In het vorige bericht hebben we besproken hoe u kunt controleren of MySQL-replicatie in goede staat is. We hebben ook gekeken naar enkele van de typische problemen. In dit bericht zullen we enkele andere problemen bekijken die u mogelijk tegenkomt bij het omgaan met MySQL-replicatie.
Ontbrekende of dubbele invoer
Dit is iets dat niet zou moeten gebeuren, maar het gebeurt heel vaak - een situatie waarin een SQL-instructie die op de master wordt uitgevoerd, slaagt, maar dezelfde instructie die op een van de slaven wordt uitgevoerd, mislukt. De belangrijkste reden is slave-drift - iets (meestal foutieve transacties maar ook andere problemen of bugs in de replicatie) zorgt ervoor dat de slave verschilt van zijn master. Een rij die bijvoorbeeld op de master bestond, bestaat niet op een slave en kan niet worden verwijderd of bijgewerkt. Hoe vaak dit probleem zich voordoet, hangt vooral af van uw replicatie-instellingen. Kortom, er zijn drie manieren waarop MySQL binaire loggebeurtenissen opslaat. Ten eerste betekent "statement", dat SQL in platte tekst is geschreven, net zoals het is uitgevoerd op een master. Deze instelling heeft de hoogste tolerantie voor slave-drift, maar het is ook degene die de consistentie van de slave niet kan garanderen - het is moeilijk aan te bevelen om het in productie te gebruiken. Het tweede formaat, "rij", slaat het queryresultaat op in plaats van de query-instructie. Een evenement kan er bijvoorbeeld als volgt uitzien:
### UPDATE `test`.`tab`
### WHERE
### @1=2
### @2=5
### SET
### @1=2
### @2=4Dit betekent dat we een rij in de 'tab'-tabel in het 'test'-schema bijwerken, waarbij de eerste kolom de waarde 2 heeft en de tweede kolom de waarde 5. We stellen de eerste kolom in op 2 (waarde verandert niet) en de tweede kolom naar 4. Zoals u kunt zien, is er niet veel ruimte voor interpretatie - het is precies gedefinieerd welke rij wordt gebruikt en hoe deze wordt gewijzigd. Als gevolg hiervan is dit formaat geweldig voor slave-consistentie, maar, zoals je je kunt voorstellen, is het erg kwetsbaar als het gaat om gegevensdrift. Toch is het de aanbevolen manier om MySQL-replicatie uit te voeren.
Ten slotte werkt de derde, "gemengd", zodanig dat gebeurtenissen die veilig in de vorm van verklaringen kunnen worden geschreven, de indeling "verklaring" gebruiken. Degenen die gegevensdrift kunnen veroorzaken, gebruiken het "rij" -formaat.
Hoe detecteer je ze?
Zoals gewoonlijk zal SHOW SLAVE STATUS ons helpen het probleem te identificeren.
Last_SQL_Errno: 1032
Last_SQL_Error: Could not execute Update_rows event on table test.tab; Can't find record in 'tab', Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND; the event's master log binlog.000021, end_log_pos 970 Last_SQL_Errno: 1062
Last_SQL_Error: Could not execute Write_rows event on table test.tab; Duplicate entry '3' for key 'PRIMARY', Error_code: 1062; handler error HA_ERR_FOUND_DUPP_KEY; the event's master log binlog.000021, end_log_pos 1229Zoals je kunt zien, zijn fouten duidelijk en spreken ze voor zich (en ze zijn in principe identiek tussen MySQL en MariaDB.
Hoe los je het probleem op?
Dit is helaas het complexe deel. Allereerst moet u een bron van waarheid identificeren. Welke host bevat de juiste gegevens? Meester of slaaf? Meestal ga je ervan uit dat het de master is, maar ga er niet standaard vanuit dat het de master is - ga op onderzoek uit! Het kan zijn dat na een failover een deel van de applicatie nog schrijft naar de oude master, die nu als slave fungeert. Het kan zijn dat read_only niet correct is ingesteld op die host of misschien gebruikt de applicatie superuser om verbinding te maken met de database (ja, we hebben dit gezien in productieomgevingen). In zo'n geval zou de slaaf de bron van de waarheid kunnen zijn - althans tot op zekere hoogte.
Afhankelijk van welke gegevens moeten blijven en welke moeten verdwijnen, is de beste manier om te bepalen wat er nodig is om de replicatie weer gesynchroniseerd te krijgen. Allereerst wordt de replicatie verbroken, dus u moet hier aandacht aan besteden. Log in op de master en controleer het binaire logboek, zelfs als de replicatie brak.
Retrieved_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1106672
Executed_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1-1106671Zoals je ziet missen we één evenement:5d1e2227-07c6-11e7-8123-080027495a77:1106672. Laten we eens kijken in de binaire logs van de master:
mysqlbinlog -v --include-gtids='5d1e2227-07c6-11e7-8123-080027495a77:1106672' /var/lib/mysql/binlog.000021
#170320 20:53:37 server id 1 end_log_pos 1066 CRC32 0xc582a367 GTID last_committed=3 sequence_number=4
SET @@SESSION.GTID_NEXT= '5d1e2227-07c6-11e7-8123-080027495a77:1106672'/*!*/;
# at 1066
#170320 20:53:37 server id 1 end_log_pos 1138 CRC32 0x6f33754d Query thread_id=5285 exec_time=0 error_code=0
SET TIMESTAMP=1490043217/*!*/;
SET @@session.pseudo_thread_id=5285/*!*/;
SET @@session.foreign_key_checks=1, @@session.sql_auto_is_null=0, @@session.unique_checks=1, @@session.autocommit=1/*!*/;
SET @@session.sql_mode=1436549152/*!*/;
SET @@session.auto_increment_increment=1, @@session.auto_increment_offset=1/*!*/;
/*!\C utf8 *//*!*/;
SET @@session.character_set_client=33,@@session.collation_connection=33,@@session.collation_server=8/*!*/;
SET @@session.lc_time_names=0/*!*/;
SET @@session.collation_database=DEFAULT/*!*/;
BEGIN
/*!*/;
# at 1138
#170320 20:53:37 server id 1 end_log_pos 1185 CRC32 0xa00b1f59 Table_map: `test`.`tab` mapped to number 571
# at 1185
#170320 20:53:37 server id 1 end_log_pos 1229 CRC32 0x5597e50a Write_rows: table id 571 flags: STMT_END_F
BINLOG '
UUHQWBMBAAAALwAAAKEEAAAAADsCAAAAAAEABHRlc3QAA3RhYgACAwMAAlkfC6A=
UUHQWB4BAAAALAAAAM0EAAAAADsCAAAAAAEAAgAC//wDAAAABwAAAArll1U=
'/*!*/;
### INSERT INTO `test`.`tab`
### SET
### @1=3
### @2=7
# at 1229
#170320 20:53:37 server id 1 end_log_pos 1260 CRC32 0xbbc3367c Xid = 5224257
COMMIT/*!*/;We kunnen zien dat het een insert was die de eerste kolom op 3 en de tweede op 7 zet. Laten we eens kijken hoe onze tabel er nu uitziet:
mysql> SELECT * FROM test.tab;
+----+------+
| id | b |
+----+------+
| 1 | 2 |
| 2 | 4 |
| 3 | 10 |
+----+------+
3 rows in set (0.01 sec)Nu hebben we twee opties, afhankelijk van welke gegevens prevaleren. Als de juiste gegevens op de master staan, kunnen we eenvoudig de rij met id =3 op de slave verwijderen. Zorg ervoor dat u binaire logboekregistratie uitschakelt om te voorkomen dat u foutieve transacties invoert. Aan de andere kant, als we hebben besloten dat de juiste gegevens op de slave staan, moeten we het REPLACE-commando op de master uitvoeren om rij in te stellen met id =3 om de inhoud van (3, 10) van huidige (3, 7) te corrigeren. Op de slave moeten we de huidige GTID echter overslaan (of, om preciezer te zijn, we zullen een lege GTID-gebeurtenis moeten maken) om de replicatie opnieuw te kunnen starten.
Het verwijderen van een rij op een slaaf is eenvoudig:
SET SESSION log_bin=0; DELETE FROM test.tab WHERE id=3; SET SESSION log_bin=1;Het invoegen van een lege GTID is bijna net zo eenvoudig:
mysql> SET @@SESSION.GTID_NEXT= '5d1e2227-07c6-11e7-8123-080027495a77:1106672';
Query OK, 0 rows affected (0.00 sec)mysql> BEGIN;
Query OK, 0 rows affected (0.00 sec)mysql> COMMIT;
Query OK, 0 rows affected (0.00 sec)mysql> SET @@SESSION.GTID_NEXT=automatic;
Query OK, 0 rows affected (0.00 sec)Een andere methode om dit specifieke probleem op te lossen (zolang we de master als een bron van waarheid accepteren) is om tools zoals pt-table-checksum en pt-table-sync te gebruiken om te identificeren waar de slave niet consistent is met zijn master en wat SQL moet op de master worden uitgevoerd om de slave weer synchroon te laten lopen. Helaas is deze methode nogal aan de zware kant - er wordt veel belasting toegevoegd aan de master en een heleboel vragen worden in de replicatiestroom geschreven, wat van invloed kan zijn op de vertraging van slaves en de algemene prestaties van de replicatie-instellingen. Dit is vooral het geval als er een aanzienlijk aantal rijen is die moeten worden gesynchroniseerd.
Ten slotte kunt u, zoals altijd, uw slave opnieuw opbouwen met behulp van gegevens van de master - op deze manier kunt u er zeker van zijn dat de slave wordt ververst met de nieuwste, up-to-date gegevens. Dit is eigenlijk niet per se een slecht idee - als we het hebben over een groot aantal rijen om te synchroniseren met behulp van pt-table-checksum/pt-table-sync, gaat dit gepaard met aanzienlijke overhead in replicatieprestaties, algehele CPU en I/O belasting en benodigde manuren.
Met ClusterControl kunt u een slave opnieuw opbouwen met een nieuwe kopie van de mastergegevens.
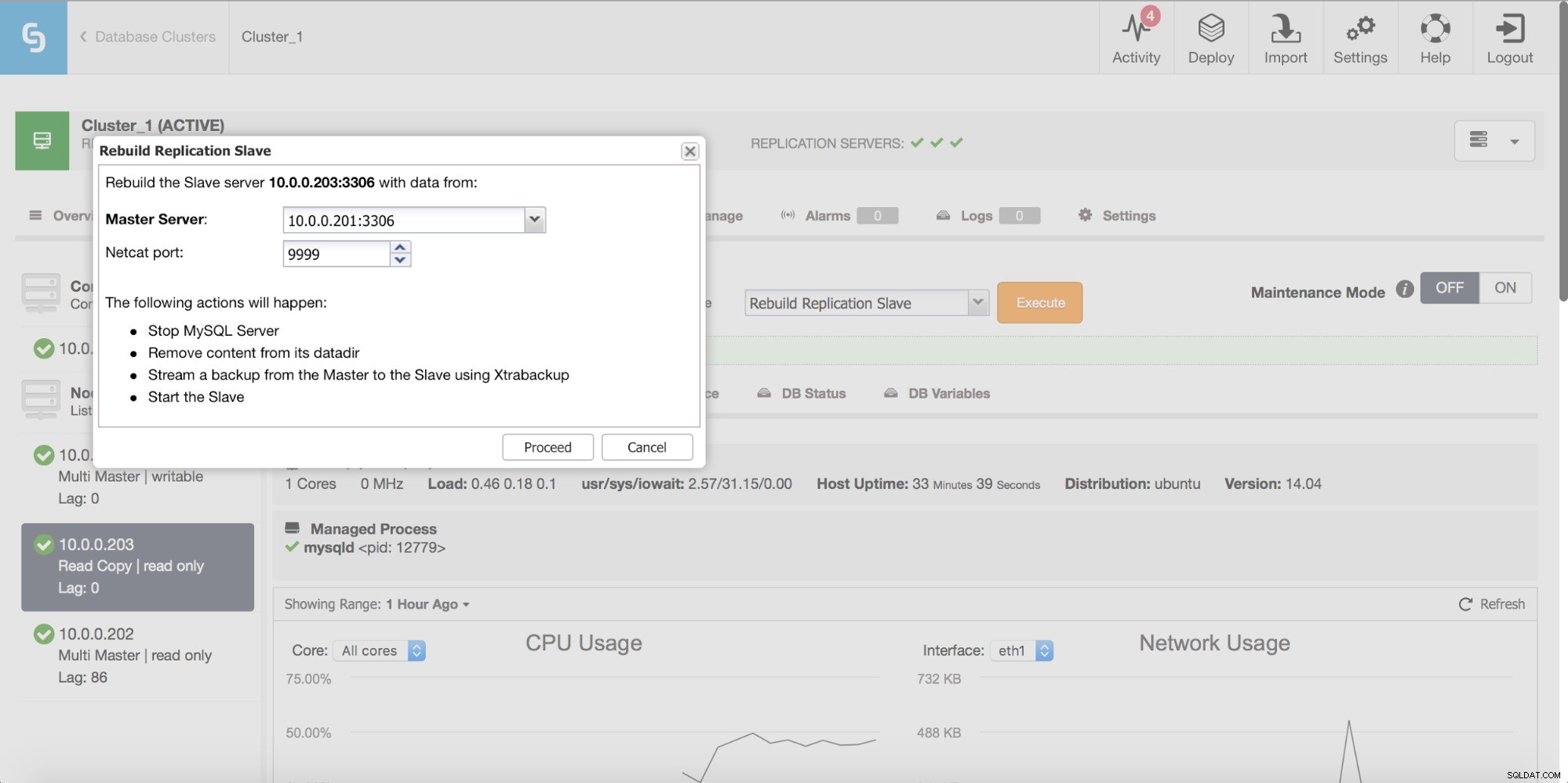
Consistentiecontroles
Zoals we in het vorige hoofdstuk vermeldden, kan consistentie een serieus probleem worden en veel hoofdpijn veroorzaken voor gebruikers die MySQL-replicatie-instellingen uitvoeren. Laten we eens kijken hoe u kunt controleren of uw MySQL-slaves synchroon lopen met de master en wat u eraan kunt doen.
Hoe een inconsistente slaaf te detecteren
Helaas is de typische manier waarop een gebruiker te weten komt dat een slaaf inconsistent is, tegen een van de problemen aan te lopen die we in het vorige hoofdstuk hebben genoemd. Om te voorkomen dat proactieve monitoring van slave-consistentie vereist is. Laten we eens kijken hoe het kan.
We gaan een tool van Percona Toolkit gebruiken:pt-table-checksum. Het is ontworpen om het replicatiecluster te scannen en eventuele discrepanties te identificeren.
We hebben een aangepast scenario gebouwd met sysbench en we hebben een beetje inconsistentie geïntroduceerd op een van de slaven. Wat belangrijk is (als je het wilt testen zoals wij deden), moet je een patch hieronder toepassen om pt-table-checksum te dwingen het 'sbtest'-schema te herkennen als niet-systeemschema:
--- pt-table-checksum 2016-12-15 14:31:07.000000000 +0000
+++ pt-table-checksum-fix 2017-03-21 20:32:53.282254794 +0000
@@ -7614,7 +7614,7 @@
my $filter = $self->{filters};
- if ( $db =~ m/information_schema|performance_schema|lost\+found|percona|percona_schema|test/ ) {
+ if ( $db =~ m/information_schema|performance_schema|lost\+found|percona|percona_schema|^test/ ) {
PTDEBUG && _d('Database', $db, 'is a system database, ignoring');
return 0;
}Eerst gaan we pt-table-checksum op de volgende manier uitvoeren:
master:~# ./pt-table-checksum --max-lag=5 --user=sbtest --password=sbtest --no-check-binlog-format --databases='sbtest'
TS ERRORS DIFFS ROWS CHUNKS SKIPPED TIME TABLE
03-21T20:33:30 0 0 1000000 15 0 27.103 sbtest.sbtest1
03-21T20:33:57 0 1 1000000 17 0 26.785 sbtest.sbtest2
03-21T20:34:26 0 0 1000000 15 0 28.503 sbtest.sbtest3
03-21T20:34:52 0 0 1000000 18 0 26.021 sbtest.sbtest4
03-21T20:35:34 0 0 1000000 17 0 42.730 sbtest.sbtest5
03-21T20:36:04 0 0 1000000 16 0 29.309 sbtest.sbtest6
03-21T20:36:42 0 0 1000000 15 0 38.071 sbtest.sbtest7
03-21T20:37:16 0 0 1000000 12 0 33.737 sbtest.sbtest8Een paar belangrijke opmerkingen over hoe we de tool hebben aangeroepen. Allereerst moet de gebruiker die we instellen op alle slaves bestaan. Als u wilt, kunt u ook '--slave-user' gebruiken om een andere, minder bevoorrechte gebruiker te definiëren voor toegang tot slaves. Nog iets dat de moeite waard is om uit te leggen - we gebruiken op rijen gebaseerde replicatie die niet volledig compatibel is met pt-table-checksum. Als u op rijen replicatie hebt, is wat er gebeurt, dat pt-table-checksum de binaire log-indeling op sessieniveau verandert in 'statement', aangezien dit de enige indeling is die wordt ondersteund. Het probleem is dat een dergelijke wijziging alleen werkt op een eerste niveau van slaves die direct zijn aangesloten op een master. Als je tussenliggende masters hebt (dus meer dan één niveau van slaves), kan het gebruik van pt-table-checksum de replicatie verbreken. Dit is de reden waarom, als het hulpprogramma op rijen gebaseerde replicatie detecteert, het standaard wordt afgesloten en een fout wordt afgedrukt:
“Replica slave1 heeft binlog_format ROW waardoor pt-table-checksum de replicatie kan verbreken. Lees "Replica's met op rijen gebaseerde replicatie" in het gedeelte BEPERKINGEN van de documentatie van het hulpprogramma. Als je de risico's begrijpt, specificeer dan --no-check-binlog-format om deze controle uit te schakelen."
We gebruikten slechts één niveau van slaves, dus het was veilig om "--no-check-binlog-format" op te geven en verder te gaan.
Ten slotte stellen we de maximale vertraging in op 5 seconden. Als deze drempel wordt bereikt, pauzeert pt-table-checksum gedurende een tijd die nodig is om de vertraging onder de drempel te brengen.
Zoals je kon zien aan de output,
03-21T20:33:57 0 1 1000000 17 0 26.785 sbtest.sbtest2er is een inconsistentie gedetecteerd in tabel sbtest.sbtest2.
Standaard slaat pt-table-checksum de checksums op in de tabel percona.checksums. Deze gegevens kunnen worden gebruikt voor een andere tool van Percona Toolkit, pt-table-sync, om te identificeren welke delen van de tabel in detail moeten worden gecontroleerd om exacte verschillen in gegevens te vinden.
Inconsistente slaaf repareren
Zoals hierboven vermeld, zullen we pt-table-sync gebruiken om dat te doen. In ons geval gaan we gegevens gebruiken die zijn verzameld door pt-table-checksum, hoewel het ook mogelijk is om pt-table-sync naar twee hosts te verwijzen (de master en een slave) en het zal alle gegevens op beide hosts vergelijken. Het is zeker een tijdrovender en meer middelenverslindend proces, dus zolang je al gegevens hebt van pt-table-checksum, is het veel beter om het te gebruiken. Dit is hoe we het hebben uitgevoerd om de uitvoer te testen:
master:~# ./pt-table-sync --user=sbtest --password=sbtest --databases=sbtest --replicate percona.checksums h=master --printREPLACE INTO `sbtest`.`sbtest2`(`id`, `k`, `c`, `pad`) VALUES ('1', '434041', '61753673565-14739672440-12887544709-74227036147-86382758284-62912436480-22536544941-50641666437-36404946534-73544093889', '23608763234-05826685838-82708573685-48410807053-00139962956') /*percona-toolkit src_db:sbtest src_tbl:sbtest2 src_dsn:h=10.0.0.101,p=...,u=sbtest dst_db:sbtest dst_tbl:sbtest2 dst_dsn:h=10.0.0.103,p=...,u=sbtest lock:1 transaction:1 changing_src:percona.checksums replicate:percona.checksums bidirectional:0 pid:25776 user:root host:vagrant-ubuntu-trusty-64*/;Zoals u kunt zien, is er als resultaat enige SQL gegenereerd. Belangrijk om op te merken is --replicate variabele. Wat hier gebeurt, is dat we pt-table-sync naar de tabel verwijzen die is gegenereerd door pt-table-checksum. We wijzen het ook naar de meester.
Om te controleren of SQL zinvol is, hebben we de optie --print gebruikt. Houd er rekening mee dat gegenereerde SQL alleen geldig is op het moment dat het wordt gegenereerd - u kunt het niet echt ergens opslaan, bekijken en vervolgens uitvoeren. Het enige dat u kunt doen, is controleren of de SQL zinvol is en onmiddellijk daarna de tool opnieuw uitvoeren met de vlag --execute:
master:~# ./pt-table-sync --user=sbtest --password=sbtest --databases=sbtest --replicate percona.checksums h=10.0.0.101 --executeDit zou de slave weer synchroon moeten laten lopen met de master. We kunnen het verifiëren met pt-table-checksum:
example@sqldat.com:~# ./pt-table-checksum --max-lag=5 --user=sbtest --password=sbtest --no-check-binlog-format --databases='sbtest'
TS ERRORS DIFFS ROWS CHUNKS SKIPPED TIME TABLE
03-21T21:36:04 0 0 1000000 13 0 23.749 sbtest.sbtest1
03-21T21:36:26 0 0 1000000 7 0 22.333 sbtest.sbtest2
03-21T21:36:51 0 0 1000000 10 0 24.780 sbtest.sbtest3
03-21T21:37:11 0 0 1000000 14 0 19.782 sbtest.sbtest4
03-21T21:37:42 0 0 1000000 15 0 30.954 sbtest.sbtest5
03-21T21:38:07 0 0 1000000 15 0 25.593 sbtest.sbtest6
03-21T21:38:27 0 0 1000000 16 0 19.339 sbtest.sbtest7
03-21T21:38:44 0 0 1000000 15 0 17.371 sbtest.sbtest8Zoals je kunt zien, zijn er geen verschillen meer in de tabel sbtest.sbtest2.
We hopen dat je deze blogpost informatief en nuttig vond. Klik hier voor meer informatie over MySQL-replicatie. Als je vragen of suggesties hebt, neem dan gerust contact met ons op via onderstaande opmerkingen.