Dit artikel geeft een stapsgewijze handleiding voor het gebruik van Machine Learning-mogelijkheden met 2UDA. In het artikel gebruiken we een voorbeeld van dieren om te voorspellen of het zoogdieren, vogels, vissen of insecten zijn.
Softwareversies
We gaan 2UDA versie 11.6-1 gebruiken om het Machine Learning-model te implementeren. 2UDA versie 11.6-1 combineert:
- PostgreSQL 11.6
- Oranje 3.23.0
Je kunt de nieuwste versie van 2UDA hier vinden.
Stap 1:Laad trainingsdataset in PostgreSQL
De voorbeelddataset die wordt gebruikt om ons model te trainen, is hier beschikbaar in de officiële Orange GitHub-repository.
Volg deze stappen om de trainingsgegevens in PostgreSQL-tabellen te laden:
- Maak verbinding met PostgreSQL via psql, OmniDB of een andere tool waarmee u bekend bent.
- Maak een tabel om onze trainingsgegevens op te slaan . Hier wordt het genoemd als training_data.
CREATE TABLE training_data( name VARCHAR (100), hair integer, feathers integer, eggs integer, milk integer, airborne integer, aquatic integer, predator integer, toothed integer, backbone integer, breathes integer, venomous integer, fins integer, legs integer, tail integer, domestic integer, catsize integer, type VARCHAR (100) );
- Voeg trainingsgegevens in de tabel in via COPY-query. Voordat u de COPY-query uitvoert, moet u ervoor zorgen dat PostgreSQL leesrechten heeft voor het gegevensbestand, anders mislukt de COPY-bewerking.
OPMERKING: Zorg ervoor dat u een tabblad typt spatie tussen enkele aanhalingstekens na het scheidingsteken zoekwoord.
COPY training_data FROM 'Path_to_training_data_file’ with delimiter ' ' csv header;
Hieronder vindt u de screenshot van de trainingsdataset
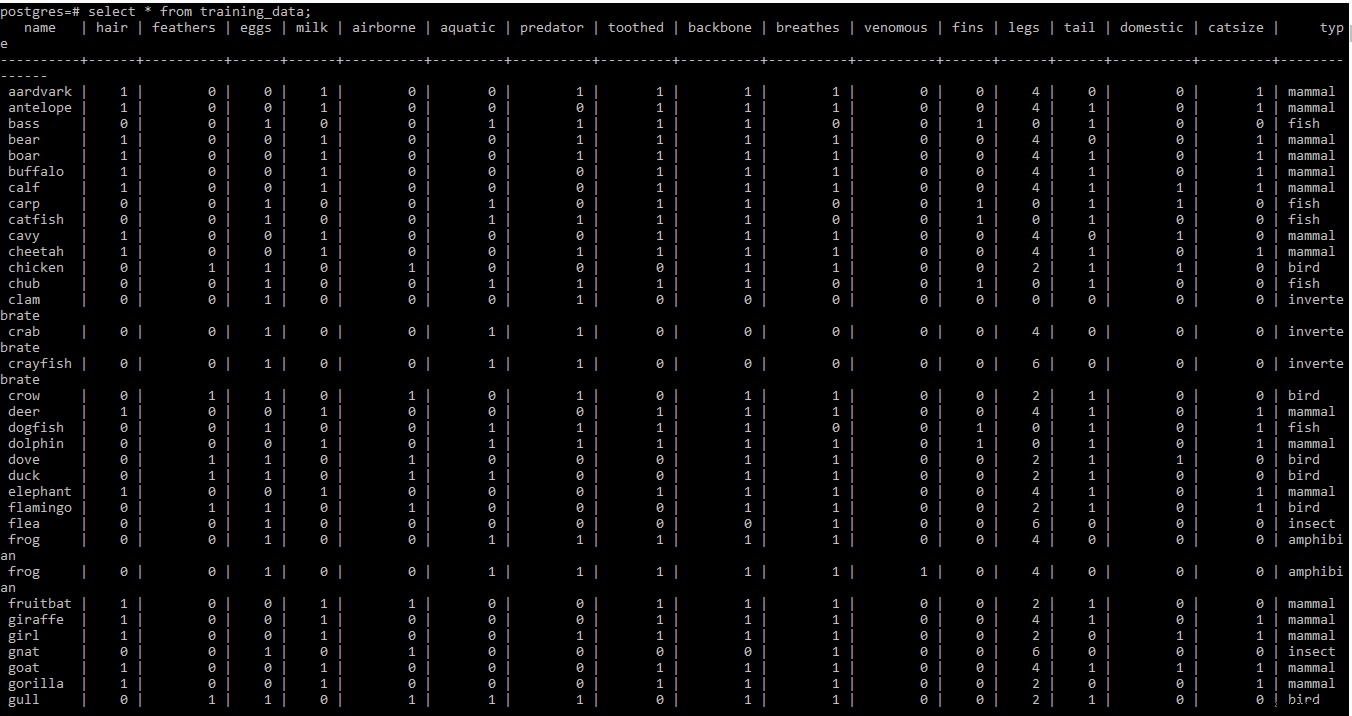
OPMERKING: Rijen twee en drie van de trainingsdataset op het .tabblad bestand wat meta-informatie bevatten. Omdat het op dit moment niet nodig is, is het uit het bestand verwijderd.
Stap 2:Creëer een workflow met Orange
- Ga naar het bureaublad en dubbelklik op het oranje pictogram.
- Zo ziet de startpagina eruit. Selecteer Nieuw optie en het zal een leeg project creëren.

Nu bent u klaar om het Machine Learning-model op de dataset toe te passen.
Stap 3:Selecteer Machine Learning-model om de gegevens te trainen
Voor dit artikel, k-nearest buren (KNN) Machine Learning-model wordt gebruikt om de gegevens te trainen. Zodra het gegevenstrainingsproces is voltooid, worden in de volgende stap testgegevens doorgegeven aan de Voorspelling widget om de nauwkeurigheid van voorspellingen te controleren.
Stap 4:Importeer trainingsgegevens van PostgreSQL naar Orange
Deze trainingsdataset wordt gebruikt om het Machine Learning-model te trainen.
- Slepen en neerzetten SQL-tabel widget uit de Data menu.
- Naam widget wijzigen (optioneel)
- Klik met de rechtermuisknop op de SQL-tabel widget.
- Selecteer Naam wijzigen .
- Maak verbinding met PostgreSQL om de trainingsdataset te laden:
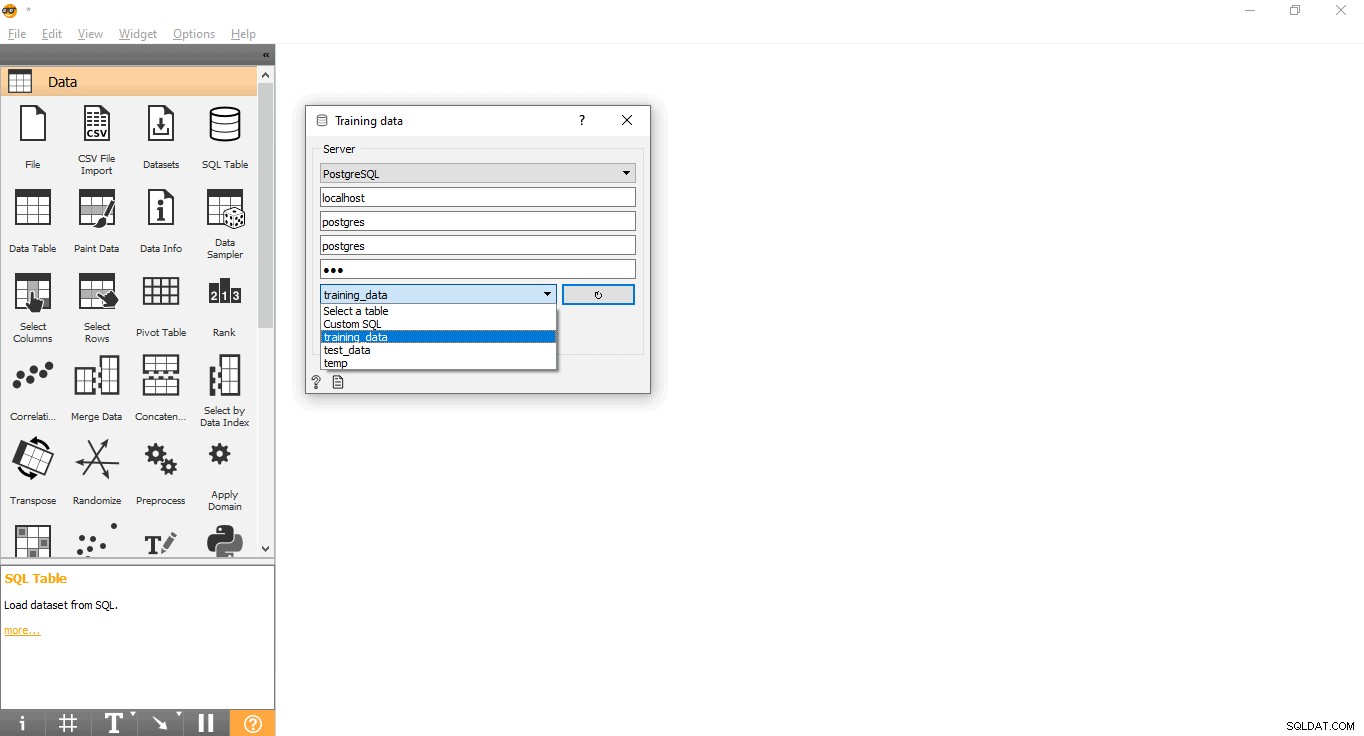
- Dubbelklik op de Trainingsgegevens widget.
- Voer inloggegevens in om verbinding te maken met de PostgreSQL-database.
- Druk op de herlaadknop om alle beschikbare tabellen uit de gegeven database te laden.
- Selecteer de training_data-tabel in het vervolgkeuzemenu en sluit de pop-up.
Stap 5:Doelkolom toevoegen
Deze stap is belangrijk omdat het Machine Learning-model zal proberen de gegevens voor deze doelvariabele/kolom te voorspellen:
- Slepen en neerzetten Kolommen selecteren widget uit de gegevens menu.
- Dubbelklik op de Kolommen selecteren widget.
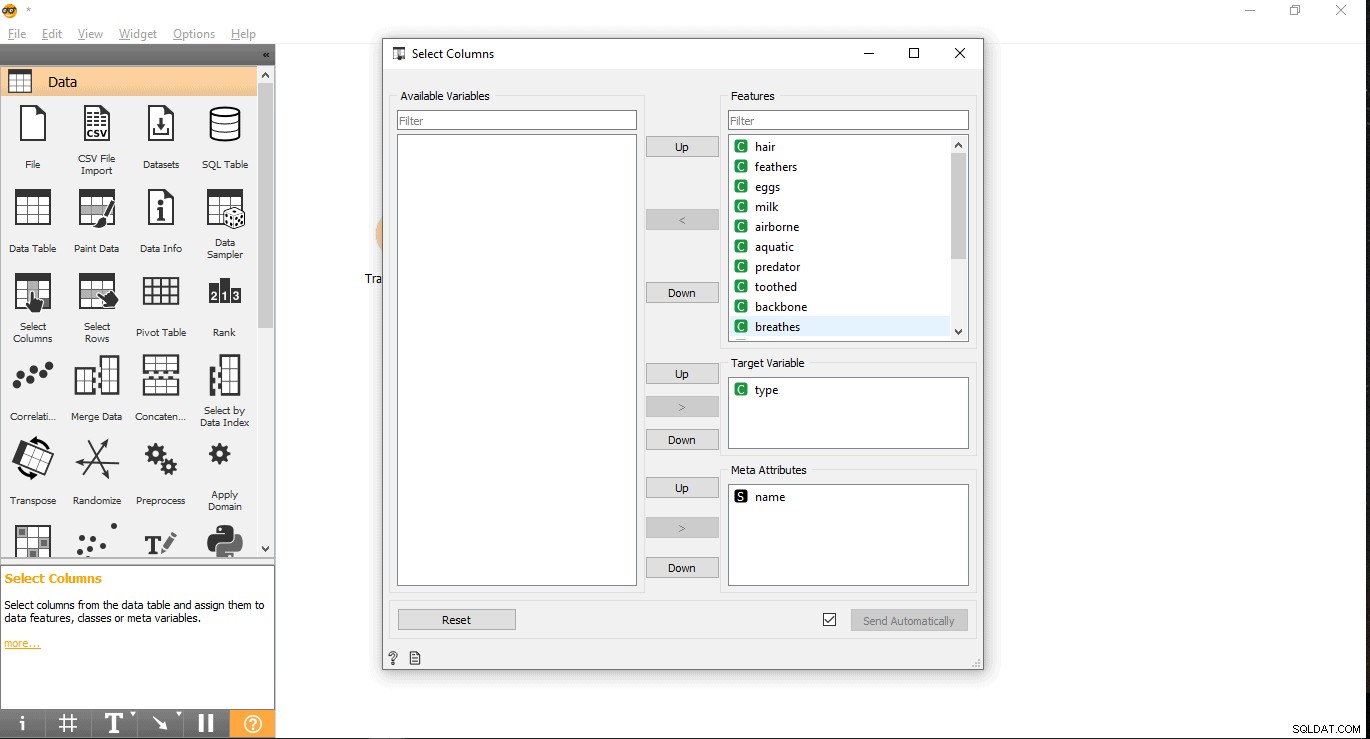
- Zoek in uw doelkolom onder het label Functies. Hier wordt type gebruikt als doelvariabele omdat we moeten zien welk type een bepaald dier is.
- Sleep het en zet het neer onder Doelvariabele en sluit de pop-up.
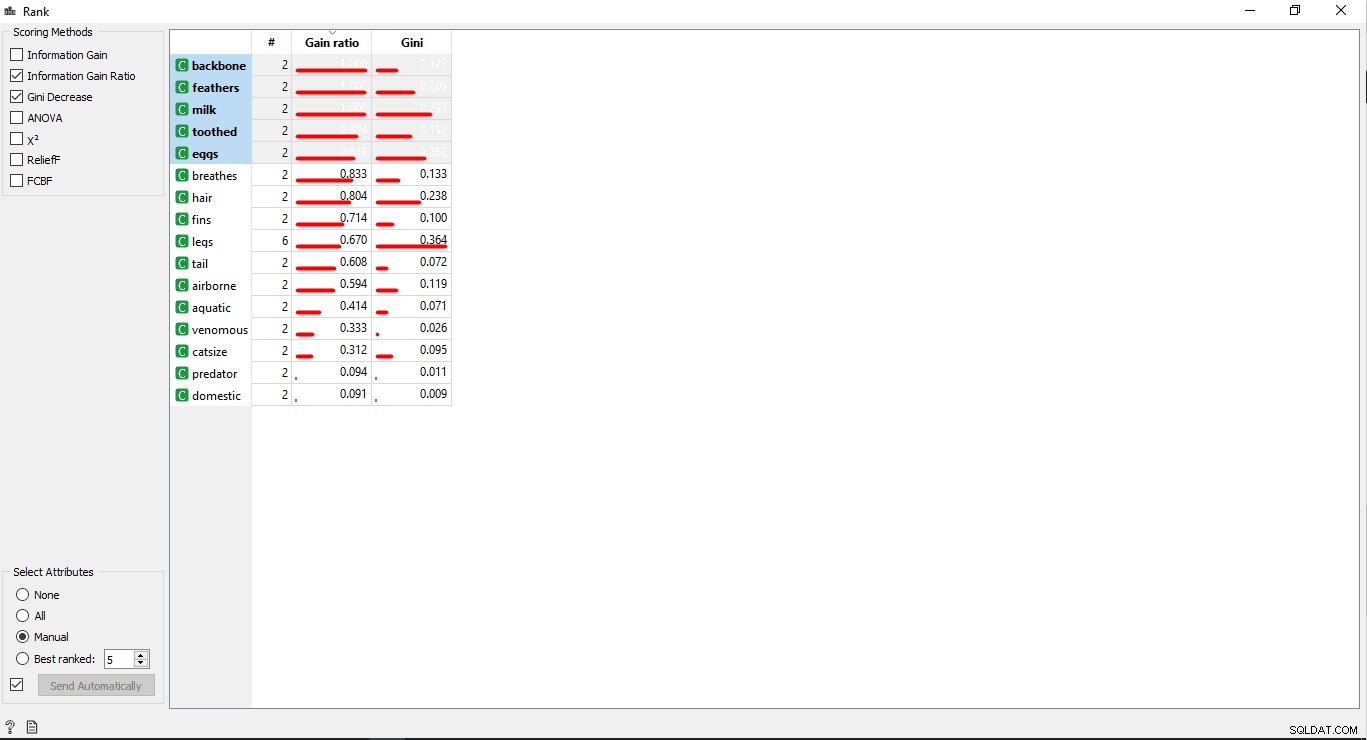
Stap 6:Kolommenrangschikking
U kunt de trainingsvariabele/kolommen rangschikken of scoren op basis van hun correlatie met de doelkolom.
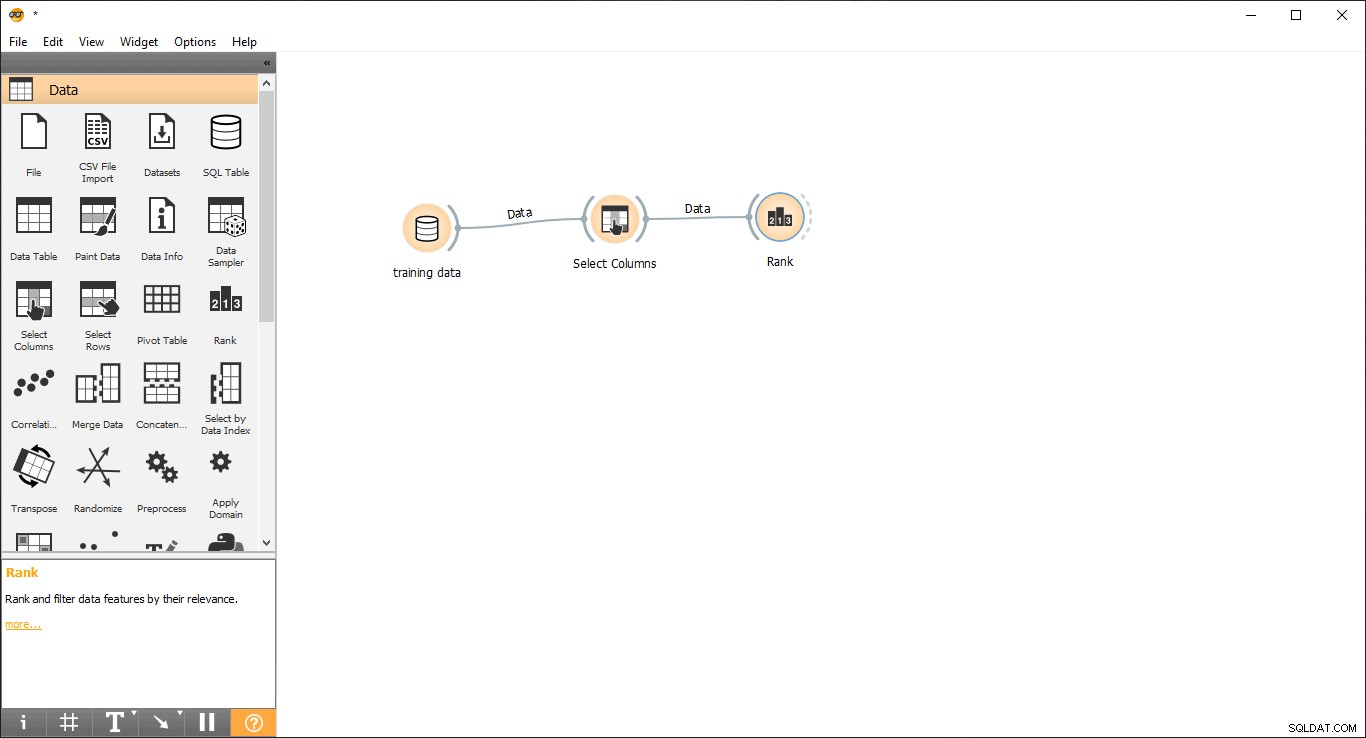
- Slepen en neerzetten Rank widget uit de gegevens menu.
- Trek een linklijn uit Kolommen selecteren widget naar Rank widget .
- Dubbelklik op de Rank widget om de meest gerelateerde kolommen in de trainingsgegevenstabel te zien. Het selecteert standaard de bovenste 5 kolommen.
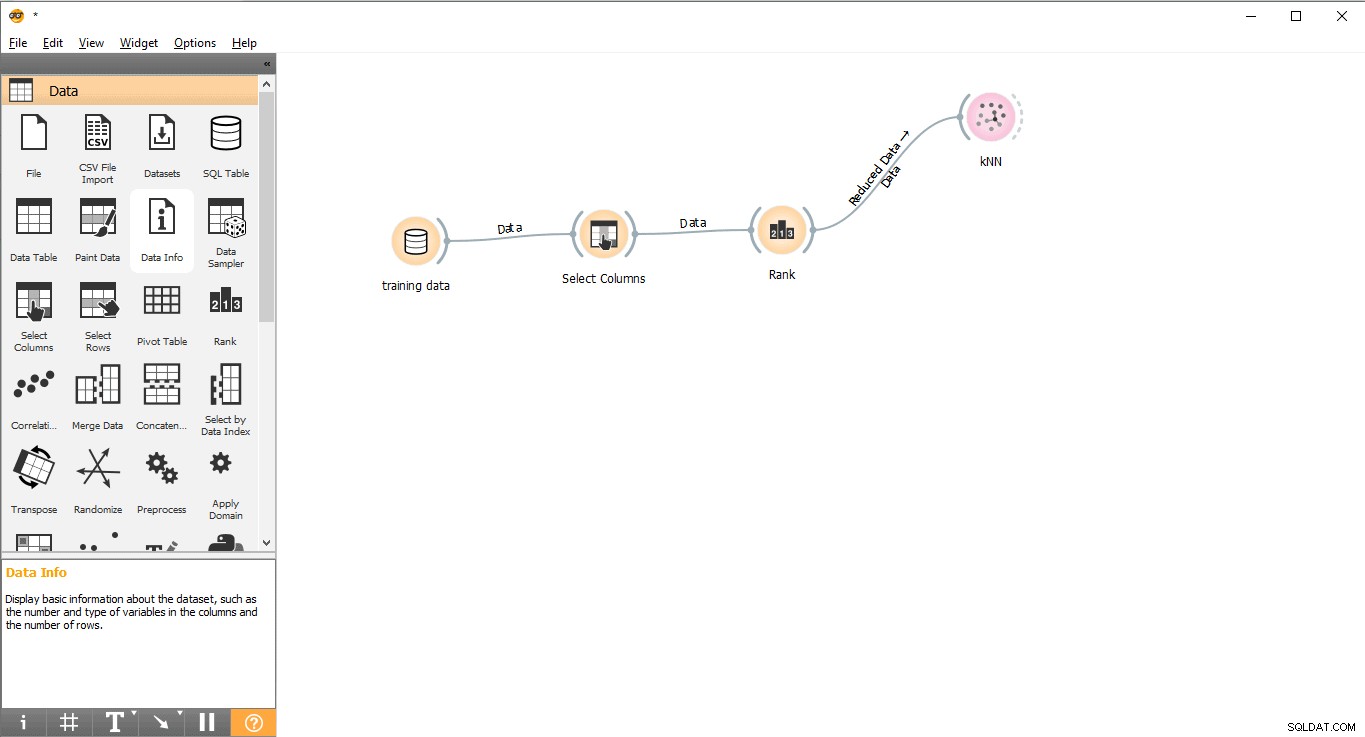
Stap 7:Datatraining
In deze stap wordt het Machine Learning Model (KNN) getraind met de trainingsdataset. Volg de volgende stappen:
- Slepen en neerzetten KNN widget van het Model menu.
- Trek een linklijn van Rang widget naar KNN widget.
Stap 8:Laad testdataset in PostgreSQL
Er wordt een aparte testdataset gemaakt om voorspellingen uit te voeren. Volg de stappen om de testdataset in de PostgreSQL-tabel te laden.
- Maak een tabel om onze testgegevens op te slaan . Hier wordt het genoemd als test_data.
CREATE TABLE test_data( name VARCHAR (100), hair integer, feathers integer, eggs integer, milk integer, airborne integer, aquatic integer, predator integer, toothed integer, backbone integer, breathes integer, venomous integer, fins integer, legs integer, tail integer, domestic integer, catsize integer, type VARCHAR (100) );
- Voeg testgegevens in de testtabel in via COPY vraag. Voordat u COPY uitvoert query zorg ervoor dat PostgreSQL leesrechten heeft voor het gegevensbestand, anders mislukt de KOPIEER-bewerking.
OPMERKING: Zorg ervoor dat u een tabblad typt spatie tussen enkele aanhalingstekens na het scheidingsteken trefwoord. Er is opzettelijk een vraagteken geplaatst in het type kolom van de testdataset omdat we het type van een bepaald dier moeten achterhalen met ons Machine Learning-model.
COPY test_data FROM 'Path_to_test_data_file’ with delimiter ' ' csv header;
Hieronder vindt u de screenshot van de testdataset

Stap 9:Importeer de testgegevens van PostgreSQL in Orange
Volg de volgende stappen om de voorspellingen toe te passen.
- Slepen en neerzetten SQL-tabel widget uit de gegevens menu.
- Naam widget wijzigen (optioneel)
- Klik met de rechtermuisknop op de SQL-tabel widget.
- Selecteer Naam wijzigen .
- Maak verbinding met PostgreSQL om testgegevens te laden.
- Dubbelklik op Testgegevens widget.
- Verbind het met Testgegevens tabel van PostgreSQL.
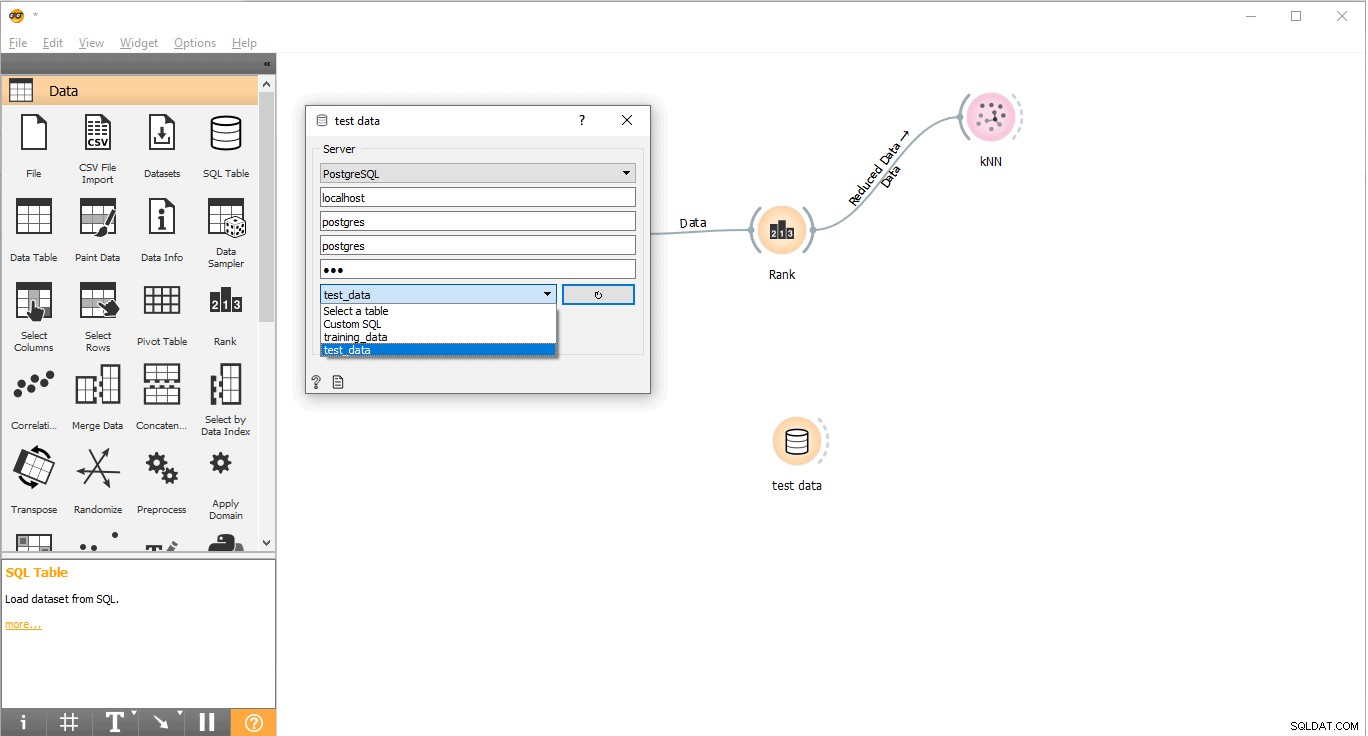
Nu zijn we klaar om voorspellingen uit te voeren.
Stap 10:Voorspellingen
Voorspelling widget probeert de testgegevens te voorspellen op basis van trainingsgegevens van KNN .
- Slepen en neerzetten Voorspelling widget van de Evalueren menu.
- Teken een linklijnformulier Testgegevens widget naar Voorspelling widget.
- Trek een linklijn van KNN widget naar Voorspelling widget.
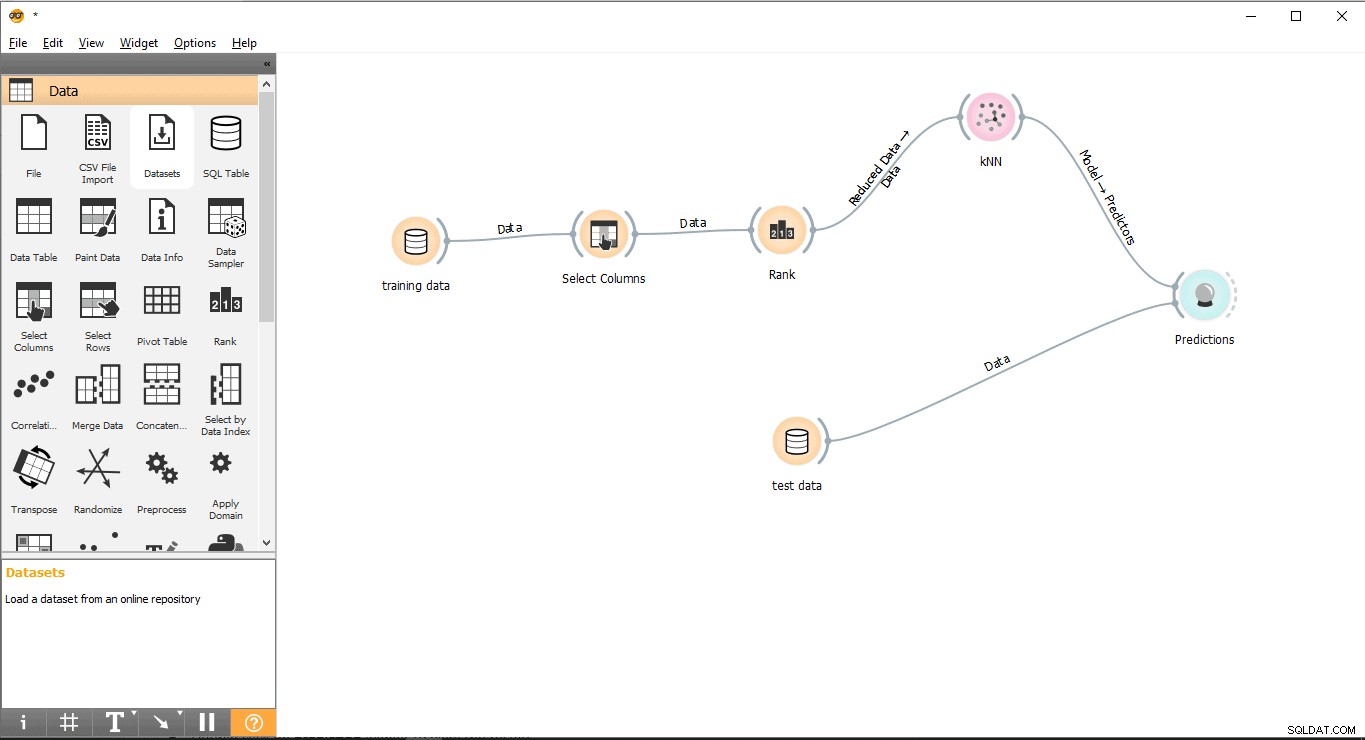
Stap 11:Resultaten
Dubbelklik op Voorspelling widget om de resultaten te bekijken.
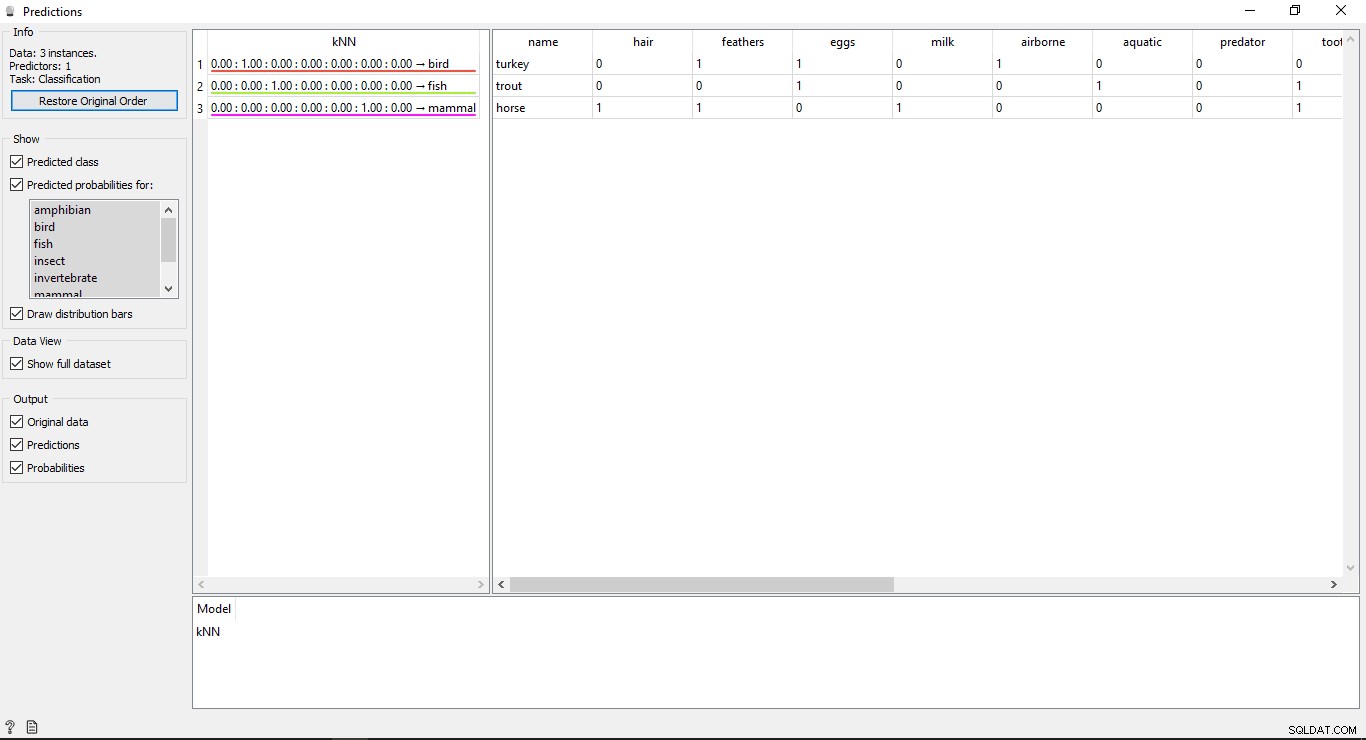
De resultaten begrijpen
U ziet 2 hoofdtabellen in het voorspellingsvenster. De tabel aan de linkerkant toont de voorspelde resultaten, terwijl de tabel aan de rechterkant de originele testgegevens toont, die werden verstrekt voor voorspellingen.
Sinds de KNN model is gebruikt om gegevens te trainen, dus u ziet één kolom met de naam KNN dat geeft de resultaten weer.
Zoals we weten:
- Paard is een Zoogdier
- Forel is een Vis
- Turkije is een Vogel
Zo kan KNN alle typen correct bepalen.
Nauwkeurigheid van voorspellingen
Als u de tabel aan de linkerkant in de uitvoer van de voorspellingswidget ziet, heeft deze enkele cijfers vóór het voorspelde type, d.w.z. 1,00. 0.00 Deze getallen geven de nauwkeurigheid van het voorspelde type weer.
We hebben 7 soorten dieren gebruikt in de trainingsgegevensset, dus het toont een totaal aantal van 7 kolommen met nauwkeurigheidswaarden, elke kolom vertegenwoordigt 1 type dier. U kunt controleren welke kolom welk type dier vertegenwoordigt door te kijken naar de lijst aan de linkerkant van uw scherm onder Voorspelde kansen voor label. Als je kijkt naar de eerste rij die zegt Turkije is een Vogel . We kunnen zien dat de nauwkeurigheid 1.00 . is (100% uit 2e kolom). Hetzelfde geldt voor andere voorbeelden Forel is een Vis en de nauwkeurigheid is 1.00 (100% uit 3e kolom).
In dit artikel hebben we het algoritme van de k-nearest buren (KNN) gebruikt om het Machine Learning-model te implementeren. In de volgende blog gebruiken we de Support Vector Machine (SVM)-model.
Neem voor vragen of opmerkingen contact met ons op via het contactformulier hier.