Camera's, draaideuren, liften, temperatuursensoren, alarmen - al deze apparaten produceren een groot aantal onderling verbonden signalen die verband houden met gebeurtenissen om ons heen. Stel je nu voor dat jij de persoon bent die statussen moet volgen, realtime rapporten moet produceren en voorspellingen moet doen op basis van al deze signaalgegevens. Om dit te doen, moet u eerst die gegevens opslaan. Een datamodel dat dergelijke signaalverwerking ondersteunt, is het onderwerp van het artikel van vandaag.
De eenvoudigste manier om inkomende signalen op te slaan, is door er simpelweg een tekstuele weergave van op te slaan in één enorme lijst. Deze aanpak zou ons in staat stellen om snel invoegingen uit te voeren, maar updates zouden problematisch zijn. Ook zou zo'n model niet worden genormaliseerd, en daarom zullen we niet in die richting gaan.
We zullen een genormaliseerd gegevensmodel maken dat kan worden gebruikt om de gegevens op te slaan die door verschillende apparaten zijn gegenereerd en ook om te definiëren hoe de apparaten aan elkaar gerelateerd zijn. Een dergelijk model zou alles wat we nodig hebben efficiënt kunnen opslaan en zou ook kunnen worden gebruikt voor analyse en voorspellende analyses.
Gegevensmodel
Het datamodel voor signaalverwerking
Het model bestaat uit drie vakgebieden:
ComplexesInstallations & DevicesSignals & Events
We zullen elk van deze onderwerpen beschrijven in de volgorde waarin ze worden vermeld.
Complexen
Bij het maken van dit datamodel ging ik ervan uit dat we het gaan gebruiken om bij te houden wat er in grotere complexen gebeurt. Complexen variëren in grootte van een eenpersoonskamer tot een winkelcentrum. Het is belangrijk dat elk complex ten minste één apparaat/sensor heeft, maar waarschijnlijk zullen er nog veel meer zijn.
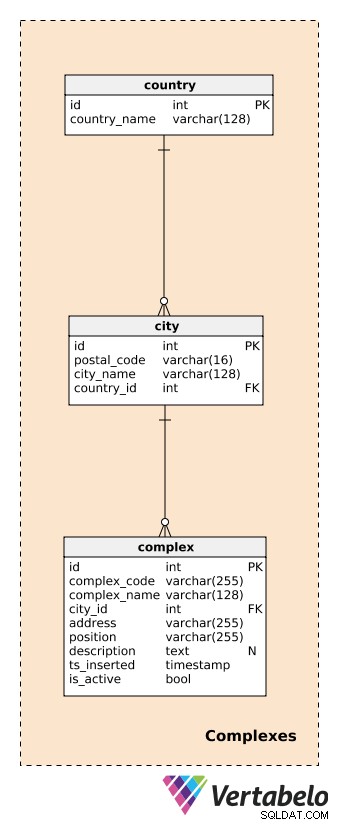
Voordat we complexen gaan beschrijven, moeten we de tabellen definiëren die landen en steden behandelen. Deze geven een vrij gedetailleerde beschrijving van de locatie van elk complex.
Voor elk country , bewaren we de UNIEKE country_name; voor elke city , slaan we de UNIEKE combinatie van postal_code op , city_name , en country_id . Ik zal hier niet in detail treden, en we gaan ervan uit dat elke stad slechts één postcode heeft. In werkelijkheid zullen de meeste steden meer dan één postcode hebben; in dat geval kunnen we de hoofdcode voor elke stad gebruiken.
Een complex is het daadwerkelijke gebouw of de locatie waar gegevensgenererende apparaten zijn geïnstalleerd. Zoals eerder vermeld, kunnen complexen variëren van een eenpersoonskamer of een meetstation tot veel grotere plaatsen zoals parkeerplaatsen, winkelcentra, bioscopen, enz. Ze zijn het onderwerp van onze analyse. We willen realtime kunnen volgen wat er op het complexe niveau gebeurt en later rapportages en analyses kunnen maken. Voor elk complex definiëren we een:
complex_code– Een UNIEKE ID voor elk complex. Hoewel we een afzonderlijk primair sleutelkenmerk hebben (id) voor deze tabel kunnen we verwachten dat we voor elk complex een andere identificatiecode van een ander systeem zullen erven.complex_name– Een naam die wordt gebruikt om dat complex te beschrijven. In het geval van winkelcentra en bioscopen zou dit hun huidige en bekende naam kunnen zijn; voor een meetstation zouden we een generieke naam kunnen gebruiken.city_id– Een verwijzing naar de stad waar het complex zich bevindt.address– Het fysieke adres van dat complex.position– De positie van het complex (d.w.z. geografische coördinaten) gedefinieerd in tekstformaat.description– Een tekstuele beschrijving die dit complex beter beschrijft.ts_inserted– Een tijdstempel wanneer deze record is ingevoegd.is_active– Een booleaanse waarde die aangeeft of dit complex nog steeds actief is of niet.
Installaties en apparaten
Nu komen we dichter bij het hart van ons model. We zullen waarschijnlijk een aantal apparaten in elk complex hebben geïnstalleerd. We zullen deze apparaten vrijwel zeker ook groeperen op basis van hun doel, bijv. we zouden camera's, deursensoren en een motor die wordt gebruikt om een deur te openen en te sluiten in een groep kunnen plaatsen, omdat ze samenwerken.
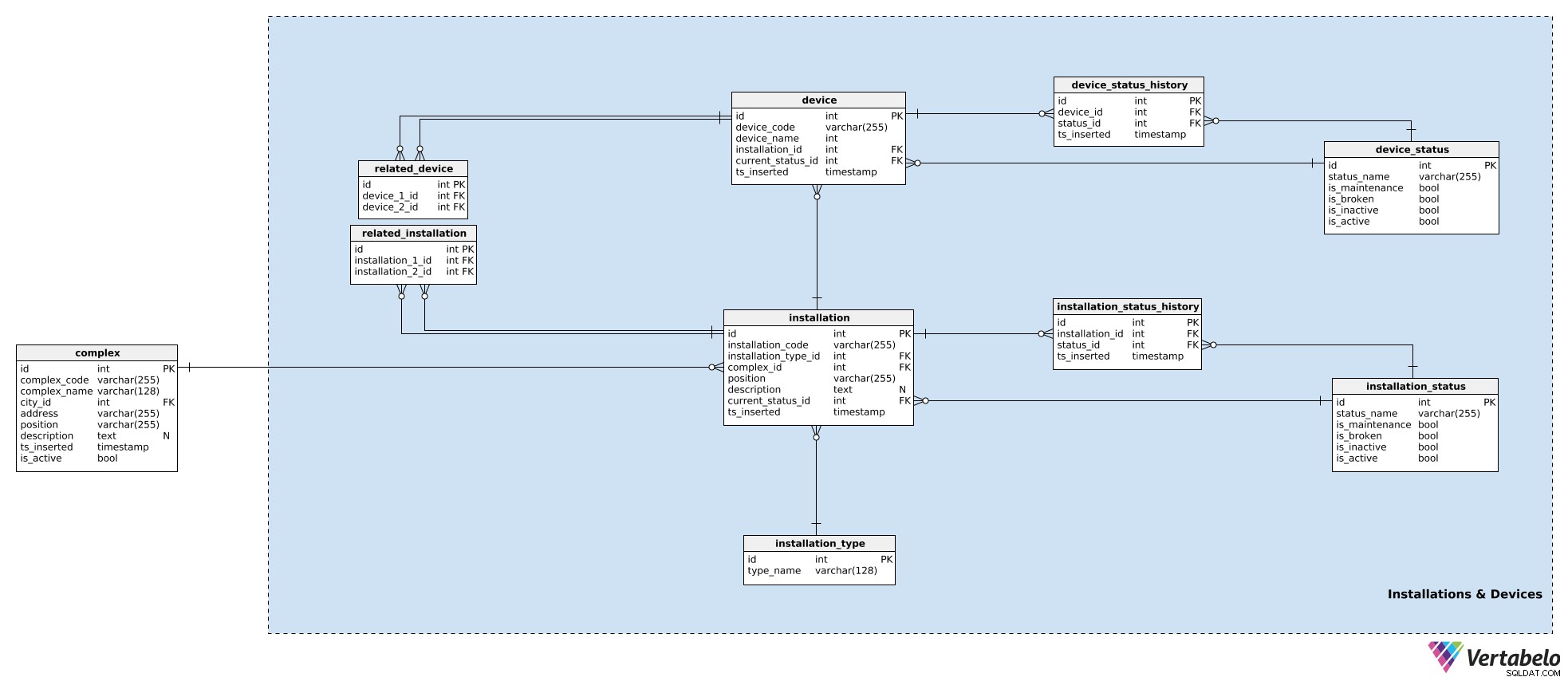
In ons model worden apparaten die samenwerken in één complex gegroepeerd in installaties. Dit kunnen voordeuren, roltrappen, temperatuursensoren, enz. zijn. Voor elke installatie slaan we de volgende details op in de installation tafel:
installation_code– Een UNIEKE code die wordt gebruikt om die installatie aan te duiden.installation type_id– Een verwijzing naar hetinstallation_typewoordenboek. Dit woordenboek slaat alleen een UNIEKEtype_name. op attribuut dat het type beschrijft, b.v. roltrap, lift.complex_id– Een verwijzing naar hetcomplexdie installatie behoort.position– De coördinaten, in tekstformaat, van die installatie in het complex.description– Een tekstuele beschrijving van die installatie.current_status_id– Een verwijzing naar de huidige status (van deinstallation_statustabel) van die installatie.ts_inserted– Een tijdstempel wanneer dit record in ons systeem is ingevoegd.
We hebben de installatiestatussen al genoemd. Een lijst met alle mogelijke statussen wordt opgeslagen in de installation_status woordenboek. Elke status wordt UNIEK gedefinieerd door zijn status_name . Daarnaast slaan we vlaggen op die aangeven of die status, indien gebruikt, impliceert dat de installatie is_broken , is_inactive , is_maintenance , of is_active . Er mag slechts één van deze vlaggen tegelijk worden ingesteld.
We hebben al een huidige status aan de installatie toegewezen. Als we willen bijhouden wat er met het apparaat gebeurt, moeten we ook de geschiedenis ervan opslaan. Om dat te doen, gebruiken we nog een tabel, installation_status_history . Voor elk record slaan we hier verwijzingen naar de gerelateerde installatie en status op, evenals het moment (ts_inserted ) wanneer die status werd toegekend.
Installaties maken deel uit van onze complexen. Hoewel elke installatie een enkele entiteit is, kan deze toch verband houden met andere installaties. (Een videosysteem bij de vooringang van een winkelcentrum is bijvoorbeeld duidelijk gerelateerd aan de voordeuren van het winkelcentrum - mensen worden eerst door de camera gezien en daarna gaan de deuren open.) Als we deze relaties willen bijhouden, slaan we ze op in de related_installation tafel. Houd er rekening mee dat deze tabel alleen UNIEKE paren van twee sleutels bevat, die beide verwijzen naar de installation tafel.
Dezelfde logica wordt gebruikt om apparaten op te slaan. Apparaten zijn losse stukjes hardware die de signalen produceren waarin we geïnteresseerd zijn. Terwijl installaties bij complexen horen, horen apparaten bij installaties. Voor elk device , we slaan op:
device_code- EEN UNIEKE manier om elk apparaat aan te duiden.device_name– Een naam voor dit apparaat.installation_id– Een verwijzing naar de installatie waartoe dit apparaat behoort.current_status_id– De huidige status van het apparaat.ts_inserted– Een tijdstempel wanneer deze record is ingevoegd.
Statussen worden op dezelfde manier behandeld. We gebruiken de device_status tabel om een lijst van alle mogelijke apparaatstatussen op te slaan. Deze tabel heeft dezelfde structuur als installation_status en de attributen worden op dezelfde manier gebruikt. De reden voor het hebben van de twee afzonderlijke statuswoordenboeken is dat apparaten en hun installaties verschillende statussen kunnen hebben - althans in naam.
De huidige status wordt opgeslagen in de device.current_status_id attribuut en de statusgeschiedenis wordt opgeslagen in de device_status_history tafel. Voor elk record hier slaan we relaties op met het apparaat en de status, evenals het moment waarop dit record werd ingevoegd.
De laatste tabel in dit onderwerpgebied is de related_device tafel. Hoewel het vrij duidelijk is dat alle apparaten binnen dezelfde installatie nauw verwant zijn, wil ik de mogelijkheid hebben om twee apparaten die bij een installatie horen te relateren. We doen dat door hun twee apparaat-ID's in deze tabel op te slaan.
Signalen en gebeurtenissen
Nu zijn we klaar voor het hart van het hele model.
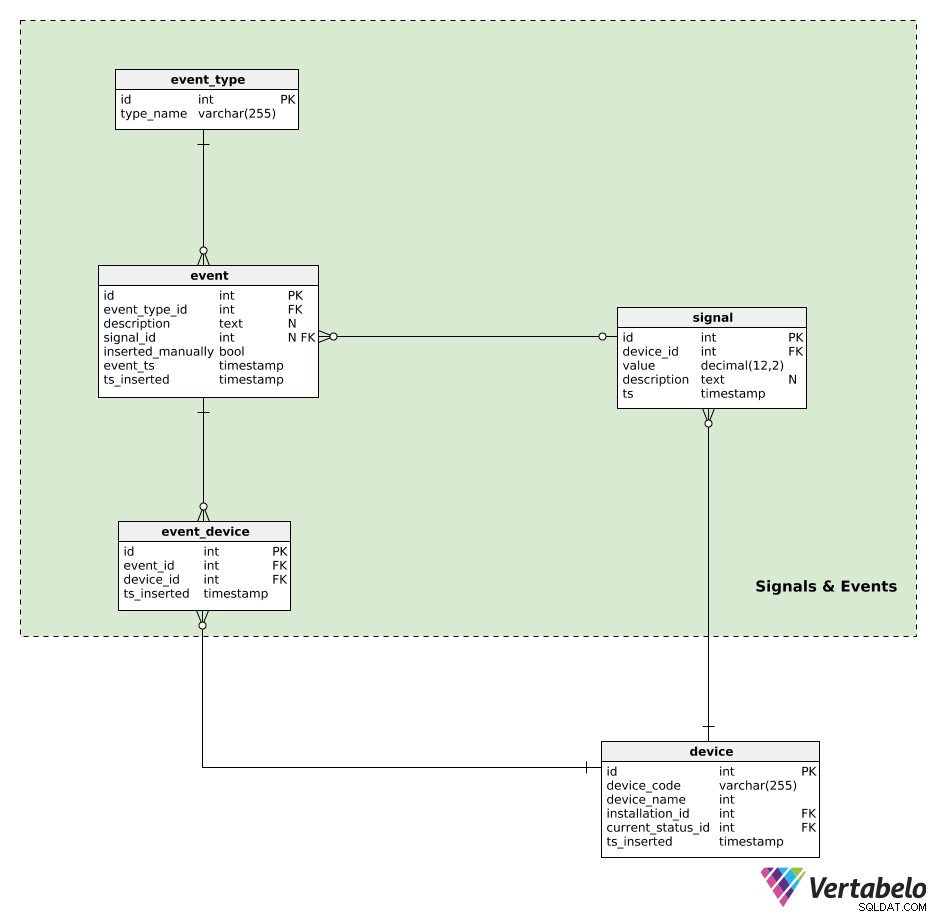
Apparaten genereren signalen. Alle signaalgegevens worden bewaard in het signal tafel. Voor elk signaal slaan we het volgende op:
device_id– Een verwijzing naar het apparaat dat dat signaal heeft gegenereerd.value– De numerieke waarde van dat signaal.description– Een tekstuele waarde die aanvullende parameters kan bevatten (bijv. signaaltype, waarden, gebruikte meeteenheid) met betrekking tot dat ene signaal. Deze gegevens worden opgeslagen in een JSON-achtig formaat.ts– Een tijdstempel wanneer dit signaal in de tabel werd ingevoegd.
We kunnen verwachten dat deze tafel extreem intensief zal worden gebruikt, met een groot aantal inserts per seconde. Daarom moet het databaseonderhoud gericht zijn op het bijhouden van de grootte van deze tabel.
Het laatste wat ik wil doen, is gebeurtenissen aan ons datamodel toevoegen. Gebeurtenissen kunnen automatisch worden gegenereerd door een signaal of handmatig worden ingevoegd. Een automatisch gegenereerde gebeurtenis zou kunnen zijn "deur open gedurende 5 minuten", terwijl een handmatig ingevoerde gebeurtenis zou kunnen zijn "het apparaat moest worden uitgeschakeld vanwege dit signaal". Het hele idee is om acties op te slaan die zijn opgetreden als gevolg van apparaatgedrag. Later zouden we deze gebeurtenissen kunnen gebruiken bij het uitvoeren van een apparaatgedragsanalyse.
Evenementen worden gegranuleerd door event_type . Elk type wordt UNIEK gedefinieerd door zijn type_name .
Alle automatisch gegenereerde of handmatig ingevoegde gebeurtenissen worden opgenomen in de event tafel. Voor elke record hier slaan we op:
event_type_id– Een verwijzing naar het gerelateerde gebeurtenistype.description– Een tekstuele beschrijving van die gebeurtenis.signal_id– Een verwijzing naar het signaal, indien aanwezig, dat de gebeurtenis heeft veroorzaakt.inserted_manually– Een vlag die aangeeft of dit record handmatig is ingevoegd of niet.event_tsents_inserted–Tijdstempels wanneer deze gebeurtenis daadwerkelijk heeft plaatsgevonden en wanneer er een record van is ingevoegd. Deze twee kunnen verschillen, vooral wanneer gebeurtenisrecords handmatig worden ingevoegd.
De laatste tabel in ons model is de event_device tafel. Deze tabel wordt gebruikt om gebeurtenissen te relateren aan alle betrokken apparaten. Voor elk record slaan we het UNIEKE paar event_id op – device_id en het tijdstempel toen de record werd ingevoegd.
Wat vindt u van ons signaalverwerkingsgegevensmodel?
Vandaag hebben we een vereenvoudigd gegevensmodel geanalyseerd dat we zouden kunnen gebruiken om signalen te volgen van een reeks apparaten die op verschillende locaties zijn geïnstalleerd. Het model zelf zou voldoende moeten zijn om alles op te slaan wat we nodig hebben om statussen bij te houden en analyses uit te voeren. Toch zijn er veel verbeteringen mogelijk. Wat zouden we kunnen toevoegen? Vertel het ons in de reacties hieronder.