Databaseschema is niet iets dat in steen is geschreven. Het is ontworpen voor een bepaalde toepassing, maar de vereisten kunnen en zullen meestal veranderen. Nieuwe modules en functionaliteiten worden aan de applicatie toegevoegd, er worden meer data verzameld, code en datamodel refactoring uitgevoerd. Daardoor is het nodig om het databaseschema aan te passen aan deze veranderingen; kolommen toevoegen of wijzigen, nieuwe tabellen maken of grote tabellen partitioneren. Query's veranderen ook naarmate ontwikkelaars nieuwe manieren toevoegen waarop gebruikers met de gegevens kunnen communiceren - nieuwe query's kunnen nieuwe, efficiëntere indexen gebruiken, dus we haasten ons om ze te maken om de toepassing de beste databaseprestaties te bieden.
Dus, hoe pakken we een schemawijziging het beste aan? Welke tools zijn handig? Hoe de impact op een productiedatabase minimaliseren? Wat zijn de meest voorkomende problemen bij het ontwerpen van schema's? Welke tools kunnen u helpen uw schema bij te houden? In deze blogpost geven we je een kort overzicht van hoe je schemawijzigingen kunt doen in MySQL en MariaDB. Houd er rekening mee dat we schemawijzigingen niet bespreken in de context van Galera Cluster. We bespraken al Total Order Isolation, Rolling Schema Upgrades en tips om de impact van RSU te minimaliseren in eerdere blogposts. We zullen ook tips en trucs bespreken met betrekking tot schemaontwerp en hoe ClusterControl u kan helpen om op de hoogte te blijven van alle schemawijzigingen.
Soorten schemawijzigingen
Eerste dingen eerst. Voordat we ingaan op het onderwerp, moeten we begrijpen hoe MySQL en MariaDB schemawijzigingen uitvoeren. Zie je, de ene schemawijziging is niet gelijk aan een andere schemawijziging.
Je hebt misschien wel eens gehoord van online alters, instant changes of in-place alters. Dit alles is het resultaat van werk dat gaande is om de impact van de schemawijzigingen op de productiedatabase te minimaliseren. Historisch gezien blokkeerden bijna alle schemawijzigingen. Als u een schemawijziging hebt uitgevoerd, beginnen alle query's zich op te stapelen, wachtend tot de ALTER is voltooid. Het was duidelijk dat dit ernstige problemen opleverde voor productie-implementaties. Natuurlijk gaan mensen meteen op zoek naar tijdelijke oplossingen, en die zullen we later in deze blog bespreken, want die zijn ook nu nog relevant. Maar er werd ook begonnen met het verbeteren van de mogelijkheden van MySQL om DDL's (Data Definition Language) uit te voeren zonder veel impact op andere zoekopdrachten.
Directe wijzigingen
Soms is het niet nodig om gegevens in de tabelruimte aan te raken, omdat het enige dat gewijzigd hoeft te worden de metagegevens zijn. Een voorbeeld hier is het laten vallen van een index of het hernoemen van een kolom. Dergelijke operaties zijn snel en efficiënt. Meestal is hun impact beperkt. Het is echter niet zonder enige impact. Soms duurt het enkele seconden om de wijziging in de metadata door te voeren en voor een dergelijke wijziging moet een metadatavergrendeling worden verkregen. Deze vergrendeling is per tafel en kan andere bewerkingen blokkeren die op deze tafel moeten worden uitgevoerd. U ziet dit als "Wachten op vergrendeling van tabelmetagegevens" in de proceslijst.
Een voorbeeld van zo'n wijziging kan instant ADD COLUMN zijn, geïntroduceerd in MariaDB 10.3 en MySQL 8.0. Het geeft de mogelijkheid om deze vrij populaire schemawijziging zonder enige vertraging uit te voeren. Zowel MariaDB als Oracle hebben besloten om code van Tencent Game op te nemen waarmee direct een nieuwe kolom aan de tabel kan worden toegevoegd. Dit is onder een aantal specifieke voorwaarden; kolom moet worden toegevoegd als de laatste, volledige tekstindexen kunnen niet in de tabel voorkomen, rij-indeling kan niet worden gecomprimeerd - u kunt meer informatie vinden over hoe direct toevoegen van een kolom werkt in MariaDB-documentatie. Voor MySQL is de enige officiële referentie te vinden op de mysqlserverteam.com blog, hoewel er een bug bestaat om de officiële documentatie bij te werken.
Plaatselijke wijzigingen
Sommige van de wijzigingen vereisen wijziging van de gegevens in de tabelruimte. Dergelijke wijzigingen kunnen op de gegevens zelf worden uitgevoerd en het is niet nodig om een tijdelijke tabel met een nieuwe gegevensstructuur te maken. Dergelijke wijzigingen zorgen er doorgaans (maar niet altijd) voor dat andere query's die de tabel raken, worden uitgevoerd terwijl de schemawijziging wordt uitgevoerd. Een voorbeeld van een dergelijke bewerking is het toevoegen van een nieuwe secundaire index aan de tabel. Het duurt even voordat deze bewerking is uitgevoerd, maar het is mogelijk om DML's uit te voeren.
Tafel opnieuw opbouwen
Als het niet mogelijk is om een wijziging door te voeren, zal InnoDB een tijdelijke tabel maken met de nieuwe, gewenste structuur. Het zal dan bestaande gegevens naar de nieuwe tabel kopiëren. Deze operatie is de duurste en het is waarschijnlijk (hoewel het niet altijd gebeurt) om de DML's te vergrendelen. Als gevolg hiervan is het erg lastig om zo'n schemawijziging uit te voeren op een grote tafel op een standalone server, zonder hulp van externe tools - je kunt het je doorgaans niet veroorloven om je database voor lange minuten of zelfs uren te vergrendelen. Een voorbeeld van zo'n bewerking zou zijn om het gegevenstype van de kolom te wijzigen, bijvoorbeeld van INT in VARCHAR.
Schemawijzigingen en replicatie
Ok, dus we weten dat InnoDB online schemawijzigingen toestaat en als we MySQL-documentatie raadplegen, zullen we zien dat de meerderheid van de schemawijzigingen (althans een van de meest voorkomende) online kunnen worden uitgevoerd. Wat is de reden achter het besteden van uren aan ontwikkeling om online hulpprogramma's voor het wijzigen van schema's zoals gh-ost te maken? We kunnen accepteren dat pt-online-schema-change een overblijfsel is van de oude, slechte tijden, maar gh-ost is nieuwe software.
Het antwoord is ingewikkeld. Er zijn twee hoofdproblemen.
Om te beginnen, als je eenmaal een schemawijziging hebt gestart, heb je er geen controle over. Je kunt het afbreken, maar je kunt het niet pauzeren. Je kunt het niet gas geven. Zoals u zich kunt voorstellen, is het opnieuw opbouwen van de tabel een dure operatie en zelfs als InnoDB toestaat dat DML's worden uitgevoerd, heeft extra I/O-werkbelasting van de DDL invloed op alle andere query's en is er geen manier om deze impact te beperken tot een niveau dat acceptabel is voor de applicatie.
Ten tweede, een nog ernstiger probleem, is replicatie. Als u een niet-blokkerende bewerking uitvoert, waarvoor een tabel opnieuw moet worden opgebouwd, worden de DML's inderdaad niet vergrendeld, maar dit geldt alleen voor de master. Laten we aannemen dat zo'n DDL 30 minuten duurde om te voltooien - ALTER-snelheid hangt af van de hardware, maar het is vrij gebruikelijk om dergelijke uitvoeringstijden te zien op tabellen met een grootte van 20 GB. Het wordt vervolgens gerepliceerd naar alle slaves en vanaf het moment dat DDL op die slaves start, zal de replicatie wachten tot het is voltooid. Het maakt niet uit of u MySQL of MariaDB gebruikt, of dat u multi-threaded replicatie gebruikt. Slaven zullen achterblijven - ze wachten die 30 minuten totdat de DDL is voltooid voordat ze beginnen met het toepassen van de resterende binlog-gebeurtenissen. Zoals je je kunt voorstellen, is een vertraging van 30 minuten (soms zelfs 30 seconden niet acceptabel - het hangt allemaal af van de toepassing) iets dat het onmogelijk maakt om die slaves te gebruiken voor scale-out. Natuurlijk zijn er tijdelijke oplossingen - u kunt schemawijzigingen van onder naar boven in de replicatieketen uitvoeren, maar dit beperkt uw opties ernstig. Vooral als u op rijen gebaseerde replicatie gebruikt, kunt u op deze manier alleen compatibele schemawijzigingen uitvoeren. Enkele voorbeelden van beperkingen van op rijen gebaseerde replicatie; u kunt geen kolom neerzetten die niet de laatste is, u kunt geen kolom toevoegen aan een andere positie dan de laatste. U kunt ook het kolomtype niet wijzigen (bijvoorbeeld INT -> VARCHAR).
Zoals u kunt zien, voegt replicatie complexiteit toe aan de manier waarop u schemawijzigingen kunt uitvoeren. Bewerkingen die niet-blokkerend zijn op de zelfstandige host, worden blokkerend wanneer ze op slaves worden uitgevoerd. Laten we een paar methoden bekijken die u kunt gebruiken om de impact van schemawijzigingen te minimaliseren.
Online hulpprogramma's voor het wijzigen van schema's
Zoals we eerder vermeldden, zijn er tools die bedoeld zijn om schemawijzigingen door te voeren. De meest populaire zijn pt-online-schema-change gemaakt door Percona en gh-ost, gemaakt door GitHub. In een reeks blogposts hebben we ze vergeleken en besproken hoe gh-ost kan worden gebruikt om schemawijzigingen door te voeren en hoe je een lopende migratie kunt vertragen en opnieuw configureren. Hier zullen we niet in details treden, maar we willen toch enkele van de belangrijkste aspecten van het gebruik van die tools noemen. Om te beginnen zal een schemawijziging die wordt uitgevoerd via pt-osc of gh-ost op alle databaseknooppunten tegelijk plaatsvinden. Er is geen enkele vertraging in termen van wanneer de wijziging zal worden toegepast. Dit maakt het mogelijk om die hulpprogramma's zelfs te gebruiken voor schemawijzigingen die niet compatibel zijn met replicatie op basis van rijen. De exacte mechanismen over hoe die tools veranderingen op de tafel volgen, zijn anders (triggers in pt-osc vs. binlog-parsing in gh-ost) maar het hoofdidee is hetzelfde:er wordt een nieuwe tabel gemaakt met het gewenste schema en bestaande gegevens worden gekopieerd van de oude tabel. In de tussentijd worden DML's bijgehouden (op de een of andere manier) en toegepast op de nieuwe tabel. Zodra alle gegevens zijn gemigreerd, krijgen de tabellen een nieuwe naam en vervangt de nieuwe tabel de oude. Dit is atomaire operatie, dus het is niet zichtbaar voor de applicatie. Beide tools hebben een optie om de belasting te beperken en de bewerkingen te pauzeren. Gh-ost kan alle activiteit stoppen, alleen pt-osc kan het proces van het kopiëren van gegevens tussen oude en nieuwe tabellen stoppen - triggers blijven actief en ze zullen doorgaan met het dupliceren van gegevens, wat wat overhead toevoegt. Vanwege de hernoemingstabel hebben beide tools enkele beperkingen met betrekking tot externe sleutels - niet ondersteund door gh-ost, gedeeltelijk ondersteund door pt-osc, hetzij via reguliere ALTER, wat replicatievertraging kan veroorzaken (niet haalbaar als de onderliggende tabel groot is) of door het verwijderen van de oude tabel voordat de nieuwe naam wordt gewijzigd - het is gevaarlijk omdat er geen manier is om terug te draaien als om de een of andere reden gegevens niet correct naar de nieuwe tabel zijn gekopieerd. Triggers zijn ook lastig te ondersteunen.
Ze worden niet ondersteund in gh-ost, pt-osc in MySQL 5.7 en nieuwer heeft beperkte ondersteuning voor tabellen met bestaande triggers. Andere belangrijke beperkingen voor online hulpprogramma's voor het wijzigen van schema's is dat er een unieke of primaire sleutel in de tabel moet staan. Het wordt gebruikt om rijen te identificeren die tussen oude en nieuwe tabellen moeten worden gekopieerd. Die tools zijn ook veel langzamer dan directe ALTER - een wijziging die uren duurt terwijl ALTER wordt uitgevoerd, kan dagen duren als deze wordt uitgevoerd met pt-osc of gh-ost.
Aan de andere kant, zoals we al zeiden, zolang aan de vereisten wordt voldaan en er geen beperkingen in het spel komen, kun je alle schemawijzigingen uitvoeren met behulp van een van de tools. Alles gebeurt tegelijkertijd op alle hosts, dus u hoeft zich geen zorgen te maken over compatibiliteit. Je hebt ook een zekere mate van controle over hoe het proces wordt uitgevoerd (minder in pt-osc, veel meer in gh-ost).
U kunt de impact van de schemawijziging verminderen, u kunt ze pauzeren en alleen onder toezicht laten lopen, u kunt de wijziging testen voordat u deze daadwerkelijk uitvoert. U kunt ze de replicatievertraging laten volgen en pauzeren als er een impact wordt gedetecteerd. Dit maakt deze tools echt een geweldige aanvulling op het arsenaal van de DBA tijdens het werken met MySQL-replicatie.
Doorlopende schemawijzigingen
Meestal gebruikt een DBA een van de online hulpprogramma's voor het wijzigen van schema's. Maar zoals we eerder hebben besproken, kunnen ze onder bepaalde omstandigheden niet worden gebruikt en is een directe wijziging de enige haalbare optie. Als we het hebben over standalone MySQL, heb je geen keus - als de wijziging niet-blokkerend is, is dat goed. Als dat niet zo is, dan kun je er niets aan doen. Maar dan, niet zo veel mensen draaien MySQL als enkele instances, toch? Hoe zit het met replicatie? Zoals we eerder hebben besproken, is directe wijziging op de master niet haalbaar - in de meeste gevallen zal dit vertraging op de slave veroorzaken en dit is mogelijk niet acceptabel. Wat wel kan, is om de verandering op een rollende manier uit te voeren. U kunt met slaves beginnen en, zodra de wijziging op alle slaven is toegepast, een van de slaven tot nieuwe master promoveren, de oude master tot slave degraderen en de wijziging daarop uitvoeren. Natuurlijk moet de wijziging compatibel zijn, maar om de waarheid te zeggen, de meest voorkomende gevallen waarin u online schemawijzigingen niet kunt gebruiken, zijn vanwege het ontbreken van een primaire of unieke sleutel. Voor alle andere gevallen is er een soort van oplossing, vooral in pt-online-schema-change omdat gh-ost meer harde beperkingen heeft. Het is een tijdelijke oplossing die je "zo zo" of "verre van ideaal" zou noemen, maar het zal het werk doen als je geen andere optie hebt om uit te kiezen. Wat ook belangrijk is, de meeste beperkingen kunnen worden vermeden als u uw schema in de gaten houdt en de problemen opvangt voordat de tabel groeit. Zelfs als iemand een tabel maakt zonder een primaire sleutel, is het geen probleem om een directe wijziging uit te voeren die een halve seconde of minder duurt, aangezien de tabel bijna leeg is.
Als het groeit, wordt dit een serieus probleem, maar het is aan de DBA om dit soort problemen op te vangen voordat ze daadwerkelijk problemen gaan veroorzaken. We zullen enkele tips en trucs bespreken om ervoor te zorgen dat u dergelijke problemen op tijd opmerkt. We zullen ook algemene tips delen voor het ontwerpen van uw schema's.
Tips en trucs
Schemaontwerp
Zoals we in dit bericht hebben laten zien, zijn online hulpprogramma's voor het wijzigen van schema's heel belangrijk bij het werken met een replicatie-instelling. Daarom is het heel belangrijk om ervoor te zorgen dat uw schema zo is ontworpen dat het uw opties voor het uitvoeren van schemawijzigingen niet beperkt. Er zijn drie belangrijke aspecten. Ten eerste moet er een primaire of unieke sleutel zijn - u moet ervoor zorgen dat er geen tabellen zijn zonder een primaire sleutel in uw database. U moet dit regelmatig controleren, anders kan het in de toekomst een serieus probleem worden. Ten tweede moet u serieus overwegen of het gebruik van externe sleutels een goed idee is. Natuurlijk hebben ze hun nut, maar ze voegen ook overhead toe aan uw database en ze kunnen het problematisch maken om online hulpprogramma's voor schemawijziging te gebruiken. Relaties kunnen worden afgedwongen door de applicatie. Zelfs als het meer werk betekent, kan het nog steeds een beter idee zijn dan externe sleutels te gaan gebruiken en ernstig te beperken tot welke typen schemawijzigingen kunnen worden uitgevoerd. Ten derde, triggers. Zelfde verhaal als bij buitenlandse sleutels. Ze zijn een leuke functie om te hebben, maar ze kunnen een last worden. Je moet serieus overwegen of de voordelen van het gebruik ervan opwegen tegen de beperkingen die ze opleveren.
Schemawijzigingen bijhouden
Schemawijzigingsbeheer gaat niet alleen over het uitvoeren van schemawijzigingen. Je moet ook op de hoogte blijven van je schemastructuur, vooral als je niet de enige bent die de wijzigingen aanbrengt.
ClusterControl biedt gebruikers tools om enkele van de meest voorkomende problemen met schemaontwerp te volgen. Het kan u helpen tabellen te volgen die geen primaire sleutels hebben:
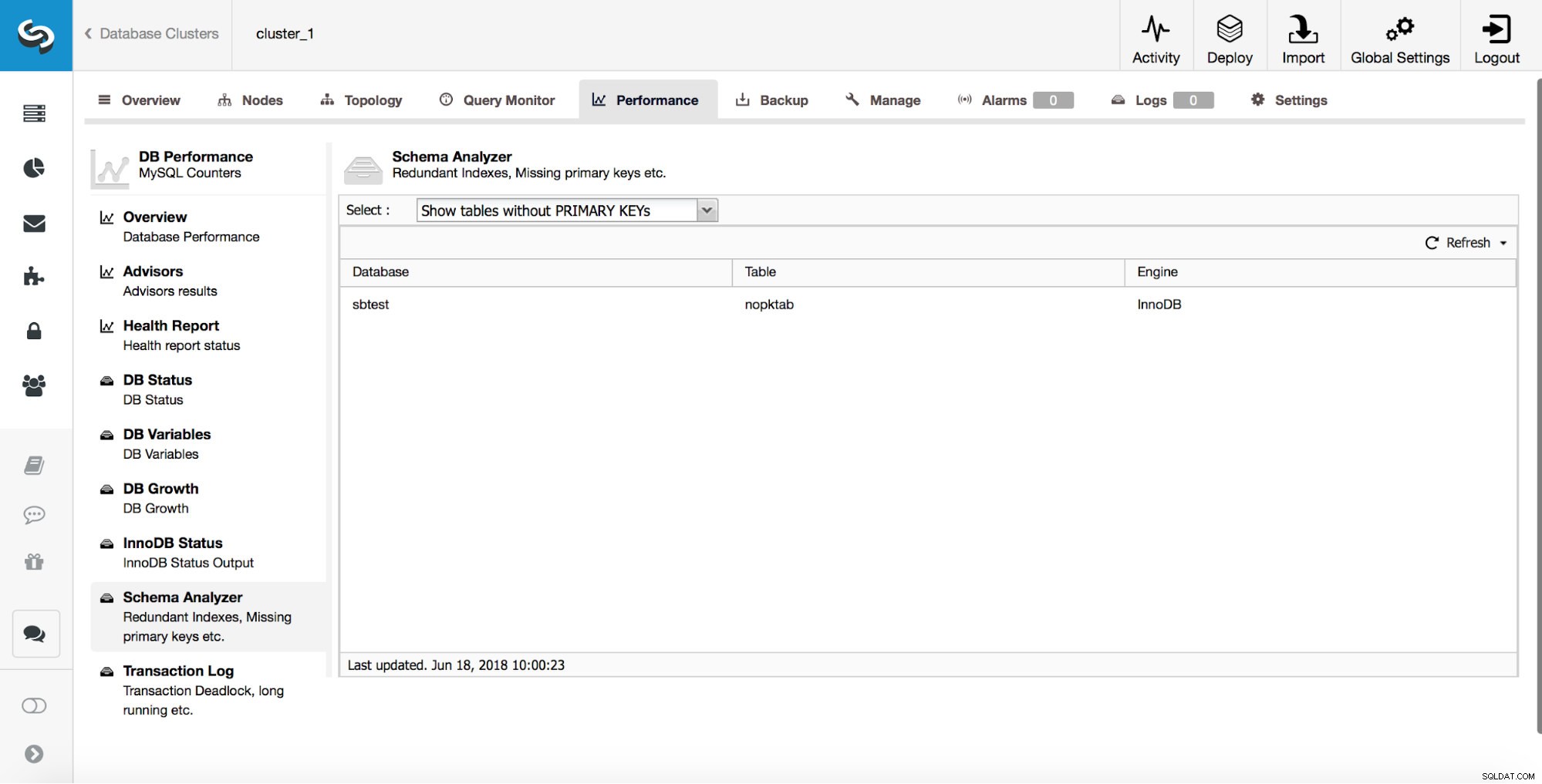
Zoals we eerder hebben besproken, is het vroeg vangen van dergelijke tabellen erg belangrijk omdat primaire sleutels moeten worden toegevoegd met behulp van direct alter.
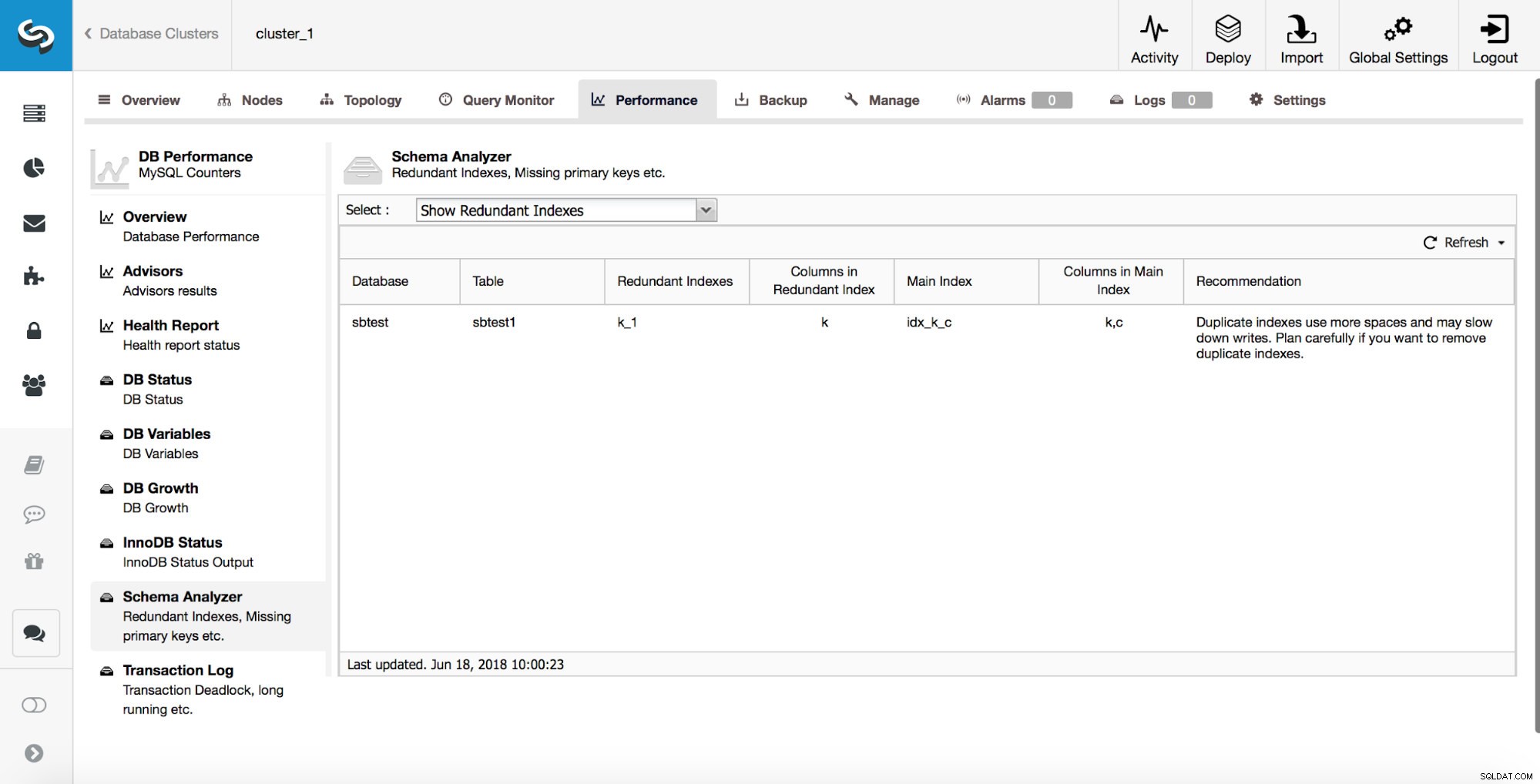
ClusterControl kan u ook helpen bij het bijhouden van dubbele indexen. Meestal wilt u niet meerdere indexen hebben die overbodig zijn. In het bovenstaande voorbeeld kun je zien dat er een index is op (k, c) en er is ook een index op (k). Elke query die een index kan gebruiken die is gemaakt op kolom 'k', kan ook een samengestelde index gebruiken die is gemaakt op kolommen (k, c). Er zijn gevallen waarin het nuttig is om redundante indexen te behouden, maar u moet dit van geval tot geval bekijken. Vanaf MySQL 8.0 is het mogelijk om snel te testen of een index echt nodig is of niet. U kunt een redundante index 'onzichtbaar' maken door het volgende uit te voeren:
ALTER TABLE sbtest.sbtest1 ALTER INDEX k_1 INVISIBLE;Hierdoor negeert MySQL die index en kunt u door middel van monitoring controleren of er een negatieve invloed was op de prestaties van de database. Als alles een tijdje werkt zoals gepland (enkele dagen of zelfs weken), kunt u plannen om de overtollige index te verwijderen. Als u ontdekt dat er iets niet klopt, kunt u deze index altijd opnieuw inschakelen door het volgende uit te voeren:
ALTER TABLE sbtest.sbtest1 ALTER INDEX k_1 VISIBLE;Die bewerkingen zijn direct en de index is er altijd en wordt nog steeds onderhouden - alleen wordt er geen rekening mee gehouden door de optimizer. Dankzij deze optie zal het verwijderen van indexen in MySQL 8.0 een veel veiligere operatie zijn. In de vorige versies kon het opnieuw toevoegen van een ten onrechte verwijderde index uren, zo niet dagen duren op grote tabellen.
ClusterControl kan u ook informeren over MyISAM-tabellen.
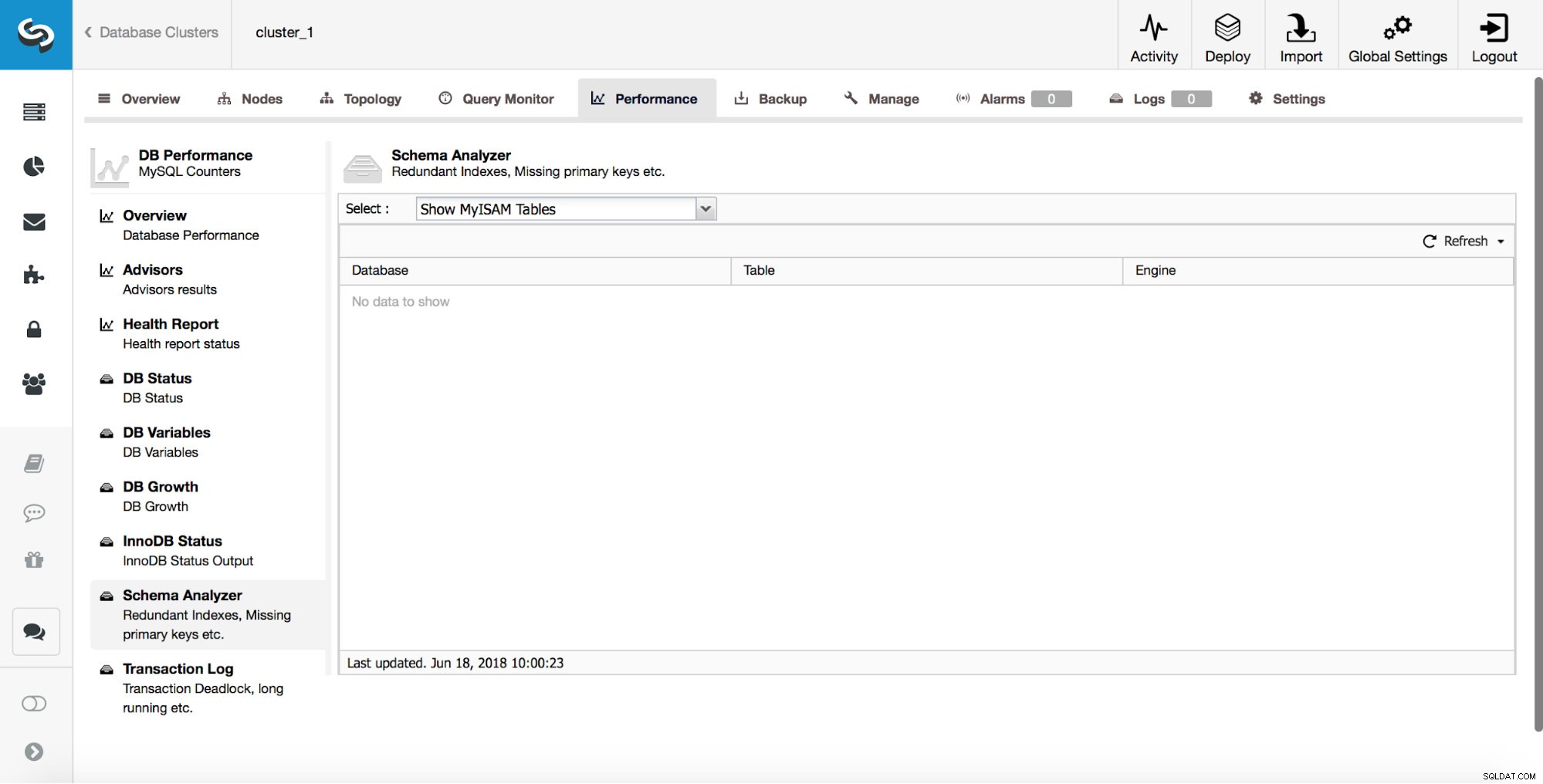
Hoewel MyISAM nog steeds zijn nut kan hebben, moet u er rekening mee houden dat het geen transactionele opslagengine is. Als zodanig kan het gemakkelijk gegevensinconsistentie introduceren tussen knooppunten in een replicatieconfiguratie.
Een andere zeer nuttige functie van ClusterControl is een van de operationele rapporten - een Schema Change Report.
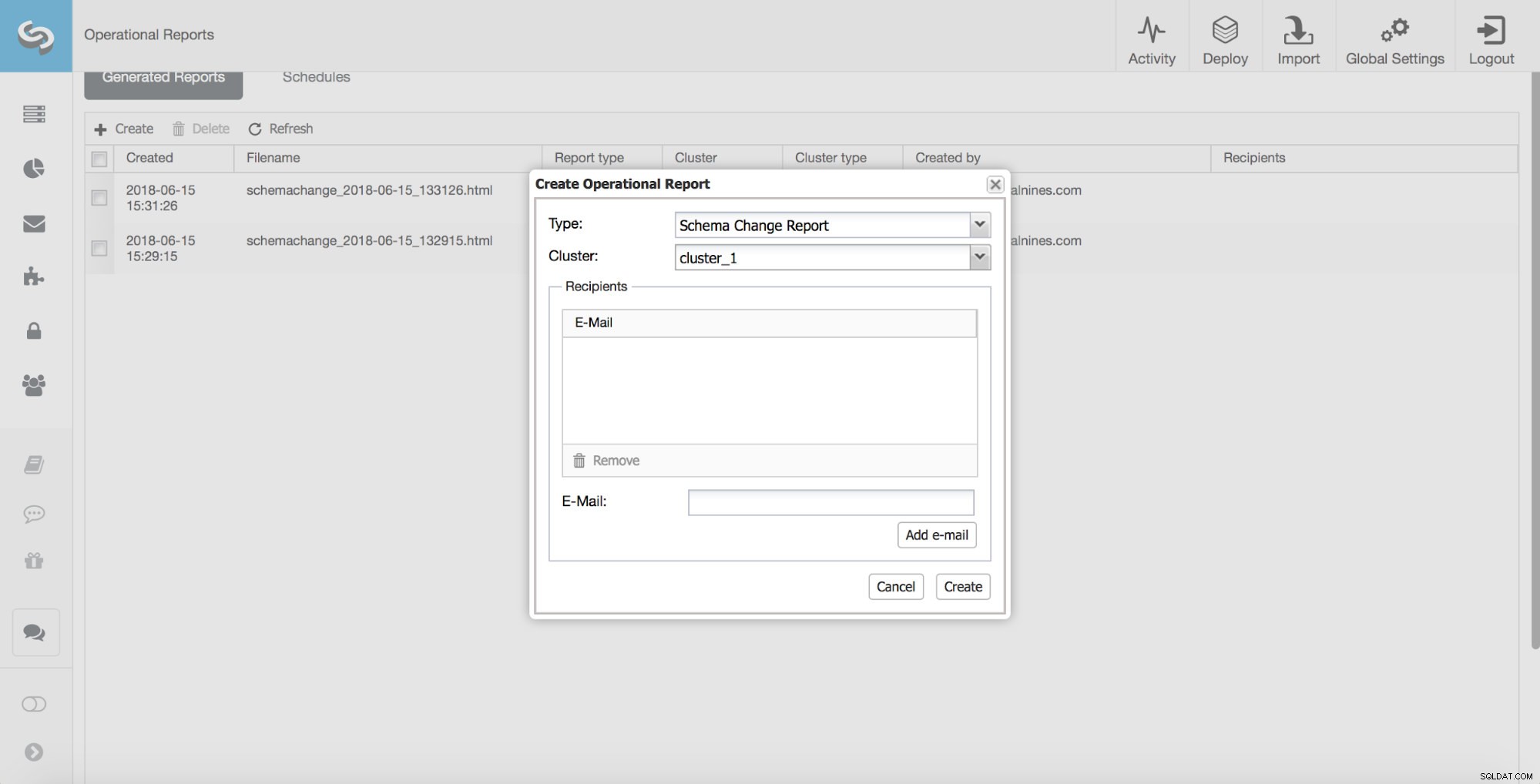
In een ideale wereld beoordeelt, keurt en implementeert een DBA alle schemawijzigingen. Helaas is dit niet altijd het geval. Een dergelijk beoordelingsproces gaat gewoon niet goed samen met agile ontwikkeling. Daarnaast is de ontwikkelaar-tot-DBA-verhouding meestal vrij hoog, wat ook een probleem kan worden, omdat DBA's moeite zouden hebben om geen knelpunt te worden. Daarom is het niet ongebruikelijk dat schemawijzigingen worden uitgevoerd buiten de kennis van de DBA. Toch is de DBA meestal degene die verantwoordelijk is voor de prestaties en stabiliteit van de database. Dankzij het Schema Change Report kunnen ze nu de schemawijzigingen bijhouden.
In eerste instantie is enige configuratie nodig. In een configuratiebestand voor een gegeven cluster (/etc/cmon.d/cmon_X.cnf), moet u definiëren op welke host ClusterControl de wijzigingen moet volgen en welke schema's moeten worden gecontroleerd.
schema_change_detection_address=10.0.0.126
schema_change_detection_databases=sbtestZodra dat is gebeurd, kunt u plannen dat een rapport regelmatig wordt uitgevoerd. Een voorbeelduitvoer kan zijn zoals hieronder:
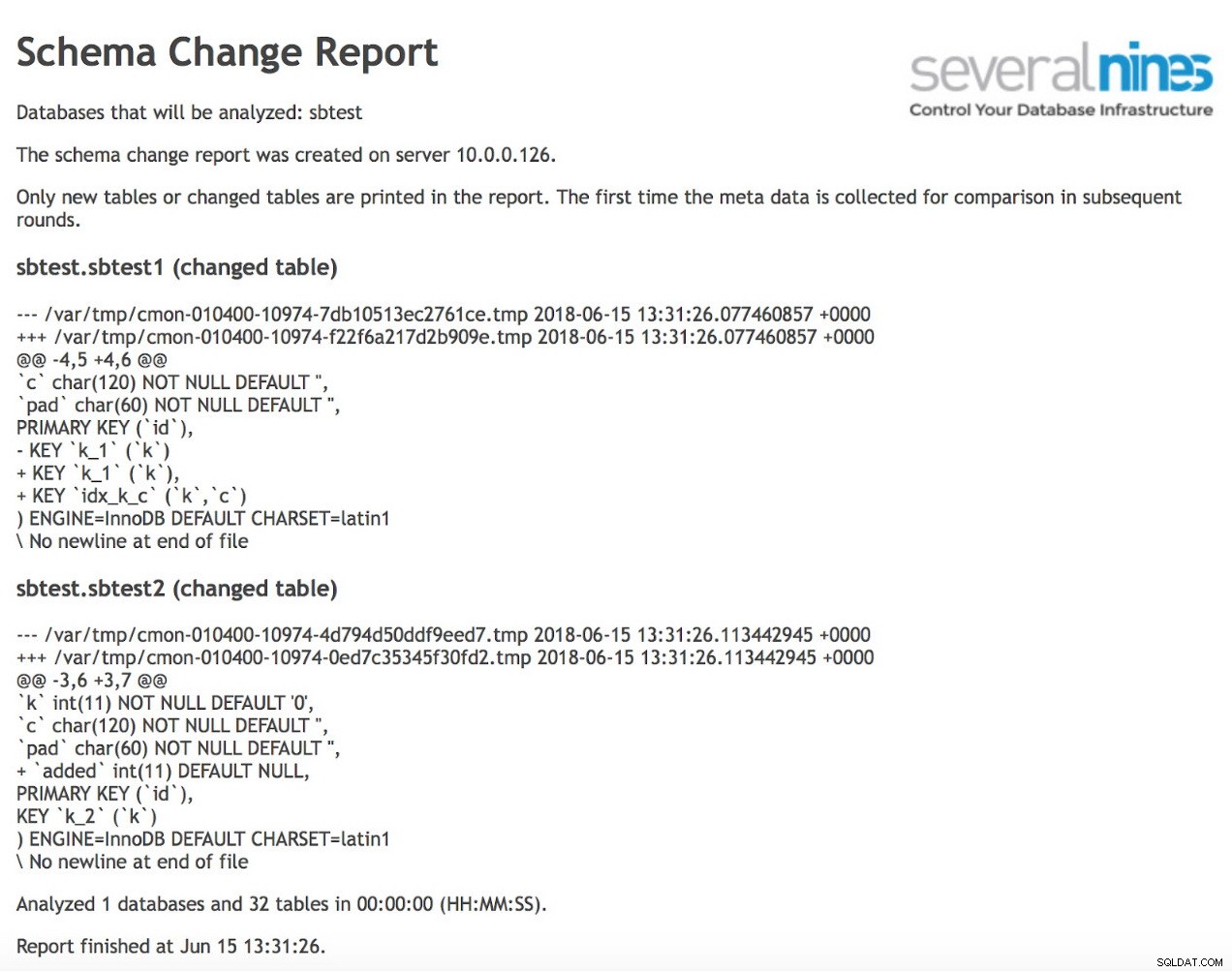
Zoals u kunt zien, zijn er twee tabellen gewijzigd sinds de vorige uitvoering van het rapport. In de eerste is een nieuwe samengestelde index gemaakt op kolommen (k, c). In de tweede tabel is een kolom toegevoegd.
In de daaropvolgende run kregen we informatie over een nieuwe tabel, die was gemaakt zonder index of primaire sleutel. Met behulp van dit soort informatie kunnen we gemakkelijk handelen wanneer dat nodig is en de problemen oplossen voordat ze daadwerkelijk blokkades worden.