Jarenlang was MySQL-replicatie gebaseerd op binaire loggebeurtenissen - het enige dat een slaaf wist, was de exacte gebeurtenis en de exacte positie die hij zojuist van de master had gelezen. Elke enkele transactie van een master kan zijn geëindigd in verschillende binaire logs en op verschillende posities in deze logs. Het was een eenvoudige oplossing met beperkingen - voor complexere topologiewijzigingen kan het nodig zijn dat een beheerder de replicatie op de betrokken hosts stopt. Of deze wijzigingen kunnen andere problemen veroorzaken, bijv. een slaaf kan niet door de replicatieketen worden verplaatst zonder een tijdrovend herbouwproces (we konden de replicatie niet gemakkelijk wijzigen van A -> B -> C in A -> C -> B zonder de replicatie op zowel B als C te stoppen). We hebben allemaal deze beperkingen moeten omzeilen terwijl we droomden van een wereldwijde transactie-ID.
GTID werd samen met MySQL 5.6 geïntroduceerd en bracht enkele grote veranderingen met zich mee in de manier waarop MySQL werkt. Allereerst heeft elke transactie een unieke identifier die deze op elke server op dezelfde manier identificeert. Het is niet meer belangrijk in welke binaire logpositie een transactie is vastgelegd, u hoeft alleen maar de GTID te weten:'966073f3-b6a4-11e4-af2c-08007880ca6:4'. GTID is opgebouwd uit twee delen:de unieke identificatie van een server waar een transactie voor het eerst is uitgevoerd, en een volgnummer. In het bovenstaande voorbeeld kunnen we zien dat de transactie is uitgevoerd door de server met server_uuid van '966073f3-b6a4-11e4-af2c-080027880ca6' en dat de 4e transactie daar is uitgevoerd. Deze informatie is voldoende om complexe topologiewijzigingen uit te voeren - MySQL weet welke transacties zijn uitgevoerd en weet daarom welke transacties vervolgens moeten worden uitgevoerd. Vergeet binaire logs, het zit allemaal in de GTID.
Dus, waar vind je GTID's? Je vindt ze op twee plaatsen. Op een slave vind je in ‘show slave status;’ twee kolommen:Retrieved_Gtid_Set en Executed_Gtid_Set. De eerste behandelt GTID's die via replicatie van de master zijn opgehaald, de tweede informeert over alle transacties die op een bepaalde host zijn uitgevoerd - zowel via replicatie als lokaal uitgevoerd.
Eenvoudig een replicatiecluster opzetten
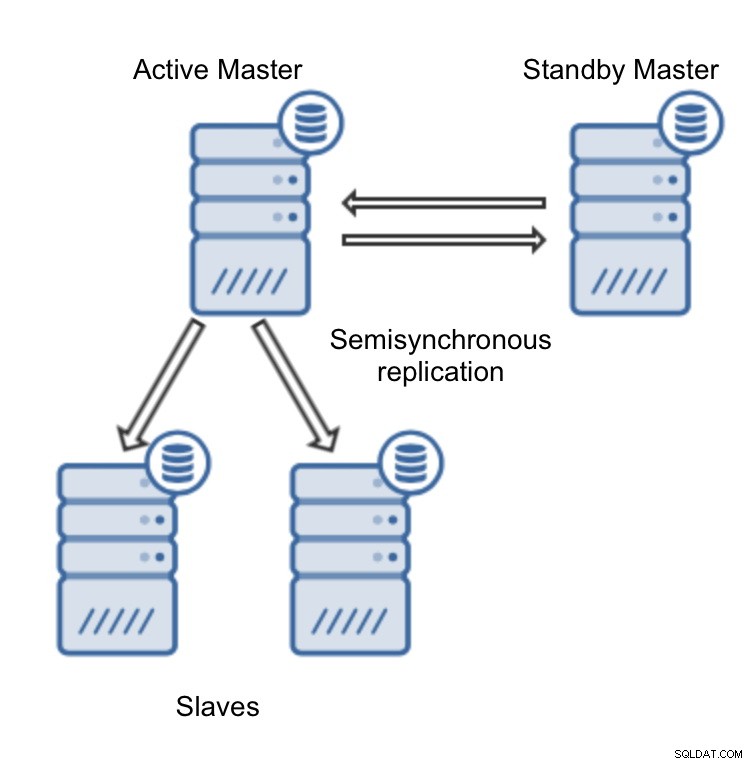
Implementatie van MySQL-replicatiecluster is heel eenvoudig in ClusterControl (u kunt het gratis proberen). De enige vereiste is dat alle hosts, die u zult gebruiken om MySQL-knooppunten te implementeren, toegankelijk zijn vanaf de ClusterControl-instantie met behulp van een wachtwoordloze SSH-verbinding.
Wanneer de connectiviteit aanwezig is, kunt u een cluster implementeren met behulp van de optie "Deploy". Wanneer het wizardvenster is geopend, moet u een aantal beslissingen nemen - wat wilt u doen? Een nieuw cluster implementeren? Implementeer een Postgresql-knooppunt of importeer een bestaand cluster.
We willen een nieuw cluster inzetten. We krijgen dan het volgende scherm te zien waarin we moeten beslissen welk type cluster we willen inzetten. Laten we replicatie kiezen en vervolgens de vereiste details over ssh-connectiviteit doorgeven.
Als u klaar bent, klikt u op Doorgaan. Deze keer moeten we beslissen welke MySQL-leverancier we willen gebruiken, welke versie en een aantal configuratie-instellingen, waaronder, onder andere, het wachtwoord voor het root-account in MySQL.
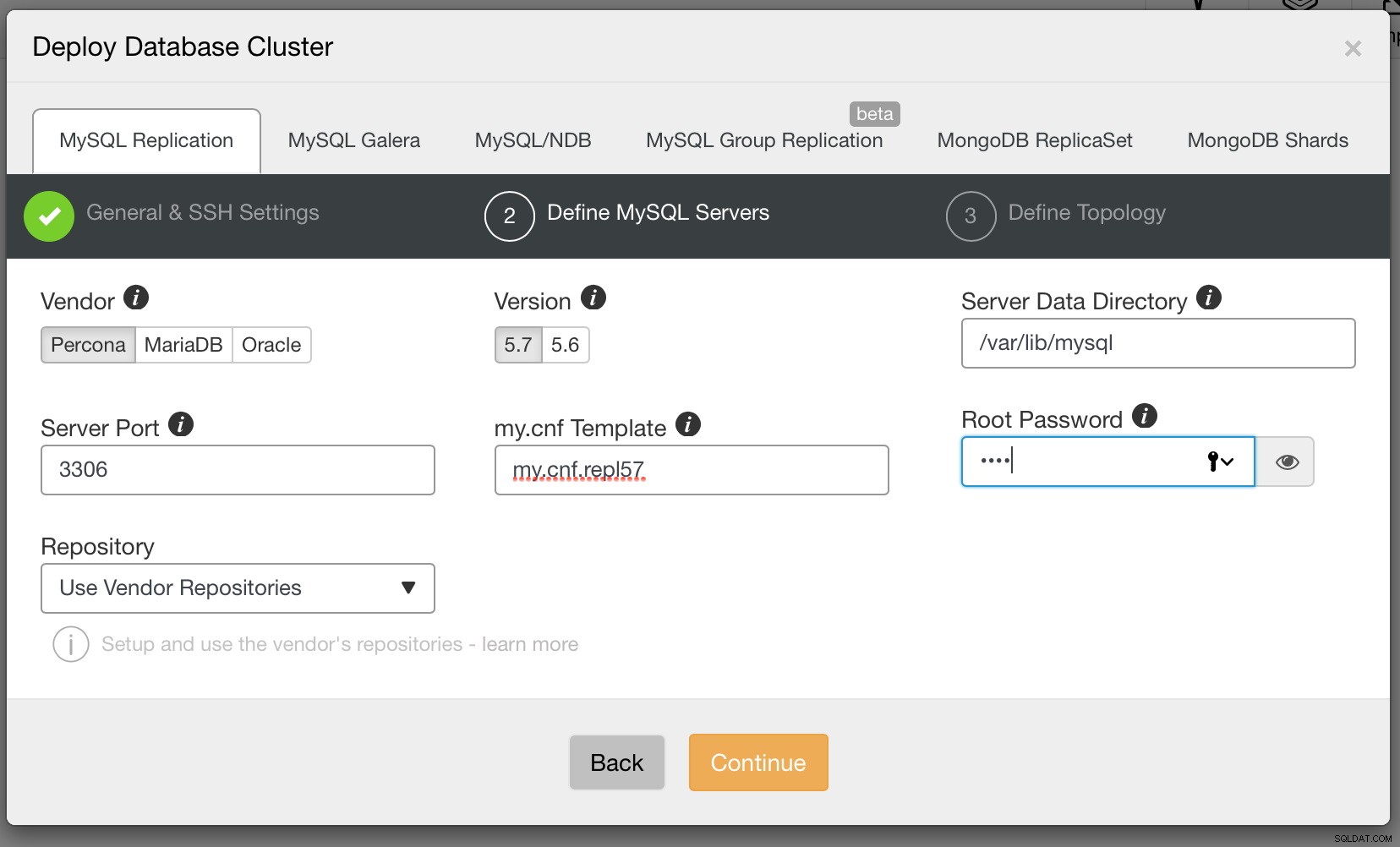
Ten slotte moeten we beslissen over de replicatietopologie - u kunt een typische master-slave-configuratie gebruiken of een meer complex, actief - standby-master-masterpaar maken (+ slaves als u ze wilt toevoegen). Als u klaar bent, klikt u gewoon op "Deploy" en binnen een paar minuten zou uw cluster moeten zijn geïmplementeerd.
Zodra dit is gebeurd, ziet u uw cluster in de clusterlijst van de gebruikersinterface van ClusterControl.
Nu de replicatie actief is, kunnen we nader bekijken hoe GTID werkt.
Foutieve transacties - wat is het probleem?
Zoals we aan het begin van dit bericht vermeldden, brachten GTID's een belangrijke verandering teweeg in de manier waarop mensen over MySQL-replicatie zouden moeten denken. Het draait allemaal om gewoonten. Laten we zeggen, om de een of andere reden, dat een toepassing een schrijfactie op een van de slaven heeft uitgevoerd. Het had niet mogen gebeuren, maar verrassend genoeg gebeurt het de hele tijd. Als gevolg hiervan stopt de replicatie met een dubbele sleutelfout. Er zijn een aantal manieren om met een dergelijk probleem om te gaan. Een daarvan zou zijn om de overtredende rij te verwijderen en de replicatie opnieuw te starten. Een andere mogelijkheid is om de binaire loggebeurtenis over te slaan en vervolgens de replicatie opnieuw te starten.
STOP SLAVE SQL_THREAD; SET GLOBAL sql_slave_skip_counter = 1; START SLAVE SQL_THREAD;Beide manieren zouden replicatie weer aan het werk moeten brengen, maar ze kunnen data-drift introduceren, dus het is noodzakelijk om te onthouden dat slave-consistentie moet worden gecontroleerd na een dergelijke gebeurtenis (pt-table-checksum en pt-table-sync werken hier goed).
Als een soortgelijk probleem optreedt tijdens het gebruik van GTID, zult u enkele verschillen opmerken. Het lijkt erop dat het probleem is opgelost door de aanstootgevende rij te verwijderen, de replicatie zou moeten kunnen beginnen. De andere methode, met behulp van sql_slave_skip_counter, zal helemaal niet werken - er wordt een fout geretourneerd. Onthoud dat het nu niet meer gaat om binlog-gebeurtenissen, het gaat er allemaal om of GTID wordt uitgevoerd of niet.
Waarom het verwijderen van de rij alleen 'lijkt' om het probleem op te lossen? Een van de belangrijkste dingen om in gedachten te houden met betrekking tot GTID is dat een slave, wanneer hij verbinding maakt met de master, controleert of er transacties ontbreken die op de master zijn uitgevoerd. Dit worden foutieve transacties genoemd. Als een slaaf dergelijke transacties vindt, zal hij ze uitvoeren. Laten we aannemen dat we de volgende SQL hebben uitgevoerd om een beledigende rij te wissen:
DELETE FROM mytable WHERE id=100;Laten we eens kijken hoe slaafstatus wordt weergegeven:
Master_UUID: 966073f3-b6a4-11e4-af2c-080027880ca6
Retrieved_Gtid_Set: 966073f3-b6a4-11e4-af2c-080027880ca6:1-29
Executed_Gtid_Set: 84d15910-b6a4-11e4-af2c-080027880ca6:1,
966073f3-b6a4-11e4-af2c-080027880ca6:1-29,En kijk waar de 84d15910-b6a4-11e4-af2c-080027880ca6:1 vandaan komt:
mysql> SHOW VARIABLES LIKE 'server_uuid'\G
*************************** 1. row ***************************
Variable_name: server_uuid
Value: 84d15910-b6a4-11e4-af2c-080027880ca6
1 row in set (0.00 sec)Zoals u kunt zien, hebben we 29 transacties die afkomstig zijn van de master, UUID van 966073f3-b6a4-11e4-af2c-080027880ca6 en één die lokaal is uitgevoerd. Laten we zeggen dat we op een gegeven moment een failover doen en de master (966073f3-b6a4-11e4-af2c-080027880ca6) een slave wordt. Het zal de lijst met uitgevoerde GTID's controleren en deze niet vinden:84d15910-b6a4-11e4-af2c-080027880ca6:1. Als resultaat wordt de gerelateerde SQL uitgevoerd:
DELETE FROM mytable WHERE id=100;Dit hadden we niet verwacht... Als in de tussentijd de binlog met deze transactie zou worden gewist op de oude slave, dan zal de nieuwe slave klagen na een failover:
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.'Hoe foutieve transacties detecteren?
MySQL biedt twee functies die erg handig zijn als je GTID-sets op verschillende hosts wilt vergelijken.
GTID_SUBSET() neemt twee GTID-sets en controleert of de eerste set een subset is van de tweede.
Laten we zeggen dat we de volgende status hebben.
Meester:
mysql> show master status\G
*************************** 1. row ***************************
File: binlog.000002
Position: 160205927
Binlog_Do_DB:
Binlog_Ignore_DB:
Executed_Gtid_Set: 8a6962d2-b907-11e4-bebc-080027880ca6:1-153,
9b09b44a-b907-11e4-bebd-080027880ca6:1,
ab8f5793-b907-11e4-bebd-080027880ca6:1-2
1 row in set (0.00 sec)Slaaf:
mysql> show slave status\G
[...]
Retrieved_Gtid_Set: 8a6962d2-b907-11e4-bebc-080027880ca6:1-153,
9b09b44a-b907-11e4-bebd-080027880ca6:1
Executed_Gtid_Set: 8a6962d2-b907-11e4-bebc-080027880ca6:1-153,
9b09b44a-b907-11e4-bebd-080027880ca6:1,
ab8f5793-b907-11e4-bebd-080027880ca6:1-4We kunnen controleren of de slaaf foutieve transacties heeft door de volgende SQL uit te voeren:
mysql> SELECT GTID_SUBSET('8a6962d2-b907-11e4-bebc-080027880ca6:1-153,ab8f5793-b907-11e4-bebd-080027880ca6:1-4', '8a6962d2-b907-11e4-bebc-080027880ca6:1-153, 9b09b44a-b907-11e4-bebd-080027880ca6:1, ab8f5793-b907-11e4-bebd-080027880ca6:1-2') as is_subset\G
*************************** 1. row ***************************
is_subset: 0
1 row in set (0.00 sec)Het lijkt erop dat er foutieve transacties zijn. Hoe identificeren we ze? We kunnen een andere functie gebruiken, GTID_SUBTRACT()
mysql> SELECT GTID_SUBTRACT('8a6962d2-b907-11e4-bebc-080027880ca6:1-153,ab8f5793-b907-11e4-bebd-080027880ca6:1-4', '8a6962d2-b907-11e4-bebc-080027880ca6:1-153, 9b09b44a-b907-11e4-bebd-080027880ca6:1, ab8f5793-b907-11e4-bebd-080027880ca6:1-2') as mising\G
*************************** 1. row ***************************
mising: ab8f5793-b907-11e4-bebd-080027880ca6:3-4
1 row in set (0.01 sec)Onze ontbrekende GTID's zijn ab8f5793-b907-11e4-bebd-080027880ca6:3-4 - die transacties zijn uitgevoerd op de slave maar niet op de master.
Hoe los je problemen op die worden veroorzaakt door foutieve transacties?
Er zijn twee manieren:lege transacties injecteren of transacties uitsluiten van de GTID-geschiedenis.
Om lege transacties te injecteren kunnen we de volgende SQL gebruiken:
mysql> SET gtid_next='ab8f5793-b907-11e4-bebd-080027880ca6:3';
Query OK, 0 rows affected (0.01 sec)mysql> begin ; commit;
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.01 sec)mysql> SET gtid_next='ab8f5793-b907-11e4-bebd-080027880ca6:4';
Query OK, 0 rows affected (0.00 sec)mysql> begin ; commit;
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.01 sec)mysql> SET gtid_next=automatic;
Query OK, 0 rows affected (0.00 sec)Dit moet worden uitgevoerd op elke host in de replicatietopologie waarop deze GTID's niet zijn uitgevoerd. Als de master beschikbaar is, kunt u die transacties daar injecteren en ze in de keten laten repliceren. Als de master niet beschikbaar is (deze is bijvoorbeeld gecrasht), moeten die lege transacties op elke slave worden uitgevoerd. Oracle heeft een tool ontwikkeld met de naam mysqlslavetrx die is ontworpen om dit proces te automatiseren.
Een andere benadering is om de GTID's uit de geschiedenis te verwijderen:
Slaaf stoppen:
mysql> STOP SLAVE;Print Executed_Gtid_Set op de slave:
mysql> SHOW MASTER STATUS\GGTID-info resetten:
RESET MASTER;Stel GTID_PURGED in op een juiste GTID-set. gebaseerd op gegevens van SHOW MASTER STATUS. U moet foutieve transacties uitsluiten van de set.
SET GLOBAL GTID_PURGED='8a6962d2-b907-11e4-bebc-080027880ca6:1-153, 9b09b44a-b907-11e4-bebd-080027880ca6:1, ab8f5793-b907-11e4-bebd-080027880ca6:1-2';Slaaf starten.
mysql> START SLAVE\GIn elk geval moet u de consistentie van uw slaves verifiëren met behulp van pt-table-checksum en pt-table-sync (indien nodig) - een foutieve transactie kan leiden tot een data-drift.
Failover in ClusterControl
Vanaf versie 1.4 heeft ClusterControl zijn failover-verwerkingsprocessen voor MySQL-replicatie verbeterd. Je kunt nog steeds een handmatige masterswitch uitvoeren door een van de slaves tot master te promoveren. De rest van de slaves zal dan overgaan naar de nieuwe master. Vanaf versie 1.4 heeft ClusterControl ook de mogelijkheid om een volledig geautomatiseerde failover uit te voeren als de master uitvalt. We hebben het uitgebreid besproken in een blogpost waarin ClusterControl en geautomatiseerde failover worden beschreven. We willen nog één functie noemen, die rechtstreeks verband houdt met het onderwerp van dit bericht.
Standaard voert ClusterControl failover uit op een "veilige manier" - op het moment van failover (of omschakeling, als het de gebruiker is die een masterswitch heeft uitgevoerd), kiest ClusterControl een masterkandidaat en controleert vervolgens of dit knooppunt geen foutieve transacties heeft wat van invloed zou zijn op replicatie zodra het is gepromoveerd tot master. Als een foutieve transactie wordt gedetecteerd, stopt ClusterControl het failoverproces en wordt de masterkandidaat niet gepromoveerd tot een nieuwe master.
Als u er 100% zeker van wilt zijn dat ClusterControl een nieuwe master zal promoten, zelfs als er problemen (zoals foutieve transacties) worden gedetecteerd, kunt u dat doen met de instelling replication_stop_on_error=0 in de cmon-configuratie. Zoals we hebben besproken, kan dit natuurlijk leiden tot problemen met replicatie - slaven kunnen gaan vragen om een binaire loggebeurtenis die niet meer beschikbaar is.
Om dergelijke gevallen aan te pakken, hebben we experimentele ondersteuning toegevoegd voor het herbouwen van slaven. Als u replication_auto_rebuild_slave=1 in de cmon-configuratie instelt en uw slave is gemarkeerd als down met de volgende fout in MySQL, zal ClusterControl proberen de slave opnieuw op te bouwen met behulp van gegevens van de master:
Kreeg fatale fout 1236 van master bij het lezen van gegevens uit binair logboek:'De slave maakt verbinding via CHANGE MASTER TO MASTER_AUTO_POSITION =1, maar de master heeft binaire logboeken gewist met GTID's die de slave nodig heeft.'
Een dergelijke instelling is misschien niet altijd geschikt, aangezien het reconstructieproces de master zwaarder zal belasten. Het kan ook zijn dat uw dataset erg groot is en regelmatig opnieuw opbouwen geen optie is - daarom is dit gedrag standaard uitgeschakeld.