In het eerste deel van deze serie heb ik basisterminologie rond loggen geïntroduceerd, dus ik raad je aan dat te lezen voordat je verder gaat met dit bericht. Al het andere dat ik in de serie zal behandelen, vereist kennis van een deel van de architectuur van het transactielogboek, dus dat is wat ik deze keer ga bespreken. Zelfs als je de serie niet gaat volgen, zijn enkele van de concepten die ik hieronder ga uitleggen de moeite waard om te weten voor dagelijkse taken die DBA's in productie uitvoeren.
Structurele hiërarchie
Het transactielogboek is intern georganiseerd met behulp van een hiërarchie met drie niveaus, zoals weergegeven in afbeelding 1 hieronder.
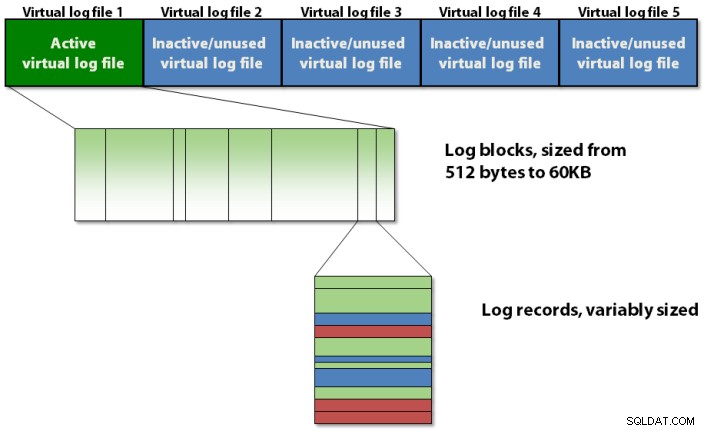 Figuur 1:De structurele hiërarchie op drie niveaus van het transactielogboek
Figuur 1:De structurele hiërarchie op drie niveaus van het transactielogboek
Het transactielogboek bevat virtuele logbestanden, die logblokken bevatten, waarin de daadwerkelijke logrecords worden opgeslagen.
Virtuele logbestanden
Het transactielogboek is opgesplitst in secties die virtuele logbestanden worden genoemd , gewoonlijk gewoon VLF's genoemd . Dit wordt gedaan om het beheer van bewerkingen in het transactielogboek gemakkelijker te maken voor de logmanager in SQL Server. U kunt niet specificeren hoeveel VLF's door SQL Server worden gemaakt wanneer de database voor het eerst wordt gemaakt of het logbestand automatisch groeit, maar u kunt dit wel beïnvloeden. Het algoritme voor hoeveel VLF's worden gemaakt, is als volgt:
- Grootte logbestand kleiner dan 64 MB:maak 4 VLF's, elk ongeveer 16 MB groot
- Grootte logbestand van 64 MB tot 1 GB:maak 8 VLF's, elk ongeveer 1/8 van de totale grootte
- Grootte logbestand groter dan 1 GB:maak 16 VLF's, elk ongeveer 1/16 van de totale grootte
Voorafgaand aan SQL Server 2014, wanneer het logbestand automatisch groeit, wordt het aantal nieuwe VLF's dat aan het einde van het logbestand wordt toegevoegd, bepaald door het bovenstaande algoritme, op basis van de automatisch groeiende grootte. Als dit algoritme echter wordt gebruikt en de grootte van de automatische groei klein is en het logbestand veel automatische groei ondergaat, kan dit leiden tot een zeer groot aantal kleine VLF's (genaamdVLF-fragmentatie ) dat voor sommige bewerkingen een groot prestatieprobleem kan zijn (zie hier).
Vanwege dit probleem is in SQL Server 2014 het algoritme gewijzigd voor automatische groei van het logbestand. Als de automatische groei kleiner is dan 1/8 van de totale grootte van het logbestand, wordt er slechts één nieuwe VLF gemaakt, anders wordt het oude algoritme gebruikt. Dit vermindert drastisch het aantal VLF's voor een logbestand dat een grote hoeveelheid automatische groei heeft ondergaan. Ik heb een voorbeeld van het verschil uitgelegd in deze blogpost.
Elke VLF heeft een volgnummer die het op unieke wijze identificeert en op verschillende plaatsen wordt gebruikt, wat ik hieronder en in toekomstige berichten zal uitleggen. Je zou denken dat de volgnummers beginnen bij 1 voor een gloednieuwe database, maar dat is niet het geval.
Op een SQL Server 2019-instantie heb ik een nieuwe database gemaakt, zonder bestandsgroottes op te geven, en vervolgens de VLF's gecontroleerd met behulp van de onderstaande code:
CREATE DATABASE NewDB;
GO
SELECT
[file_id],
[vlf_begin_offset],
[vlf_size_mb],
[vlf_sequence_number]
FROM
sys.dm_db_log_info (DB_ID (N'NewDB'));
Let op de sys.dm_db_log_info DMV is toegevoegd in SQL Server 2016 SP2. Daarvoor (en vandaag, omdat het nog steeds bestaat) kun je de ongedocumenteerde DBCC LOGINFO gebruiken commando, maar je kunt het geen selectielijst geven - doe gewoon DBCC LOGINFO(N'NewDB'); en de VLF-volgnummers staan in de FSeqNo kolom van de resultatenset.
Hoe dan ook, de resultaten van het bevragen van sys.dm_db_log_info waren:
file_id vlf_begin_offset vlf_size_mb vlf_sequence_number ------- ---------------- ----------- ------------------- 2 8192 1.93 37 2 2039808 1.93 0 2 4071424 1.93 0 2 6103040 2.17 0
Merk op dat de eerste VLF begint bij een offset van 8.192 bytes in het logbestand. Dit komt omdat alle databasebestanden, inclusief het transactielogboek, een bestandskoppagina hebben die de eerste 8 KB in beslag neemt en verschillende metadata over het bestand opslaat.
Dus waarom kiest SQL Server 37 en niet 1 voor het eerste VLF-volgnummer? Het vindt het hoogste VLF-volgnummer in het model database en vervolgens, voor elke nieuwe database, gebruikt de eerste VLF van het transactielogboek dat nummer plus 1 voor het volgnummer. Ik weet niet waarom dit algoritme in de nevelen der tijden is gekozen, maar dat is al zo sinds SQL Server 7.0.
Om het te bewijzen, heb ik deze code uitgevoerd:
SELECT
MAX ([vlf_sequence_number]) AS [Max_VLF_SeqNo]
FROM
sys.dm_db_log_info (DB_ID (N'model')); En de resultaten waren:
Max_VLF_SeqNo -------------------- 36
Dus daar heb je het.
Er valt meer te bespreken over VLF's en hoe ze worden gebruikt, maar voor nu is het voldoende om te weten dat elke VLF een volgnummer heeft, dat met één wordt verhoogd voor elke VLF.
Logblokken
Elke VLF bevat een kleine metadatakop en de rest van de ruimte is gevuld met logblokken. Elk logblok begint bij 512 bytes en groeit in stappen van 512 bytes tot een maximale grootte van 60 KB, waarna het naar schijf moet worden geschreven. Als een van de volgende situaties zich voordoet, kan een logblok naar de schijf worden geschreven voordat het de maximale grootte heeft bereikt:
- Een transactie wordt vastgelegd en vertraagde duurzaamheid wordt niet gebruikt voor deze transactie, dus het logblok moet naar schijf worden geschreven om de transactie duurzaam te maken
- Vertraagde duurzaamheid is in gebruik en de achtergrond "spoelt het huidige logblok naar schijf" 1 ms timertaak wordt geactiveerd
- Een gegevensbestandspagina wordt naar schijf geschreven door een controlepunt of de luie schrijver, en er zijn een of meer logrecords in het huidige logblok die van invloed zijn op de pagina die op het punt staat te worden geschreven (denk eraan gegarandeerd)
U kunt een logblok beschouwen als een pagina met variabele afmetingen waarin logrecords worden opgeslagen in de volgorde waarin ze zijn gemaakt door transacties die de database wijzigen. Er is geen logblok voor elke transactie; de logrecords voor meerdere gelijktijdige transacties kunnen worden vermengd in een logblok. Je zou kunnen denken dat dit problemen zou opleveren voor bewerkingen die alle logrecords voor een enkele transactie moeten vinden, maar dat is niet het geval, zoals ik zal uitleggen wanneer ik in een later bericht zal uitleggen hoe het terugdraaien van transacties werkt.
Bovendien, wanneer een logblok naar schijf wordt geschreven, is het heel goed mogelijk dat het logrecords van niet-vastgelegde transacties bevat. Dit is ook geen probleem vanwege de manier waarop crashherstel werkt, wat een flink aantal berichten in de toekomst van de serie is.
Logvolgnummers
Logblokken hebben een ID binnen een VLF, beginnend bij 1 en toenemend met 1 voor elk nieuw logblok in de VLF. Logrecords hebben ook een ID binnen een logblok, beginnend bij 1 en oplopend met 1 voor elk nieuw logrecord in het logblok. Dus alle drie de elementen in de structurele hiërarchie van het transactielogboek hebben een ID en ze worden samengevoegd tot een tripartiete identifier die een logvolgnummer wordt genoemd. , beter bekend als een LSN .
Een LSN wordt gedefinieerd als <VLF sequence number>:<log block ID>:<log record ID> (4 bytes:4 bytes:2 bytes) en identificeert op unieke wijze een enkele logrecord. Het is een steeds groter wordende identificatie, omdat de VLF-volgnummers voor altijd toenemen.
Grondwerk gedaan!
Hoewel VLF's belangrijk zijn om te weten, is naar mijn mening de LSN het belangrijkste concept om te begrijpen rond de implementatie van logboekregistratie door SQL Server, aangezien LSN's de hoeksteen zijn waarop het terugdraaien van transacties en crashherstel zijn gebouwd, en LSN's zullen steeds weer opduiken als Ik ga door de serie heen. In de volgende post zal ik het afkappen van logboeken en de circulaire aard van het transactielogboek behandelen, wat allemaal te maken heeft met VLF's en hoe ze opnieuw worden gebruikt.