Hoe worden al die publieke opiniegegevens opgeslagen? We bekijken een datamodel van een opiniepeiling.
Iedereen wil weten wat het publiek denkt, van politici en bedrijven tot individuen die willen weten wat anderen over een bepaald onderwerp denken. Dit soort werk wordt meestal uitgevoerd door bureaus die gespecialiseerd zijn in dat soort onderzoek.
Vandaag bekijken we een datamodel dat zo'n bureau zou kunnen gebruiken om alle relevante pollgegevens op te slaan, van vragen en vooraf gedefinieerde antwoorden tot de daadwerkelijke feedback. Deze gegevens zouden later worden gebruikt om verschillende rapporten te maken. Laten we beginnen.
Idee
Polls kunnen overal worden gemaakt. Ze kunnen goed gepland zijn en een representatieve steekproef van het publiek bevatten (op basis van demografie). Of u kunt ze ter plaatse doen, b.v. als je verkiezingsuitslagen wilt voorspellen op basis van een steekproef (zoals een exitpoll), zou je mensen op het stembureau waarschijnlijk vragen hoe ze hebben gestemd.
Aan de andere kant, als u vóór de verkiezing dezelfde peiling wilt maken, selecteert u waarschijnlijk een steekproef en neemt u telefonisch of persoonlijk contact op met personen. Meestal zijn er maar een paar vragen voor dit soort peilingen - sommige om demografische gegevens te behandelen en andere om te bespreken waar we echt in geïnteresseerd zijn.
Peilingen kunnen ook veel complexer zijn, b.v. als u de publieke opinie over een bepaald product wilt weten, over alles, van de prestaties tot de verpakking.
In dit artikel zal ik niet bespreken hoe je een steekproef van mensen kunt selecteren; ik zal me eerder concentreren op de peiling zelf, de vragen en de reacties.
Gegevensmodel
Gegevensmodel voor publieke opiniebureaus
Het model bestaat uit drie vakgebieden:
PollsQuestions & AnswersResult
We beschrijven elk onderwerp in de volgorde waarin het wordt vermeld.
Polls
Voordat we vragen gaan stellen, moeten we definiëren waarin we geïnteresseerd zijn. We definiëren peilingen en vragenlijsten in deze sectie en voegen vervolgens vragen en antwoorden toe in de volgende.
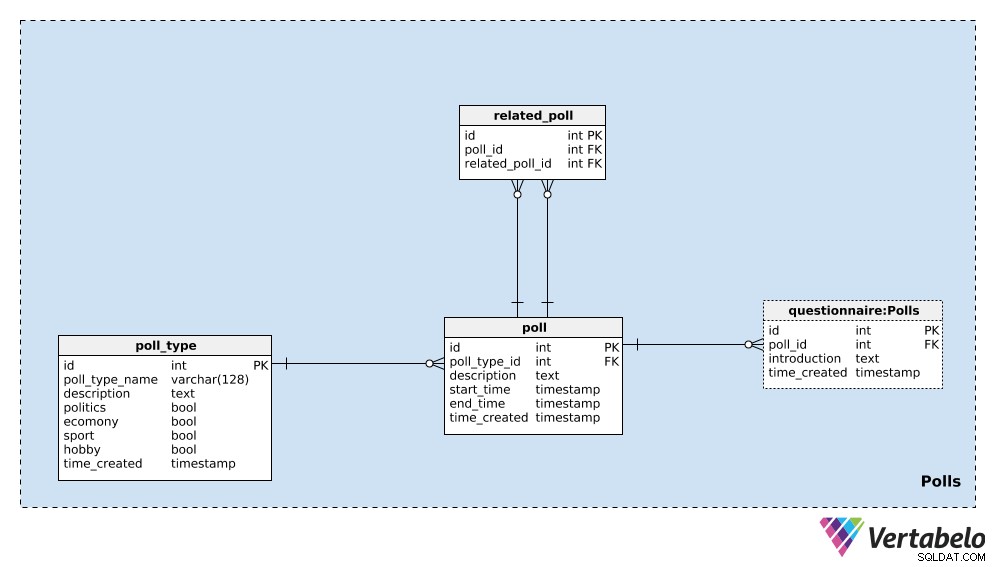
We beginnen met de poll_type woordenboek. We kunnen verwachten dat we peilingen van hetzelfde type meestal zullen herhalen. Het meest voorkomende type zijn waarschijnlijk verkiezingspeilingen, maar we willen onderweg nieuwe soorten peilingen kunnen toevoegen. Voor elk poll-type slaan we een UNIEKE poll_type_name op en gebruik de description attribuut om aanvullende details te geven.
Vier vlaggen – politics , economy , sport , en hobby – worden gebruikt om het type peiling aan te duiden. Een peiling kan betrekking hebben op een of meer van die onderwerpen; indien nodig kunnen we deze categorieën opsplitsen in een apart woordenboek en een veel-op-veel-relatie hebben tussen dat woordenboek en het poll_type tafel.
Het laatste kenmerk in deze tabel is time_created . Het geeft het moment aan waarop een rij in deze tabel wordt ingevoegd.
Het volgende dat we moeten doen is een enkele poll . Dit is een enkel geval, b.v. "Presidentsverkiezingen in de Verenigde Staten van 2020 – peiling van april 2020" . Voor elke peiling slaan we de volgende gegevens op:
poll_type_id– Een verwijzing naar hetpoll_type.description– Alle details met betrekking tot deze peiling, in tekstformaat.start_timeenend_time– De gedefinieerde begin- en eindtijden waarop deze peiling wordt afgenomen.time_created– Het actuele moment waarop deze poll is gemaakt.
Polls kunnen aan elkaar gerelateerd zijn. In het voorbeeld van de "Presidentsverkiezingen in de Verenigde Staten van 2020 – peiling van april 2020" , zouden we de volgende maand dezelfde peiling kunnen doen om de meest actuele meningen te zien. We zouden dit 'Presidentsverkiezingen in de Verenigde Staten van 2020 – peiling van mei 2020' . noemen . Deze twee peilingen zijn gerelateerd omdat hun resultaten trends laten zien. Om die relatie vast te stellen, gebruiken we de related_poll tafel in ons model. Het bevat alleen het UNIEKE paar poll_id – related_poll_id , ter aanduiding van de peiling en zijn voorganger.
Merk op dat we deze tabel kunnen gebruiken om alle peilingen op te slaan die op enigerlei wijze gerelateerd zijn, niet alleen voorgangers/opvolgers. Als we verschillende relaties wilden definiëren, zouden we een ander woordenboek moeten toevoegen, maar in dit artikel gaan we daar niet op in.
De laatste tabel in dit onderwerpgebied is de questionnaire tafel. In de meeste gevallen zal elke peiling precies één vragenlijst bevatten, maar ik wil de optie laten dat we er meer dan één zouden kunnen hebben indien nodig. Daarom heb ik een aparte tabel gebruikt. In deze tabel slaan we alleen de ID van de gerelateerde poll op (poll_id ), een introduction met een beschrijving van die vragenlijst en het tijdstempel waarop de record werd ingevoegd (time_created ).
Vragen en antwoorden
Nu zijn we klaar om alle details van de vragenlijst te maken. We kunnen ook alle vragen opsommen die we willen stellen, evenals alle vooraf gedefinieerde antwoorden.
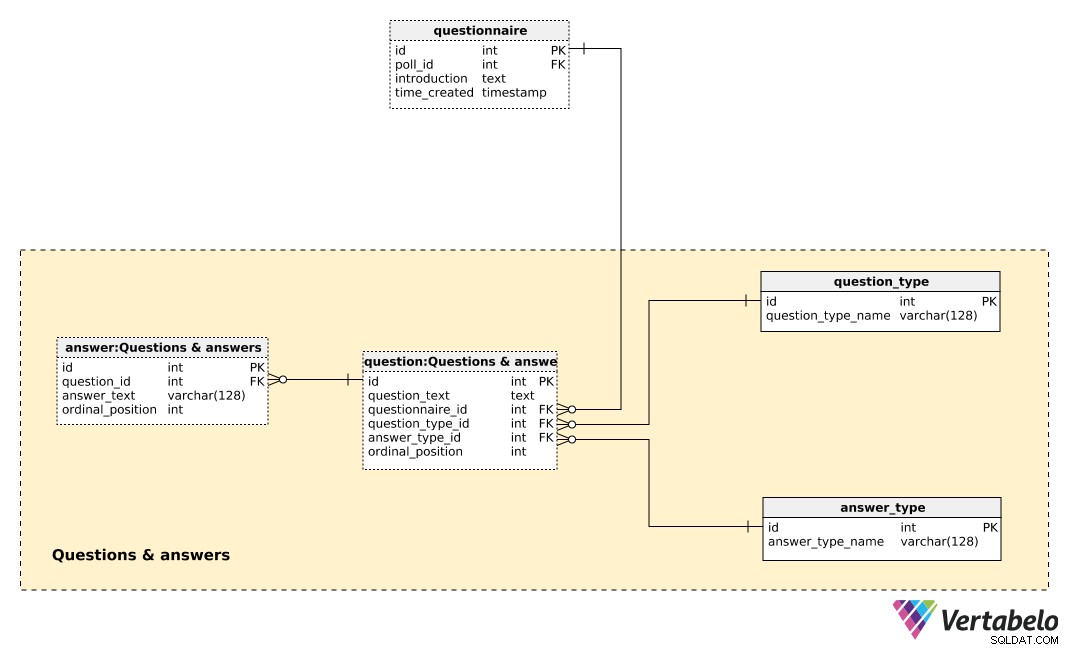
De centrale tabel in dit onderwerpgebied is de question tafel. Elke vraag wordt gedefinieerd door de volgende details:
question_text– Een tekst die wordt weergegeven aan elke persoon die wordt ondervraagd.questionnaire_id– Een referentie die de vragenlijst van deze vraag aangeeft.question_type_id– Een referentie die hetquestion_type, wat UNIEK wordt aangeduid met dequestion_type_name. Dit zijn in principe categorieën, b.v. "demografie", "opinie", "controle", enz. Hiermee zouden we demografische en opinievragen kunnen scheiden en een verband tussen beide kunnen vinden.answer_type_id– Een verwijzing naar het type antwoord dat voor deze vraag zal worden gebruikt. Elkeanswer_typeis UNIEK gedefinieerd door deanswer_type_nameen geeft aan hoe het antwoord wordt weergegeven. Sommige verwachte typen zijn "open", "lijst", "checkbox" en "meerdere".ordinal_position– Deze waarde geeft de positie van deze vraag in de vragenlijst aan. Samen met dequestionnaire_id, het vormt de alternatieve sleutel van deze tabel.
Een lijst met alle vooraf gedefinieerde antwoorden wordt opgeslagen in de answer tafel. Als het vraagtype niet open is (d.w.z. dat de persoon geen tekst invoert), hebben we een reeks vooraf gedefinieerde antwoorden. Voor elk antwoord definiëren we bij welke vraag het hoort (question_id ), de answer_text , en de ordinal_position van dat antwoord in die vraag. Wederom een UNIEK paar – deze keer question_id – ordinal_position – vormt de alternatieve sleutel van deze tabel.
Resultaat
In de vorige twee onderwerpgebieden hebben we alles gedefinieerd wat we nodig hebben om de poll te maken en vragen te gaan stellen. Nu moeten we een gegevensstructuur definiëren om werkelijke antwoorden op te slaan.
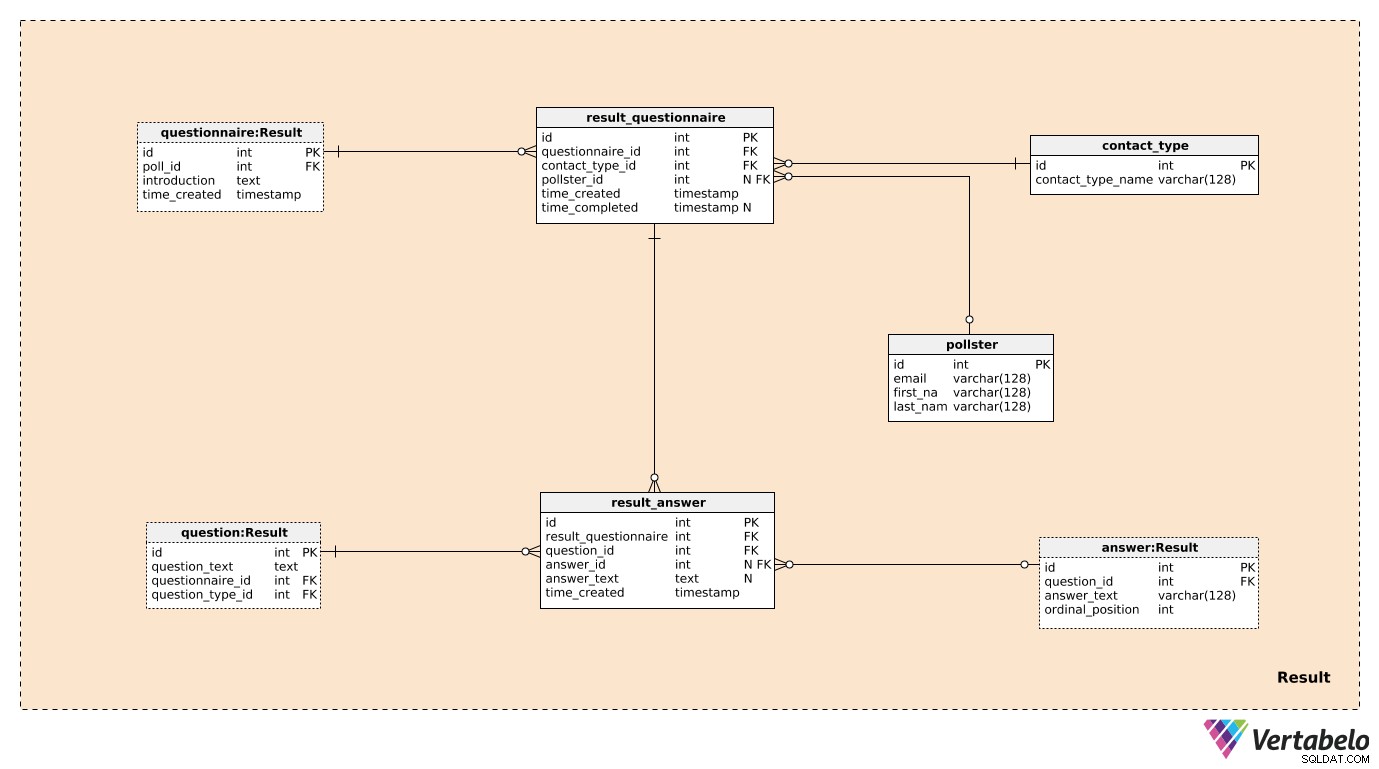
Drie van de zeven tabellen in het Result vakgebied werden eerder genoemd en beschreven. Dit zijn questionnaire , question , en answer . De overige vier tabellen worden gebruikt om op te slaan waar we echt in geïnteresseerd zijn.
We maken één record in de result_questionnaire tabel voor elke persoon die deelneemt aan de peiling. De questionnaire_id geef esus alle informatie over de betreffende peiling. De contact_type_id is een verwijzing naar het contact_type woordenboek. Waarden in deze tabel beschrijven de manier waarop we met deze persoon hebben gecommuniceerd. Deze waarden worden UNIEK gedefinieerd door de contact_type_name waarde en kan zoiets zijn als "telefoon", "persoonlijk", "e-mail", "webformulier", enz.
De pollster_id attribuut is een verwijzing naar de pollster tabel, die informatie geeft over wie die daadwerkelijke peiling heeft uitgevoerd. Voor elke pollster , slaan we alleen hun UNIEKE e-mailadres en hun first_name op en last_name . De time_created attribuut geeft de werkelijke tijd aan waarop dit record is gemaakt, terwijl de time_completed worden ingesteld op het moment dat dit onderzoek is voltooid. (Tot die tijd is het NULL).
De laatste tabel in het model is de result_answer tafel. Zoals de naam al doet vermoeden, slaan we hier de daadwerkelijke reacties op die we van enquêteurs hebben gekregen. Voor elk record in deze tabel hebben we:
result_questionnaire_id– Een verwijzing naar de relevante vragenlijst.question_id– Een verwijzing die de vraag aangeeft die door dit antwoord wordt beantwoord.answer_id– Een verwijzing naar het antwoord dat is gebruikt om deze vraag te beantwoorden. Dit kenmerk bevat een NULL-waarde wanneer de vraag van het type "open" is (omdat er geen vooraf gedefinieerde antwoorden waren om uit te kiezen).answer_text– De tekst die is ingevoegd om deze vraag te beantwoorden. Dit attribuut zal een waarde bevatten wanneer de vraag "open" was; in alle andere gevallen is het NULL.time_created– De werkelijke tijd waarop dit antwoord in ons systeem is ingevoerd.
Mogelijke verbeteringen
Tot nu toe hebben we besproken hoe we peilinggegevens kunnen opslaan. We hebben niet besproken wat we met de gegevens zouden doen nadat de peiling is gesloten. We kunnen verwachten dat we de oude gegevens in de toekomst niet meer nodig zullen hebben, althans niet in onze operationele database. Daarom kunnen we twee dingen doen:
- Sla een opiniepeilingoverzicht op in een aparte tabel in de operationele database. Dit zou dergelijke informatie tot onze beschikking houden als we wilden zien wat er gebeurde met een soortgelijke peiling.
- Sla alle peilinggegevens op in een back-updatabase die dezelfde structuur had als de operationele database. Hierdoor zouden we toegang hebben tot de details wanneer we ze nodig hadden.
We zouden ook een datawarehouse kunnen maken om enquêteresultaten op te slaan, maar dat zou niet nodig zijn als we de taken die in de twee opsommingstekens worden beschreven al hadden uitgevoerd.
Wat vindt u van ons gegevensmodel voor opiniepeilingen?
We willen graag uw mening horen over wat we zouden kunnen veranderen om het datamodel van de opiniepeiling te verbeteren. Heb je ervaring in de branche? Denk je dat we iets gemist hebben? Zou je iets toevoegen of verwijderen? Ik kijk uit naar uw mening.