Dit is de tweede aflevering van een tweedelige serie over 2ndQuadrant's repmgr, een open-source tool met hoge beschikbaarheid voor PostgreSQL.
In het eerste deel hebben we een PostgreSQL 12-cluster met drie knooppunten opgezet, samen met een "getuige" -knooppunt. Het cluster bestond uit een primair knooppunt en twee standby-knooppunten. Het cluster en dewitness node werden gehost in een Amazon Web Service Virtual Private Cloud (VPC). De EC2-servers die de Postgres-instanties hosten, werden in subnetten in verschillende beschikbaarheidszones (AZ) geplaatst, zoals hieronder weergegeven:
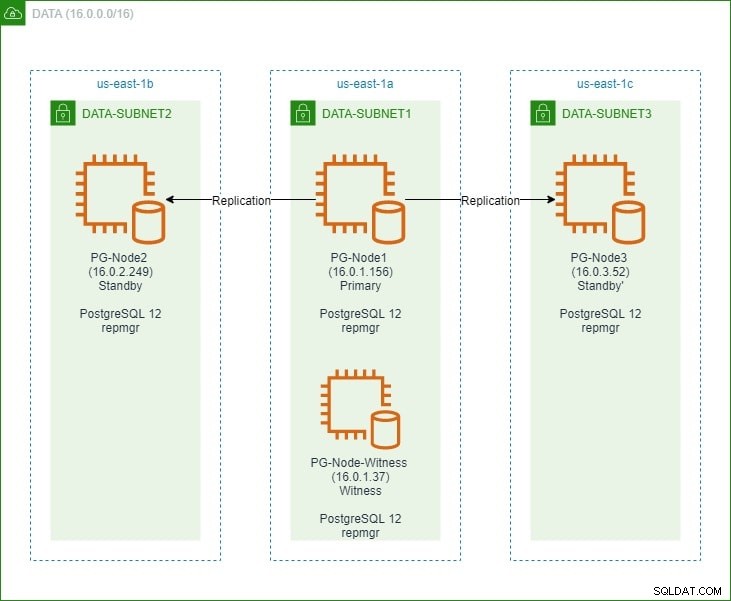
We zullen uitgebreid verwijzen naar de knooppuntnamen en hun IP-adressen, dus hier is de tabel nogmaals met de details van de knooppunten:
| Knooppuntnaam | IP-adres | Rol | Apps actief |
| PG-Node1 | 16.0.1.156 | Primair | PostgreSQL 12 en repmgr |
| PG-Node2 | 16.0.2.249 | Stand-by 1 | PostgreSQL 12 en repmgr |
| PG-Node3 | 16.0.3.52 | Stand-by 2 | PostgreSQL 12 en repmgr |
| PG-Node-Witness | 16.0.1.37 | Getuige | PostgreSQL 12 en repmgr |
We hebben repmgr geïnstalleerd in de primaire en standby-knooppunten en vervolgens het primaire knooppunt geregistreerd met repmgr. Vervolgens hebben we beide standby-knooppunten van de primaire gekloond en gestart. Beide standby-knooppunten waren ook geregistreerd bij repmgr. De opdracht "repmgr cluster show" liet ons zien dat alles werkte zoals verwacht:

Huidig probleem
Het instellen van streaming-replicatie met repmgr is heel eenvoudig. Wat we vervolgens moeten doen, is ervoor zorgen dat het cluster blijft functioneren, zelfs als de primaire niet meer beschikbaar is. Dit is wat we in dit artikel zullen behandelen.
In PostgreSQL-replicatie kan een primaire om een aantal redenen niet meer beschikbaar zijn. Bijvoorbeeld:
- Het besturingssysteem van het primaire knooppunt kan crashen of niet meer reageren
- Het primaire knooppunt kan zijn netwerkverbinding verliezen
- De PostgreSQL-service in het primaire knooppunt kan crashen, stoppen of onverwachts niet meer beschikbaar zijn
- De PostgreSQL-service in het primaire knooppunt kan opzettelijk of per ongeluk worden gestopt
Wanneer een primaire niet meer beschikbaar is, doet een standby niet zichzelf automatisch promoveren naar de primaire rol. Een stand-by blijft alleen-lezen-query's leveren, hoewel de gegevens actueel zijn tot aan de laatste LSN die van de primaire LSN is ontvangen. Elke poging voor een schrijfbewerking zal mislukken.
Er zijn twee manieren om dit te verminderen:
- De stand-by is handmatig opgewaardeerd naar een primaire functie. Dit is meestal het geval bij een geplande failover of “omschakeling”
- De stand-by is automatisch gepromoveerd tot een primaire functie. Dit is het geval met niet-native tools die replicatie continu controleren en herstelacties ondernemen wanneer de primaire niet beschikbaar is. repmgr is zo'n tool.
We zullen hier het tweede scenario bekijken. Deze situatie heeft echter enkele extra uitdagingen:
- Als er meer dan één stand-by is, hoe bepaalt de tool (of de stand-by) dan welke als primaire moet worden gepromoot? Hoe werkt het quorum en het promotieproces?
- Voor meerdere standbys, als er een primair is gemaakt, hoe beginnen de andere nodes deze dan te "volgen" als de nieuwe primaire?
- Wat gebeurt er als de primaire wel functioneert, maar om de een of andere reden tijdelijk is losgekoppeld van het netwerk? Als een van de standbys wordt gepromoveerd tot primair en vervolgens komt de oorspronkelijke primaire weer online, hoe kan een "gespleten brein"-situatie worden vermeden?
antwoord van remgr:Witness Node en de repmgr Daemon
Om deze vragen te beantwoorden, gebruikt repmgr iets dat een witness node wordt genoemd . Wanneer de primaire niet beschikbaar is, is het de taak van de getuige-knooppunt om de standbys te helpen een quorum te bereiken als een van hen moet worden gepromoveerd tot een primaire rol. De standbys bereiken dit quorum door te bepalen of het primaire knooppunt daadwerkelijk offline is of slechts tijdelijk niet beschikbaar is. Het Witness-knooppunt moet zich in hetzelfde datacenter/netwerksegment/subnet bevinden als het primaire knooppunt, maar mag NOOIT op dezelfde fysieke host worden uitgevoerd als het primaire knooppunt.
Onthoud dat we in het eerste deel van deze serie een getuigenknooppunt hebben uitgerold in dezelfde beschikbaarheidszone en hetzelfde subnet als het primaire knooppunt. We noemden het PG-Node-Witness en installeerden daar een PostgreSQL 12-instantie. In dit bericht zullen we daar ook repmgr installeren, maar daarover later meer.
Het tweede onderdeel van de oplossing is de repmgr daemon (repmgrd) uitgevoerd in alle knooppunten van het cluster en het getuige-knooppunt. Nogmaals, we zijn deze daemon niet gestart in het eerste deel van deze serie, maar we zullen dit hier doen. De daemon wordt geleverd als onderdeel van het repmgr-pakket - indien ingeschakeld, werkt het als een reguliere service en bewaakt het continu de status van het cluster. Het initieert een failover wanneer een quorum is bereikt dat de primaire offline is. Het kan niet alleen automatisch een standby promoten, het kan ook andere standbys opnieuw starten in een cluster met meerdere knooppunten om de nieuwe primaire te volgen .
Het quorumproces
Wanneer een standby zich realiseert dat hij de primaire niet kan zien, overlegt hij met andere standbys. Alle standbys die in het cluster actief zijn, bereiken een quorum om een nieuwe primaire te kiezen met behulp van een reeks controles:
- Elke stand-by ondervraagt andere stand-by's over de tijd dat deze de primaire stand-by voor het laatst heeft 'gezien'. Als het laatst gerepliceerde LSN van een standby-station of het tijdstip van de laatste communicatie met het primaire knooppunt recenter is dan het laatst gerepliceerde LSN van het huidige knooppunt of het tijdstip van de laatste communicatie, doet het knooppunt niets en wacht tot de communicatie met de primaire is hersteld
- Als geen van de standbys de primaire kan zien, controleren ze of dewitness node beschikbaar is. Als het getuigenknooppunt ook niet kan worden bereikt, gaan de standbys ervan uit dat er een netwerkstoring is aan de primaire kant en gaan ze niet verder met het kiezen van een nieuwe primaire.
- Als de getuige kan worden bereikt, gaan de standbys ervan uit dat de primaire is uitgeschakeld en gaan ze verder met het kiezen van een primaire
- Het knooppunt dat is geconfigureerd als de primaire 'voorkeur', wordt dan gepromoveerd. Bij elke stand-by wordt de replicatie opnieuw geïnitialiseerd om de nieuwe primaire te volgen.
Het cluster configureren voor automatische failover
We gaan nu het cluster en dewitness node configureren voor automatische failover.
Stap 1:installeer en configureer repmgr in Witness
We hebben al gezien hoe je het repmgr-pakket installeert in ons laatste artikel. We doen dit ook in de getuigenknoop:
# wget https://download.postgresql.org/pub/repos/yum/reporpms/EL-8-x86_64/pgdg-redhat-repo-latest.noarch.rpm
En dan:
# yum install repmgr12 -y
Vervolgens voegen we de volgende regels toe aan het bestand postgresql.conf van dewitness node:
listen_addresses = '*' shared_preload_libraries = 'repmgr'
We voegen ook de volgende regels toe aan het bestand pg_hba.conf in de getuigenknoop. Merk op hoe we het CIDR-bereik van het cluster gebruiken in plaats van individuele IP-adressen op te geven.
local replication repmgr trust host replication repmgr 127.0.0.1/32 trust host replication repmgr 16.0.0.0/16 trust local repmgr repmgr trust host repmgr repmgr 127.0.0.1/32 trust host repmgr repmgr 16.0.0.0/16 trust
Opmerking
[De stappen die hier worden beschreven, zijn alleen voor demonstratiedoeleinden. Ons voorbeeld hier gebruikt extern bereikbare IP's voor de knooppunten. Het gebruik van listen_address ='*' samen met het 'trust'-beveiligingsmechanisme van pg_hba vormt daarom een beveiligingsrisico en mag NIET worden gebruikt in productiescenario's. In een productiesysteem bevinden de knooppunten zich allemaal in een of meer privésubnetten, bereikbaar via privé-IP's van jumphosts.]
Nadat de wijzigingen in postgresql.conf en pg_hba.conf zijn aangebracht, creëren we de repmgr-gebruiker en de repmgr-database in dewitness, en wijzigen we het standaard zoekpad van de repmgr-gebruiker:
[example@sqldat.comitness ~]$ createuser --superuser repmgr [example@sqldat.com ~]$ createdb --owner=repmgr repmgr [example@sqldat.com ~]$ psql -c "ALTER USER repmgr SET search_path TO repmgr, public;"
Ten slotte voegen we de volgende regels toe aan het bestand repmgr.conf, te vinden onder /etc/repmgr/12/
node_id=4 node_name='PG-Node-Witness' conninfo='host=16.0.1.37 user=repmgr dbname=repmgr connect_timeout=2' data_directory='/var/lib/pgsql/12/data'
Zodra de configuratieparameters zijn ingesteld, herstarten we de PostgreSQL-service in dewitness-node:
# systemctl restart postgresql-12.service
Om de verbinding met het getuige knooppunt repmgr te testen, kunnen we dit commando uitvoeren vanaf het primaire knooppunt:
[example@sqldat.com ~]$ psql 'host=16.0.1.37 user=repmgr dbname=repmgr connect_timeout=2'
Vervolgens registreren we dewitness node met repmgr door de opdracht "repmgrwitness register" uit te voeren als de postgres-gebruiker. Merk op hoe we het adres van de primaire . gebruiken knooppunt, en NIET het getuigenknooppunt in het onderstaande commando:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf witness register -h 16.0.1.156
Dit komt doordat de opdracht "repmgrwitness register" de metadata van dewitness node toevoegt aan de repmgr-database van de primaire node, en indien nodig, dewitness node initialiseert door de repmgr-extensie te installeren en de repmgr-metadata naar dewitness node te kopiëren.
De uitvoer ziet er als volgt uit:
INFO: connecting to witness node "PG-Node-Witness" (ID: 4) INFO: connecting to primary node NOTICE: attempting to install extension "repmgr" NOTICE: "repmgr" extension successfully installed INFO: witness registration complete NOTICE: witness node "PG-Node-Witness" (ID: 4) successfully registered
Ten slotte controleren we de status van de algehele installatie vanaf elk knooppunt:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster show --compact
De uitvoer ziet er als volgt uit:

Stap 2:Het sudoers-bestand wijzigen
Terwijl het cluster en dewitness actief zijn, voegen we de volgende regels toe aan het sudoers-bestand in elk knooppunt van het cluster en het getuigenknooppunt:
Defaults:postgres !requiretty postgres ALL = NOPASSWD: /usr/bin/systemctl stop postgresql-12.service, /usr/bin/systemctl start postgresql-12.service, /usr/bin/systemctl restart postgresql-12.service, /usr/bin/systemctl reload postgresql-12.service, /usr/bin/systemctl start repmgr12.service, /usr/bin/systemctl stop repmgr12.service
Stap 3:Repmgrd-parameters configureren
We hebben al vier parameters toegevoegd in het bestand repmgr.conf in elk knooppunt. De toegevoegde parameters zijn de basisparameters die nodig zijn voor de repmgr-bewerking. Om de repmgr-daemon en automatische failover in te schakelen, moeten een aantal andere parameters worden ingeschakeld/toegevoegd. In de volgende paragrafen beschrijven we elke parameter en de waarde waarop ze in elk knooppunt worden ingesteld.
failover
De failoverparameter is een van de verplichte parameters voor de repmgr-daemon. Deze parameter vertelt de daemon of deze een automatische failover moet starten wanneer een failover-situatie wordt gedetecteerd. Het kan twee waarden hebben:"handmatig" of "automatisch". We zullen dit instellen op automatisch in elk knooppunt:
failover='automatic'
promote_command
Dit is een andere verplichte parameter voor de repmgr-daemon. Deze parameter vertelt de repmgr-daemon welk commando het moet uitvoeren om een stand-by te promoten. De waarde van deze parameter is meestal de opdracht "repmgr standby promote", of het pad naar een shellscript dat de opdracht aanroept. Voor ons gebruik hebben we dit in elk knooppunt ingesteld op het volgende:
promote_command='/usr/pgsql-12/bin/repmgr standby promote -f /etc/repmgr/12/repmgr.conf --log-to-file'
follow_command
Dit is de derde verplichte parameter voor de repmgr-daemon. Deze parameter vertelt een standby-knooppunt om de nieuwe primaire te volgen. De repmgr-daemon vervangt de %n tijdelijke aanduiding door de node-ID van de nieuwe primaire tijdens runtime:
follow_command='/usr/pgsql-12/bin/repmgr standby follow -f /etc/repmgr/12/repmgr.conf --log-to-file --upstream-node-id=%n'
prioriteit
De parameter prioriteit voegt gewicht toe aan de geschiktheid van een knooppunt om primair te worden. Als u deze parameter op een hogere waarde instelt, komt een knooppunt meer in aanmerking om het primaire knooppunt te worden. Als u deze waarde voor een knooppunt op nul instelt, zorgt u er ook voor dat het knooppunt nooit als primair wordt gepromoot.
In onze use case hebben we twee standbys:PG-Node2 en PG-Node3. We willen PG-Node2 promoten als de nieuwe primary wanneer PG-Node1 offline gaat, en PG-Node3 om PG-Node2 te volgen als zijn nieuwe primary. We stellen de parameter in op de volgende waarden in de twee standby-knooppunten:
| Knooppuntnaam | Parameterinstelling |
| PG-Node2 | prioriteit =60 |
| PG-Node3 | prioriteit =40 |
monitor_interval_secs
Deze parameter vertelt de repmgr-daemon hoe vaak (in aantal seconden) hij de beschikbaarheid van het upstream-knooppunt moet controleren. In ons geval is er maar één stroomopwaarts knooppunt:het primaire knooppunt. De standaardwaarde is 2 seconden, maar we zullen dit hoe dan ook expliciet instellen in elk knooppunt:
monitor_interval_secs=2
connection_check_type
De parameter connection_check_type bepaalt het protocol dat de repmgr-daemon zal gebruiken om contact te maken met het stroomopwaartse knooppunt. Deze parameter kan drie waarden aannemen:
- ping :repmgr gebruikt de methode PQPing()
- verbinding :repmgr probeert een nieuwe verbinding te maken met het stroomopwaartse knooppunt
- query :repmgr probeert een SQL-query uit te voeren op het stroomopwaartse knooppunt met behulp van de bestaande verbinding
Nogmaals, we zullen deze parameter instellen op de standaardwaarde van ping in elk knooppunt:
connection_check_type='ping'
reconnect_attempts en reconnect_interval
Wanneer de primaire niet meer beschikbaar is, zal de repmgr-daemon in de stand-by-knooppunten proberen opnieuw verbinding te maken met de primaire gedurende herverbindingspogingen. De standaardwaarde voor deze parameter is 6. Tussen elke poging om opnieuw verbinding te maken, wordt gewacht op reconnect_interval seconden, wat een standaardwaarde van 10 heeft. Voor demonstratiedoeleinden gebruiken we een kort interval en minder pogingen om opnieuw verbinding te maken. We stellen deze parameter in elk knooppunt in:
reconnect_attempts=4 reconnect_interval=8
primary_visibility_consensus
Wanneer de primaire niet meer beschikbaar is in een cluster met meerdere knooppunten, kunnen de standbys met elkaar overleggen om een quorum op te bouwen over een failover. Dit wordt gedaan door elke stand-by te vragen naar de tijd waarop deze de primary voor het laatst heeft gezien. Als de laatste communicatie van een knooppunt zeer recent was en later dan het moment waarop het lokale knooppunt de primaire heeft gezien, gaat de lokale knooppunt ervan uit dat de primaire knooppunt nog steeds beschikbaar is en gaat het niet door met een failover-beslissing.
Om dit consensusmodel mogelijk te maken, moet de parameter primary_visibility_consensus worden ingesteld op "true" in elk knooppunt - inclusief de getuige:
primary_visibility_consensus=true
standby_disconnect_on_failover
Wanneer de parameter standby_disconnect_on_failover is ingesteld op "true" in een standby-knooppunt, zorgt de repmgr-daemon ervoor dat zijn WAL-ontvanger wordt losgekoppeld van de primaire en geen WAL-segmenten ontvangt. Het zal ook wachten tot de WAL-ontvangers van andere standby-knooppunten stoppen voordat een failover-beslissing wordt genomen. Deze parameter moet in elk knooppunt op dezelfde waarde worden ingesteld. We zetten dit op "true".
standby_disconnect_on_failover=true
Als u deze parameter instelt op true, betekent dit dat elk standby-knooppunt geen gegevens meer ontvangt van de primaire als de failover plaatsvindt. Het proces heeft een vertraging van 5 seconden plus de tijd die de WAL-ontvanger nodig heeft om te stoppen voordat een failover-beslissing wordt genomen. Standaard wacht de repmgr-daemon 30 seconden om te bevestigen dat alle verwante nodes geen WAL-segmenten meer ontvangen voordat de failover plaatsvindt.
repmgrd_service_start_command en repmgrd_service_stop_command
Deze twee parameters specificeren hoe de repmgr-daemon moet worden gestart en gestopt met behulp van de opdrachten "repmgr daemon start" en "repmgr daemon stop".
Kortom, deze twee opdrachten zijn wrappers rond opdrachten van het besturingssysteem voor het starten/stoppen van de service. De twee parameterwaarden wijzen deze opdrachten toe aan hun OS-specifieke versies. We stellen deze parameters in op de volgende waarden in elk knooppunt:
repmgrd_service_start_command='sudo /usr/bin/systemctl start repmgr12.service' repmgrd_service_stop_command='sudo /usr/bin/systemctl stop repmgr12.service'
PostgreSQL Service Start/Stop/Herstart Commando's
Als onderdeel van zijn werking zal de repmgr-daemon vaak de PostgreSQL-service moeten stoppen, starten of herstarten. Om ervoor te zorgen dat dit soepel gebeurt, is het het beste om de bijbehorende commando's van het besturingssysteem op te geven als parameterwaarden in het bestand repmgr.conf. We zullen voor dit doel vier parameters in elk knooppunt instellen:
service_start_command='sudo /usr/bin/systemctl start postgresql-12.service' service_stop_command='sudo /usr/bin/systemctl stop postgresql-12.service' service_restart_command='sudo /usr/bin/systemctl restart postgresql-12.service' service_reload_command='sudo /usr/bin/systemctl reload postgresql-12.service'
monitoring_history
Als u de parameter monitoring_history instelt op "yes", zorgt u ervoor dat repmgr zijn clusterbewakingsgegevens opslaat. We stellen dit in op "ja" in elk knooppunt:
monitoring_history=yes
log_status_interval
We stellen de parameter in elk knooppunt in om aan te geven hoe vaak de repmgr-daemon een statusbericht zal loggen. In dit geval stellen we dit in op elke 60 seconden:
log_status_interval=60
Stap 4:De repmgr Daemon starten
Met de parameters die nu zijn ingesteld in het cluster en het knooppunt van de getuige, voeren we een test uit van het commando om de repmgr-daemon te starten. We testen dit eerst in de primaire node, dan in de twee standby-nodes, gevolgd door dewitness node. Het commando moet worden uitgevoerd als de postgres-gebruiker:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf daemon start --dry-run
De uitvoer zou er als volgt uit moeten zien:
INFO: prerequisites for starting repmgrd met DETAIL: following command would be executed: sudo /usr/bin/systemctl start repmgr12.service
Vervolgens starten we de daemon in alle vier de nodes:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf daemon start
De uitvoer in elk knooppunt moet laten zien dat de daemon is gestart:
NOTICE: executing: "sudo /usr/bin/systemctl start repmgr12.service" NOTICE: repmgrd was successfully started
We kunnen de opstartgebeurtenis van de service ook controleren vanaf de primaire of stand-by-knooppunten:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster event --event=repmgrd_start
De uitvoer zou moeten laten zien dat de daemon de verbindingen bewaakt:
Node ID | Name | Event | OK | Timestamp | Details --------+-----------------+---------------+----+---------------------+------------------------------------------------------------------ 4 | PG-Node-Witness | repmgrd_start | t | 2020-02-05 11:37:31 | witness monitoring connection to primary node "PG-Node1" (ID: 1) 3 | PG-Node3 | repmgrd_start | t | 2020-02-05 11:37:24 | monitoring connection to upstream node "PG-Node1" (ID: 1) 2 | PG-Node2 | repmgrd_start | t | 2020-02-05 11:37:19 | monitoring connection to upstream node "PG-Node1" (ID: 1) 1 | PG-Node1 | repmgrd_start | t | 2020-02-05 11:37:14 | monitoring cluster primary "PG-Node1" (ID: 1)
Ten slotte kunnen we de daemon-uitvoer van de syslog in elk van de standbys controleren:
# cat /var/log/messages | grep repmgr | less
Hier is de uitvoer van PG-Node3:
Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [NOTICE] using provided configuration file "/etc/repmgr/12/repmgr.conf" Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [NOTICE] repmgrd (repmgrd 5.0.0) starting up Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [INFO] connecting to database "host=16.0.3.52 user=repmgr dbname=repmgr connect_timeout=2" Feb 5 11:37:24 PG-Node3 systemd[1]: repmgr12.service: Can't open PID file /run/repmgr/repmgrd-12.pid (yet?) after start: No such file or directory Feb 5 11:37:24 PG-Node3 repmgrd[2014]: INFO: set_repmgrd_pid(): provided pidfile is /run/repmgr/repmgrd-12.pid Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [NOTICE] starting monitoring of node "PG-Node3" (ID: 3) Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [INFO] "connection_check_type" set to "ping" Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [INFO] monitoring connection to upstream node "PG-Node1" (ID: 1) Feb 5 11:38:25 PG-Node3 repmgrd[2014]: [2020-02-05 11:38:25] [INFO] node "PG-Node3" (ID: 3) monitoring upstream node "PG-Node1" (ID: 1) in normal state Feb 5 11:38:25 PG-Node3 repmgrd[2014]: [2020-02-05 11:38:25] [DETAIL] last monitoring statistics update was 2 seconds ago Feb 5 11:39:26 PG-Node3 repmgrd[2014]: [2020-02-05 11:39:26] [INFO] node "PG-Node3" (ID: 3) monitoring upstream node "PG-Node1" (ID: 1) in normal state … …
Het controleren van de syslog in het primaire knooppunt toont een ander type uitvoer:
Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [NOTICE] using provided configuration file "/etc/repmgr/12/repmgr.conf" Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [NOTICE] repmgrd (repmgrd 5.0.0) starting up Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [INFO] connecting to database "host=16.0.1.156 user=repmgr dbname=repmgr connect_timeout=2" Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [NOTICE] starting monitoring of node "PG-Node1" (ID: 1) Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [INFO] "connection_check_type" set to "ping" Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [NOTICE] monitoring cluster primary "PG-Node1" (ID: 1) Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [INFO] child node "PG-Node-Witness" (ID: 4) is not yet attached Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [INFO] child node "PG-Node3" (ID: 3) is attached Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [INFO] child node "PG-Node2" (ID: 2) is attached Feb 5 11:37:32 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:32] [NOTICE] new witness "PG-Node-Witness" (ID: 4) has connected Feb 5 11:38:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:38:14] [INFO] monitoring primary node "PG-Node1" (ID: 1) in normal state Feb 5 11:39:15 PG-Node1 repmgrd[2017]: [2020-02-05 11:39:15] [INFO] monitoring primary node "PG-Node1" (ID: 1) in normal state … …
Stap 5:Een mislukte primaire simulatie simuleren
Nu gaan we een mislukte primary simuleren door de primaire node (PG-Node1) te stoppen. Vanaf de shell-prompt van het knooppunt voeren we de volgende opdracht uit:
# systemctl stop postgresql-12.service
Het failoverproces
Zodra het proces stopt, wachten we ongeveer een minuut of twee en controleren dan het syslog-bestand van PG-Node2. De volgende berichten worden getoond. Voor de duidelijkheid en eenvoud hebben we kleurgecodeerde groepen berichten en toegevoegde witruimten tussen regels:
… Feb 5 11:53:36 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:36] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr" Feb 5 11:53:36 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:36] [DETAIL] PQping() returned "PQPING_NO_RESPONSE" Feb 5 11:53:36 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:36] [INFO] sleeping 8 seconds until next reconnection attempt Feb 5 11:53:44 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:44] [INFO] checking state of node 1, 2 of 4 attempts Feb 5 11:53:44 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:44] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr" Feb 5 11:53:44 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:44] [DETAIL] PQping() returned "PQPING_NO_RESPONSE" Feb 5 11:53:44 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:44] [INFO] sleeping 8 seconds until next reconnection attempt Feb 5 11:53:52 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:52] [INFO] checking state of node 1, 3 of 4 attempts Feb 5 11:53:52 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:52] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr" Feb 5 11:53:52 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:52] [DETAIL] PQping() returned "PQPING_NO_RESPONSE" Feb 5 11:53:52 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:52] [INFO] sleeping 8 seconds until next reconnection attempt Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] checking state of node 1, 4 of 4 attempts Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr" Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [DETAIL] PQping() returned "PQPING_NO_RESPONSE" Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [WARNING] unable to reconnect to node 1 after 4 attempts Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] setting "wal_retrieve_retry_interval" to 86405000 milliseconds Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [WARNING] wal receiver not running Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] WAL receiver disconnected on all sibling nodes Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] WAL receiver disconnected on all 2 sibling nodes Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] local node's last receive lsn: 0/2214A000 Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] checking state of sibling node "PG-Node3" (ID: 3) Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node "PG-Node3" (ID: 3) reports its upstream is node 1, last seen 26 second(s) ago Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node 3 last saw primary node 26 second(s) ago Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] last receive LSN for sibling node "PG-Node3" (ID: 3) is: 0/2214A000 Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node "PG-Node3" (ID: 3) has same LSN as current candidate "PG-Node2" (ID: 2) Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node "PG-Node3" (ID: 3) has lower priority (40) than current candidate "PG-Node2" (ID: 2) (60) Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] checking state of sibling node "PG-Node-Witness" (ID: 4) Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node "PG-Node-Witness" (ID: 4) reports its upstream is node 1, last seen 26 second(s) ago Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node 4 last saw primary node 26 second(s) ago Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] visible nodes: 3; total nodes: 3; no nodes have seen the primary within the last 4 seconds … … Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] promotion candidate is "PG-Node2" (ID: 2) Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] setting "wal_retrieve_retry_interval" to 5000 ms Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] this node is the winner, will now promote itself and inform other nodes … … Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] promoting standby to primary Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [DETAIL] promoting server "PG-Node2" (ID: 2) using pg_promote() Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] waiting up to 60 seconds (parameter "promote_check_timeout") for promotion to complete Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [NOTICE] STANDBY PROMOTE successful Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [DETAIL] server "PG-Node2" (ID: 2) was successfully promoted to primary Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [INFO] 2 followers to notify Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [NOTICE] notifying node "PG-Node3" (ID: 3) to follow node 2 Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [NOTICE] notifying node "PG-Node-Witness" (ID: 4) to follow node 2 Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [INFO] switching to primary monitoring mode Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [NOTICE] monitoring cluster primary "PG-Node2" (ID: 2) Feb 5 11:54:07 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:07] [NOTICE] new witness "PG-Node-Witness" (ID: 4) has connected Feb 5 11:54:07 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:07] [NOTICE] new standby "PG-Node3" (ID: 3) has connected Feb 5 11:54:07 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:07] [NOTICE] new standby "PG-Node3" (ID: 3) has connected Feb 5 11:55:02 PG-Node2 repmgrd[2165]: [2020-02-05 11:55:02] [INFO] monitoring primary node "PG-Node2" (ID: 2) in normal state Feb 5 11:56:02 PG-Node2 repmgrd[2165]: [2020-02-05 11:56:02] [INFO] monitoring primary node "PG-Node2" (ID: 2) in normal state … …
There is a lot of information here, but let’s break down how the events have unfolded. For simplicity, we have grouped messages and placed whitespaces between the groups.
The first set of messages shows the repmgr daemon is trying to connect to the primary node (node ID 1) four times using PQPing(). This is because we specified the connection_check_type parameter to “ping” in the repmgr.conf file. After 4 attempts, the daemon reports it cannot connect to the primary node.
The next set of messages tells us the standbys have disconnected their WAL receivers. This is because we had set the parameter standby_disconnect_on_failover to “true” in the repmgr.conf file.
In the next set of messages, the standby nodes and the witness inquire about the last received LSN from the primary and the last time each saw the primary. The last received LSNs match for both the standby nodes. The nodes agree they cannot see the primary within the last 4 seconds. Note how repmgr daemon also finds PG-Node3 has a lower priority for promotion. As none of the nodes have seen the primary recently, they can reach a quorum that the primary is down.
After this, we have messages that show repmgr is choosing PG-Node2 as the promotion candidate. It declares the node winner and says the node will promote itself and inform other nodes.
The group of messages after this shows PG-Node2 successfully promoting to the primary role. Once that’s done, the nodes PG-Node3 (node ID 3) and PG-Node-Witness (node ID 4) are signaled to follow the newly promoted primary.
The final set of messages shows the two nodes have connected to the new primary and the repmgr daemon has started monitoring the local node.
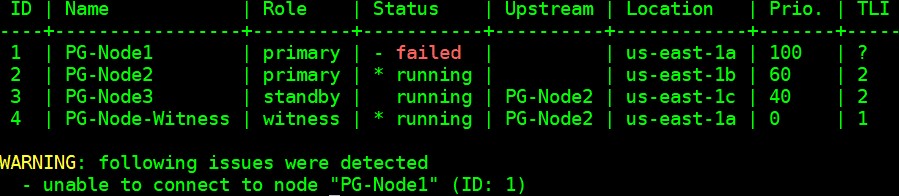
Our cluster is now back in action. We can confirm this by running the “repmgr cluster show” command:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster show --compact
The output shown in the image below is self-explanatory:
We can also look for the events by running the “repmgr cluster event” command:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster event
The output displays how it happened:
Node ID | Name | Event | OK | Timestamp | Details --------+-----------------+----------------------------+----+---------------------+------------------------------------------------------------------------------------ 3 | PG-Node3 | repmgrd_failover_follow | t | 2020-02-05 11:54:08 | node 3 now following new upstream node 2 3 | PG-Node3 | standby_follow | t | 2020-02-05 11:54:08 | standby attached to upstream node "PG-Node2" (ID: 2) 2 | PG-Node2 | child_node_new_connect | t | 2020-02-05 11:54:07 | new standby "PG-Node3" (ID: 3) has connected 2 | PG-Node2 | child_node_new_connect | t | 2020-02-05 11:54:07 | new witness "PG-Node-Witness" (ID: 4) has connected 4 | PG-Node-Witness | repmgrd_upstream_reconnect | t | 2020-02-05 11:54:02 | witness monitoring connection to primary node "PG-Node2" (ID: 2) 4 | PG-Node-Witness | repmgrd_failover_follow | t | 2020-02-05 11:54:02 | witness node 4 now following new primary node 2 2 | PG-Node2 | repmgrd_reload | t | 2020-02-05 11:54:01 | monitoring cluster primary "PG-Node2" (ID: 2) 2 | PG-Node2 | repmgrd_failover_promote | t | 2020-02-05 11:54:01 | node 2 promoted to primary; old primary 1 marked as failed 2 | PG-Node2 | standby_promote | t | 2020-02-05 11:54:01 | server "PG-Node2" (ID: 2) was successfully promoted to primary 1 | PG-Node1 | child_node_new_connect | t | 2020-02-05 11:37:32 | new witness "PG-Node-Witness" (ID: 4) has connected
Conclusie
This completes our two-part series on repmgr and its daemon repmgrd. As we saw in the first part, setting up a multi-node PostgreSQL replication is very simple with repmgr. The daemon makes it even easier to automate a failover. It also automatically redirects existing standbys to follow the new primary. In native PostgreSQL replication, all existing standbys have to be manually configured to replicate from the new primary – automating this process saves valuable time and effort for the DBA.
One thing we have not covered here is “fencing off” the failed primary. In a failover situation, a failed primary needs to be removed from the cluster, and remain inaccessible to client connections. This is to prevent any split-brain situation in the event the old primary accidentally comes back online. The repmgr daemon can work with a connection-pooling tool like pgbouncer to implement the fence-off process. For more information, you can refer to this 2ndQuadrant Github documentation.
Also, after a failover, applications connecting to the cluster need to have their connection strings changed to repoint to the new master. This is a big topic in itself and we will not go into the details here, but one of the methods to address this can be the use of a virtual IP address (and associated DNS resolution) to hide the underlying master node of the cluster.
How to Automate PostgreSQL 12 Replication and Failover with repmgr – Part 1