Het draaien van databases op een cloudinfrastructuur wordt tegenwoordig steeds populairder. Hoewel een cloud-VM misschien niet zo betrouwbaar is als een enterprise-grade server, bieden de belangrijkste cloudproviders een verscheidenheid aan tools om de servicebeschikbaarheid te vergroten. In deze blogpost laten we u zien hoe u uw MySQL- of MariaDB-database bouwt voor hoge beschikbaarheid, in de cloud. We zullen specifiek kijken naar Amazon Web Services en Google Cloud Platform, maar de meeste tips kunnen ook met andere cloudproviders worden gebruikt.
Zowel AWS als Google bieden databaseservices op hun clouds en deze services kunnen worden geconfigureerd voor hoge beschikbaarheid. Het is mogelijk om kopieën in verschillende beschikbaarheidszones (of zones in GCP) te hebben om uw kansen te vergroten om een gedeeltelijke uitval van services binnen een regio te overleven. Hoewel een gehoste service een erg handige manier is om een database te runnen, moet u er rekening mee houden dat de service is ontworpen om zich op een specifieke manier te gedragen en dat deze al dan niet aan uw eisen voldoet. AWS RDS voor MySQL heeft bijvoorbeeld een vrij beperkte lijst met opties als het gaat om het afhandelen van failover. Multi-AZ-implementaties worden geleverd met een failovertijd van 60-120 seconden volgens de documentatie. In feite, gezien de "schaduw" MySQL-instantie moet beginnen met een "beschadigde" dataset, kan dit zelfs nog langer duren omdat er meer werk nodig kan zijn bij het toepassen of terugdraaien van transacties van InnoDB-redo-logs. Er is een optie om een slave te promoveren tot master, maar dit is niet haalbaar omdat je bestaande slaves niet van de nieuwe master kunt reslaven. In het geval van een managed service is het ook intrinsiek complexer en moeilijker om prestatieproblemen op te sporen. Meer inzichten over RDS voor MySQL en de beperkingen ervan in deze blogpost.
Aan de andere kant, als u besluit de databases te beheren, bevindt u zich in een andere wereld van mogelijkheden. Een aantal dingen die je op bare metal kunt doen, zijn ook mogelijk op EC2- of Compute Engine-instanties. U heeft niet de overhead van het beheer van de onderliggende hardware, maar behoudt toch de controle over de architectuur van het systeem. Er zijn twee hoofdopties bij het ontwerpen voor MySQL-beschikbaarheid:MySQL-replicatie en Galera Cluster. Laten we ze bespreken.
MySQL-replicatie
MySQL-replicatie is een veelgebruikte manier om MySQL te schalen met meerdere kopieën van de gegevens. Asynchroon of semi-synchroon, het maakt het mogelijk om wijzigingen die zijn uitgevoerd op een enkele schrijver, de master, door te geven aan replica's/slaves - die elk de volledige dataset bevatten en kunnen worden gepromoveerd om de nieuwe master te worden. Replicatie kan ook worden gebruikt voor het schalen van reads, door leesverkeer naar replica's te leiden en de master op deze manier te ontlasten. Het belangrijkste voordeel van replicatie is het gebruiksgemak - het is zo algemeen bekend en populair (het is ook gemakkelijk te configureren) dat er talloze bronnen en hulpmiddelen zijn om u te helpen bij het beheren en configureren ervan. Ons eigen ClusterControl is er een van - u kunt het gebruiken om eenvoudig een MySQL-replicatie-installatie met geïntegreerde load balancers te implementeren, topologiewijzigingen, failover/herstel, enzovoort te beheren.
Een groot probleem met MySQL-replicatie is dat het niet is ontworpen om netwerksplitsingen of masterstoringen aan te pakken. Als een master uitvalt, moet je een van de replica's promoten. Dit is een handmatig proces, hoewel het kan worden geautomatiseerd met externe tools (bijvoorbeeld ClusterControl). Er is ook geen quorummechanisme en er is geen ondersteuning voor het afschermen van mislukte hoofdinstanties in MySQL-replicatie. Helaas kan dit leiden tot ernstige problemen in gedistribueerde omgevingen. Als u een nieuwe master promoot terwijl uw oude weer online komt, kan het zijn dat u naar twee knooppunten schrijft, waardoor gegevensafwijkingen ontstaan en ernstige problemen met de gegevensconsistentie ontstaan.
We zullen later in dit bericht enkele voorbeelden bekijken, die u laten zien hoe u netwerksplitsingen kunt detecteren en STONITH of een ander hekwerkmechanisme kunt implementeren voor uw MySQL-replicatie-installatie.
Galera-cluster
We hebben in de vorige sectie gezien dat MySQL-replicatie geen hekwerk en quorumondersteuning heeft - dit is waar Galera Cluster uitblinkt. Het heeft een ingebouwde quorumondersteuning, het heeft ook een hekwerkmechanisme dat voorkomt dat gepartitioneerde knooppunten schrijfbewerkingen accepteren. Dit maakt Galera Cluster geschikter dan replicatie in multi-datacenteropstellingen. Galera Cluster ondersteunt ook meerdere schrijvers en is in staat om schrijfconflicten op te lossen. U bent daarom niet beperkt tot een enkele schrijver in een multi-datacenter opstelling, het is mogelijk om een schrijver in elk datacenter te hebben waardoor de latentie tussen uw applicatie en databaselaag wordt verminderd. Het versnelt het schrijven niet, aangezien elk schrijven nog steeds naar elk Galera-knooppunt moet worden gestuurd voor certificering, maar het is nog steeds eenvoudiger dan het schrijven van alle applicatieservers via WAN naar één enkele externe master.
Hoe goed Galera ook is, het is niet altijd de beste keuze voor alle workloads. Galera is geen vervanging voor MySQL/InnoDB. Het deelt gemeenschappelijke functies met "normale" MySQL - het gebruikt InnoDB als opslagengine, het bevat de volledige dataset op elk knooppunt, wat JOINs mogelijk maakt. Toch verschillen sommige prestatiekenmerken van Galera (zoals de schrijfprestaties die worden beïnvloed door netwerklatentie) van wat je zou verwachten van replicatie-instellingen. Onderhoud ziet er ook anders uit:de afhandeling van schemawijzigingen werkt iets anders. Sommige schema-ontwerpen zijn niet optimaal:als u hotspots in uw tabellen hebt, zoals regelmatig bijgewerkte tellers, kan dit leiden tot prestatieproblemen. Er is ook een verschil in best practices met betrekking tot batchverwerking - in plaats van query's uit te voeren in grote transacties, wilt u dat uw transacties klein zijn.
Proxy-laag
Het is erg moeilijk en omslachtig om een zeer beschikbare opstelling te bouwen zonder proxy's. Natuurlijk kunt u code in uw toepassing schrijven om database-instanties bij te houden, ongezonde exemplaren op de zwarte lijst te zetten, de beschrijfbare master(s) bij te houden, enzovoort. Maar dit is veel complexer dan alleen verkeer naar een enkel eindpunt te sturen - en dat is waar een proxy van pas komt. Met ClusterControl kunt u ProxySQL, HAProxy en MaxScale implementeren. We zullen enkele voorbeelden geven van het gebruik van ProxySQL, omdat het ons een goede flexibiliteit geeft bij het beheren van databaseverkeer.
ProxySQL kan op een aantal manieren worden ingezet. Om te beginnen kan het op afzonderlijke hosts worden geïmplementeerd en kan Keepalive worden gebruikt om virtuele IP te bieden. Het virtuele IP-adres wordt verplaatst als een van de ProxySQL-instanties faalt. In de cloud kan deze configuratie problematisch zijn, omdat het toevoegen van een IP aan de interface meestal niet voldoende is. U zou de Keepalive-configuratie en -scripts moeten aanpassen om met elastische IP te werken (of statisch - hoe het ook door uw cloudprovider wordt genoemd). Dan zou men cloud-API of CLI gebruiken om dit IP-adres naar een andere host te verplaatsen. Om deze reden raden we aan om ProxySQL samen met de applicatie te plaatsen. Elke applicatieserver zou worden geconfigureerd om verbinding te maken met de lokale ProxySQL, met behulp van Unix-sockets. Omdat ProxySQL een angel-proces gebruikt, kunnen ProxySQL-crashes binnen een seconde worden gedetecteerd/herstart. In het geval van een hardwarecrash, zal die specifieke applicatieserver samen met ProxySQL uitvallen. De overige applicatieservers hebben nog steeds toegang tot hun respectievelijke lokale ProxySQL-instanties. Deze specifieke opstelling heeft extra functies. Beveiliging - ProxySQL biedt vanaf versie 1.4.8 geen ondersteuning voor client-side SSL. Het kan alleen een SSL-verbinding instellen tussen ProxySQL en de backend. Het colloceren van ProxySQL op de applicatiehost en het gebruik van Unix-sockets is een goede oplossing. ProxySQL heeft ook de mogelijkheid om query's te cachen en als u deze functie gaat gebruiken, is het logisch om deze zo dicht mogelijk bij de toepassing te houden om de latentie te verminderen. We raden u aan dit patroon te gebruiken om ProxySQL te implementeren.
Typische instellingen
Laten we eens kijken naar voorbeelden van zeer beschikbare instellingen.
Eén datacenter, MySQL-replicatie
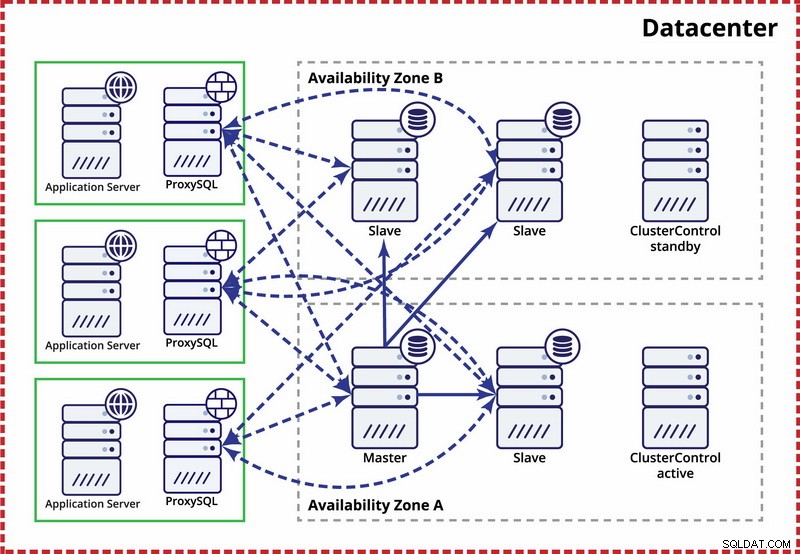
De veronderstelling hierbij is dat er binnen het datacenter twee aparte zones zijn. Elke zone heeft redundante en aparte voeding, netwerken en connectiviteit om de kans te verkleinen dat twee zones tegelijkertijd uitvallen. Het is mogelijk om een replicatietopologie in te stellen die beide zones omspant.
Hier gebruiken we ClusterControl om de failover te beheren. Om het split-brain-scenario tussen beschikbaarheidszones op te lossen, brengen we de actieve ClusterControl samen met de master. We zetten ook slaves op de zwarte lijst in de andere beschikbaarheidszone om ervoor te zorgen dat automatische failover er niet toe leidt dat er twee masters beschikbaar zijn.
Meerdere datacenters, MySQL-replicatie
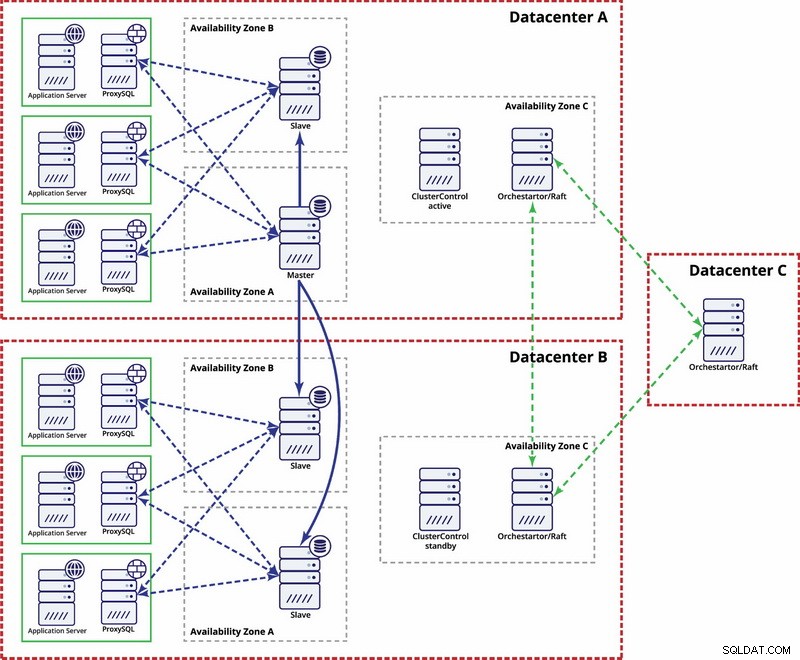
In dit voorbeeld gebruiken we drie datacenters en Orchestrator/Raft voor quorumberekening. Mogelijk moet u uw eigen scripts schrijven om STONITH te implementeren als master zich in het gepartitioneerde segment van de infrastructuur bevindt. ClusterControl wordt gebruikt voor knooppuntherstel en beheerfuncties.
Meerdere datacenters, Galera Cluster
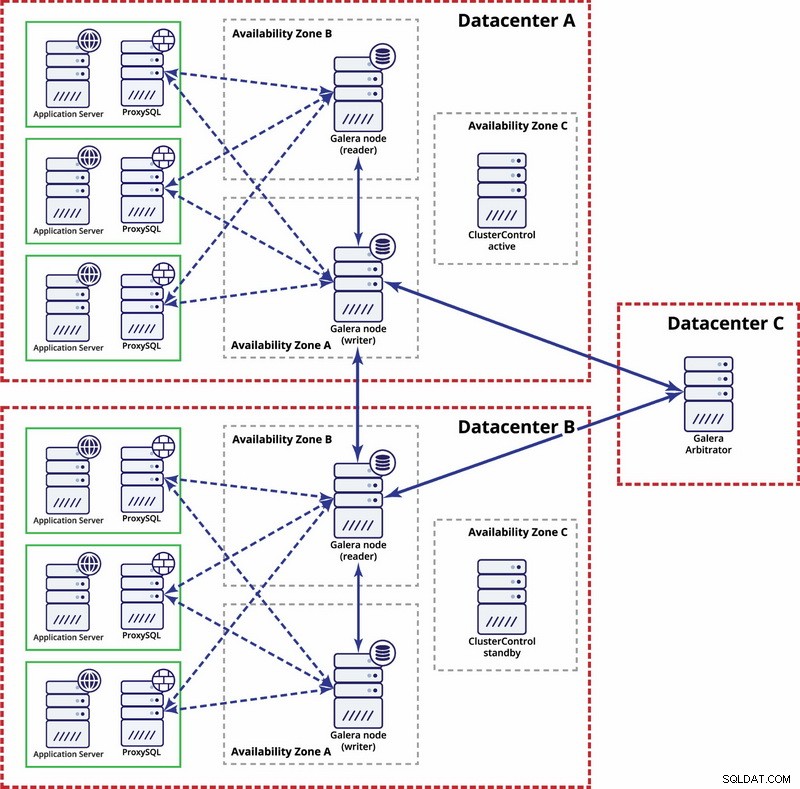
In dit geval gebruiken we drie datacenters met een Galera-arbiter in de derde - dit maakt het mogelijk om een volledige datacenterstoring op te lossen en vermindert het risico op netwerkpartitionering, aangezien het derde datacenter als relais kan worden gebruikt.
Voor meer informatie kunt u de whitepaper "Hoe zeer beschikbare open source database-omgevingen ontwerpen" bekijken en de webinar "Ontwerpen van open source-databases voor hoge beschikbaarheid" bekijken.