In mijn laatste bericht ("Dude, wie is de eigenaar van die #temp-tabel?"), stelde ik voor dat je in SQL Server 2012 en hoger Extended Events zou kunnen gebruiken om het maken van #temp-tabellen te controleren. Dit zou je in staat stellen om specifieke objecten die veel ruimte innemen in tempdb te correleren met de sessie waarin ze zijn gemaakt (bijvoorbeeld om te bepalen of de sessie kan worden afgebroken om te proberen de ruimte vrij te maken). Wat ik niet heb besproken, is de overhead van deze tracking - we verwachten dat Extended Events lichter zijn dan traceren, maar geen enkele monitoring is volledig gratis.
Aangezien de meeste mensen de standaardtracering ingeschakeld laten, laten we die op zijn plaats. We zullen beide hopen testen met SELECT INTO (die de standaardtracering niet verzamelt) en geclusterde indexen (wat het wel zal doen), en we timen de batch op zichzelf als een basislijn, en voeren de batch vervolgens opnieuw uit terwijl de Extended Events-sessie actief is. We zullen ook testen tegen zowel SQL Server 2012 als SQL Server 2014. De batch zelf is vrij eenvoudig:
STEL NOCOUNT IN; SELECT SYSDATETIME();GO -- voer dit gedeelte uit voor alleen de heap batch:SELECT TOP (100) [object_id] INTO #foo FROM sys.all_objects ORDER BY [object_id];DROP TABLE #foo; -- voer dit gedeelte alleen uit voor de CIX-batch:CREATE TABLE #bar(id INT PRIMARY KEY);INSERT #bar(id) SELECT TOP (100) [object_id] FROM sys.all_objects ORDER BY [object_id];DROP TABLE #bar; GA 100000 SELECTEER SYSDATETIME();
Beide instanties hebben tempdb geconfigureerd met vier gegevensbestanden en met TF 1117 en TF 1118 ingeschakeld, in een VM met vier CPU's, 16 GB geheugen en alleen SSD. Ik heb opzettelijk kleine #temp-tabellen gemaakt om de waargenomen impact op de batch zelf te vergroten (die zou worden overstemd als het maken van de #temp-tabellen lang zou duren of overmatige autogrowth-gebeurtenissen zou veroorzaken).
Ik heb deze batches in elk scenario uitgevoerd en hier waren de resultaten, gemeten in batchduur in seconden:
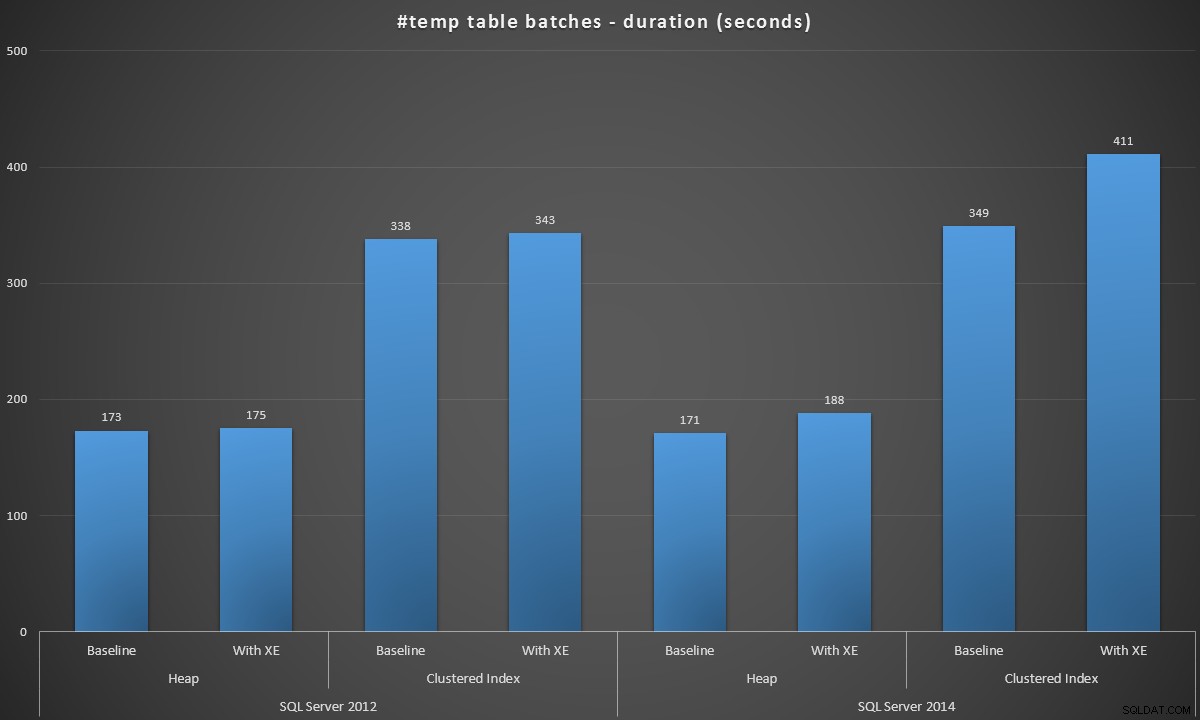
Batchduur, in seconden, voor het maken van 100.000 #temp-tabellen
Als we de gegevens een beetje anders uitdrukken, kunnen we, als we 100.000 delen door de duur, het aantal #temp-tabellen laten zien dat we per seconde in elk scenario kunnen maken (lees:doorvoer). Dit zijn de resultaten:
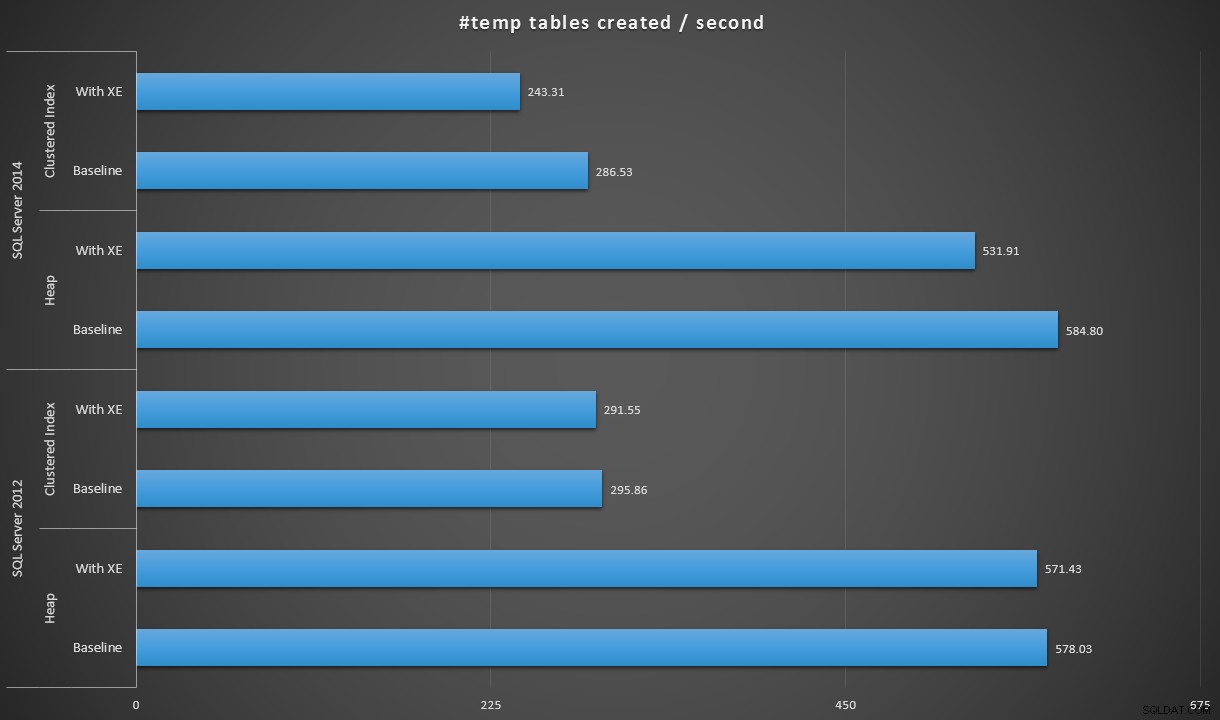
#temp-tabellen per seconde gemaakt onder elk scenario
De resultaten waren een beetje verrassend voor mij - ik verwachtte dat, met de verbeteringen van SQL Server 2014 in de gretige schrijflogica, de heap-populatie op zijn minst een stuk sneller zou werken. De hoop in 2014 was twee miezerige seconden sneller dan 2012 bij de basisconfiguratie, maar Extended Events zorgden voor een behoorlijke stijging van de tijd (ongeveer een stijging van 10% ten opzichte van de basislijn); terwijl de geclusterde indextijd vergelijkbaar was met 2012 bij de basislijn, maar met bijna 18% steeg met Extended Events ingeschakeld. In 2012 waren de delta's voor heaps en geclusterde indexen veel bescheidener:respectievelijk 1,1% en 1,5%. (En voor alle duidelijkheid, er hebben zich tijdens de tests geen autogrow-gebeurtenissen voorgedaan.)
Dus, dacht ik, wat als ik een slankere, gemenere Extended Events-sessie zou maken? Ik zou zeker enkele van die actiekolommen kunnen verwijderen - misschien heb ik alleen inlognaam en spid nodig en kan ik de app-naam, hostnaam en mogelijk dure sql_text negeren. Misschien zou ik het extra filter tegen de commit kunnen laten vallen (twee keer zoveel gebeurtenissen verzamelen, maar minder CPU besteden aan filteren) en meervoudig verlies van gebeurtenissen toestaan om de potentiële impact op de werklast te verminderen. Deze slankere sessie ziet er als volgt uit:
CREATE EVENT SESSION [TempTableCreation2014_LeanerMeaner] OP SERVER EVENEMENT TOEVOEGEN sqlserver.object_created( ACTIE ( sqlserver.server_principal_name, sqlserver.session_id ) WHERE ( sqlserver.like_i_sql_unicode_name_string) ( SET FILENAME ='c:\temp\TempTableCreation2014_LeanerMeaner.xel', MAX_FILE_SIZE =32768, MAX_ROLLOVER_FILES =10)MET ( EVENT_RETENTION_MODE =ALLOW_MULTIPLE_EVENT_LOSS);GOALTER EVENT-SESSIEHelaas, nee, zelfde resultaten. Iets meer dan drie minuten voor de heap en iets minder dan zeven minuten voor de geclusterde index. Om dieper te graven in waar de extra tijd werd besteed, heb ik de instantie van 2014 met SQL Sentry bekeken en heb ik alleen de geclusterde indexbatch uitgevoerd zonder dat er Extended Events-sessies waren geconfigureerd. Daarna heb ik de batch opnieuw uitgevoerd, dit keer met de lichtere XE-sessie geconfigureerd. De batchtijden waren 5:47 (347 seconden) en 6:55 (415 seconden) - dus heel erg in lijn met de vorige batch (ik was blij om te zien dat onze monitoring niet verder bijdroeg aan de duur :-)) . Ik heb gevalideerd dat er geen gebeurtenissen zijn verwijderd en nogmaals dat er geen autogrow-gebeurtenissen hebben plaatsgevonden.
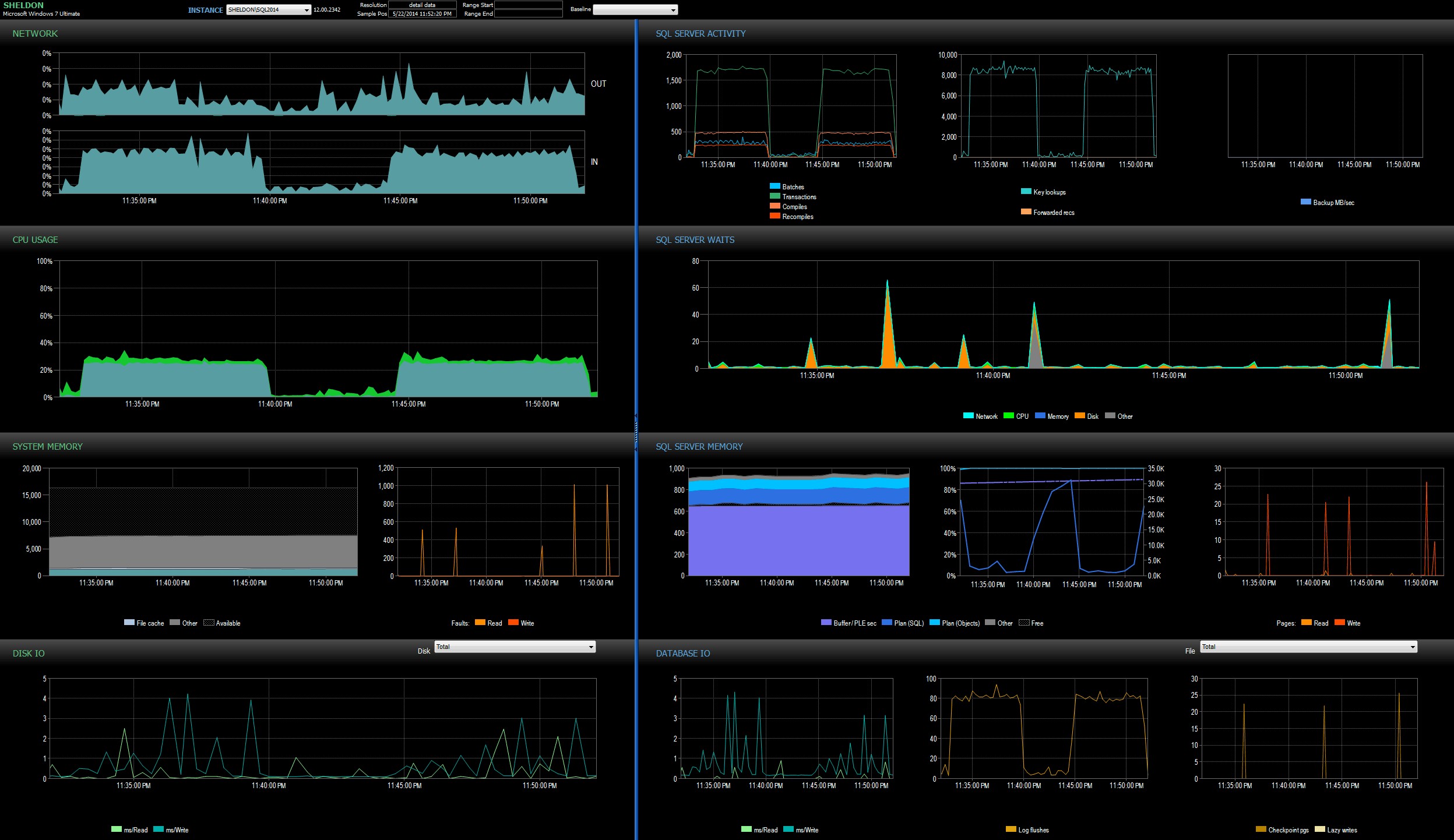
Ik keek naar het SQL Sentry-dashboard in de geschiedenismodus, waardoor ik snel de prestatiestatistieken van beide batches naast elkaar kon bekijken:
SQL Sentry-dashboard, in geschiedenismodus, met beide batchesBeide batches waren vrijwel identiek in termen van netwerk, CPU, transacties, compiles, key-lookups, enz. Er is een klein verschil in de wachttijden - de pieken tijdens de eerste batch waren uitsluitend WRITELOG, terwijl er enkele kleine CXPACKET-wachttijden werden gevonden in de tweede portie. Mijn werktheorie ruim na middernacht is dat misschien een groot deel van de waargenomen vertraging te wijten was aan het wisselen van context veroorzaakt door het Extended Events-proces. Aangezien we geen zicht hebben op wat XE precies onder de dekens doet, en we ook niet weten welke onderliggende mechanica tussen 2012 en 2014 in XE is veranderd, is dat het verhaal waar ik me voorlopig aan houd, totdat ik comfortabeler met xperf en/of WinDbg.
Conclusie
Het is in ieder geval duidelijk dat het bijhouden van #temp-tabellen niet gratis is en dat de kosten kunnen variëren, afhankelijk van het type #temp-tabellen dat u maakt, de hoeveelheid informatie die u verzamelt in uw XE-sessies en zelfs de versie van SQL Server die u gebruikt. U kunt dus soortgelijke tests uitvoeren als wat ik hier heb gedaan, en beslissen hoe waardevol het is om deze informatie in uw omgeving te verzamelen.