Inleiding
Een paar jaar geleden werden we belast met een zakelijke vereiste voor kaartgegevens in een specifiek formaat met het oog op iets dat 'afstemming' wordt genoemd. Het idee was om de gegevens in een tabel te presenteren aan een applicatie die de gegevens zou consumeren en verwerken, met een bewaartermijn van zes maanden. We moesten een nieuwe database maken voor deze zakelijke behoefte en vervolgens de kerntabel maken als een gepartitioneerde tabel. Het proces dat hier wordt beschreven, is het proces dat we gebruiken om ervoor te zorgen dat gegevens die ouder zijn dan zes maanden op een schone manier uit de tabel worden verwijderd.
Een beetje over partitioneren
Tabelpartitionering is een databasetechnologie waarmee u gegevens die tot één logische eenheid (de tabel) behoren, kunt opslaan als een set partities die op een afzonderlijke fysieke structuur (gegevensbestanden) worden geplaatst via een abstractielaag met de naam Bestandsgroepen in SQL Server. Het proces van het maken van deze gepartitioneerde tabel omvat twee belangrijke objecten:
Een partitiefunctie :Een partitiefunctie definieert hoe de rijen van een gepartitioneerde tabel worden toegewezen op basis van de waarden van een opgegeven kolom (de partitiekolom). Een gepartitioneerde tabel kan gebaseerd zijn op een lijst of een bereik. Voor het doel van onze use-case (waarbij slechts zes maanden aan gegevens bewaard zijn gebleven), hebben we een Bereikpartitie gebruikt . Een partitiefunctie kan worden gedefinieerd als RANGE RIGHT of RANGE LEFT. We gebruikten RANGE RIGHT zoals weergegeven in de code in Listing 1, wat betekent dat de grenswaarde aan de rechterkant van het grenswaarde-interval hoort wanneer de waarden in oplopende volgorde van links naar rechts worden gesorteerd.
-- Listing 1:Maak een partitiefunctieGEBRUIK [post_office_history]GOCREATE PARTITION FUNCTIONPostTranPartFunc (datetime)AS RANGE RIGHTFOR VALUES ('20190201','20190301','20190401','20190501','20190601','20190701', '20190801','20190901','20191001','20191101','20191201')GO Een partitieschema :Een partitieschema is gebaseerd op de partitiefunctie en bepaalt op welke fysieke structuren rijen behorende bij elke partitie worden geplaatst. Dit wordt bereikt door dergelijke rijen toe te wijzen aan bestandsgroepen. Listing 2 toont de code voor het maken van een partitieschema. Voordat het partitieschema wordt gemaakt, moeten de bestandsgroepen waarnaar het verwijst bestaan.
-- Lijst 2:Partitieschema maken ---- Stap 1:Bestandsgroepen maken --USE [master]GOALTER DATABASE [post_office_history] ADD FILEGROUP [JAN]ALTER DATABASE [post_office_history] ADD FILEGROUP [FEB]ALTER DATABASE [post_office_history ] ADD FILEGROUP [MAR]ALTER DATABASE [post_office_history] ADD FILEGROUP [APR]ALTER DATABASE [post_office_history] ADD FILEGROUP [MAY]ALTER DATABASE [post_office_history] ADD FILEGROUP [JUN]ALTERoffice_history [postDD_office_history] ] FILEGROUP TOEVOEGEN [AUG]ALTER DATABASE [post_office_history] ADD FILEGROUP [SEP]ALTER DATABASE [post_office_history] ADD FILEGROUP [OCT]ALTER DATABASE [post_office_history] ADD FILEGROUP [NOV]ALTER DATABASE [postDD_office_history] ADD_office_history 2:Voeg gegevensbestanden toe aan elke bestandsgroep --USE [master]GOALTER DATABASE [post_office_history] ADD FILE (NAME =N'post_office_history_part_01', FILENAME =N'E:\MSSQL\DATA\post_office_history_part_01.ndf', SIZE =2097152KB, FILENAME =N'E:\MSSQL\DATA\post_office_history_part_01.ndf', SIZE =2097152KB, FILE=1048576KB) NAAR FILEGROUP [JAN]DATABASE WIJZIGEN [post_office_history] BESTAND TOEVOEGEN (NAAM =N'post_office_history_part_02', FILENAME =N'E:\MSSQL\DATA\post_office_history_part_02.ndf', SIZE =20FI97152KB, FILENAME =N'E:\MSSQL\DATA\post_office_history_part_02.ndf', SIZE =2048597152KB FEB]ALTER DATABASE [post_office_history] BESTAND TOEVOEGEN (NAME =N'post_office_history_part_03', FILENAME =N'E:\MSSQL\DATA\post_office_history_part_03.ndf', SIZE =2097152KB, FILEGROWTH =1048576KBATA ] BESTAND TOEVOEGEN (NAME =N'post_office_history_part_04', FILENAME =N'E:\MSSQL\DATA\post_office_history_part_04.ndf', SIZE =2097152KB, FILEGROWTH =1048576KB) NAAR BESTANDSGROEP [APR]ALTER DATAFIStory =N'post_office_history_part_05', FILENAME =N'E:\MSSQL\DATA\post_office_history_part_05.ndf', SIZE =2097152KB, FILEGROWTH =1048576KB) NAAR FILEGROUP [MAY]ALTER DATABASE [post_office_history_NAME] =06 =N'G:\MSSQL\DATA\post_office_history_part_06. ndf', SIZE =2097152KB, FILEGROWTH =1048576KB) NAAR FILEGROUP [JUN]ALTER DATABASE [post_office_history] VOEG BESTAND TOE (NAME =N'post_office_history_part_07', FILENAME =N'G:\MSSQL\DATA\post_07SI_history. , FILEGROWTH =1048576KB) NAAR FILEGROUP [JUL]DATABASE WIJZIGEN [post_office_history] BESTAND TOEVOEGEN (NAME =N'post_office_history_part_08', FILENAME =N'G:\MSSQL\DATA\post_office_history_part_08.ndf', GROUP FILEGROUP [AUG]ALTER DATABASE [post_office_history] BESTAND TOEVOEGEN (NAME =N'post_office_history_part_09', FILENAME =N'G:\MSSQL\DATA\post_office_history_part_09.ndf', SIZE =2097152KB, FILEEPGROUP] [post_office_history] BESTAND TOEVOEGEN (NAAM =N'post_office_history_part_10', FILENAME =N'G:\MSSQL\DATA\post_office_history_part_10.ndf', SIZE =2097152KB, FILEGROWTH =1048576KB) AAN FILEGOALTER_FILEGOALTER_DOATABA NAAM =N'post_office_history_part_09', FILENAME =N'G:\MS SQL\DATA\post_office_history_part_11.ndf', SIZE =2097152KB, FILEGROWTH =1048576KB) NAAR FILEGROUP [NOV]ALTER DATABASE [post_office_history] BESTAND TOEVOEGEN (NAME =N'post_office_history_part_10', FILENAMEMS =Q'Gpart_10' ndf', SIZE =2097152KB, FILEGROWTH =1048576KB) NAAR FILEGROUP [DEC]GO-- Stap 3:Partitieschema maken --PRINT 'partitieschema maken ...'GOUSE [post_office_history]GOCREATE PARTITIESCHEMA PostTranPartSch ALS PARTITIE PostTranPartFunc TO(JAN ,FEB,MAR,APR,MEI,JUN,JUL,AUG,SEP,OCT,NOV,DEC)GO
Merk op dat voor N partities, zal er altijd N-1 . zijn grenzen. Voorzichtigheid is geboden bij het definiëren van de eerste bestandsgroep in het partitieschema. De eerste grens die in de partitiefunctie wordt vermeld, zal tussen de eerste en tweede bestandsgroep liggen, dus deze grenswaarde (20190201) zal in de tweede partitie (FEB) zitten. Daarnaast is het eigenlijk mogelijk om alle partities in één bestandsgroep te plaatsen, maar in dit geval hebben we voor aparte bestandsgroepen gekozen.
Onze handen vuil maken
Dus laten we ons verdiepen in de taak om partities uit te schakelen!
Het eerste dat we moeten doen, is bepalen hoe onze gegevens precies over de partities zijn verdeeld, zodat we kunnen weten welke partitie we willen uitschakelen. Meestal schakelen we de oudste partitie uit.
-- Lijst 3:Controleer gegevensdistributie in partities --USE POST_OFFICE_HISTORYGOSELECT $PARTITION.POSTTRANPARTFUNC(DATETIME_TRAN_LOCAL) AS [PARTITION NUMBER] , MIN(DATETIME_TRAN_LOCAL) AS [MIN DATE] , MAX(DATETIME_TRAN_LOCAL) AS COUNT(*) AS [ROWS IN PARTITION]VAN DBO.POST_TRAN_TAB -- GEPARTITIONEERDE TABLEGROUP DOOR $PARTITION.POSTTRANPARTFUNC(DATETIME_TRAN_LOCAL)ORDER DOOR [PARTITIENUMMER]GO
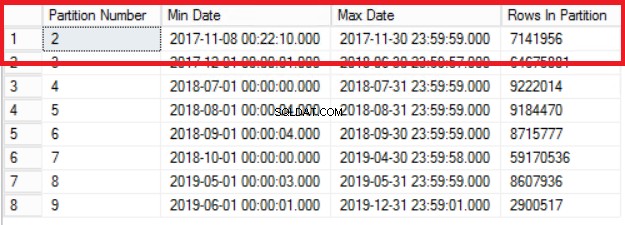
Afb. 1 Uitvoer van lijst 3
Fig. 1 toont ons de uitvoer van de query in Listing 3. De oudste partitie is Partitie 2 die rijen uit het jaar 2017 bevat. We verifiëren dit met de query in Listing 4. Listing 4 laat ons ook zien welke Filegroup de gegevens in Partition bevat 2.
-- Lijst 4:Controleer bestandsgroep geassocieerd met partitie --USE POST_OFFICE_HISTORYGOSELECT PS.NAME AS PSNAME, DDS.DESTINATION_ID AS PARTITIONNUMBER, FG.NAME AS FILEGROUPNAMEFROM (((SYS.TABLES AS T INNER JOIN SYS.INDEXES AS I ON) (T.OBJECT_ID =I.OBJECT_ID)) INNER WORDT SYS.PARTITION_SCHEMES ALS PS AAN (I.DATA_SPACE_ID =PS.DATA_SPACE_ID)) INNER WORDT SYS.DESTINATION_DATA_SPACES ALS DDS AAN (PS.DATA_SPACE_IDYS =DDS.PARTITION_ID) BESTANDSGROEPEN ALS FG OP DDS.DATA_SPACE_ID =FG.DATA_SPACE_IDWHERE (T.NAME ='POST_TRAN_TAB') AND (I.INDEX_ID IN (0,1)) AND DDS.DESTINATION_ID =$PARTITION.POSTTRANPARTFUNC('20171108'); Afb. 1 Uitvoer van lijst 3
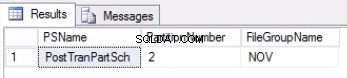
Fig. 2 Uitvoer van listing 4
Lijst 4 laat ons zien dat de bestandsgroep geassocieerd met Partitie 2 NOV is . Om Partitie 2 uit te schakelen, hebben we een geschiedenistabel nodig die een replica is van de live-tabel, maar zich in dezelfde bestandsgroep bevindt als de partitie die we willen uitschakelen. Aangezien we deze tabel al hebben, is alles wat we nodig hebben, het opnieuw te maken in de gewenste bestandsgroep. U moet ook de geclusterde index opnieuw maken. Houd er rekening mee dat deze geclusterde index dezelfde definitie heeft als de geclusterde index in de tabel post_tran_tab en zit ook in dezelfde bestandsgroep als post_tran_tab_hist tafel.
-- Lijst 5:Maak de geschiedenistabel opnieuw -- Maak de geschiedenistabel opnieuw --USE [post_office_history]GOSET ANSI_NULLS ONGOSET QUOTED_IDENTIFIER ONGOSET ANSI_PADDING ONGODROP TABLE [dbo].[post_tran_tab_hist]GOCREATE TABLE [dbo].[ post_tran_tab_hist]( [tran_nr] [bigint] NOT NULL, [tran_type] [char](2) NULL, [tran_reversed] [char](2) NULL, [batch_nr] [int] NULL, [message_type] [char](4 ) NULL, [source_node_name] [varchar] (12) NULL, [system_trace_audit_nr] [char] (6) NULL, [settle_currency_code] [char] (3) NULL, [sink_node_name] [varchar] (30) NULL, [sink_node_currency_code] [char](3) NULL, [to_account_id] [varchar](30) NULL, [pan] [varchar](19) NOT NULL, [pan_encrypted] [char](18) NULL, [pan_reference] [char](70 ) NULL, [datetime_tran_local] [datetime] NOT NULL, [tran_amount_req] [float] NOT NULL, [tran_amount_rsp] [float] NOT NULL, [tran_cash_req] [float] NOT NULL, [tran_cash_rsp] [float] NOT NULL, [datetime_tran_gmtttime_tran_gmtttime_tran_gmt ] [char](10) NULL, [merchant_type] [char](4) NULL, [pos_entry_mode] [char] (3) NULL, [pos_condition_code] [char](2) NULL, [acquiring_inst_id_code] [varchar](11) NULL, [retrieval_reference_nr] [char] (12) NULL, [auth_id_rsp] [char] (6) NULL, [ rsp_code_rsp] [char](2) NULL, [service_restriction_code] [char](3) NULL, [terminal_id] [char](8) NULL, [terminal_owner] [varchar](25) NULL, [card_acceptor_id_code] [char]( 15) NULL, [card_acceptor_name_loc] [char](40) NULL, [from_account_id] [varchar](28) NULL, [auth_reason] [char](1) NULL, [auth_type] [char](1) NULL, [message_reason_code ] [char](4) NULL, [datetime_req] [datetime] NULL, [datetime_rsp] [datetime] NULL, [from_account_type] [char](2) NULL, [to_account_type] [char](2) NULL, [insert_date] [datetime] NOT NULL, [tran_postilion_originated] [int] NOT NULL, [card_product] [varchar](20) NULL, [card_seq_nr] [char](3) NULL, [expiry_date] [char](4) NULL, [srcnode_cash_approved ] [float] NOT NULL, [tran_completed] [char](2) NULL) ON [NOV] GOSET ANSI_PADDING OFFGO-- Maak de geclusterde index opnieuw --USE [post_office_history]GO MAAK GECLUSTERDE INDEX [IX_Datetime_Local] AAN [dbo].[post_tran_tab_hist] ( [datetime_tran_local] ASC, [tran_nr] ASC ) MET (PAD_INDEX =UIT, STATISTICS_NORECOMPUTE =UIT, SORT_IN_TEMPDB =UIT, IGNORE_D UP_OP_TOETS =UIT, IGNORE_D ) , ALLOW_ROW_LOCKS =AAN, ALLOW_PAGE_LOCKS =AAN) OP [NOV]GO
Het uitschakelen van de laatste partitie is nu een eenregelig commando. Door beide tabellen te tellen voor en na het uitvoeren van deze eenregelige opdracht, weet u zeker dat we over alle gewenste gegevens beschikken.
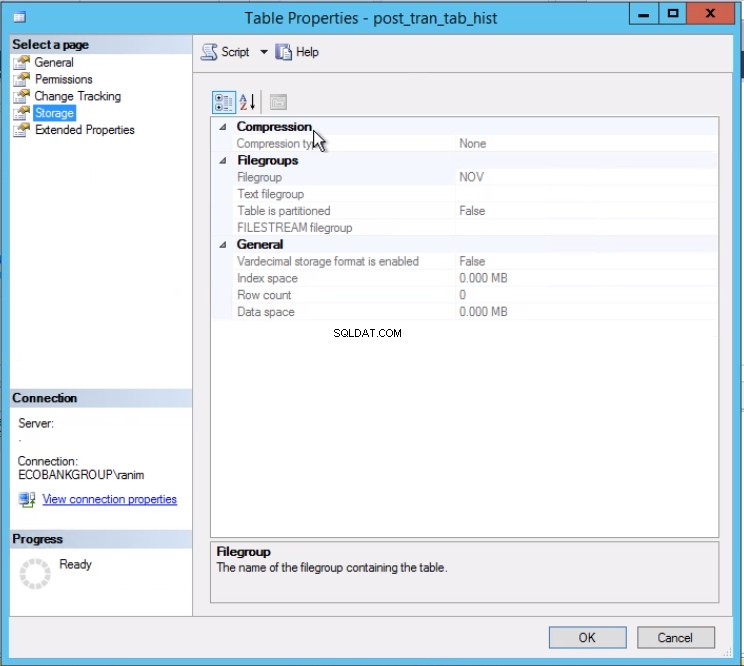
Fig. 3 Tabel post_tran_tab_hist staat op de NOV-bestandsgroep
-- Lijst 6:Uitschakelen van de laatste partitieSELECT COUNT(*) FROM 'POST_TRAN_TAB';SELECT COUNT(*) FROM 'POST_TRAN_TAB_HIST';USE [POST_OFFICE_HISTORY]GOALTER TABLE POST_TRAN_TAB SWITCH PARTITION 2 TO POST_HISTGO POST_TRAN_TAB';SELECT COUNT(*) FROM 'POST_TRAN_TAB_HIST';
Omdat we de laatste partitie hebben uitgeschakeld, hebben we de grens niet langer nodig. We voegen de twee bereiken samen die eerder door die grens waren gesplitst met behulp van de opdracht in Listing 7. We kappen de geschiedenistabel verder af zoals weergegeven in Listing 8. We doen dit omdat dit het hele punt is:het verwijderen van oude gegevens die we niet langer nodig hebben.
-- Lijst 7:Partitiebereiken samenvoegen-- Bereik samenvoegenUSE [POST_OFFICE_HISTORY]GOALTER PARTITION FUNCTION POSTTRANPARTFUNC() MERGE RANGE ('20171101');-- Bevestig dat het bereik is samengevoegdUSE [POST_OFFICE_HISTORY]GOSELECT * FROM SYS.PARTITION_RANGE_VALUE_VALUES>
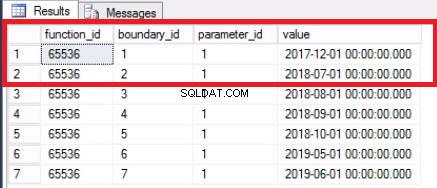
Afb. 4 Grens samengevoegd
-- Lijst 8:kap de geschiedenistabel afUSE [post_office_history]GOTRUNCATE TABLE post_tran_tab_hist;GO
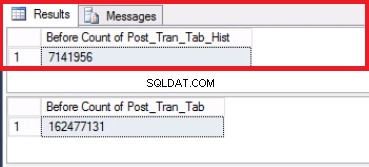
Fig. 5 Aantal rijen voor beide tabellen vóór afkappen
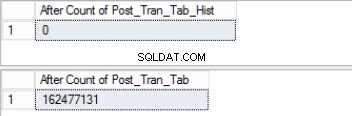
Houd er rekening mee dat het aantal rijen in de geschiedenistabel precies hetzelfde is als het aantal rijen eerder in Partitie 2, zoals weergegeven in Fig. 1. U kunt ook een stap verder gaan door de lege ruimte in de bestandsgroep die bij de laatste hoort te herstellen. partitie. Dit is handig als u deze ruimte nodig heeft voor de nieuwe gegevens die op de eerdere partitie komen te staan. Deze stap is misschien niet nodig als je denkt dat je voldoende ruimte hebt in je omgeving.
-- Lijst 9:Herstel ruimte op besturingssysteem-- Bepaal dat het bestand is geleegdUSE [post_office_history]GOSELECT DF.FILE_ID, DF.NAME, DF.PHYSICAL_NAME, DS.NAME, DS.TYPE, DF.STATE_DESC FROM SYS .DATABASE_FILES DFJOIN SYS.DATA_SPACES DS OP DF.DATA_SPACE_ID =DS.DATA_SPACE_ID;
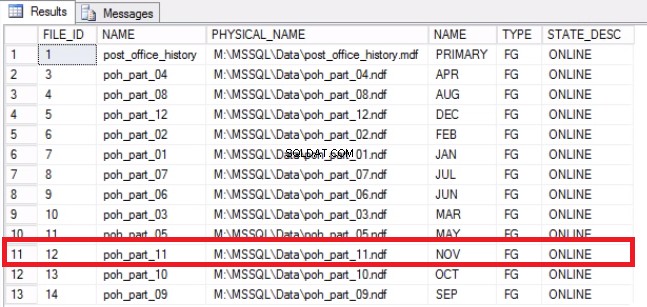
Fig. 7 Toewijzingen van bestand naar bestandsgroep
-- Verklein het bestand naar 2GBUSE [post_office_history]GODBCC SHRINKFILE (N'post_office_history_part_11', 2048)GO-- Bevestig vanuit het besturingssysteem vrije ruimte op schijvenSELECT DISTINCT DB_NAME (S.DATABASE_ID) AS DATABASE_NAME,S.DATABASE_ID, S. VOLUME_MOUNT_POINT--, S.VOLUME_ID, S.LOGICAL_VOLUME_NAME, S.FILE_SYSTEM_TYPE, S.TOTAL_BYTES/1024/1024/1024 AS [TOTAL_SIZE (GB)], S.AVAILABLE_BYTES/1024/1024/1024 AS [FREE_SPACE (GB)], LINKS ((ROUND (((S.AVAILABLE_BYTES*1.0)/S.TOTAL_BYTES), 4)*100),4) AS PERCENT_FREEFROM SYS.MASTER_FILES AS FROSS APPLY SYS.DM_OS_VOLUME_STATS (F.DATABASE_ID, F.FILE_ID) ALS SWHERE NAME (S.DATABASE_ID) ='POST_OFFICE_HISTORY';

Afb. 8 Vrije ruimte op besturingssysteem
Conclusie
In dit artikel hebben we het proces doorlopen om partities uit een gepartitioneerde tabel te schakelen. Dit is een zeer efficiënte manier om de gegevensgroei native in SQL Server te beheren. Meer geavanceerde technologieën zoals Stretch Database zijn beschikbaar in de huidige versies van SQL Server.
Referenties
Isakov, V. (2018). Examenreferentie 70-764 Beheer van een SQL-databaseinfrastructuur. Pearson Onderwijs
Gepartitioneerde tabellen en indexen in SQL Server