Zodra u een databaseserver begint te gebruiken en uw gebruik groeit, wordt u blootgesteld aan vele soorten technische problemen, prestatievermindering en databasestoringen. Elk van deze kan leiden tot veel grotere problemen, zoals catastrofale storingen of gegevensverlies. Het is als een kettingreactie, waarbij het één tot het ander kan leiden, wat steeds meer problemen veroorzaakt. Er moeten proactieve tegenmaatregelen worden genomen om ervoor te zorgen dat u zo lang mogelijk een stabiele omgeving heeft.
In deze blogpost gaan we kijken naar een aantal coole functies die worden aangeboden door ClusterControl die ons enorm kunnen helpen bij het oplossen van problemen met onze MySQL-database wanneer ze zich voordoen.
Database alarmen en meldingen
Voor alle ongewenste gebeurtenissen logt ClusterControl alles onder Alarmen, toegankelijk op de Activiteit (Top Menu) van de ClusterControl-pagina. Dit is meestal de eerste stap om te beginnen met het oplossen van problemen als er iets misgaat. Vanaf deze pagina kunnen we een idee krijgen van wat er werkelijk aan de hand is met ons databasecluster:
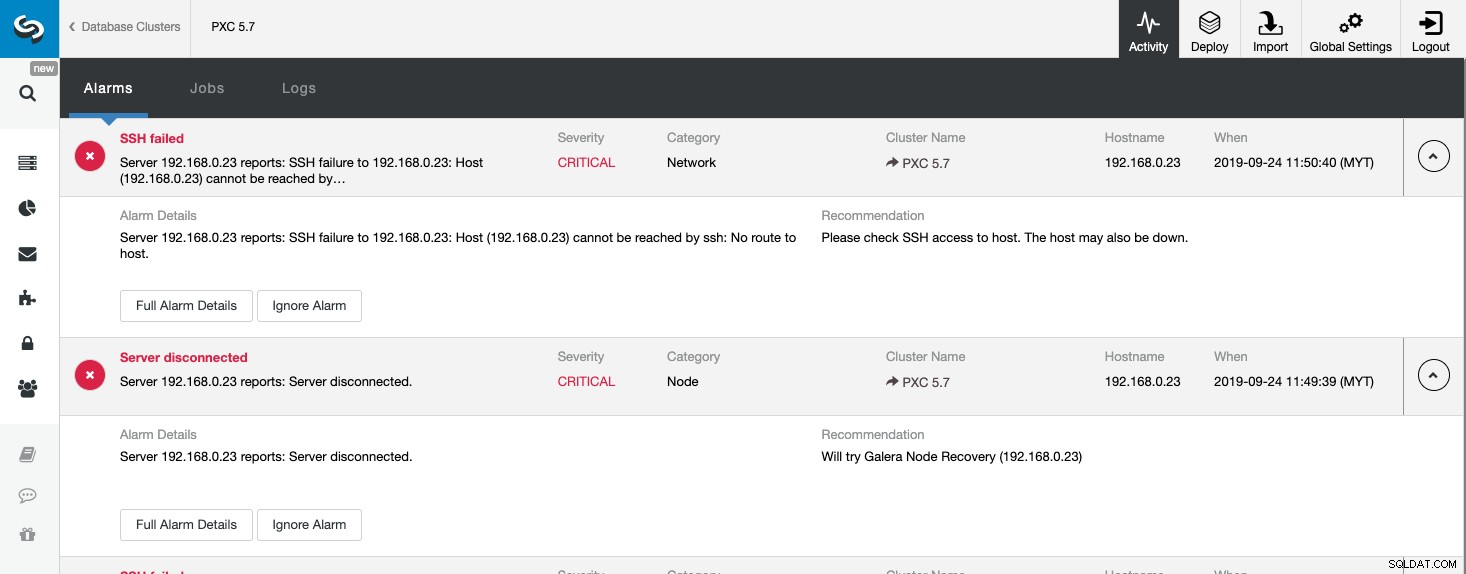
De bovenstaande schermafbeelding toont een voorbeeld van een onbereikbare servergebeurtenis, met de ernst KRITIEK , gedetecteerd door twee componenten, Network en Node. Als u de instelling voor e-mailmeldingen hebt geconfigureerd, zou u een kopie van deze alarmen in uw mailbox moeten krijgen.
Als u op "Volledige alarmdetails" klikt, kunt u de belangrijke details van het alarm krijgen, zoals hostnaam, tijdstempel, clusternaam enzovoort. Het biedt ook de volgende aanbevolen stap die moet worden genomen. U kunt dit alarm ook als e-mail verzenden naar andere ontvangers die zijn geconfigureerd onder Instellingen voor e-mailmeldingen.
U kunt er ook voor kiezen om een alarm uit te zetten door op de knop "Alarm negeren" te klikken. Het zal dan niet meer in de lijst verschijnen. Het negeren van een alarm kan handig zijn als u een alarm van lage ernst heeft en weet hoe u dit moet aanpakken of omzeilen. Bijvoorbeeld als ClusterControl een dubbele index in uw database detecteert, die in sommige gevallen nodig zou zijn voor uw legacy-applicaties.
Door naar deze pagina te kijken, krijgen we direct inzicht in wat er aan de hand is met ons databasecluster en wat de volgende stap is om het probleem op te lossen. Zoals in dit geval ging een van de databaseknooppunten uit en werd onbereikbaar via SSH vanaf de ClusterControl-host. Zelfs een beginnende SysAdmin weet nu wat hij moet doen als dit alarm verschijnt.
Gecentraliseerde database-logbestanden
Hier kunnen we uitzoeken wat er mis was met onze databaseserver. Onder ClusterControl -> Logboeken -> Systeemlogboeken kunt u alle logbestanden zien die betrekking hebben op het databasecluster. Wat betreft op MySQL gebaseerde databasecluster, ClusterControl haalt het ProxySQL-logboek, MySQL-foutlogboek en back-uplogboeken op:
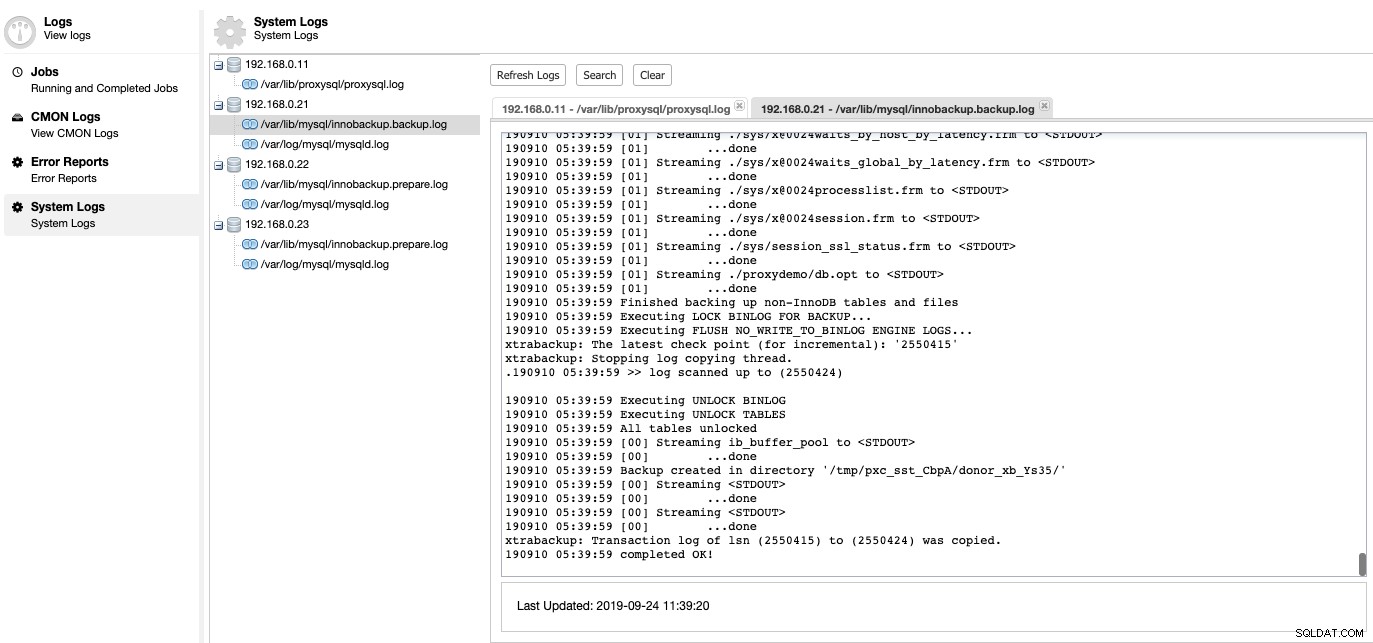
Klik op "Refresh Log" om de laatste log op te halen van alle hosts die op dat moment toegankelijk zijn. Als een node onbereikbaar is, zal ClusterControl nog steeds de verouderde login bekijken, aangezien deze informatie is opgeslagen in de CMON-database. ClusterControl blijft standaard elke 10 minuten de systeemlogs ophalen, configureerbaar onder Instellingen -> Loginterval.
ClusterControl activeert de taak om het laatste logboek van elke server op te halen, zoals weergegeven in de volgende taak "Logboeken verzamelen":
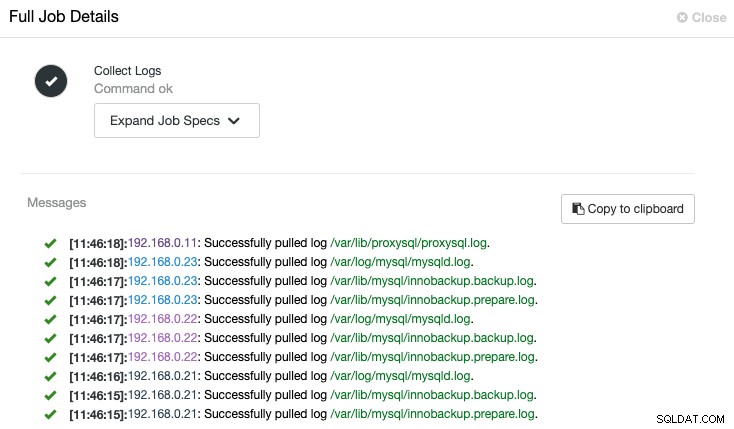
Een gecentraliseerde weergave van het logbestand stelt ons in staat sneller te begrijpen wat er is gebeurd mis. Voor een databasecluster waarbij vaak meerdere knooppunten en lagen betrokken zijn, zal deze functie het lezen van logboeken aanzienlijk verbeteren, waarbij een SysAdmin deze logboeken naast elkaar kan vergelijken en kritieke gebeurtenissen kan lokaliseren, waardoor de totale tijd voor het oplossen van problemen wordt verkort.
Web SSH-console
ClusterControl biedt een webgebaseerde SSH-console, zodat u rechtstreeks toegang hebt tot de DB-server via de gebruikersinterface van ClusterControl (aangezien de SSH-gebruiker is geconfigureerd om verbinding te maken met de databasehosts). Van hieruit kunnen we veel meer informatie verzamelen waardoor we het probleem nog sneller kunnen oplossen. Iedereen weet dat wanneer een databaseprobleem het productiesysteem bereikt, elke seconde downtime telt.
Om via internet toegang te krijgen tot de SSH-console, kiest u eenvoudig de knooppunten onder Knooppunten -> Knooppuntacties -> SSH-console, of klikt u op het tandwielpictogram voor een snelkoppeling:
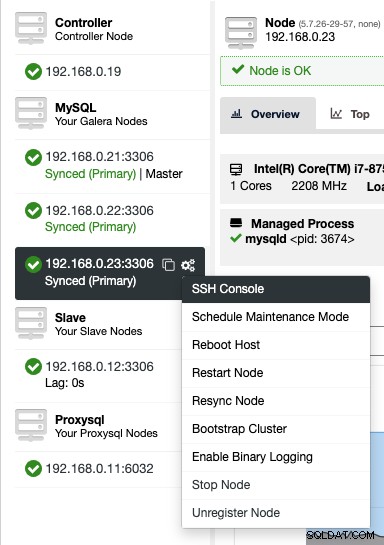
Vanwege veiligheidsproblemen die met deze functie kunnen optreden, vooral voor -user of multi-tenant omgeving, men kan het uitschakelen door naar /var/www/html/clustercontrol/bootstrap.php op de ClusterControl-server te gaan en de volgende constante in te stellen op false:
define('SSH_ENABLED', false);Vernieuw de ClusterControl UI-pagina om de nieuwe wijzigingen te laden.
Kwesties met databaseprestaties
Afgezien van monitoring- en trendingfuncties, stuurt ClusterControl u proactief verschillende alarmen en adviseurs met betrekking tot databaseprestaties, bijvoorbeeld:
- Overmatig gebruik - Bron die bepaalde drempels overschrijdt, zoals CPU, geheugen, swapgebruik en schijfruimte.
- Clusterdegradatie - Cluster- en netwerkpartitionering.
- Systeemtijdafwijking - Tijdsverschil tussen alle knooppunten in het cluster (inclusief ClusterControl-knooppunt).
- Diverse andere MySQL-gerelateerde adviseurs:
- Replicatie - replicatievertraging, verlopen binlog, locatie en groei
- Galera - SST-methode, scan GRA-logbestand, clusteradrescontrole
- Schemacontrole - niet-transactionele tabel op Galera Cluster.
- Verbindingen - Verhouding schroefdraadverbinding
- InnoDB - verhouding vuile pagina's, groei InnoDB-logbestanden
- Langzame zoekopdrachten - ClusterControl zal standaard alarm slaan als een zoekopdracht langer dan 30 seconden wordt uitgevoerd. Dit is natuurlijk configureerbaar onder Instellingen -> Runtime-configuratie -> Lange zoekopdracht.
- Deadlocks - InnoDB-transacties impasse en Galera-impasse.
- Indexen - Dubbele sleutels, tabel zonder primaire sleutels.
Bekijk de pagina Adviseurs onder Prestaties -> Adviseurs voor de details van dingen die kunnen worden verbeterd, zoals voorgesteld door ClusterControl. Voor elke adviseur geeft het rechtvaardigingen en advies, zoals weergegeven in het volgende voorbeeld voor de adviseur "Gebruik van schijfruimte controleren":
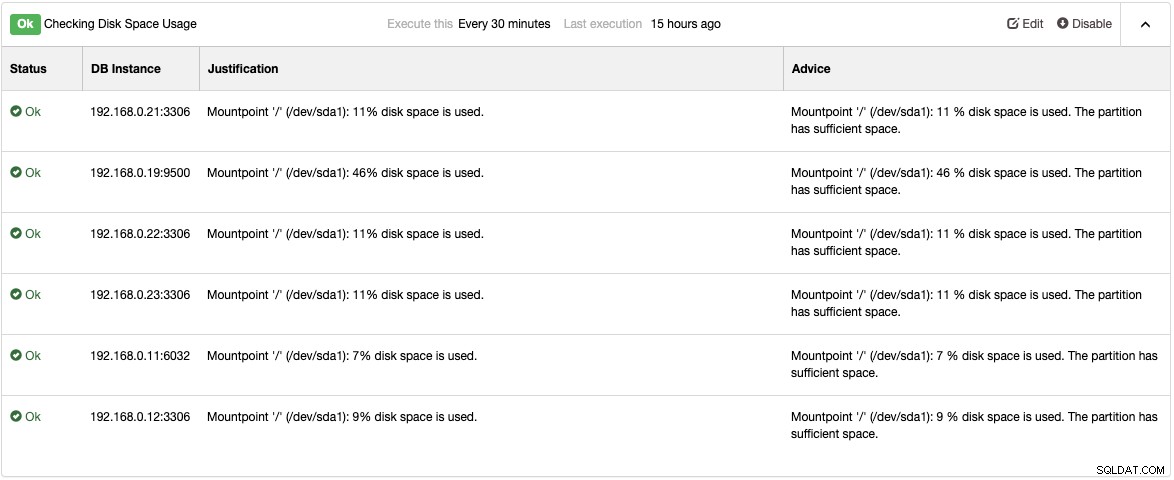
Als zich een prestatieprobleem voordoet, krijgt u een "Waarschuwing" (geel) of "Kritieke" (rode) status op deze adviseurs. Verdere afstemming is vaak nodig om het probleem op te lossen. Adviseurs alarmeren, wat betekent dat gebruikers een kopie van deze alarmen in de mailbox krijgen als e-mailmeldingen dienovereenkomstig zijn geconfigureerd. Voor elk alarm dat door ClusterControl of haar adviseurs wordt geuit, krijgen gebruikers ook een e-mail als het alarm is opgeheven. Deze zijn voorgeconfigureerd binnen ClusterControl en vereisen geen initiële configuratie. Verder maatwerk is altijd mogelijk onder Beheren -> Developer Studio. Je kunt deze blogpost lezen over hoe je je eigen adviseur kunt schrijven.
ClusterControl biedt ook een speciale pagina met betrekking tot databaseprestaties onder ClusterControl -> Prestaties. Het biedt allerlei soorten database-inzichten volgens de best practices, zoals een gecentraliseerde weergave van DB-status, variabelen, InnoDB-status, Schema Analyzer, transactielogboeken. Deze zijn vrij duidelijk en eenvoudig te begrijpen.
Voor queryprestaties kunt u Topquery's en Query-uitschieters inspecteren, waarbij ClusterControl query's markeert die aanzienlijk verschillen van hun gemiddelde query. We hebben dit onderwerp in detail behandeld in deze blogpost, MySQL Query Performance Tuning.
Databasefoutrapporten
ClusterControl wordt geleverd met een hulpprogramma voor het genereren van foutenrapporten, waarmee u foutopsporingsinformatie over uw databasecluster kunt verzamelen om de huidige situatie en status beter te begrijpen. Om een foutenrapport te genereren, gaat u naar ClusterControl -> Logs -> Error Reports -> Create Error Report:
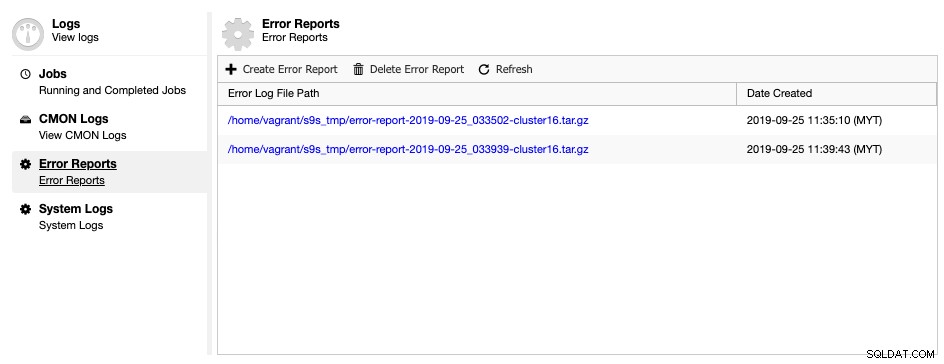
Het gegenereerde foutenrapport kan zodra het gereed is vanaf deze pagina worden gedownload. Dit gegenereerde rapport heeft de TAR-ball-indeling (tar.gz) en u kunt het bij een ondersteuningsverzoek voegen. Aangezien het ondersteuningsticket de limiet heeft van 10 MB bestandsgrootte, als de tarball-grootte groter is dan dat, kunt u het uploaden naar een clouddrive en alleen de downloadlink met de juiste toestemming met ons delen. U kunt het later verwijderen zodra we het bestand al hebben. U kunt het foutenrapport ook genereren via de opdrachtregel, zoals uitgelegd op de documentatiepagina van het foutenrapport.
In het geval van een storing raden we u ten zeerste aan om meerdere foutrapporten te genereren tijdens en direct na de storing. Deze rapporten zijn zeer nuttig om te proberen te begrijpen wat er is misgegaan, wat de gevolgen zijn van de storing en om te verifiëren of het cluster na een rampzalige gebeurtenis weer in de operationele status is.
Conclusie
Proactieve monitoring van ClusterControl, samen met een reeks functies voor probleemoplossing, bieden gebruikers een efficiënt platform om problemen met MySQL-databases op te lossen. De traditionele manier om problemen op te lossen is allang voorbij, waarbij men meerdere SSH-sessies moet openen om toegang te krijgen tot meerdere hosts en meerdere opdrachten herhaaldelijk moet uitvoeren om de oorzaak te achterhalen.
Als de bovengenoemde functies u niet helpen bij het oplossen van het probleem of het oplossen van het databaseprobleem, neem dan altijd contact op met het ondersteuningsteam van verschillendenines om u te helpen. Onze toegewijde technische experts 24/7/365 zijn beschikbaar om op elk moment aan uw verzoek te voldoen. Onze gemiddelde eerste antwoordtijd is meestal minder dan 30 minuten.