Er is geen relevante hard gecodeerde limiet (65.536 * netwerkpakketgrootte van 4 KB is 268 MB en uw scriptlengte is lang niet zo lang), hoewel het niet raadzaam is om deze methode te gebruiken voor een groot aantal rijen.
De fout die u ziet, wordt veroorzaakt door de clienthulpprogramma's en niet door SQL Server. Als u de SQL String construeert in dynamische SQL-compilatie, kan deze op zijn minst succesvol starten
DECLARE @SQL NVARCHAR(MAX) = '(100,200,300),
';
SELECT @SQL = 'SELECT * FROM (VALUES ' + REPLICATE(@SQL, 1000000) + '
(100,200,300)) tc (proj_d, period_sid, val)';
SELECT @SQL AS [processing-instruction(x)]
FOR XML PATH('')
SELECT DATALENGTH(@SQL) / 1048576.0 AS [Length in MB] --30.517705917
EXEC(@SQL);
Hoewel ik het bovenstaande na ~ 30 minuten compilatietijd heb gedood en het nog steeds geen rij had geproduceerd. De letterlijke waarden moeten in het plan zelf worden opgeslagen als een tabel met constanten en SQL Server besteedt veel tijd proberen ook eigenschappen over hen af te leiden.
SSMS is een 32-bits applicatie en genereert een std::bad_alloc uitzondering tijdens het ontleden van de batch
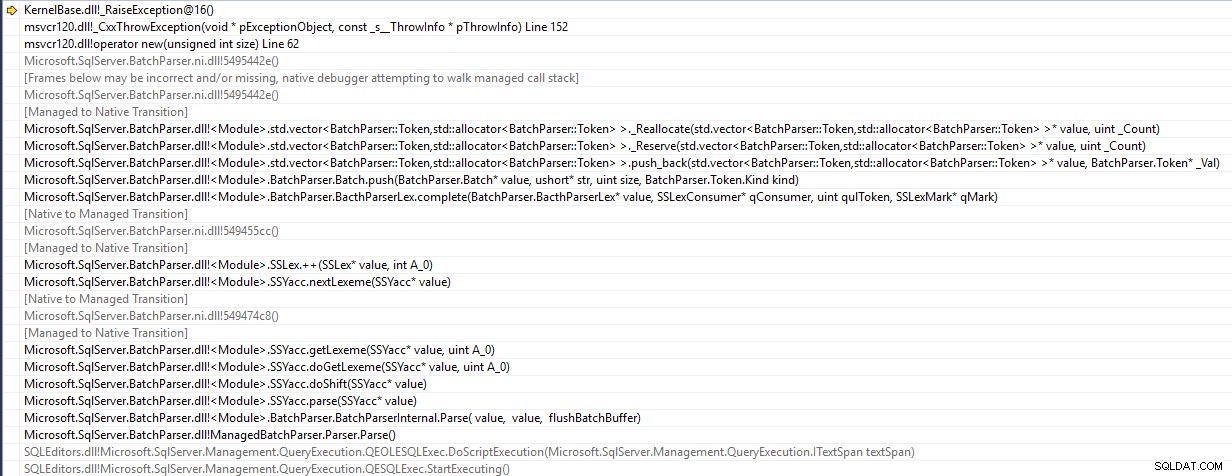
Het probeert een element op een vector van Token te duwen die zijn capaciteit heeft bereikt en zijn poging om de grootte te wijzigen mislukt vanwege het niet beschikbaar zijn van een voldoende groot aaneengesloten geheugengebied. Dus de verklaring komt zelfs nooit zo ver als de server.
De vectorcapaciteit groeit elke keer met 50% (d.w.z. door de volgorde hier te volgen ). De capaciteit waartoe de vector moet groeien, hangt af van hoe de code is ingedeeld.
Het volgende moet groeien van een capaciteit van 19 naar 28.
SELECT * FROM (VALUES (100,200,300),(100,200,300),(100,200,300),(100,200,300),(100,200,300),(100,200,300)) tc (proj_d, period_sid, val)
en het volgende heeft slechts een maat van 2 nodig
SELECT * FROM (VALUES (100,200,300),(100,200,300),(100,200,300),(100,200,300),(100,200,300),(100,200,300)) tc (proj_d, period_sid, val)
Het volgende heeft een capaciteit van> 63 en <=94 nodig.
SELECT *
FROM (VALUES
(100,
200,
300),
(100,
200,
300),
(100,
200,
300),
(100,
200,
300),
(100,
200,
300),
(100,
200,
300)
) tc (proj_d, period_sid, val)
Voor een miljoen rijen die zijn aangelegd zoals in geval 1 moet de vectorcapaciteit groeien tot 3.543.306.
Mogelijk zult u merken dat een van de volgende zaken het parsen aan de clientzijde zal laten slagen.
- Verminder het aantal regeleinden.
- SSMS opnieuw starten in de hoop dat het verzoek om groot aaneengesloten geheugen slaagt wanneer er minder fragmentatie van de adresruimte is.
Maar zelfs als je het met succes naar de server verzendt, zal het de server uiteindelijk alleen maar doden tijdens het genereren van het uitvoeringsplan, zoals hierboven besproken.
Het is veel beter om de import-exportwizard te gebruiken om de tabel te laden. Als je het in TSQL moet doen, zul je merken dat het opbreken in kleinere batches en/of het gebruik van een andere methode, zoals het vernietigen van XML, beter zal presteren dan Table Valued Constructors. Het volgende wordt bijvoorbeeld in 13 seconden op mijn computer uitgevoerd (hoewel als u SSMS gebruikt, u waarschijnlijk nog steeds in meerdere batches moet opsplitsen in plaats van een enorme XML-tekenreeks letterlijk te plakken).
DECLARE @S NVARCHAR(MAX) = '<x proj_d="100" period_sid="200" val="300" />
' ;
DECLARE @Xml XML = REPLICATE(@S,1000000);
SELECT
x.value('@proj_d','int'),
x.value('@period_sid','int'),
x.value('@val','int')
FROM @Xml.nodes('/x') c(x)