Inleiding
Een tabel is een logische structuur. Wanneer u een tabel maakt, maakt het u doorgaans niet uit op welke schijven deze zich in de opslaglaag bevindt. Als u echter een databasebeheerder bent, kan deze kennis essentieel worden als u bepaalde databasegedeelten naar een alternatieve opslag of volume moet verplaatsen. Dan wilt u misschien dat bepaalde tabellen op een bepaald volume of een bepaalde set schijven staan.
Bestandsgroepen in SQL Server bieden die abstractielaag waarmee we de fysieke locatie van onze logische structuren kunnen controleren - tabellen, indexen, enz.
Bestandsgroepen
Een bestandsgroep is een logische structuur voor het groeperen van gegevensbestanden in SQL Server. Als we een bestandsgroep maken en deze koppelen aan een set gegevensbestanden, zal elk logisch object dat op die bestandsgroep wordt gemaakt zich fysiek op die set fysieke bestanden bevinden.
Het primaire doel van een dergelijke fysieke bestandsgroepering is gegevenstoewijzing en gegevensplaatsing. We willen bijvoorbeeld dat onze transactiegegevens op één set snelle schijven worden opgeslagen. Tegelijkertijd hebben we de historische gegevens nodig die zijn opgeslagen op een andere set goedkopere schijven. In een dergelijk scenario zouden we de Tran . maken tabel op de TXN-bestandsgroep en de TranHist tabel op een andere HIST-bestandsgroep. Verderop in dit artikel zullen we zien hoe dit zich vertaalt in het hebben van gegevens op verschillende schijven.
Bestandsgroepen maken
De syntaxis voor het maken van bestandsgroepen wordt weergegeven in Lijst 1 . Opmerking :De databasecontext is de master databank. Bij het uitgeven van de instructies wijzigen we de DB2-database door er nieuwe bestandsgroepen aan toe te voegen. In wezen zijn deze bestandsgroepen op dit moment slechts logische constructies. Ze bevatten geen gegevens.
-- Listing 1: Creating File Groups
USE [master]
GO
ALTER DATABASE [DB2] ADD FILEGROUP [HIST]
GO
ALTER DATABASE [DB2] ADD FILEGROUP [TXN]
GO
Bestanden aan bestandsgroepen toevoegen
De volgende stap is het toevoegen van een bestand aan elk van de bestandsgroepen. We kunnen meer dan één bestand toevoegen, maar we houden het eenvoudig voor demonstratiedoeleinden. Merk op dat elk bestand zich volledig op een andere schijf bevindt, en de syntaxis stelt ons in staat om de beoogde bestandsgroep te specificeren.
-- Listing 2: Adding Files to Filegroups
USE [master]
GO
ALTER DATABASE [DB2] ADD FILE ( NAME = N'DB2_HIST_01', FILENAME = N'E:\MSSQL\Data\DB2_HIST_01.ndf' , SIZE = 102400KB , FILEGROWTH = 131072KB ) TO FILEGROUP [HIST]
GO
ALTER DATABASE [DB2] ADD FILE ( NAME = N'DB2_TXN_01', FILENAME = N'C:\MSSQL\Data\DB2_TXN_01.ndf' , SIZE = 102400KB , FILEGROWTH = 131072KB ) TO FILEGROUP [TXN]
GO
Tabellen maken voor bestandsgroepen
Hier zorgen we ervoor dat tabellen op de gewenste schijven staan. De syntaxis voor het maken van tabellen stelt ons in staat om de gewenste bestandsgroep te specificeren.
-- Listing 3: Creating a table on Filegroups TXN and HIST
USE [DB2]
GO
CREATE TABLE [dbo].[tran](
[TranID] [int] NULL
,TranTime [datetime]
,TranAmt [money]
) ON [TXN]
GO
CREATE CLUSTERED INDEX [IX_Clustered01] ON [dbo].[tran]
(
[TranID] ASC
) ON [TXN]
GO
CREATE TABLE [dbo].[tranhist](
[TranID] [int] NULL
,TranTime [datetime]
,TranAmt [money]
) ON [HIST]
GO
Door een stap terug te doen, stellen we vast dat we nu het volgende hebben bereikt:
- Twee bestandsgroepen gemaakt.
- Bepaald welke gegevensbestanden (en schijven) aan elke bestandsgroep zijn gekoppeld.
- Bepaalde de tabellen die bij elke bestandsgroep horen.
In wezen is de bestandsgroep de abstractielaag .
Controleren op welke bestandsgroepen onze tabellen staan
Om te controleren tot welke bestandsgroep elke tabel behoort, voeren we de code in Listing 4 uit. We gebruiken twee hoofdweergaven van de systeemcatalogus:sys.indexes en sys.data_spaces . De sys.data_spaces catalogusweergave bevat informatie over bestandsgroepen en partities, en de belangrijkste logische structuren waarin tabellen en indexen worden opgeslagen.
Opmerking:we hebben geen gebruik gemaakt van sys.tables . De SQL Server associeert indexen in een tabel met gegevensruimten in plaats van tabellen, zoals we intuïtief zouden kunnen denken.
-- Listing 4: Check the filegroup of an index or table
USE DB2
GO
select object_name(i.object_id) [Table Name]
, i.name [Index Name]
, i.type_desc [Index Type]
, d.name [FileGroup]
from sys.indexes i inner join sys.data_spaces d
on i.data_space_id=d.data_space_id
where d.name<>'PRIMARY'
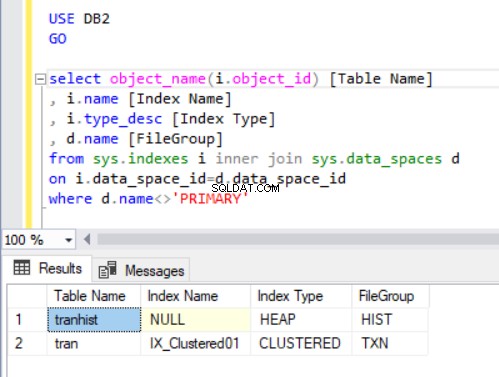
De uitvoer van de query in Listing 4 toont twee tabellen die we zojuist hebben gemaakt. Merk op dat de tranhist tabel heeft geen index. Toch verschijnt het in de resultatenset, geïdentificeerd als een hoop .
Een hoop is een tabel die geen geclusterde index heeft die de ordergegevens bepaalt die fysiek in een tabel zijn opgeslagen. Er kan slechts één geclusterde index in een tabel zijn.
De Tran-tabel vullen
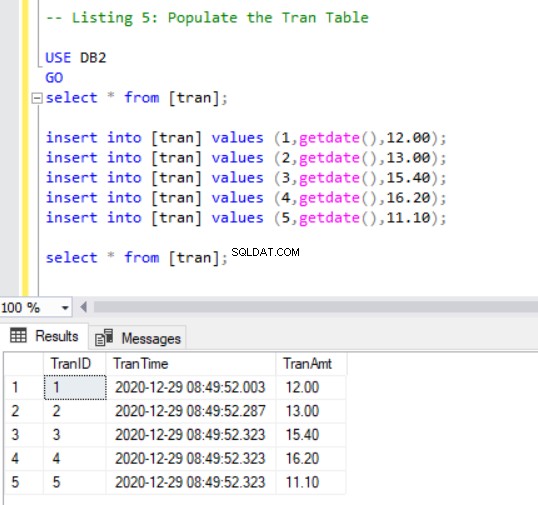
Nu moeten we een paar records toevoegen aan de tran tabel met de volgende code:
-- Listing 5: Populate the Tran Table
USE DB2
GO
SELECT * FROM [tran];
INSERT INTO [tran] VALUES (1, GETDATE(),12.00);
INSERT INTO [tran] VALUES (2, GETDATE(),13.00);
INSERT INTO [tran] VALUES (3, GETDATE(),15.40);
INSERT INTO [tran] VALUES (4, GETDATE(),16.20);
INSERT INTO [tran] VALUES (5, GETDATE(),11.10);
SELECT * FROM [tran];
Een tabel naar een andere bestandsgroep verplaatsen
De tran verplaatsen tabel naar een andere bestandsgroep, hoeven we alleen de geclusterde index opnieuw op te bouwen en specificeer de nieuwe bestandsgroep tijdens het opnieuw opbouwen. Lijst 5 laat deze benadering zien.
We voeren twee stappen uit:eerst de index laten vallen en vervolgens opnieuw maken. Tussendoor controleren we of de gegevens en de locatie van de twee tabellen die we eerder hebben gemaakt intact blijven.
-- Listing 6: Check what filegroup an index or table belongs to
USE [DB2]
GO
DROP INDEX [IX_Clustered01] ON [dbo].[tran] WITH ( ONLINE = OFF )
GO
CREATE CLUSTERED INDEX [IX_Clustered01] ON [dbo].[tran]
(
[TranID] ASC
) ON [HIST]
GO
Door de geclusterde index van de tran tabel, we hebben het geconverteerd naar een heap :
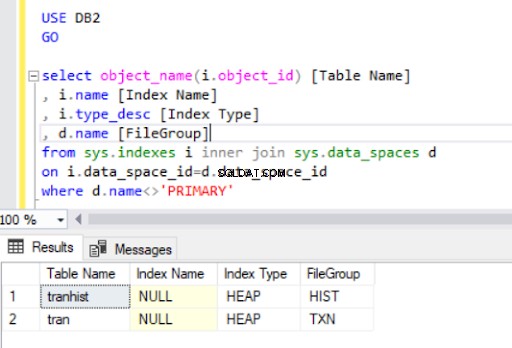
Wanneer we de geclusterde index opnieuw maken, wordt deze ook aangegeven in de uitvoer van Listing 4.
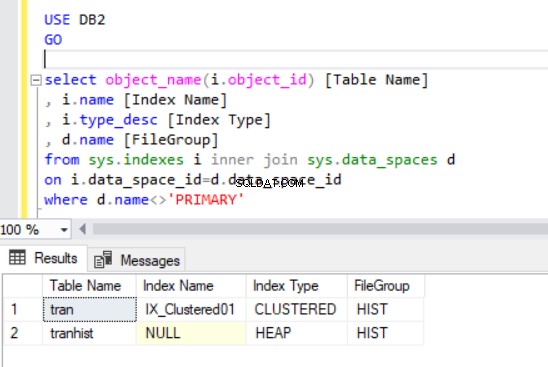
Nu hebben we de tran tabel in de HIST-bestandsgroep.
Conclusie
Dit artikel demonstreerde de relatie tussen tabellen, indexen, bestanden en bestandsgroepen in termen van onze SQL Server-gegevensopslag. We hebben ook uitgelegd hoe u een tabel van de ene bestandsgroep naar de andere verplaatst door de geclusterde index opnieuw te maken.
Deze vaardigheid is handig wanneer u gegevens naar nieuwe opslag moet migreren (snellere schijven of langzamere schijven voor archivering). In meer geavanceerde scenario's kunt u bestandsgroepen gebruiken om de gegevenslevenscyclus te beheren door tabelpartities te implementeren.
Referenties
- Databasebestanden en bestandsgroepen
- Tabelpartities uitschakelen - een oplossing