We hebben onlangs verschillende blogs geschreven over hoe verschillende cloudproviders met database-failover omgaan. We vergeleken de failover-prestaties in Amazon Aurora, Amazon RDS en ClusterControl, testten het failover-gedrag in Amazon RDS en ook op Google Cloud Platform. Hoewel deze services geweldige opties bieden als het gaat om failover, zijn ze misschien niet geschikt voor elke toepassing.
In deze blogpost zullen we wat tijd besteden aan het analyseren van de voor- en nadelen van het gebruik van de DBaaS-oplossingen in vergelijking met het handmatig ontwerpen van een omgeving of met behulp van een databasebeheerplatform, zoals ClusterControl.
Implementatie van databases met hoge beschikbaarheid met beheerde oplossingen
De belangrijkste reden om bestaande oplossingen te gebruiken is gebruiksgemak. U kunt met slechts een paar klikken een maximaal beschikbare oplossing met geautomatiseerde failover implementeren. Het is niet nodig om verschillende tools te combineren, de databases met de hand te beheren, tools te implementeren, scripts te schrijven, de monitoring te ontwerpen of andere databasebeheeractiviteiten. Alles is al op zijn plaats. Dit kan de leercurve aanzienlijk verkorten en vereist minder ervaring om een zeer beschikbare omgeving voor de databases op te zetten; waardoor in principe iedereen dergelijke instellingen kan implementeren.
In de meeste gevallen wordt bij deze oplossingen het failoverproces binnen een redelijke tijd uitgevoerd. Het kan razendsnel zijn zoals bij Amazon Aurora of iets langzamer zoals bij Google Cloud Platform SQL-knooppunten. In de meeste gevallen zijn dit soort resultaten acceptabel.
Het komt erop neer. Als je 30 - 60 seconden downtime kunt accepteren, zou je in orde moeten zijn met een van de DBaaS-platforms.
Het nadeel van het gebruik van een beheerde oplossing voor HA
Hoewel DBaaS-oplossingen eenvoudig te gebruiken zijn, hebben ze ook enkele ernstige nadelen. Om te beginnen is er altijd een vendor lock-in component om te overwegen. Als je eenmaal een cluster in Amazon Web Services hebt geïmplementeerd, is het behoorlijk lastig om uit die provider te migreren. Er zijn geen gemakkelijke methoden om de volledige dataset te downloaden via een fysieke back-up. Bij de meeste providers zijn alleen handmatig uitgevoerde logische back-ups beschikbaar. Natuurlijk zijn er altijd opties om dit te bereiken, maar het is meestal een complex, tijdrovend proces, dat toch enige downtime kan vergen.
Het gebruik van een provider als Amazon RDS brengt ook beperkingen met zich mee. Sommige acties kunnen niet eenvoudig worden uitgevoerd, wat heel eenvoudig zou zijn in omgevingen die volledig door de gebruiker worden beheerd (bijv. AWS EC2). Sommige van deze beperkingen zijn al behandeld in andere blogs, maar om samen te vatten:geen enkele DBaaS-service biedt u hetzelfde niveau van flexibiliteit als gewone MySQL GTID-gebaseerde replicatie. Je kunt elke slaaf promoten, je kunt elk knooppunt opnieuw tot slaaf maken van een ander... vrijwel elke actie is mogelijk. Met tools zoals RDS heb je te maken met door het ontwerp veroorzaakte beperkingen die je niet kunt omzeilen.
Het probleem zit hem ook in het vermogen om prestatiedetails te begrijpen. Wanneer u uw eigen configuratie met hoge beschikbaarheid ontwerpt, krijgt u kennis over mogelijke prestatieproblemen die zich kunnen voordoen. Aan de andere kant zijn RDS en vergelijkbare omgevingen vrijwel 'zwarte dozen'. Ja, we hebben vernomen dat Amazon RDS DRBD gebruikt om een schaduwkopie van de master te maken, we weten dat Aurora gedeelde, gerepliceerde opslag gebruikt om zeer snelle failovers te implementeren. Dat is slechts een algemene kennis. We kunnen niet zeggen wat de prestatie-implicaties zijn van die oplossingen, behalve wat we terloops zouden kunnen opmerken. Wat zijn veelvoorkomende problemen die ermee samenhangen? Hoe stabiel zijn die oplossingen? Alleen de ontwikkelaars achter de oplossing weten het zeker.
Wat is het alternatief voor DBaaS-oplossingen?
Je vraagt je misschien af, is er een alternatief voor DBaaS? Het is tenslotte zo handig om de beheerde service uit te voeren waar u via de gebruikersinterface toegang hebt tot de meeste typische acties. U kunt back-ups maken en terugzetten, failover wordt automatisch voor u afgehandeld. De omgeving is gebruiksvriendelijk, wat aantrekkelijk kan zijn voor bedrijven die geen toegewijd en ervaren personeel hebben voor het omgaan met databases.
ClusterControl biedt een geweldig alternatief voor cloudgebaseerde DBaaS-services. Het biedt u een grafische gebruikersinterface die kan worden gebruikt voor het implementeren, beheren en bewaken van open source-databases.
In een paar klikken kunt u eenvoudig een zeer beschikbare databasecluster implementeren, met geautomatiseerde failover (sneller dan de meeste DBaaS-aanbiedingen), back-upbeheer, geavanceerde bewaking en andere functies zoals integratie met externe tools (bijv. Slack of PagerDuty) of upgradebeheer. Dit alles terwijl vendor lock-in volledig wordt vermeden.
ClusterControl maakt het niet uit waar uw databases zich bevinden, zolang het er maar verbinding mee kan maken via SSH. U kunt setups hebben in de cloud, on-prem of in een gemengde omgeving van meerdere cloudproviders. Zolang er connectiviteit is, kan ClusterControl de omgeving beheren. Door de oplossingen te gebruiken die u wilt (en niet degene die u niet kent of kent), kunt u op elk moment de volledige controle over de omgeving krijgen.
Welke setup je ook hebt geïmplementeerd met ClusterControl, je kunt het gemakkelijk beheren op een meer traditionele, handmatige of gescripte manier. ClusterControl biedt u zelfs een opdrachtregelinterface, waarmee u taken die door ClusterControl worden uitgevoerd, in uw shellscripts kunt opnemen. Je hebt alle controle die je wilt - niets is een zwarte doos, elk onderdeel van de omgeving zou worden gebouwd met behulp van open source-oplossingen die samen worden gecombineerd en geïmplementeerd door ClusterControl.
Laten we eens kijken hoe gemakkelijk u een MySQL-replicatiecluster kunt implementeren met ClusterControl. Laten we aannemen dat u de omgeving hebt voorbereid met ClusterControl geïnstalleerd op één instantie en alle andere knooppunten die toegankelijk zijn via SSH vanaf de ClusterControl-host.
We beginnen met het kiezen van de wizard 'Deploy'.
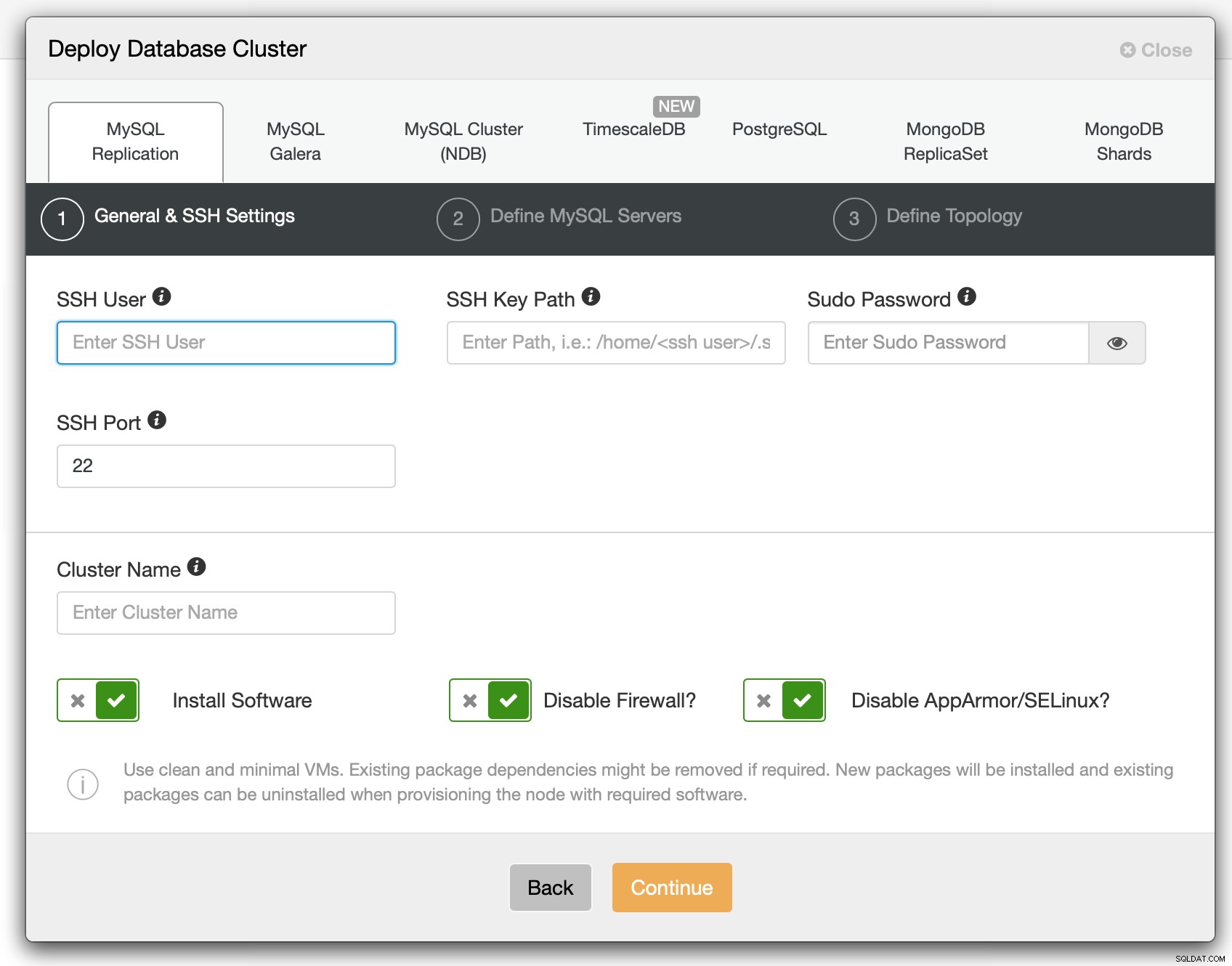
Bij de eerste stap moeten we definiëren hoe ClusterControl verbinding moet maken met de knooppunten waarop databases moeten worden ingezet. Zowel root-toegang als sudo (met of zonder het wachtwoord) worden ondersteund.
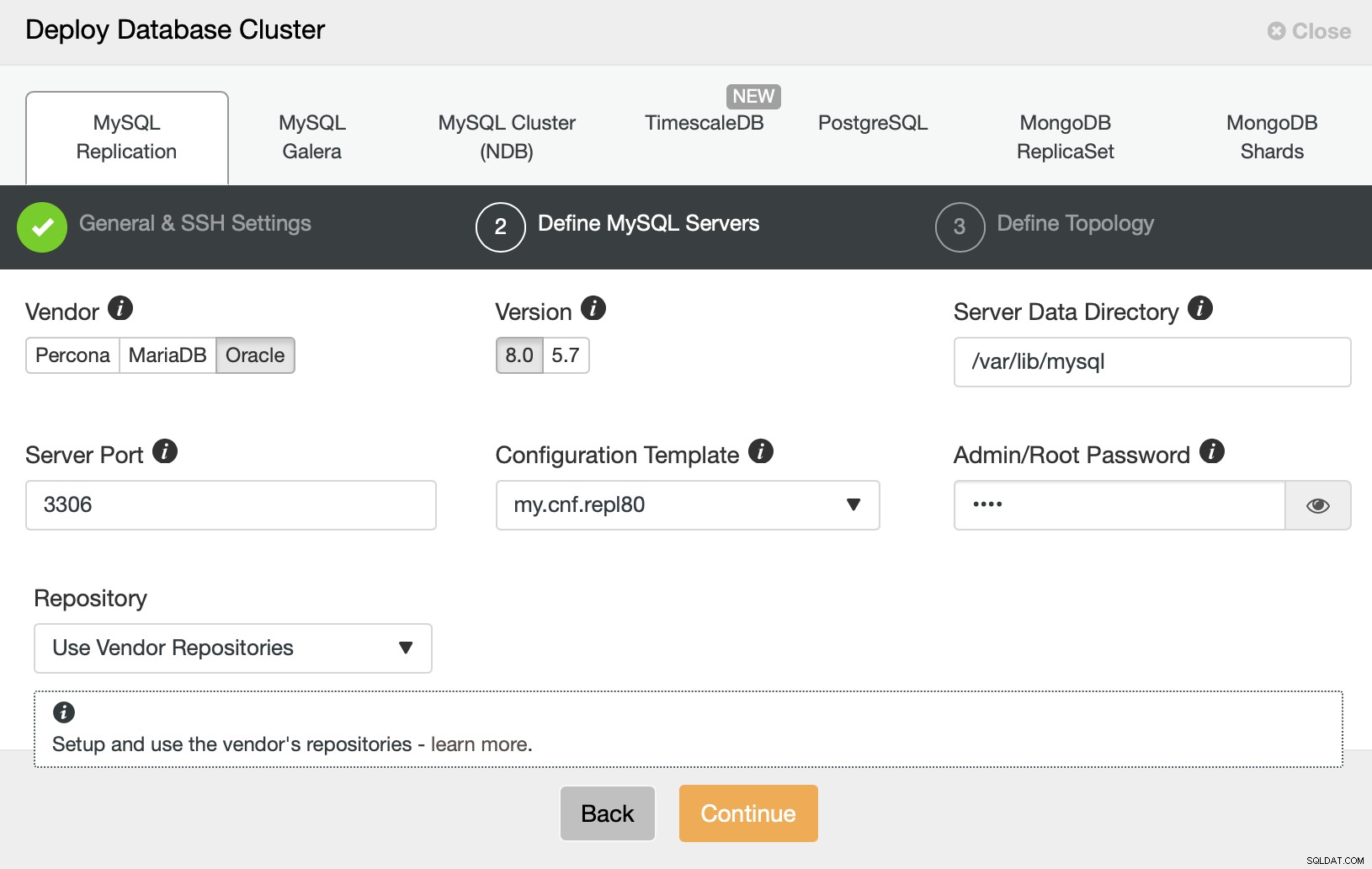
Vervolgens willen we een leverancier en versie kiezen en het wachtwoord doorgeven voor de administratieve gebruiker in onze MySQL-database.
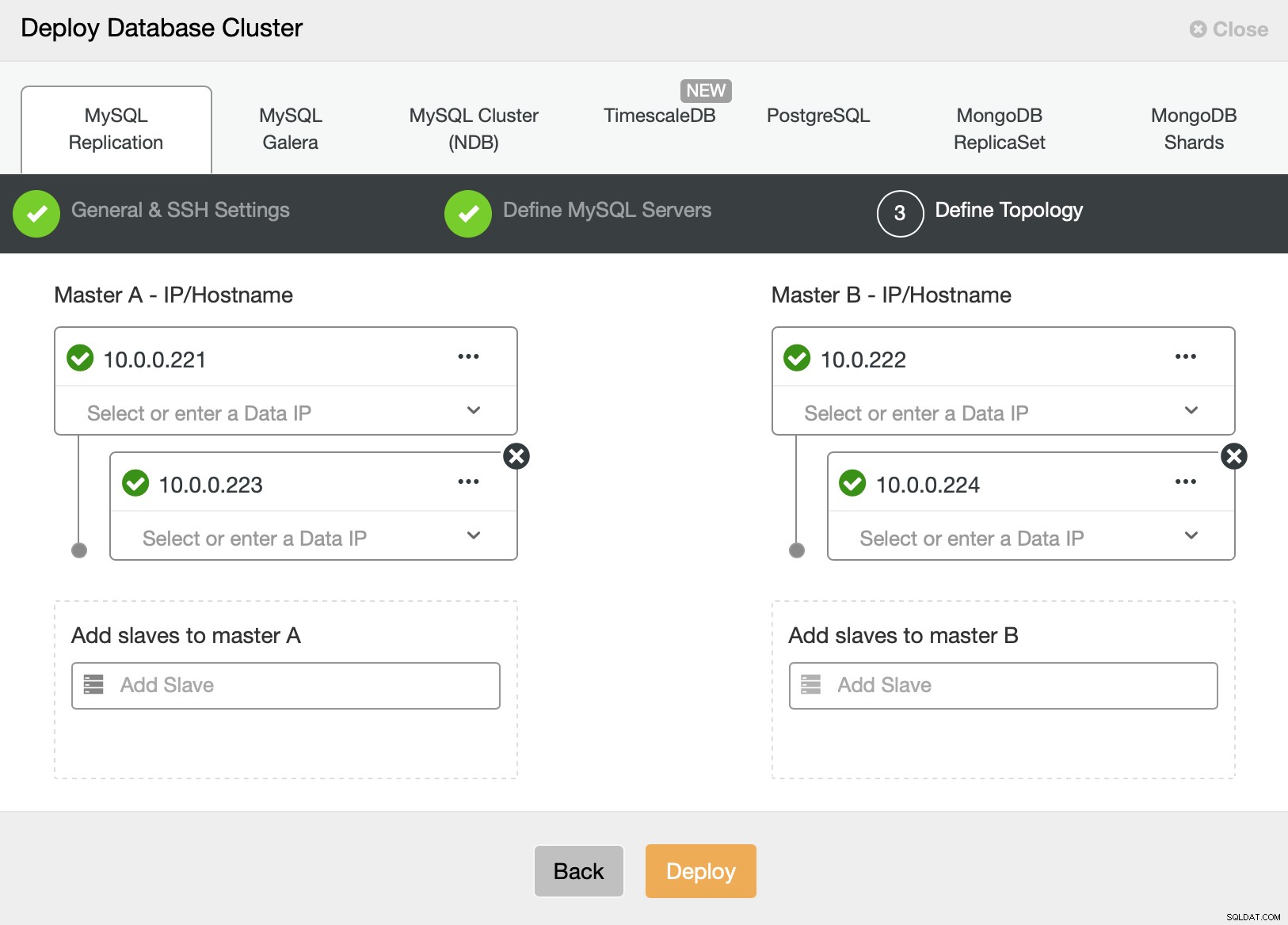
Ten slotte willen we de topologie voor ons nieuwe cluster definiëren. Zoals u kunt zien, is dit al een vrij complexe installatie, in tegenstelling tot iets dat u kunt implementeren met behulp van AWS RDS of GCP SQL-knooppunt.
Het enige dat we nu hoeven te doen, is wachten tot het proces is voltooid. ClusterControl zal zijn best doen om de omgeving waarin het wordt geïmplementeerd te begrijpen en de vereiste set pakketten te installeren, inclusief de database zelf.

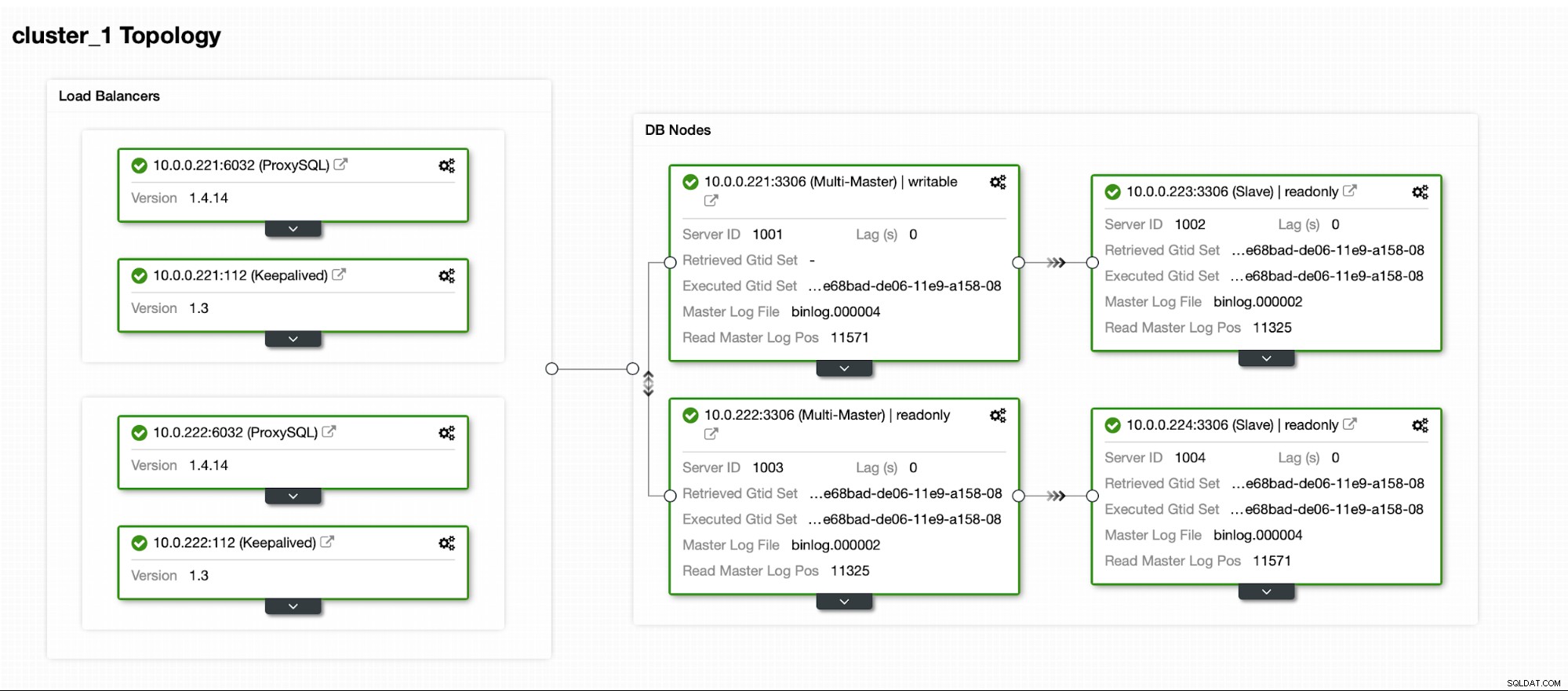
Zodra het cluster actief is, kunt u doorgaan met de implementatie de proxylaag (die uw toepassing een enkel toegangspunt tot de databaselaag zal geven). Dit is min of meer wat er achter de schermen gebeurt met DBaaS, waar je ook eindpunten hebt om verbinding te maken met het databasecluster. Het is vrij gebruikelijk om een enkel eindpunt te gebruiken voor schrijfbewerkingen en meerdere eindpunten voor het bereiken van bepaalde replica's.
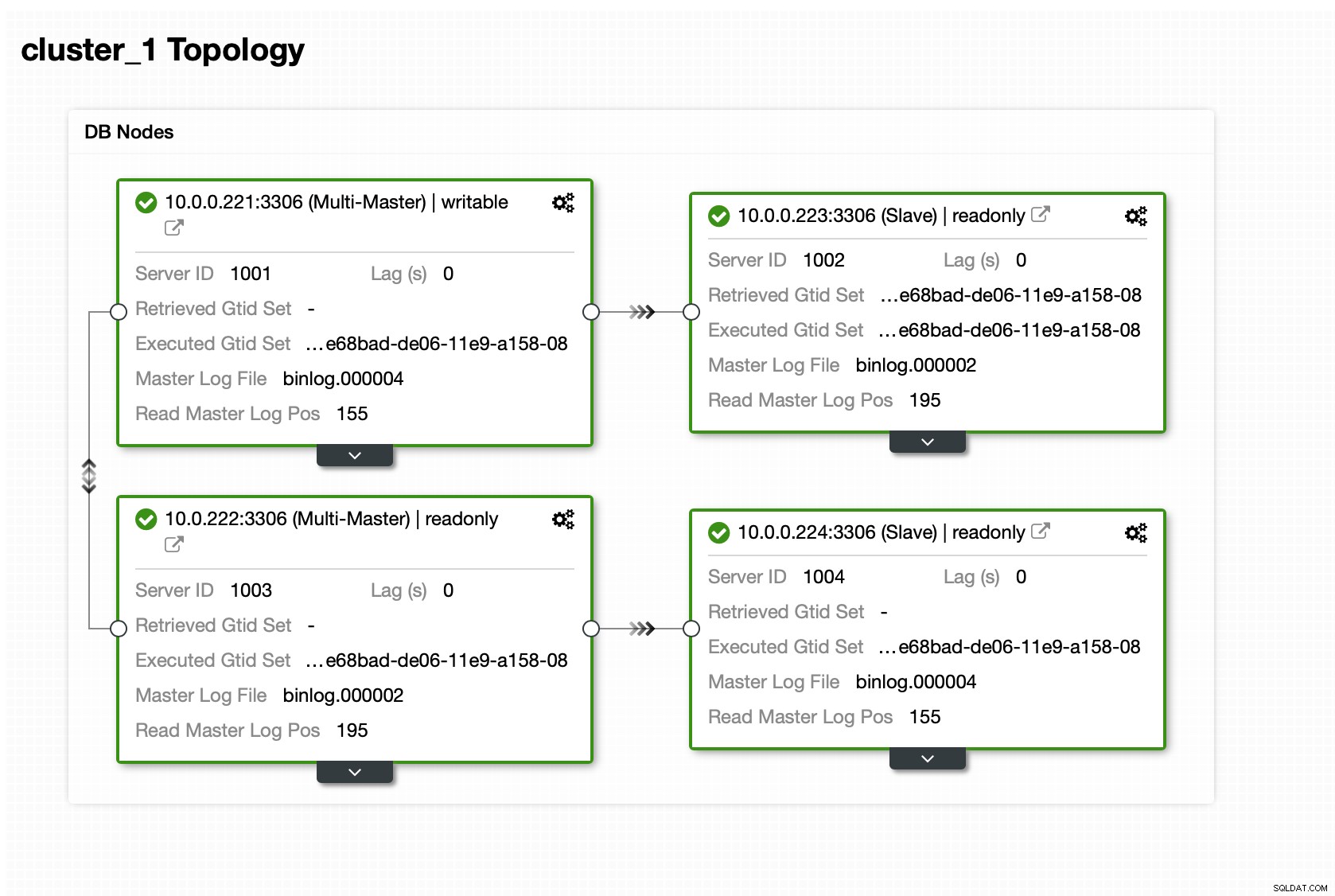
Hier zullen we ProxySQL gebruiken, dat het vuile werk voor ons zal doen - het begrijpt de topologie, stuurt alleen schrijfacties naar de master en verdeelt alleen-lezen query's over alle replica's die we hebben.
Om ProxySQL te implementeren, gaan we naar Beheren -> Load Balancers.
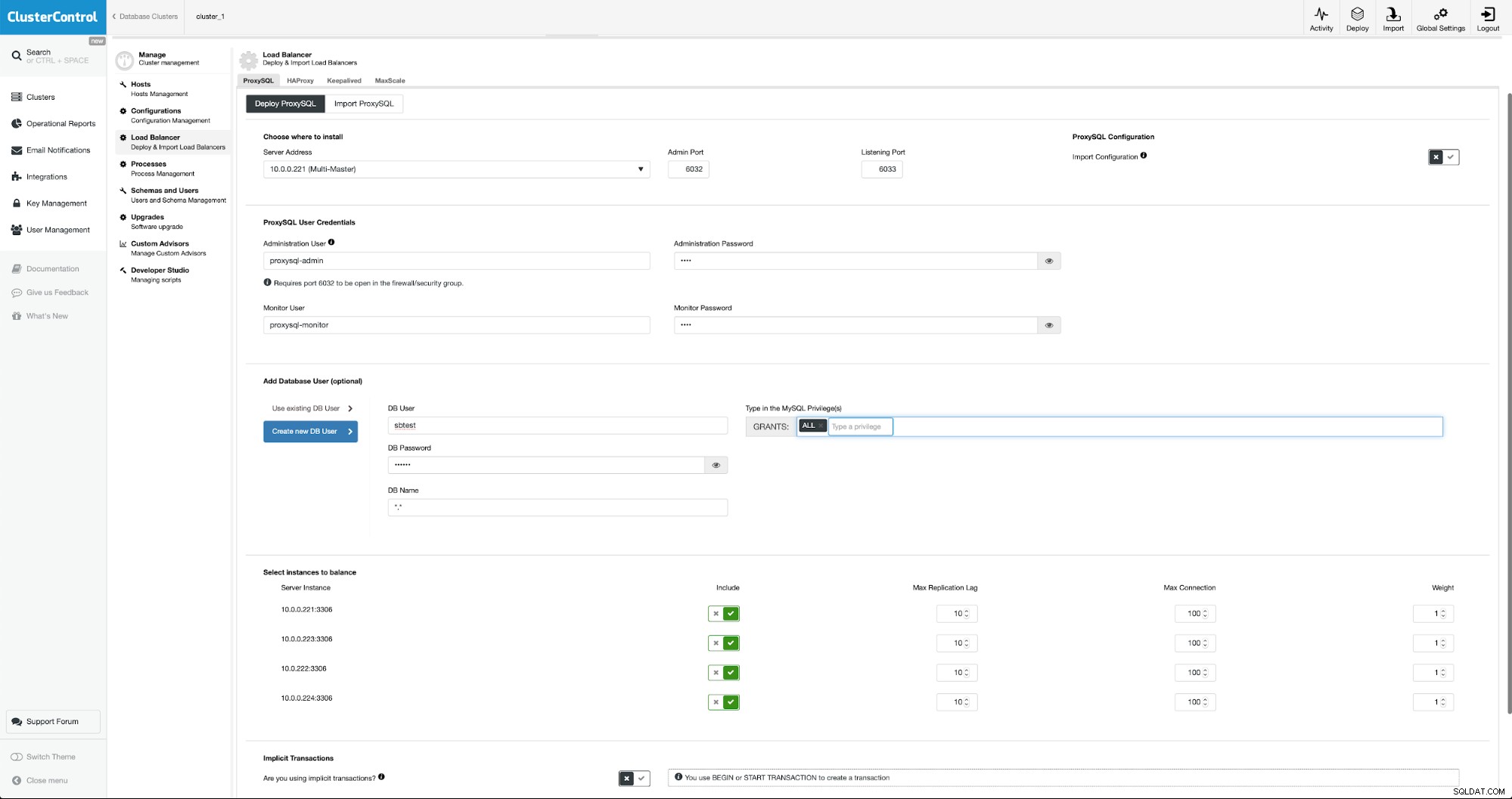
We moeten alle vereiste velden invullen:hosts om op te implementeren, inloggegevens voor de administratieve en controlerende gebruiker, kunnen we een bestaande gebruiker uit MySQL importeren in ProxySQL of een nieuwe aanmaken. Alle details over ProxySQL zijn gemakkelijk te vinden in meerdere blogs in onze blogsectie.
We willen dat er ten minste twee ProxySQL-knooppunten worden geïmplementeerd om een hoge beschikbaarheid te garanderen. Zodra ze zijn geïmplementeerd, zullen we Keepalive naast ProxySQL implementeren. Dit zorgt ervoor dat Virtual IP wordt geconfigureerd en verwijst naar een van de ProxySQL-instanties, zolang er tenminste één gezond knooppunt is.
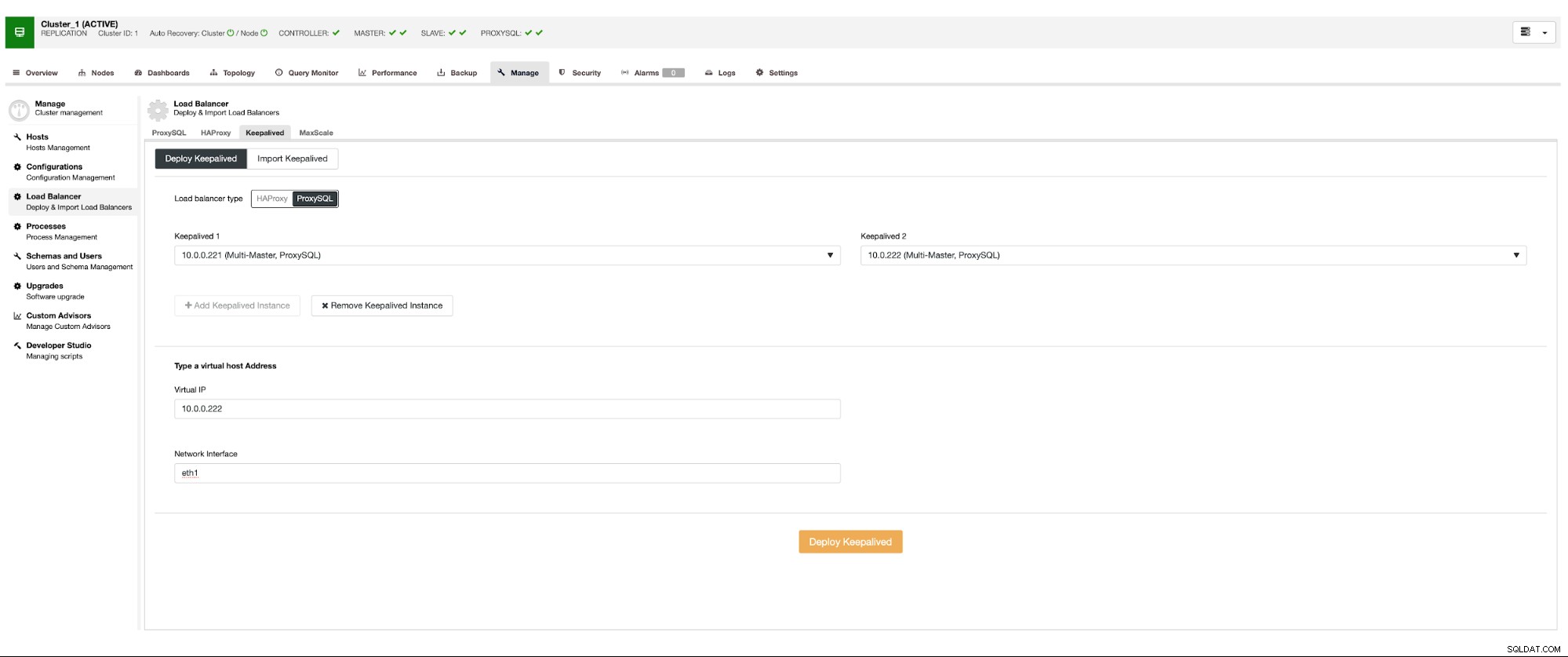
Dit is het enige potentiële probleem als je met cloudomgevingen werkt waar routering werkt op een manier dat je niet gemakkelijk een netwerkinterface ter sprake kunt brengen. In een dergelijk geval moet u de configuratie van Keepalive wijzigen, het 'notify_master'-script introduceren en een script gebruiken dat de nodige IP-wijzigingen zal aanbrengen - in het geval van EC2 zou het Elastic IP van de ene host moeten loskoppelen en aan de andere gastheer.
Er zijn tal van instructies om dat te doen met behulp van breed geteste open source-software in opstellingen die door ClusterControl zijn geïmplementeerd. U kunt gemakkelijk aanvullende informatie, tips en how-to's vinden die relevant zijn voor uw specifieke omgeving.
Conclusie
We hopen dat je deze blogpost inzichtelijk vond. Als u ClusterControl wilt testen, wordt het geleverd met een proefversie van 30 dagen voor ondernemingen waarbij u over alle functies beschikt. Je kunt het gratis downloaden en testen of het in jouw omgeving past.