Dit artikel laat zien hoe SQL Server dichtheidsinformatie uit meerdere statistieken met één kolom combineert om een kardinaliteitsschatting te produceren voor een aggregatie over meerdere kolommen. De details zijn hopelijk op zich interessant. Ze bieden ook inzicht in enkele van de algemene benaderingen en algoritmen die worden gebruikt door de kardinaliteitsschatter.
Overweeg de volgende voorbeelddatabasequery van AdventureWorks, waarin het aantal productvoorraaditems in elke bak op elke plank in het magazijn wordt vermeld:
SELECT
INV.Shelf,
INV.Bin,
COUNT_BIG(*)
FROM Production.ProductInventory AS INV
GROUP BY
INV.Shelf,
INV.Bin
ORDER BY
INV.Shelf,
INV.Bin;
Het geschatte uitvoeringsplan toont 1.069 rijen die uit de tabel worden gelezen, gesorteerd in Shelf en Bin order, vervolgens geaggregeerd met behulp van een Stream Aggregate-operator:
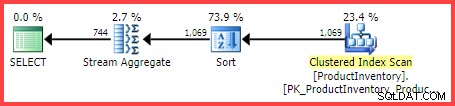
Geschat uitvoeringsplan
De vraag is, hoe kwam de SQL Server-query-optimizer tot de uiteindelijke schatting van 744 rijen?
Beschikbare statistieken
Bij het compileren van de bovenstaande query maakt de query-optimizer statistieken met één kolom op de Shelf en Bin kolommen, als er nog geen geschikte statistieken bestaan. Deze statistieken geven onder andere informatie over het aantal verschillende kolomwaarden (in de dichtheidsvector):
DBCC SHOW_STATISTICS
(
[Production.ProductInventory],
[Shelf]
)
WITH DENSITY_VECTOR;
DBCC SHOW_STATISTICS
(
[Production.ProductInventory],
[Bin]
)
WITH DENSITY_VECTOR; De resultaten zijn samengevat in onderstaande tabel (de derde kolom wordt berekend uit de dichtheid):
| Kolom | Dichtheid | 1 / Dichtheid |
|---|---|---|
| Plank | 0,04761905 | 21 |
| Vuilnis | 0.01612903 | 62 |
Informatie over de dichtheid van planken en bakken
Zoals de documentatie aangeeft, is het omgekeerde van de dichtheid het aantal verschillende waarden in de kolom. Uit de bovenstaande statistische informatie weet SQL Server dat er 21 verschillende Shelf waren waarden en 62 verschillende Bin waarden in de tabel, wanneer de statistieken werden verzameld.
De taak om het aantal rijen te schatten dat wordt geproduceerd door een GROUP BY clausule is triviaal als het slechts om één kolom gaat (ervan uitgaande dat er geen andere predikaten zijn). Het is bijvoorbeeld gemakkelijk te zien dat GROUP BY Shelf zal 21 rijen produceren; GROUP BY Bin zal 62 produceren.
Het is echter niet meteen duidelijk hoe SQL Server het aantal verschillende (Shelf, Bin) kan schatten. combinaties voor onze GROUP BY Shelf, Bin vraag. Om de vraag op een iets andere manier te stellen:hoeveel unieke plank- en bakcombinaties zullen er zijn, gegeven 21 planken en 62 bakken? Afgezien van fysieke aspecten en andere menselijke kennis van het probleemdomein, kan het antwoord variëren van max(21, 62) =62 tot (21 * 62) =1.302. Zonder meer informatie is er geen voor de hand liggende manier om te weten waar je een schatting in dat bereik moet plaatsen.
Maar voor onze voorbeeldquery schat SQL Server 744.312 rijen (afgerond op 744 in de weergave Planverkenner), maar op welke basis?
Kadinaliteitsschatting uitgebreide gebeurtenis
De gedocumenteerde manier om het kardinaliteitsschattingsproces te onderzoeken, is door de Extended Event query_optimizer_estimate_cardinality te gebruiken (ondanks dat het in het "debug"-kanaal zit). Terwijl een sessie die deze gebeurtenis verzamelt, wordt uitgevoerd, krijgen uitvoeringsplanoperators een extra eigenschap StatsCollectionId die schattingen van individuele operators koppelt aan de berekeningen die ze hebben opgeleverd. Voor onze voorbeeldquery is statistiekverzameling-ID 2 gekoppeld aan de kardinaliteitsschatting voor de groep per aggregaatoperator.
De relevante output van de Extended Event voor onze testquery is:
<data name="calculator">
<type name="xml" package="package0"></type>
<value>
<CalculatorList>
<DistinctCountCalculator CalculatorName="CDVCPlanLeaf" SingleColumnStat="Shelf,Bin" />
</CalculatorList>
</value>
</data>
<data name="stats_collection">
<type name="xml" package="package0"></type>
<value>
<StatsCollection Name="CStCollGroupBy" Id="2" Card="744.31">
<LoadedStats>
<StatsInfo DbId="6" ObjectId="258099960" StatsId="3" />
<StatsInfo DbId="6" ObjectId="258099960" StatsId="4" />
</LoadedStats>
</StatsCollection>
</value>
</data> Er is zeker wat nuttige informatie.
We kunnen zien dat de rekenklasse met verschillende waarden van het planblad (CDVCPlanLeaf ) werd gebruikt, gebruikmakend van éénkolomsstatistieken op Shelf en Bin als ingangen. Het stats-verzamelingselement vergelijkt dit fragment met de id (2) die wordt weergegeven in het uitvoeringsplan, dat de kardinaliteitsschatting van 744.31 toont , en ook meer informatie over de gebruikte statistische object-ID's.
Helaas is er niets in de gebeurtenisuitvoer om precies te zeggen hoe de rekenmachine tot het uiteindelijke cijfer is gekomen, en dat is waar we echt in geïnteresseerd zijn.
Afzonderlijke tellingen combineren
Als we een minder gedocumenteerde route volgen, kunnen we een geschat plan voor de zoekopdracht aanvragen met traceervlaggen 2363 en 3604 ingeschakeld:
SELECT
INV.Shelf,
INV.Bin,
COUNT_BIG(*)
FROM Production.ProductInventory AS INV
GROUP BY
INV.Shelf,
INV.Bin
ORDER BY
INV.Shelf,
INV.Bin
OPTION (QUERYTRACEON 3604, QUERYTRACEON 2363); Hiermee wordt foutopsporingsinformatie geretourneerd naar het tabblad Berichten in SQL Server Management Studio. Het interessante deel wordt hieronder weergegeven:
Begin distinct values computation
Input tree:
LogOp_GbAgg OUT(QCOL: [INV].Shelf,QCOL: [INV].Bin,COL: Expr1001 ,) BY(QCOL: [INV].Shelf,QCOL: [INV].Bin,)
CStCollBaseTable(ID=1, CARD=1069 TBL: Production.ProductInventory AS TBL: INV)
AncOp_PrjList
AncOp_PrjEl COL: Expr1001
ScaOp_AggFunc stopCountBig
ScaOp_Const TI(int,ML=4) XVAR(int,Not Owned,Value=0)
Plan for computation:
CDVCPlanLeaf
0 Multi-Column Stats, 2 Single-Column Stats, 0 Guesses
Loaded histogram for column QCOL: [INV].Shelf from stats with id 3
Loaded histogram for column QCOL: [INV].Bin from stats with id 4
Using ambient cardinality 1069 to combine distinct counts:
21
62
Combined distinct count: 744.312
Result of computation: 744.312
Stats collection generated:
CStCollGroupBy(ID=2, CARD=744.312)
CStCollBaseTable(ID=1, CARD=1069 TBL: Production.ProductInventory AS TBL: INV)
End distinct values computation Dit toont vrijwel dezelfde informatie als het uitgebreide evenement in een (aantoonbaar) gemakkelijker te gebruiken formaat:
- De relationele invoeroperator om een kardinaliteitsschatting te berekenen voor (
LogOp_GbAgg– logische groep op aggregaat) - De gebruikte rekenmachine (
CDVCPlanLeaf) en invoerstatistieken - De resulterende gegevens voor het verzamelen van statistieken
Het interessante nieuwe stuk informatie is het deel over het gebruik van ambient-kardinaliteit om verschillende tellingen te combineren .
Hieruit blijkt duidelijk dat de waarden 21, 62 en 1069 zijn gebruikt, maar (frustrerend) nog steeds niet precies welke berekeningen zijn uitgevoerd om tot de 744.312 te komen resultaat.
Naar Debugger!
Door een debugger toe te voegen en openbare symbolen te gebruiken, kunnen we in detail het gevolgde codepad verkennen tijdens het compileren van de voorbeeldquery.
De onderstaande snapshot toont het bovenste gedeelte van de call-stack op een representatief punt in het proces:
MSVCR120!log sqllang!OdblNHlogN sqllang!CCardUtilSQL12::ProbSampleWithoutReplacement sqllang!CCardUtilSQL12::CardDistinctMunged sqllang!CCardUtilSQL12::CardDistinctCombined sqllang!CStCollAbstractLeaf::CardDistinctImpl sqllang!IStatsCollection::CardDistinct sqllang!CCardUtilSQL12::CardGroupByHelperCore sqllang!CCardUtilSQL12::PstcollGroupByHelper sqllang!CLogOp_GbAgg::PstcollDeriveCardinality sqllang!CCardFrameworkSQL12::DeriveCardinalityProperties
Er zijn een paar interessante details hier. Als we van onder naar boven werken, zien we dat kardinaliteit wordt afgeleid met behulp van de bijgewerkte CE (CCardFrameworkSQL12 ) beschikbaar in SQL Server 2014 en later (de originele CE is CCardFrameworkSQL7 ), voor de groep op geaggregeerde logische operator (CLogOp_GbAgg ).
Het berekenen van de verschillende kardinaliteit omvat het combineren (munging) van meerdere inputs, met behulp van bemonstering zonder vervanging.
De verwijzing naar H en een (natuurlijke) logaritme in de tweede methode van boven toont het gebruik van Shannon Entropy in de berekening:
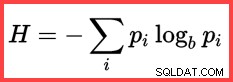
Shannon Entropie
Entropie kan worden gebruikt om de informatieve correlatie (wederzijdse informatie) tussen twee statistieken te schatten:
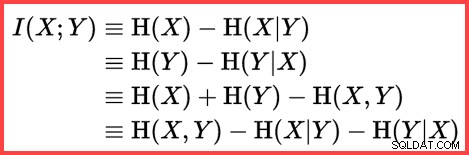
Wederzijdse informatie
Door dit alles samen te voegen, kunnen we een T-SQL-berekeningsscript construeren dat overeenkomt met de manier waarop SQL Server sampling gebruikt zonder vervanging, Shannon Entropy en wederzijdse informatie om de uiteindelijke kardinaliteitsschatting te maken.
We beginnen met de invoernummers (omgevingskardinaliteit en het aantal verschillende waarden in elke kolom):
DECLARE
@Card float = 1069,
@Distinct1 float = 21,
@Distinct2 float = 62; De frequentie van elke kolom is het gemiddelde aantal rijen per afzonderlijke waarde:
DECLARE
@Frequency1 float = @Card / @Distinct1,
@Frequency2 float = @Card / @Distinct2; Sampling zonder vervanging (SWR) is een kwestie van het gemiddelde aantal rijen per afzonderlijke waarde (frequentie) aftrekken van het totale aantal rijen:
DECLARE
@SWR1 float = @Card - @Frequency1,
@SWR2 float = @Card - @Frequency2,
@SWR3 float = @Card - @Frequency1 - @Frequency2; Bereken de entropieën (N log N) en wederzijdse informatie:
DECLARE
@E1 float = (@SWR1 + 0.5) * LOG(@SWR1),
@E2 float = (@SWR2 + 0.5) * LOG(@SWR2),
@E3 float = (@SWR3 + 0.5) * LOG(@SWR3),
@E4 float = (@Card + 0.5) * LOG(@Card);
-- Using logarithms allows us to express
-- multiplication as addition and division as subtraction
DECLARE
@MI float = EXP(@E1 + @E2 - @E3 - @E4); Nu we hebben geschat hoe gecorreleerd zijn de twee sets statistieken, kunnen we de uiteindelijke schatting berekenen:
SELECT (1e0 - @MI) * @Distinct1 * @Distinct2;
Het resultaat van de berekening is 744.311823994677, dat is 744.312 afgerond op drie decimalen.
Voor het gemak is hier de hele code in één blok:
DECLARE
@Card float = 1069,
@Distinct1 float = 21,
@Distinct2 float = 62;
DECLARE
@Frequency1 float = @Card / @Distinct1,
@Frequency2 float = @Card / @Distinct2;
-- Sample without replacement
DECLARE
@SWR1 float = @Card - @Frequency1,
@SWR2 float = @Card - @Frequency2,
@SWR3 float = @Card - @Frequency1 - @Frequency2;
-- Entropy
DECLARE
@E1 float = (@SWR1 + 0.5) * LOG(@SWR1),
@E2 float = (@SWR2 + 0.5) * LOG(@SWR2),
@E3 float = (@SWR3 + 0.5) * LOG(@SWR3),
@E4 float = (@Card + 0.5) * LOG(@Card);
-- Mutual information
DECLARE
@MI float = EXP(@E1 + @E2 - @E3 - @E4);
-- Final estimate
SELECT (1e0 - @MI) * @Distinct1 * @Distinct2; Laatste gedachten
De uiteindelijke schatting is in dit geval onvolmaakt - de voorbeeldquery retourneert feitelijk 441 rijen.
Om een betere schatting te krijgen, kunnen we de optimizer betere informatie geven over de dichtheid van de Bin en Shelf kolommen met behulp van een statistiek met meerdere kolommen. Bijvoorbeeld:
CREATE STATISTICS stat_Shelf_Bin ON Production.ProductInventory (Shelf, Bin);
Met die statistiek op zijn plaats (ofwel als gegeven, of als een neveneffect van het toevoegen van een vergelijkbare index met meerdere kolommen), is de kardinaliteitsschatting voor de voorbeeldquery precies goed. Het is echter zeldzaam om zo'n eenvoudige aggregatie te berekenen. Met aanvullende predikaten kan de statistiek met meerdere kolommen minder effectief zijn. Desalniettemin is het belangrijk om te onthouden dat de aanvullende dichtheidsinformatie die wordt verschaft door statistieken met meerdere kolommen nuttig kan zijn voor aggregaties (evenals voor vergelijkingen van gelijkheid).
Zonder een statistiek met meerdere kolommen kan een geaggregeerde query met aanvullende predikaten mogelijk nog steeds de essentiële logica gebruiken die in dit artikel wordt weergegeven. In plaats van de formule bijvoorbeeld toe te passen op de tabelkardinaliteit, kan deze stap voor stap worden toegepast om histogrammen in te voeren.
Gerelateerde inhoud:Kardinaliteitsschatting voor een predikaat op een COUNT-uitdrukking