U gebruikt de overerving (ook bekend in entiteit-relatiemodellering als 'subklasse' of 'categorie'). Over het algemeen zijn er 3 manieren om het in de database weer te geven:
- "Alle klassen in één tabel": Heb slechts één tabel die de bovenliggende en alle onderliggende klassen "beslaat" (d.w.z. met alle bovenliggende en onderliggende kolommen), met een beperking CHECK om ervoor te zorgen dat de juiste subset van velden niet-NULL is (d.w.z. twee verschillende kinderen "vermengen zich niet").
- "Betonklasse per tafel": Zorg voor een andere tafel voor elk kind, maar geen bovenliggende tafel. Dit vereist dat de ouderrelaties (in jouw geval Inventory <- Storage) worden herhaald bij alle kinderen.
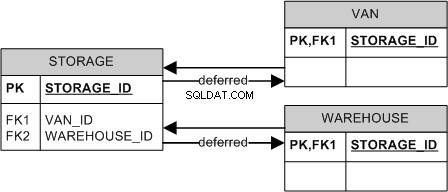
- "Klasse per tafel": Het hebben van een bovenliggende tafel en een aparte tafel voor elk kind, dat is wat u probeert te doen. Dit is het schoonst, maar kan wat prestaties kosten (meestal bij het wijzigen van gegevens, niet zozeer bij het opvragen omdat je rechtstreeks vanuit een kind kunt deelnemen en de ouder kunt overslaan).
Ik geef meestal de voorkeur aan de derde benadering, maar dwing zowel de aanwezigheid . af en de exclusiviteit van een kind op toepassingsniveau. Beide op databaseniveau afdwingen is een beetje omslachtig, maar kan worden gedaan als het DBMS uitgestelde beperkingen ondersteunt. Bijvoorbeeld:
CHECK (
(
(VAN_ID IS NOT NULL AND VAN_ID = STORAGE_ID)
AND WAREHOUSE_ID IS NULL
)
OR (
VAN_ID IS NULL
AND (WAREHOUSE_ID IS NOT NULL AND WAREHOUSE_ID = STORAGE_ID)
)
)
Dit zal zowel de exclusiviteit (vanwege de CHECK ) en de aanwezigheid (door de combinatie van CHECK en FK1 /FK2 ) van het kind.
Helaas ondersteunt MS SQL Server geen uitgestelde beperkingen, maar u kunt mogelijk de hele bewerking achter opgeslagen procedures "verbergen" en clients verbieden de tabellen rechtstreeks te wijzigen.
Alleen de exclusiviteit kan worden afgedwongen zonder uitgestelde beperkingen:
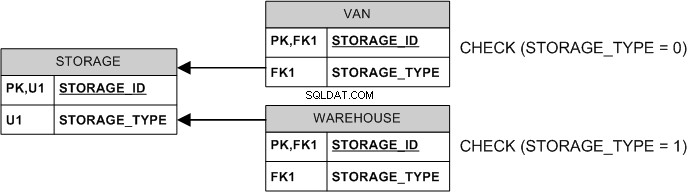
De STORAGE_TYPE is een typediscriminator, meestal een geheel getal om ruimte te besparen (in het bovenstaande voorbeeld zijn 0 en 1 "bekend" bij uw toepassing en dienovereenkomstig geïnterpreteerd).
De VAN.STORAGE_TYPE en WAREHOUSE.STORAGE_TYPE kan worden berekend (ook bekend als "berekende") kolommen om opslag te besparen en de noodzaak van de CHECK te vermijden v.
--- BEWERKEN ---
Berekende kolommen zouden als volgt onder SQL Server werken:
CREATE TABLE STORAGE (
STORAGE_ID int PRIMARY KEY,
STORAGE_TYPE tinyint NOT NULL,
UNIQUE (STORAGE_ID, STORAGE_TYPE)
);
CREATE TABLE VAN (
STORAGE_ID int PRIMARY KEY,
STORAGE_TYPE AS CAST(0 as tinyint) PERSISTED,
FOREIGN KEY (STORAGE_ID, STORAGE_TYPE) REFERENCES STORAGE(STORAGE_ID, STORAGE_TYPE)
);
CREATE TABLE WAREHOUSE (
STORAGE_ID int PRIMARY KEY,
STORAGE_TYPE AS CAST(1 as tinyint) PERSISTED,
FOREIGN KEY (STORAGE_ID, STORAGE_TYPE) REFERENCES STORAGE(STORAGE_ID, STORAGE_TYPE)
);
-- We can make a new van.
INSERT INTO STORAGE VALUES (100, 0);
INSERT INTO VAN VALUES (100);
-- But we cannot make it a warehouse too.
INSERT INTO WAREHOUSE VALUES (100);
-- Msg 547, Level 16, State 0, Line 24
-- The INSERT statement conflicted with the FOREIGN KEY constraint "FK__WAREHOUSE__695C9DA1". The conflict occurred in database "master", table "dbo.STORAGE".
Helaas vereist SQL Server een berekende kolom die wordt gebruikt in een vreemde sleutel die moet worden volgehouden. Andere databases hebben deze beperking mogelijk niet (bijvoorbeeld de virtuele kolommen van Oracle), wat opslagruimte kan besparen.