Onlangs werkte ik aan een verbeteringsproject voor databaseprestaties. Een opgeslagen procedure daar veroorzaakte problemen. In zijn code vulde een query het aantal rijen in en sloeg de waarde op in een lokale variabele. Die query scande een grote tabel. Als gevolg daarvan werd het gebruik van hulpbronnen aanzienlijk hoger. Om het probleem op te lossen, hebben we de foutieve code verwijderd en de SQL Server-catalogusweergaven gebruikt om het aantal rijen van de tabel te genereren.
Er zijn verschillende manieren om het aantal rijen in een tabel van SQL Server te tellen. Dit artikel beschrijft ze zodat je altijd de juiste manier kunt kiezen om het te doen.
We kunnen het aantal rijen van de tabel verkrijgen met een van de volgende methoden:
- Gebruik COUNT() functie.
- SQL Server-catalogusweergaven combineren.
- Gebruik sp_spaceused opgeslagen procedure.
- SQL Server Management-studio gebruiken.
Laten we dieper graven.
Haal het aantal rijen op met COUNT(*) of Count(1)
We kunnen de functie AANTAL(*) of AANTAL(1) gebruiken – de resultaten die door deze twee functies worden gegenereerd, zijn identiek.
Om het aantal rijen te krijgen, laten we eerst de query uitvoeren met COUNT(*). Voor demonstratiedoeleinden heb ik de waarde van STATISTICS IO ingesteld op ON.
USE wideworldimporters
go
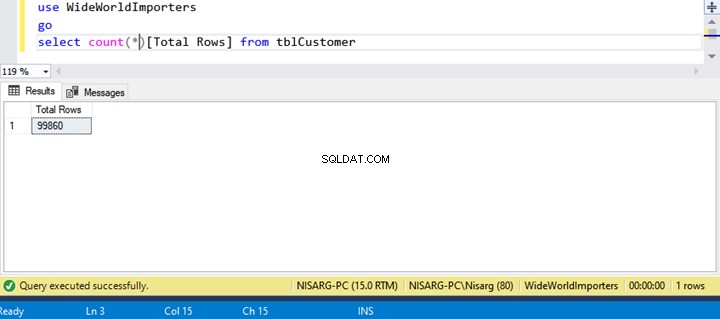
SELECT Count(*)
FROM tblcustomer
go
Uitvoer:
IO-statistieken:
Table 'tblCustomer'. Scan count 1, logical reads 691, physical reads 315, page server reads 0, read-ahead reads 276, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.Zoals je kunt zien, moet de SQL Server 691 logische reads uitvoeren om aan het resultaat te voldoen.
Laten we nu de query uitvoeren met COUNT(1):
USE wideworldimporters
go
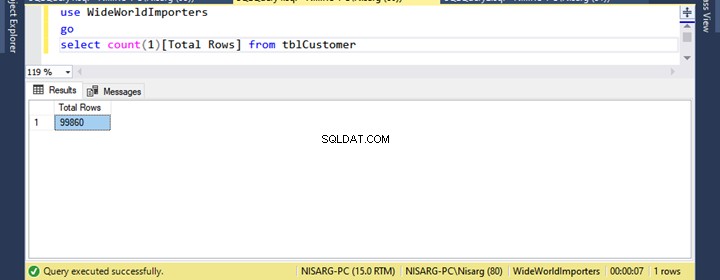
SELECT Count(1)
FROM tblcustomer
go
Uitvoer:
IO-statistieken:
Table 'tblCustomer'. Scan count 1, logical reads 691, physical reads 687, page server reads 0, read-ahead reads 687, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.Nogmaals, SQL Server moet 691 logische reads uitvoeren om aan het resultaat te voldoen.
We moeten vermelden dat er een mening is dat de functie Count (1) sneller is dan de functie Count (*). Zoals u in de bovenstaande voorbeelden kunt zien, zijn de resultatensets en IO-statistieken echter hetzelfde. Daarom kunt u elke methode gebruiken om het aantal rijen van tabellen te genereren.
Pluspunten:
De COUNT-functie vult een nauwkeurig aantal rijen uit de tabel.
Nadelen:
Wanneer u de COUNT-functie uitvoert, wordt er een slot op de tafel geplaatst. Andere query's die toegang krijgen tot de tabel moeten wachten tot het resultaat is gegenereerd. Als u op een druk systeem werkt met een tabel met miljoenen rijen, kunt u de functie AANTAL tijdens kantooruren beter vermijden, tenzij u het exacte aantal rijen van de tabel moet invullen.
SQL Server-catalogusweergaven combineren
We kunnen SQL Server-catalogusweergaven gebruiken met de volgende dynamische beheerweergaven:
- sys.tables – vult de lijst met tabellen.
- sys.indexes – vult de lijst met indexen van de tabel.
- sys.partities – vult de rijen van elke partitie.
Voer het volgende script uit om het aantal rijen te krijgen:
SELECT a.NAME,
c.NAME,
Sum(b.rows)
FROM sys.tables a
INNER JOIN sys.partitions b
ON a.object_id = b.object_id
INNER JOIN sys.indexes c
ON b.index_id = c.index_id
AND b.object_id = c.object_id
WHERE a.object_id = Object_id('tblCustomer')
AND c.index_id < 2
Uitvoer:
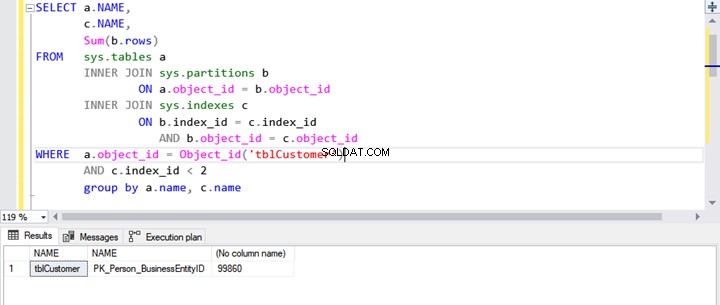
De zoekopdracht vult de tabelnaam , indexnaam, en totaal aantal rijen in alle partities.
Laten we nu eens kijken naar de IO-statistieken:
Table 'syssingleobjrefs'. Scan count 3, logical reads 6, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
Table 'sysidxstats'. Scan count 1, logical reads 6, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
Table 'sysschobjs'. Scan count 0, logical reads 4, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
Table 'sysrowsets'. Scan count 2, logical reads 14, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
Zoals u kunt zien, voert de query slechts 30 logische uitlezingen uit.
Pluspunten:
Deze aanpak is sneller dan de COUNT-functie. Het krijgt geen slot op de gebruikerstafel, dus je kunt het gebruiken in een druk systeem.
Nadelen:
De methode vult bij benadering het aantal rijen in. In de Microsoft-documentatie van sys.partitions kunt u zien dat de rijen kolom geeft het geschatte aantal rijen voor de partities.
Dus als u op zoek bent naar een query die het resultaat sneller oplevert dan de COUNT-functie, kunt u deze gebruiken. Het resultaat kan echter onnauwkeurig zijn.
Gebruik sp_spaceused
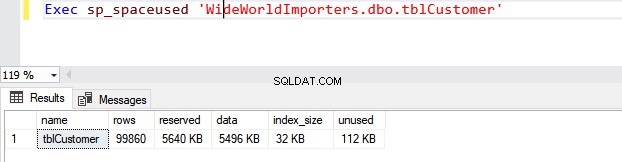
De sp_spaceused procedure samen met het aantal rijen geeft de volgende details:
- Naam – de tabelnaam
- Rijen – het aantal rijen in een tabel.
- Gereserveerd – de totale gereserveerde ruimte voor een tafel.
- Gegevens – de totale ruimte die door de tafel wordt gebruikt.
- Index_size – de totale ruimte die door de index wordt gebruikt.
- Ongebruikt – de totale gereserveerde ruimte voor een tafel die niet wordt gebruikt.
De syntaxis is:
EXEC Sp_spaceused 'database_name.schema_name.table_name' De vraag:
EXEC Sp_spaceused 'WideWorldImportors.dbo.tblCustomer' Uitvoer:
Gebruik SQL Server Management Studio
Om het aantal rijen van de tabel te krijgen, kunnen we SQL Server Management Studio gebruiken.
Open SQL Server Management studio> Maak verbinding met de database-instantie> Vouw Tabellen uit> Klik met de rechtermuisknop op tblCustomer> Eigenschappen
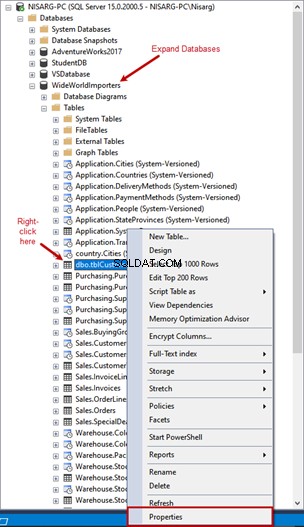
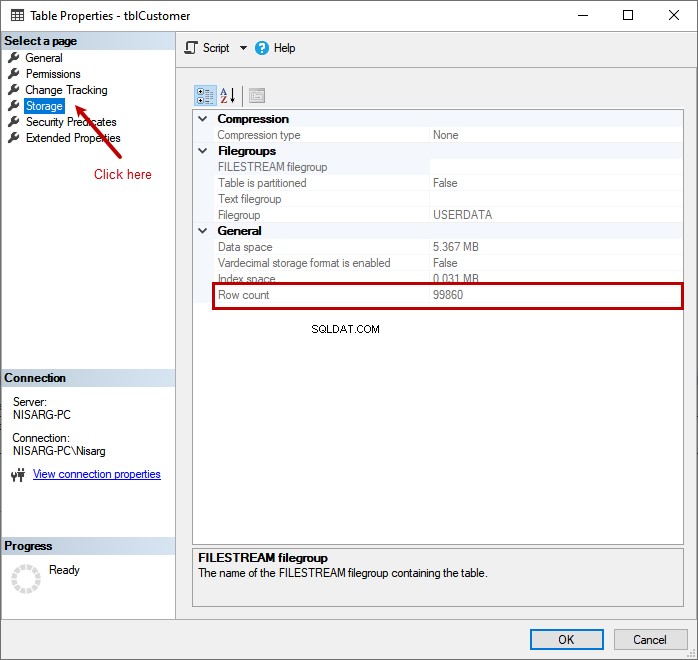
In de Tabel Eigenschappen venster, klik op Opslag . U ziet het aantal rijen waarde aan de rechterkant:
Een andere optie om het aantal rijen in een tabel te krijgen, wordt geleverd met de SQL Complete SSMS-invoegtoepassing. Met deze verbetering kunt u het geschatte aantal rijen in een hint zien wanneer u de muisaanwijzer over een tabelnaam beweegt in het venster Objectverkenner. Op deze manier kunt u zonder extra inspanningen de benodigde gegevens in een visuele modus krijgen.
Conclusie
In dit artikel worden verschillende benaderingen uitgelegd voor het berekenen van het totale aantal rijen van de tabel, met name:
- De COUNT-functie gebruiken.
- Verschillende catalogusweergaven combineren.
- Gebruik sp_spaceused opgeslagen procedure.
- SQL Server Management-studio gebruiken.
Het is niet nodig om je aan slechts één methode te houden. Elke variant heeft zijn specifieke kenmerken en u kunt degene toepassen die het beste bij uw situatie past.