In het vorige deel hebben we de back-uptijd en effectiviteit van de compressie getest voor verschillende back-upcompressieniveaus en -methoden. In deze blog zullen we onze inspanningen voortzetten en zullen we praten over meer instellingen die, waarschijnlijk, de meeste gebruikers niet echt veranderen, maar ze kunnen een zichtbaar effect hebben op het back-upproces.
De setup is hetzelfde als in het vorige deel:we zullen MariaDB master-slave replicatiecluster gebruiken met ProxySQL en Keepalived.
We hebben 7,6 GB aan gegevens gegenereerd met sysbench:
sysbench /root/sysbench/src/lua/oltp_read_write.lua --threads=4 --mysql-host=10.0.0.111 --mysql-user=sbtest --mysql-password=sbtest --mysql-port=6033 --tables=32 --table-size=1000000 preparePIGZ gebruiken
Deze keer gaan we PIGZ gebruiken voor parallelle gzip inschakelen voor onze back-ups. Zoals eerder zullen we elk compressieniveau testen om te zien hoe het presteert.
We slaan de back-up lokaal op de instantie op, de instantie is geconfigureerd met 4 vCPU's.
Het resultaat is een beetje te verwachten. Het back-upproces was aanzienlijk sneller dan wanneer we slechts een enkele CPU-kern gebruikten. De grootte van de back-up blijft vrijwel hetzelfde, er is geen echte reden om deze aanzienlijk te wijzigen. Het is duidelijk dat het gebruik van pigz de back-uptijd verbetert. Er is echter een schaduwzijde aan het gebruik van parallelle gzip, en het is CPU-gebruik:
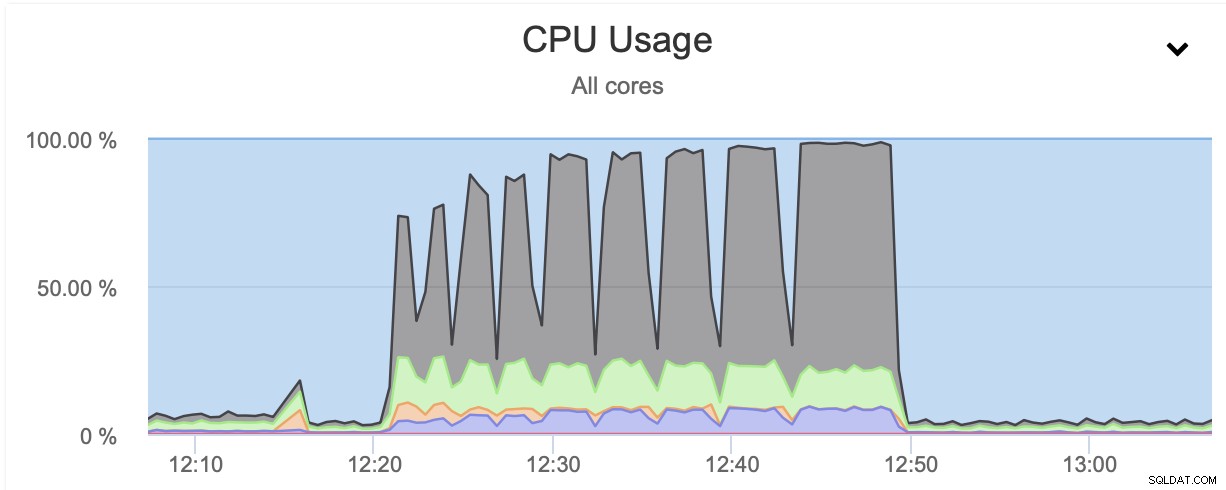
Zoals u kunt zien, schiet het CPU-gebruik omhoog en bereikt het bijna 100% voor hogere compressieniveaus. Het verhogen van het CPU-gebruik op de databaseserver is niet per se het beste idee, omdat we doorgaans willen dat de CPU beschikbaar is voor de database. Aan de andere kant, als we toevallig een replica hebben die is bedoeld voor het maken van back-ups en, laten we zeggen, zwaardere query's - een knooppunt dat niet wordt gebruikt voor het bedienen van een OLTP-type verkeer, kunnen we parallelle gzip inschakelen om de back-up aanzienlijk te verminderen tijd. Zoals duidelijk te zien is, is het niet voor iedereen een optie, maar het is zeker iets dat je in sommige specifieke scenario's nuttig kunt vinden. Houd er rekening mee dat het CPU-gebruik iets is dat u moet volgen, omdat het van invloed is op de latentie van de zoekopdrachten en daardoor ook op de gebruikerservaring - iets waar we altijd rekening mee moeten houden bij het werken met de databases.
Xtrabackup parallelle kopieerthreads
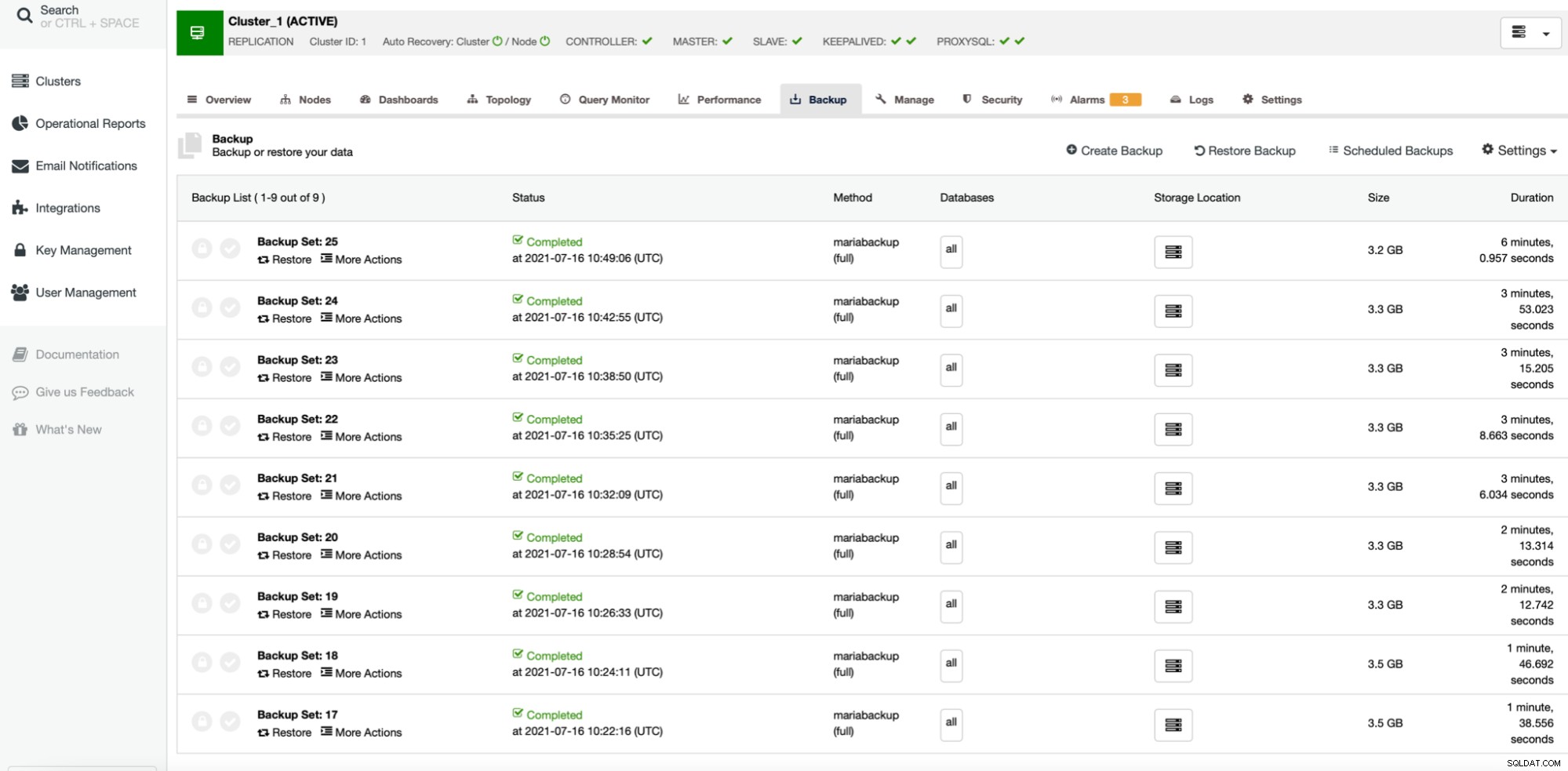
Een andere instelling die we willen benadrukken is Xtrabackup Parallel Copy Threads. Om te begrijpen wat het is, laten we het hebben over de manier waarop Xtrabackup (of MariaBackup) werkt. Kortom, die tools voeren twee acties tegelijk uit. Ze kopiëren de gegevens, fysieke bestanden, van de databaseserver naar de back-uplocatie terwijl ze de InnoDB-logboeken controleren op eventuele updates. De back-up bestaat uit de bestanden en het overzicht van alle wijzigingen aan InnoDB die tijdens het back-upproces hebben plaatsgevonden. Dit, met back-upvergrendelingen of FLUSH TABLES MET READ LOCK, maakt het mogelijk om een back-up te maken die consistent is op het moment dat de gegevensoverdracht is voltooid. Xtrabackup Parallel Copy Threads bepalen het aantal threads dat de gegevensoverdracht zal uitvoeren. Als we dit op 1 zetten, wordt er één bestand tegelijk gekopieerd. Als we het op 8 zetten, kunnen in theorie maximaal 8 bestanden tegelijk worden overgedragen. Natuurlijk moet er snel genoeg opslagruimte zijn om daadwerkelijk van zo'n instelling te kunnen profiteren. We gaan verschillende tests uitvoeren, waarbij we Xtrabackup Parallel Copy Threads wijzigen van 1 tot 2 en 4 naar 8. We zullen tests uitvoeren op compressieniveau 6 (standaard één) met en zonder parallelle gzip ingeschakeld.
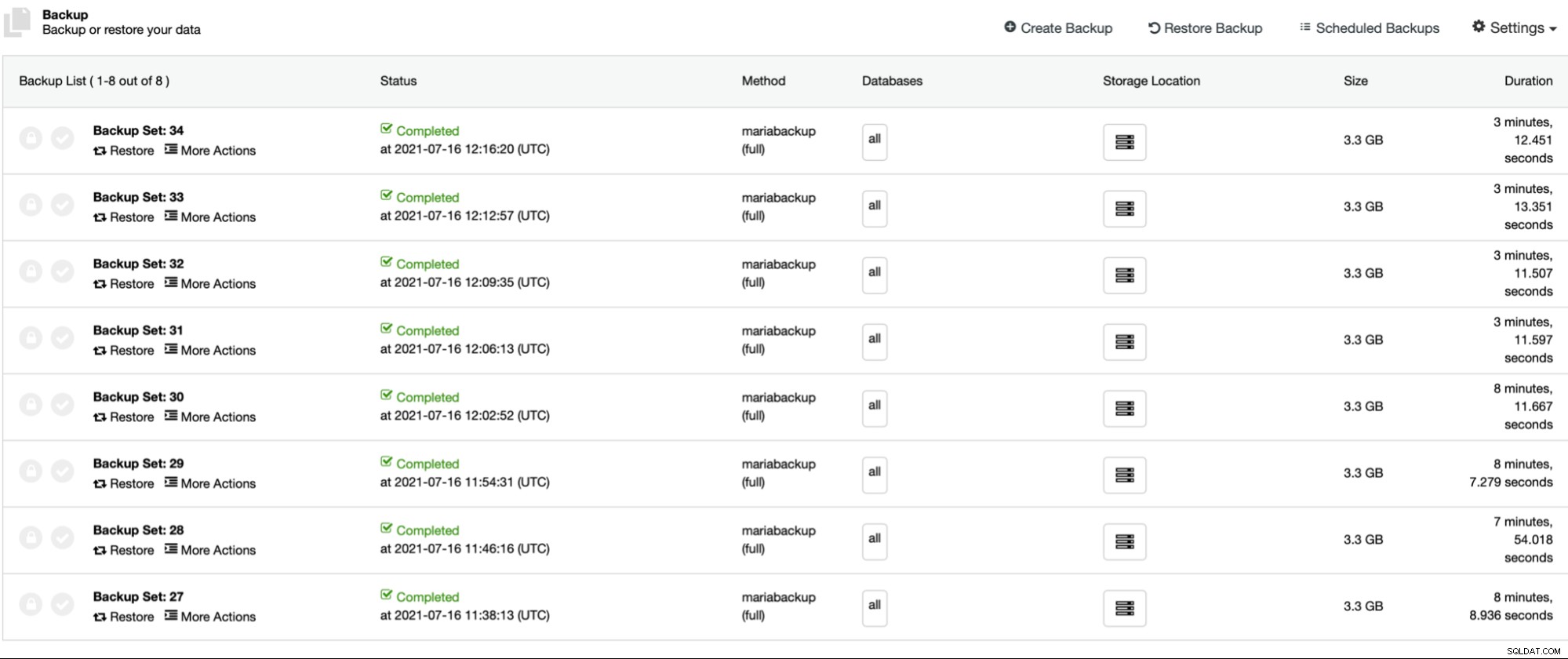
De eerste vier back-ups (27 - 30) zijn gemaakt zonder parallelle gzip, beginnend bij 1 tot 2, 4 en 8 parallelle kopieerthreads. Daarna herhaalden we hetzelfde proces voor back-ups 31 tot 34, dit keer met parallelle gzip. Zoals je kunt zien, is er in ons geval nauwelijks een verschil tussen de parallelle kopieerthreads. Dit zal hoogstwaarschijnlijk meer impact hebben als we de omvang van de dataset zouden vergroten. Het zou ook de back-upprestaties verbeteren als we snellere, betrouwbaardere opslag zouden gebruiken. Zoals gewoonlijk varieert uw kilometerstand en in verschillende omgevingen kan deze instelling het back-upproces meer beïnvloeden dan we hier zien.
Netwerkbeperking
Tot slot, in dit deel van onze korte serie willen we het hebben over de mogelijkheid om het netwerkgebruik te beperken.
Zoals je misschien hebt gezien, kunnen back-ups lokaal worden opgeslagen op het knooppunt of het kan ook naar de controllerhost worden gestreamd. Dit gebeurt via het netwerk en wordt standaard "zo snel mogelijk" gedaan.
In sommige gevallen, waar uw netwerkdoorvoer beperkt is (bijvoorbeeld cloud-instanties), wilt u misschien het netwerkgebruik dat wordt veroorzaakt door MariaBackup verminderen door een limiet in te stellen voor de netwerkoverdracht. Wanneer u dat doet, gebruikt ClusterControl de 'pv'-tool om de beschikbare bandbreedte voor het proces te beperken.
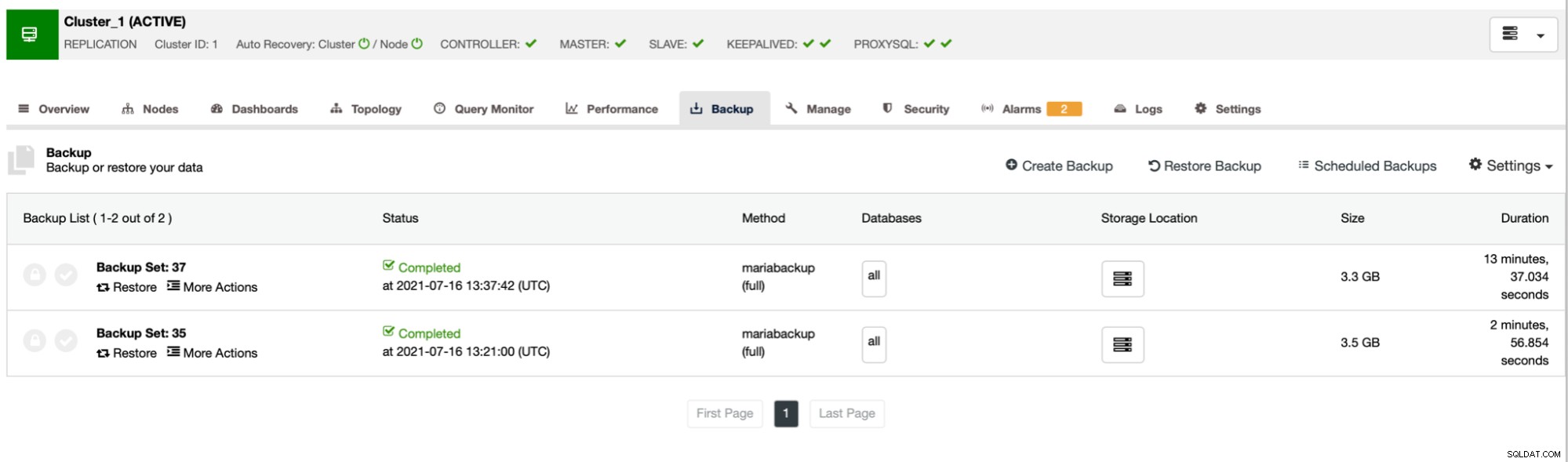
Zoals u kunt zien, duurde de eerste back-up ongeveer 3 minuten, maar toen we beperkte de netwerkdoorvoer, back-up duurde 13 minuten en 37 seconden.
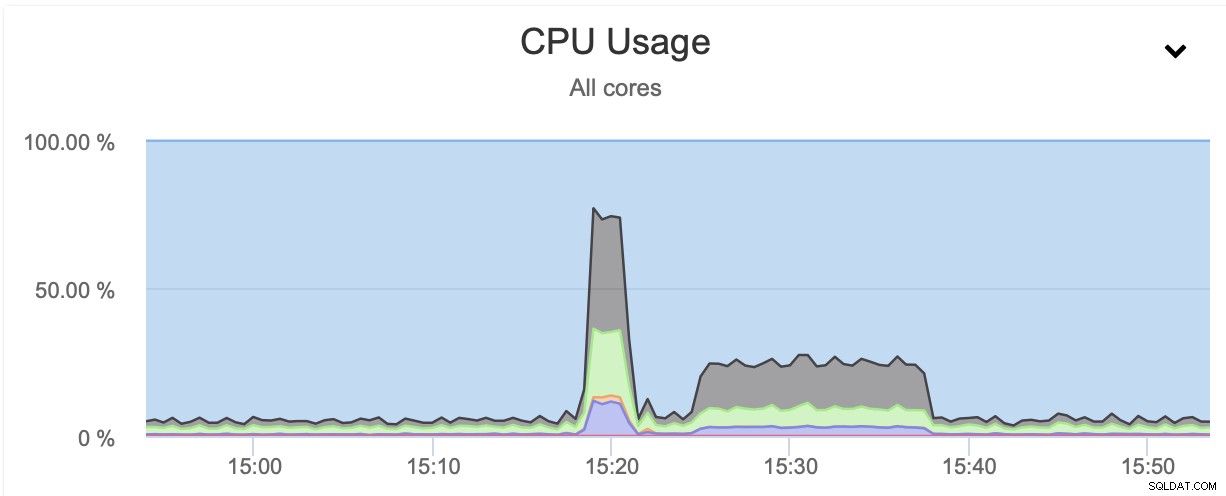
In beide gevallen gebruikten we pigz en het compressieniveau 1. De grafiek hierboven toont aan dat het beperken van het netwerk ook het CPU-gebruik verminderde. Het is logisch, als pigz moet wachten tot het netwerk de gegevens heeft overgedragen, hoeft het niet hard op de CPU te duwen, omdat het het grootste deel van de tijd inactief moet zijn.
Hopelijk vond je deze korte blog interessant en misschien zal het je aanmoedigen om te experimenteren met enkele van de niet zo vaak gebruikte functies en opties van MariaBackup. Als je wat van je ervaringen wilt delen, horen we graag van je in de reacties hieronder.