Volledig eens met @PaulStock dat aggregaten het beste aan bronsystemen kunnen worden overgelaten. Een aggregaat in SSIS is een volledig blokkerende component, net als een soort en ik heb heb mijn argument op dat punt al gemaakt .
Maar er zijn momenten waarop het doen van die bewerkingen in het bronsysteem gewoon niet gaat werken. Het beste wat ik heb kunnen bedenken, is om de gegevens in feite dubbel te verwerken. Ja, maar ik heb nooit een manier kunnen vinden om een column onaangetast door te laten. Voor Min/Max-scenario's zou ik dat als optie willen, maar het is duidelijk dat zoiets als een Som het voor de component moeilijk zou maken om te weten aan welke "bron"-rij het zou worden gekoppeld.
2005
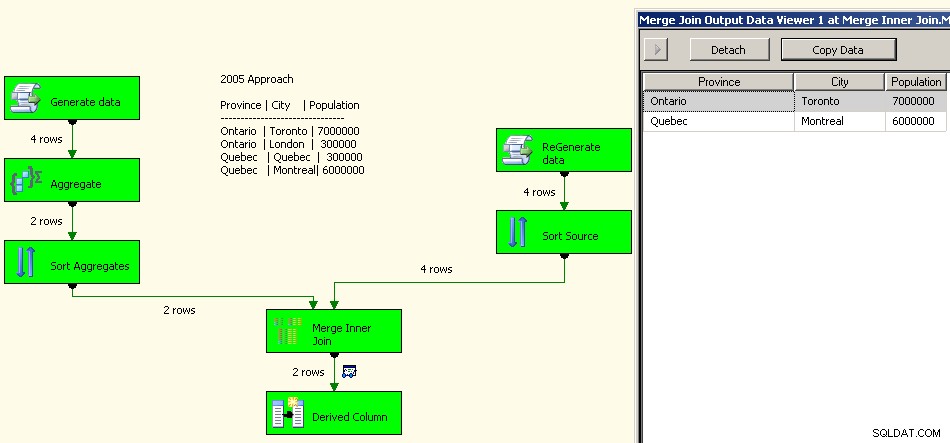
Een implementatie uit 2005 zou er als volgt uitzien. Je prestaties zullen niet goed zijn, in feite een paar ordes van grootte van goed, omdat je al deze blokkeringstransformaties zult hebben naast het opnieuw verwerken van je brongegevens.
Samenvoegen 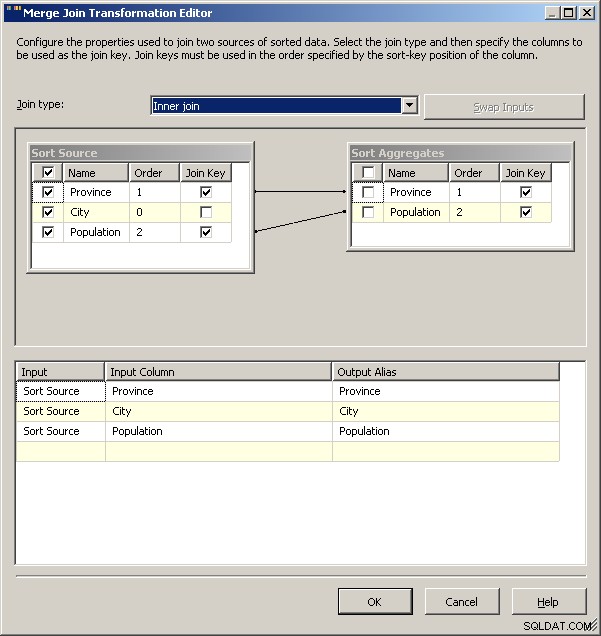
2008
In 2008 heeft u de mogelijkheid om de Cache Connection Manager te gebruiken wat zou helpen de blokkeringstransformaties te elimineren, tenminste waar het ertoe doet, maar je zult nog steeds de kosten moeten betalen van dubbele verwerking van je brongegevens.
Sleep twee gegevensstromen naar het canvas. De eerste zal de cache-verbindingsbeheerder vullen en zou de plaats moeten zijn waar de aggregatie plaatsvindt.
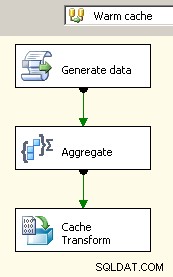
Nu de cache de geaggregeerde gegevens bevat, laat u een opzoektaak in uw hoofdgegevensstroom vallen en voert u een zoekopdracht uit met de cache.
Tabblad Algemeen opzoeken
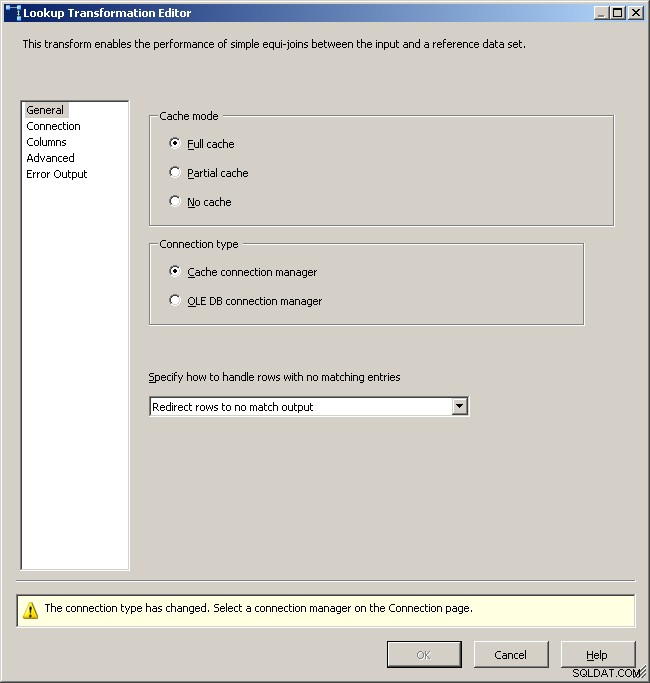
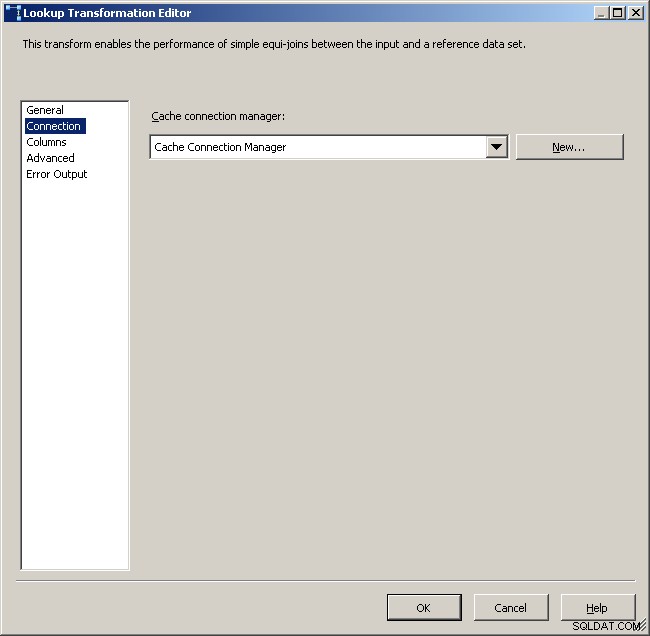
Selecteer de cacheverbindingsbeheerder
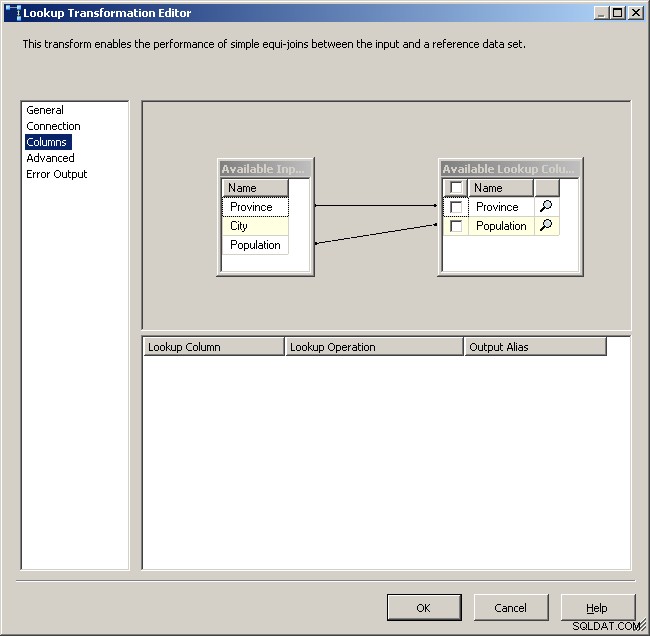
Wijs de juiste kolommen toe
Groot succes 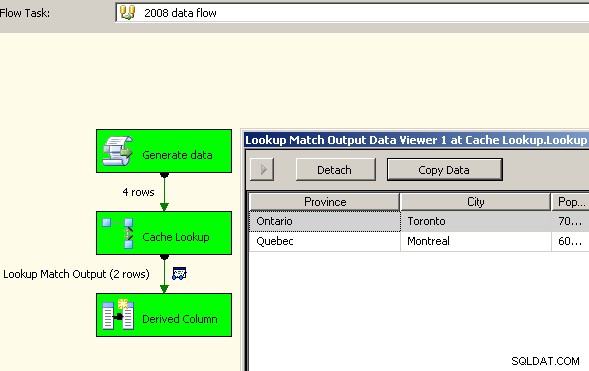
Scripttaak
De derde benadering die ik kan bedenken, 2005 of 2008, is om het zelf te schrijven. Als algemene regel probeer ik de scripttaken te vermijden, maar dit is een geval waarin het waarschijnlijk logisch is. Je moet er een asynchrone scripttransformatie maar handel daar eenvoudig uw aggregaties af. Meer code om te onderhouden, maar u kunt uzelf de moeite besparen om uw brongegevens opnieuw te verwerken.
Tot slot, als algemeen voorbehoud, zou ik onderzoeken wat de impact van banden op uw oplossing zal doen. Voor deze dataset zou ik verwachten dat zoiets als Guelph plotseling zou opzwellen en Toronto zou binden, maar als dat zo was, wat zou het pakket dan moeten doen? Op dit moment zullen beide resulteren in 2 rijen voor Ontario, maar is dat het beoogde gedrag? Script stelt u natuurlijk in staat om te definiëren wat er gebeurt in het geval van banden. Je zou waarschijnlijk de 2008-oplossing op zijn kop kunnen zetten door de "normale" gegevens in de cache te plaatsen en die als je opzoekconditie te gebruiken en de aggregaten te gebruiken om slechts een van de banden terug te trekken. 2005 kan waarschijnlijk hetzelfde doen door het aggregaat als de linkerbron voor de samenvoegverbinding te plaatsen
Bewerkingen
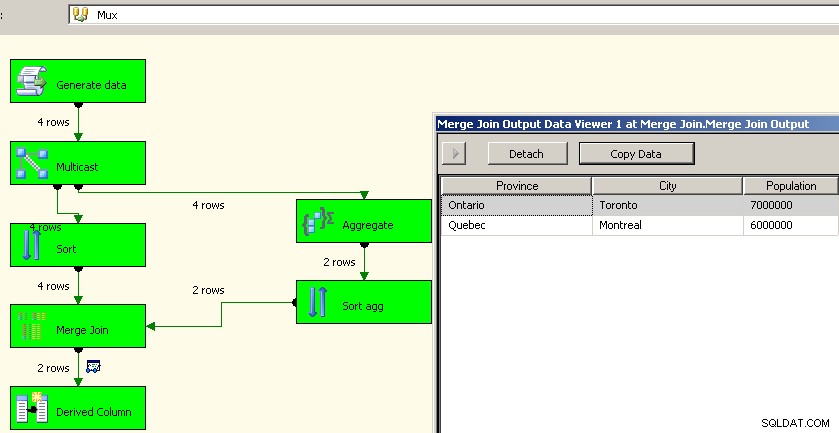
Jason Horner had een goed idee in zijn commentaar. Een andere benadering zou zijn om een multicast-transformatie te gebruiken en de aggregatie in één stroom uit te voeren en weer bij elkaar te brengen. Ik kon er niet achter komen hoe ik het met een vakbond kon laten werken, maar we konden soorten gebruiken en samenvoegen, net zoals in het bovenstaande. Dit is waarschijnlijk een betere benadering omdat het ons de moeite bespaart om de brongegevens opnieuw te verwerken.