Ik ben al lang een voorstander van het kiezen van het juiste datatype. Ik heb enkele voorbeelden besproken in een eerdere "Bad Habits"-blogpost, maar dit weekend op SQL Saturday #162 (Cambridge, VK), het onderwerp van het gebruik van DATETIME kwam standaard naar voren. In een gesprek na mijn T-SQL:Bad Habits and Best Practices-presentatie, verklaarde een gebruiker dat ze gewoon DATETIME gebruiken zelfs als ze alleen tot op de minuut of dag gedetailleerdheid nodig hebben, zijn de datum/tijd-kolommen in hun hele onderneming altijd van hetzelfde gegevenstype. Ik suggereerde dat dit misschien verspillend zou zijn en dat de consistentie het misschien niet waard was, maar vandaag besloot ik om mijn theorie te bewijzen.
TL;DR-versie
Mijn tests hieronder laten zien dat er zeker scenario's zijn waarin je zou kunnen overwegen om een dunner gegevenstype te gebruiken in plaats van vast te houden aan DATETIME overal. Maar het is belangrijk om te zien waar mijn tests hiervoor de andere kant op wezen, en het is ook belangrijk om deze scenario's te testen tegen uw schema, in uw omgeving, met hardware en gegevens die zo productiegetrouw mogelijk zijn. Uw resultaten kunnen, en zullen vrijwel zeker, variëren.
De bestemmingstabellen
Laten we eens kijken naar het geval waarin granulariteit alleen belangrijk is voor de dag (we geven niet om uren, minuten, seconden). Hiervoor zouden we DATETIME kunnen kiezen (zoals de gebruiker heeft voorgesteld), of SMALLDATETIME , of DATE op SQL Server 2008+. Er zijn ook twee verschillende soorten gegevens die ik wilde overwegen:
- Gegevens die ongeveer sequentieel in realtime zouden worden ingevoegd (bijvoorbeeld gebeurtenissen die nu plaatsvinden);
- Gegevens die willekeurig zouden worden ingevoegd (bijv. geboortedata van nieuwe leden).
Ik begon met 2 tabellen zoals de volgende, en maakte er daarna nog 4 (2 voor SMALLDATETIME, 2 voor DATE):
CREER TABEL dbo.BirthDatesRandom_Datetime( ID INT IDENTITY(1,1) PRIMAIRE SLEUTEL, dt DATETIME NOT NULL); MAAK TABEL dbo.EventsSequential_Datetime (ID INT IDENTITY (1,1) PRIMAIRE SLEUTEL, dt DATETIME NOT NULL); MAAK INDEX d OP dbo.BirthDatesRandom_Datetime(dt);CREATE INDEX d OP dbo.EventsSequential_Datetime(dt); -- Herhaal dan voor DATE en SMALLDATETIME.
En mijn doel was om de prestaties van batch-inserts op die twee verschillende manieren te testen, evenals de impact op de totale opslagomvang en fragmentatie, en uiteindelijk de prestaties van bereikquery's.
Voorbeeldgegevens
Om wat voorbeeldgegevens te genereren, gebruikte ik een van mijn handige technieken om iets zinvols te genereren uit iets dat dat niet is:de catalogusweergaven. Op mijn systeem leverde dit 971 verschillende datum/tijd-waarden op (1.000.000 rijen in totaal) in ongeveer 12 seconden:
;WITH y AS ( SELECTEER TOP (1000000) d =DATEADD(SECOND, x, DATEADD(DAY, DATEDIFF(DAY, x, 0), '20120101')) FROM ( SELECT s1.[object_id] % 1000 FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2 ) AS x(x) ORDER BY NEWID()) SELECTEER DISTINCT d FROM y;
Ik plaatste deze miljoen rijen in een tabel zodat ik opeenvolgende/willekeurige invoegingen kon simuleren met verschillende toegangsmethoden voor exact dezelfde gegevens uit drie verschillende sessievensters:
MAAK TABEL dbo.Staging( ID INT IDENTITY(1,1) PRIMARY KEY, source_date DATETIME NOT NULL);;WITH Staging_Data AS ( SELECT TOP (1000000) dt =DATEADD(SECOND, x, DATEADD(DAY, DATEDIFF(DAY, x, 0), '20110101')) FROM ( SELECT s1.[object_id] % 1000 FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2 ) AS sd(x) ORDER BY NEWID())INSERT dbo.Staging(source_date) SELECT dt FROM y ORDER BY dt;
Dit proces duurde iets langer (20 seconden). Daarna heb ik een tweede tabel gemaakt om dezelfde gegevens op te slaan, maar willekeurig verdeeld (zodat ik dezelfde verdeling over alle inserts kon herhalen).
CREATE TABLE dbo.Staging_Random( ID INT IDENTITY(1,1) PRIMARY KEY, source_date DATETIME NOT NULL); INSERT dbo.Staging_Random(source_date) SELECT source_date FROM dbo.Staging ORDER DOOR NEWID();
Vragen om de tabellen te vullen
Vervolgens heb ik een reeks query's geschreven om de andere tabellen met deze gegevens te vullen, waarbij ik drie queryvensters heb gebruikt om op zijn minst een beetje gelijktijdigheid te simuleren:
WACHTTIJD '13:53';GO DECLARE @d DATETIME2 =SYSDATETIME(); INSERT dbo.{table_name}(dt) -- afhankelijk van methode / gegevenstype SELECT source_date FROM dbo.Staging[_Random] -- afhankelijk van bestemming WHERE ID % 3 =<0,1,2> -- afhankelijk van queryvenster ORDER OP ID; SELECTEER DATUMVERSCHIL(MILLISECOND, @d, SYSDATETIME()); Net als in mijn laatste bericht heb ik de database vooraf uitgebreid om te voorkomen dat elk type automatische groei van gegevensbestanden de resultaten verstoort. Ik realiseer me dat het niet helemaal realistisch is om in één keer invoegingen van miljoenen rijen uit te voeren, omdat ik niet kan voorkomen dat logactiviteiten voor zo'n grote transactie interfereren, maar het zou dit consistent moeten doen voor elke methode. Aangezien de hardware waarmee ik test compleet anders is dan de hardware die u gebruikt, zouden de absolute resultaten niet het belangrijkste moeten zijn, maar alleen de relatieve vergelijking.
(In een toekomstige test zal ik dit ook proberen met echte batches die binnenkomen uit logbestanden met relatief gemengde gegevens, en brokken van de brontabel in loops gebruiken - ik denk dat dat ook interessante experimenten zouden zijn. En natuurlijk toevoegen compressie in de mix.)
De resultaten:
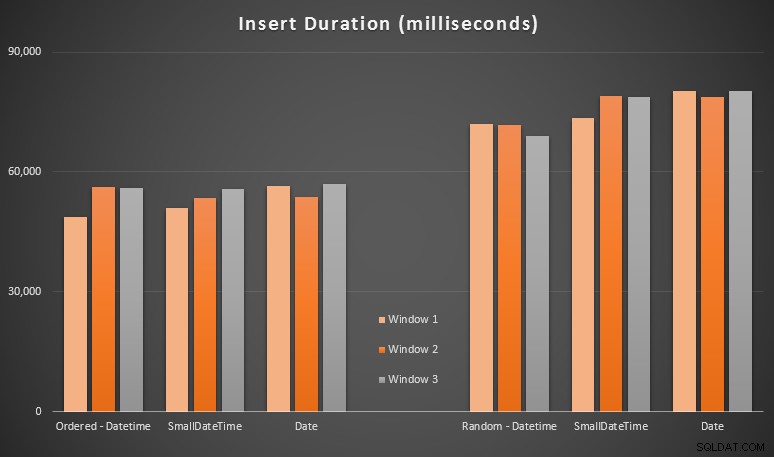
Deze resultaten waren niet zo verrassend voor mij - invoegen in willekeurige volgorde leidde tot langere runtimes dan sequentieel invoegen, iets wat we allemaal kunnen terughalen naar onze oorsprong van begrip van hoe indexen in SQL Server werken en hoe meer "slechte" paginasplitsingen kunnen gebeuren in dit scenario (ik heb in deze oefening niet specifiek gekeken naar paginasplitsingen, maar het is iets dat ik in toekomstige tests zal overwegen).
Ik merkte dat, aan de willekeurige kant, de impliciete conversies op de binnenkomende gegevens een impact zouden kunnen hebben op de timing, aangezien ze een beetje hoger leken dan de native DATETIME -> DATETIME inzetstukken. Dus besloot ik twee nieuwe tabellen te maken met brongegevens:één met DATE en een met SMALLDATETIME . Dit zou tot op zekere hoogte simuleren dat uw gegevenstype correct wordt geconverteerd voordat het wordt doorgegeven aan de insert-instructie, zodat een impliciete conversie niet vereist is tijdens de insertie. Dit zijn de nieuwe tabellen en hoe ze zijn gevuld:
CREATE TABLE dbo.Staging_Random_SmallDatetime( ID INT IDENTITY(1,1) PRIMARY KEY, source_date SMALLDATETIME NOT NULL); MAAK TABEL dbo.Staging_Random_Date (ID INT IDENTITY (1,1) PRIMAIRE SLEUTEL, source_date DATE NOT NULL); INSERT dbo.Staging_Random_SmallDatetime(source_date) SELECT CONVERT(SMALLDATETIME, source_date) VANUIT dbo.Staging_Random ORDER OP ID; INSERT dbo.Staging_Random_Date(source_date) SELECT CONVERT(DATE, source_date) FROM dbo.Staging_Random ORDER OP ID;
Dit had niet het effect waar ik op hoopte - de timing was in alle gevallen vergelijkbaar. Dus dat was een wilde gansjacht.
Gebruikte ruimte en fragmentatie
Ik heb de volgende query uitgevoerd om te bepalen hoeveel pagina's er voor elke tabel waren gereserveerd:
SELECT naam ='dbo.' + OBJECT_NAME([object_id]), pagina's =SUM(reserved_page_count)FROM sys.dm_db_partition_stats GROUP BY OBJECT_NAME([object_id])ORDER BY pagina's;
De resultaten:
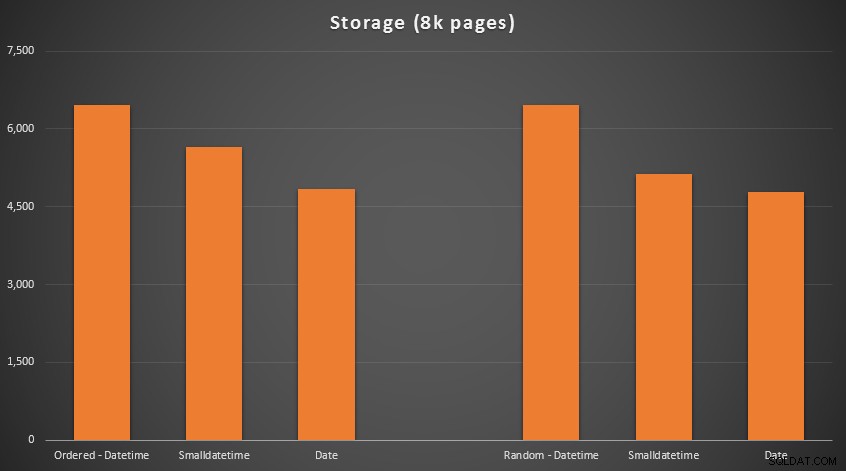
Geen raketwetenschap hier; een kleiner gegevenstype gebruikt, moet u minder pagina's gebruiken. Overschakelen van DATETIME tot DATE leverde consequent een vermindering van 25% in het aantal gebruikte pagina's op, terwijl SMALLDATETIME verminderde de vereiste met 13-20%.
Nu voor fragmentatie en paginadichtheid op de niet-geclusterde indexen (er was heel weinig verschil voor de geclusterde indexen):
SELECT '{table_name}', index_id avg_page_space_used_in_percent, avg_fragmentation_in_percent FROM sys.dm_db_index_physical_stats ( DB_ID(), OBJECT_ID('{table_name}'), NULL, NULL, 'DETAILED' =WHERE_index =index /pre>
Resultaten:
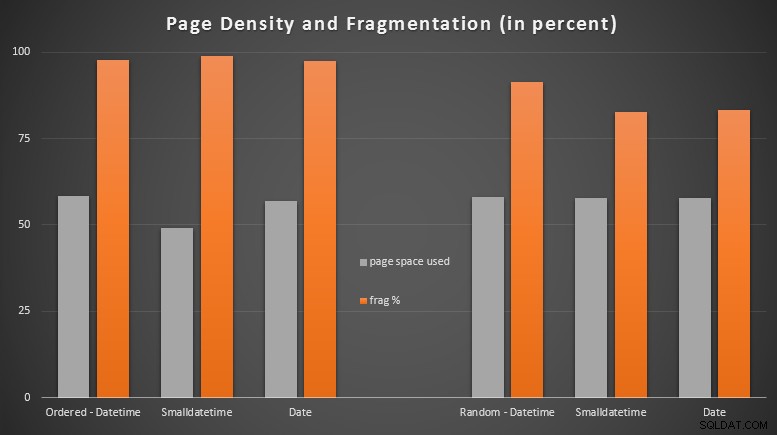
Ik was nogal verrast om te zien dat de geordende gegevens bijna volledig gefragmenteerd raakten, terwijl de willekeurig ingevoerde gegevens uiteindelijk een iets beter paginagebruik opleverden. Ik heb opgemerkt dat dit verder onderzoek rechtvaardigt buiten de reikwijdte van deze specifieke tests, maar het is misschien iets dat u wilt controleren als u niet-geclusterde indexen heeft die afhankelijk zijn van grotendeels opeenvolgende invoegingen.
[Een online reconstructie van de niet-geclusterde indexen op alle 6 tabellen verliep in 7 seconden, waardoor de paginadichtheid weer opliep tot 99,5% en de fragmentatie tot minder dan 1% werd teruggebracht. Maar ik heb dat pas uitgevoerd toen ik de onderstaande querytests uitvoerde...]
Bereikquerytest
Ten slotte wilde ik de impact zien op runtimes voor eenvoudige datumbereikquery's tegen de verschillende indexen, zowel met de inherente fragmentatie veroorzaakt door OLTP-type schrijfactiviteit, als op een schone index die opnieuw wordt opgebouwd. De vraag zelf is vrij eenvoudig:
SELECTEER TOP (200000) dt VAN dbo.{table_name} WHERE dt>='20110101' BESTEL DOOR dt;
Hier zijn de resultaten voordat de indexen opnieuw werden opgebouwd, met behulp van SQL Sentry Plan Explorer:
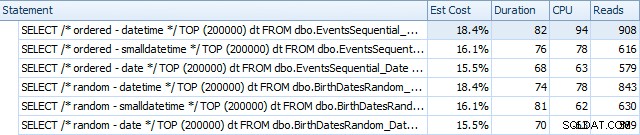
En ze verschillen enigszins na de verbouwing:
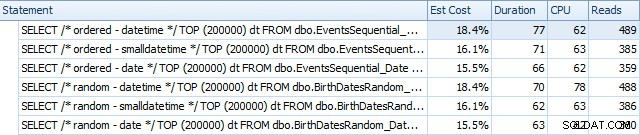
In wezen zien we iets hogere duur en uitlezingen voor de DATETIME-versies, maar heel weinig verschil in CPU. En de verschillen tussen SMALLDATETIME en DATE zijn in vergelijking verwaarloosbaar. Alle zoekopdrachten hadden simplistische zoekopdrachten zoals deze:

(Het zoeken is natuurlijk een geordende bereikscan.)
Conclusie
Hoewel deze tests weliswaar behoorlijk verzonnen zijn en baat hadden kunnen hebben bij meer permutaties, laten ze ongeveer zien wat ik verwachtte te zien:de grootste impact op deze specifieke keuze is de ruimte die wordt ingenomen door de niet-geclusterde index (waarbij het kiezen van een dunner gegevenstype zal zeker voordeel), en op de tijd die nodig is om invoegingen uit te voeren in willekeurige, in plaats van sequentiële, volgorde (waarbij DATETIME heeft slechts een marginale rand).
Ik zou graag uw ideeën horen over hoe u dit soort keuzes voor gegevenstypes grondiger en zwaarder kunt testen. Ik ben van plan om in toekomstige berichten op meer details in te gaan.