Je hebt misschien wel eens gehoord van de term ‘gespleten brein’. Wat het is? Hoe beïnvloedt het uw clusters? In deze blogpost bespreken we wat het precies is, welk gevaar het kan vormen voor uw database, hoe we het kunnen voorkomen en als alles misgaat, hoe u ervan kunt herstellen.
De dagen van single instances zijn allang voorbij, tegenwoordig draaien bijna alle databases in replicatiegroepen of clusters. Dit is geweldig voor hoge beschikbaarheid en schaalbaarheid, maar een gedistribueerde database introduceert nieuwe gevaren en beperkingen. Een geval dat dodelijk kan zijn, is een netwerksplitsing. Stelt u zich een cluster van meerdere knooppunten voor die vanwege netwerkproblemen in twee delen is opgesplitst. Om voor de hand liggende redenen (gegevensconsistentie) mogen beide delen het verkeer niet tegelijkertijd verwerken, omdat ze van elkaar zijn geïsoleerd en gegevens niet tussen hen kunnen worden overgedragen. Het is ook verkeerd vanuit het oogpunt van de toepassing - zelfs als er uiteindelijk een manier zou zijn om de gegevens te synchroniseren (hoewel afstemming van 2 gegevenssets niet triviaal is). Een tijdje zou een deel van de applicatie zich niet bewust zijn van de wijzigingen die zijn aangebracht door andere applicatiehosts, die toegang hebben tot het andere deel van het databasecluster. Dit kan tot ernstige problemen leiden.
De toestand waarin het cluster is verdeeld in twee of meer delen die bereid zijn om schrijfacties te accepteren, wordt "gespleten brein" genoemd.
Het grootste probleem met split-brain is data-drift, aangezien er op beide delen van het cluster wordt geschreven. Geen van de MySQL-smaken biedt geautomatiseerde middelen voor het samenvoegen van datasets die uiteen zijn gelopen. U zult een dergelijke functie niet vinden in MySQL-replicatie, groepsreplicatie of Galera. Als de gegevens eenmaal zijn gedivergeerd, is de enige optie om ofwel een van de delen van het cluster als de bron van waarheid te gebruiken en de wijzigingen die op het andere deel zijn uitgevoerd, te negeren, tenzij we een handmatig proces kunnen volgen om de gegevens samen te voegen.
Dit is waarom we zullen beginnen met hoe je een gespleten brein kunt voorkomen. Dit is zo veel gemakkelijker dan het moeten oplossen van een discrepantie in de gegevens.
Hoe gespleten hersenen te voorkomen
De exacte oplossing hangt af van het type database en de inrichting van de omgeving. We zullen enkele van de meest voorkomende gevallen van Galera Cluster en MySQL-replicatie bekijken.
Galera-cluster
Galera heeft een ingebouwde "stroomonderbreker" om gespleten hersenen aan te kunnen:het is gebaseerd op een quorummechanisme. Als een meerderheid (50% + 1) van de nodes in het cluster beschikbaar is, zal Galera normaal werken. Als er geen meerderheid is, zal Galera stoppen met het bedienen van verkeer en overschakelen naar de zogenaamde "niet-primaire" staat. Dit is vrijwel alles wat je nodig hebt om met een gespleten breinsituatie om te gaan tijdens het gebruik van Galera. Natuurlijk zijn er handmatige methoden om Galera in de "primaire" staat te dwingen, zelfs als er geen meerderheid is. Het punt is, tenzij je dat doet, zou je veilig moeten zijn.
De manier waarop het quorum wordt berekend, heeft belangrijke gevolgen:op een enkel datacenterniveau wilt u een oneven aantal knooppunten hebben. Drie knooppunten geven u een tolerantie voor het falen van één knooppunt (2 knooppunten komen overeen met de vereiste dat meer dan 50% van de knooppunten in het cluster beschikbaar zijn). Vijf knooppunten geven u een tolerantie voor het falen van twee knooppunten (5 - 2 =3, wat meer is dan 50% van 5 knooppunten). Aan de andere kant zal het gebruik van vier knooppunten uw tolerantie ten opzichte van een cluster met drie knooppunten niet verbeteren. Het zou nog steeds slechts een storing van één knooppunt afhandelen (4 - 1 =3, meer dan 50% van 4), terwijl het falen van twee knooppunten het cluster onbruikbaar maakt (4 - 2 =2, slechts 50%, niet meer).
Houd er bij het implementeren van Galera-cluster in een enkel datacenter rekening mee dat u idealiter nodes over meerdere beschikbaarheidszones (afzonderlijke stroombron, netwerk, enz.) . Een eenvoudige installatie kan er als volgt uitzien:
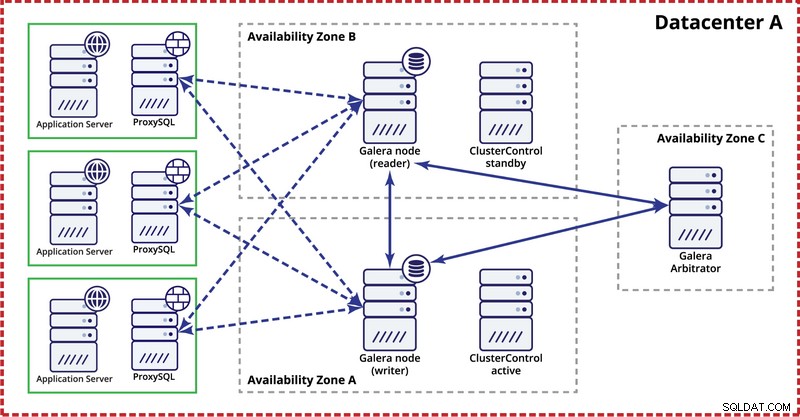
Op multidatacenterniveau zijn die overwegingen ook van toepassing. Als u wilt dat het Galera-cluster automatisch datacenterstoringen afhandelt, moet u een oneven aantal datacenters gebruiken. Om de kosten te verlagen, kunt u in een ervan een Galera-arbiter gebruiken in plaats van een databaseknooppunt. Galera-arbiter (garbd) is een proces dat deelneemt aan de quorumberekening, maar het bevat geen gegevens. Dit maakt het mogelijk om het zelfs op zeer kleine instanties te gebruiken, omdat het niet veel middelen kost - hoewel de netwerkconnectiviteit goed moet zijn omdat het al het replicatieverkeer 'ziet'. Een voorbeeldconfiguratie kan er als volgt uitzien in een diagram hieronder:
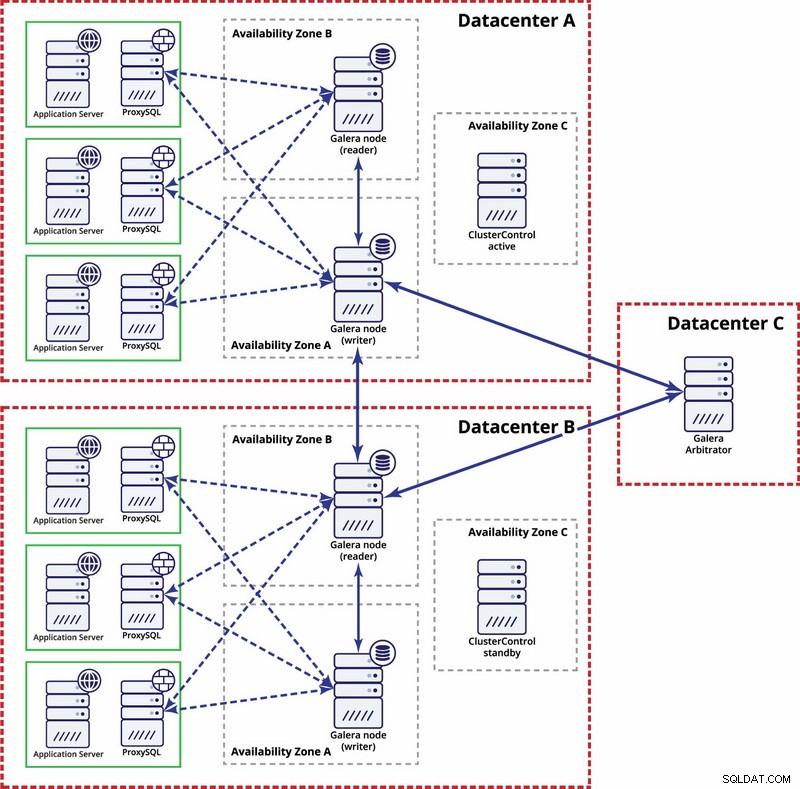
MySQL-replicatie
Met MySQL-replicatie is het grootste probleem dat er geen quorummechanisme is ingebouwd, zoals in het Galera-cluster. Daarom zijn er meer stappen nodig om ervoor te zorgen dat je opstelling niet wordt beïnvloed door een gespleten brein.
Eén methode is om geautomatiseerde failovers tussen datacenters te voorkomen. U kunt uw failover-oplossing configureren (dit kan via ClusterControl, of MHA of Orchestrator) om alleen binnen één datacenter een failover uit te voeren. Als er een volledige uitval van het datacenter is, is het aan de beheerder om te beslissen hoe een failover wordt uitgevoerd en hoe ervoor te zorgen dat de servers in het defecte datacenter niet worden gebruikt.
Er zijn opties om het meer geautomatiseerd te maken. U kunt Consul gebruiken om gegevens over de knooppunten in de replicatie-instellingen op te slaan, en welke daarvan de master is. Vervolgens is het aan de beheerder (of via scripting) om dit item bij te werken en schrijfbewerkingen naar het tweede datacenter te verplaatsen. U kunt profiteren van een Orchestrator/Raft-configuratie waarbij Orchestrator-knooppunten kunnen worden gedistribueerd over meerdere datacenters en gesplitste hersenen kunnen worden gedetecteerd. Op basis hiervan kunt u verschillende acties ondernemen, zoals, zoals we eerder vermeldden, vermeldingen in onze Consul of etcd bijwerken. Het punt is dat dit een veel complexere omgeving is om in te stellen en te automatiseren dan het Galera-cluster. Hieronder vindt u een voorbeeld van een multi-datacenterconfiguratie voor MySQL-replicatie.
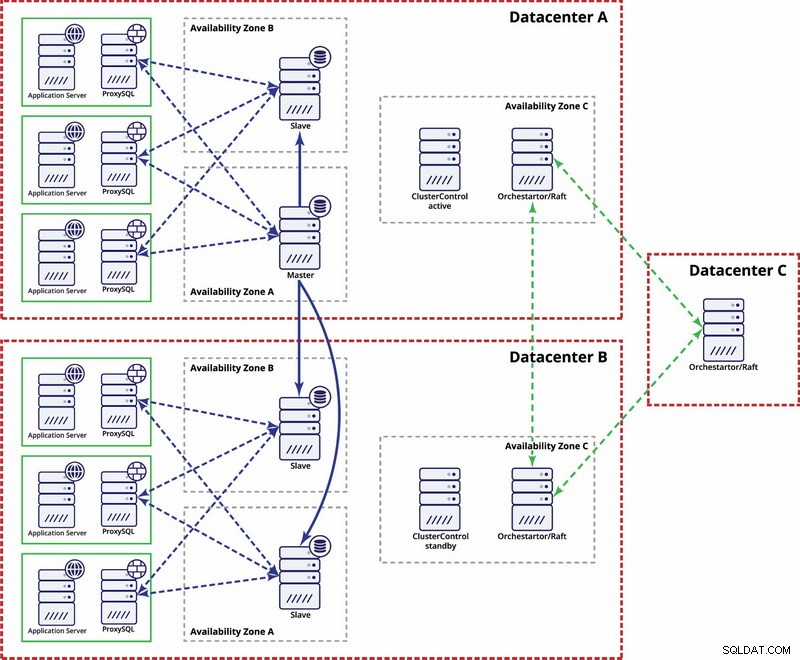
Houd er rekening mee dat u nog steeds scripts moet maken om het te laten werken, d.w.z. Orchestrator-knooppunten bewaken voor een gespleten brein en de nodige acties ondernemen om STONITH te implementeren en ervoor te zorgen dat de master in datacenter A niet wordt gebruikt zodra het netwerk convergeert en de connectiviteit worden hersteld.
Split Brain is gebeurd - Wat nu te doen?
Het worstcasescenario is gebeurd en we hebben gegevensdrift. We zullen proberen u enkele hints te geven wat u hier kunt doen. Helaas zijn de exacte stappen grotendeels afhankelijk van uw schemaontwerp, dus het is niet mogelijk om een precieze handleiding te schrijven.
Wat u in gedachten moet houden, is dat het uiteindelijke doel is om gegevens van de ene master naar de andere te kopiëren en alle relaties tussen tabellen opnieuw te creëren.
Allereerst moet u bepalen welk knooppunt gegevens als master zal blijven dienen. Dit is een dataset waarmee u gegevens samenvoegt die zijn opgeslagen op de andere "master" -instantie. Zodra dat is gebeurd, moet u gegevens identificeren van de oude master die ontbreekt op de huidige master. Dit zal handwerk zijn. Als u tijdstempels in uw tabellen heeft, kunt u deze gebruiken om de ontbrekende gegevens te lokaliseren. Uiteindelijk zullen binaire logboeken alle gegevenswijzigingen bevatten, zodat u erop kunt vertrouwen. Mogelijk moet u ook vertrouwen op uw kennis van de gegevensstructuur en relaties tussen tabellen. Als uw gegevens zijn genormaliseerd, kan één record in één tabel gerelateerd zijn aan records in andere tabellen. Uw toepassing kan bijvoorbeeld gegevens invoegen in de "user"-tabel die gerelateerd is aan de "address"-tabel met behulp van user_id. Je zult alle gerelateerde rijen moeten vinden en ze uitpakken.
De volgende stap is om deze gegevens in de nieuwe master te laden. Hier komt het lastige deel - als je je setups van tevoren hebt voorbereid, kan dit gewoon een kwestie zijn van een paar inserts. Zo niet, dan kan dit nogal ingewikkeld zijn. Het draait allemaal om de primaire sleutel en unieke indexwaarden. Als uw primaire sleutelwaarden op elke server als uniek worden gegenereerd met behulp van een soort UUID-generator of met behulp van auto_increment_increment en auto_increment_offset-instellingen in MySQL, kunt u er zeker van zijn dat de gegevens van de oude master die u moet invoegen geen primaire sleutel of unieke sleutelconflicten met gegevens op de nieuwe master. Anders moet u mogelijk handmatig gegevens van de oude master wijzigen om ervoor te zorgen dat deze correct kunnen worden ingevoegd. Het klinkt ingewikkeld, dus laten we een voorbeeld bekijken.
Laten we ons voorstellen dat we rijen invoegen met auto_increment op knooppunt A, dat een master is. Omwille van de eenvoud zullen we ons concentreren op slechts een enkele rij. Er zijn kolommen 'id' en 'value'.
Als we het invoegen zonder een bepaalde instelling, zien we items zoals hieronder:
1000, ‘some value0’
1001, ‘some value1’
1002, ‘some value2’
1003, ‘some value3’Die zullen repliceren naar de slaaf (B). Als het gespleten brein plaatsvindt en het schrijven op zowel de oude als de nieuwe master wordt uitgevoerd, krijgen we de volgende situatie:
A
1000, ‘some value0’
1001, ‘some value1’
1002, ‘some value2’
1003, ‘some value3’
1004, ‘some value4’
1005, ‘some value5’
1006, ‘some value7’B
1000, ‘some value0’
1001, ‘some value1’
1002, ‘some value2’
1003, ‘some value3’
1004, ‘some value6’
1005, ‘some value8’
1006, ‘some value9’Zoals je kunt zien, is er geen manier om eenvoudig records met id van 1004, 1005 en 1006 van knooppunt A te dumpen en ze op knooppunt B op te slaan, omdat we zullen eindigen met gedupliceerde primaire sleutelitems. Wat moet worden gedaan, is om de waarden van de id-kolom in de rijen die worden ingevoegd te wijzigen in een waarde die groter is dan de maximale waarde van de id-kolom uit de tabel. Dit is alles wat nodig is voor enkele rijen. Voor complexere relaties, waarbij meerdere tabellen betrokken zijn, moet u de wijzigingen mogelijk op meerdere locaties aanbrengen.
Aan de andere kant, als we dit potentiële probleem hadden voorzien en onze knooppunten hadden geconfigureerd om oneven id's op knooppunt A en even id's op knooppunt B op te slaan, zou het probleem zoveel gemakkelijker op te lossen zijn geweest.
Knooppunt A is geconfigureerd met auto_increment_offset =1 en auto_increment_increment =2
Knooppunt B is geconfigureerd met auto_increment_offset =2 en auto_increment_increment =2
Dit is hoe de gegevens eruit zouden zien op knooppunt A vóór het gespleten brein:
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’Wanneer een gespleten brein plaatsvond, ziet het er als volgt uit.
Knooppunt A:
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’
1009, ‘some value4’
1011, ‘some value5’
1013, ‘some value7’Knooppunt B:
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’
1008, ‘some value6’
1010, ‘some value8’
1012, ‘some value9’Nu kunnen we eenvoudig ontbrekende gegevens van knooppunt A kopiëren:
1009, ‘some value4’
1011, ‘some value5’
1013, ‘some value7’En laad het naar knooppunt B en eindig met de volgende dataset:
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’
1008, ‘some value6’
1009, ‘some value4’
1010, ‘some value8’
1011, ‘some value5’
1012, ‘some value9’
1013, ‘some value7’Natuurlijk staan de rijen niet in de oorspronkelijke volgorde, maar dit zou in orde moeten zijn. In het ergste geval moet u in query's sorteren op 'waarde'-kolom en er misschien een index aan toevoegen om het sorteren snel te maken.
Stel je nu honderden of duizenden rijen voor en een sterk genormaliseerde tabelstructuur - om één rij te herstellen, kan het zijn dat je er meerdere in extra tabellen moet herstellen. Met de noodzaak om id's te wijzigen (omdat je geen beschermende instellingen had) in alle gerelateerde rijen en dit allemaal handmatig werk is, kun je je voorstellen dat dit niet de beste situatie is om in te verkeren. Het kost tijd om te herstellen en het is een foutgevoelig proces. Gelukkig zijn er, zoals we aan het begin bespraken, middelen om de kans te minimaliseren dat gespleten hersenen je systeem zullen beïnvloeden of om het werk dat gedaan moet worden om je nodes terug te synchroniseren, te verminderen. Zorg ervoor dat je ze gebruikt en blijf voorbereid.