Galera Cluster wordt geleverd met veel opvallende functies die niet beschikbaar zijn in standaard MySQL-replicatie (of groepsreplicatie); automatische node-provisioning, echte multi-master met conflictoplossing en automatische failover. Er zijn ook een aantal beperkingen die mogelijk van invloed kunnen zijn op de clusterprestaties. Gelukkig zijn er oplossingen als u zich hier niet van bewust bent. En als u het goed doet, kunt u de impact van deze beperkingen minimaliseren en de algehele prestaties verbeteren.
We hebben eerder veel tips en trucs behandeld met betrekking tot Galera Cluster, waaronder het draaien van Galera op AWS Cloud. Deze blogpost duikt duidelijk in de prestatieaspecten, met voorbeelden om het meeste uit Galera te halen.
Replicatie-payload
Een beetje introductie - Galera repliceert schrijfsets tijdens de vastleggingsfase, waarbij schrijfsets synchroon worden overgedragen van het oorspronkelijke knooppunt naar de ontvangerknooppunten via de wsrep-replicatieplug-in. Deze plug-in certificeert ook schrijfsets op de ontvangerknooppunten. Als het certificeringsproces slaagt, keert het als OK terug naar de client op het oorspronkelijke knooppunt en wordt het op een later tijdstip asynchroon toegepast op de ontvangende knooppunten. Anders wordt de transactie teruggedraaid op het oorspronkelijke knooppunt (retourfout naar de client) en worden de schrijfsets die zijn overgedragen naar de ontvangerknooppunten verwijderd.
Een schrijfset bestaat uit schrijfbewerkingen binnen een transactie die de databasestatus wijzigen. In Galera Cluster, autocommit is standaard ingesteld op 1 (ingeschakeld). Letterlijk, elk SQL-statement dat in Galera Cluster wordt uitgevoerd, wordt als transactie ingesloten, tenzij u expliciet begint met BEGIN, START TRANSACTION of SET autocommit=0. Het volgende diagram illustreert de inkapseling van een enkele DML-instructie in een schrijfset:
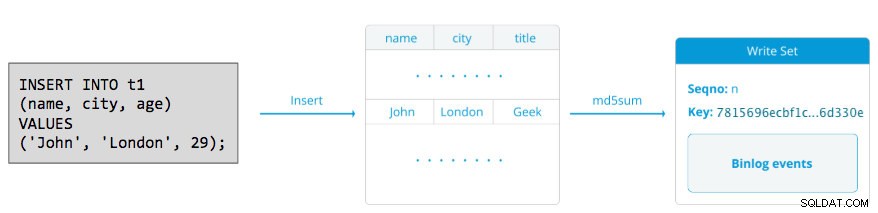
Voor DML (INSERT, UPDATE, DELETE..) bestaat de writeset-payload uit de binaire loggebeurtenissen voor een bepaalde transactie, terwijl voor DDL's (ALTER, GRANT, CREATE..) de writeset-payload de DDL-instructie zelf is. Voor DML's moet de schrijfset worden gecertificeerd tegen conflicten op het ontvangerknooppunt, terwijl voor DDL's (afhankelijk van wsrep_osu_method , standaard ingesteld op TOI), voert het clustercluster de DDL-instructie uit op alle knooppunten in dezelfde totale volgorde, waardoor andere transacties niet kunnen worden doorgevoerd terwijl de DDL wordt uitgevoerd (zie ook RSU). Simpel gezegd, Galera Cluster gaat anders om met DDL- en DML-replicatie.
Retourtijd
Over het algemeen bepalen de volgende factoren hoe snel Galera een schrijfset kan repliceren van een oorspronkelijk knooppunt naar alle ontvangerknooppunten:
- Retourtijd (RTT) naar het verste knooppunt in het cluster vanaf het oorspronkelijke knooppunt.
- De grootte van een schrijfset die moet worden overgedragen en gecertificeerd voor conflict op het ontvangerknooppunt.
Als we bijvoorbeeld een Galera-cluster met drie knooppunten hebben en een van de knooppunten bevindt zich op 10 milliseconden (0,01 seconde), is het zeer onwaarschijnlijk dat u meer dan 100 keer per seconde naar dezelfde rij kunt schrijven zonder conflict. Er is een populair citaat van Mark Callaghan dat dit gedrag vrij goed beschrijft:
"[In een Galera-cluster] kan een bepaalde rij niet meer dan één keer per RTT worden gewijzigd"
Om de RTT-waarde te meten, voert u eenvoudig een ping uit op het oorspronkelijke knooppunt naar het verste knooppunt in het cluster:
$ ping 192.168.55.173 # the farthest nodeWacht een paar seconden (of minuten) en beëindig de opdracht. De laatste regel van het gedeelte met pingstatistieken is wat we zoeken:
--- 192.168.55.172 ping statistics ---
65 packets transmitted, 65 received, 0% packet loss, time 64019ms
rtt min/avg/max/mdev = 0.111/0.431/1.340/0.240 msDe max waarde is 1,340 ms (0,00134s) en we moeten deze waarde nemen bij het schatten van het minimum transacties per seconde (tps) voor dit cluster. Het gemiddelde waarde is 0,431 ms (0,000431s) en we kunnen gebruiken om het gemiddelde te schatten tps while min waarde is 0,111ms (0,000111s) die we kunnen gebruiken om het maximum . te schatten tps. De mdev geeft aan hoe de RTT-samples werden verdeeld vanaf het gemiddelde. Lagere waarde betekent stabielere RTT.
Daarom kunnen transacties per seconde worden geschat door RTT (in seconden) te delen in 1 seconde:

Resulterend,
- Minimale tps:1 / 0,00134 (max. RTT) =746,26 ~ 746 tps
- Gemiddelde tps:1 / 0,000431 (gem. RTT) =2320,19 ~ 2320 tps
- Maximale tps:1 / 0,000111 (min RTT) =9009.01 ~ 9009 tps
Houd er rekening mee dat dit slechts een schatting is om te anticiperen op de replicatieprestaties. Er is niet veel dat we kunnen doen om dit aan de databasekant te verbeteren, als alles eenmaal is geïmplementeerd en draait. Behalve als u de databaseservers dichter bij elkaar verplaatst of migreert om de RTT tussen knooppunten te verbeteren of de netwerkrandapparatuur of -infrastructuur te upgraden. Dit vereist een onderhoudsperiode en een goede planning.
Grote transacties opdelen
Een andere factor is de transactiegrootte. Nadat de schrijfset is overgedragen, vindt er een certificeringsproces plaats. Certificering is een proces om te bepalen of het knooppunt de schrijfset kan toepassen. Galera genereert MD5 checksum pseudo-sleutels van elke volledige rij. De kosten van certificering zijn afhankelijk van de grootte van de schrijfset, wat zich vertaalt in een aantal unieke sleutelzoekopdrachten in de certificeringsindex (een hashtabel). Als u bijvoorbeeld 500.000 rijen in één transactie bijwerkt:
# a 500,000 rows table
mysql> UPDATE mydb.settings SET success = 1;Het bovenstaande genereert een enkele schrijfset met 500.000 binaire loggebeurtenissen erin. Deze enorme schrijfset is niet groter dan wsrep_max_ws_size (standaard op 2 GB), zodat het door de Galera-replicatie-plug-in wordt overgedragen naar alle knooppunten in het cluster, waarbij deze 500.000 rijen op de ontvangerknooppunten worden gecertificeerd voor eventuele conflicterende transacties die zich nog in de slave-wachtrij bevinden. Ten slotte wordt de certificeringsstatus teruggestuurd naar de groepsreplicatie-plug-in. Hoe groter de transactieomvang, hoe groter het risico dat deze in conflict komt met andere transacties die van een andere master afkomstig zijn. Conflicterende transacties verspillen serverbronnen en veroorzaken een enorme terugdraaiing naar het oorspronkelijke knooppunt. Merk op dat een rollback-bewerking in MySQL veel langzamer en minder geoptimaliseerd is dan de commit-bewerking.
De bovenstaande SQL-instructie kan worden herschreven in een meer Galera-vriendelijke instructie met behulp van een eenvoudige lus, zoals in het onderstaande voorbeeld:
(bash)$ for i in {1..500}; do \
mysql -uuser -ppassword -e "UPDATE mydb.settings SET success = 1 WHERE success != 1 LIMIT 1000"; \
sleep 2; \
doneHet bovenstaande shell-commando zou 1000 rijen per transactie 500 keer bijwerken en 2 seconden wachten tussen uitvoeringen. U kunt ook een opgeslagen procedure of andere middelen gebruiken om een vergelijkbaar resultaat te bereiken. Als het herschrijven van de SQL-query geen optie is, geeft u de toepassing de opdracht om de grote transactie uit te voeren tijdens een onderhoudsperiode om het risico op conflicten te verkleinen.
Voor grote verwijderingen kunt u overwegen om pt-archiver uit de Percona Toolkit te gebruiken - een taak met weinig impact, alleen voorwaarts om oude gegevens uit de tabel te knabbelen zonder dat dit veel invloed heeft op OLTP-query's.
Parallelle slavedraden
In Galera is de applier een multithreaded proces. Applier is een thread die binnen Galera wordt uitgevoerd om de binnenkomende schrijfsets van een ander knooppunt toe te passen. Dat betekent dat het voor alle ontvangers mogelijk is om meerdere DML-bewerkingen tegelijkertijd uit te voeren die rechtstreeks van het oorspronkelijke (master) knooppunt komen. Galera parallelle replicatie wordt alleen toegepast op transacties wanneer dit veilig kan. Het verbetert de kans dat het knooppunt synchroniseert met het oorspronkelijke knooppunt. De replicatiesnelheid is echter nog steeds beperkt tot RTT- en schrijfsetgrootte.
Om hier het beste uit te halen, moeten we twee dingen weten:
- Het aantal cores dat de server heeft.
- De waarde van wsrep_cert_deps_distance status.
De status wsrep_cert_deps_distance vertelt ons de potentiële mate van parallellisatie. Het is de waarde van de gemiddelde afstand tussen de hoogste en laagste seqno-waarden die mogelijk parallel kan worden toegepast. U kunt de wsrep_cert_deps_distance . gebruiken statusvariabele om het maximale aantal mogelijke slave-threads te bepalen. Houd er rekening mee dat dit een gemiddelde waarde over de tijd is. Om een goede waarde te krijgen, moet u dus het cluster raken met schrijfbewerkingen via testwerkbelasting of benchmark totdat u een stabiele waarde ziet verschijnen.
Om het aantal kernen te krijgen, kunt u eenvoudig de volgende opdracht gebruiken:
$ grep -c processor /proc/cpuinfo
4In het ideale geval is 2, 3 of 4 threads van slave-applier per CPU-kern een goed begin. De minimumwaarde voor de slave-threads moet dus 4 x het aantal CPU-kernen zijn en mag de wsrep_cert_deps_distance niet overschrijden. waarde:
MariaDB [(none)]> SHOW STATUS LIKE 'wsrep_cert_deps_distance';
+--------------------------+----------+
| Variable_name | Value |
+--------------------------+----------+
| wsrep_cert_deps_distance | 48.16667 |
+--------------------------+----------+U kunt het aantal slave-applierthreads regelen met wsrep_slave_thread variabel. Ook al is dit een dynamische variabele, alleen het verhogen van het aantal zou direct effect hebben. Als u de waarde dynamisch verlaagt, zou het enige tijd duren voordat de toepassingsthread wordt afgesloten nadat deze is toegepast. Een aanbevolen waarde ligt tussen 16 en 48:
mysql> SET GLOBAL wsrep_slave_threads = 48;Houd er rekening mee dat om parallelle slave-threads te laten werken, het volgende moet worden ingesteld (wat meestal vooraf is geconfigureerd voor Galera Cluster):
innodb_autoinc_lock_mode=2Galera-cache (gcache)
Galera gebruikt een vooraf toegewezen bestand met een specifieke grootte genaamd gcache, waarbij een Galera-knooppunt een kopie van schrijfsets in circulaire bufferstijl bewaart. Standaard is de grootte 128 MB, wat vrij klein is. Incremental State Transfer (IST) is een methode om een joiner voor te bereiden door alleen de ontbrekende schrijfsets te verzenden die beschikbaar zijn in de gcache van de donor. IST is sneller dan state snapshot transfer (SST), het is niet-blokkerend en heeft geen significante invloed op de prestaties van de donor. Het zou waar mogelijk de voorkeursoptie moeten zijn.
IST kan alleen worden bereikt als alle wijzigingen die door de joiner zijn gemist, nog steeds in het gcache-bestand van de donor staan. De aanbevolen instelling hiervoor is om zo groot te zijn als de hele MySQL-dataset. Als de schijfruimte beperkt of kostbaar is, is het bepalen van de juiste grootte van de gcache-grootte cruciaal, omdat dit de gegevenssynchronisatieprestaties tussen Galera-knooppunten kan beïnvloeden.
De onderstaande verklaring geeft ons een idee van de hoeveelheid gegevens die door Galera worden gerepliceerd. Voer de volgende instructie uit op een van de Galera-knooppunten tijdens piekuren (getest op MariaDB>10.0 en PXC>5.6, galera>3.x):
mysql> SET @start := (SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME LIKE 'WSREP%bytes'); do sleep(60); SET @end := (SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME LIKE 'WSREP%bytes'); SET @gcache := (SELECT SUBSTRING_INDEX(SUBSTRING_INDEX(@@GLOBAL.wsrep_provider_options,'gcache.size = ',-1), 'M', 1)); SELECT ROUND((@end - @start),2) AS `MB/min`, ROUND((@end - @start),2) * 60 as `MB/hour`, @gcache as `gcache Size(MB)`, ROUND(@gcache/round((@end - @start),2),2) as `Time to full(minutes)`;
+--------+---------+-----------------+-----------------------+
| MB/min | MB/hour | gcache Size(MB) | Time to full(minutes) |
+--------+---------+-----------------+-----------------------+
| 7.95 | 477.00 | 128 | 16.10 |
+--------+---------+-----------------+-----------------------+
We kunnen schatten dat de Galera-node ongeveer 16 minuten downtime kan hebben, zonder dat SST nodig is om deel te nemen (tenzij Galera de joiner-status niet kan bepalen). Als dit te kort is en u voldoende schijfruimte op uw nodes heeft, kunt u de wsrep_provider_options="gcache.size=
Het wordt ook aanbevolen om gcache.recover=yes . te gebruiken in wsrep_provider_options (Galera>3.19), waarbij Galera zal proberen het gcache-bestand bij het opstarten in een bruikbare staat te herstellen in plaats van het te verwijderen, waardoor de mogelijkheid om IST te hebben behouden blijft en SST zoveel mogelijk wordt vermeden. Codership en Percona hebben dit uitgebreid besproken in hun blogs. IST is altijd de beste methode om te synchroniseren nadat een knoop punt zich weer bij het cluster heeft aangesloten. Het is 50% sneller dan xtrabackup of mariabackup en 5x sneller dan mysqldump.
Asynchrone slaaf
Galera-knooppunten zijn nauw aan elkaar gekoppeld, waarbij de replicatieprestaties net zo snel zijn als het langzaamste knooppunt. Galera gebruikt een stroomcontrolemechanisme om de replicatiestroom tussen leden te regelen en eventuele slaafvertragingen te elimineren. De replicatie kan op elk knooppunt snel of langzaam zijn en wordt automatisch aangepast door Galera. Als je meer wilt weten over flow control, lees dan deze blogpost van Jay Janssen van Percona.
In de meeste gevallen zijn zware bewerkingen zoals langdurige analyse (leesintensief) en back-ups (leesintensief, vergrendeling) vaak onvermijdelijk, wat de clusterprestaties mogelijk zou kunnen verslechteren. De beste manier om dit soort zoekopdrachten uit te voeren, is door ze naar een losgekoppelde replicaserver te sturen, bijvoorbeeld een asynchrone slave.
Een asynchrone slave repliceert vanaf een Galera-knooppunt met behulp van het standaard MySQL-protocol voor asynchrone replicatie. Er is geen limiet aan het aantal slaves dat op één Galera-node kan worden aangesloten en het is ook mogelijk om deze uit te ketenen met een tussenliggende master. MySQL-bewerkingen die op deze server worden uitgevoerd, hebben geen invloed op de clusterprestaties, afgezien van de initiële synchronisatiefase waarbij een volledige back-up moet worden gemaakt op de Galera-node om de slave te stagen voordat de replicatiekoppeling tot stand wordt gebracht (hoewel u met ClusterControl de asynchrone eerst slaaf van een bestaande back-up, voordat u deze op het cluster aansluit).
GTID (Global Transaction Identifier) biedt een betere toewijzing van transacties tussen knooppunten en wordt ondersteund in MySQL 5.6 en MariaDB 10.0. Met GTID wordt de failover-operatie op een slave naar een andere master (een ander Galera-knooppunt) vereenvoudigd, zonder dat het exacte logbestand en de exacte positie moeten worden uitgezocht. Galera heeft ook een eigen GTID-implementatie, maar deze twee zijn onafhankelijk van elkaar.
Het uitschalen van een asynchrone slave is één klik verwijderd als u de functie ClusterControl -> Replicatie-slave toevoegen gebruikt:
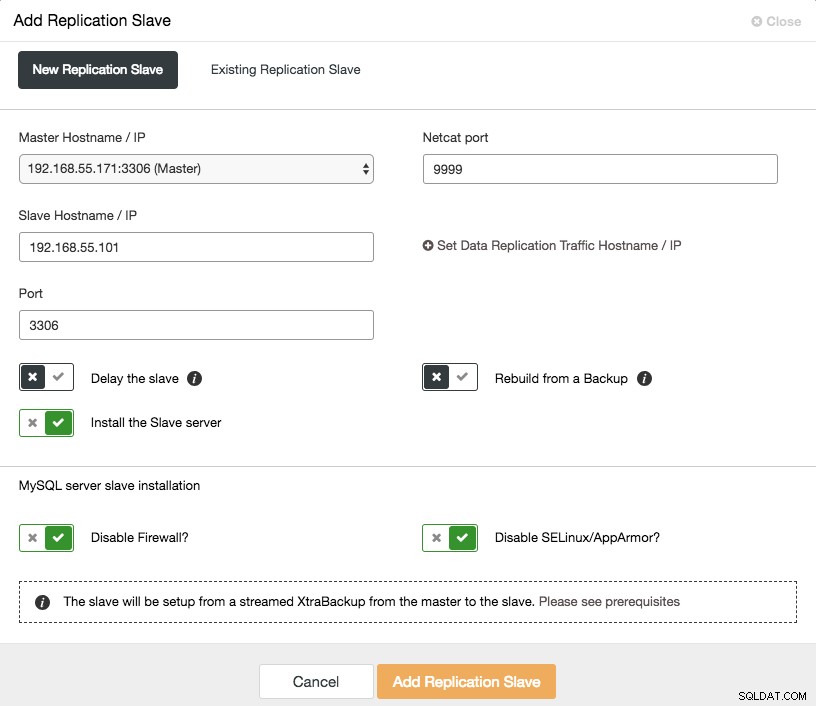
Houd er rekening mee dat binaire logs moeten zijn ingeschakeld op de master (de gekozen Galera-node) voordat we verder kunnen gaan met deze setup. We hebben in dit vorige bericht ook de handmatige manier behandeld.
De volgende screenshot van ClusterControl toont de clustertopologie, het illustreert onze Galera Cluster-architectuur met een asynchrone slave:
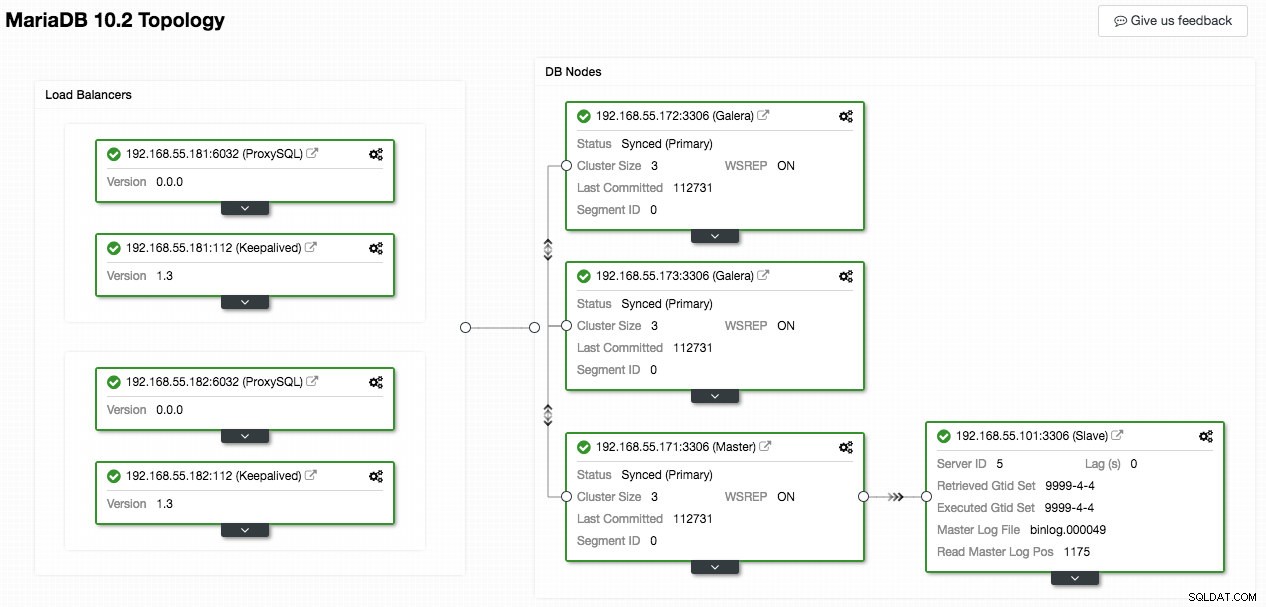
ClusterControl ontdekt automatisch de topologie en genereert het supercoole diagram zoals hierboven. U kunt ook rechtstreeks vanaf deze pagina beheertaken uitvoeren door op het tandwielpictogram rechtsboven in elk vak te klikken.
SQL-bewuste Reverse Proxy
ProxySQL en MariaDB MaxScale zijn intelligente reverse-proxy's die het MySQL-protocol begrijpen en kunnen fungeren als gateway, router, load balancer en firewall voor uw Galera-knooppunten. Met de hulp van een virtuele IP-adresprovider zoals LVS of Keepalive, en dit te combineren met Galera multi-master replicatietechnologie, kunnen we een zeer beschikbare databaseservice hebben, waarbij alle mogelijke single-point-of-failures (SPOF) van het toepassingspunt worden geëlimineerd -uitzicht. Dit zal zeker de beschikbaarheid en betrouwbaarheid van de architectuur als geheel verbeteren.
Een ander voordeel van deze aanpak is dat u de inkomende SQL-query's kunt bewaken, herschrijven of omleiden op basis van een reeks regels voordat ze de daadwerkelijke databaseserver bereiken, waardoor de wijzigingen aan de toepassings- of clientzijde en het routeren van query's naar een meer geschikt knooppunt voor optimale prestaties. Risicovolle zoekopdrachten voor Galera zoals LOCK TABLES en FLUSH TABLES WITH READ LOCK kunnen ver van tevoren worden voorkomen voordat ze schade aan het systeem zouden veroorzaken, terwijl ze van invloed zijn op zoekopdrachten zoals "hotspot"-zoekopdrachten (een rij waartoe verschillende zoekopdrachten tegelijkertijd toegang willen hebben) worden herschreven of worden doorgestuurd naar een enkele Galera-node om het risico op transactieconflicten te verminderen. Voor zware alleen-lezen-query's zoals OLAP of back-up, kunt u deze doorsturen naar een asynchrone slave als u die heeft.
Reverse proxy bewaakt ook de databasestatus, query's en variabelen om de veranderingen in de topologie te begrijpen en een nauwkeurige routeringsbeslissing naar de backend-servers te produceren. Indirect centraliseert het de monitoring van de nodes en het clusteroverzicht zonder de noodzaak om elke afzonderlijke Galera-node regelmatig te controleren. De volgende schermafbeelding toont het ProxySQL-monitoringdashboard in ClusterControl:
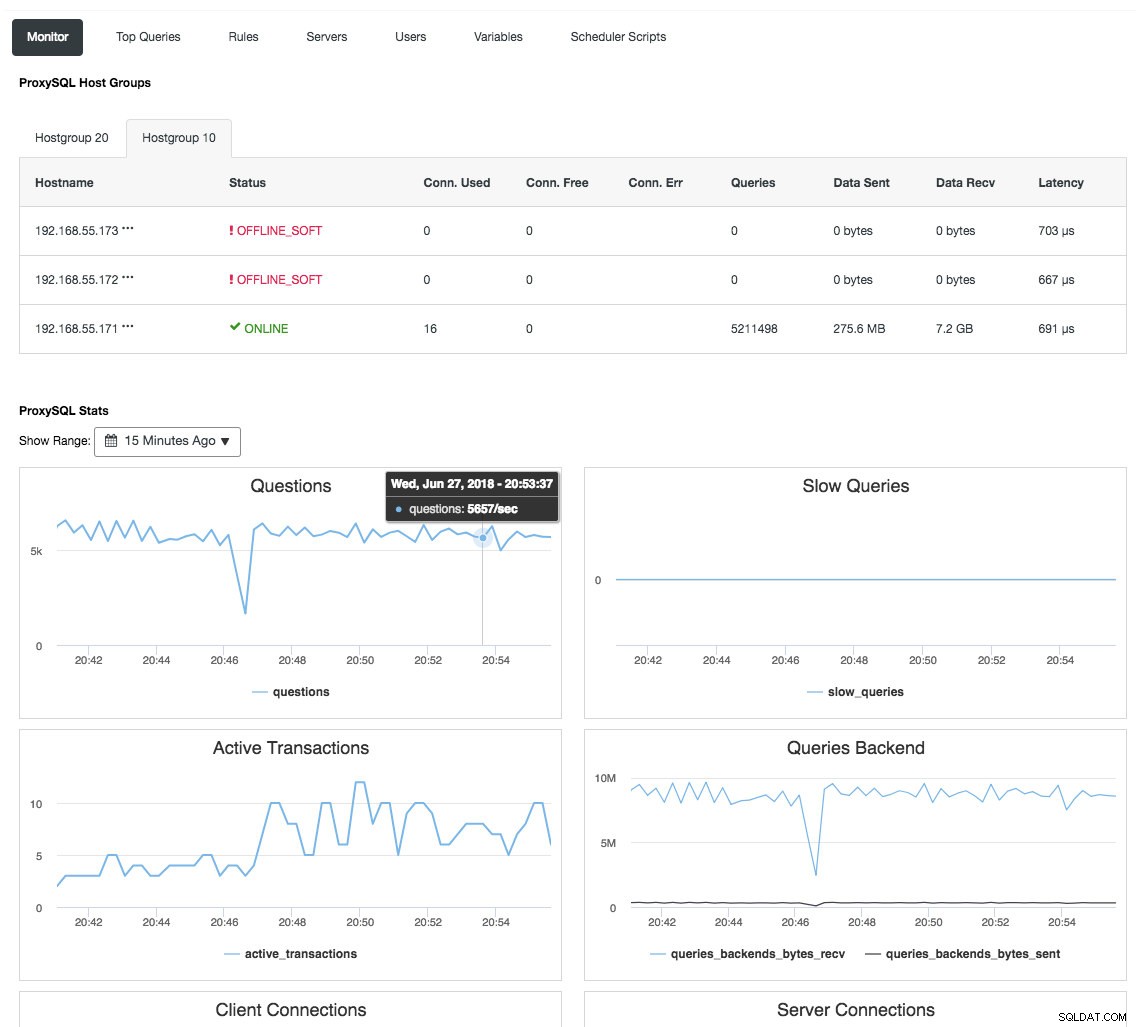
Er zijn ook veel andere voordelen die een load balancer kan bieden om Galera Cluster aanzienlijk te verbeteren, zoals beschreven in deze blogpost, Word een ClusterControl DBA:uw DB-componenten HA HA maken via Load Balancers.
Laatste gedachten
Met een goed begrip van hoe Galera Cluster intern werkt, kunnen we enkele van de beperkingen omzeilen en de databaseservice verbeteren. Veel plezier met clusteren!