De meest voorkomende behoefte om tijd van een datetime-waarde te verwijderen, is om alle rijen te krijgen die bestellingen (of bezoeken of ongelukken) vertegenwoordigen die op een bepaalde dag hebben plaatsgevonden. Niet alle technieken die hiervoor gebruikt worden zijn echter efficiënt of zelfs veilig.
TL;DR-versie
Als u een veilige bereikquery wilt die goed presteert, gebruik dan een open-end bereik of, voor eendaagse query's op SQL Server 2008 en hoger, gebruik CONVERT(DATE) :
DECLARE @today DATETIME; -- only on <= 2005: SET @today = DATEADD(DAY, DATEDIFF(DAY, '20000101', CURRENT_TIMESTAMP), '20000101'); -- or on 2008 and above: SET @today = CONVERT(DATE, CURRENT_TIMESTAMP); -- and then use an open-ended range in the query: ... WHERE OrderDate >= @today AND OrderDate < DATEADD(DAY, 1, @today); -- you can also do this (again, in SQL Server 2008 and above): ... WHERE CONVERT(DATE, OrderDate) = @today;
Enkele kanttekeningen:
- Wees voorzichtig met de
DATEDIFFbenadering, aangezien er enkele afwijkingen in kardinaliteitsschattingen kunnen optreden (zie deze blogpost en de Stack Overflow-vraag die de aanleiding vormde voor meer informatie). - Hoewel de laatste mogelijk nog steeds een indexzoekopdracht zal gebruiken (in tegenstelling tot elke andere niet-sargeerbare uitdrukking die ik ooit ben tegengekomen), moet je voorzichtig zijn met het converteren van de kolom naar een datum voordat je gaat vergelijken. Ook deze benadering kan fundamenteel verkeerde kardinaliteitsschattingen opleveren. Zie dit antwoord van Martin Smith voor meer details.
Lees in ieder geval verder om te begrijpen waarom dit de enige twee benaderingen zijn die ik ooit aanbeveel.
Niet alle benaderingen zijn veilig
Als een onveilig voorbeeld zie ik dat deze veel wordt gebruikt:
WHERE OrderDate BETWEEN DATEDIFF(DAY, 0, GETDATE()) AND DATEADD(MILLISECOND, -3, DATEDIFF(DAY, 0, GETDATE()) + 1);
Er zijn een paar problemen met deze aanpak, maar de meest opvallende is de berekening van het "einde" van vandaag - als het onderliggende gegevenstype SMALLDATETIME is , dat eindbereik gaat naar boven afronden; als het DATETIME2 . is , zou u aan het eind van de dag in theorie gegevens kunnen missen. Als u minuten of nanoseconden of een ander gat kiest om het huidige gegevenstype te accommoderen, zal uw zoekopdracht raar gedrag gaan vertonen als het gegevenstype later ooit verandert (en laten we eerlijk zijn, als iemand het type van die kolom verandert om min of meer gedetailleerd te zijn, ze rennen niet rond om elke query te controleren die er toegang toe heeft). Op deze manier moeten coderen, afhankelijk van het type datum/tijd-gegevens in de onderliggende kolom, is gefragmenteerd en foutgevoelig. Het is veel beter om hiervoor periodes met een open einde te gebruiken:
Ik praat hier veel meer over in een paar oude blogposts:
- Wat hebben TUSSEN en de duivel gemeen?
- Slechte gewoonten om te schoppen:verkeerde behandeling van zoekopdrachten op datum/bereik
Maar ik wilde de prestaties vergelijken van enkele van de meest voorkomende benaderingen die ik zie. Ik heb altijd open bereiken gebruikt en sinds SQL Server 2008 kunnen we CONVERT(DATE) gebruiken en gebruik nog steeds een index op die kolom, wat behoorlijk krachtig is.
SELECT CONVERT(CHAR(8), CURRENT_TIMESTAMP, 112); SELECT CONVERT(CHAR(10), CURRENT_TIMESTAMP, 120); SELECT CONVERT(DATE, CURRENT_TIMESTAMP); SELECT DATEADD(DAY, DATEDIFF(DAY, '19000101', CURRENT_TIMESTAMP), '19000101'); SELECT CONVERT(DATETIME, DATEDIFF(DAY, '19000101', CURRENT_TIMESTAMP)); SELECT CONVERT(DATETIME, CONVERT(INT, CONVERT(FLOAT, CURRENT_TIMESTAMP))); SELECT CONVERT(DATETIME, FLOOR(CONVERT(FLOAT, CURRENT_TIMESTAMP)));
Een eenvoudige prestatietest
Om een zeer eenvoudige initiële prestatietest uit te voeren, deed ik het volgende voor elk van de bovenstaande uitspraken, waarbij ik 100.000 keer een variabele in de uitvoer van de berekening zette:
SELECT SYSDATETIME(); GO DECLARE @d DATETIME = [conversion method]; GO 100000 SELECT SYSDATETIME(); GO
Ik deed dit drie keer voor elke methode en ze liepen allemaal binnen het bereik van 34-38 seconden. Dus strikt genomen zijn er zeer verwaarloosbare verschillen in deze methoden bij het uitvoeren van de bewerkingen in het geheugen:
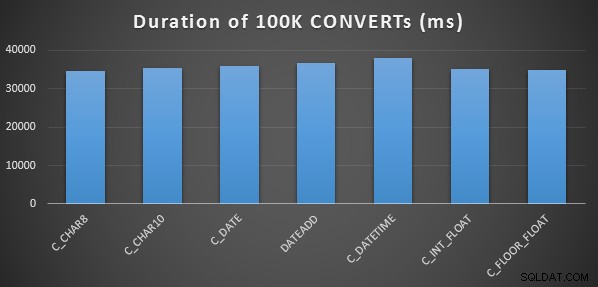
Een uitgebreidere prestatietest
Ik wilde deze methoden ook vergelijken met verschillende gegevenstypen (DATETIME , SMALLDATETIME , en DATETIME2 ), tegen zowel een geclusterde index als een heap, en met en zonder datacompressie. Dus heb ik eerst een eenvoudige database gemaakt. Door middel van experimenten heb ik vastgesteld dat de optimale grootte voor het verwerken van 120 miljoen rijen en alle logactiviteit die zou kunnen optreden (en om te voorkomen dat auto-grow-gebeurtenissen het testen verstoren) een gegevensbestand van 20 GB en een log van 3 GB was:
CREATE DATABASE [Datetime_Testing] ON PRIMARY ( NAME = N'Datetime_Testing_Data', FILENAME = N'D:\DATA\Datetime_Testing.mdf', SIZE = 20480000KB , MAXSIZE = UNLIMITED, FILEGROWTH = 102400KB ) LOG ON ( NAME = N'Datetime_Testing_Log', FILENAME = N'E:\LOGS\Datetime_Testing_log.ldf', SIZE = 3000000KB , MAXSIZE = UNLIMITED, FILEGROWTH = 20480KB );
Vervolgens heb ik 12 tabellen gemaakt:
-- clustered index with no compression: CREATE TABLE dbo.smalldatetime_nocompression_clustered(dt SMALLDATETIME); CREATE CLUSTERED INDEX x ON dbo.smalldatetime_nocompression_clustered(dt); -- heap with no compression: CREATE TABLE dbo.smalldatetime_nocompression_heap(dt SMALLDATETIME); -- clustered index with page compression: CREATE TABLE dbo.smalldatetime_compression_clustered(dt SMALLDATETIME) WITH (DATA_COMPRESSION = PAGE); CREATE CLUSTERED INDEX x ON dbo.smalldatetime_compression_clustered(dt) WITH (DATA_COMPRESSION = PAGE); -- heap with page compression: CREATE TABLE dbo.smalldatetime_compression_heap(dt SMALLDATETIME) WITH (DATA_COMPRESSION = PAGE);
[Herhaal daarna opnieuw voor DATETIME en DATETIME2.]
Vervolgens heb ik 10.000.000 rijen in elke tabel ingevoegd. Ik deed dit door een weergave te maken die elke keer dezelfde 10.000.000 datums zou genereren:
CREATE VIEW dbo.TenMillionDates AS SELECT TOP (10000000) d = DATEADD(MINUTE, ROW_NUMBER() OVER (ORDER BY s1.[object_id]), '19700101') FROM sys.all_columns AS s1 CROSS JOIN sys.all_objects AS s2 ORDER BY s1.[object_id];
Hierdoor kon ik de tabellen op deze manier vullen:
INSERT /* dt_comp_clus */ dbo.datetime_compression_clustered(dt) SELECT CONVERT(DATETIME, d) FROM dbo.TenMillionDates; CHECKPOINT; INSERT /* dt2_comp_clus */ dbo.datetime2_compression_clustered(dt) SELECT CONVERT(DATETIME2, d) FROM dbo.TenMillionDates; CHECKPOINT; INSERT /* sdt_comp_clus */ dbo.smalldatetime_compression_clustered(dt) SELECT CONVERT(SMALLDATETIME, d) FROM dbo.TenMillionDates; CHECKPOINT;
[Herhaal dan opnieuw voor de hopen en de niet-gecomprimeerde geclusterde index. Ik plaats een CHECKPOINT tussen elke insert om hergebruik van logs te garanderen (het herstelmodel is eenvoudig).]
VOEG Timings en gebruikte ruimte in
Dit zijn de tijden voor elke inzet (zoals vastgelegd met Plan Explorer):
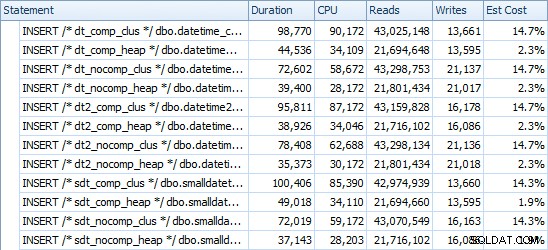
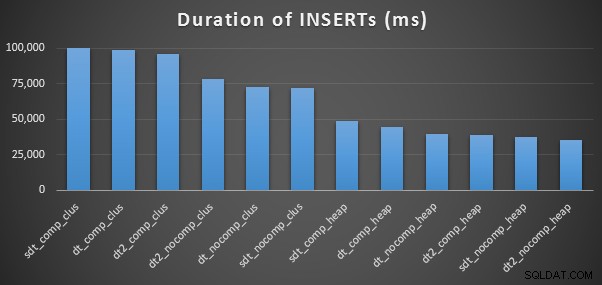
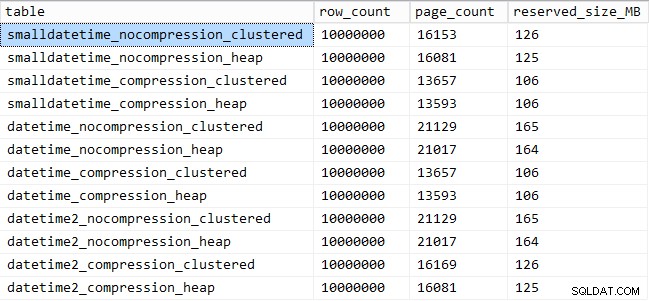
En hier is de hoeveelheid ruimte die elke tafel inneemt:
SELECT [table] = OBJECT_NAME([object_id]), row_count, page_count = reserved_page_count, reserved_size_MB = reserved_page_count * 8/1024 FROM sys.dm_db_partition_stats WHERE OBJECT_NAME([object_id]) LIKE '%datetime%';
Prestaties van querypatroon
Vervolgens ging ik twee verschillende querypatronen testen op prestaties:
- Het tellen van de rijen voor een specifieke dag, met behulp van de bovenstaande zeven benaderingen, evenals het datumbereik met een open einde
- Alle 10.000.000 rijen converteren met behulp van de bovenstaande zeven benaderingen, evenals alleen de onbewerkte gegevens retourneren (aangezien opmaak aan de clientzijde misschien beter is)
[Met uitzondering van de FLOAT methoden en de DATETIME2 kolom, aangezien deze conversie niet legaal is.]
Voor de eerste vraag zien de zoekopdrachten er als volgt uit (herhaald voor elk tabeltype):
SELECT /* C_CHAR10 - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(CHAR(10), dt, 120) = '19860301';
SELECT /* C_CHAR8 - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(CHAR(8), dt, 112) = '19860301';
SELECT /* C_FLOOR_FLOAT - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(DATETIME, FLOOR(CONVERT(FLOAT, dt))) = '19860301';
SELECT /* C_DATETIME - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(DATETIME, DATEDIFF(DAY, '19000101', dt)) = '19860301';
SELECT /* C_DATE - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(DATE, dt) = '19860301';
SELECT /* C_INT_FLOAT - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(DATETIME, CONVERT(INT, CONVERT(FLOAT, dt))) = '19860301';
SELECT /* DATEADD - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE DATEADD(DAY, DATEDIFF(DAY, '19000101', dt), '19000101') = '19860301';
SELECT /* RANGE - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE dt >= '19860301' AND dt < '19860302'; De resultaten tegen een geclusterde index zien er als volgt uit (klik om te vergroten):
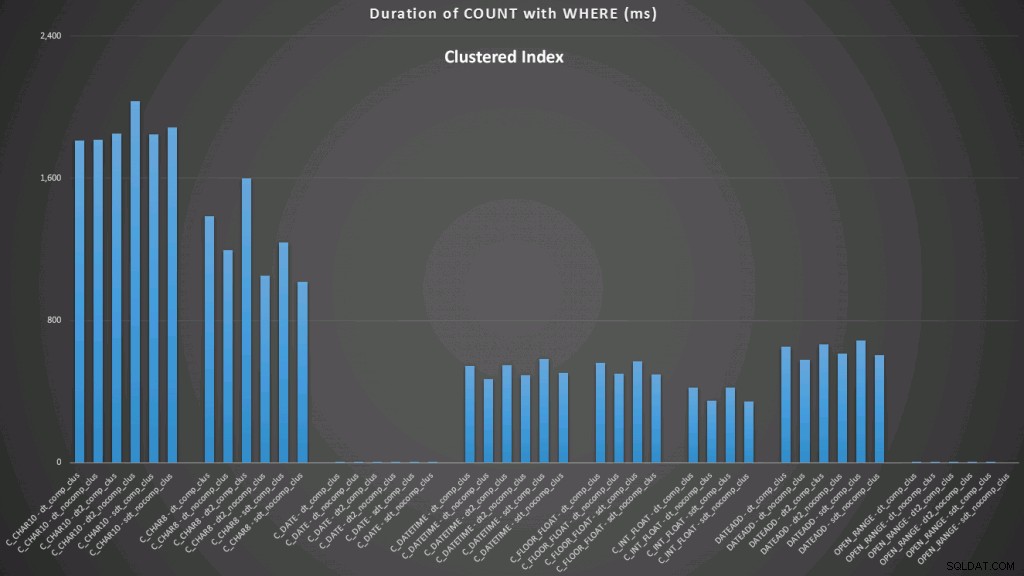
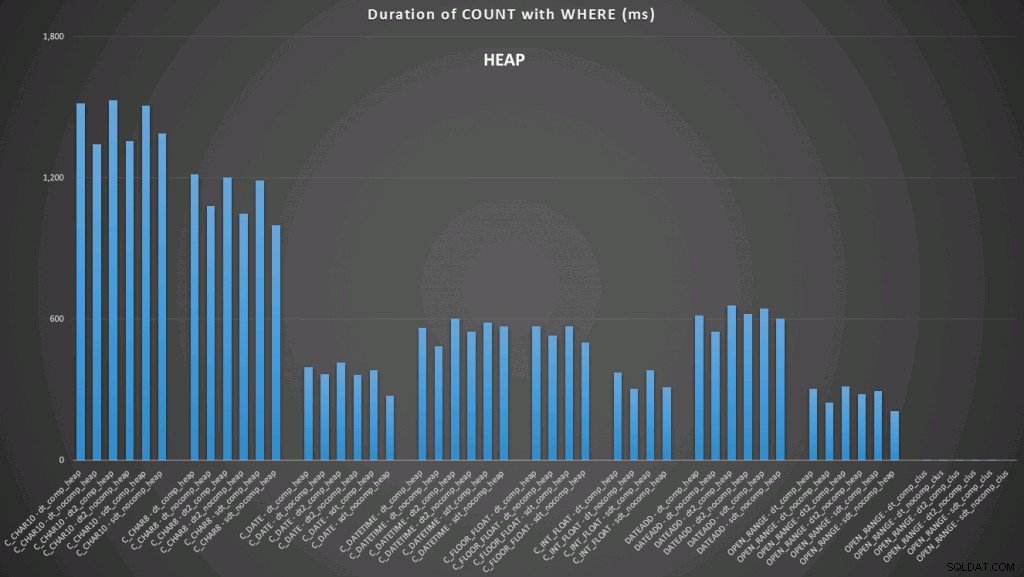
Hier zien we dat de convert-to-date en het open-ended bereik met behulp van een index de beste presteerders zijn. Tegen een hoop kost het converteren naar datum echter enige tijd, waardoor het open-ended bereik de optimale keuze is (klik om te vergroten):
En hier zijn de tweede reeks zoekopdrachten (opnieuw herhalend voor elk tabeltype):
SELECT /* C_CHAR10 - dt_comp_clus */ dt = CONVERT(CHAR(10), dt, 120)
FROM dbo.datetime_compression_clustered;
SELECT /* C_CHAR8 - dt_comp_clus */ dt = CONVERT(CHAR(8), dt, 112)
FROM dbo.datetime_compression_clustered;
SELECT /* C_FLOOR_FLOAT - dt_comp_clus */ dt = CONVERT(DATETIME, FLOOR(CONVERT(FLOAT, dt)))
FROM dbo.datetime_compression_clustered;
SELECT /* C_DATETIME - dt_comp_clus */ dt = CONVERT(DATETIME, DATEDIFF(DAY, '19000101', dt))
FROM dbo.datetime_compression_clustered;
SELECT /* C_DATE - dt_comp_clus */ dt = CONVERT(DATE, dt)
FROM dbo.datetime_compression_clustered;
SELECT /* C_INT_FLOAT - dt_comp_clus */ dt = CONVERT(DATETIME, CONVERT(INT, CONVERT(FLOAT, dt)))
FROM dbo.datetime_compression_clustered;
SELECT /* DATEADD - dt_comp_clus */ dt = DATEADD(DAY, DATEDIFF(DAY, '19000101', dt), '19000101')
FROM dbo.datetime_compression_clustered;
SELECT /* RAW - dt_comp_clus */ dt
FROM dbo.datetime_compression_clustered; Als we ons concentreren op de resultaten voor tabellen met een geclusterde index, is het duidelijk dat de conversie tot nu toe heel goed presteerde bij het selecteren van de onbewerkte gegevens (klik om te vergroten):
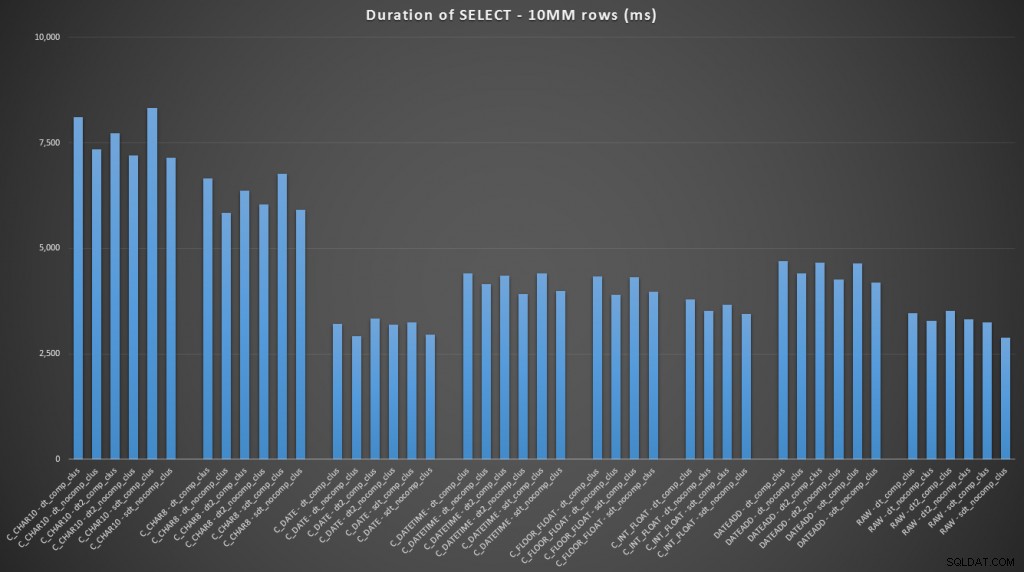
(Voor deze reeks zoekopdrachten vertoonde de heap zeer vergelijkbare resultaten - praktisch niet te onderscheiden.)
Conclusie
In het geval dat u naar de clou wilde gaan, deze resultaten laten zien dat conversies in het geheugen niet belangrijk zijn, maar als u gegevens converteert op weg naar een tabel (of als onderdeel van een zoekpredikaat), kan de methode die u kiest hebben een dramatische impact op de prestaties. Converteren naar een DATE (voor een enkele dag) of het gebruik van een periode met een open einde in ieder geval de beste prestaties zal opleveren, terwijl de meest populaire methode die er is - converteren naar een string - absoluut verschrikkelijk is.
We zien ook dat compressie een behoorlijk effect kan hebben op de opslagruimte, met een zeer kleine impact op de queryprestaties. Het effect op de invoegprestaties lijkt net zo afhankelijk te zijn van het al dan niet hebben van een geclusterde index dan van het al dan niet inschakelen van compressie. Met een geclusterde index was er echter een merkbare stijging in de duur die nodig was om 10 miljoen rijen in te voegen. Iets om in gedachten te houden en in evenwicht te brengen met de besparing op schijfruimte.
Het is duidelijk dat er veel meer testen nodig zijn, met meer substantiële en gevarieerde werklasten, die ik in een toekomstig bericht verder kan onderzoeken.