De SQL Server-optimizer bevat logica om redundante joins te verwijderen, maar er zijn beperkingen, en de joins moeten aantoonbaar redundant . Samenvattend kan een join vier effecten hebben:
- Het kan extra kolommen toevoegen (van de samengevoegde tabel)
- Het kan extra rijen toevoegen (de samengevoegde tabel kan meer dan één keer overeenkomen met een bronrij)
- Het kan rijen verwijderen (de samengevoegde tabel heeft mogelijk geen overeenkomst)
- Het kan
NULLintroduceren s (voor eenRIGHTofFULL JOIN)
Om een redundante join met succes te verwijderen, moet de query (of view) rekening houden met alle vier de mogelijkheden. Als dit op de juiste manier wordt gedaan, kan het effect verbluffend zijn. Bijvoorbeeld:
USE AdventureWorks2012;
GO
CREATE VIEW dbo.ComplexView
AS
SELECT
pc.ProductCategoryID, pc.Name AS CatName,
ps.ProductSubcategoryID, ps.Name AS SubCatName,
p.ProductID, p.Name AS ProductName,
p.Color, p.ListPrice, p.ReorderPoint,
pm.Name AS ModelName, pm.ModifiedDate
FROM Production.ProductCategory AS pc
FULL JOIN Production.ProductSubcategory AS ps ON
ps.ProductCategoryID = pc.ProductCategoryID
FULL JOIN Production.Product AS p ON
p.ProductSubcategoryID = ps.ProductSubcategoryID
FULL JOIN Production.ProductModel AS pm ON
pm.ProductModelID = p.ProductModelID
De optimizer kan de volgende zoekopdracht met succes vereenvoudigen:
SELECT
c.ProductID,
c.ProductName
FROM dbo.ComplexView AS c
WHERE
c.ProductName LIKE N'G%';
Aan:

Rob Farley schreef uitgebreid over deze ideeën in het originele MVP Deep Dives-boek , en er is een opname van zijn presentatie over het onderwerp op SQLBits.
De belangrijkste beperkingen zijn dat relaties met externe sleutels moet gebaseerd zijn op een enkele sleutel om bij te dragen aan het vereenvoudigingsproces, en de compilatietijd voor de query's tegen een dergelijke weergave kan behoorlijk lang worden, vooral naarmate het aantal joins toeneemt. Het kan een hele uitdaging zijn om een weergave van 100 tabellen te schrijven waarin alle semantiek precies correct is. Ik zou geneigd zijn om een alternatieve oplossing te vinden, misschien met behulp van dynamische SQL .
Dat gezegd hebbende, kunnen de specifieke eigenschappen van uw gedenormaliseerde tabel betekenen dat de weergave vrij eenvoudig te assembleren is en alleen afgedwongen FOREIGN KEYs vereist niet-NULL kolommen waarnaar wordt verwezen en de juiste UNIQUE beperkingen om deze oplossing te laten werken zoals u zou hopen, zonder de overhead van 100 fysieke join-operators in het plan.
Voorbeeld
Tien tabellen gebruiken in plaats van honderd:
-- Referenced tables
CREATE TABLE dbo.Ref01 (col01 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref02 (col02 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref03 (col03 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref04 (col04 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref05 (col05 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref06 (col06 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref07 (col07 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref08 (col08 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref09 (col09 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref10 (col10 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
De definitie van de bovenliggende tabel (met paginacompressie):
CREATE TABLE dbo.Normalized
(
pk integer IDENTITY NOT NULL,
col01 tinyint NOT NULL REFERENCES dbo.Ref01,
col02 tinyint NOT NULL REFERENCES dbo.Ref02,
col03 tinyint NOT NULL REFERENCES dbo.Ref03,
col04 tinyint NOT NULL REFERENCES dbo.Ref04,
col05 tinyint NOT NULL REFERENCES dbo.Ref05,
col06 tinyint NOT NULL REFERENCES dbo.Ref06,
col07 tinyint NOT NULL REFERENCES dbo.Ref07,
col08 tinyint NOT NULL REFERENCES dbo.Ref08,
col09 tinyint NOT NULL REFERENCES dbo.Ref09,
col10 tinyint NOT NULL REFERENCES dbo.Ref10,
CONSTRAINT PK_Normalized
PRIMARY KEY CLUSTERED (pk)
WITH (DATA_COMPRESSION = PAGE)
);
Het uitzicht:
CREATE VIEW dbo.Denormalized
WITH SCHEMABINDING AS
SELECT
item01 = r01.item,
item02 = r02.item,
item03 = r03.item,
item04 = r04.item,
item05 = r05.item,
item06 = r06.item,
item07 = r07.item,
item08 = r08.item,
item09 = r09.item,
item10 = r10.item
FROM dbo.Normalized AS n
JOIN dbo.Ref01 AS r01 ON r01.col01 = n.col01
JOIN dbo.Ref02 AS r02 ON r02.col02 = n.col02
JOIN dbo.Ref03 AS r03 ON r03.col03 = n.col03
JOIN dbo.Ref04 AS r04 ON r04.col04 = n.col04
JOIN dbo.Ref05 AS r05 ON r05.col05 = n.col05
JOIN dbo.Ref06 AS r06 ON r06.col06 = n.col06
JOIN dbo.Ref07 AS r07 ON r07.col07 = n.col07
JOIN dbo.Ref08 AS r08 ON r08.col08 = n.col08
JOIN dbo.Ref09 AS r09 ON r09.col09 = n.col09
JOIN dbo.Ref10 AS r10 ON r10.col10 = n.col10;
Hack de statistieken om de optimizer te laten denken dat de tabel erg groot is:
UPDATE STATISTICS dbo.Normalized WITH ROWCOUNT = 100000000, PAGECOUNT = 5000000;
Voorbeeld gebruikersvraag:
SELECT
d.item06,
d.item07
FROM dbo.Denormalized AS d
WHERE
d.item08 = 'Banana'
AND d.item01 = 'Green';
Geeft ons dit uitvoeringsplan:
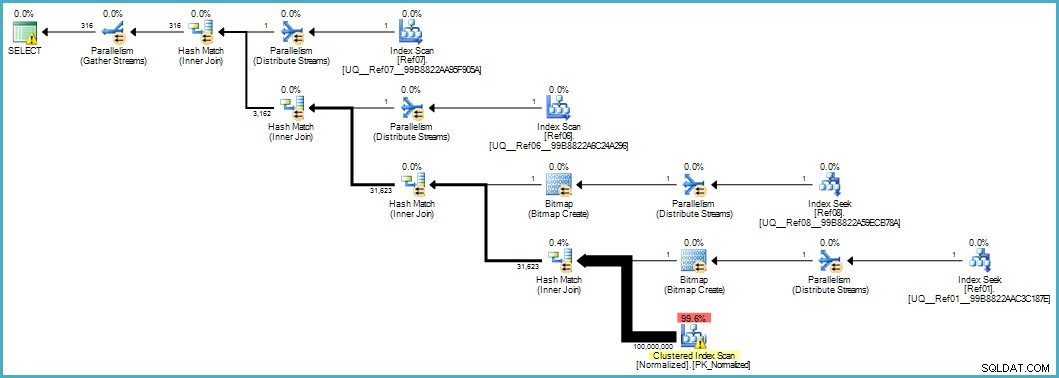
De scan van de genormaliseerde tabel ziet er slecht uit, maar beide Bloom-filter-bitmaps worden tijdens de scan toegepast door de opslagengine (dus rijen die niet overeenkomen, komen niet eens zo ver als de queryprocessor naar boven). Dit kan in uw geval voldoende zijn om acceptabele prestaties te leveren, en zeker beter dan het scannen van de originele tabel met zijn overvolle kolommen.
Als u op een bepaald moment kunt upgraden naar SQL Server 2012 Enterprise, heeft u een andere optie:een column-store-index maken in de tabel Normalized:
CREATE NONCLUSTERED COLUMNSTORE INDEX cs
ON dbo.Normalized (col01,col02,col03,col04,col05,col06,col07,col08,col09,col10);
Het uitvoeringsplan is:
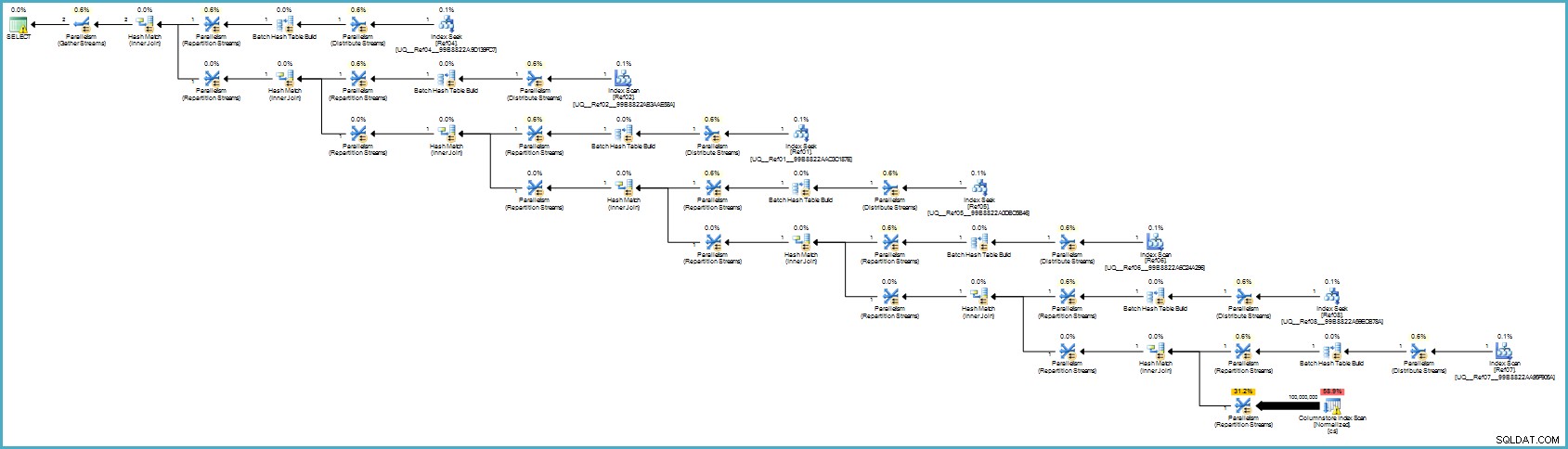
Dat ziet er waarschijnlijk slechter uit, maar kolomopslag biedt uitzonderlijke compressie en het hele uitvoeringsplan werkt in batchmodus met filters voor alle bijdragende kolommen. Als de server voldoende threads en geheugen beschikbaar heeft, kan dit alternatief echt vliegen.
Uiteindelijk weet ik niet zeker of deze normalisatie de juiste aanpak is, gezien het aantal tabellen en de kans op een slecht uitvoeringsplan of een buitensporige compilatietijd. Ik zou waarschijnlijk eerst het schema van de gedenormaliseerde tabel corrigeren (juiste gegevenstypen enzovoort), mogelijk datacompressie toepassen ... de gebruikelijke dingen.
Als de gegevens echt in een sterschema thuishoren, is er waarschijnlijk meer ontwerpwerk nodig dan alleen het opsplitsen van herhalende gegevenselementen in afzonderlijke tabellen.