Stel dat u een SQL Server-databasetoepassing ontwerpt voor de CEO van een bedrijf en dat u de vijfde best betaalde werknemer in het bedrijf moet weergeven.
Wat zou jij doen? Een oplossing is om een query als deze te schrijven:
SELECT EmployeeName FROM Employees ORDER BY Salary DESC OFFSET 4 ROWS FETCH FIRST 1 ROWS ONLY;
De bovenstaande zoekopdracht ziet er omslachtig uit, vooral als u alle werknemers moet rangschikken. In dat geval is een oplossing om de werknemers in aflopende volgorde van salaris te rangschikken en vervolgens de index van de werknemer als rang te nemen. Het wordt echter ingewikkeld als de meerdere werknemers hetzelfde salaris hebben. Hoe zou je ze rangschikken?
Gelukkig wordt SQL Server geleverd met ingebouwde rangschikkingsfuncties die kunnen worden gebruikt om records op verschillende manieren te rangschikken. In dit artikel zullen we de rangschikkingsfuncties van SQL-servers in detail introduceren en dit illustreren met de voorbeelden.
Er zijn vier verschillende soorten rangschikkingsfuncties in SQL Server:
- Rang()
- Dense_Rank()
- Rijnummer()
- Ntile()
Het is belangrijk om te vermelden dat alle rangschikkingsfuncties in de SQL-server de ORDER BY-clausule vereisen.
Voordat we elk van de rangschikkingsfuncties in detail bekijken, laten we eerst dummy-gegevens maken die we in dit artikel zullen gebruiken om de rangschikkingsfunctie uit te leggen. Voer het volgende script uit:
CREATE DATABASE Showroom
Use Showroom
CREATE TABLE Car
(
CarId int identity(1,1) primary key,
Name varchar(100),
Make varchar(100),
Model int ,
Price int ,
Type varchar(20)
)
insert into Car( Name, Make, Model , Price, Type)
VALUES ('Corrolla','Toyota',2015, 20000,'Sedan'),
('Civic','Honda',2018, 25000,'Sedan'),
('Passo','Toyota',2012, 18000,'Hatchback'),
('Land Cruiser','Toyota',2017, 40000,'SUV'),
('Corrolla','Toyota',2011, 17000,'Sedan'),
('Vitz','Toyota',2014, 15000,'Hatchback'),
('Accord','Honda',2018, 28000,'Sedan'),
('7500','BMW',2015, 50000,'Sedan'),
('Parado','Toyota',2011, 25000,'SUV'),
('C200','Mercedez',2010, 26000,'Sedan'),
('Corrolla','Toyota',2014, 19000,'Sedan'),
('Civic','Honda',2015, 20000,'Sedan') In het bovenstaande script creëren we Showroom-database met één tafelwagen. De tabel Auto heeft vijf kenmerken:CarId, naam, merk, model, prijs en type.
Vervolgens hebben we 12 dummy-records toegevoegd aan de tabel Car.
Nu zie je alle rangschikkingsfuncties.
1. Rangfunctie
De rangfunctie in SQL-server kent rang toe aan elk record dat is besteld door de ORDER BY-clausule. Als u bijvoorbeeld de vijfde duurste auto in de tabel Auto wilt zien, kunt u de rangschikkingsfunctie als volgt gebruiken:
Use Showroom SELECT Name,Make,Model, Price, Type, RANK() OVER(ORDER BY Price DESC) as PriceRank FROM Car
Selecteer in het bovenstaande script de naam, het merk, het model, de prijs, het type en de rangorde van elke auto die is besteld op prijs als de kolom 'Prijsrangschikking'. De syntaxis voor de functie Rang is eenvoudig. U moet de functie RANK schrijven gevolgd door de operator OVER. Binnen de OVER-operator moet u de ORDER BY-component doorgeven die de gegevens sorteert. De uitvoer van het bovenstaande script ziet er als volgt uit:
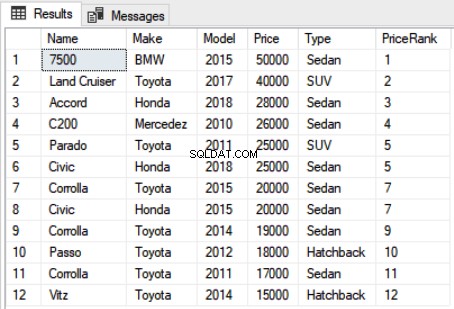
U kunt de rangorde voor elke auto zien. Het is belangrijk om te vermelden dat als er een gelijkspel is tussen de rangen van twee records, de volgende rankingpositie wordt overgeslagen. Zo is er een gelijkspel tussen record 5 en 6 in de output. Zowel de Parado als de Civic hebben gelijke prijzen en zijn daarom gerangschikt als 5. De volgende rang, in het bijzonder rang 6, wordt echter overgeslagen en de volgende twee auto's in de lijst zijn gerangschikt 7 omdat ze ook dezelfde prijs hebben. Na de 7e rang wordt de rang 8 weer overgeslagen en de volgende toegewezen rang is 9.
U kunt de gegevens in partities verdelen en vervolgens classificatie toepassen op afzonderlijke partities. In het volgende script is er de verdeling van de records op type. We rangschikken de auto's binnen elke partitie.
SELECT Name,Make,Model, Price, Type, RANK() OVER(PARTITION BY Type ORDER BY Price DESC) as PriceRank FROM Car
De uitvoer van het bovenstaande script ziet er als volgt uit:
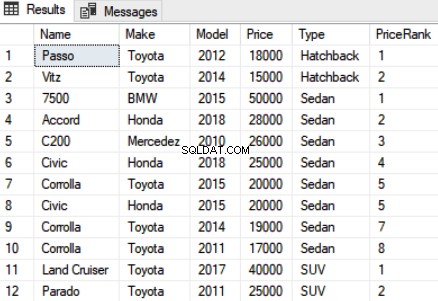
Uit de output blijkt dat de records zijn gepartitioneerd volgens autotypes en dat de rang lokaal binnen de partitie is toegewezen. De eerste twee records behoren bijvoorbeeld tot partitie "Hatchback" en zijn gerangschikt op 1 en 2. Voor de volgende partitie, d.w.z. "Sedan", wordt de rangorde teruggezet naar 1.
2. Functie Dichte_Rank
De functie density_rank is vergelijkbaar met de rank-functie. Als er echter een gelijkspel is tussen twee records in termen van rangorde, wordt de volgende rangorde niet overgeslagen in het geval van density_rank. Laten we eens kijken om het te demonstreren met het voorbeeld. Voer het volgende script uit:
Use Showroom SELECT Name,Make,Model, Price, Type, DENSE_RANK() OVER(ORDER BY Price DESC) as DensePriceRank FROM Car
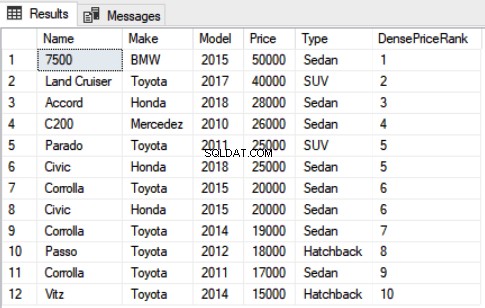
Nogmaals, je kunt zien dat het 5e en 6e record dezelfde waarde hebben voor Prijs en beide hebben rang 5 toegewezen gekregen. Echter, in tegenstelling tot rangfunctie die de volgende rang oversloeg, slaat de dichte_rangfunctie de volgende rang niet over, en de rang 6 is toegewezen aan de volgende record.
Net als de rangfunctie kan de functie density_rank ook worden toegepast op de partitie per clausule. Bekijk het volgende script:
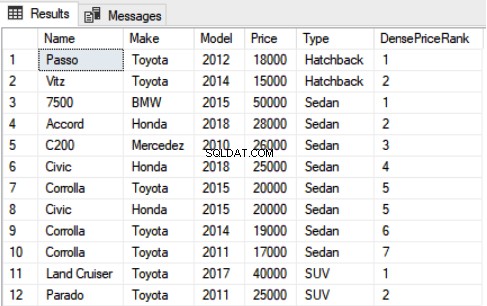
SELECT Name,Make,Model, Price, Type, DENSE_RANK() OVER(PARTITION BY Type ORDER BY Price DESC) as DensePriceRank FROM Car
De uitvoer van het bovenstaande script ziet er als volgt uit:
3. Functie Row_Number
De functie row_number rangschikt de records ook volgens de voorwaarden die zijn gespecificeerd door de ORDER BY-component. In tegenstelling tot de functies rank en density_rank, wijst de functie row_number echter niet dezelfde rang toe als er dubbele waarden zijn voor de kolom die is gespecificeerd door de ORDER BY-component. Bekijk het volgende script:
SELECT Name,Make,Model, Price, Type, DENSE_RANK() OVER(PARTITION BY Type ORDER BY Price DESC) as DensePriceRank FROM Car
De uitvoer van het bovenstaande script ziet er als volgt uit:
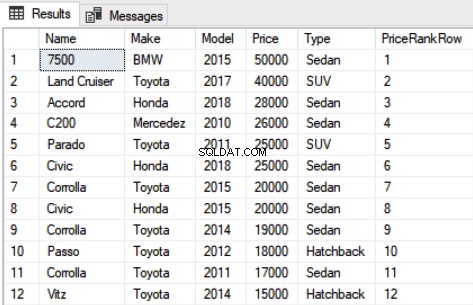
In het bovenstaande script kun je zien dat zowel de 5e als de 6e records dezelfde waarde hebben voor de kolom Prijs, maar de rang die eraan is toegewezen is anders.
Evenzo kan de functie rijnummer worden toegepast op de gepartitioneerde gegevens. Kijk bijvoorbeeld naar het volgende script.
SELECT Name,Make,Model, Price, Type, ROW_NUMBER() OVER(PARTITION BY Type ORDER BY Price DESC) AS PriceRankRow FROM Car
De uitvoer van het bovenstaande script ziet er als volgt uit:
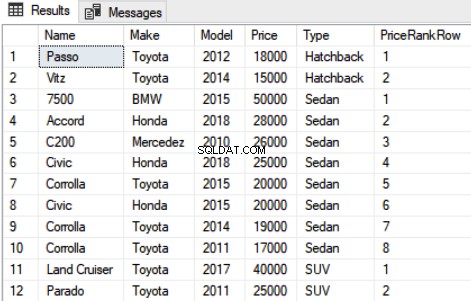
4. NTILE-functie
NTILE-functie groepeert de rangorde. Stel dat u 12 records in een tabel heeft en u wilt ze in groepen van 4 rangschikken. De eerste drie records hebben rang 1, de volgende drie records hebben rang 2 enzovoort.
Laten we eens kijken naar een voorbeeld van de NTILE-functie.
Use Showroom SELECT Name,Make,Model, Price, Type, NTILE(4) OVER(ORDER BY Price DESC) as NtilePrice FROM Car
In het bovenstaande script hebben we 4 als parameter doorgegeven aan de NTILE-functie. Aangezien we 12 records hebben, ziet u in totaal 4 verschillende rangen waarbij 1 rang wordt toegewezen aan drie records. De uitvoer ziet er als volgt uit:
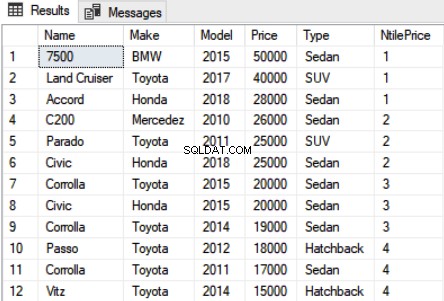
Je kunt zien dat de eerste drie duurste auto's op nummer 1 staan, de volgende drie op nummer 2 enzovoort.
De NTILE-functie kan ook worden toegepast op de gepartitioneerde gegevens. Bekijk het volgende script:
SELECT Name,Make,Model, Price, Type, NTILE(4) OVER(PARTITION BY Type ORDER BY Price DESC) as NtilePrice FROM Car
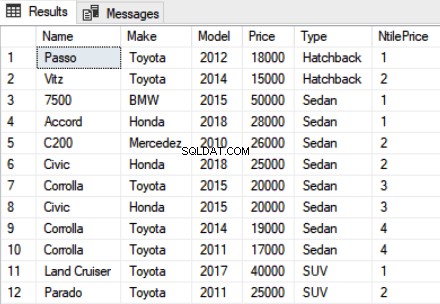
Conclusie
Rangschikkingsfuncties in SQL Server worden gebruikt om gegevens op verschillende manieren te rangschikken. In deze lezing hebben we verschillende soorten rangschikkingsfuncties geïntroduceerd met de voorbeelden. De functies rank en density_rank geven dezelfde rangorde aan de gegevens met dezelfde waarden in de ORDER BY-component, terwijl de functie row_number het record incrementeel rangschikt, zelfs als er een gelijkspel is.
In het geval er geen dubbele records in de opgegeven kolom zijn door de ORDER BY-clausule gedragen de functies rank, density_rank en row_number zich op een vergelijkbare manier.