillende werkbelastingpatronen te testen met de volgende attributen:
- Herstelmodel:eenvoudig versus volledig
- Loglocatie:SSD versus HDD
- Duurzaamheid:vertraagd versus volledig duurzaam
Ik ben echt, echt, echt lui efficiënt over dit soort dingen. Omdat ik wil voorkomen dat dezelfde bewerkingen binnen elke database worden herhaald, heb ik de volgende tabel tijdelijk gemaakt in model :
USE model; GO CREATE TABLE dbo.TheTable ( TheID INT IDENTITY(1,1) PRIMARY KEY, TheDate DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP, RowGuid UNIQUEIDENTIFIER NOT NULL DEFAULT NEWID() );
Vervolgens bouwde ik een reeks dynamische SQL-opdrachten om deze 8 databases te bouwen, in plaats van de databases afzonderlijk te maken en vervolgens te rotzooien met de instellingen:
-- C and D are SSD, G is HDD
DECLARE @sql NVARCHAR(MAX) = N'';
;WITH l AS (SELECT l FROM (VALUES('D'),('G')) AS l(l)),
r AS (SELECT r FROM (VALUES('FULL'),('SIMPLE')) AS r(r)),
d AS (SELECT d FROM (VALUES('FORCED'),('DISABLED')) AS d(d)),
x AS (SELECT l.l, r.r, d.d, n = CONVERT(CHAR(1),ROW_NUMBER() OVER
(ORDER BY d.d DESC, l.l)) FROM l CROSS JOIN r CROSS JOIN d)
SELECT @sql += N'
CREATE DATABASE dd' + n + ' ON '
+ '(name = ''dd' + n + '_data'','
+ ' filename = ''C:\SQLData\dd' + n + '.mdf'', size = 1024MB)
LOG ON (name = ''dd' + n + '_log'','
+ ' filename = ''' + l + ':\SQLLog\dd' + n + '.ldf'', size = 1024MB);
ALTER DATABASE dd' + n + ' SET RECOVERY ' + r + ';
ALTER DATABASE dd' + n + ' SET DELAYED_DURABILITY = ' + d + ';'
FROM x ORDER BY d, l;
PRINT @sql;
-- EXEC sp_executesql @sql;
Voel je vrij om deze code zelf uit te voeren (met de EXEC nog steeds becommentarieerd) om te zien dat dit 4 databases zou creëren met Delayed Durability OFF (twee in VOLLEDIG herstel, twee in EENVOUDIG, een van elk met inloggen op langzame schijf en een van elk met inloggen op SSD). Herhaal dat patroon voor 4 databases met Delayed Durability FORCED - ik deed dit om de code in de test te vereenvoudigen, in plaats van weer te geven wat ik in het echte leven zou doen (waar ik waarschijnlijk sommige transacties als kritiek zou willen behandelen, en sommige als, nou ja, minder dan kritisch).
Voor het controleren van de gezondheid heb ik de volgende query uitgevoerd om ervoor te zorgen dat de databases de juiste matrix met attributen hadden:
SELECT d.name, d.recovery_model_desc, d.delayed_durability_desc, log_disk = CASE WHEN mf.physical_name LIKE N'D%' THEN 'SSD' else 'HDD' END FROM sys.databases AS d INNER JOIN sys.master_files AS mf ON d.database_id = mf.database_id WHERE d.name LIKE N'dd[1-8]' AND mf.[type] = 1; -- log
Resultaten:
| naam | recovery_model | delayed_durability | log_disk |
|---|---|---|---|
| dd1 | VOL | GEDWONGEN | SSD |
| dd2 | EENVOUDIG | GEDWONGEN | SSD |
| dd3 | VOL | GEDWONGEN | HDD |
| dd4 | EENVOUDIG | GEDWONGEN | HDD |
| dd5 | VOL | UITGESCHAKELD | SSD |
| dd6 | EENVOUDIG | UITGESCHAKELD | SSD |
| dd7 | VOL | UITGESCHAKELD | HDD |
| dd8 | EENVOUDIG | UITGESCHAKELD | HDD |
Relevante configuratie van de 8 testdatabases
Ik heb de test ook meerdere keren netjes uitgevoerd om ervoor te zorgen dat een gegevensbestand van 1 GB en een logbestand van 1 GB voldoende zouden zijn om de volledige reeks workloads uit te voeren zonder autogrowth-gebeurtenissen in de vergelijking te introduceren. Als best practice doe ik routinematig mijn best om ervoor te zorgen dat de systemen van klanten voldoende toegewezen ruimte hebben (en de juiste waarschuwingen ingebouwd) zodat er nooit een groeigebeurtenis plaatsvindt op een onverwacht moment. In de echte wereld weet ik dat dit niet altijd gebeurt, maar het is ideaal.
Ik heb het systeem zo ingesteld dat het moet worden gecontroleerd met SQL Sentry - dit zou me in staat stellen om gemakkelijk de meeste prestatiestatistieken te tonen die ik wilde benadrukken. Maar ik heb ook een tijdelijke tabel gemaakt om batchstatistieken op te slaan, inclusief duur en zeer specifieke uitvoer van sys.dm_io_virtual_file_stats:
SELECT test = 1, cycle = 1, start_time = GETDATE(), *
INTO #Metrics
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2) WHERE 1 = 0; Hierdoor zou ik de start- en eindtijd van elke afzonderlijke batch kunnen registreren en delta's in de DMV tussen starttijd en eindtijd kunnen meten (alleen betrouwbaar in dit geval omdat ik weet dat ik de enige gebruiker op het systeem ben).
Veel kleine transacties
De eerste test die ik wilde uitvoeren, waren veel kleine transacties. Voor elke database wilde ik eindigen met 500.000 afzonderlijke batches van elk een enkele insert:
INSERT #Metrics SELECT 1, 1, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2);
GO
INSERT dbo.TheTable DEFAULT VALUES;
GO 500000
INSERT #Metrics SELECT 1, 2, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2);
Denk eraan, ik probeer lui te zijn efficiënt over dit soort dingen. Dus om de code voor alle 8 databases te genereren, heb ik dit uitgevoerd:
;WITH x AS
(
SELECT TOP (8) number FROM master..spt_values
WHERE type = N'P' ORDER BY number
)
SELECT CONVERT(NVARCHAR(MAX), N'') + N'
INSERT #Metrics SELECT 1, 1, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID(''dd' + RTRIM(number+1) + '''), 2);
GO
INSERT dbo.TheTable DEFAULT VALUES;
GO 500000
INSERT #Metrics SELECT 1, 2, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID(''dd' + RTRIM(number+1) + '''), 2);'
FROM x;
Ik deed deze test en keek toen naar de #Metrics tabel met de volgende vraag:
SELECT
[database] = db_name(m1.database_id),
num_writes = m2.num_of_writes - m1.num_of_writes,
write_bytes = m2.num_of_bytes_written - m1.num_of_bytes_written,
bytes_per_write = (m2.num_of_bytes_written - m1.num_of_bytes_written)*1.0
/(m2.num_of_writes - m1.num_of_writes),
io_stall_ms = m2.io_stall_write_ms - m1.io_stall_write_ms,
m1.start_time,
end_time = m2.start_time,
duration = DATEDIFF(SECOND, m1.start_time, m2.start_time)
FROM #Metrics AS m1
INNER JOIN #Metrics AS m2
ON m1.database_id = m2.database_id
WHERE m1.cycle = 1 AND m2.cycle = 2
AND m1.test = 1 AND m2.test = 1; Dit leverde de volgende resultaten op (en ik heb via meerdere tests bevestigd dat de resultaten consistent waren):
| database | schrijft | bytes | bytes/schrijven | io_stall_ms | start_time | eindtijd | duur (seconden) |
|---|---|---|---|---|---|---|---|
| dd1 | 8.068 | 261.894.656 | 32.460,91 | 6.232 | 2014-04-26 17:20:00 | 2014-04-26 17:21:08 | 68 |
| dd2 | 8.072 | 261,682,688 | 32.418.56 | 2.740 | 2014-04-26 17:21:08 | 2014-04-26 17:22:16 | 68 |
| dd3 | 8.246 | 262.254.592 | 31,803,85 | 3.996 | 2014-04-26 17:22:16 | 2014-04-26 17:23:24 | 68 |
| dd4 | 8.055 | 261.688.320 | 32,487.68 | 4.231 | 2014-04-26 17:23:24 | 2014-04-26 17:24:32 | 68 |
| dd5 | 500.012 | 526.448.640 | 1.052,87 | 35.593 | 2014-04-26 17:24:32 | 2014-04-26 17:26:32 | 120 |
| dd6 | 500.014 | 525.870.080 | 1.051,71 | 35,435 | 2014-04-26 17:26:32 | 2014-04-26 17:28:31 | 119 |
| dd7 | 500.015 | 526.120.448 | 1.052,20 | 50,857 | 2014-04-26 17:28:31 | 2014-04-26 17:30:45 | 134 |
| dd8 | 500.017 | 525.886.976 | 1.051,73 | 49.680 | 133 |
Kleine transacties:duur en resultaten van sys.dm_io_virtual_file_stats
Absoluut een aantal interessante observaties hier:
- Het aantal afzonderlijke schrijfbewerkingen was erg klein voor de Delayed Durability-databases (~60X voor traditioneel).
- Het totale aantal geschreven bytes is gehalveerd met behulp van Delayed Durability (ik neem aan dat alle schrijfbewerkingen in het traditionele geval veel verspilde ruimte bevatten).
- Het aantal bytes per schrijfbewerking was een stuk hoger voor Delayed Durability. Dit was niet echt verrassend, aangezien het hele doel van de functie is om schrijfbewerkingen in grotere batches te bundelen.
- De totale duur van I/O-blokkades was volatiel, maar ongeveer een orde van grootte lager voor vertraagde duurzaamheid. De kraampjes onder volledig duurzame transacties waren veel gevoeliger voor het type schijf.
- Als iets je tot nu toe niet heeft overtuigd, is de kolom met de duur veelzeggend. Volledig duurzame batches die twee minuten of langer duren, worden bijna gehalveerd.
Dankzij de kolommen met begin- en eindtijd kon ik me concentreren op het Performance Advisor-dashboard voor de precieze periode waarin deze transacties plaatsvonden, waar we veel aanvullende visuele indicatoren kunnen tekenen:
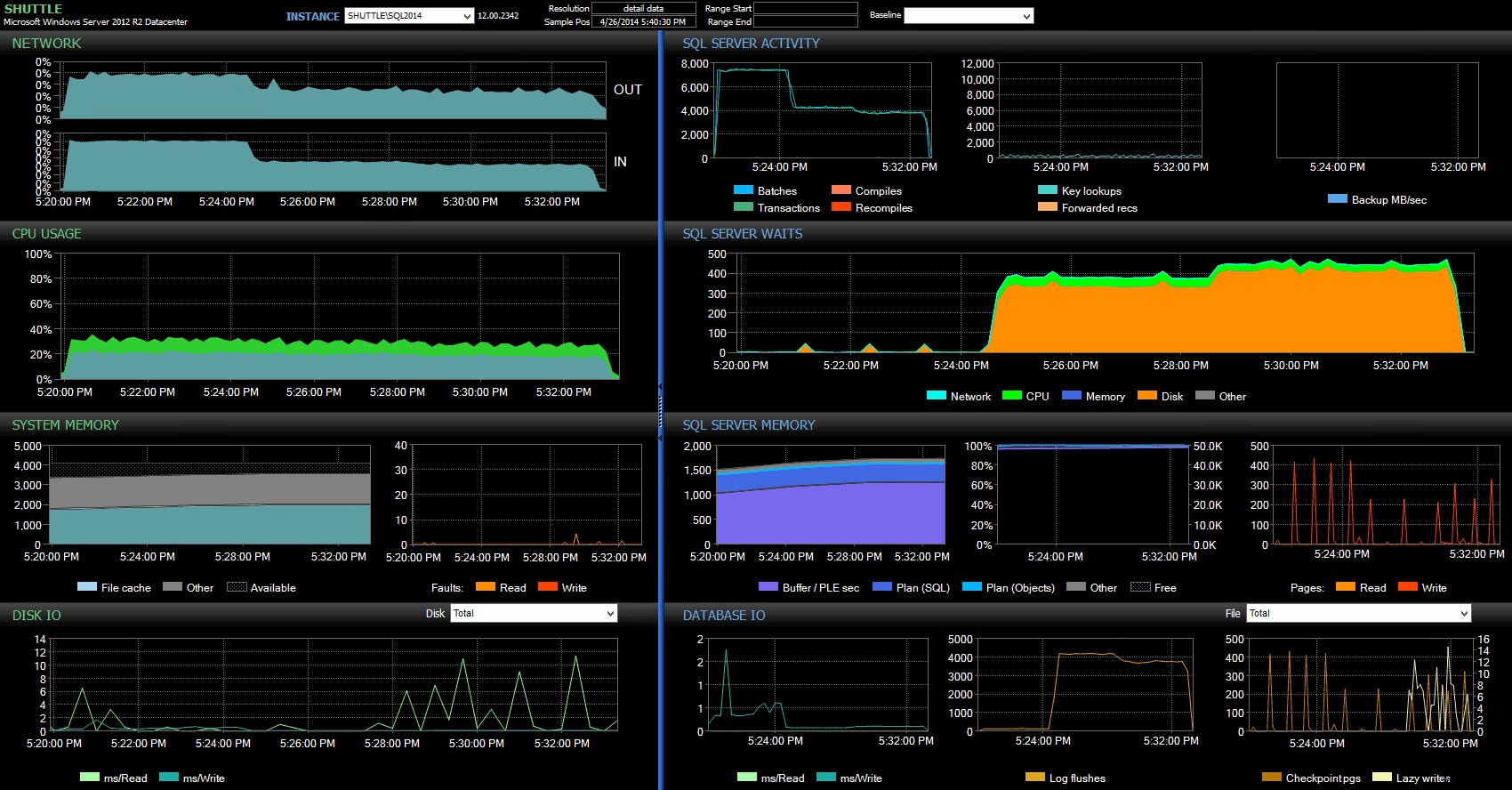
SQL Sentry-dashboard – klik om te vergroten
Verdere opmerkingen hier:
- In verschillende grafieken kun je duidelijk precies zien wanneer het niet-vertraagde duurzaamheidsgedeelte van de batch het overnam (~5:24:32 PM).
- Er is geen waarneembare impact op de CPU of het geheugen bij gebruik van uitgestelde duurzaamheid.
- U kunt een enorme impact op batches/transacties per seconde zien in de eerste grafiek onder SQL Server-activiteit.
- SQL Server-wachten gaan door het dak wanneer de volledig duurzame transacties begonnen. Deze bestonden bijna uitsluitend uit
WRITELOGwacht, met een klein aantalPAGEIOLOATCH_EXenPAGEIOLATCH_UPwacht op een goede maatregel. - Het totale aantal logspoelingen tijdens de operaties met vertraagde duurzaamheid was vrij klein (lage 100s/sec), terwijl dit steeg tot meer dan 4.000/sec voor het traditionele gedrag (en iets lager voor de duur van de HDD van de test).
- /ul>
Minder, grotere transacties
Voor de volgende test wilde ik zien wat er zou gebeuren als we minder bewerkingen zouden uitvoeren, maar ervoor zouden zorgen dat elke instructie een grotere hoeveelheid gegevens zou beïnvloeden. Ik wilde dat deze batch tegen elke database zou worden uitgevoerd:
CREATE TABLE dbo.Rnd ( batch TINYINT, TheID INT ); INSERT dbo.Rnd SELECT TOP (1000) 1, TheID FROM dbo.TheTable ORDER BY NEWID(); INSERT dbo.Rnd SELECT TOP (10) 2, TheID FROM dbo.TheTable ORDER BY NEWID(); INSERT dbo.Rnd SELECT TOP (300) 3, TheID FROM dbo.TheTable ORDER BY NEWID(); GO INSERT #Metrics SELECT 1, GETDATE(), * FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2); GO UPDATE t SET TheDate = DATEADD(MINUTE, 1, TheDate) FROM dbo.TheTable AS t INNER JOIN dbo.Rnd AS r ON t.TheID = r.TheID WHERE r.batch = 1; GO 10000 UPDATE t SET RowGuid = NEWID() FROM dbo.TheTable AS t INNER JOIN dbo.Rnd AS r ON t.TheID = r.TheID WHERE r.batch = 2; GO 10000 DELETE dbo.TheTable WHERE TheID IN (SELECT TheID FROM dbo.Rnd WHERE batch = 3); DELETE dbo.TheTable WHERE TheID IN (SELECT TheID+1 FROM dbo.Rnd WHERE batch = 3); DELETE dbo.TheTable WHERE TheID IN (SELECT TheID-1 FROM dbo.Rnd WHERE batch = 3); GO INSERT #Metrics SELECT 2, GETDATE(), * FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2);Dus opnieuw gebruikte ik de luie methode om 8 kopieën van dit script te maken, één per database:
;WITH x AS (SELECT TOP (8) number FROM master..spt_values WHERE type = N'P' ORDER BY number) SELECT N' USE dd' + RTRIM(Number+1) + '; GO CREATE TABLE dbo.Rnd ( batch TINYINT, TheID INT ); INSERT dbo.Rnd SELECT TOP (1000) 1, TheID FROM dbo.TheTable ORDER BY NEWID(); INSERT dbo.Rnd SELECT TOP (10) 2, TheID FROM dbo.TheTable ORDER BY NEWID(); INSERT dbo.Rnd SELECT TOP (300) 3, TheID FROM dbo.TheTable ORDER BY NEWID(); GO INSERT #Metrics SELECT 2, 1, GETDATE(), * FROM sys.dm_io_virtual_file_stats(DB_ID(''dd' + RTRIM(number+1) + ''', 2); GO UPDATE t SET TheDate = DATEADD(MINUTE, 1, TheDate) FROM dbo.TheTable AS t INNER JOIN dbo.rnd AS r ON t.TheID = r.TheID WHERE r.cycle = 1; GO 10000 UPDATE t SET RowGuid = NEWID() FROM dbo.TheTable AS t INNER JOIN dbo.rnd AS r ON t.TheID = r.TheID WHERE r.cycle = 2; GO 10000 DELETE dbo.TheTable WHERE TheID IN (SELECT TheID FROM dbo.rnd WHERE cycle = 3); DELETE dbo.TheTable WHERE TheID IN (SELECT TheID+1 FROM dbo.rnd WHERE cycle = 3); DELETE dbo.TheTable WHERE TheID IN (SELECT TheID-1 FROM dbo.rnd WHERE cycle = 3); GO INSERT #Metrics SELECT 2, 2, GETDATE(), * FROM sys.dm_io_virtual_file_stats(DB_ID(''dd' + RTRIM(number+1) + '''), 2);' FROM x;Ik heb deze batch uitgevoerd en vervolgens de query gewijzigd tegen
#Metricshierboven om naar de tweede test te kijken in plaats van de eerste. De resultaten:database schrijft bytes bytes/schrijven io_stall_ms start_time eindtijd duur (seconden) dd1 20.970 1.271.911.936 60,653,88 12.577 2014-04-26 17:41:21 2014-04-26 17:43:46 145 dd2 20.997 1.272.145.408 60.587.00 14.698 2014-04-26 17:43:46 2014-04-26 17:46:11 145 dd3 20.973 1.272.982.016 60,696.22 12.085 2014-04-26 17:46:11 2014-04-26 17:48:33 142 dd4 20.958 1.272.064.512 60,695,89 11.795 2014-04-26 17:48:33 2014-04-26 17:50:56 143 dd5 30.138 1.282.231.808 42.545,35 7.402 2014-04-26 17:50:56 2014-04-26 17:53:23 147 dd6 30.138 1.282.260.992 42.546,31 7.806 2014-04-26 17:53:23 2014-04-26 17:55:53 150 dd7 30.129 1.281.575.424 42.536,27 9,888 2014-04-26 17:55:53 2014-04-26 17:58:25 152 dd8 30.130 1.281.449.472 42.530,68 11.452 2014-04-26 17:58:25 2014-04-26 18:00:55 150 Grotere transacties:duur en resultaten van sys.dm_io_virtual_file_stats
Deze keer is de impact van vertraagde duurzaamheid veel minder merkbaar. We zien een iets kleiner aantal schrijfbewerkingen, bij een iets groter aantal bytes per schrijfbewerking, waarbij het totale aantal geschreven bytes bijna identiek is. In dit geval zien we dat de I/O-blokkades hoger zijn voor vertraagde duurzaamheid, en dit verklaart waarschijnlijk dat de duur ook bijna identiek was.
Uit het Performance Advisor-dashboard zien we enkele overeenkomsten met de vorige test, en ook enkele grote verschillen:
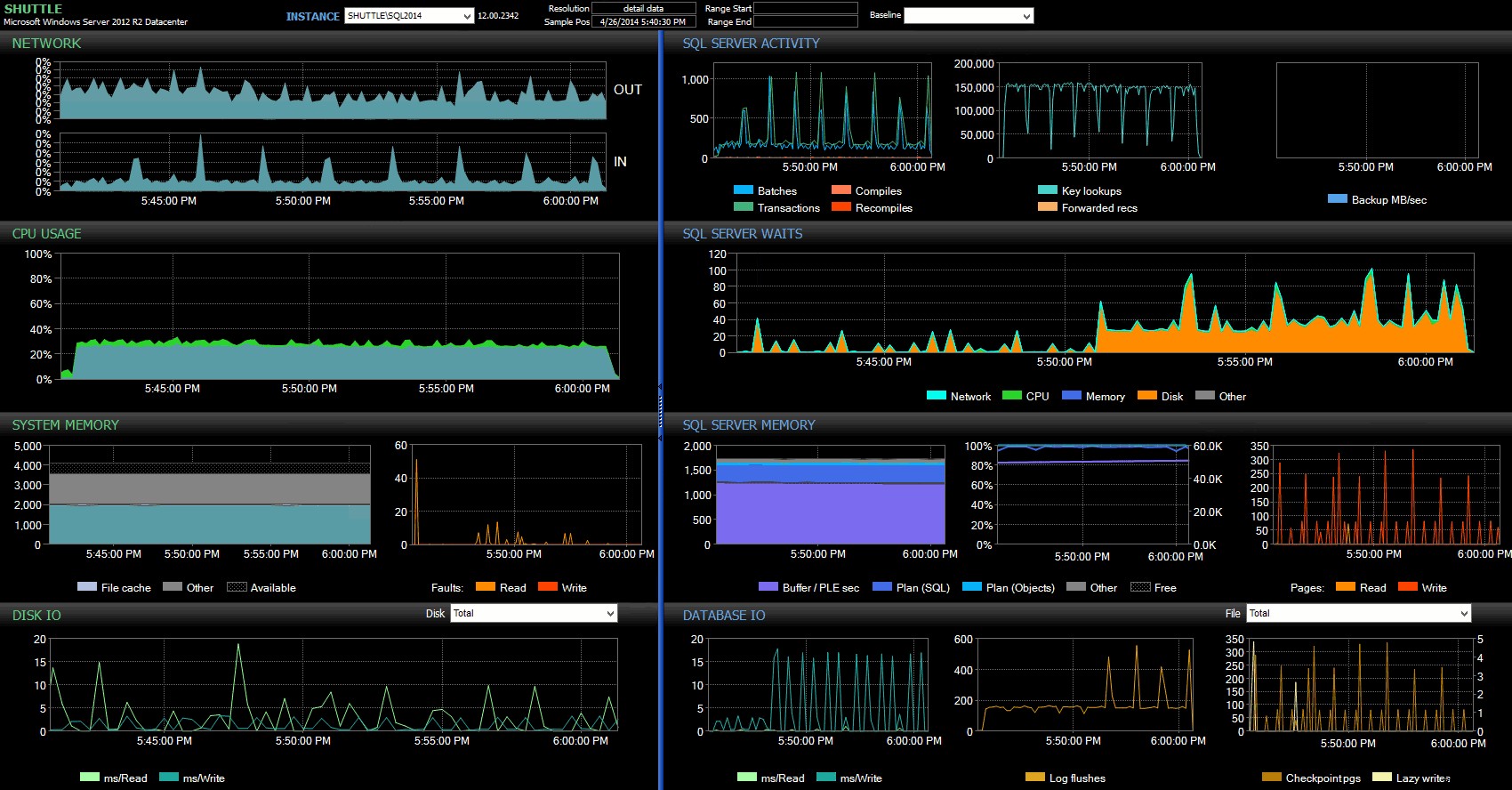
SQL Sentry-dashboard – klik om te vergrotenEen van de grote verschillen om hier op te wijzen is dat de delta in wachtstatistieken niet zo uitgesproken is als bij de vorige test - er is nog steeds een veel hogere frequentie van
WRITELOGwacht op de volledig duurzame batches, maar lang niet in de buurt van de niveaus die worden gezien bij de kleinere transacties. Wat ook meteen opvalt, is dat de eerder waargenomen impact op batches en transacties per seconde niet meer aanwezig is. En tot slot, hoewel er meer log flushes zijn bij volledig duurzame transacties dan bij uitgestelde transacties, is dit verschil veel minder uitgesproken dan bij de kleinere transacties.
Conclusie
Het mag duidelijk zijn dat er bepaalde soorten werkbelasting zijn die veel baat kunnen hebben bij vertraagde duurzaamheid, op voorwaarde natuurlijk dat u een tolerantie heeft voor gegevensverlies . Deze functie is niet beperkt tot In-Memory OLTP, is beschikbaar op alle edities van SQL Server 2014 en kan worden geïmplementeerd met weinig tot geen wijzigingen in de code. Het kan zeker een krachtige techniek zijn als je werkdruk het kan ondersteunen. Maar nogmaals, u moet uw werklast testen om er zeker van te zijn dat deze van deze functie profiteert, en ook sterk overwegen of dit uw blootstelling aan het risico van gegevensverlies vergroot.
Even terzijde, dit lijkt voor de SQL Server-menigte misschien een fris nieuw idee, maar in werkelijkheid introduceerde Oracle dit in 2006 als "Asynchronous Commit" (zie COMMIT WRITE ... NOWAIT zoals hier gedocumenteerd en waarover in 2007 is geblogd). En het idee zelf bestaat al bijna 3 decennia; zie Hal Berenson's korte kroniek van zijn geschiedenis.
Volgende keer
Een idee dat ik heb uitgeprobeerd, is om te proberen de prestaties van tempdb te verbeteren door Vertraagde Duurzaamheid daar te forceren. Een speciale eigenschap van tempdb dat het zo'n verleidelijke kandidaat maakt, is dat het van nature van voorbijgaande aard is - alles in tempdb is expliciet ontworpen om te kunnen worden gebruikt in het kielzog van een breed scala aan systeemgebeurtenissen. Ik zeg dit nu zonder enig idee te hebben of er een workload-vorm is waar dit goed zal werken; maar ik ben van plan het uit te proberen, en als ik iets interessants vind, kun je er zeker van zijn dat ik het hier zal posten.