In dit artikel bespreken we verschillende problemen waarmee u te maken kunt krijgen bij het maken, configureren of onderhouden van een Always on Availability Group-site.
Voordat u dit artikel doorneemt, is het raadzaam om het vorige artikel, Always on Availability Group in SQL Server instellen en configureren, te lezen om bekend te zijn met het Always on Availability Group-concept en de New Availability Group-wizards die in dit artikel worden weergegeven.
Always-on-beschikbaarheidsgroepfunctie niet ingeschakeld
Stel dat u bij het maken van een nieuwe Always-on-beschikbaarheidsgroep, vanaf het Always On High Availability-knooppunt, onder de Object Explorer van de SQL Server Management Studio, de onderstaande foutmelding kreeg:
De functie Always On Availability Groups moet zijn ingeschakeld voor serverinstantie 'SQL1' voordat u een beschikbaarheidsgroep op deze instantie kunt maken. Om deze functie in te schakelen, opent u de SQL Server Configuration Manager, selecteert u SQL Server Services, klikt u met de rechtermuisknop op de naam van de SQL Server-service, selecteert u Eigenschappen en gebruikt u het tabblad AlwaysOn-beschikbaarheidsgroepen van het dialoogvenster Servereigenschappen. Als u AlwaysOn-beschikbaarheidsgroepen inschakelt, moet het serverexemplaar mogelijk worden gehost door een Windows Server Failover Cluster (WSFC)-knooppunt. (Microsoft.SqlServer.Management.HadrTasks)

Uit het foutbericht blijkt duidelijk dat de functie AlwaysOn-beschikbaarheidsgroepen moet worden ingeschakeld op elke SQL Server-instantie die deelneemt aan de Always on Availability Group-site, voordat die site wordt gemaakt.
U kunt de functie Always on Availability Group eenvoudig inschakelen door de SQL Server Configuration Manager-console te openen, door het tabblad SQL Server Services te bladeren en vervolgens met de rechtermuisknop op de SQL Server Database Engine-service te klikken en de optie Eigenschappen te kiezen.
Ga vanuit het geopende venster Eigenschappen van SQL Server naar het tabblad Always on High Availability en vink het selectievakje aan naast de Always on Availability Group inschakelen , rekening houdend met het feit dat deze wijziging het herstarten van de SQL Server-service vereist om van kracht te worden, zoals hieronder weergegeven:

Database Vereisten Validatieprobleem
In de eerdere stappen van de wizard Nieuwe beschikbaarheidsgroep wordt u gevraagd om de database(s) op te geven die zullen deelnemen aan de Always-on-beschikbaarheidsgroep. Voordat de database wordt toegevoegd, moet de database de validatiecontrole van de vereisten doorstaan. Anders kan de database niet worden geselecteerd uit de databaselijsten, zoals weergegeven in de onderstaande foutmelding:
Om te worden toegevoegd aan een beschikbaarheidsgroep, moet deze database zijn ingesteld op het volledige herstelmodel. Stel de database-eigenschap Recovery Model in op Full en maak een volledige of differentiële databaseback-up op de database. U moet dan logback-ups plannen in de database.

De boodschap is duidelijk. Waarbij de database moet worden geconfigureerd met een volledig herstelmodel en een volledige of differentiële back-up moet worden uitgevoerd op die database.
De wizard waarschuwt u ook om een back-up van het transactielogboek voor die database te plannen nadat het herstelmodel is gewijzigd in Volledig, om het transactielogboekbestand automatisch af te kappen en te voorkomen dat het transactielogboekbestand zonder vrije ruimte wordt uitgevoerd.
Om dat probleem op te lossen, wijzigt u het databaseherstelmodel van Eenvoudig in Volledig, vanaf het tabblad Opties van het database-eigenschappenvenster en maakt u vervolgens een volledige back-up van die database, zoals hieronder weergegeven:

Als u het venster Databases selecteren vernieuwt, wordt de databasestatus gewijzigd in Voldoet aan de vereisten, zoals hieronder weergegeven:

Kwestie van toestemming voor gedeelde netwerklocatie
Tijdens het configureren van een Always-on-beschikbaarheidsgroep-site is de validatiestap van de wizard Nieuwe beschikbaarheidsgroep mislukt met het onderstaande foutbericht:
De primaire server 'SQL1' kan niet schrijven naar '\\SQL1\AlwaysON\BackupLocDb_dbb55cb4-af89-4ed3-b189-1fcaad42358c.bak'. (Microsoft.SqlServer.Management.HadrModel)
Back-up mislukt voor server 'SQL1'. (Microsoft.SqlServer.SmoExtended)
Kan back-upapparaat '\\SQL1\AlwaysON\BackupLocDb_dbb55cb4-af89-4ed3-b189-1fcaad42358c.bak' niet openen. Besturingssysteemfout 5 (Toegang is geweigerd.).
BACKUP DATABASE wordt abnormaal beëindigd. (.Net SqlClient-gegevensprovider)
In de initiële synchronisatiemethode Volledige database en logboekback-up is een gedeelde map vereist om de volledige back-up en transactielogboekback-upbestanden tijdelijk te bewaren om deze te herstellen naar alle secundaire replica's. Als de primaire replica de back-upbestanden er niet naar kan schrijven, of de secundaire replica's de back-upbestanden niet kunnen lezen, mislukt het validatieproces van de nieuwe beschikbaarheidsgroep zoals hieronder:

Om dat probleem op te lossen, moeten we het SQL Server-serviceaccount van de primaire en secundaire replica's lees- en schrijfmachtigingen geven voor de gedeelde map die in het foutbericht wordt weergegeven, en vervolgens het validatieproces opnieuw uitvoeren om ervoor te zorgen dat alle controles zijn geslaagd , zoals hieronder weergegeven:

Probleem met Windows-failovercluster
Stel dat u de status van een bestaande Always on Availability Group-site controleert en zie dat:
- De primaire rol wordt verplaatst van SQL1-instantie naar SQL2.
- In SQL2 hebben de databases de status Gesynchroniseerd.
- In SQL1 zijn de databases niet gesynchroniseerd.
- SQL1 bevindt zich in de status Oplossen.
Zoals je duidelijk kunt zien in de SSMS Object Explorer hieronder:

Als we de SQL Server-foutlogboeken in het problematische knooppunt controleren, kunnen we zien dat de replica van de beschikbaarheidsgroep offline wordt en dat de beschikbaarheidsgroep niet meer werkt vanwege een probleem in het Windows Server-failovercluster, zoals weergegeven in de onderstaande fouten:
- Always On-beschikbaarheidsgroepen:Lokale Windows Server Failover Clustering-knooppunt is niet langer online . Dit is alleen een informatief bericht. Er is geen gebruikersactie vereist.
- Altijd aan:de beschikbaarheidsreplicamanager gaat offline omdat het lokale Windows Server Failover Clustering (WSFC)-knooppunt het quorum heeft verloren. Dit is alleen een informatief bericht. Er is geen gebruikersactie vereist.
- Always On:de lokale replica van de beschikbaarheidsgroep 'DemoGroup' stopt. Dit is alleen een informatief bericht. Er is geen gebruikersactie vereist.

Hetzelfde kan worden gedetecteerd vanuit de Windows Server Event Viewer, die geleidelijk laat zien hoe de replica zijn status verandert in de status Resolving, zoals hieronder:
- Always On:de lokale replica van de beschikbaarheidsgroep 'DemoGroup' bereidt zich voor op de overgang naar de oplossende rol . Dit is alleen een informatief bericht. Er is geen gebruikersactie vereist.
- De beschikbaarheidsgroep 'DemoGroup' wordt gevraagd de huurverlenging stop te zetten omdat de beschikbaarheidsgroep offline gaat . Dit is alleen een informatief bericht. Er is geen gebruikersactie vereist.
- De status van de lokale beschikbaarheidsreplica in de beschikbaarheidsgroep 'DemoGroup' is gewijzigd van 'PRIMARY_NORMAL' in 'RESOLVING_NORMAL'. De status is gewijzigd omdat de beschikbaarheidsgroep offline gaat. De replica gaat offline omdat de bijbehorende beschikbaarheidsgroep is verwijderd, of de gebruiker de bijbehorende beschikbaarheidsgroep offline heeft gehaald in de beheerconsole van Windows Server Failover Clustering (WSFC), of de beschikbaarheidsgroep een failover uitvoert naar een ander SQL Server-exemplaar. Zie het foutenlogboek van SQL Server of het clusterlogboek voor meer informatie. Als dit een beschikbaarheidsgroep voor Windows Server Failover Clustering (WSFC) is, kunt u ook de WSFC-beheerconsole zien.

Om de status van de Windows Cluster-site te controleren, gebruiken we Failover Cluster Manager om te zien welk deel van de Windows Cluster niet werkt.
Maar de Failover Cluster Manager laat zien dat het hele cluster niet beschikbaar is, zoals hieronder weergegeven:

Het eerste dat hier vanaf de kant van Windows Failover Cluster moet worden gevalideerd, is de Cluster-service, die kan worden gecontroleerd vanuit de Windows Services-console, zoals hieronder:

Het is duidelijk uit de Services-console dat de Cluster-service niet actief is. Om dat probleem op te lossen, start u de service vanaf die console en vernieuwt u vervolgens de Failover Cluster Manager-console om ervoor te zorgen dat de Windows Cluster-site actief is, zoals hieronder wordt weergegeven:

Als u de Always on Availability Group opnieuw controleert, ziet u dat de databases weer gesynchroniseerd zijn en dat de Always on Availability Group-site weer in de gezondheidstoestand verkeert, zoals hieronder wordt weergegeven:

Transactielogbestand is vol aan de primaire zijde
Stel dat u de onderstaande foutmelding krijgt wanneer u een nieuwe query probeert uit te voeren op een van de Always on Availability Group-databases:

Als u controleert wat het transactielogboekbestand blokkeert en voorkomt dat het wordt afgekapt, zult u zien dat het transactielogboekbestand van deze database in afwachting is van een logback-upbewerking om te worden afgekapt, zoals hieronder weergegeven:

Een back-up van het transactielogboek maken voor die database, voor het geval u vergeet een back-uptaak van het transactielogboek te plannen, als volgt:

En controleer opnieuw wat het transactielogboek van die database blokkeert, het laat in mijn scenario zien dat het wacht op Availability_Replica. Dit betekent dat de logboeken wachten om naar de secundaire replica te worden geschreven, maar deze transactielogboeken niet naar de secundaire replica's kunnen verzenden vanwege een probleem op de Always on Availability Group-site, zoals hieronder:

De beste locatie om de Always on Availability Group-site te controleren en problemen op te lossen is het Always on Dashboard, dat kan worden geopend door met de rechtermuisknop op de naam van de Availability Group te klikken en de optie Dashboard weergeven te kiezen.
Op het dashboard kunt u zien dat de secundaire replica SQL2 niet is gesynchroniseerd met de primaire replica vanwege een verbindingsprobleem, zoals hieronder wordt weergegeven:

De secundaire replica controleren en ervoor zorgen dat de SQL Server-service aan de secundaire kant actief is, als volgt:

Vernieuw vervolgens het dashboard van de Beschikbaarheidsgroep opnieuw, u zult zien dat de site Always on Availability Group weer in orde is. Checking if the transaction logs file is blocked by any operation, we will see that it is pending OLDEST_PAGE, indicating that the oldest page of the database is older than the checkpoint LSN. This issue can be fixed easily by taking another transaction log backup and the transaction log file will be blocked by nothing, as shown clearly below:

Always on Availability Group Failover Misconfiguration
Assume that the Primary replica becomes offline due to an unplanned issue. As expected, the system will not be affected as an automatic failover operation will be performed and the secondary replica will act as the new Primary replica.
But in our case, this happy scenario is not valid, where the secondary replica changed to Resolving state and the system is down!

Checking the secondary replica’s error log and see why it is not acting as the new Primary as expected, you will see that it is failing due to a role synchronization issue, as shown below:
The availability group database "AdventureWorks2017" is changing roles from "SECONDARY" to "RESOLVING" because the mirroring session or availability group failed over due to role synchronization. This is an informational message only. No user action is required.

This means that there is an issue with the synchronization mode that is used in this Availability Group. The synchronization mode used, can be checked from the Always on Availability Group properties page.
From the properties page below, it is clear that the Failover mode in this Availability Group is configured to be performed Manually only. In this case, you need to manually perform a failover operation before rebooting or shutting down the server:

This can be fixed easily by changing the Failover Mode to Automatic, where an automatic failover operation will be performed in case of any unplanned shutdown or reboot:

The same issue can be faced when the Windows Failover Cluster quorum is configured with Node Majority for an even number of replicas, where any failure for one of the servers will bring the Windows Failover Cluster site offline. For more information, check Windows Failover Cluster Quorum Modes in SQL Server Always On Availability Groups:

Failover with Data Loss
Assume that you are trying to perform a manual failover between the Primary and one of the Secondary replicas, but in the Select New Primary Replica window, you see a warning message that the failover operation may end up with data loss as the Primary and the selected Secondary replica are not synchronized, as shown below:

To identify the cause of that issue, we will browse the Always on Health events using the Always on Availability Group dashboard, which shows that the Primary replica is not able to open a connection to the Secondary replica, ash shown below:

After fixing the connectivity issue between the Primary and the Secondary, refresh the replicas list and you will see that the data loss issue is fixed, as shown below. For more information about troubleshooting the connectivity issues, check Troubleshoot connecting to the SQL Server Database Engine.

Monitoring Always on Availability Group Latency
The Availability Group dashboard can be modified to include additional columns that provide information about the synchronization latency between Primary and Secondary replicas, including the Commit LSN, Sent LSN and harden LSN values, without showing why there is a latency, as shown below:
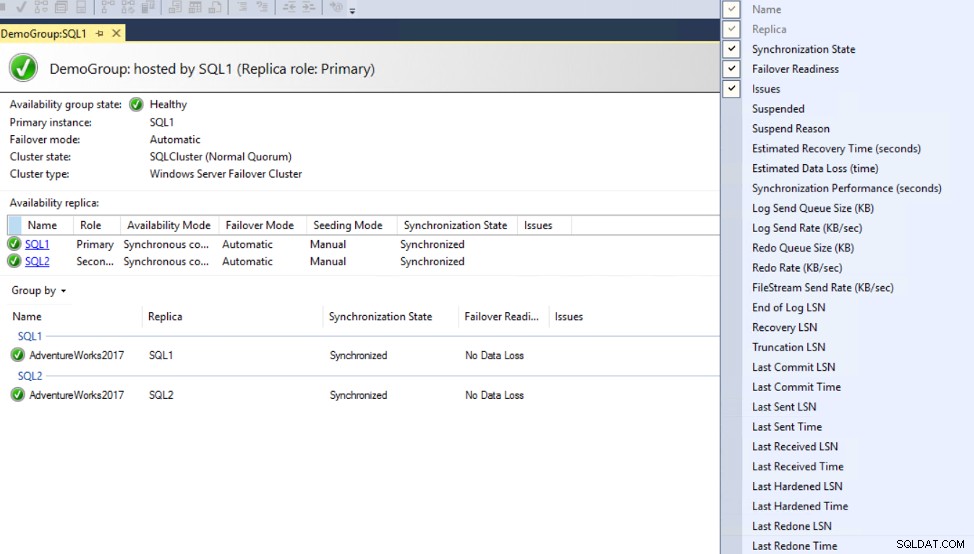
For more information about measuring the latency, check the Measuring Availability Group synchronization lag.
Starting from SSMS 17.4, the Always on Availability Group dashboard enhanced to include two new options that are used for latency information calculation, analysis and reporting, which helps in identifying the bottlenecks in the transaction logs flow between the Primary and the Secondary replicas and narrow down the cause of that latency.
For more information about the new functionality and reports, check to Use the Always on Availability Group dashboard.
To trigger using this new option, click on Collect Latency Data option from the Always on Availability Group dashboard, that will create a new SQL Agent job on the Primary and Secondary replicas to collect the latency data, As shown below:

When the created job execution has completed on all the Availability Group replicas, you will be able to view the latency statistics from the latency reports by right-clicking on the Availability Group name and choose the Primary Replica Latency or Secondary Replica Latency report, based on the replica role in the Availability Group.
After providing information about the Availability Group replicas, the latency report will show a graphical view of the transaction log commit time on the Primary replica and the remote Hardening time for the secondary replicas, aggregated as average values. Also, the report provides statistical values for the transaction logs send, receive, commit, compress, decompress and other numerical values based on the replica role in the Availability Group.
For more information about the latency report, check New in SSMS - Always On Availability Group Latency Reports.
The below report is an example of the latency reports generated from the Secondary replica, showing normal logs transport operations:

Also, the Log Block Latency report shows the amount of time, in ms, that the transaction log on the Primary replica waits for Secondary replicas to commit that transaction. After enabling it from the Availability Group Dashboard, you can browse it from the SSMS similar to the previous latency reports. Take into consideration that, the large latency time indicates that the Primary replica is waiting a long time for the Secondary replicas to commit the sent transactions, as shown below:
