Datum- en tijdgegevens in een bucket opnemen houdt in dat gegevens voor analytische doeleinden in groepen worden geordend die vaste tijdsintervallen vertegenwoordigen. Vaak zijn de invoer tijdreeksgegevens die zijn opgeslagen in een tabel waarin de rijen metingen vertegenwoordigen die met regelmatige tijdsintervallen zijn genomen. De metingen kunnen bijvoorbeeld temperatuur- en vochtigheidsmetingen zijn die elke 5 minuten worden genomen, en u wilt de gegevens groeperen met behulp van uurlijkse buckets en compute-aggregaten zoals het gemiddelde per uur. Hoewel tijdreeksgegevens een veelgebruikte bron zijn voor op buckets gebaseerde analyses, is het concept net zo relevant voor alle gegevens die betrekking hebben op datum- en tijdattributen en bijbehorende metingen. U wilt bijvoorbeeld verkoopgegevens ordenen in buckets voor fiscale jaar en aggregaten berekenen, zoals de totale verkoopwaarde per fiscaal jaar. In dit artikel behandel ik twee methoden om datum- en tijdgegevens in een bucket te plaatsen. De ene gebruikt een functie met de naam DATE_BUCKET, die op het moment van schrijven alleen beschikbaar is in Azure SQL Edge. Een andere is het gebruik van een aangepaste berekening die de functie DATE_BUCKET emuleert, die u kunt gebruiken in elke versie, editie en smaak van SQL Server en Azure SQL Database.
In mijn voorbeelden gebruik ik de voorbeelddatabase TSQLV5. U vindt het script dat TSQLV5 maakt en vult hier en het ER-diagram hier.
DATE_BUCKET
Zoals vermeld, is de functie DATE_BUCKET momenteel alleen beschikbaar in Azure SQL Edge. SQL Server Management Studio heeft al IntelliSense-ondersteuning, zoals weergegeven in Afbeelding 1:
 Figuur 1:Intellisence-ondersteuning voor DATE_BUCKET in SSMS
Figuur 1:Intellisence-ondersteuning voor DATE_BUCKET in SSMS
De syntaxis van de functie is als volgt:
DATE_BUCKET (De invoer oorsprong vertegenwoordigt een ankerpunt op de pijl van de tijd. Het kan een van de ondersteunde datum- en tijdgegevenstypen zijn. Indien niet gespecificeerd, is de standaardwaarde 1900, 1 januari middernacht. Je kunt je dan voorstellen dat de tijdlijn is verdeeld in discrete intervallen, beginnend met het oorsprongspunt, waarbij de lengte van elk interval is gebaseerd op de invoer emmerbreedte en datumgedeelte . De eerste is de hoeveelheid en de laatste is de eenheid. Als u de tijdlijn bijvoorbeeld in eenheden van 2 maanden wilt indelen, geeft u 2 . op als de emmerbreedte invoer en maand als het datumgedeelte invoer.
De invoer tijdstempel is een willekeurig tijdstip dat moet worden geassocieerd met de bijbehorende emmer. Het gegevenstype moet overeenkomen met het gegevenstype van de invoer oorsprong . De invoer tijdstempel is de datum- en tijdwaarde die is gekoppeld aan de metingen die u vastlegt.
De uitvoer van de functie is dan het startpunt van de bevattende emmer. Het datatype van de output is dat van de input timestamp .
Als het nog niet duidelijk was, zou je meestal de functie DATE_BUCKET gebruiken als een groeperingsset-element in de GROUP BY-clausule van de query en deze natuurlijk ook retourneren in de SELECT-lijst, samen met geaggregeerde metingen.
Nog steeds een beetje in de war over de functie, de invoer en de uitvoer? Misschien zou een specifiek voorbeeld met een visuele weergave van de logica van de functie helpen. Ik zal beginnen met een voorbeeld dat invoervariabelen gebruikt en later in het artikel demonstreert u de meer typische manier waarop u het zou gebruiken als onderdeel van een query tegen een invoertabel.
Beschouw het volgende voorbeeld:
DECLARE @timestamp AS DATETIME2 = '20210510 06:30:00', @bucketwidth AS INT = 2, @origin AS DATETIME2 = '20210115 00:00:00'; SELECT DATE_BUCKET(month, @bucketwidth, @timestamp, @origin);
Een visuele weergave van de logica van de functie vindt u in figuur 2.
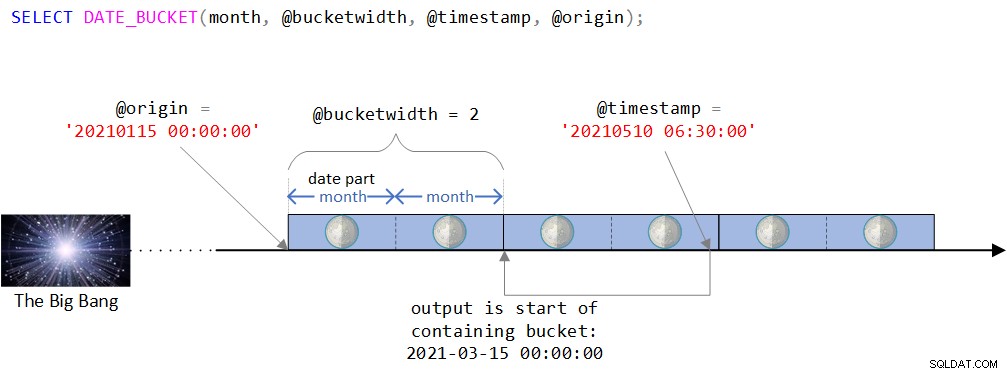 Figuur 2:Visuele weergave van de logica van de DATE_BUCKET-functie
Figuur 2:Visuele weergave van de logica van de DATE_BUCKET-functie
Zoals je kunt zien in figuur 2, is het beginpunt de DATETIME2-waarde op 15 januari 2021, middernacht. Als dit beginpunt een beetje vreemd lijkt, zou je intuïtief gelijk hebben dat je normaal gesproken een meer natuurlijke zou gebruiken, zoals het begin van een jaar of het begin van een dag. In feite zou je vaak tevreden zijn met de standaard, die, zoals je je herinnert, 1 januari 1900 om middernacht is. Ik wilde opzettelijk een minder triviaal oorsprongspunt gebruiken om bepaalde complexiteiten te kunnen bespreken die misschien niet relevant zijn bij het gebruik van een meer natuurlijk punt. Hierover binnenkort meer.
De tijdlijn wordt vervolgens verdeeld in afzonderlijke intervallen van 2 maanden, beginnend met het beginpunt. De ingevoerde tijdstempel is de DATETIME2-waarde op 10 mei 2021, 06:30 uur.
Houd er rekening mee dat de invoertijdstempel deel uitmaakt van de bucket die begint op 15 maart 2021, middernacht. Inderdaad, de functie retourneert deze waarde als een DATETIME2-getypte waarde:
--------------------------- 2021-03-15 00:00:00.0000000
DATE_BUCKET emuleren
Tenzij u Azure SQL Edge gebruikt, moet u voorlopig uw eigen aangepaste oplossing maken om te emuleren wat de DATE_BUCKET-functie doet, als u datum- en tijdgegevens in een bucket wilt plaatsen. Dit is niet al te ingewikkeld, maar ook niet te eenvoudig. Omgaan met datum- en tijdgegevens gaat vaak gepaard met lastige logica en valkuilen waar je voorzichtig mee moet zijn.
Ik zal de berekening in stappen bouwen en dezelfde invoer gebruiken die ik heb gebruikt met het DATE_BUCKET-voorbeeld dat ik eerder heb laten zien:
DECLARE @timestamp AS DATETIME2 = '20210510 06:30:00', @bucketwidth AS INT = 2, @origin AS DATETIME2 = '20210115 00:00:00';
Zorg ervoor dat je dit deel opneemt voor elk van de codevoorbeelden die ik zal laten zien als je de code echt wilt uitvoeren.
In stap 1 gebruikt u de DATEDIFF-functie om het verschil in datumgedeelte te berekenen eenheden tussen oorsprong en tijdstempel . Ik noem dit verschil diff1 . Dit gebeurt met de volgende code:
SELECT DATEDIFF(month, @origin, @timestamp) AS diff1;
Met onze voorbeeldinvoer levert deze uitdrukking 4 op.
Het lastige hier is dat je moet berekenen hoeveel hele eenheden van datumdeel bestaan tussen oorsprong en tijdstempel . Met onze voorbeeldinvoer zijn er 3 hele maanden tussen de twee en niet 4. De reden dat de DATEDIFF-functie 4 rapporteert, is dat, wanneer het het verschil berekent, het alleen kijkt naar het gevraagde deel van de invoer en hogere delen, maar niet naar lagere delen . Dus als u om het verschil in maanden vraagt, geeft de functie alleen om het jaar- en maandgedeelte van de invoer en niet om de gedeelten onder de maand (dag, uur, minuut, seconde, enz.). Er zijn inderdaad 4 maanden tussen januari 2021 en mei 2021, maar slechts 3 hele maanden tussen de volledige invoer.
Het doel van stap 2 is dan om te berekenen hoeveel hele eenheden van datumdeel bestaan tussen oorsprong en tijdstempel . Ik noem dit verschil diff2 . Om dit te bereiken, kunt u diff1 . toevoegen eenheden van datumdeel naar oorsprong . Als het resultaat groter is dan tijdstempel , trek je 1 af van diff1 om diff2 te berekenen , trek anders 0 af en gebruik daarom diff1 als diff2 . Dit kan worden gedaan met behulp van een CASE-expressie, zoals:
SELECT
DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END AS diff2; Deze uitdrukking retourneert 3, wat het aantal hele maanden is tussen de twee invoer.
Bedenk dat ik eerder vermeldde dat ik in mijn voorbeeld opzettelijk een oorsprongspunt gebruikte dat niet natuurlijk is, zoals een rond begin van een punt, zodat ik bepaalde complexiteiten kan bespreken die dan relevant kunnen zijn. Als u bijvoorbeeld maand . gebruikt als het datumgedeelte, en het exacte begin van een maand (1 van een maand om middernacht) als de oorsprong, kunt u stap 2 veilig overslaan en diff1 gebruiken als diff2 . Dat komt omdat oorsprong + diff1 kan nooit> tijdstempel . zijn in zo'n geval. Het is echter mijn doel om een logisch equivalent alternatief te bieden voor de DATE_BUCKET-functie dat correct zou werken voor elk oorsprongspunt, algemeen of niet. Dus ik zal de logica voor stap 2 in mijn voorbeelden opnemen, maar onthoud dat wanneer je gevallen identificeert waarin deze stap niet relevant is, je veilig het deel kunt verwijderen waar je de uitvoer van de CASE-expressie aftrekt.
In stap 3 identificeert u hoeveel eenheden van datumdeel er zijn in hele buckets die bestaan tussen oorsprong en tijdstempel . Ik noem deze waarde diff3 . Dit kan met de volgende formule:
diff3 = diff2 / <bucket width> * <bucket width>
De truc hier is dat bij gebruik van de delingsoperator / in T-SQL met gehele operanden, u gehele deling krijgt. 3/2 in T-SQL is bijvoorbeeld 1 en niet 1,5. De uitdrukking diff2 /
SELECT
( DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth AS diff3; Deze expressie retourneert 2, wat het aantal maanden is in de hele buckets van 2 maanden die tussen de twee invoer bestaan.
In stap 4, de laatste stap, voegt u diff3 . toe eenheden van datumdeel naar oorsprong om het begin van de bevattende emmer te berekenen. Hier is de code om dit te bereiken:
SELECT DATEADD(
month,
( DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin); Deze code genereert de volgende uitvoer:
--------------------------- 2021-03-15 00:00:00.0000000
Zoals u zich herinnert, is dit dezelfde uitvoer die wordt geproduceerd door de DATE_BUCKET-functie voor dezelfde ingangen.
Ik stel voor dat je deze uitdrukking probeert met verschillende invoer en delen. Ik zal hier een paar voorbeelden laten zien, maar probeer gerust je eigen voorbeelden.
Hier is een voorbeeld waar oorsprong loopt net iets voor op tijdstempel in de maand:
DECLARE
@timestamp AS DATETIME2 = '20210510 06:30:00',
@bucketwidth AS INT = 2,
@origin AS DATETIME2 = '20210110 06:30:01';
-- SELECT DATE_BUCKET(week, @bucketwidth, @timestamp, @origin);
SELECT DATEADD(
month,
( DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin); Deze code genereert de volgende uitvoer:
--------------------------- 2021-03-10 06:30:01.0000000
Merk op dat de start van de bevattende emmer in maart is.
Hier is een voorbeeld waar oorsprong is op hetzelfde punt binnen de maand als timestamp :
DECLARE
@timestamp AS DATETIME2 = '20210510 06:30:00',
@bucketwidth AS INT = 2,
@origin AS DATETIME2 = '20210110 06:30:00';
-- SELECT DATE_BUCKET(week, @bucketwidth, @timestamp, @origin);
SELECT DATEADD(
month,
( DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin); Deze code genereert de volgende uitvoer:
--------------------------- 2021-05-10 06:30:00.0000000
Merk op dat de start van de container deze keer in mei is.
Hier is een voorbeeld met buckets van 4 weken:
DECLARE
@timestamp AS DATETIME2 = '20210303 21:22:11',
@bucketwidth AS INT = 4,
@origin AS DATETIME2 = '20210115';
-- SELECT DATE_BUCKET(week, @bucketwidth, @timestamp, @origin);
SELECT DATEADD(
week,
( DATEDIFF(week, @origin, @timestamp)
- CASE
WHEN DATEADD(
week,
DATEDIFF(week, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin); Merk op dat de code de week . gebruikt deel deze keer.
Deze code genereert de volgende uitvoer:
--------------------------- 2021-02-12 00:00:00.0000000
Hier is een voorbeeld met buckets van 15 minuten:
DECLARE
@timestamp AS DATETIME2 = '20210203 21:22:11',
@bucketwidth AS INT = 15,
@origin AS DATETIME2 = '19000101';
-- SELECT DATE_BUCKET(minute, @bucketwidth, @timestamp);
SELECT DATEADD(
minute,
( DATEDIFF(minute, @origin, @timestamp)
- CASE
WHEN DATEADD(
minute,
DATEDIFF(minute, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin); Deze code genereert de volgende uitvoer:
--------------------------- 2021-02-03 21:15:00.0000000
Merk op dat het deel minuut is . In dit voorbeeld wilt u emmers van 15 minuten gebruiken die beginnen bij de bodem van het uur, dus een oorsprongspunt dat de bodem van elk uur is, zou werken. In feite zou een oorsprongspunt met een minuuteenheid van 00, 15, 30 of 45 met nullen in lagere delen, met elke datum en uur werken. Dus de standaard die de functie DATE_BUCKET gebruikt voor de invoer oorsprong zou werken. Wanneer u de aangepaste expressie gebruikt, moet u natuurlijk expliciet zijn over het oorsprongspunt. Dus, om mee te voelen met de DATE_BUCKET-functie, zou je de basisdatum om middernacht kunnen gebruiken, zoals ik in het bovenstaande voorbeeld doe.
Kun je trouwens zien waarom dit een goed voorbeeld zou zijn waarbij het volkomen veilig is om stap 2 in de oplossing over te slaan? Als je er inderdaad voor hebt gekozen om stap 2 over te slaan, krijg je de volgende code:
DECLARE
@timestamp AS DATETIME2 = '20210203 21:22:11',
@bucketwidth AS INT = 15,
@origin AS DATETIME2 = '19000101';
-- SELECT DATE_BUCKET(minute, @bucketwidth, @timestamp);
SELECT DATEADD(
minute,
( DATEDIFF( minute, @origin, @timestamp ) ) / @bucketwidth * @bucketwidth,
@origin
); Het is duidelijk dat de code aanzienlijk eenvoudiger wordt wanneer stap 2 niet nodig is.
Groeperen en aggregeren van gegevens op datum- en tijdbuckets
Er zijn gevallen waarin u datum- en tijdgegevens moet opsplitsen waarvoor geen geavanceerde functies of logge uitdrukkingen nodig zijn. Stel dat u de weergave Sales.OrderValues in de TSQLV5-database wilt opvragen, de gegevens jaarlijks wilt groeperen en het totale aantal bestellingen en de waarden per jaar wilt berekenen. Het is duidelijk dat het voldoende is om de functie YEAR(orderdate) als het groeperingsset-element te gebruiken, zoals:
USE TSQLV5; SELECT YEAR(orderdate) AS orderyear, COUNT(*) AS numorders, SUM(val) AS totalvalue FROM Sales.OrderValues GROUP BY YEAR(orderdate) ORDER BY orderyear;
Deze code genereert de volgende uitvoer:
orderyear numorders totalvalue ----------- ----------- ----------- 2017 152 208083.99 2018 408 617085.30 2019 270 440623.93
Maar wat als u de gegevens in het fiscale jaar van uw organisatie wilt opnemen? Sommige organisaties gebruiken een fiscaal jaar voor boekhoud-, budget- en financiële rapportagedoeleinden, dat niet is afgestemd op het kalenderjaar. Stel bijvoorbeeld dat het fiscale jaar van uw organisatie werkt volgens een fiscale kalender van oktober tot september, en wordt aangegeven door het kalenderjaar waarin het fiscale jaar eindigt. Dus een evenement dat plaatsvond op 3 oktober 2018 behoort tot het fiscale jaar dat begon op 1 oktober 2018, eindigde op 30 september 2019 en wordt aangeduid met het jaar 2019.
Dit is vrij eenvoudig te bereiken met de DATE_BUCKET-functie, zoals:
DECLARE @bucketwidth AS INT = 1, @origin AS DATETIME2 = '19001001'; -- this is Oct 1 of some year SELECT YEAR(startofbucket) + 1 AS fiscalyear, COUNT(*) AS numorders, SUM(val) AS totalvalue FROM Sales.OrderValues CROSS APPLY ( VALUES( DATE_BUCKET( year, @bucketwidth, orderdate, @origin ) ) ) AS A(startofbucket) GROUP BY startofbucket ORDER BY startofbucket;
En hier is de code die het aangepaste logische equivalent van de DATE_BUCKET-functie gebruikt:
DECLARE
@bucketwidth AS INT = 1,
@origin AS DATETIME2 = '19001001'; -- this is Oct 1 of some year
SELECT
YEAR(startofbucket) + 1 AS fiscalyear,
COUNT(*) AS numorders,
SUM(val) AS totalvalue
FROM Sales.OrderValues
CROSS APPLY ( VALUES(
DATEADD(
year,
( DATEDIFF(year, @origin, orderdate)
- CASE
WHEN DATEADD(
year,
DATEDIFF(year, @origin, orderdate),
@origin) > orderdate
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin) ) ) AS A(startofbucket)
GROUP BY startofbucket
ORDER BY startofbucket; Deze code genereert de volgende uitvoer:
fiscalyear numorders totalvalue ----------- ----------- ----------- 2017 70 79728.58 2018 370 563759.24 2019 390 622305.40
Ik heb hier variabelen gebruikt voor de emmerbreedte en het oorsprongspunt om de code meer algemeen te maken, maar je kunt die vervangen door constanten als je altijd dezelfde gebruikt, en de berekening vervolgens waar nodig vereenvoudigen.
Als een kleine variatie op het bovenstaande, stel dat uw fiscale jaar loopt van 15 juli van het ene kalenderjaar tot 14 juli van het volgende kalenderjaar, en wordt aangegeven door het kalenderjaar waartoe het begin van het fiscale jaar behoort. Dus een evenement dat plaatsvond op 18 juli 2018 behoort tot het fiscale jaar 2018. Een evenement dat plaatsvond op 14 juli 2018 behoort tot het fiscale jaar 2017. Met de DATE_BUCKET-functie zou u dit als volgt bereiken:
DECLARE @bucketwidth AS INT = 1, @origin AS DATETIME2 = '19000715'; -- July 15 marks start of fiscal year SELECT YEAR(startofbucket) AS fiscalyear, -- no need to add 1 here COUNT(*) AS numorders, SUM(val) AS totalvalue FROM Sales.OrderValues CROSS APPLY ( VALUES( DATE_BUCKET( year, @bucketwidth, orderdate, @origin ) ) ) AS A(startofbucket) GROUP BY startofbucket ORDER BY startofbucket;
Je kunt de wijzigingen ten opzichte van het vorige voorbeeld zien in de opmerkingen.
En hier is de code die het aangepaste logische equivalent van de DATE_BUCKET-functie gebruikt:
DECLARE
@bucketwidth AS INT = 1,
@origin AS DATETIME2 = '19000715';
SELECT
YEAR(startofbucket) AS fiscalyear,
COUNT(*) AS numorders,
SUM(val) AS totalvalue
FROM Sales.OrderValues
CROSS APPLY ( VALUES(
DATEADD(
year,
( DATEDIFF(year, @origin, orderdate)
- CASE
WHEN DATEADD(
year,
DATEDIFF(year, @origin, orderdate),
@origin) > orderdate
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin) ) ) AS A(startofbucket)
GROUP BY startofbucket
ORDER BY startofbucket; Deze code genereert de volgende uitvoer:
fiscalyear numorders totalvalue ----------- ----------- ----------- 2016 8 12599.88 2017 343 495118.14 2018 479 758075.20
Uiteraard zijn er alternatieve methoden die u in specifieke gevallen kunt gebruiken. Neem het voorbeeld voor het laatste, waar het fiscale jaar loopt van oktober tot september en wordt aangeduid met het kalenderjaar waarin het fiscale jaar eindigt. In zo'n geval zou je de volgende, veel eenvoudigere uitdrukking kunnen gebruiken:
YEAR(orderdate) + CASE WHEN MONTH(orderdate) BETWEEN 10 AND 12 THEN 1 ELSE 0 END
En dan ziet je vraag er als volgt uit:
SELECT
fiscalyear,
COUNT(*) AS numorders,
SUM(val) AS totalvalue
FROM Sales.OrderValues
CROSS APPLY ( VALUES(
YEAR(orderdate)
+ CASE
WHEN MONTH(orderdate) BETWEEN 10 AND 12 THEN 1
ELSE 0
END ) ) AS A(fiscalyear)
GROUP BY fiscalyear
ORDER BY fiscalyear; Als u echter een algemene oplossing wilt die in veel meer gevallen zou werken en die u zou kunnen parametriseren, zou u natuurlijk de meer algemene vorm willen gebruiken. Als je toegang hebt tot de DATE_BUCKET-functie, is dat geweldig. Als u dat niet doet, kunt u het aangepaste logische equivalent gebruiken.
Conclusie
De DATE_BUCKET-functie is een behoorlijk handige functie waarmee u datum- en tijdgegevens kunt bucketiseren. Het is handig voor het verwerken van tijdreeksgegevens, maar ook voor het in een bucket plaatsen van gegevens die datum- en tijdattributen bevatten. In dit artikel heb ik uitgelegd hoe de DATE_BUCKET-functie werkt en heb ik een aangepast logisch equivalent gegeven voor het geval het platform dat je gebruikt dit niet ondersteunt.