Dit is het derde deel in een serie over oplossingen voor de uitdaging voor het genereren van getallenreeksen. In deel 1 heb ik oplossingen behandeld die de rijen on-the-fly genereren. In deel 2 heb ik oplossingen behandeld die een fysieke basistabel opvragen die u vooraf met rijen vult. Deze maand ga ik me concentreren op een fascinerende techniek die kan worden gebruikt om onze uitdaging aan te gaan, maar die ook interessante toepassingen heeft die veel verder gaan. Ik ben niet op de hoogte van een officiële naam voor de techniek, maar het lijkt qua concept enigszins op de verwijdering van horizontale partities, dus ik zal er informeel naar verwijzen als de verwijdering van horizontale eenheden techniek. De techniek kan interessante positieve prestatievoordelen hebben, maar er zijn ook kanttekeningen waarvan u zich bewust moet zijn, waar deze onder bepaalde omstandigheden een prestatiestraf kan opleveren.
Nogmaals bedankt aan Alan Burstein, Joe Obbish, Adam Machanic, Christopher Ford, Jeff Moden, Charlie, NoamGr, Kamil Kosno, Dave Mason, John Nelson #2, Ed Wagner, Michael Burbea en Paul White voor het delen van uw ideeën en opmerkingen.
Ik zal mijn testen doen in tempdb, zodat tijdstatistieken mogelijk zijn:
SET NOCOUNT ON; USE tempdb; SET STATISTICS TIME ON;
Eerdere ideeën
De techniek voor horizontale eliminatie van eenheden kan worden gebruikt als alternatief voor de logica voor kolomeliminatie, of verticale eliminatie van eenheden techniek, waarop ik vertrouwde in verschillende van de oplossingen die ik eerder heb behandeld. U kunt meer lezen over de grondbeginselen van de logica van kolomverwijdering met tabeluitdrukkingen in Grondbeginselen van tabeluitdrukkingen, deel 3 – Afgeleide tabellen, overwegingen voor optimalisatie onder "Kolomprojectie en een woord op SELECT *."
Het basisidee van de techniek voor het elimineren van verticale eenheden is dat als u een geneste tabelexpressie hebt die de kolommen x en y retourneert, en uw buitenste query alleen naar kolom x verwijst, het querycompilatieproces y elimineert uit de initiële queryboom, en dus het plan hoeft het niet te evalueren. Dit heeft verschillende positieve implicaties voor optimalisatie, zoals het bereiken van indexdekking met alleen x, en als y het resultaat is van een berekening, hoeft de onderliggende uitdrukking van y helemaal niet te worden geëvalueerd. Dit idee vormde de kern van de oplossing van Alan Burstein. Ik vertrouwde er ook op in verschillende van de andere oplossingen die ik behandelde, zoals met de functie dbo.GetNumsAlanCharlieItzikBatch (uit Part 1), de functies dbo.GetNumsJohn2DaveObbishAlanCharlieItzik en dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2 (uit Part 2), en anderen. Als voorbeeld gebruik ik dbo.GetNumsAlanCharlieItzikBatch als de basislijnoplossing met de verticale eliminatielogica.
Ter herinnering:deze oplossing gebruikt een join met een dummy-tabel die een columnstore-index heeft om batchverwerking te krijgen. Hier is de code om de dummy-tabel te maken:
DROP TABLE IF EXISTS dbo.BatchMe; GO CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
En hier is de code met de definitie van de dbo.GetNumsAlanCharlieItzikBatch-functie:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum;
GO Ik heb de volgende code gebruikt om de prestaties van de functie te testen met 100 miljoen rijen, waarbij ik de berekende resultaatkolom n retourneerde (manipulatie van het resultaat van de ROW_NUMBER-functie), geordend op n:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) ORDER BY n OPTION(MAXDOP 1);
Dit zijn de tijdstatistieken die ik voor deze test heb gekregen:
CPU-tijd =9328 ms, verstreken tijd =9330 ms.Ik heb de volgende code gebruikt om de prestaties van de functie te testen met 100 miljoen rijen, waarbij de kolom rn werd geretourneerd (direct, niet-gemanipuleerd, resultaat van de ROW_NUMBER-functie), geordend op rn:
DECLARE @n AS BIGINT; SELECT @n = rn FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) ORDER BY rn OPTION(MAXDOP 1);
Dit zijn de tijdstatistieken die ik voor deze test heb gekregen:
CPU-tijd =7296 ms, verstreken tijd =7291 ms.Laten we eens kijken naar de belangrijke ideeën die zijn ingebed in deze oplossing.
Alan baseerde zich op de logica van kolomverwijdering en kwam op het idee om niet slechts één kolom met de getallenreeks terug te geven, maar drie:
- Kolom rn vertegenwoordigt een niet-gemanipuleerd resultaat van de ROW_NUMBER-functie, die begint met 1. Het is goedkoop om te berekenen. Het is ordebehoud, zowel wanneer u constanten opgeeft als wanneer u niet-constanten (variabelen, kolommen) opgeeft als invoer voor de functie. Dit betekent dat wanneer uw buitenste query ORDER BY rn gebruikt, u geen sorteeroperator in het plan krijgt.
- Kolom n vertegenwoordigt een berekening op basis van @low, een constante en rownum (resultaat van de functie ROW_NUMBER). Het is ordebehoud met betrekking tot rownum wanneer u constanten opgeeft als invoer voor de functie. Dat is te danken aan Charlie's inzicht met betrekking tot constant vouwen (zie deel 1 voor details). Het is echter niet om de volgorde te behouden wanneer u niet-constanten als invoer opgeeft, omdat u niet constant vouwt. Ik zal dit later demonstreren in het gedeelte over voorbehouden.
- Kolom op staat voor n in tegengestelde volgorde. Het is het resultaat van een berekening en het is niet om de volgorde te behouden.
Als u op basis van de logica voor het elimineren van kolommen een reeks getallen wilt retourneren die met 1 begint, zoekt u naar kolom rn, wat goedkoper is dan het opvragen van n. Als u een getallenreeks nodig heeft die begint met een andere waarde dan 1, zoekt u naar n en betaalt u de extra kosten. Als u het resultaat nodig hebt, geordend op de nummerkolom, met constanten als invoer, kunt u ORDER BY rn of ORDER BY n gebruiken. Maar met niet-constanten als invoer, wil je er zeker van zijn dat je ORDER BY rn gebruikt. Het is misschien een goed idee om altijd ORDER BY rn te gebruiken wanneer u het resultaat wilt bestellen om aan de veilige kant te blijven.
Het idee van horizontale eliminatie van eenheden is vergelijkbaar met het idee van verticale eliminatie van eenheden, alleen is het van toepassing op reeksen rijen in plaats van reeksen kolommen. Joe Obbish vertrouwde zelfs op dit idee in zijn functie dbo.GetNumsObbish (uit deel 2), en we gaan nog een stap verder. In zijn oplossing verenigde Joe meerdere query's die onsamenhangende subbereiken van getallen vertegenwoordigen, met behulp van een filter in de WHERE-component van elke query om de toepasbaarheid van het subbereik te definiëren. Wanneer u de functie aanroept en constante invoer doorgeeft die de scheidingstekens van uw gewenste bereik vertegenwoordigen, elimineert SQL Server de niet-toepasbare query's tijdens het compileren, zodat het plan ze niet eens weerspiegelt.
Horizontale eenheidseliminatie, compileertijd versus runtime
Misschien zou het een goed idee zijn om te beginnen met het demonstreren van het concept van horizontale eenheidseliminatie in een meer algemeen geval, en ook een belangrijk onderscheid te bespreken tussen compile-time en runtime-eliminatie. Dan kunnen we bespreken hoe we het idee kunnen toepassen op onze uitdaging voor getallenreeksen.
Ik gebruik in mijn voorbeeld drie tabellen met de naam dbo.T1, dbo.T2 en dbo.T3. Gebruik de volgende DDL- en DML-code om deze tabellen te maken en te vullen:
DROP TABLE IF EXISTS dbo.T1, dbo.T2, dbo.T3; GO CREATE TABLE dbo.T1(col1 INT); INSERT INTO dbo.T1(col1) VALUES(1); CREATE TABLE dbo.T2(col1 INT); INSERT INTO dbo.T2(col1) VALUES(2); CREATE TABLE dbo.T3(col1 INT); INSERT INTO dbo.T3(col1) VALUES(3);
Stel dat u een inline TVF met de naam dbo.OneTable wilt implementeren die een van de drie bovenstaande tabelnamen als invoer accepteert en de gegevens uit de gevraagde tabel retourneert. Gebaseerd op het concept voor het elimineren van horizontale eenheden, zou u de functie als volgt kunnen implementeren:
CREATE OR ALTER FUNCTION dbo.OneTable(@WhichTable AS NVARCHAR(257)) RETURNS TABLE AS RETURN SELECT col1 FROM dbo.T1 WHERE @WhichTable = N'dbo.T1' UNION ALL SELECT col1 FROM dbo.T2 WHERE @WhichTable = N'dbo.T2' UNION ALL SELECT col1 FROM dbo.T3 WHERE @WhichTable = N'dbo.T3'; GO
Onthoud dat een inline TVF parameterinbedding toepast. Dit betekent dat wanneer u een constante zoals N'dbo.T2' als invoer doorgeeft, het inlining-proces alle verwijzingen naar @WhichTable vervangt door de constante vóór optimalisatie . Het eliminatieproces kan vervolgens de verwijzingen naar T1 en T3 uit de oorspronkelijke zoekstructuur verwijderen, en zo resulteert de optimalisatie van de zoekopdracht in een plan dat alleen naar T2 verwijst. Laten we dit idee testen met de volgende vraag:
SELECT * FROM dbo.OneTable(N'dbo.T2');
Het plan voor deze zoekopdracht wordt getoond in figuur 1.
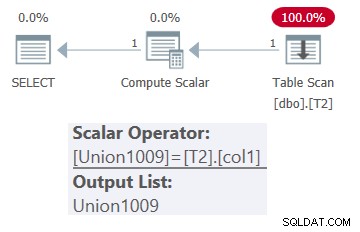 Figuur 1:Plan voor dbo.OneTable met constante invoer
Figuur 1:Plan voor dbo.OneTable met constante invoer
Zoals je kunt zien, verschijnt alleen tafel T2 in het plan.
Het wordt wat lastiger als je een niet-constante als invoer doorgeeft. Dit kan het geval zijn bij het gebruik van een variabele, een procedureparameter of het doorgeven van een kolom via APPLY. De invoerwaarde is ofwel onbekend tijdens het compileren, of er moet rekening worden gehouden met het potentieel voor hergebruik van het plan.
De optimizer kan geen van de tabellen uit het plan verwijderen, maar hij heeft nog steeds een truc. Het kan opstartfilteroperators gebruiken boven de substructuren die toegang hebben tot de tabellen, en alleen de relevante substructuur uitvoeren op basis van de runtime-waarde van @WhichTable. Gebruik de volgende code om deze strategie te testen:
DECLARE @T AS NVARCHAR(257) = N'dbo.T2'; SELECT * FROM dbo.OneTable(@T);
Het plan voor deze uitvoering is weergegeven in figuur 2:
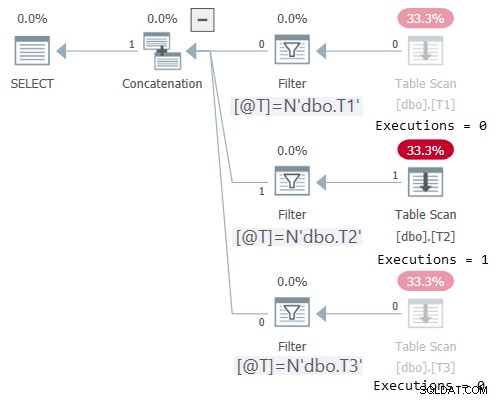 Figuur 2:Plan voor dbo.OneTable met niet-constante invoer
Figuur 2:Plan voor dbo.OneTable met niet-constante invoer
Plan Explorer maakt het wonderbaarlijk duidelijk om te zien dat alleen de toepasselijke substructuur is uitgevoerd (Uitvoeringen =1), en grijst de subbomen die niet zijn uitgevoerd (Uitvoeringen =0). STATISTICS IO toont ook alleen I/O-info voor de tabel die is geopend:
Tabel 'T2'. Aantal scans 1, logische leest 1, fysieke leest 0, paginaserver leest 0, read-ahead leest 0, pageserver read-ahead leest 0, lob logische leest 0, lob fysieke leest 0, lob pageserver leest 0, lob read- vooruit leest 0, lob page server read-ahead leest 0.Horizontale logica voor het elimineren van eenheden toepassen op de uitdaging van de getallenreeks
Zoals vermeld, kunt u het concept voor horizontale eliminatie van eenheden toepassen door een van de eerdere oplossingen te wijzigen die momenteel verticale eliminatielogica gebruiken. Ik gebruik de functie dbo.GetNumsAlanCharlieItzikBatch als startpunt voor mijn voorbeeld.
Bedenk dat Joe Obbish horizontale eenheidseliminatie gebruikte om de relevante disjuncte deelbereiken van de getallenreeks te extraheren. We zullen het concept gebruiken om de goedkopere berekening (rn) waar @low =1 horizontaal te scheiden van de duurdere berekening (n) waarbij @low <> 1.
Terwijl we toch bezig zijn, kunnen we experimenteren door het idee van Jeff Moden toe te voegen aan zijn fnTally-functie, waar hij een schildwachtrij gebruikt met de waarde 0 voor gevallen waarin het bereik begint met @low =0.
We hebben dus vier horizontale eenheden:
- Sentinelrij met 0 waarbij @low =0, met n =0
- TOP (@high) rijen waarbij @low =0, met goedkope n =rownum, en op =@high – rownum
- TOP (@high) rijen waar @low =1, met goedkope n =rownum, en op =@high + 1 – rownum
- TOP(@high – @low + 1) rijen waarbij @low <> 0 AND @low <> 1, met duurdere n =@low – 1 + rownum, en op =@high + 1 – rownum
Deze oplossing combineert ideeën van Alan, Charlie, Joe, Jeff en mezelf, dus we noemen de batch-modusversie van de functie dbo.GetNumsAlanCharlieJoeJeffItzikBatch.
Denk er eerst aan om ervoor te zorgen dat u nog steeds de dummy-tabel dbo.BatchMe aanwezig hebt om batchverwerking in onze oplossing te krijgen, of gebruik de volgende code als u dat niet doet:
DROP TABLE IF EXISTS dbo.BatchMe; GO CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
Hier is de code met de definitie van dbo.GetNumsAlanCharlieJoeJeffItzikBatch-functie:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieJoeJeffItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT @low AS n, @high AS op WHERE @low = 0 AND @high > @low
UNION ALL
SELECT TOP(@high)
rownum AS n,
@high - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
WHERE @low = 0
ORDER BY rownum
UNION ALL
SELECT TOP(@high)
rownum AS n,
@high + 1 - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
WHERE @low = 1
ORDER BY rownum
UNION ALL
SELECT TOP(@high - @low + 1)
@low - 1 + rownum AS n,
@high + 1 - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
WHERE @low <> 0 AND @low <> 1
ORDER BY rownum;
GO Belangrijk:het concept voor het elimineren van horizontale eenheden is ongetwijfeld complexer om te implementeren dan het verticale, dus waarom zou je je druk maken? Omdat het de verantwoordelijkheid om de juiste kolom te kiezen bij de gebruiker wegneemt. De gebruiker hoeft zich alleen zorgen te maken over het opvragen van een kolom met de naam n, in plaats van eraan te denken rn te gebruiken wanneer het bereik begint met 1, en anders met n.
Laten we beginnen met het testen van de oplossing met constante invoer 1 en 100.000.000, en vragen om het resultaat te bestellen:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeJeffItzikBatch(1, 100000000) ORDER BY n OPTION(MAXDOP 1);
Het plan voor deze uitvoering is weergegeven in figuur 3.
 Figuur 3:Plan voor dbo.GetNumsAlanCharlieJoeJeffItzikBatch(1, 100M)
Figuur 3:Plan voor dbo.GetNumsAlanCharlieJoeJeffItzikBatch(1, 100M)
Merk op dat de enige geretourneerde kolom is gebaseerd op de directe, niet-gemanipuleerde ROW_NUMBER-expressie (Expr1313). Merk ook op dat er niet hoeft te worden gesorteerd in het plan.
Ik heb de volgende tijdstatistieken voor deze uitvoering:
CPU-tijd =7359 ms, verstreken tijd =7354 ms.De runtime weerspiegelt adequaat het feit dat het plan de batchmodus, de niet-gemanipuleerde ROW_NUMBER-expressie en geen sortering gebruikt.
Test vervolgens de functie met het constante bereik 0 tot 99.999.999:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeJeffItzikBatch(0, 99999999) ORDER BY n OPTION(MAXDOP 1);
Het plan voor deze uitvoering is weergegeven in figuur 4.
 Figuur 4:Plan voor dbo.GetNumsAlanCharlieJoeJeffItzikBatch(0, 99999999)
Figuur 4:Plan voor dbo.GetNumsAlanCharlieJoeJeffItzikBatch(0, 99999999)
Het plan maakt gebruik van een Merge Join (Concatenation)-operator om de schildwachtrij samen te voegen met de waarde 0 en de rest. Hoewel het tweede deel even efficiënt is als voorheen, eist de samenvoeglogica een behoorlijk hoge tol van ongeveer 26% tijdens de looptijd, wat resulteert in de volgende tijdstatistieken:
CPU-tijd =9265 ms, verstreken tijd =9298 ms.Laten we de functie testen met het constante bereik 2 tot 100.000.001:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeJeffItzikBatch(2, 100000001) ORDER BY n OPTION(MAXDOP 1);
Het plan voor deze uitvoering wordt getoond in figuur 5.
 Figuur 5:Plan voor dbo.GetNumsAlanCharlieJoeJeffItzikBatch(2, 100000001)
Figuur 5:Plan voor dbo.GetNumsAlanCharlieJoeJeffItzikBatch(2, 100000001)
Deze keer is er geen dure samenvoeglogica omdat het schildwachtrijgedeelte niet relevant is. Merk echter op dat de geretourneerde kolom de gemanipuleerde uitdrukking @low – 1 + rownum is, die na inbedding/inlining van parameters en constant vouwen 1 + rownum werd.
Dit zijn de tijdstatistieken die ik voor deze uitvoering heb gekregen:
CPU-tijd =9000 ms, verstreken tijd =9015 ms.Zoals verwacht is dit niet zo snel als bij een bereik dat begint met 1, maar interessant genoeg sneller dan bij een bereik dat begint met 0.
De 0 schildwachtrij verwijderen
Aangezien de techniek met de schildwachtrij met de waarde 0 langzamer lijkt te zijn dan het toepassen van manipulatie op rijnum, is het logisch om het gewoon te vermijden. Dit brengt ons bij een vereenvoudigde, op horizontale eliminatie gebaseerde oplossing die de ideeën van Alan, Charlie, Joe en mijzelf combineert. Ik noem de functie met deze oplossing dbo.GetNumsAlanCharlieJoeItzikBatch. Dit is de definitie van de functie:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieJoeItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high)
rownum AS n,
@high + 1 - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
WHERE @low = 1
ORDER BY rownum
UNION ALL
SELECT TOP(@high - @low + 1)
@low - 1 + rownum AS n,
@high + 1 - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
WHERE @low <> 1
ORDER BY rownum;
GO Laten we het testen met het bereik van 1 tot 100M:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeItzikBatch(1, 100000000) ORDER BY n OPTION(MAXDOP 1);
Het plan is zoals verwacht hetzelfde als eerder in figuur 3 getoond.
Dienovereenkomstig heb ik de volgende tijdstatistieken:
CPU-tijd =7219 ms, verstreken tijd =7243 ms.Test het met het bereik 0 tot 99.999.999:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeItzikBatch(0, 99999999) ORDER BY n OPTION(MAXDOP 1);
Deze keer krijg je hetzelfde plan als eerder in figuur 5, niet in figuur 4.
Dit zijn de tijdstatistieken die ik voor deze uitvoering heb gekregen:
CPU-tijd =9313 ms, verstreken tijd =9334 ms.Test het met het bereik 2 tot 100.000,001:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeItzikBatch(2, 100000001) ORDER BY n OPTION(MAXDOP 1);
Wederom krijg je hetzelfde plan als eerder getoond in figuur 5.
Ik heb de volgende tijdstatistieken voor deze uitvoering:
CPU-tijd =9125 ms, verstreken tijd =9148 ms.Voorbehoud bij gebruik van niet-constante invoer
Met zowel de verticale als de horizontale eliminatietechnieken voor eenheden, werkt het ideaal zolang je constanten als invoer doorgeeft. U moet zich echter bewust zijn van kanttekeningen die kunnen leiden tot prestatiestraffen wanneer u niet-constante invoer doorgeeft. De techniek voor het elimineren van verticale eenheden heeft minder problemen en de problemen die er zijn, zijn gemakkelijker op te lossen, dus laten we ermee beginnen.
Onthoud dat we in dit artikel de functie dbo.GetNumsAlanCharlieItzikBatch hebben gebruikt als ons voorbeeld, dat is gebaseerd op het concept voor verticale eliminatie van eenheden. Laten we een reeks tests uitvoeren met niet-constante invoer, zoals variabelen.
Als onze eerste test zullen we rn retourneren en om de gegevens vragen die zijn besteld door rn:
DECLARE @mylow AS BIGINT = 1, @myhigh AS BIGINT = 100000000; DECLARE @n AS BIGINT; SELECT @n = rn FROM dbo.GetNumsAlanCharlieItzikBatch(@mylow, @myhigh) ORDER BY rn OPTION(MAXDOP 1);
Onthoud dat rn de niet-gemanipuleerde ROW_NUMBER-expressie vertegenwoordigt, dus het feit dat we niet-constante invoer gebruiken heeft in dit geval geen speciale betekenis. Er is geen behoefte aan expliciete sortering in het plan.
Ik heb de volgende tijdstatistieken voor deze uitvoering:
CPU-tijd =7390 ms, verstreken tijd =7386 ms.Deze cijfers vertegenwoordigen het ideale geval.
In de volgende test, rangschik de resultaatrijen op n:
DECLARE @mylow AS BIGINT = 1, @myhigh AS BIGINT = 100000000; DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(@mylow, @myhigh) ORDER BY n OPTION(MAXDOP 1);
Het plan voor deze uitvoering is weergegeven in figuur 6.
 Figuur 6:Plan voor dbo.GetNumsAlanCharlieItzikBatch(@mylow, @myhigh) bestellen door n
Figuur 6:Plan voor dbo.GetNumsAlanCharlieItzikBatch(@mylow, @myhigh) bestellen door n
Zie je het probleem? Na inlining werd @low vervangen door @mylow - niet met de waarde in @mylow, die 1 is. Bijgevolg vond er geen constant vouwen plaats, en daarom is n geen volgordebehoud met betrekking tot rijnum. Dit resulteerde in een expliciete sortering in het plan.
Dit zijn de tijdstatistieken die ik voor deze uitvoering heb gekregen:
CPU-tijd =25141 ms, verstreken tijd =25628 ms.De uitvoeringstijd is bijna verdrievoudigd in vergelijking met wanneer expliciet sorteren niet nodig was.
Een eenvoudige oplossing is om het oorspronkelijke idee van Alan Burstein te gebruiken om altijd op rn te bestellen wanneer u het resultaat wilt bestellen, zowel bij het retourneren van rn als bij het retourneren van n, zoals:
DECLARE @mylow AS BIGINT = 1, @myhigh AS BIGINT = 100000000; DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(@mylow, @myhigh) ORDER BY rn OPTION(MAXDOP 1);
Deze keer is er geen expliciete sortering in het plan.
Ik heb de volgende tijdstatistieken voor deze uitvoering:
CPU-tijd =9156 ms, verstreken tijd =9184 ms.De cijfers geven adequaat weer dat u de gemanipuleerde uitdrukking retourneert, maar niet expliciet sorteert.
Met oplossingen die zijn gebaseerd op de horizontale eenheidseliminatietechniek, zoals onze dbo.GetNumsAlanCharlieJoeItzikBatch-functie, is de situatie gecompliceerder bij het gebruik van niet-constante invoer.
Laten we eerst de functie testen met een heel klein bereik van 10 getallen:
DECLARE @mylow AS BIGINT = 1, @myhigh AS BIGINT = 10; DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh) ORDER BY n OPTION(MAXDOP 1);
Het plan voor deze uitvoering is weergegeven in figuur 7.
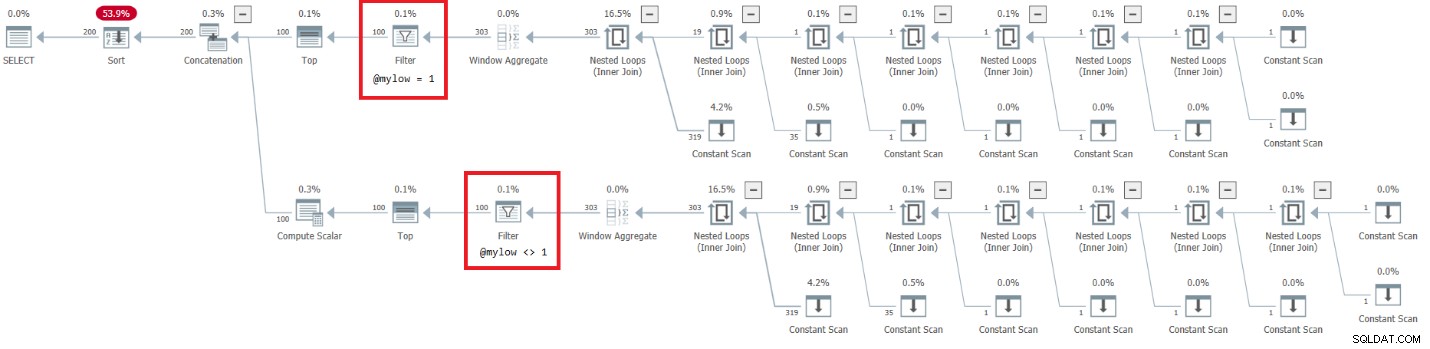 Figuur 7:Plan voor dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh)
Figuur 7:Plan voor dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh)
Er is een zeer alarmerende kant aan dit plan. Merk op dat de filteroperators hieronder verschijnen de Top-operators! Bij elke aanroep van de functie met niet-constante invoer, zal natuurlijk een van de takken onder de aaneenschakelingsoperator altijd een foutieve filtervoorwaarde hebben. Beide Top-operators vragen echter om een niet-nul aantal rijen. Dus de operator Top boven de operator met de fout-filtervoorwaarde zal om rijen vragen en zal nooit tevreden zijn, aangezien de filteroperator alle rijen die hij van zijn onderliggende node krijgt, zal weggooien. Het werk in de substructuur onder de filteroperator zal moeten worden voltooid. In ons geval betekent dit dat de substructuur het werk van het genereren van 4B-rijen zal doorlopen, die de filteroperator zal weggooien. Je vraagt je af waarom de filteroperator de moeite neemt om rijen van zijn onderliggende node op te vragen, maar het lijkt erop dat het momenteel zo werkt. Het is moeilijk om dit te zien met een statisch plan. Het is gemakkelijker om dit live te zien, bijvoorbeeld met de optie voor het uitvoeren van live-query's in SentryOne Plan Explorer, zoals weergegeven in afbeelding 8. Probeer het.
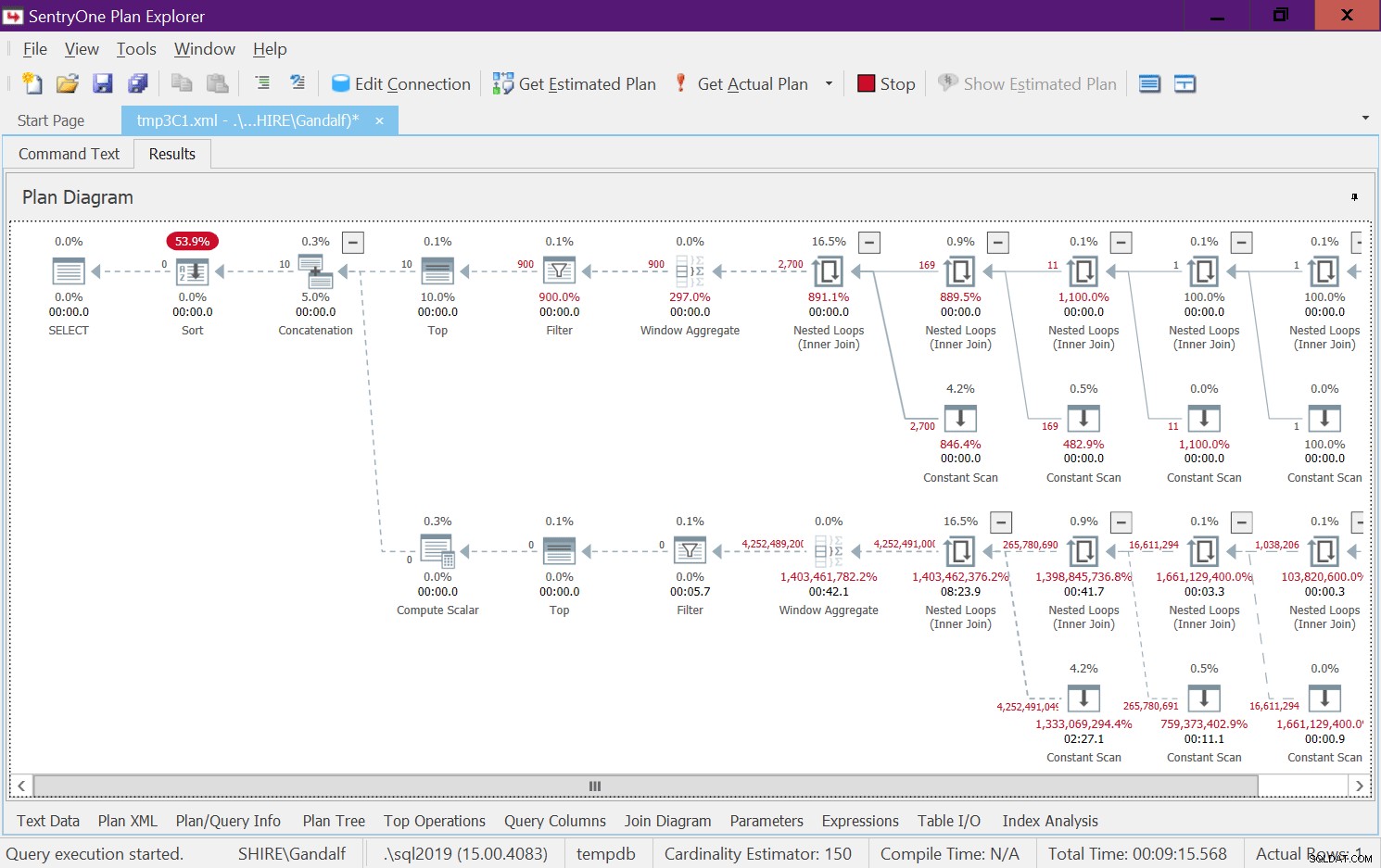 Figuur 8:Live Query-statistieken voor dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh)
Figuur 8:Live Query-statistieken voor dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh)
Het kostte deze test 9:15 minuten om op mijn computer te voltooien, en onthoud dat het verzoek was om een bereik van 10 cijfers te retourneren.
Laten we eens kijken of er een manier is om te voorkomen dat de irrelevante substructuur in zijn geheel wordt geactiveerd. Om dit te bereiken, wilt u dat de opstartfilter-operators hierboven verschijnen de Top-operators in plaats van eronder. Als u Grondbeginselen van tabeluitdrukkingen, Deel 4 – Afgeleide tabellen, optimalisatieoverwegingen, vervolgd leest, weet u dat een TOP-filter het ongedaan maken van tabeluitdrukkingen voorkomt. Het enige wat u dus hoeft te doen, is de TOP-query in een afgeleide tabel plaatsen en het filter in een buitenste query toepassen op de afgeleide tabel.
Hier is onze aangepaste functie die deze truc implementeert:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieJoeItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT *
FROM ( SELECT TOP(@high)
rownum AS n,
@high + 1 - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum ) AS D1
WHERE @low = 1
UNION ALL
SELECT *
FROM ( SELECT TOP(@high - @low + 1)
@low - 1 + rownum AS n,
@high + 1 - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum ) AS D2
WHERE @low <> 1;
GO Zoals verwacht blijven uitvoeringen met constanten zich hetzelfde gedragen en presteren als zonder de truc.
Wat betreft niet-constante invoer, nu met kleine bereiken is het erg snel. Hier is een test met een bereik van 10 cijfers:
DECLARE @mylow AS BIGINT = 1, @myhigh AS BIGINT = 10; DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh) ORDER BY n OPTION(MAXDOP 1);
Het plan voor deze uitvoering wordt getoond in figuur 9.
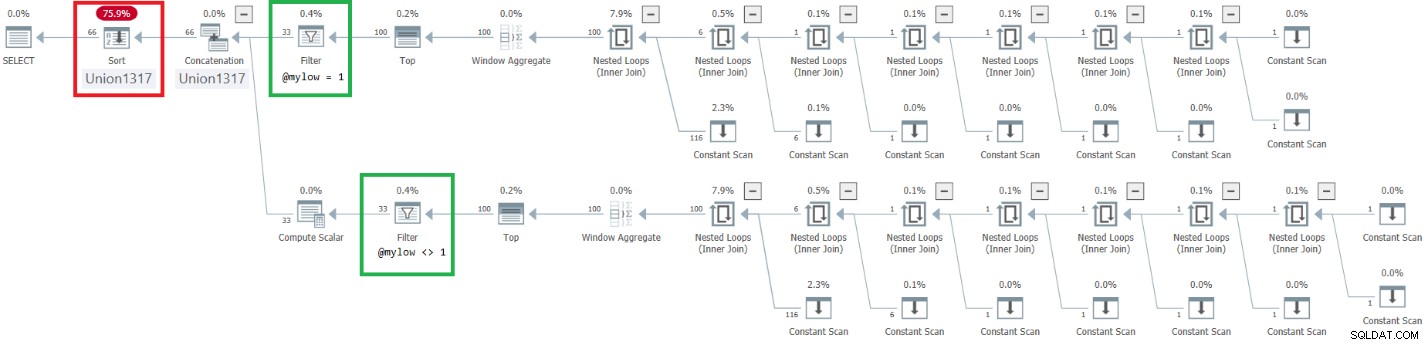 Figuur 9:Plan voor verbeterde dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh)
Figuur 9:Plan voor verbeterde dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh)
Merk op dat het gewenste effect van het plaatsen van de Filter-operators boven de Top-operators is bereikt. De volgordekolom n wordt echter behandeld als een resultaat van manipulatie en wordt daarom niet beschouwd als een volgordebehoudende kolom met betrekking tot rijnummer. Daarom is er expliciete sortering in het plan.
Test de functie met een groot bereik van 100 miljoen nummers:
DECLARE @mylow AS BIGINT = 1, @myhigh AS BIGINT = 100000000; DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh) ORDER BY n OPTION(MAXDOP 1);
Ik heb de volgende tijdstatistieken:
CPU-tijd =29907 ms, verstreken tijd =29909 ms.Wat een spelbreker; het was bijna perfect!
Prestatiesamenvatting en inzichten
Figuur 10 heeft een samenvatting van de tijdstatistieken voor de verschillende oplossingen.
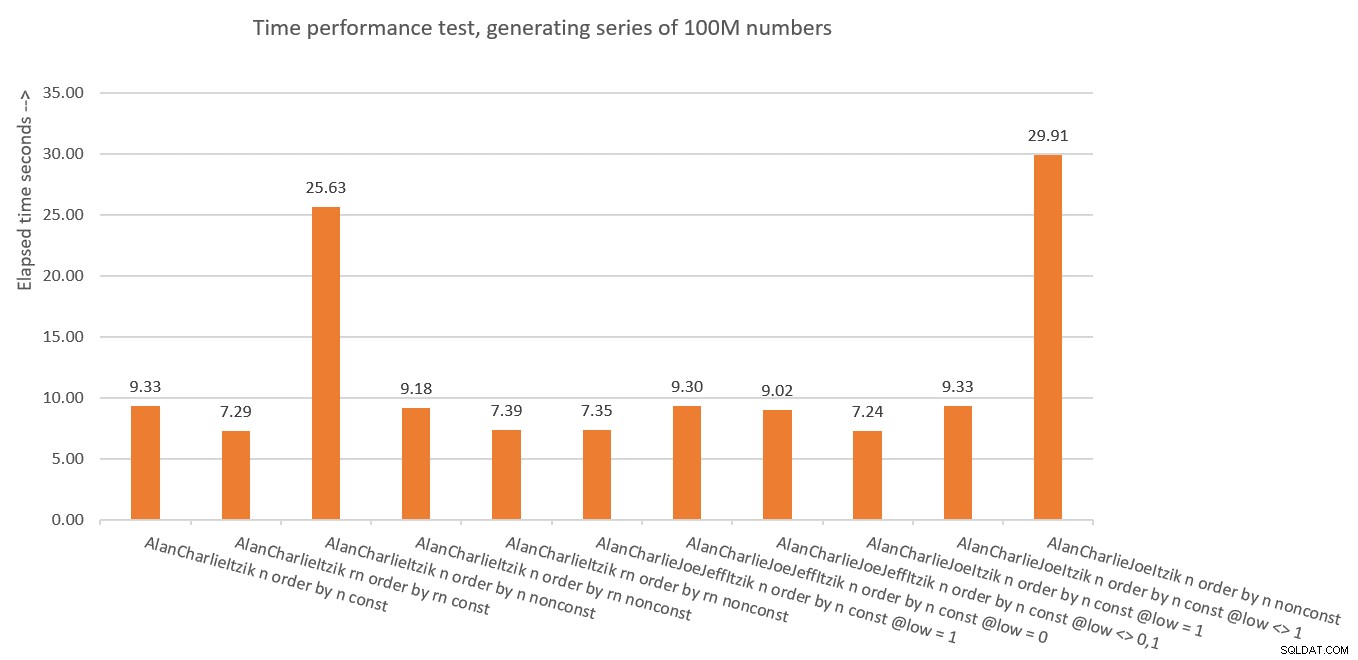 Figuur 10:Tijdprestatieoverzicht van oplossingen
Figuur 10:Tijdprestatieoverzicht van oplossingen
Dus wat hebben we van dit alles geleerd? Ik denk om het niet nog een keer te doen! Grapje. We hebben geleerd dat het veiliger is om het concept voor verticale eliminatie te gebruiken, zoals in dbo.GetNumsAlanCharlieItzikBatch, dat zowel het niet-gemanipuleerde ROW_NUMBER-resultaat (rn) als het gemanipuleerde resultaat (n) blootlegt. Zorg er wel voor dat wanneer u het bestelde resultaat moet retourneren, u altijd op rn bestelt, of u nu rn of n retourneert.
Als u er absoluut zeker van bent dat uw oplossing altijd zal worden gebruikt met constanten als invoer, kunt u het concept voor horizontale eliminatie van eenheden gebruiken. Dit zal resulteren in een meer intuïtieve oplossing voor de gebruiker, aangezien ze zullen communiceren met één kolom voor de oplopende waarden. Ik raad nog steeds aan om de truc met de afgeleide tabellen te gebruiken om unnesting te voorkomen en de Filter-operators boven de Top-operators te plaatsen als de functie ooit wordt gebruikt met niet-constante invoer, voor de zekerheid.
We zijn nog steeds niet klaar. Volgende maand ga ik verder met het verkennen van aanvullende oplossingen.