In mijn vorige artikel heb ik in het kort databasestatistieken behandeld, het belang ervan en waarom statistieken moeten worden bijgewerkt. Bovendien heb ik een stapsgewijs proces gedemonstreerd om een SQL Server-onderhoudsplan te maken om statistieken bij te werken. In dit artikel worden de volgende problemen uitgelegd:1. Hoe u statistieken kunt bijwerken met T-SQL Command. 2. Hoe de vaak bijgewerkte tabellen te identificeren met behulp van T-SQL en ook hoe de statistieken van tabellen met vaak ingevoegde / bijgewerkte / verwijderde gegevens kunnen worden bijgewerkt.
Statistieken bijwerken met T-SQL
U kunt statistieken bijwerken met behulp van het T-SQL-script. Als u statistieken wilt bijwerken met behulp van T-SQL of SQL Server-beheerstudio, heeft u ALTER-database nodig toestemming voor de database. Bekijk het T-SQL-codevoorbeeld om de statistieken van een specifieke tabel bij te werken:
UPDATE STATISTICS <schema_name>.<table_name>.
Laten we eens kijken naar het voorbeeld van het bijwerken van de statistieken van de OrderLines tabel van de WideWorldImporters databank. Het volgende script zal dat doen.
UPDATE STATISTICS [Sales].[OrderLines]
Als u de statistieken van een specifieke index wilt bijwerken, kunt u het volgende script gebruiken:
UPDATE STATISTICS <schema_name>.<table_name> <index_name>
Als u de statistieken van de IX_Sales_OrderLines_Perf_20160301_02 wilt bijwerken index van de OrderLines tabel, kunt u het volgende script uitvoeren:
UPDATE STATISTICS [Sales].[OrderLines] [IX_Sales_OrderLines_Perf_20160301_02]
U kunt ook de statistieken van de hele database bijwerken. Als u een zeer kleine database heeft met weinig tabellen en weinig gegevens, dan kunt u de statistieken van alle tabellen in een database bijwerken. Zie het volgende script:
USE wideworldimporters go EXEC Sp_updatestats
Statistieken bijwerken voor tabellen met vaak ingevoegde / bijgewerkte / verwijderde gegevens
Bij grote databases wordt het plannen van de statistische taak ingewikkeld, vooral wanneer u maar een paar uur hebt om indexonderhoud uit te voeren, statistieken bij te werken en andere onderhoudstaken uit te voeren. Met een grote database bedoel ik een database die duizenden tabellen bevat en elke tabel duizenden rijen. We hebben bijvoorbeeld een database met de naam X. Deze heeft honderden tabellen en elke tabel heeft miljoenen rijen. En slechts een paar tabellen worden regelmatig bijgewerkt. Andere tabellen worden zelden gewijzigd en er worden zeer weinig transacties op uitgevoerd. Zoals ik al eerder zei, moeten tabelstatistieken up-to-date zijn om de databaseprestaties op peil te houden. Daarom maken we een SQL-onderhoudsplan om de statistieken van alle tabellen in de X-database bij te werken. Wanneer SQL-server de statistieken van een tabel bijwerkt, gebruikt deze een aanzienlijke hoeveelheid bronnen die tot prestatieproblemen kunnen leiden. Het duurt dus lang om de statistieken van honderden grote tabellen bij te werken en terwijl de statistieken worden bijgewerkt, nemen de prestaties van de database aanzienlijk af. In dergelijke omstandigheden is het altijd raadzaam om de statistieken alleen bij te werken voor de tabellen die regelmatig worden bijgewerkt. U kunt wijzigingen in het gegevensvolume of het aantal rijen in de loop van de tijd bijhouden met behulp van de volgende dynamische beheerweergaven:1. sys.partitions geeft informatie over het totale aantal rijen in een tabel. 2. sys.dm_db_partition_stats geeft informatie over het aantal rijen en pagina's, per partitie. 3. sys.dm_db_index_physical_stats geeft informatie over het aantal rijen en pagina's, plus informatie over indexfragmentatie en meer. De details over het datavolume zijn belangrijk, maar maken het beeld van de database-activiteit niet compleet. Een verzameltabel met bijna hetzelfde aantal records kan bijvoorbeeld elke dag uit de tabel worden verwijderd of in een tabel worden ingevoegd. Daarom zou een momentopname van het aantal rijen suggereren dat de tabel statisch is. Het is mogelijk dat de toegevoegde en verwijderde records zeer verschillende waarden hebben die de gegevensdistributie sterk veranderen. In dit geval maakt het automatisch bijwerken van statistieken in SQL Server statistieken zinloos. Daarom is het erg handig om het aantal wijzigingen aan een tabel bij te houden. Dit kan op de volgende manieren worden gedaan:1. rowmodctr kolom in sys.sysindexes 2. modified_count kolom in sys.system_internals_partition_columns 3. modification_counter kolom in sys.dm_db_stats_properties Dus, zoals ik eerder heb uitgelegd, als je beperkte tijd hebt voor database-onderhoud, is het altijd raadzaam om de statistieken alleen bij te werken voor de tabellen met een hogere frequentie van gegevensverandering (invoegen / bijwerken / verwijderen). Om dat efficiënt te doen, heb ik een script gemaakt dat de statistieken voor de "actieve" tabellen bijwerkt. Het script voert de volgende taken uit:• Declareert de vereiste parameters • Maakt een tijdelijke tabel met de naam #tempstatistics om de tabelnaam, schemanaam en databasenaam op te slaan • Maakt een andere tabel met de naam #tempdatabase om de databasenaam op te slaan. Voer eerst het volgende script uit om twee tabellen te maken:
DECLARE @databasename VARCHAR(500) DECLARE @i INT=0 DECLARE @DBCOunt INT DECLARE @SQLCOmmand NVARCHAR(max) DECLARE @StatsUpdateCOmmand NVARCHAR(max) CREATE TABLE #tempstatistics ( databasename VARCHAR(max), tablename VARCHAR(max), schemaname VARCHAR(max) ) CREATE TABLE #tempdatabases ( databasename VARCHAR(max) ) INSERT INTO #tempdatabases (databasename) SELECT NAME FROM sys.databases WHERE database_id > 4 ORDER BY NAME
Schrijf vervolgens een while-lus om een dynamische SQL-query te maken die alle databases doorloopt en een lijst met tabellen met een wijzigingsteller groter dan 200 invoegt in de #tempstatistics tafel. Om informatie over gegevenswijzigingen te verkrijgen, gebruik ik sys.dm_db_stats_properties . Bestudeer het volgende codevoorbeeld:
SET @DBCOunt=(SELECT Count(*) FROM #tempdatabases) WHILE ( @i < @DBCOunt ) BEGIN DECLARE @DBName VARCHAR(max) SET @DBName=(SELECT TOP 1 databasename FROM #tempdatabases) SET @SQLCOmmand= ' use [' + @DBName + ']; select distinct ''' + @DBName+ ''', a.TableName,a.SchemaName from (SELECT obj.name as TableName, b.name as SchemaName,obj.object_id, stat.name, stat.stats_id, last_updated, modification_counter FROM [' + @DBName+ '].sys.objects AS obj inner join ['+ @DBName + '].sys.schemas b on obj.schema_id=b.schema_id INNER JOIN [' + @DBName+ '].sys.stats AS stat ON stat.object_id = obj.object_id CROSS APPLY [' + @DBName+'].sys.dm_db_stats_properties(stat.object_id, stat.stats_id) AS sp WHERE modification_counter > 200 and obj.name not like ''sys%''and b.name not like ''sys%'')a' INSERT INTO #tempstatistics (databasename, tablename, schemaname) EXEC Sp_executesql @SQLCOmmand
Maak nu de tweede lus binnen de eerste lus. Het genereert een dynamische SQL-query die de statistieken bijwerkt met een volledige scan. Zie het codevoorbeeld hieronder:
DECLARE @j INT=0 DECLARE @StatCount INT SET @StatCount =(SELECT Count(*) FROM #tempstatistics) WHILE @J < @StatCount BEGIN DECLARE @DatabaseName_Stats VARCHAR(max) DECLARE @Table_Stats VARCHAR(max) DECLARE @Schema_Stats VARCHAR(max) DECLARE @StatUpdateCommand NVARCHAR(max) SET @DatabaseName_Stats=(SELECT TOP 1 databasename FROM #tempstatistics) SET @Table_Stats=(SELECT TOP 1 tablename FROM #tempstatistics) SET @Schema_Stats=(SELECT TOP 1 schemaname FROM #tempstatistics) SET @StatUpdateCommand='Update Statistics [' + @DatabaseName_Stats + '].[' + @Schema_Stats + '].[' + @Table_Stats + '] with fullscan' EXEC Sp_executesql @StatUpdateCommand SET @example@sqldat.com + 1 DELETE FROM #tempstatistics WHERE databasename = @DatabaseName_Stats AND tablename = @Table_Stats AND schemaname = @Schema_Stats END SET @example@sqldat.com + 1 DELETE FROM #tempdatabases WHERE databasename = @DBName END
Zodra de uitvoering van het script is voltooid, worden alle tijdelijke tabellen verwijderd.
SELECT * FROM #tempstatistics DROP TABLE #tempdatabases DROP TABLE #tempstatistics
Het volledige script zal er als volgt uitzien:
--set count on CREATE PROCEDURE Statistics_maintenance AS BEGIN DECLARE @databasename VARCHAR(500) DECLARE @i INT=0 DECLARE @DBCOunt INT DECLARE @SQLCOmmand NVARCHAR(max) DECLARE @StatsUpdateCOmmand NVARCHAR(max) CREATE TABLE #tempstatistics ( databasename VARCHAR(max), tablename VARCHAR(max), schemaname VARCHAR(max) ) CREATE TABLE #tempdatabases ( databasename VARCHAR(max) ) INSERT INTO #tempdatabases (databasename) SELECT NAME FROM sys.databases WHERE database_id > 4 ORDER BY NAME SET @DBCOunt=(SELECT Count(*) FROM #tempdatabases) WHILE ( @i < @DBCOunt ) BEGIN DECLARE @DBName VARCHAR(max) SET @DBName=(SELECT TOP 1 databasename FROM #tempdatabases) SET @SQLCOmmand= ' use [' + @DBName + ']; select distinct ''' + @DBName+ ''', a.TableName,a.SchemaName from (SELECT obj.name as TableName, b.name as SchemaName,obj.object_id, stat.name, stat.stats_id, last_updated, modification_counter FROM [' + @DBName+ '].sys.objects AS obj inner join ['+ @DBName + '].sys.schemas b on obj.schema_id=b.schema_id INNER JOIN [' + @DBName+ '].sys.stats AS stat ON stat.object_id = obj.object_id CROSS APPLY [' + @DBName+'].sys.dm_db_stats_properties(stat.object_id, stat.stats_id) AS sp WHERE modification_counter > 200 and obj.name not like ''sys%''and b.name not like ''sys%'')a' INSERT INTO #tempstatistics (databasename, tablename, schemaname) EXEC Sp_executesql @SQLCOmmand DECLARE @j INT=0 DECLARE @StatCount INT SET @StatCount =(SELECT Count(*) FROM #tempstatistics) WHILE @J < @StatCount BEGIN DECLARE @DatabaseName_Stats VARCHAR(max) DECLARE @Table_Stats VARCHAR(max) DECLARE @Schema_Stats VARCHAR(max) DECLARE @StatUpdateCommand NVARCHAR(max) SET @DatabaseName_Stats=(SELECT TOP 1 databasename FROM #tempstatistics) SET @Table_Stats=(SELECT TOP 1 tablename FROM #tempstatistics) SET @Schema_Stats=(SELECT TOP 1 schemaname FROM #tempstatistics) SET @StatUpdateCommand='Update Statistics [' + @DatabaseName_Stats + '].[' + @Schema_Stats + '].[' + @Table_Stats + '] with fullscan' EXEC Sp_executesql @StatUpdateCommand SET @example@sqldat.com + 1 DELETE FROM #tempstatistics WHERE databasename = @DatabaseName_Stats AND tablename = @Table_Stats AND schemaname = @Schema_Stats END SET @example@sqldat.com + 1 DELETE FROM #tempdatabases WHERE databasename = @DBName END SELECT * FROM #tempstatistics DROP TABLE #tempdatabases DROP TABLE #tempstatistics END
U kunt dit script ook automatiseren door een SQL Server Agent-taak te maken die het op een gepland tijdstip uitvoert. Hieronder vindt u een stapsgewijze instructie om deze taak te automatiseren.
Een SQL-taak maken
Laten we eerst een SQL-taak maken om het proces te automatiseren. Open hiervoor SSMS, maak verbinding met de gewenste server en vouw SQL Server Agent uit, klik met de rechtermuisknop op Vacatures en selecteer Nieuwe baan . 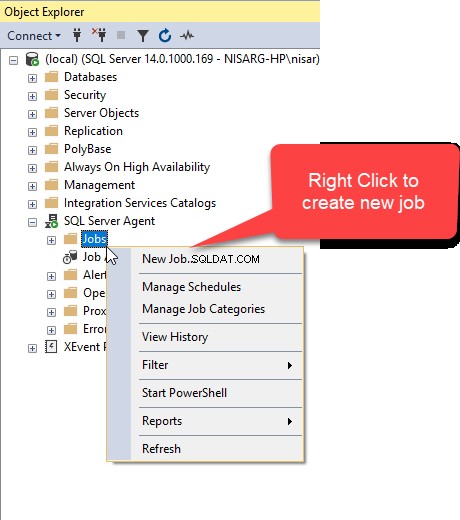 In de Nieuwe baan typt u de gewenste naam in de Naam veld.
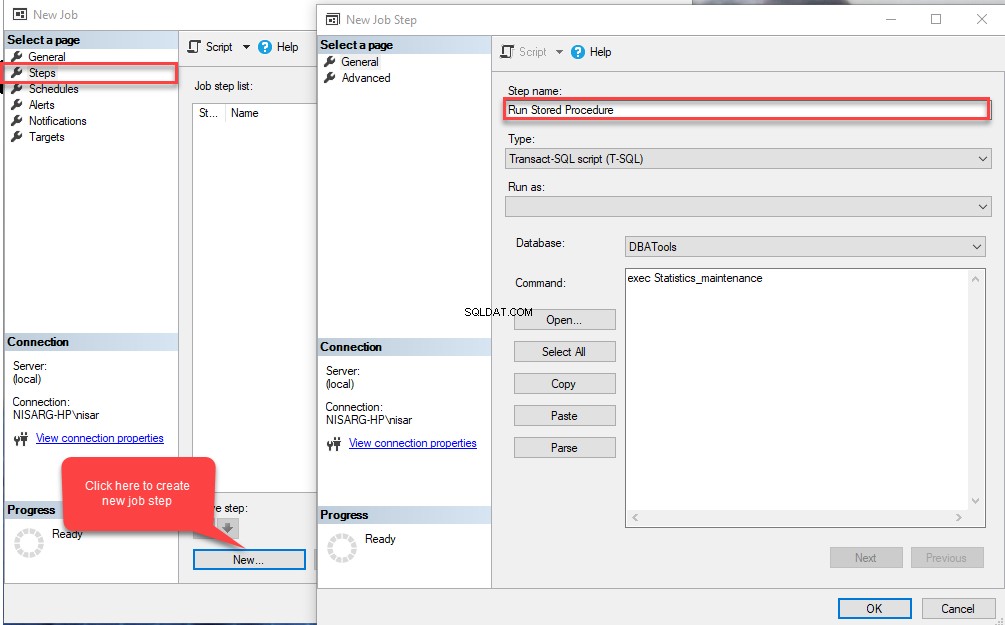
In de Nieuwe baan typt u de gewenste naam in de Naam veld. 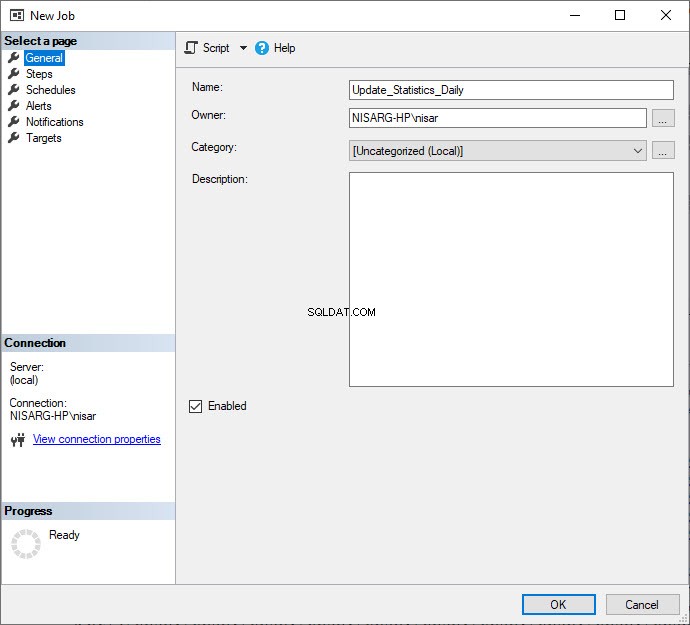 Klik nu op Stappen menu-optie in het linkerdeelvenster van de Nieuwe taak dialoogvenster en klik vervolgens op Nieuw in de Stappen raam. In de Nieuwe taakstap dialoogvenster dat wordt geopend, geeft u de gewenste naam op in de Stapnaam veld. Selecteer vervolgens Transact-SQL-script (T-SQL) in het Type vervolgkeuzelijst. Selecteer vervolgens DBATools in de Database vervolgkeuzelijst en schrijf de volgende vraag in het opdrachttekstvak:
Klik nu op Stappen menu-optie in het linkerdeelvenster van de Nieuwe taak dialoogvenster en klik vervolgens op Nieuw in de Stappen raam. In de Nieuwe taakstap dialoogvenster dat wordt geopend, geeft u de gewenste naam op in de Stapnaam veld. Selecteer vervolgens Transact-SQL-script (T-SQL) in het Type vervolgkeuzelijst. Selecteer vervolgens DBATools in de Database vervolgkeuzelijst en schrijf de volgende vraag in het opdrachttekstvak:
EXEC Statistics_maintenance
 Klik op Schedules om de planning van de taak te configureren menu-optie in de Nieuwe taak dialoog venster. Het Nieuwe takenschema dialoogvenster wordt geopend. In de Naam veld, geef de gewenste planningsnaam op. In ons voorbeeld willen we dat deze taak elke nacht om 01.00 uur wordt uitgevoerd, dus in de Occurs vervolgkeuzelijst in de Frequentie sectie, selecteer Dagelijks . In de Gebeurt een keer om veld in de Dagelijkse frequentie sectie, voer 01:00:00 in.
Klik op Schedules om de planning van de taak te configureren menu-optie in de Nieuwe taak dialoog venster. Het Nieuwe takenschema dialoogvenster wordt geopend. In de Naam veld, geef de gewenste planningsnaam op. In ons voorbeeld willen we dat deze taak elke nacht om 01.00 uur wordt uitgevoerd, dus in de Occurs vervolgkeuzelijst in de Frequentie sectie, selecteer Dagelijks . In de Gebeurt een keer om veld in de Dagelijkse frequentie sectie, voer 01:00:00 in. 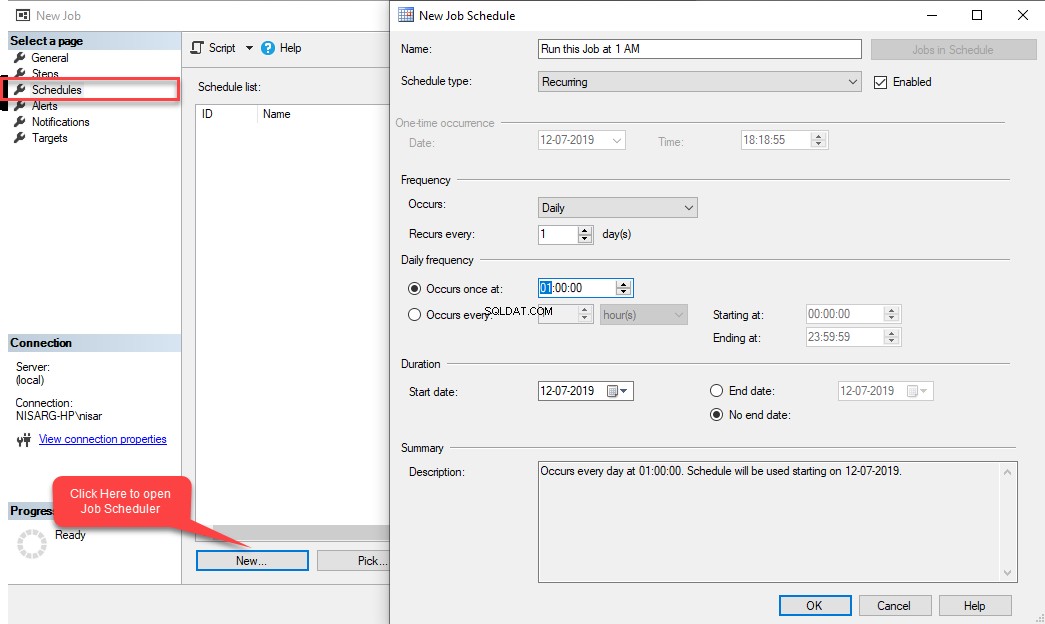 Klik op OK om het Nieuw taakschema te sluiten venster en klik vervolgens op OK opnieuw in de Nieuwe baan dialoogvenster om het te sluiten. Laten we nu deze baan testen. Klik onder SQL Server Agent met de rechtermuisknop op Update_Statistics_Daily .
Klik op OK om het Nieuw taakschema te sluiten venster en klik vervolgens op OK opnieuw in de Nieuwe baan dialoogvenster om het te sluiten. Laten we nu deze baan testen. Klik onder SQL Server Agent met de rechtermuisknop op Update_Statistics_Daily . 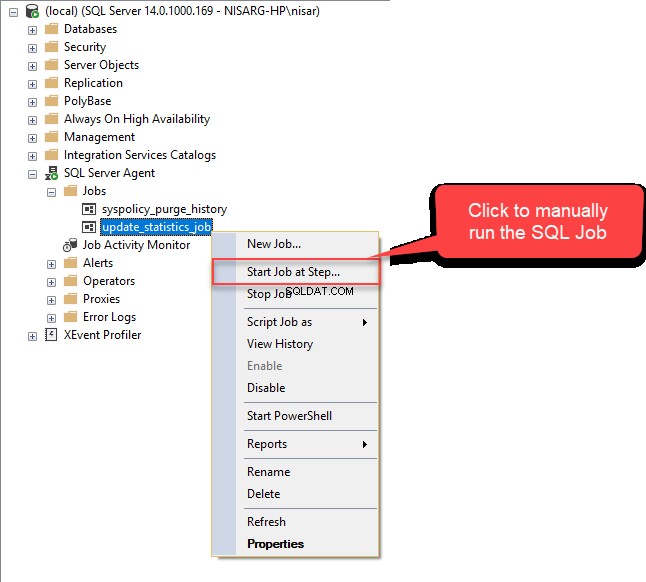 Als de taak met succes is uitgevoerd, ziet u het volgende venster.
Als de taak met succes is uitgevoerd, ziet u het volgende venster. 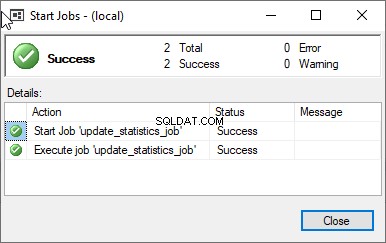
Samenvatting
In dit artikel zijn de volgende problemen behandeld:1. Hoe u de statistieken van tabellen kunt bijwerken met behulp van T-SQL Script. 2. Hoe informatie te verkrijgen over veranderingen in datavolume en frequentie van dataveranderingen. 3. Hoe u het script maakt dat statistieken over actieve tabellen bijwerkt. 4. Hoe maak je een SQL Server Agent Job aan om het script op het geplande tijdstip uit te voeren.