
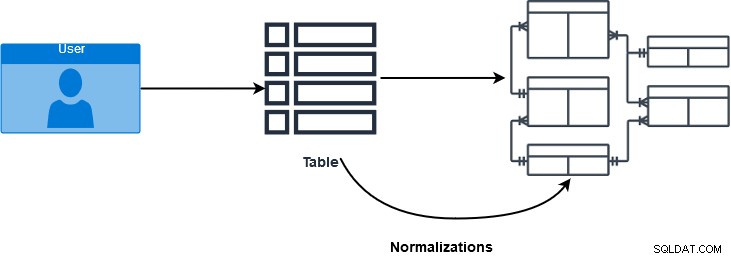
SQL JOIN is een clausule die wordt gebruikt om meerdere tabellen te combineren en gegevens op te halen op basis van een gemeenschappelijk veld in relationele databases. Databaseprofessionals gebruiken normalisaties om de gegevensintegriteit te waarborgen en te verbeteren. In de verschillende normalisatievormen worden gegevens verdeeld in meerdere logische tabellen. Deze tabellen gebruiken referentiële beperkingen - primaire sleutel en externe sleutels - om de gegevensintegriteit in SQL Server-tabellen af te dwingen. In de onderstaande afbeelding krijgen we een glimp van het normalisatieproces van de database.
De verschillende typen SQL JOIN begrijpen
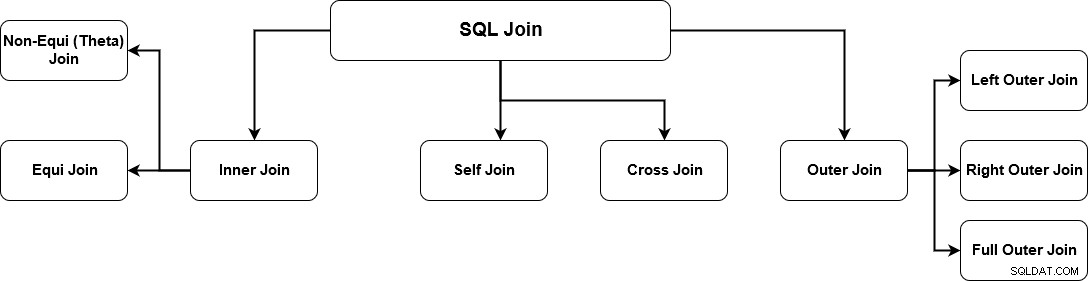
SQL JOIN genereert zinvolle gegevens door meerdere relationele tabellen te combineren. Deze tabellen zijn gerelateerd met behulp van een sleutel en hebben een-op-een- of een-op-veel-relaties. Om de juiste gegevens op te halen, moet u de gegevensvereisten en de juiste verbindingsmechanismen kennen. SQL Server ondersteunt meerdere joins en elke methode heeft een specifieke manier om gegevens uit meerdere tabellen op te halen. De onderstaande afbeelding geeft de ondersteunde SQL Server-joins aan.
SQL inner join
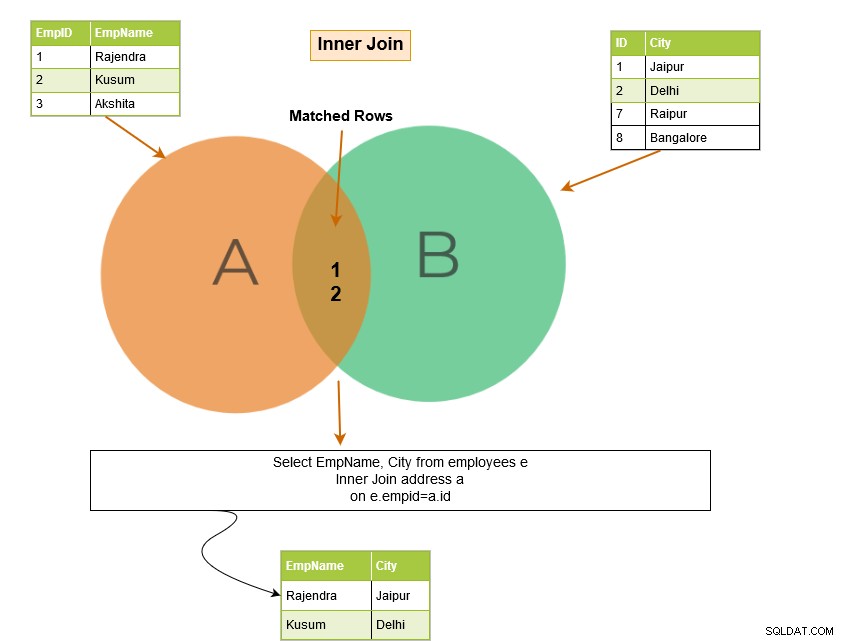
De SQL inner join bevat rijen uit de tabellen waar aan de join-voorwaarden is voldaan. In het onderstaande Venn-diagram retourneert inner join bijvoorbeeld de overeenkomende rijen uit Tabel A en Tabel B.
Let in het onderstaande voorbeeld op de volgende dingen:
- We hebben twee tabellen:[Werknemers] en [Adres].
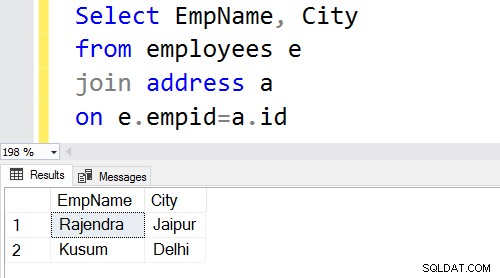
- De SQL-query wordt samengevoegd in de kolommen [Employees].[EmpID] en [Address].[ID].
De uitvoer van de query retourneert de werknemersrecords voor EmpID die in beide tabellen voorkomen.
De inner join retourneert overeenkomende rijen uit beide tabellen; daarom is het ook bekend als Equi join. Als we het inner keyword niet specificeren, voert SQL Server de inner join-bewerking uit.
In een ander type inner join, een theta join, gebruiken we de gelijkheidsoperator (=) niet in de ON-clausule. In plaats daarvan gebruiken we niet-gelijkheidsoperatoren zoals
SELECTEER * UIT Tabel1 T1, Tabel2 T2 WAAR T1.Prijs
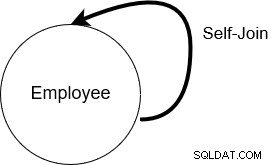
In een self-join voegt SQL Server zich bij de tabel met zichzelf. Dit betekent dat de tabelnaam twee keer voorkomt in de from-clausule.
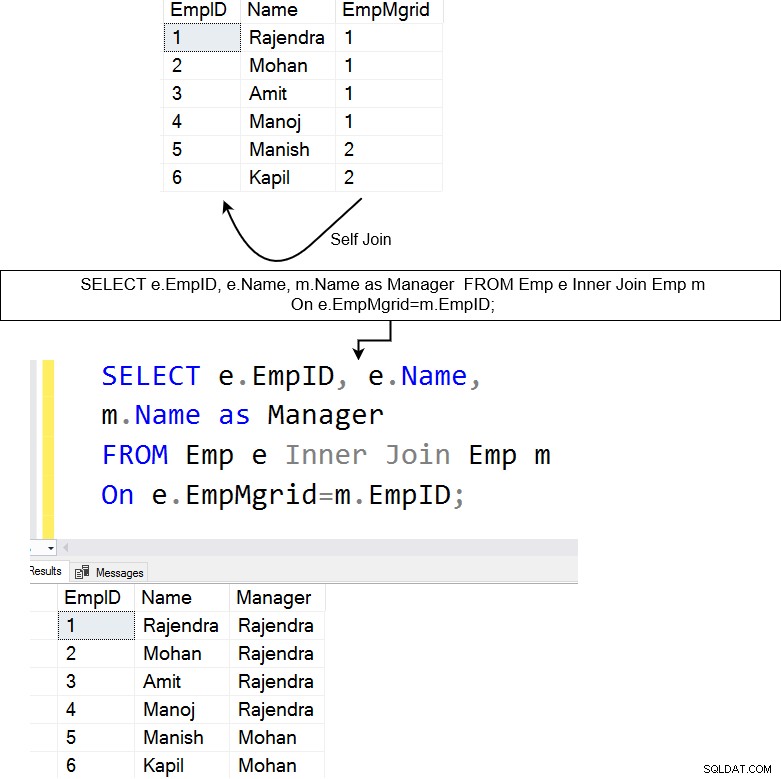
Hieronder hebben we een tabel [Emp] die zowel werknemers als de gegevens van hun managers bevat. De self-join is handig voor het opvragen van hiërarchische gegevens. In de werknemerstabel kunnen we bijvoorbeeld self-join gebruiken om de naam van elke werknemer en hun rapporterende manager te leren.
De bovenstaande query plaatst een self-join op de [Emp]-tabel. Het voegt de kolom EmpMgrID samen met de kolom EmpID en retourneert de overeenkomende rijen.
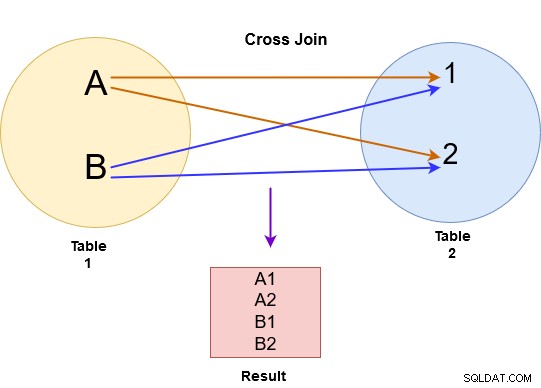
In de cross join retourneert SQL Server een Cartesiaans product uit beide tabellen. In de onderstaande afbeelding hebben we bijvoorbeeld een cross-join uitgevoerd voor tabel A en B.
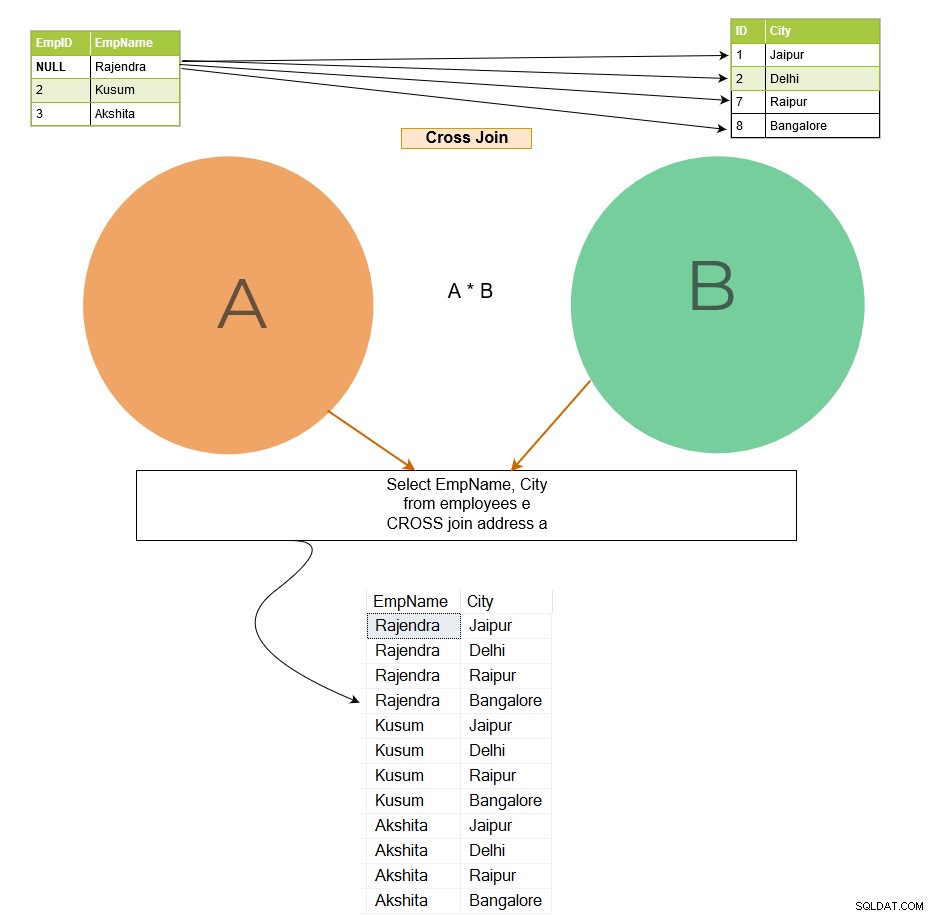
De cross join verbindt elke rij van tabel A met elke beschikbare rij in tabel B. Daarom wordt de uitvoer ook wel een cartesiaans product van beide tabellen genoemd. Let in de onderstaande afbeelding op het volgende:
In de cross-join-uitvoer voegt rij 1 van de [Werknemer]-tabel zich samen met alle rijen van de [Adres]-tabel en volgt hetzelfde patroon voor de overige rijen.
Als de eerste tabel x aantal rijen heeft en de tweede tabel n aantal rijen heeft, geeft cross join x*n aantal rijen in de uitvoer. U moet cross-join op grotere tabellen vermijden, omdat het een groot aantal records kan retourneren en SQL Server veel rekenkracht (CPU, geheugen en IO) vereist voor het verwerken van dergelijke uitgebreide gegevens.
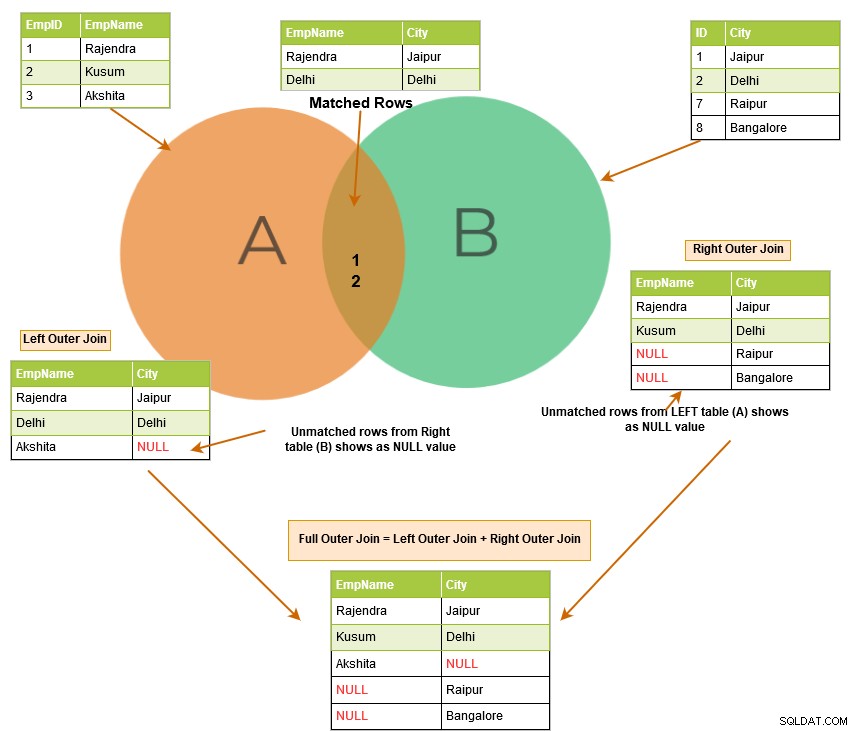
Zoals we eerder hebben uitgelegd, retourneert de inner join de overeenkomende rijen van beide tabellen. Wanneer u een SQL outer join gebruikt, worden niet alleen de overeenkomende rijen weergegeven, maar worden ook de niet-overeenkomende rijen uit de andere tabellen geretourneerd. De niet-overeenkomende rij is afhankelijk van de linker-, rechter- of volledige zoekwoorden.
De onderstaande afbeelding beschrijft op hoog niveau de linker, rechter en volledige outer join.
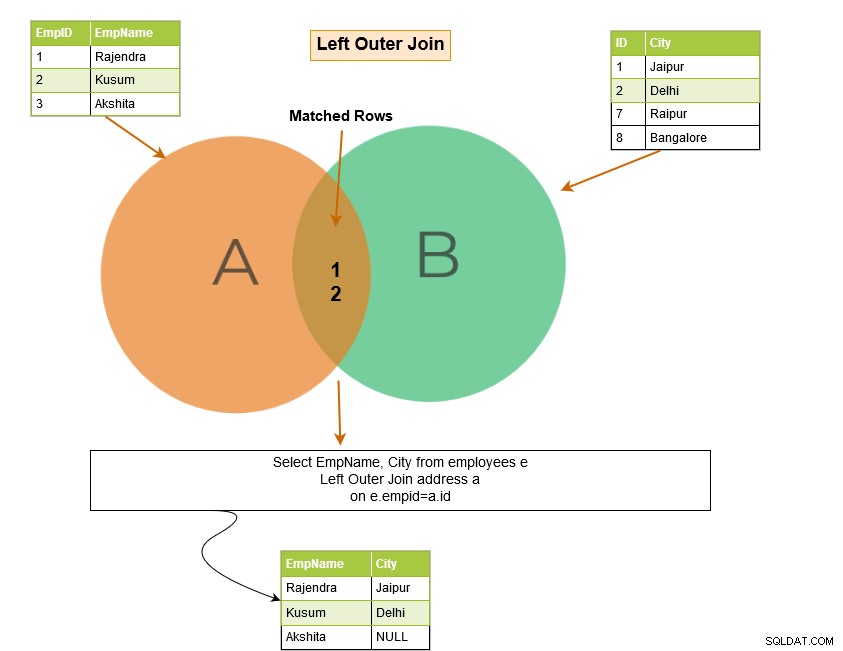
SQL left outer join retourneert de overeenkomende rijen van beide tabellen samen met de niet-overeenkomende rijen uit de linkertabel. Als een record uit de linkertabel geen overeenkomende rijen in de rechtertabel heeft, wordt de record weergegeven met NULL-waarden.
In het onderstaande voorbeeld retourneert de linker outer join de volgende rijen:
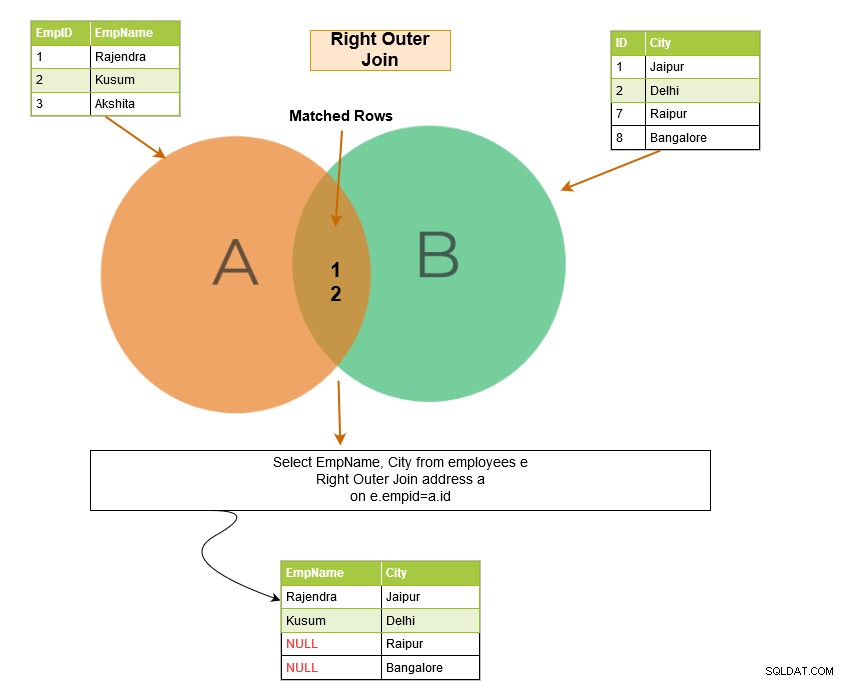
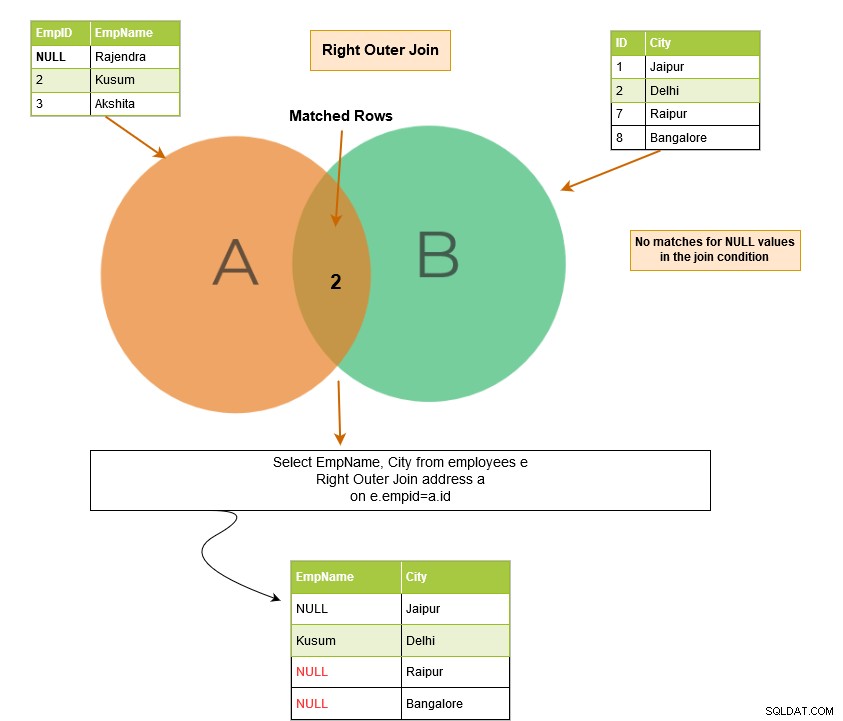
SQL right outer join retourneert de overeenkomende rijen van beide tabellen samen met de niet-overeenkomende rijen uit de rechtertabel. Als een record uit de rechtertabel geen overeenkomende rijen in de linkertabel heeft, wordt de record weergegeven met NULL-waarden.
In het onderstaande voorbeeld hebben we de volgende uitvoerrijen:
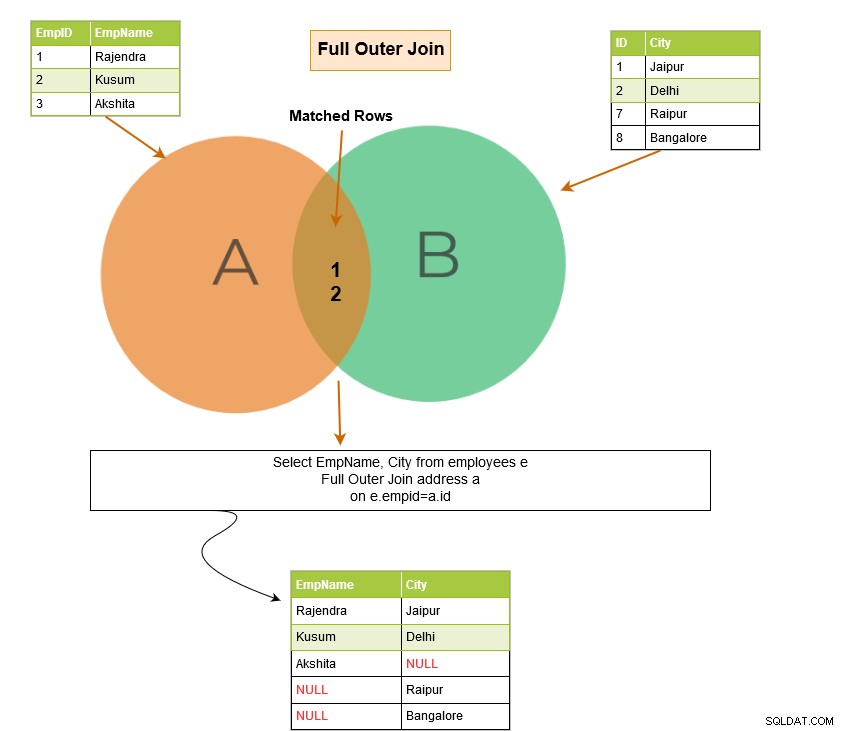
Een volledige outer join retourneert de volgende rijen in de uitvoer:
In de vorige voorbeelden gebruiken we twee tabellen in een SQL-query om samenvoegbewerkingen uit te voeren. Meestal voegen we meerdere tabellen samen en het geeft de relevante gegevens terug.
De onderstaande query gebruikt meerdere inner joins.
Laten we de zoekopdracht in de volgende stappen analyseren:
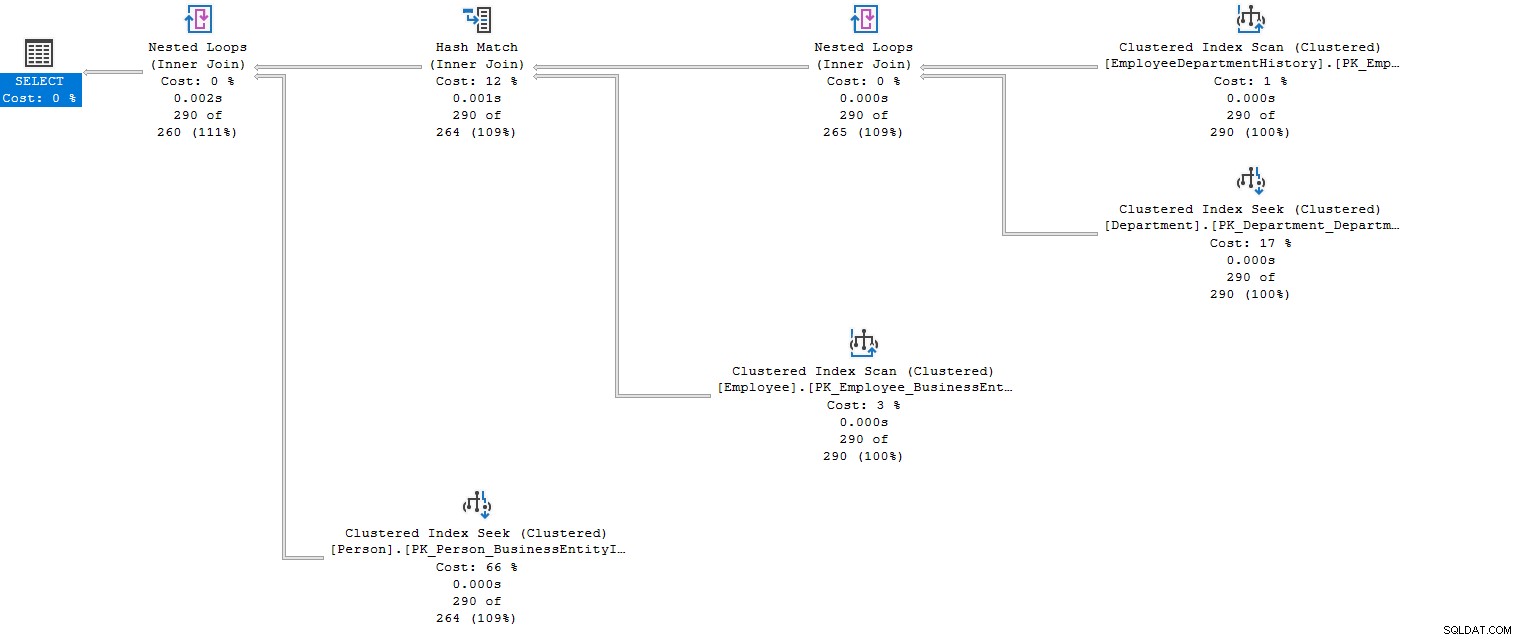
Nadat u de query met meerdere joins heeft uitgevoerd, stelt Query Optimizer het uitvoeringsplan op. Het bereidt een kostengeoptimaliseerd uitvoeringsplan voor dat voldoet aan de join-voorwaarden met resourcegebruik - in het onderstaande werkelijke uitvoeringsplan kunnen we bijvoorbeeld kijken naar meerdere geneste lussen (inner join) en hash-match (inner join) waarbij gegevens uit meerdere samenvoegtabellen worden gecombineerd .
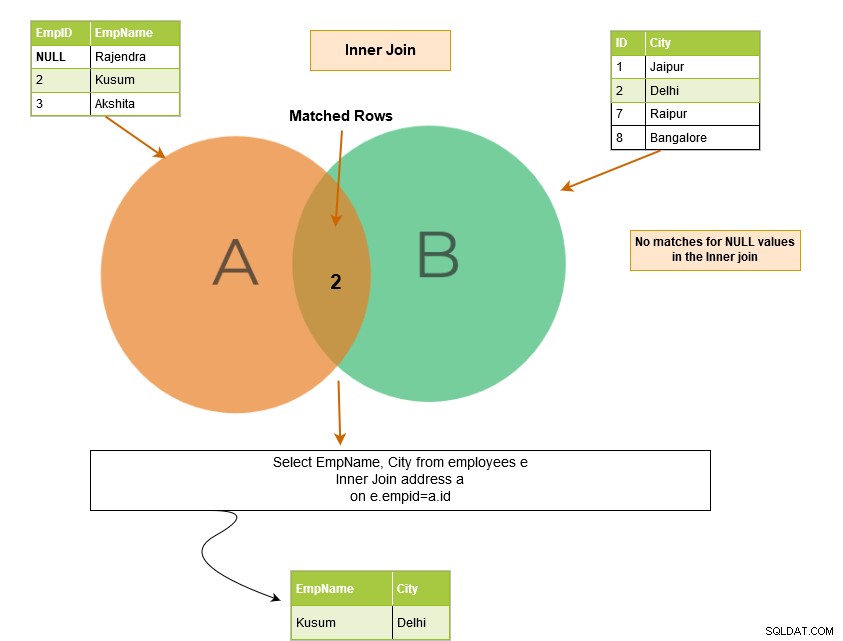
Stel dat we NULL-waarden in de tabelkolommen hebben, en we voegen de tabellen in die kolommen samen. Komt SQL Server overeen met NULL-waarden?
De NULL-waarden komen niet met elkaar overeen. Daarom kan SQL Server de overeenkomende rij niet retourneren. In het onderstaande voorbeeld hebben we NULL in de kolom EmpID van de tabel [Employees]. Daarom retourneert het in de uitvoer alleen de overeenkomende rij voor [EmpID] 2.
We kunnen deze NULL-rij in de uitvoer krijgen in het geval van een SQL outer join omdat het ook de niet-overeenkomende rijen retourneert.
In dit artikel hebben we de verschillende typen SQL-join onderzocht. Hier zijn een paar belangrijke best practices om te onthouden en toe te passen bij het gebruik van SQL-joins.SQL self-join
SQL cross-join
SQL outer join
Linker buitenste join
Rechter buitenste join
Volledige outer join
SQL joins met meerdere tabellen
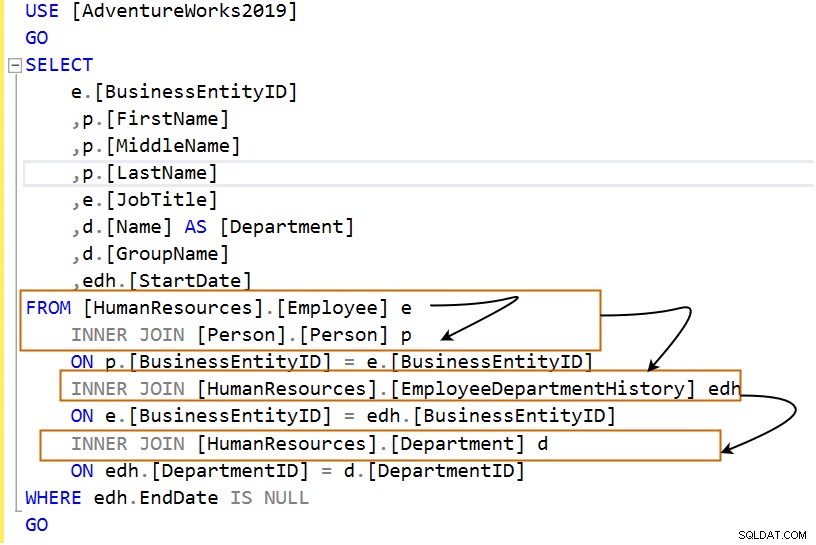
USE [AdventureWorks2019]
GO
SELECT
e.[BusinessEntityID]
,p.[FirstName]
,p.[MiddleName]
,p.[LastName]
,e.[JobTitle]
,d.[Name] AS [Department]
,d.[GroupName]
,edh.[StartDate]
FROM [HumanResources].[Employee] e
INNER JOIN [Person].[Person] p
ON p.[BusinessEntityID] = e.[BusinessEntityID]
INNER JOIN [HumanResources].[EmployeeDepartmentHistory] edh
ON e.[BusinessEntityID] = edh.[BusinessEntityID]
INNER JOIN [HumanResources].[Department] d
ON edh.[DepartmentID] = d.[DepartmentID]
WHERE edh.EndDate IS NULL
GO
NULL-waarden en SQL-joins
SQL sluit zich aan bij best practices