Voordat u schemawijzigingen in uw productiedatabases probeert uit te voeren, moet u ervoor zorgen dat u een solide terugdraaiplan hebt; en dat uw wijzigingsprocedure succesvol is getest en gevalideerd in een aparte omgeving. Tegelijkertijd is het jouw verantwoordelijkheid om ervoor te zorgen dat de verandering geen of zo min mogelijk impact heeft die acceptabel is voor het bedrijf. Het is zeker geen gemakkelijke taak.
In dit artikel zullen we bekijken hoe u op een gecontroleerde manier databasewijzigingen op MySQL en MariaDB kunt uitvoeren. We zullen het hebben over enkele goede gewoonten in uw dagelijkse DBA-werk. We concentreren ons op de vereisten en taken tijdens de daadwerkelijke bewerkingen en op problemen waarmee u te maken kunt krijgen wanneer u te maken krijgt met wijzigingen in het databaseschema. We zullen ook praten over open source-tools die u hierbij kunnen helpen.
Test- en terugdraaiscenario's
Back-up
Er zijn veel manieren om uw gegevens te verliezen. Schema-upgradefout is er een van. In tegenstelling tot applicatiecode, kunt u geen bundel bestanden laten vallen en verklaren dat een nieuwe versie succesvol is geïmplementeerd. U kunt ook niet zomaar een oudere set bestanden terugzetten om uw wijzigingen ongedaan te maken. U kunt natuurlijk een ander SQL-script uitvoeren om de database opnieuw te wijzigen, maar er zijn gevallen waarin de enige juiste manier om wijzigingen ongedaan te maken, is door de volledige database vanaf een back-up te herstellen.
Maar wat als u het zich niet kunt veroorloven om uw database terug te draaien naar de nieuwste back-up, of als uw onderhoudsperiode niet groot genoeg is (gezien de systeemprestaties), zodat u geen volledige databaseback-up kunt uitvoeren vóór de wijziging?
Je hebt misschien een geavanceerde, redundante omgeving, maar zolang gegevens worden gewijzigd op zowel primaire als standby-locaties, is er niet veel aan te doen. Veel scripts kunnen maar één keer worden uitgevoerd, of de wijzigingen kunnen niet ongedaan worden gemaakt. De meeste SQL-wijzigingscodes vallen in twee groepen:
- Eén keer uitvoeren – u kunt dezelfde kolom niet twee keer aan de tabel toevoegen.
- Onmogelijk om ongedaan te maken - als je die kolom eenmaal hebt laten vallen, is hij weg. Je zou ongetwijfeld je database kunnen herstellen, maar dat is niet echt ongedaan maken.
U kunt dit probleem op ten minste twee mogelijke manieren aanpakken. Een daarvan zou zijn om het binaire logboek in te schakelen en een back-up te maken, die compatibel is met PITR. Een dergelijke back-up moet volledig, volledig en consistent zijn. Voor xtrabackup, zolang het een volledige dataset bevat, zal het PITR-compatibel zijn. Voor mysqldump is er een optie om het ook PITR-compatibel te maken. Voor kleinere wijzigingen zou een variatie op mysqldump-back-up zijn om slechts een subset van gegevens te wijzigen. Dit kan gedaan worden met --where optie. De back-up moet deel uitmaken van het geplande onderhoud.
mysqldump -u -p --lock-all-tables --where="WHERE employee_id=100" mydb employees> backup_table_tmp_change_07132018.sqlEen andere mogelijkheid is om CREATE TABLE AS SELECT te gebruiken.
U kunt gegevens of eenvoudige structuurwijzigingen opslaan in de vorm van een vaste tijdelijke tabel. Met deze aanpak krijgt u een bron als u uw wijzigingen moet terugdraaien. Het kan best handig zijn als u niet veel gegevens wijzigt. Het terugdraaien kan worden gedaan door er gegevens uit te halen. Als er fouten optreden tijdens het kopiëren van de gegevens naar de tabel, wordt deze automatisch verwijderd en niet gemaakt, dus zorg ervoor dat uw verklaring een kopie maakt die u nodig hebt.
Uiteraard zijn er ook enkele beperkingen.
Omdat de volgorde van de rijen in de onderliggende SELECT-instructies niet altijd kan worden bepaald, worden CREATE TABLE ... IGNORE SELECT en CREATE TABLE ... REPLACE SELECT gemarkeerd als onveilig voor replicatie op basis van instructies. Dergelijke instructies produceren een waarschuwing in het foutenlogboek bij gebruik van de op instructie gebaseerde modus en worden naar het binaire logboek geschreven met behulp van de op rijen gebaseerde indeling bij gebruik van de MIXED-modus.
Een heel eenvoudig voorbeeld van zo'n methode zou kunnen zijn:
CREATE TABLE tmp_employees_change_07132018 AS SELECT * FROM employees where employee_id=100;
UPDATE employees SET salary=120000 WHERE employee_id=100;
COMMMIT;Een andere interessante optie kan de MariaDB flashback-database zijn. Wanneer een verkeerde update of verwijdering plaatsvindt en u op een bepaald moment wilt terugkeren naar een staat van de database (of alleen een tabel), kunt u de flashback-functie gebruiken.
Met Point-in-time rollback kunnen DBA's gegevens sneller herstellen door transacties terug te draaien naar een eerder tijdstip in plaats van een herstel vanaf een back-up uit te voeren. Op basis van op ROW gebaseerde DML-gebeurtenissen kan flashback het binaire logboek transformeren en doelen omkeren. Dat betekent dat het kan helpen om bepaalde rijwijzigingen snel ongedaan te maken. Het kan bijvoorbeeld DELETE-gebeurtenissen veranderen in INSERT's en vice versa, en het zal WHERE- en SET-delen van de UPDATE-gebeurtenissen verwisselen. Dit eenvoudige idee kan het herstel van bepaalde soorten fouten of rampen drastisch versnellen. Voor degenen die bekend zijn met de Oracle-database, het is een bekende functie. De beperking van MariaDB-flashback is het gebrek aan DDL-ondersteuning.
Maak een vertraagde replicatieslave
Sinds versie 5.6 ondersteunt MySQL vertraagde replicatie. Een slave-server kan minimaal een bepaalde tijd achterlopen op de master. De standaardvertraging is 0 seconden. Gebruik de MASTER_DELAY optie voor CHANGE MASTER TO om de vertraging in te stellen op N seconden:
CHANGE MASTER TO MASTER_DELAY = N;Het zou een goede optie zijn als u geen tijd had om een goed herstelscenario voor te bereiden. U moet voldoende vertraging hebben om de problematische verandering op te merken. Het voordeel van deze aanpak is dat u uw database niet hoeft te herstellen om gegevens te verwijderen die nodig zijn om uw wijziging op te lossen. Standby DB is actief, klaar om gegevens op te halen, wat de benodigde tijd tot een minimum beperkt.
Maak een asynchrone slaaf die geen deel uitmaakt van de cluster
Als het gaat om Galera-cluster, is het testen van veranderingen niet eenvoudig. Alle knooppunten voeren dezelfde gegevens uit en zware belasting kan de stroomregeling schaden. U moet dus niet alleen controleren of wijzigingen met succes zijn doorgevoerd, maar ook wat de impact op de clusterstatus was. Om uw testprocedure zo dicht mogelijk bij de productiewerkbelasting te brengen, wilt u misschien een asynchrone slave aan uw cluster toevoegen en uw test daar uitvoeren. De test heeft geen invloed op de synchronisatie tussen clusterknooppunten, omdat het technisch gezien geen deel uitmaakt van het cluster, maar je hebt wel een optie om het te controleren met echte gegevens. Zo'n slave kan eenvoudig worden toegevoegd vanuit ClusterControl.
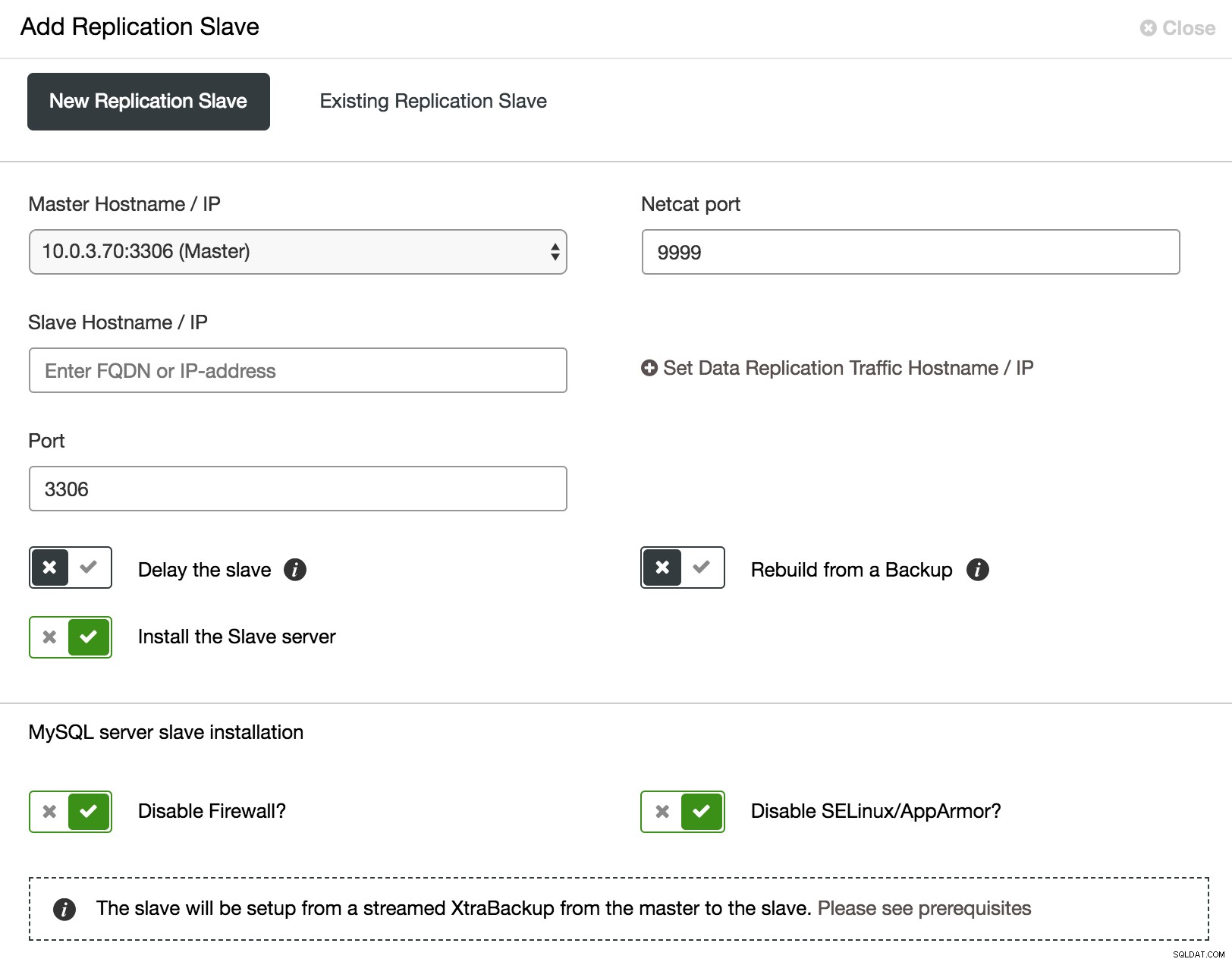 ClusterControl voegt asynchrone slaaf toe
ClusterControl voegt asynchrone slaaf toe Zoals te zien is in de bovenstaande schermafbeelding, kan ClusterControl het proces van het toevoegen van een asynchrone slave op een aantal manieren automatiseren. U kunt het knooppunt aan het cluster toevoegen, de slaaf vertragen. Om de impact op de master te verminderen, kunt u een bestaande back-up gebruiken in plaats van de master als gegevensbron bij het bouwen van de slave.
Database klonen en tijd meten
Een goede test moet zo dicht mogelijk bij de productieverandering liggen. De beste manier om dit te doen is door uw bestaande omgeving te klonen.
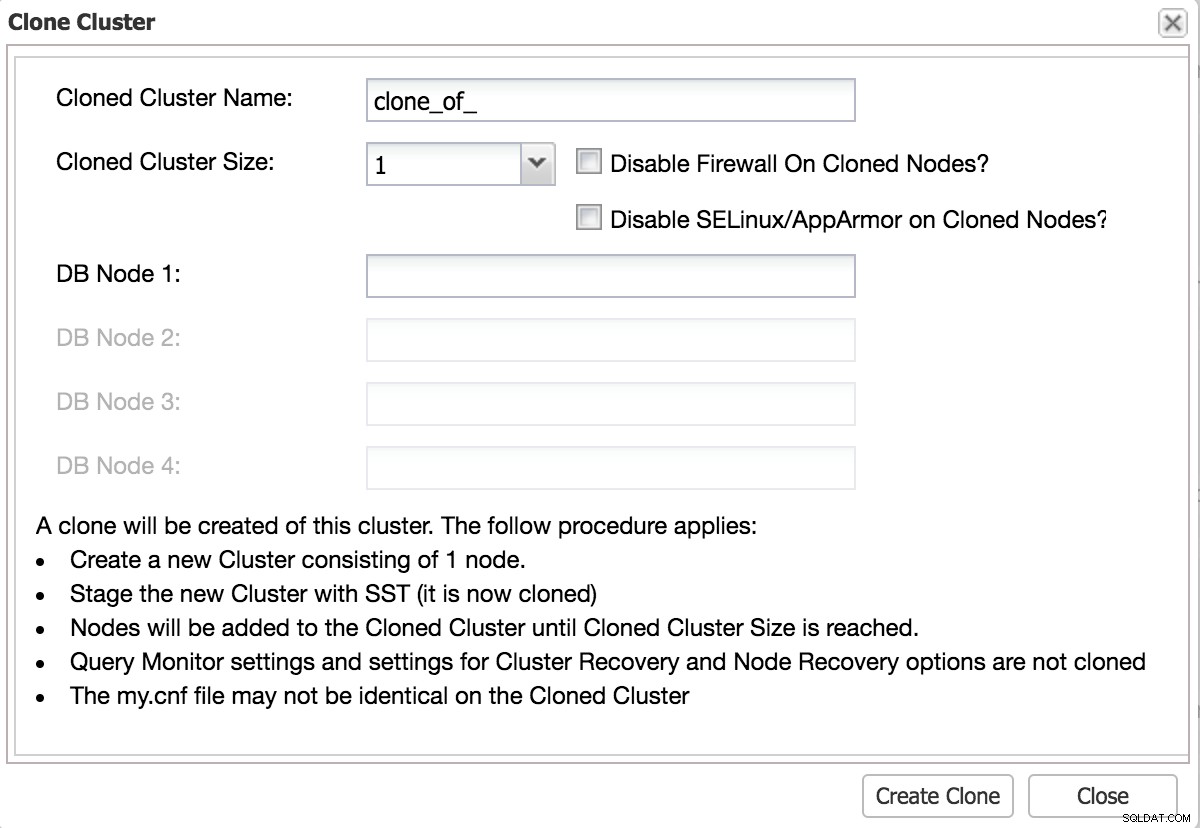 ClusterControl Clone Cluster voor test
ClusterControl Clone Cluster voor test Wijzigingen uitvoeren via replicatie
Om uw wijzigingen beter onder controle te hebben, kunt u ze van tevoren op een slaveserver toepassen en vervolgens overschakelen. Voor replicatie op basis van instructies werkt dit prima, maar voor replicatie op basis van rijen kan dit tot op zekere hoogte werken. Op rijen gebaseerde replicatie zorgt ervoor dat er extra kolommen aan het einde van de tabel kunnen staan, dus zolang het de eerste kolommen kan schrijven, komt het goed. Pas deze instelling eerst toe op alle slaves, vervolgens failover op een van de slaven en voer vervolgens de wijziging door naar de master en koppel die als slave. Als uw wijziging betrekking heeft op het invoegen of verwijderen van een kolom in het midden van de tabel, werkt deze met op rijen gebaseerde replicatie.
Bediening
Tijdens het onderhoudsvenster willen we geen applicatieverkeer op de database hebben. Soms is het moeilijk om alle applicaties verspreid over het hele bedrijf uit te schakelen. Als alternatief willen we alleen enkele specifieke hosts toestaan om op afstand toegang te krijgen tot MySQL (bijvoorbeeld het monitoringsysteem of de back-upserver). Voor dit doel kunnen we de Linux-pakketfiltering gebruiken. Om te zien welke regels voor pakketfiltering beschikbaar zijn, kunnen we de volgende opdracht uitvoeren:
iptables -L INPUT -vOm de MySQL-poort op alle interfaces te sluiten die we gebruiken:
iptables -A INPUT -p tcp --dport mysql -j DROPen om de MySQL-poort opnieuw te openen na het onderhoudsvenster:
iptables -D INPUT -p tcp --dport mysql -j DROPVoor degenen zonder root-toegang, kunt u max_connection wijzigen in 1 of 'netwerk overslaan'.
Logboekregistratie
Om het logproces te starten, gebruikt u het tee-commando bij de MySQL-clientprompt, als volgt:
mysql> tee /tmp/my.out;Die opdracht vertelt MySQL om zowel de invoer als de uitvoer van uw huidige MySQL-aanmeldingssessie in een bestand met de naam /tmp/my.out te loggen. Voer vervolgens uw scriptbestand uit met het broncommando.
Om een beter idee te krijgen van uw uitvoeringstijden, kunt u deze combineren met de profiler-functie. Start de profiler met
SET profiling = 1;Voer vervolgens uw zoekopdracht uit met
SHOW PROFILES;je ziet een lijst met zoekopdrachten waarvoor de profiler statistieken heeft. Dus tot slot kiest u met welke query u wilt onderzoeken
SHOW PROFILE FOR QUERY 1;Hulpprogramma's voor schemamigratie
Vaak is een rechtstreekse ALTER op de master niet mogelijk - in de meeste gevallen veroorzaakt dit vertraging op de slave, en dit is misschien niet acceptabel voor de toepassingen. Wat wel kan, is om de wijziging in een rollende modus uit te voeren. Je kunt beginnen met slaves en, zodra de wijziging is toegepast op de slave, een van de slaven migreren als een nieuwe master, de oude master degraderen tot een slave en de wijziging daarop uitvoeren.
Een tool die hierbij kan helpen is Percona’s pt-online-schema-change. Pt-online-schema-verandering is eenvoudig - het creëert een tijdelijke tabel met het gewenste nieuwe schema (bijvoorbeeld als we een index hebben toegevoegd of een kolom uit een tabel hebben verwijderd). Vervolgens maakt het triggers op de oude tafel. Die triggers zijn er om veranderingen die op de oorspronkelijke tafel plaatsvinden, te spiegelen aan de nieuwe tafel. Wijzigingen worden gespiegeld tijdens het schemawijzigingsproces. Als een rij aan de oorspronkelijke tabel wordt toegevoegd, wordt deze ook aan de nieuwe toegevoegd. Het emuleert de manier waarop MySQL tabellen intern wijzigt, maar het werkt op een kopie van de tabel die u wilt wijzigen. Het betekent dat de oorspronkelijke tabel niet is vergrendeld en dat klanten de gegevens erin kunnen blijven lezen en wijzigen.
Evenzo, als een rij wordt gewijzigd of verwijderd in de oude tabel, wordt deze ook toegepast in de nieuwe tabel. Vervolgens begint een achtergrondproces voor het kopiëren van gegevens (met LOW_PRIORITY INSERT) tussen de oude en de nieuwe tabel. Zodra de gegevens zijn gekopieerd, wordt RENAME TABLE uitgevoerd.
Een ander interessant hulpmiddel is gh-ost. Gh-ost maakt een tijdelijke tabel met het gewijzigde schema, net zoals pt-online-schema-change dat doet. Het voert INSERT-query's uit, die het volgende patroon gebruiken om gegevens van de oude naar de nieuwe tabel te kopiëren. Toch maakt het geen gebruik van triggers. Helaas kunnen triggers de oorzaak zijn van veel beperkingen. gh-ost gebruikt de binaire logstroom om tabelwijzigingen vast te leggen en past deze asynchroon toe op de spooktabel. Nadat we hebben geverifieerd dat gh-os onze schemawijziging correct kan uitvoeren, is het tijd om het daadwerkelijk uit te voeren. Houd er rekening mee dat u mogelijk handmatig oude tabellen moet verwijderen die door gh-os zijn gemaakt tijdens het testen van de migratie. Je kunt ook --initially-drop-ghost-table en --initially-drop-old-table vlaggen gebruiken om gh-ost te vragen het voor je te doen. Het laatste commando dat moet worden uitgevoerd is precies hetzelfde als dat we gebruikten om onze wijziging te testen, we hebben er zojuist --execute aan toegevoegd.
pt-online-schema-change en gh-ost zijn erg populair onder Galera-gebruikers. Toch heeft Galera enkele extra opties. De twee methoden Total Order Isolation (TOI) en Rolling Schema Upgrade (RSU) hebben zowel hun voor- als nadelen.
TOI - Dit is de standaard DDL-replicatiemethode. Het knooppunt dat de schrijfset voortbrengt, detecteert DDL tijdens het parseren en verzendt een replicatiegebeurtenis voor de SQL-instructie voordat de DDL-verwerking wordt gestart. Schema-upgrades worden uitgevoerd op alle clusterknooppunten in dezelfde totale volgorde, waardoor wordt voorkomen dat andere transacties worden doorgevoerd voor de duur van de bewerking. Deze methode is goed als u wilt dat uw online schema-upgrades repliceren via het cluster en het niet erg vindt om de hele tabel te vergrendelen (vergelijkbaar met hoe standaardschemawijzigingen plaatsvonden in MySQL).
SET GLOBAL wsrep_OSU_method='TOI';RSU - voer de schema-upgrades lokaal uit. Bij deze methode hebben uw schrijfbewerkingen alleen invloed op het knooppunt waarop ze worden uitgevoerd. De wijzigingen worden niet gerepliceerd naar de rest van het cluster. Deze methode is goed voor niet-conflicterende bewerkingen en vertraagt het cluster niet.
SET GLOBAL wsrep_OSU_method='RSU';Terwijl het knoop punt de schema-upgrade verwerkt, desynchroniseert het met het cluster. Wanneer het klaar is met het verwerken van de schema-upgrade, past het vertraagde replicatiegebeurtenissen toe en synchroniseert het zichzelf met het cluster. Dit kan een goede optie zijn om zware indexcreaties uit te voeren.
Conclusie
We hebben hier verschillende methoden gepresenteerd die u kunnen helpen bij het plannen van uw schemawijzigingen. Het hangt natuurlijk allemaal af van uw toepassing en zakelijke vereisten. U kunt uw veranderplan ontwerpen, noodzakelijke testen uitvoeren, maar de kans is klein dat er iets misgaat. Volgens de wet van Murphy - "zal er in elke situatie iets mis gaan, als je ze een kans geeft". Zorg er dus voor dat u verschillende manieren uitprobeert om deze wijzigingen door te voeren, en kies degene die u het prettigst vindt.