Benchmarks zijn een van de activiteiten die databasebeheerders uitvoeren. U voert ze uit om te zien hoe uw hardware zich gedraagt, u voert ze uit om te zien hoe uw applicatie en database samenwerken onder druk. Je gebruikt ze in veel verschillende situaties. Laten we het er even over hebben, wat zijn de uitdagingen waarmee u te maken krijgt, welke problemen moet u vermijden.
Soorten benchmarks
Elke benchmark is anders. Ze dienen verschillende doelen en er moet rekening mee worden gehouden wanneer u van plan bent er een te gebruiken. Over het algemeen kun je twee hoofdtypen benchmarks definiëren:synthetische benchmarks en, laten we het noemen, een 'echte' benchmark.
Synthetische benchmarks zijn meestal tools die een soort werklast simuleren. Het kan een OLTP-werklast zijn zoals in het geval van Sysbench, het kan een "standaard" benchmark zijn zoals in TPC-C of TPC-H. Meestal is het idee dat zo'n benchmark een soort werklast simuleert en het kan handig zijn als je echte werklast hetzelfde patroon gaat volgen. Het kan ook worden gebruikt om te bepalen hoe uw mix van hardware- en databaseconfiguratie samenwerkt onder een bepaald type werkbelasting. De voordelen van synthetische benchmarks zijn vrij duidelijk. Je kunt ze overal gebruiken, ze zijn niet afhankelijk van een bepaalde setup of schemaontwerp. Nou, dat doen ze, maar ze komen met tools om alles in te stellen vanaf de lege databaseserver. Het belangrijkste nadeel is dat dit niet uw werklast is. Als u OLTP-tests gaat uitvoeren met Sysbench, moet u er rekening mee houden dat uw toepassing nooit Sysbench zal zijn. Het kan ook OLTP-werkbelasting uitvoeren, maar de querymix zal anders zijn. Nooit, onder geen enkele omstandigheid, zal een synthetische benchmark u precies vertellen hoe uw applicatie zich zal gedragen op een bepaalde hardware/configuratiemix.
Aan de andere kant van het spectrum hebben we, wat we 'echte' benchmarks noemden. Wat we hier bedoelen is een benchmark die gebruik maakt van een dataset en queries met betrekking tot uw applicatie. Het heeft niet altijd een volledige dataset en een volledige querymix. Misschien wilt u zich concentreren op sommige delen van uw toepassing, maar het belangrijkste idee erachter is dat u de exacte interacties tussen de toepassing, hardware en databaseconfiguratie wilt begrijpen, in het algemeen of in een bepaald aspect.
Zoals we hierboven vermeldden, hebben we twee verschillende soorten benchmarks, maar toch hebben ze een aantal gemeenschappelijke dingen waarmee u rekening moet houden bij het uitvoeren van de benchmarks.
-
Beslis wat je wilt testen
Allereerst is benchmarken voor het uitvoeren van benchmarks zinloos. Het moet ontworpen zijn om daadwerkelijk iets te bereiken. Wat wil je uit de benchmarkrun halen? Wil je de queries afstemmen? Wil je de configuratie aanpassen? Wilt u de schaalbaarheid van uw stack beoordelen? Wilt u uw stapel voorbereiden op een hogere belasting? Wilt u een generieke configuratie-tweeking doen voor een nieuw project? Wilt u de beste instellingen voor uw hardware bepalen? Dat zijn voorbeelden van doelen die u wellicht wilt bereiken. Elk van deze vereist een andere aanpak en een andere benchmarkopstelling.
-
Maak één wijziging tegelijk
Wat u ook aan het testen en aanpassen bent, het is van het grootste belang dat u slechts één configuratiewijziging tegelijk aanbrengt. Dit is echt kritisch. De benchmark is bedoeld om u een idee te geven van de prestaties. Query's per seconde, latentie, 99 percentiel, dit alles vertelt je hoe snel je de queries kunt uitvoeren en hoe stabiel en voorspelbaar de werklast is. Het is gemakkelijk te zien of de wijziging die u heeft aangebracht in de configuratie, hardware of querymix iets verandert:de metrieken van de benchmark zullen er anders uitzien. Het punt is dat als je een paar wijzigingen tegelijkertijd aanbrengt, er geen manier is om te zeggen welke verantwoordelijk is voor het algehele resultaat. Het kan zelfs verder gaan dan dat. Stel dat u twee waarden in de databaseconfiguratie hebt gewijzigd. Waarde A en B. De algehele verbetering is 20%, wat best goed is voor slechts een configuratiewijziging. Onder de motorkap bracht de verandering naar waarde A echter een verbetering van 30%, terwijl een extra verandering naar waarde B deze terugbracht naar 20%. Met meerdere wijzigingen tegelijkertijd kunt u alleen hun gemeenschappelijke impact observeren, dit is niet de manier om het resultaat van elke afzonderlijke wijziging die u heeft aangebracht goed te bepalen. Natuurlijk, dit verlengt de tijd die u besteedt aan het uitvoeren van de benchmark aanzienlijk, maar zo is het nu eenmaal.
-
Maak meerdere benchmark-runs
Computers zijn op zichzelf al complexe systemen. Ze hebben meerdere componenten die met elkaar communiceren:geheugen, CPU, schijf, netwerken. Laten we dan aan deze virtualisatie, containerisatie, toevoegen. Dan software - besturingssysteem, applicatie, database. Laag over laag over laag over laag van elementen die op de een of andere manier op elkaar inwerken. Het is niet eenvoudig om zijn gedrag te voorspellen. Nou, je kunt zeggen dat het bijna onmogelijk is om het gedrag van dergelijke complexe systemen precies te voorspellen. Dit is de reden waarom het uitvoeren van één benchmarkrun niet voldoende is om conclusies te trekken. Wat als, onbewust voor u, een element dat totaal geen verband houdt met wat u wilt testen, van invloed is op de algehele prestaties? Hoge belasting op een andere virtuele machine die zich op dezelfde host bevindt. Een andere server streamt back-up over het netwerk. Dit kan tijdelijk van invloed zijn op de prestaties en de benchmarkresultaten scheeftrekken. Als u slechts één benchmarkrun uitvoert, krijgt u onjuiste resultaten. Dit is de reden waarom het het beste is om meerdere passen van een benchmark uit te voeren en vervolgens de langzaamste en de snelste te verwijderen, waarbij het gemiddelde van de andere wordt genomen.
-
Een foto zegt meer dan duizenden woorden
Nou, dit is zo'n beetje een zeer nauwkeurige beschrijving van benchmarking. Genereer indien mogelijk altijd grafieken. In het ideale geval volgt u de statistieken tijdens de benchmark zo vaak als u kunt. Eén seconde granulariteit zou in de meeste gevallen voldoende moeten zijn. Om te voorkomen dat u duizenden woorden schrijft, nemen we dit voorbeeld op. Wat denk je dat handiger is? Deze set benchmark-outputs die de gemiddelde QPS vertegenwoordigen voor elk van 10 passen, waarbij elke passage 600 seconden duurt
11650.52
11237.97
11550.16
11247.08
11177.78
11163.76
11131.47
11235.06
11235.59
11277.25
Of dit plot:
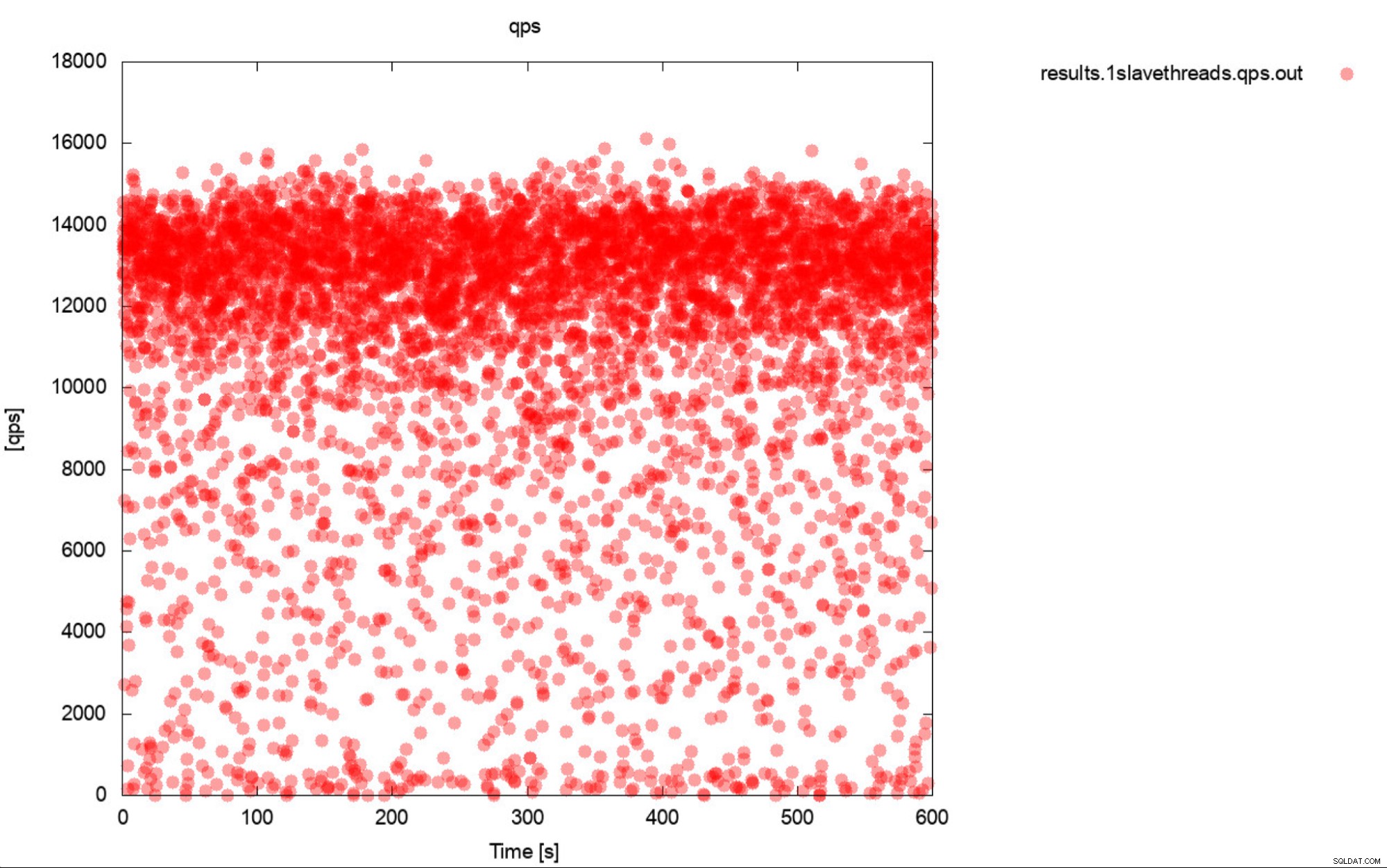
De gemiddelde QPS is 11k, maar de realiteit is dat de prestaties over het hele plaats, inclusief dips naar 0 zoekopdrachten die binnen een seconde worden uitgevoerd, en het is zeker iets dat u wilt werken aan en verbeteren van de productiesystemen.
-
Query's per seconde zijn niet de belangrijkste statistiek
Je denkt misschien dat query's per seconde de heilige graal van prestaties zijn, omdat het aangeeft hoeveel query's een database binnen één seconde kan uitvoeren. De waarheid is dat het niet de belangrijkste statistiek is, vooral als we het hebben over de gemiddelde output van een benchmark. QPS vertegenwoordigt de doorvoer, maar negeert de latentie. U kunt proberen een groot aantal zoekopdrachten te pushen, maar dan moet u wachten tot ze resultaten opleveren. Dit is niet wat gebruikers van de applicatie verwachten. Gebruikers verwachten stabiele prestaties. Het hoeft niet razendsnel te zijn, maar als het een seconde duurt voordat een actie is voltooid, hebben we de neiging om te verwachten dat het uitvoeren van die actie altijd die ene seconde duurt. Als het om wat voor reden dan ook langer begint te duren, hebben mensen de neiging om angstig te worden. Dit is de belangrijkste reden waarom we de voorkeur geven aan latentie, vooral de P99 (99e percentiel) als een betrouwbaardere statistiek. Latency vertelt ons hoe lang de applicatie heeft moeten wachten op het resultaat uit de database. P99 vertelt ons dat de latentie voor 99% van de zoekopdrachten lager is dan. Laten we zeggen dat we een P99 van 100 ms hebben, dit betekent dat 99% van de zoekopdrachten resultaten opleveren die niet langzamer zijn dan 100 ms. Als we de latentie van P99 laag zien, betekent dit dat bijna alle zoekopdrachten snel terugkeren en op een stabiele, voorspelbare manier presteren. Dit willen onze gebruikers zien.
-
Begrijp wat er gebeurt voordat je conclusies trekt
Laatste punt dat we in deze korte blog hebben, maar we zouden zeggen dat dit het belangrijkste is. U zult verschillende vreemde en onverwachte resultaten en gedragingen zien tijdens benchmarks. Erger nog, u ziet mogelijk vrij standaard, repetitieve maar nog steeds gebrekkige resultaten. De meeste zijn te herleiden tot het gedrag van de database of hardware. Dit is echt cruciaal - voordat u het resultaat als vanzelfsprekend beschouwt, moet u het gedrag kunnen verklaren en beschrijven wat er is gebeurd. We weten dat het niet gemakkelijk is en we weten dat het echt databasespecifieke kennis vereist, vooral kennis met betrekking tot de interne onderdelen van de database. We weten dat mensen in de echte wereld zich hier doorgaans niet mee bezig houden, ze willen gewoon wat resultaten behalen. Het punt is dat, vooral voor gevallen waarin je probeert de prestaties te verbeteren door middel van configuratie- of hardware-tweaks, je begrijpt wat er onder de motorkap is gebeurd, zodat je de juiste manier kunt kiezen waarop je afstemming moet verlopen. Het maakt het ook mogelijk om te zien of de uitgevoerde benchmark zin heeft. Testen we eigenlijk wel het juiste element? Een voorbeeld is een test die via het netwerk wordt uitgevoerd (omdat u geen lokale CPU-kernen van het databaseknooppunt voor benchmarktool wilt gebruiken). Het is vrij waarschijnlijk dat het netwerk zelf en de softirq CPU-belasting de beperkende factor zullen zijn, veel eerder dan dat u "verwachte" knelpunten zoals CPU-verzadiging zou tegenkomen. Als u zich niet bewust bent van uw omgeving en het gedrag ervan, meet u uw netwerkprestaties om grote hoeveelheden gegevens over te dragen, niet de CPU-prestaties.
Zoals je kunt zien, is benchmarken niet het gemakkelijkste om te doen, je moet een niveau van bewustzijn hebben van wat er aan de hand is, je moet een goed plan hebben voor wat je gaat doen en wat wil je testen? In het volgende deel van deze blog gaan we enkele van de praktijktests doornemen. Wat kan er mis gaan, welke problemen komen we tegen en hoe gaan we daarmee om.