Het antwoord zal natuurlijk zijn "het hangt ervan af", maar op basis van het testen van dit doel...
Ervan uitgaande dat
- 1 miljoen producten
productheeft een geclusterde index opproduct_id- De meeste (zo niet alle) producten hebben overeenkomstige informatie in de
product_codetafel - Ideale indexen aanwezig op
product_codevoor beide vragen.
De PIVOT versie heeft idealiter een index product_code(product_id, type) INCLUDE (code) terwijl de JOIN versie heeft idealiter een index product_code(type,product_id) INCLUDE (code)
Als deze aanwezig zijn, geef dan de onderstaande plannen
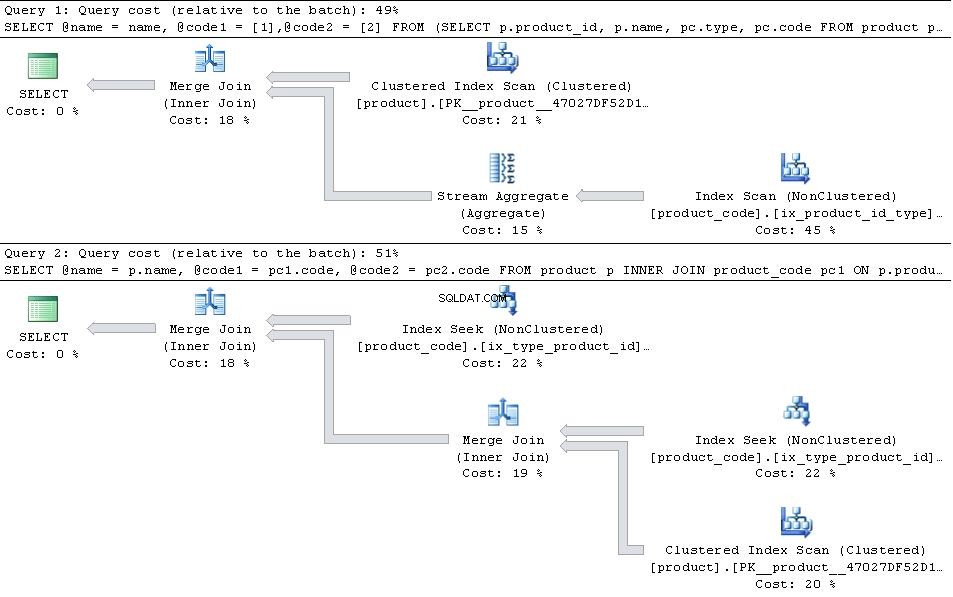
dan de JOIN versie is efficiënter.
In het geval dat type 1 en type 2 zijn de enige types in de tabel dan de PIVOT versie heeft een klein voordeel wat betreft het aantal reads omdat het niet in product_code hoeft te zoeken twee keer, maar dat wordt ruimschoots gecompenseerd door de extra overhead van de stroomaggregaatbeheerder
DRAAIEN
Table 'product_code'. Scan count 1, logical reads 10467
Table 'product'. Scan count 1, logical reads 4750
CPU time = 3297 ms, elapsed time = 3260 ms.
DOE MEE
Table 'product_code'. Scan count 2, logical reads 10471
Table 'product'. Scan count 1, logical reads 4750
CPU time = 1906 ms, elapsed time = 1866 ms.
Als er extra type zijn andere records dan 1 en 2 de JOIN versie zal zijn voordeel vergroten omdat het alleen merge joins doet op de relevante secties van het type,product_id index terwijl de PIVOT abonnement gebruikt product_id, type en dus zou moeten scannen over het extra type rijen die vermengd zijn met de 1 en 2 rijen.