SQL Server 2014 SP2 en later produceren runtime ("werkelijke") uitvoeringsplannen die verstreken tijd kunnen bevatten en CPU-gebruik voor elke uitvoeringsplan-operator (zie KB3170113 en deze blogpost van Pedro Lopes).
Het interpreteren van deze cijfers is niet altijd zo eenvoudig als men zou verwachten. Er zijn belangrijke verschillen tussen rijmodus en batchmodus uitvoering, evenals lastige problemen met rijmodus parallelisme . SQL Server maakt enkele timing aanpassingen in parallelle plannen om de samenhang te bevorderen, maar ze worden niet perfect uitgevoerd. Dit kan het moeilijk maken om degelijke prestatie-afstemmingsconclusies te trekken.
Dit artikel is bedoeld om u te helpen begrijpen waar de tijdstippen in elk geval vandaan komen en hoe ze het beste in de context kunnen worden geïnterpreteerd.
Setup
De volgende voorbeelden gebruiken de openbare Stack Overflow 2013 database (downloaddetails), met een enkele index toegevoegd:
CREATE INDEX PP ON dbo.Posts (PostTypeId ASC, CreationDate ASC) INCLUDE (AcceptedAnswerId);
De testquery's retourneren het aantal vragen met een geaccepteerd antwoord, gegroepeerd op maand en jaar. Ze worden uitgevoerd op SQL Server 2019 CU9 , op een laptop met 8 cores en 16 GB geheugen toegewezen aan de SQL Server 2019-instantie. Compatibiliteitsniveau 150 wordt uitsluitend gebruikt.
Batch-modus seriële uitvoering
SELECT
CA.TheYear,
CA.TheMonth,
AcceptedAnswers = COUNT_BIG(*)
FROM dbo.Posts AS Q
JOIN dbo.Posts AS A
ON A.Id = Q.AcceptedAnswerId
CROSS APPLY
(
VALUES
(
YEAR(Q.CreationDate),
MONTH (Q.CreationDate)
)
) AS CA (TheYear, TheMonth)
WHERE
Q.PostTypeId = 1
AND A.PostTypeId = 2
GROUP BY
CA.TheYear, CA.TheMonth
ORDER BY
CA.TheYear, CA.TheMonth
OPTION
(
MAXDOP 1,
USE HINT ('DISABLE_BATCH_MODE_ADAPTIVE_JOINS')
); Het uitvoeringsplan is (klik om te vergroten):
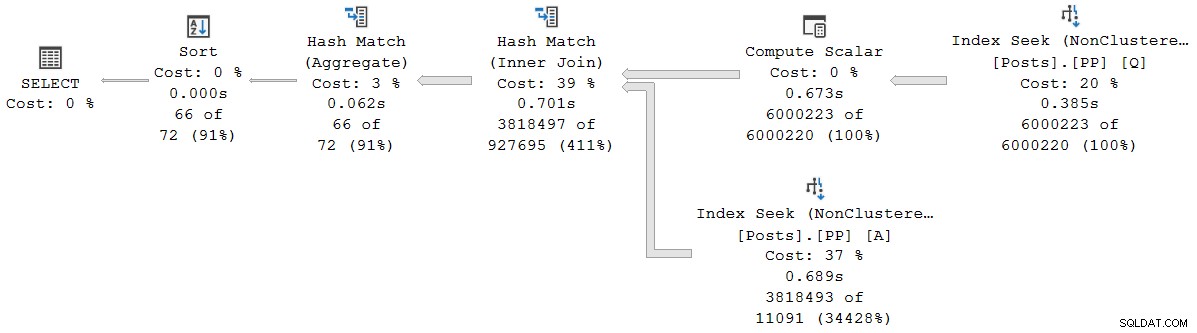
Elke operator in dit plan werkt in batchmodus, dankzij de batchmodus op rowstore Intelligente Query Processing-functie in SQL Server 2019 (geen columnstore-index nodig). De zoekopdracht duurt 2,523 ms met 2.522ms CPU-tijd gebruikt, wanneer alle benodigde gegevens zich al in de bufferpool bevinden.
Zoals Pedro Lopes opmerkt in de eerder gelinkte blogpost, zijn de verstreken en CPU-tijden gerapporteerd voor individuele batchmodus operators vertegenwoordigen de tijd die wordt gebruikt door die operator alleen .
SSMS toont verstreken tijd in de grafische weergave. Om de CPU-tijden te zien , selecteer een planoperator en kijk in de Eigenschappen raam. Deze gedetailleerde weergave toont zowel de verstreken tijd als de CPU-tijd, per operator en per thread.
De showplan tijden (inclusief de XML representatie) zijn afgekapt tot milliseconden. Als je meer precisie nodig hebt, gebruik dan de query_thread_profile uitgebreide gebeurtenis, die rapporteert in microseconden . De output van deze gebeurtenis voor het hierboven getoonde uitvoeringsplan is:
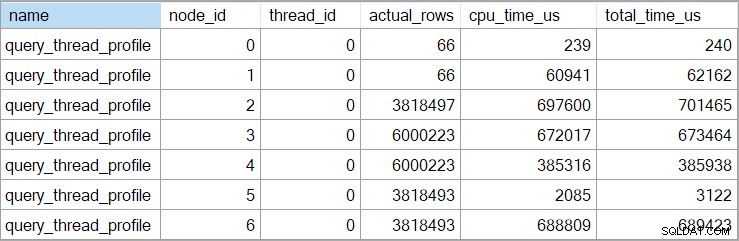
Dit geeft aan dat de verstreken tijd voor de join (knooppunt 2) 701.465µs is (afgekort tot 701ms in showplan). Het aggregaat heeft een verstreken tijd van 62.162 µs (62 ms). De zoekindex voor 'vragen' wordt weergegeven als actief voor 385 ms, terwijl de uitgebreide gebeurtenis laat zien dat het werkelijke cijfer voor knooppunt 4 385.938 µs was (bijna 386 ms).
SQL Server gebruikt de hoge precisie QueryPerformanceCounter API om timinggegevens vast te leggen. Dit maakt gebruik van hardware, meestal een kristaloscillator, die tikken produceert met een zeer hoge constante snelheid, ongeacht de processorsnelheid, energie-instellingen of iets van die aard. Zelfs tijdens de slaap blijft de klok op hetzelfde tempo lopen. Zie het gelinkte zeer gedetailleerde artikel als je geïnteresseerd bent in alle fijnere details. De korte samenvatting is dat u erop kunt vertrouwen dat de microseconden nauwkeurig zijn.
In dit pure batchmodusplan ligt de totale uitvoeringstijd zeer dicht bij de som van de individuele verstreken tijden van de operator. Het verschil is grotendeels te wijten aan post-statement werk dat niet geassocieerd is met plan-operators (die tegen die tijd allemaal zijn gesloten), hoewel de afknotting in milliseconden ook een rol speelt.
In pure batchmodusplannen moet u de huidige en onderliggende operatortijden handmatig optellen om de cumulatieve te verkrijgen verstreken tijd op een bepaald knooppunt.
Batch-modus parallelle uitvoering
SELECT
CA.TheYear,
CA.TheMonth,
AcceptedAnswers = COUNT_BIG(*)
FROM dbo.Posts AS Q
JOIN dbo.Posts AS A
ON A.Id = Q.AcceptedAnswerId
CROSS APPLY
(
VALUES
(
YEAR(Q.CreationDate),
MONTH (Q.CreationDate)
)
) AS CA (TheYear, TheMonth)
WHERE
Q.PostTypeId = 1
AND A.PostTypeId = 2
GROUP BY
CA.TheYear, CA.TheMonth
ORDER BY
CA.TheYear, CA.TheMonth
OPTION
(
MAXDOP 8,
USE HINT ('DISABLE_BATCH_MODE_ADAPTIVE_JOINS')
); Het uitvoeringsplan is:
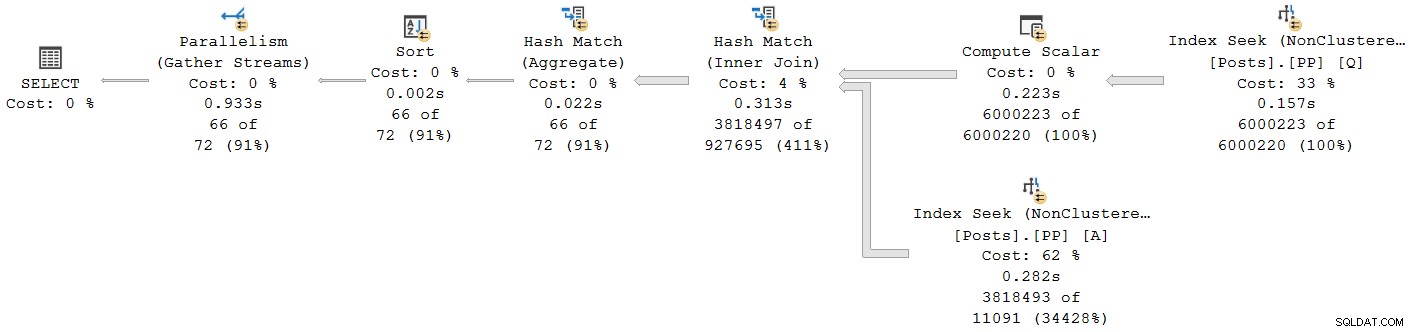
Elke operator, behalve de laatste collect stream-uitwisseling, werkt in batchmodus. De totale verstreken tijd is 933ms met 6.673 ms CPU-tijd met een warme cache.
De hash-join selecteren en zoeken in de SSMS Eigenschappen venster zien we de verstreken en CPU-tijd per thread voor die operator:
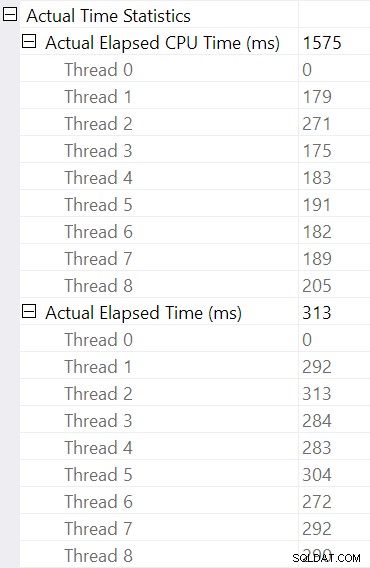
De CPU-tijd gerapporteerd voor de operator is de som van de individuele thread CPU-tijden. De gerapporteerde operator verstreken tijd is het maximum van de per thread verstreken tijden. Beide berekeningen worden uitgevoerd over de afgekapte millisecondewaarden per thread. Net als voorheen ligt de totale uitvoeringstijd zeer dicht bij de som van de individuele verstreken tijd van de operator.
Parallelle plannen in batchmodus gebruiken geen uitwisselingen om werk over threads te verdelen. Batch-operators zijn geïmplementeerd zodat meerdere threads efficiënt kunnen werken op een enkele gedeelde structuur (bijv. hashtabel). Enige synchronisatie tussen threads is nog steeds vereist in parallelle plannen in batchmodus, maar synchronisatiepunten en andere details zijn niet zichtbaar in showplan-uitvoer.
Seriële uitvoering in rijmodus
SELECT
CA.TheYear,
CA.TheMonth,
AcceptedAnswers = COUNT_BIG(*)
FROM dbo.Posts AS Q
JOIN dbo.Posts AS A
ON A.Id = Q.AcceptedAnswerId
CROSS APPLY
(
VALUES
(
YEAR(Q.CreationDate),
MONTH (Q.CreationDate)
)
) AS CA (TheYear, TheMonth)
WHERE
Q.PostTypeId = 1
AND A.PostTypeId = 2
GROUP BY
CA.TheYear, CA.TheMonth
ORDER BY
CA.TheYear, CA.TheMonth
OPTION
(
MAXDOP 1,
USE HINT ('DISALLOW_BATCH_MODE')
); Het uitvoeringsplan is visueel hetzelfde als het serieel plan in batchmodus, maar elke operator werkt nu in rijmodus:
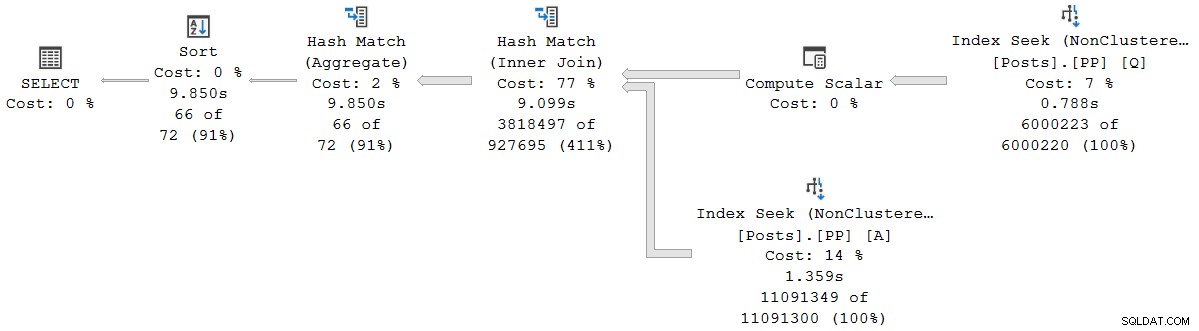
De query duurt 9.850 ms met een CPU-tijd van 9,845 ms. Dit is een stuk langzamer dan de seriële batchmodusquery (2523ms/2522ms), zoals verwacht. Belangrijker voor de huidige discussie is de rijmodus operator verstreken en CPU-tijden vertegenwoordigen de tijd die wordt gebruikt door de huidige operator en al zijn kinderen .
De uitgebreide gebeurtenis toont ook cumulatieve CPU en verstreken tijden op elk knooppunt (in microseconden):
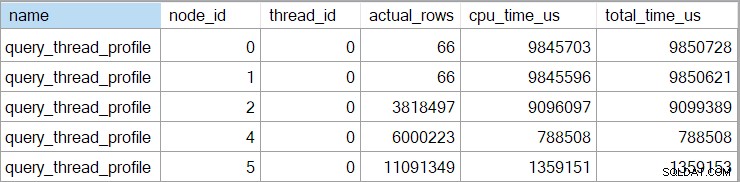
Er zijn geen gegevens voor de scalaire rekenoperator (knooppunt 3) omdat uitvoering in rijmodus kan uitstellen meeste uitdrukkingsberekeningen aan de operator die het resultaat verbruikt. Dit is momenteel niet geïmplementeerd voor uitvoering in batchmodus.
De gerapporteerde cumulatieve verstreken tijd voor operators in rijmodus betekent dat de tijd die wordt weergegeven voor de laatste sorteeroperator nauw aansluit bij de totale uitvoeringstijd voor de query (in ieder geval tot millisecondenresolutie). De verstreken tijd voor de hash-join omvat eveneens bijdragen van de twee indexzoekopdrachten eronder, evenals de eigen tijd. De verstreken tijd berekenen alleen voor de hash-join in de rijmodus zouden we beide zoektijden ervan moeten aftrekken.
Er zijn voor- en nadelen aan beide presentaties (cumulatief voor rijmodus, individuele operator alleen voor batchmodus). Wat je voorkeur ook heeft, het is belangrijk om je bewust te zijn van de verschillen.
Gemengde uitvoeringsmodusplannen
Over het algemeen kunnen moderne uitvoeringsplannen elke combinatie van rijmodus- en batchmodusoperators bevatten. De operators in de batchmodus rapporteren de tijden alleen voor zichzelf. De rijmodusoperators zullen een cumulatief totaal tot dat punt in het plan opnemen, inclusief alle kind exploitanten. Voor alle duidelijkheid:de cumulatieve tijden van een rijmodusoperator inclusief alle onderliggende operatoren in batchmodus.
We zagen dit eerder in het parallelle batchmodusplan:de laatste (rijmodus) verzamelstreams-operator had een weergegeven (cumulatieve) verstreken tijd van 0,933s - inclusief alle onderliggende batchmodus-operators. De andere operators werkten allemaal in batchmodus en rapporteerden dus tijden alleen voor de individuele operator.
Deze situatie, waarbij sommige planoperators in hetzelfde plan cumulatieve tijden hebben en andere niet, zullen ongetwijfeld worden beschouwd als verwarrend door veel mensen.
Rijmodus parallelle uitvoering
SELECT
CA.TheYear,
CA.TheMonth,
AcceptedAnswers = COUNT_BIG(*)
FROM dbo.Posts AS Q
JOIN dbo.Posts AS A
ON A.Id = Q.AcceptedAnswerId
CROSS APPLY
(
VALUES
(
YEAR(Q.CreationDate),
MONTH (Q.CreationDate)
)
) AS CA (TheYear, TheMonth)
WHERE
Q.PostTypeId = 1
AND A.PostTypeId = 2
GROUP BY
CA.TheYear, CA.TheMonth
ORDER BY
CA.TheYear, CA.TheMonth
OPTION
(
MAXDOP 8,
USE HINT ('DISALLOW_BATCH_MODE')
); Het uitvoeringsplan is:

Elke operator is rijmodus. De zoekopdracht duurt 4.677 ms met 23.311ms CPU-tijd (som van alle threads).
Als exclusief rijmodusplan verwachten we dat alle tijden cumulatief zijn . Verhuizen van kind naar ouder (van rechts naar links), de tijden zouden in die richting moeten toenemen.
Laten we eens kijken naar het meest rechtse gedeelte van het plan:
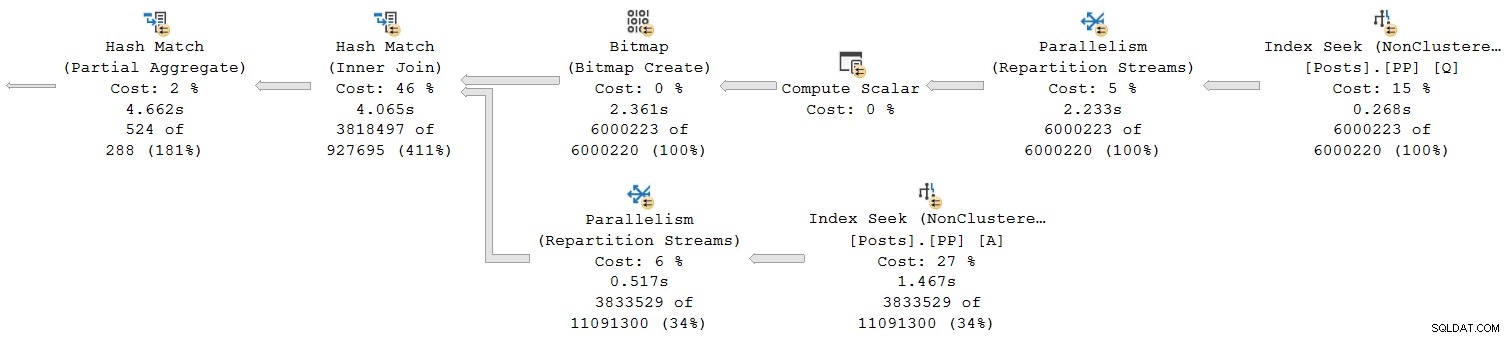
Werkend van rechts naar links op de bovenste rij, lijken cumulatieve tijden zeker het geval te zijn. Maar er is een uitzondering op de onderste invoer naar de hash-join:de indexzoekactie heeft een verstreken tijd van 1.467s , terwijl de ouder herpartitioneer streams heeft een verstreken tijd van slechts 0,517s .
Hoe kan een ouder operator werkt minder tijd dan zijn kind als verstreken tijden cumulatief zijn in rijmodusplannen?
Inconsistente tijden
Het antwoord op deze puzzel bestaat uit verschillende onderdelen. Laten we het stukje bij beetje bekijken, want het is best ingewikkeld:
Bedenk eerst dat een uitwisseling (parallelisme-operator) uit twee delen bestaat. De linkerhand (consument ) kant is verbonden met een set threads met operators in de parallelle vertakking naar links. De rechterhand (producent .) ) kant van de uitwisseling is verbonden met een andere reeks threads met operators in de parallelle tak aan de rechterkant.
Rijen van de kant van de producent worden samengevoegd tot pakketten en vervolgens overgedragen aan de kant van de consument. Dit zorgt voor een zekere mate van buffering en flow control tussen de twee sets van verbonden draden. (Als je een opfrissing nodig hebt over uitwisselingen en parallelle planvertakkingen, raadpleeg dan mijn artikel Parallelle uitvoeringsplannen - takken en threads.)
De scope van cumulatieve tijden
Kijkend naar de parallelle tak op de producer kant van de beurs:
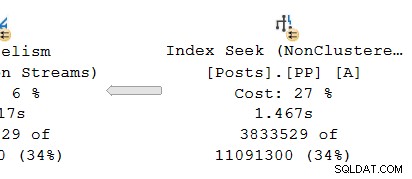
Zoals gewoonlijk voeren DOP (mate van parallellisme) extra werkthreads een onafhankelijke serie uit kopie van de planbeheerders in deze branche. Dus bij DOP 8 zijn er 8 onafhankelijke seriële indexzoekacties die samenwerken om het bereikscangedeelte van de algehele (parallelle) indexzoekbewerking uit te voeren. Elke single-threaded zoekactie is verbonden met een andere ingang (poort) aan de producerzijde van de single shared uitwisselingsoperator.
Een vergelijkbare situatie bestaat bij de consument kant van de beurs. Bij DOP 8 zijn er 8 afzonderlijke single-threaded kopieën van deze branch die allemaal onafhankelijk draaien:
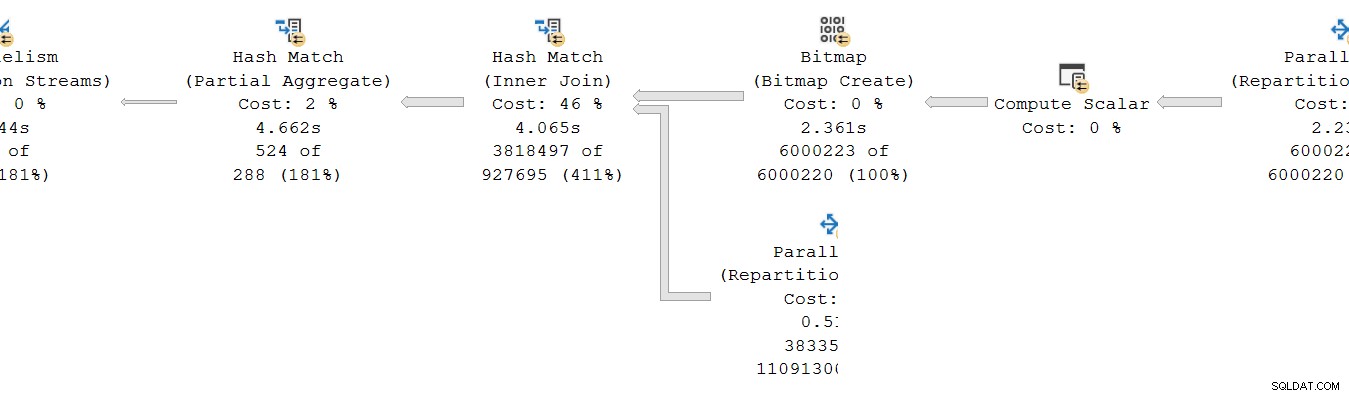
Elk van deze single-threaded subplannen wordt op de gebruikelijke manier uitgevoerd, waarbij elke operator de verstreken en CPU-tijdtotalen op elk knooppunt optelt. Omdat het rijmodusoperators zijn, vertegenwoordigt elk totaal de tijd die is besteed aan het cumulatieve totaal voor het huidige knooppunt en elk van zijn onderliggende.
Het cruciale punt is dat de cumulatieve totalen neem alleen operators op in de dezelfde thread en alleen binnen de huidige vestiging . Hopelijk is dit intuïtief logisch, omdat elke thread geen idee heeft wat er ergens anders aan de hand kan zijn.
Hoe statistieken voor rijmodus worden verzameld
Het tweede deel van de puzzel heeft betrekking op de manier waarop rijtellingen en timingstatistieken worden verzameld in rijmodusplannen. Wanneer runtime ("werkelijke") planinformatie vereist is, voegt de uitvoeringsengine een onzichtbare . toe profileringsoperator naar onmiddellijk links (ouder) van elke operator in het plan dat tijdens runtime wordt uitgevoerd.
Deze operator kan (onder andere) het verschil registreren tussen het moment waarop het de besturing aan de onderliggende operator heeft doorgegeven, en het tijdstip waarop de besturing werd teruggegeven. Dit tijdsverschil vertegenwoordigt de verstreken tijd voor de gecontroleerde operator en al zijn kinderen , aangezien het kind per rij zijn eigen kind aanroept, enzovoort. Een operator kan vaak worden aangeroepen (om te initialiseren, dan één keer per rij, uiteindelijk om te sluiten), dus de tijd die wordt verzameld door de profileringsoperator is een accumulatie over mogelijk veel iteraties per rij.
Voor meer details over de profileringsgegevens verzameld met behulp van verschillende vastlegmethoden, zie de productdocumentatie over de Query Profiling Infrastructure. Voor degenen die in dergelijke zaken geïnteresseerd zijn, is de naam van de onzichtbare profileringsoperator die door de standaardinfrastructuur wordt gebruikt sqlmin!CQScanProfileNew . Zoals alle iterators van de rijmodus, heeft het Open , GetRow , en Close onder andere methoden. Elke methode bevat aanroepen naar de Windows QueryPerformanceCounter API om de huidige timerwaarde met hoge resolutie te verzamelen.
Aangezien de profileringsoperator zich aan de links bevindt van de doeloperator, meet het alleen de consument kant van de beurs. Er is geen profileringsoperator voor de producent kant van de beurs (helaas). Als dat zo zou zijn, zou het overeenkomen met of langer zijn dan de verstreken tijd die wordt weergegeven op de indexzoekopdracht, omdat de indexzoek- en de producentkant dezelfde reeks threads hebben en de producentkant van de uitwisseling de bovenliggende operator van de indexzoekopdracht is.
Timing opnieuw bezocht

Dat gezegd hebbende, heb je misschien nog steeds problemen met de hierboven getoonde timing. Hoe kan het zoeken naar een index 1.467s duren? om rijen door te geven aan de producentenkant van een beurs, maar de consumentenkant neemt slechts 0,517s om ze te ontvangen? Ongeacht afzonderlijke threads, buffering en dergelijke, zeker de uitwisseling zou (end-to-end) langer moeten duren dan de zoekactie?
Nou ja, dat doet het, maar dat is een andere meting van verstreken of CPU-tijd. Laten we precies zijn over wat we hier meten.
Voor rijmodus verstreken tijd , stel je een stopwatch per thread voor bij elke exploitant. De stopwatch start wanneer SQL Server de code invoert voor een operator van zijn ouder, en stopt (maar wordt niet gereset) wanneer die code de operator verlaat om de controle terug te geven aan de ouder (niet aan een kind). Verstreken tijd inclusief eventuele wachttijden of vertragingen in de planning - geen van beide stopt het horloge.
Voor rijmodus CPU-tijd , stel je dezelfde stopwatch voor met dezelfde kenmerken, behalve dat hij stopt tijdens wachttijden en vertragingen bij het plannen. Het verzamelt alleen tijd wanneer de operator of een van zijn kinderen actief bezig is met het uitvoeren van een planner (CPU). De totale tijd op een stopwatch per thread per operator is opgebouwd uit een start-stopcyclus voor elke rij.
Laten we dat toepassen op de huidige situatie met de consumentenkant van de beurs en de index zoekt:
Onthoud dat de consumentenkant van de uitwisseling en het zoeken naar indexen zich in verschillende branches bevinden, dus ze draaien op afzonderlijke threads . De consumentenkant heeft geen kinderen in dezelfde thread. De index-zoekopdracht heeft de producentkant van de uitwisseling als de ouder met dezelfde draad, maar we hebben daar geen stopwatch.
Elke consumententhread start zijn horloge wanneer de bovenliggende operator (de sondezijde van de hash-join) de controle doorgeeft (bijvoorbeeld om een rij op te halen). Het horloge loopt door terwijl de consument een rij uit het huidige ruilpakket haalt. Het horloge stopt wanneer de controle de consument verlaat en terugkeert naar de hash join-sondezijde. Verdere ouders (het gedeeltelijke aggregaat en de bovenliggende uitwisseling) werken ook aan die rij (en kunnen wachten) voordat de controle terugkeert naar de consumentenkant van onze uitwisseling om de volgende rij op te halen. Op dat moment begint de consumentenkant van onze uitwisseling de verstreken en CPU-tijd weer te verzamelen.
Ondertussen, onafhankelijk van wat de threads van de zijtak van de consument ook doen, de index-zoekfunctie threads blijven rijen in de index lokaliseren en invoeren in de uitwisseling. Een indexzoekthread start zijn stopwatch wanneer de producentkant van de beurs hem om een rij vraagt. De stopwatch wordt gepauzeerd wanneer de rij wordt doorgegeven aan de centrale. Wanneer de uitwisseling om de volgende rij vraagt, wordt de stopwatch voor het zoeken naar indexen hervat.
Merk op dat de producentenkant van de uitwisseling CXPACKET kan ervaren wacht terwijl de uitwisselingsbuffers vol raken, maar dat zal niet bijdragen aan de verstreken tijden die zijn geregistreerd bij het zoeken naar de index, omdat de stopwatch niet loopt wanneer dat gebeurt. Als we een stopwatch hadden voor de producentenkant van de beurs, zou de ontbrekende verstreken tijd daar verschijnen.
Om een visuele samenvatting van de situatie te schetsen, toont het volgende diagram wanneer elke operator de verstreken tijd in de twee parallelle takken accumuleert:
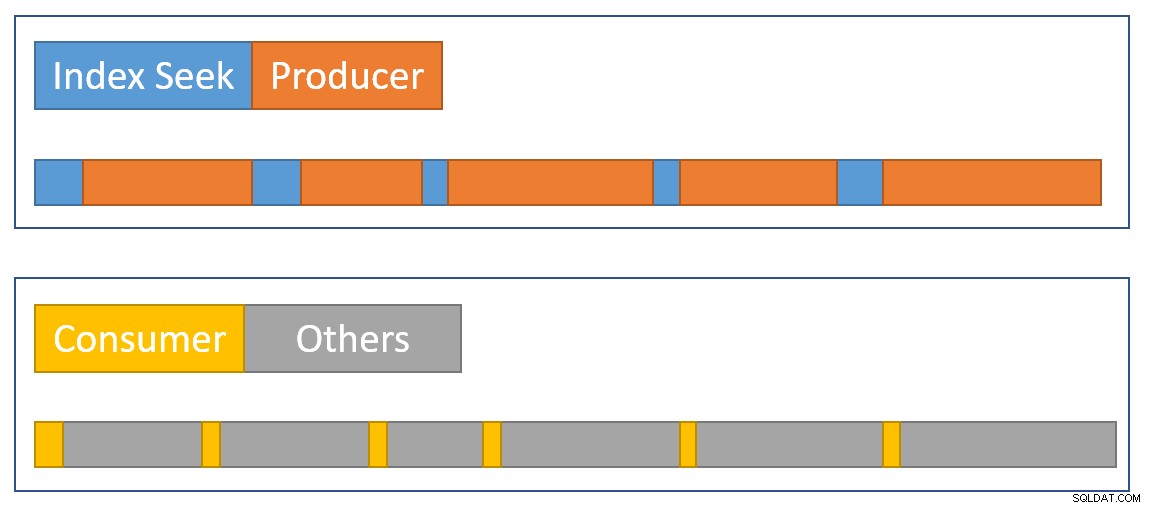
De blauwe index zoektijdbalken zijn kort omdat het ophalen van een rij uit een index snel gaat. De oranje productietijden kunnen lang zijn vanwege CXPACKET wacht. De gele consumententijden zijn kort omdat er snel een rij uit de centrale kan worden opgehaald wanneer gegevens beschikbaar zijn. De grijze tijdsegmenten vertegenwoordigen de tijd die wordt gebruikt door de andere operators (hash join-sondezijde, gedeeltelijk aggregaat en de producentzijde van de moederbeurs) boven de consumentenzijde van de beurs.
We verwachten dat de uitwisselingspakketten snel worden gevuld door de index zoeken, maar langzaam geleegd (relatief gezien) door de exploitanten aan de consumentenkant omdat ze meer werk te doen hebben. Dit betekent dat pakketten in de centrale meestal vol of bijna vol zijn. De consument kan een wachtrij snel ophalen, maar de producent moet mogelijk wachten tot er pakketruimte verschijnt.
Het is jammer dat we de verstreken tijd niet kunnen zien aan de producentenkant van de beurs. Ik ben al lang van mening dat een uitwisseling moet worden vertegenwoordigd door twee verschillende operators in uitvoeringsplannen. Het zou CXPACKET . moeilijk maken /CXCONSUMER wacht analyse veel minder nodig, en uitvoeringsplannen veel gemakkelijker te begrijpen. De exploitant van de beursproducent zou natuurlijk zijn eigen profileringsexploitant krijgen.
Alternatieve ontwerpen
Er zijn veel manieren waarop SQL Server consistente cumulatieve kan bereiken verstreken en CPU-tijd over parallelle takken in principe . In plaats van operators te profileren, kon elke rij informatie bevatten over de verstreken tijd en de CPU-tijd die het tot nu toe had opgebouwd tijdens zijn reis door het plan. Met de geschiedenis die aan elke rij is gekoppeld, maakt het niet uit hoe exchanges rijen herverdelen over threads, enzovoort.
Dat is niet hoe het product is ontworpen, dus dat is niet wat we hebben (en het kan hoe dan ook inefficiënt zijn). Om eerlijk te zijn, had het oorspronkelijke ontwerp van de rijmodus alleen betrekking op zaken als het verzamelen van het werkelijke aantal rijen en het aantal herhalingen bij elke operator. Het toevoegen van verstreken tijd per operator aan plannen was een veelgevraagde functie , maar het was niet eenvoudig om in het bestaande raamwerk op te nemen.
Toen batchverwerking aan het product werd toegevoegd, kon een andere benadering (timing alleen voor de huidige operator) worden geïmplementeerd als onderdeel van de oorspronkelijke ontwikkeling zonder iets te breken. Nogmaals, in principe , rijmodusoperatoren hadden kunnen worden aangepast om op dezelfde manier te werken als batchmodusoperatoren, maar dat zou veel werk hebben gekost om elke bestaande rijmodusoperator opnieuw te ontwerpen. Het toevoegen van een nieuw gegevenspunt aan de bestaande profileringsoperatoren in de rijmodus was veel eenvoudiger. Gezien de beperkte technische middelen en een lange lijst van gewenste productverbeteringen, moeten dergelijke compromissen vaak worden gesloten.
Het tweede probleem
Een andere cumulatieve inconsistentie in de timing doet zich voor in het huidige plan aan de linkerkant:

Op het eerste gezicht lijkt dit hetzelfde probleem:het gedeeltelijke aggregaat heeft een verstreken tijd van 4.662s , maar de uitwisseling erboven werkt slechts voor 2.844s . Dezelfde basismechanica als voorheen is natuurlijk van toepassing, maar er is nog een andere belangrijke factor. Een aanwijzing ligt in de verdacht gelijke tijden die zijn gerapporteerd voor de stream-aggregatie-, sorteer- en herpartitioneringsuitwisseling.
Herinner je je de "timingaanpassingen" die ik in de inleiding noemde? Dit is waar die binnenkomen. Laten we eens kijken naar de individuele verstreken tijden voor threads aan de consumentenkant van de uitwisseling van herverdelingsstromen:
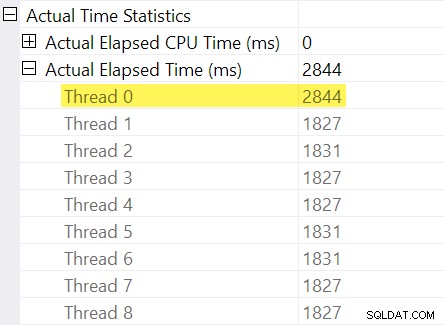
Bedenk dat plannen de verstreken tijd voor een parallelle operator weergeven als het maximum van de tijden per draad. Alle 8 threads hadden een verstreken tijd van ongeveer 1.830 ms, maar er is een extra invoer voor "Thread 0" met 2.844 ms. Inderdaad elke operator in deze parallelle tak (de uitwisselingsconsument, het soort en het stroomaggregaat) hebben dezelfde 2.844 ms bijdrage van "Thread 0".
Thread nul (ook bekend als bovenliggende taak of coördinator) voert operators alleen rechtstreeks uit aan de linkerkant van de laatste operator voor het verzamelen van streams. Waarom is er hier werk aan toegewezen, in een parallelle tak?
Uitleg
Dit probleem kan optreden wanneer er een blokkerende operator is in de parallelle tak hieronder (rechts van) de huidige. Zonder deze aanpassing zouden operators in de huidige vestiging verstreken tijd te weinig rapporteren met de hoeveelheid tijd die nodig is om de onderliggende vertakking te openen (er zijn ingewikkelde architectonische redenen hiervoor).
SQL Server probeert hier rekening mee te houden door de vertraging van de onderliggende vertakking bij de centrale vast te leggen in de onzichtbare profileringsoperator. De tijdwaarde wordt geregistreerd tegen de bovenliggende taak ("Thread 0") in het verschil tussen de eerste actieve en laatst actief keer. (Het lijkt misschien vreemd om het nummer op deze manier vast te leggen, maar op het moment dat het nummer moet worden vastgelegd, zijn de extra parallelle werkthreads nog niet gemaakt).
In het huidige geval is de 2.844 ms aanpassing ontstaat voornamelijk vanwege de tijd die de hash-join nodig heeft om zijn hash-tabel te bouwen. (Let op:deze tijd is anders dan het totaal uitvoeringstijd van de hash-join, inclusief de tijd die nodig is om de testzijde van de join te verwerken).
De noodzaak voor een aanpassing ontstaat omdat een hash-join de build-invoer blokkeert. (Interessant is dat het hash gedeeltelijke aggregaat in het plan wordt in deze context niet als blokkering beschouwd omdat het slechts een minimale hoeveelheid geheugen toegewezen krijgt, nooit overloopt naar tempdb , en stopt gewoon met aggregeren als het geheugen vol raakt (en daardoor terugkeert naar een streamingmodus). Craig Freedman legt dit uit in zijn post, Partial Aggregation).
Aangezien de aanpassing van de verstreken tijd een initialisatievertraging in de onderliggende vertakking vertegenwoordigt, moet SQL Server zou om de waarde “Thread 0” te behandelen als een offset voor de gemeten per-thread verstreken tijdnummers binnen de huidige tak. Het maximum . nemen van alle threads aangezien de verstreken tijd over het algemeen redelijk is, omdat threads de neiging hebben om op hetzelfde moment te beginnen. Het doet niet zinvol om dit te doen wanneer een van de draadwaarden een offset is voor alle andere waarden!
We kunnen de juiste offsetberekening . doen handmatig met behulp van de gegevens die beschikbaar zijn in het plan. Aan de consumentenkant van de beurs hebben we:
De maximale verstreken tijd tussen de extra werkthreads is 1.831ms (exclusief de offsetwaarde die is opgeslagen in "Thread 0"). De offset . toevoegen van 2.844 ms geeft een totaal van 4.675 ms .
In elk abonnement waarbij de tijden per thread minder zijn dan de offset, zal de operator onjuist toon de offset als de totale verstreken tijd. Dit is waarschijnlijk het geval wanneer de eerdere blokkerende operator traag is (misschien een soort of globale aggregatie over een grote set gegevens) en de latere vertakkingsoperatoren minder tijdrovend zijn.
Dit deel van het plan opnieuw bekijken:
Vervanging van de 2.844 ms offset die ten onrechte is toegewezen aan de operators voor herverdeling van streams, sortering en streamaggregatie door onze berekende 4.675ms waarde plaatst hun cumulatieve verstreken tijd netjes tussen de 4.662 ms bij het gedeeltelijke totaal en de 4.676 ms bij de laatste verzamelstromen. (Het sorteren en aggregeren werken op een klein aantal rijen, zodat hun berekeningen voor de verstreken tijd hetzelfde zijn als het sorteren, maar over het algemeen zouden ze vaak anders zijn):

Alle operators in het bovenstaande planfragment hebben 0 ms verstreken CPU-tijd over alle threads (afgezien van het gedeeltelijke totaal, dat 14.891 ms heeft). Het plan met onze berekende getallen is daarom veel logischer dan het weergegeven plan:
- 4.675ms – 4.662ms =13ms verstreken is een veel redelijker aantal voor de tijd die wordt verbruikt door de herpartitiestreams alleen . Deze operator verbruikt geen CPU-tijd en verwerkt slechts 524 rijen.
- 0 ms verstreken (tot milliseconde resolutie) is redelijk voor de kleine soort en stream-aggregaat (wederom, met uitzondering van hun kinderen).
- 4.676ms – 4.675ms =1ms lijkt goed voor de laatste verzamelstreams om 66 rijen op de bovenliggende taakthread te verzamelen voor teruggave aan de klant.
Afgezien van de duidelijke inconsistentie in het gegeven plan tussen de gedeeltelijke aggregaat (4.662 ms) en herverdelingsstromen (2.844 ms), is het onredelijk om te denken dat de uiteindelijke verzamelstromen van 66 rijen verantwoordelijk kunnen zijn voor 4.676 ms - 2.844 ms = 1.832ms van verstreken tijd. Het gecorrigeerde aantal (1 ms) is veel nauwkeuriger en zal de vraagstemmers niet misleiden.
Nu, zelfs als deze offsetberekening correct zou zijn uitgevoerd, zouden parallelle rijmodusplannen niet . kunnen zijn tonen consistente cumulatieve tijden in alle gevallen, om de eerder besproken redenen. Het bereiken van volledige consistentie kan moeilijk of zelfs onmogelijk zijn zonder grote architecturale veranderingen.
Om te anticiperen op een vraag die zich op dit punt zou kunnen voordoen:Nee, bij de eerdere analyse van uitwisseling en index zoeken was er geen "Thread 0" offset-berekeningsfout. Er is geen blokkerende operator onder die centrale, dus er treedt geen initialisatievertraging op.
Een laatste voorbeeld
Deze volgende voorbeeldquery gebruikt dezelfde database en index als voorheen. Ik zal er niet te veel in detail op ingaan, want het dient alleen ter uitbreiding van punten die ik al heb gemaakt, voor de geïnteresseerde lezer.
De kenmerken van deze demo zijn:
- Zonder een
ORDER GROUPhint, het laat zien hoe een gedeeltelijk aggregaat niet als een blokkerende operator wordt beschouwd, dus er ontstaat geen "Thread 0" -aanpassing bij de uitwisseling van herverdelingsstromen. De verstreken tijden zijn consistent. - Met de hint worden blokkerende soorten geïntroduceerd in plaats van een hash-gedeeltelijk aggregaat. Twee verschillende "Thread 0" -aanpassingen verschijnen op de twee herpartitioneringsuitwisselingen. Verstreken tijden zijn inconsistent op beide takken, op verschillende manieren.
Vraag:
SELECT * FROM
(
SELECT
yr = YEAR(P.CreationDate),
mth = MONTH(P.CreationDate),
mx = MAX(P.CreationDate)
FROM dbo.Posts AS P
WHERE
P.PostTypeId = 1
GROUP BY
YEAR(P.CreationDate),
MONTH(P.CreationDate)
) AS C1
JOIN
(
SELECT
yr = YEAR(P.CreationDate),
mth = MONTH(P.CreationDate),
mx = MAX(P.CreationDate)
FROM dbo.Posts AS P
WHERE
P.PostTypeId = 2
GROUP BY
YEAR(P.CreationDate),
MONTH(P.CreationDate)
) AS C2
ON C2.yr = C1.yr
AND C2.mth = C1.mth
ORDER BY
C1.yr ASC,
C1.mth ASC
OPTION
(
--ORDER GROUP,
USE HINT ('DISALLOW_BATCH_MODE')
);
Uitvoeringsplan zonder ORDER GROUP (geen aanpassing, consistente tijden):

Uitvoeringsplan met ORDER GROUP (twee verschillende aanpassingen, inconsistente tijden):

Samenvatting en conclusies
Row mode plan operators report cumulative times inclusive of all child operators in the same thread. Batch mode operators record the time used inside that operator alone .
A single plan can include both row and batch mode operators; the row mode operators will record cumulative elapsed time, including any batch operators. Correctly interpreting elapsed times in mixed-mode plans can be challenging.
For parallel plans, total CPU time for an operator is the sum of individual thread contributions. Total elapsed time is the maximum of the per-thread numbers.
Row mode actual plans include an invisible profiling operator to the immediate left (parent) of executing visible operators to collect runtime statistics like total row count, number of iterations, and timings. Because the row mode profiling operator is a parent of the target operator, it captures activity for that operator and all children (but only in the same thread).
Exchanges are row mode operators. There is no separate hidden profiling operator for the producer side, so exchanges only show details and timings for the consumer side . The consumer side has no children in the same thread so it reports timings for itself only.
Long elapsed times on an exchange with low CPU usage generally mean the consumer side has to wait for rows (CXCONSUMER ). This is often caused by a slow producer side (with various root causes). For an example of that with a super investigation, see CXCONSUMER As a Sign of Slow Parallel Joins by Josh Darneli.
Batch mode operators do not use separate profiling operators. The batch mode operator itself contains code to record timing on every entry and exit (e.g. per batch). Passing control to a child operator counts as an exit . This is why batch mode operators record only their own activity (exclusive of their child operators).
Internal architectural details mean the way parallel row mode plans start up would cause elapsed times to be under-reported for operators in a parallel branch when a child parallel branch contains a blocking operator. An attempt is made to adjust for the timing offset caused by this, but the implementation appears to be incomplete, resulting in inconsistent and potentially misleading elapsed times. Multiple separate adjustments may be present in a single execution plan. Adjustments may accumulate when multiple branches contain blocking operators, and a single operator may combine more than one adjustment (e.g. merge join with an adjustment on each input).
Without the attempted adjustments, parallel row-mode plans would only show consistent elapsed times within a branch (i.e. between parallelism operators). This would not be ideal, but it would arguably be better than the current situation. As it is, we simply cannot trust elapsed times in parallel row-mode plans to be a true reflection of reality.
Look out for “Thread 0” elapsed times on exchanges, and the associated branch plan operators. These will sometimes show up as implausibly identical times for operators within that branch. You may need to manually add the offset to the maximum per-thread times for each affected operator to get sensible results.
The same adjustment mechanism exists for CPU times , but it appears non-functional at the moment. Unfortunately, this means you should not expect CPU times to be cumulative across branches in row mode parallel plans. This is somewhat ironic because it does make sense to sum CPU times (including the “Thread 0” value). I doubt many people rely on cumulative CPU times in execution plans though.
With any luck, these calculations will be improved in a future product update, if the required corrective work is not too onerous.
In the meantime, this all represents another reason to prefer batch mode plans when dealing with even moderately large numbers of rows. Performance will usually be improved, and the timing numbers will make more sense. Remember, SQL Server 2019 makes batch mode processing easier to achieve in practice because it does not require a columnstore index.