Replicatie is een van de meest voorkomende manieren om hoge beschikbaarheid voor MySQL en MariaDB te bereiken. Het is veel robuuster geworden met de toevoeging van GTID's en is grondig getest door duizenden en duizenden gebruikers. MySQL-replicatie is echter geen 'set and forget'-eigenschap, het moet worden gecontroleerd op mogelijke problemen en onderhouden, zodat het in goede staat blijft. In deze blogpost willen we enkele tips en trucs delen voor het onderhouden, oplossen en oplossen van problemen met MySQL-replicatie.
Hoe te bepalen of MySQL-replicatie in goede staat verkeert?
Dit is zonder twijfel de belangrijkste vaardigheid die iedereen die voor een MySQL-replicatie-installatie zorgt, moet bezitten. Laten we eens kijken waar we informatie moeten zoeken over de replicatiestatus. Er is een klein verschil tussen MySQL en MariaDB en we zullen dit ook bespreken.
TOEN SLAVESTATUS
Dit is zonder twijfel de meest gebruikelijke methode om de replicatiestatus op een slave-host te controleren - het is altijd bij ons en het is meestal de eerste plaats waar we heen gaan als we verwachten dat er een probleem is met de replicatie.
mysql> SHOW SLAVE STATUS\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.0.0.101
Master_User: rpl_user
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000002
Read_Master_Log_Pos: 767658564
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 405
Relay_Master_Log_File: binlog.000002
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 767658564
Relay_Log_Space: 606
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
Master_UUID: 5d1e2227-07c6-11e7-8123-080027495a77
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1-394233
Auto_Position: 1
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:
1 row in set (0.00 sec)Sommige details kunnen verschillen tussen MySQL en MariaDB, maar het grootste deel van de inhoud zal er hetzelfde uitzien. Wijzigingen zijn zichtbaar in de GTID-sectie omdat MySQL en MariaDB het op een andere manier doen. Uit SHOW SLAVE STATUS kun je wat informatie afleiden - welke master wordt gebruikt, welke gebruiker en welke poort wordt gebruikt om verbinding te maken met de master. We hebben wat gegevens over de huidige binaire logpositie (niet zo belangrijk meer omdat we GTID kunnen gebruiken en binlogs kunnen vergeten) en de status van SQL- en I/O-replicatiethreads. Vervolgens kunt u zien of en hoe filtering is geconfigureerd. U kunt ook wat informatie vinden over fouten, replicatievertraging, SSL-instellingen en GTID. Het bovenstaande voorbeeld is afkomstig van MySQL 5.7-slave die zich in een gezonde staat bevindt. Laten we eens kijken naar een voorbeeld waarbij de replicatie wordt verbroken.
MariaDB [test]> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.0.0.104
Master_User: rpl_user
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000003
Read_Master_Log_Pos: 636
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 765
Relay_Master_Log_File: binlog.000003
Slave_IO_Running: Yes
Slave_SQL_Running: No
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 1032
Last_Error: Could not execute Update_rows_v1 event on table test.tab; Can't find record in 'tab', Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND; the event's master log binlog.000003, end_log_pos 609
Skip_Counter: 0
Exec_Master_Log_Pos: 480
Relay_Log_Space: 1213
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: NULL
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 1032
Last_SQL_Error: Could not execute Update_rows_v1 event on table test.tab; Can't find record in 'tab', Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND; the event's master log binlog.000003, end_log_pos 609
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
Master_SSL_Crl:
Master_SSL_Crlpath:
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 0-1-73243
Replicate_Do_Domain_Ids:
Replicate_Ignore_Domain_Ids:
Parallel_Mode: conservative
1 row in set (0.00 sec)Dit voorbeeld is afkomstig uit MariaDB 10.1, u kunt onderaan de uitvoer wijzigingen zien om het te laten werken met MariaDB GTID's. Wat voor ons belangrijk is, is de fout - je kunt zien dat er iets niet klopt in de SQL-thread:
Last_SQL_Error: Could not execute Update_rows_v1 event on table test.tab; Can't find record in 'tab', Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND; the event's master log binlog.000003, end_log_pos 609We zullen dit specifieke probleem later bespreken, voor nu is het voldoende dat u zult zien hoe u kunt controleren of er fouten in de replicatie zitten met SHOW SLAVE STATUS.
Een andere belangrijke informatie die voortkomt uit SHOW SLAVE STATUS is - hoe erg onze slaaf achterblijft. U kunt het controleren in de kolom "Seconds_Behind_Master". Deze statistiek is vooral belangrijk om bij te houden als u weet dat uw app gevoelig is als het gaat om verouderde reads.
In ClusterControl kunt u deze gegevens volgen in het gedeelte "Overzicht":
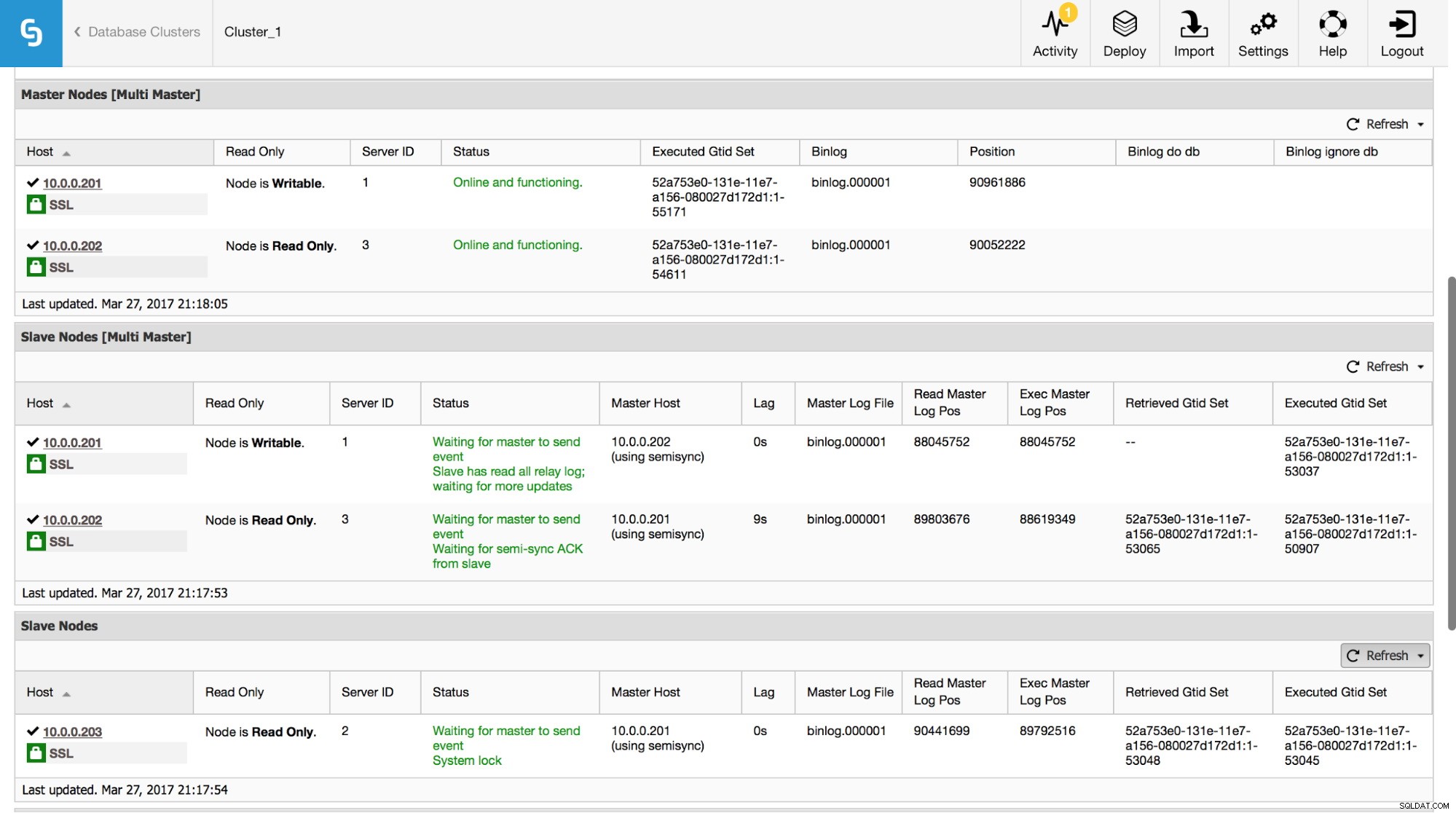
We hebben alle belangrijke stukjes informatie van het SHOW SLAVE STATUS-commando zichtbaar gemaakt. U kunt de status van de replicatie controleren, wie de master is, of er een replicatievertraging is of niet, binaire logposities. U kunt ook opgehaalde en uitgevoerde GTID's vinden.
Prestatieschema
Een andere plaats waar u informatie over replicatie kunt zoeken, is het performance_schema. Dit is alleen van toepassing op Oracle's MySQL 5.7 - eerdere versies en MariaDB verzamelen deze gegevens niet.
mysql> SHOW TABLES FROM performance_schema LIKE 'replication%';
+---------------------------------------------+
| Tables_in_performance_schema (replication%) |
+---------------------------------------------+
| replication_applier_configuration |
| replication_applier_status |
| replication_applier_status_by_coordinator |
| replication_applier_status_by_worker |
| replication_connection_configuration |
| replication_connection_status |
| replication_group_member_stats |
| replication_group_members |
+---------------------------------------------+
8 rows in set (0.00 sec)Hieronder vindt u enkele voorbeelden van gegevens die in sommige van die tabellen beschikbaar zijn.
mysql> select * from replication_connection_status\G
*************************** 1. row ***************************
CHANNEL_NAME:
GROUP_NAME:
SOURCE_UUID: 5d1e2227-07c6-11e7-8123-080027495a77
THREAD_ID: 32
SERVICE_STATE: ON
COUNT_RECEIVED_HEARTBEATS: 1
LAST_HEARTBEAT_TIMESTAMP: 2017-03-17 19:41:34
RECEIVED_TRANSACTION_SET: 5d1e2227-07c6-11e7-8123-080027495a77:715599-724966
LAST_ERROR_NUMBER: 0
LAST_ERROR_MESSAGE:
LAST_ERROR_TIMESTAMP: 0000-00-00 00:00:00
1 row in set (0.00 sec)mysql> select * from replication_applier_status_by_worker\G
*************************** 1. row ***************************
CHANNEL_NAME:
WORKER_ID: 0
THREAD_ID: 31
SERVICE_STATE: ON
LAST_SEEN_TRANSACTION: 5d1e2227-07c6-11e7-8123-080027495a77:726086
LAST_ERROR_NUMBER: 0
LAST_ERROR_MESSAGE:
LAST_ERROR_TIMESTAMP: 0000-00-00 00:00:00
1 row in set (0.00 sec)Zoals u kunt zien, kunnen we de staat van de replicatie, de laatste fout, de ontvangen transactieset en wat meer gegevens verifiëren. Wat belangrijk is - als u multi-threaded replicatie hebt ingeschakeld, ziet u in de tabel replication_applier_status_by_worker de status van elke afzonderlijke worker - dit helpt u de replicatiestatus voor elk van de worker-threads te begrijpen.
Replicatievertraging
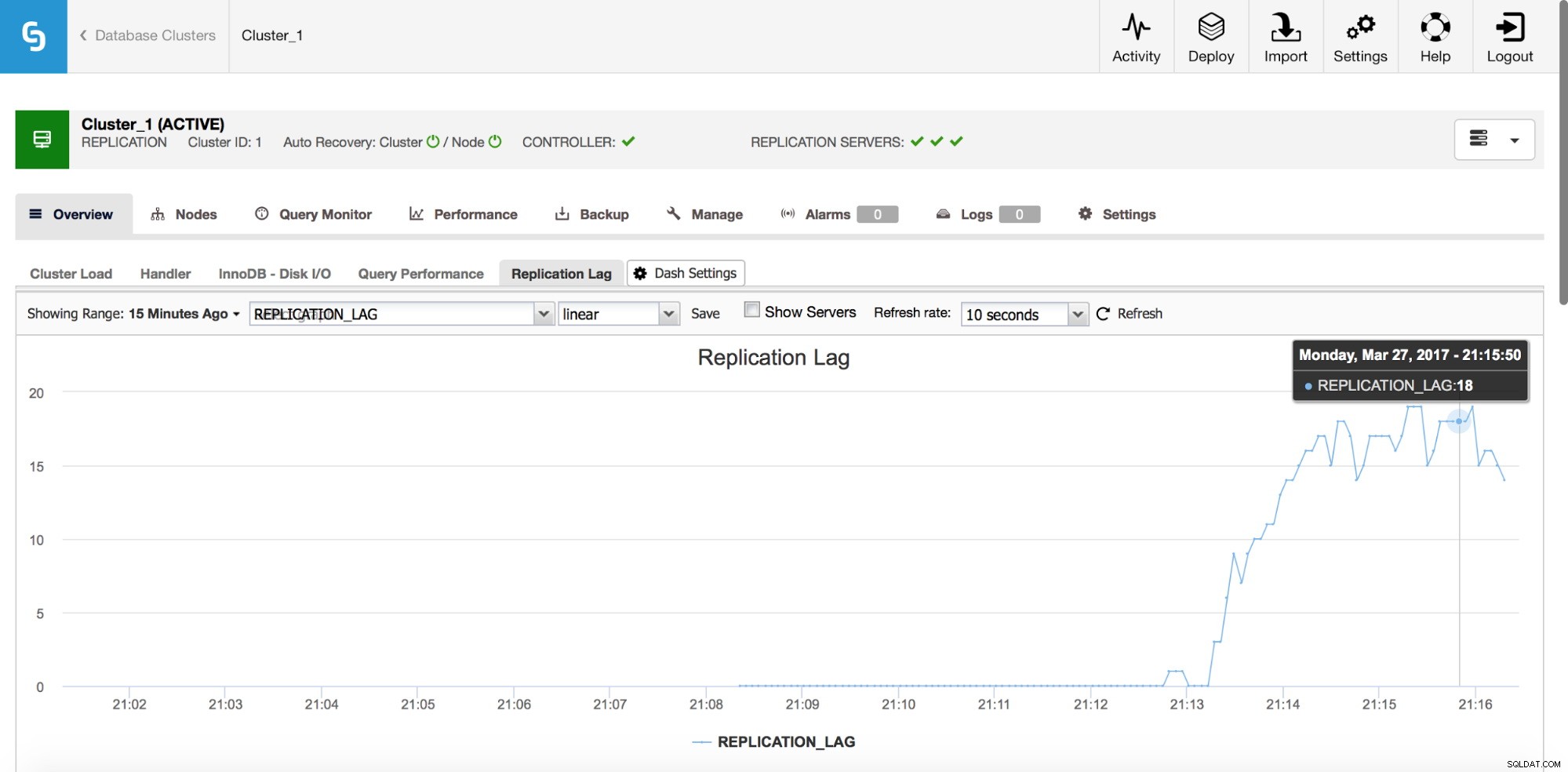
Lag is zeker een van de meest voorkomende problemen waarmee u te maken krijgt bij het werken met MySQL-replicatie. Replicatievertraging treedt op wanneer een van de slaven de hoeveelheid schrijfbewerkingen die door de master worden uitgevoerd niet kan bijhouden. Redenen kunnen verschillen - verschillende hardwareconfiguratie, zwaardere belasting van de slave, hoge mate van parallellisatie bij het schrijven op de master die moet worden geserialiseerd (wanneer u een enkele thread gebruikt voor de replicatie) of de schrijfbewerkingen kunnen niet in dezelfde mate worden geparalliseerd als het heeft op de master is geweest (wanneer u multi-threaded replicatie gebruikt).
Hoe het te detecteren?
Er zijn een aantal methoden om de replicatievertraging te detecteren. Allereerst kun je "Seconds_Behind_Master" aanvinken in de SHOW SLAVE STATUS output - het zal je vertellen of de slave achterblijft of niet. Het werkt in de meeste gevallen goed, maar in meer complexe topologieën, als je tussenliggende masters gebruikt, op hosts ergens laag in de replicatieketen, is het misschien niet precies. Een andere, betere oplossing is om te vertrouwen op externe tools zoals pt-heartbeat. Het idee is simpel - er wordt een tabel gemaakt met oa een tijdstempelkolom. Deze kolom wordt regelmatig op de master bijgewerkt. Op een slave kun je dan het tijdstempel van die kolom vergelijken met de huidige tijd - het zal je vertellen hoe ver de slave achterloopt.
Ongeacht de manier waarop u de vertraging berekent, zorg ervoor dat uw hosts in de tijd synchroon lopen. Gebruik ntpd of andere manieren om tijd te synchroniseren - als er een tijdafwijking is, ziet u een "valse" vertraging op uw slaven.
Hoe vertraging verminderen?
Dit is geen gemakkelijke vraag om te beantwoorden. Kortom, het hangt af van wat de vertraging veroorzaakt en wat een knelpunt werd. Er zijn twee typische patronen:slaaf is I/O-gebonden, wat betekent dat zijn I/O-subsysteem de hoeveelheid schrijf- en leesbewerkingen niet aankan. Ten tweede - slave is CPU-gebonden, wat betekent dat de replicatiethread alle mogelijke CPU's gebruikt (één thread kan slechts één CPU-kern gebruiken) en het is nog steeds niet genoeg om alle schrijfbewerkingen af te handelen.
Wanneer de CPU een knelpunt is, kan de oplossing zo simpel zijn als het gebruik van multi-threaded replicatie. Verhoog het aantal werkende threads om een hogere parallellisatie mogelijk te maken. Het is echter niet altijd mogelijk - in dat geval wil je misschien een beetje spelen met groepscommit-variabelen (voor zowel MySQL als MariaDB) om commits een korte tijd uit te stellen (we hebben het hier over milliseconden) en op deze manier , verhoog de parallellisatie van commits.
Als het probleem in de I/O zit, is het probleem wat moeilijker op te lossen. Natuurlijk moet u uw InnoDB I/O-instellingen herzien - misschien is er ruimte voor verbeteringen. Als my.cnf-afstemming niet helpt, heb je niet al te veel opties - verbeter je zoekopdrachten (waar mogelijk) of upgrade je I/O-subsysteem naar iets meer capabels.
De meeste proxy's (bijvoorbeeld alle proxy's die kunnen worden ingezet vanuit ClusterControl:ProxySQL, HAProxy en MaxScale) bieden u de mogelijkheid om een slaaf uit de rotatie te verwijderen als de replicatievertraging een vooraf gedefinieerde drempel overschrijdt. Dit is geenszins een methode om lag te verminderen, maar het kan nuttig zijn om verouderde reads te voorkomen en, als bijwerking, om de belasting van een slave te verminderen, wat hem zou moeten helpen om de achterstand in te halen.
Het afstemmen van zoekopdrachten kan natuurlijk in beide gevallen een oplossing zijn - het is altijd goed om zoekopdrachten te verbeteren die CPU- of I/O-zwaar zijn.
Foutieve transacties
Foutieve transacties zijn transacties die alleen op een slave zijn uitgevoerd, niet op de master. Kortom, ze maken een slaaf inconsistent met de meester. Bij gebruik van op GTID gebaseerde replicatie kan dit ernstige problemen veroorzaken als de slave wordt gepromoveerd tot master. We hebben een diepgaande post over dit onderwerp en we raden u aan er naar te kijken en vertrouwd te raken met het opsporen en oplossen van problemen met foutieve transacties. We hebben ook informatie opgenomen over hoe ClusterControl foutieve transacties detecteert en afhandelt.
Geen Binlog-bestand op de master
Hoe het probleem te identificeren?
Onder bepaalde omstandigheden kan het voorkomen dat een slave verbinding maakt met een master en om een niet-bestaand binair logbestand vraagt. Een reden hiervoor kan de foutieve transactie zijn - op een bepaald moment is er een transactie uitgevoerd op een slave en later wordt deze slave een master. Andere hosts, die zijn geconfigureerd om die master te slaven, zullen om die ontbrekende transactie vragen. Als het lang geleden is uitgevoerd, bestaat de kans dat binaire logbestanden al zijn verwijderd.
Een ander, meer typisch voorbeeld - u wilt een slave inrichten met xtrabackup. U kopieert de back-up op een host, past het logboek toe, wijzigt de eigenaar van de MySQL-gegevensdirectory - typische bewerkingen die u uitvoert om een back-up te herstellen. Jij voert uit
SET GLOBAL gtid_purged=gebaseerd op de gegevens van xtrabackup_binlog_info en je voert CHANGE MASTER TO … MASTER_AUTO_POSITION=1 uit (dit is in MySQL, MariaDB heeft een iets ander proces), start de slave en dan krijg je een foutmelding zoals:
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.'in MySQL of:
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'Could not find GTID state requested by slave in any binlog files. Probably the slave state is too old and required binlog files have been purged.'in MariaDB.
Dit betekent in feite dat de master niet alle binaire logboeken heeft die nodig zijn om alle ontbrekende transacties uit te voeren. Hoogstwaarschijnlijk is de back-up te oud en heeft de master al enkele binaire logboeken gewist die zijn gemaakt tussen het moment waarop de back-up werd gemaakt en het moment waarop de slave werd ingericht.
Hoe dit probleem op te lossen?
Helaas kunt u in dit specifieke geval niet veel doen. Als je MySQL-hosts hebt die binaire logs langer bewaren dan de master, kun je proberen die logs te gebruiken om ontbrekende transacties op de slave opnieuw af te spelen. Laten we eens kijken hoe het kan.
Laten we eerst eens kijken naar de oudste GTID in de binaire logs van de master:
mysql> SHOW BINARY LOGS\G
*************************** 1. row ***************************
Log_name: binlog.000021
File_size: 463
1 row in set (0.00 sec)Dus 'binlog.000021' is het nieuwste (en enige) bestand. Laten we eens kijken wat het eerste GTID-item in dit bestand is:
example@sqldat.com:~# mysqlbinlog /var/lib/mysql/binlog.000021
/*!50530 SET @@SESSION.PSEUDO_SLAVE_MODE=1*/;
/*!50003 SET @example@sqldat.com@COMPLETION_TYPE,COMPLETION_TYPE=0*/;
DELIMITER /*!*/;
# at 4
#170320 10:39:51 server id 1 end_log_pos 123 CRC32 0x5644fc9b Start: binlog v 4, server v 5.7.17-11-log created 170320 10:39:51
# Warning: this binlog is either in use or was not closed properly.
BINLOG '
d7HPWA8BAAAAdwAAAHsAAAABAAQANS43LjE3LTExLWxvZwAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAEzgNAAgAEgAEBAQEEgAAXwAEGggAAAAICAgCAAAACgoKKioAEjQA
AZv8RFY=
'/*!*/;
# at 123
#170320 10:39:51 server id 1 end_log_pos 194 CRC32 0x5c096d62 Previous-GTIDs
# 5d1e2227-07c6-11e7-8123-080027495a77:1-1106668
# at 194
#170320 11:21:26 server id 1 end_log_pos 259 CRC32 0xde21b300 GTID last_committed=0 sequence_number=1
SET @@SESSION.GTID_NEXT= '5d1e2227-07c6-11e7-8123-080027495a77:1106669'/*!*/;
# at 259Zoals we kunnen zien, is de oudste binaire logboekvermelding die beschikbaar is:5d1e2227-07c6-11e7-8123-080027495a77:1106669
We moeten ook controleren wat de laatste GTID is die in de back-up wordt gedekt:
example@sqldat.com:~# cat /var/lib/mysql/xtrabackup_binlog_info
binlog.000017 194 5d1e2227-07c6-11e7-8123-080027495a77:1-1106666
Het is:5d1e2227-07c6-11e7-8123-080027495a77:1-1106666 dus we missen twee gebeurtenissen:
5d1e2227-07c6-11e7-8123-080027495a77:1106667-1106668
Laten we kijken of we die transacties op andere slaven kunnen vinden.
mysql> SHOW BINARY LOGS;
+---------------+------------+
| Log_name | File_size |
+---------------+------------+
| binlog.000001 | 1074130062 |
| binlog.000002 | 764366611 |
| binlog.000003 | 382576490 |
+---------------+------------+
3 rows in set (0.00 sec)Het lijkt erop dat 'binlog.000003' het nieuwste binaire logboek is. We moeten controleren of onze ontbrekende GTID's erin terug te vinden zijn:
slave2:~# mysqlbinlog /var/lib/mysql/binlog.000003 | grep "5d1e2227-07c6-11e7-8123-080027495a77:110666[78]"
SET @@SESSION.GTID_NEXT= '5d1e2227-07c6-11e7-8123-080027495a77:1106667'/*!*/;
SET @@SESSION.GTID_NEXT= '5d1e2227-07c6-11e7-8123-080027495a77:1106668'/*!*/;Houd er rekening mee dat u binlog-bestanden buiten de productieserver wilt kopiëren, omdat het verwerken ervan voor enige belasting kan zorgen. Omdat we hebben geverifieerd dat die GTID's bestaan, kunnen we ze extraheren:
slave2:~# mysqlbinlog --exclude-gtids='5d1e2227-07c6-11e7-8123-080027495a77:1-1106666,5d1e2227-07c6-11e7-8123-080027495a77:1106669' /var/lib/mysql/binlog.000003 > to_apply_on_slave1.sqlNa een snelle scp kunnen we die gebeurtenissen toepassen op de slaaf
slave1:~# mysql -ppass < to_apply_on_slave1.sqlAls we klaar zijn, kunnen we controleren of die GTID's zijn toegepast door te kijken naar de uitvoer van SHOW SLAVE STATUS:
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.'
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
Master_UUID: 5d1e2227-07c6-11e7-8123-080027495a77
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp: 170320 10:45:04
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1-1106668Executed_GTID_set ziet er goed uit, daarom kunnen we slave-threads starten:
mysql> START SLAVE;
Query OK, 0 rows affected (0.00 sec)Laten we eens kijken of het goed werkte. We zullen opnieuw de SHOW SLAVE STATUS-uitvoer gebruiken:
Master_SSL_Crlpath:
Retrieved_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1106669
Executed_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1-1106669Ziet er goed uit, het werkt!
Een andere methode om dit probleem op te lossen is om nog een keer een back-up te maken en de slave opnieuw te voorzien van nieuwe gegevens. Dit zal waarschijnlijk sneller en zeker betrouwbaarder zijn. Het komt niet vaak voor dat u een verschillend beleid voor het opschonen van binlogs hebt voor master en slaves)
We zullen in de volgende blogpost doorgaan met het bespreken van andere soorten replicatieproblemen.