Recovery Time Objective (RTO) is de tijdsperiode waarbinnen een dienst moet worden hersteld om onaanvaardbare gevolgen te voorkomen. Door te berekenen hoe lang het kan duren om te herstellen van een databasefout, kunnen we weten welk voorbereidingsniveau vereist is. Als RTO een paar minuten is, is een aanzienlijke investering in failover vereist. Een RTO van 36 uur vereist een aanzienlijk lagere investering. Dit is waar failover-automatisering van pas komt.
In onze vorige blogs hebben we het gehad over failover voor MongoDB, MySQL/MariaDB/Percona, PostgreSQL of TimeScaleDB. Om het samen te vatten, "Failover " is het vermogen van een systeem om te blijven functioneren, zelfs als er een storing optreedt. Het suggereert dat de functies van het systeem worden overgenomen door secundaire componenten als de primaire componenten falen. Failover is een natuurlijk onderdeel van elk systeem met hoge beschikbaarheid, en in sommige gevallen , het moet zelfs worden geautomatiseerd. Handmatige failovers duren gewoon te lang, maar er zijn gevallen waarin automatisering niet goed zal werken - bijvoorbeeld in het geval van een gespleten brein waar databasereplicatie wordt verbroken en de twee 'helften' effectief updates blijven ontvangen wat leidt tot uiteenlopende datasets en inconsistentie.
We schreven eerder over de leidende principes achter automatische failover-procedures van ClusterControl. Waar mogelijk biedt geautomatiseerde failover efficiëntie omdat het snel herstel van storingen mogelijk maakt. In deze blog bekijken we hoe u met ClusterControl automatische failover kunt realiseren in een master-slave (of primary-standby) replicatieconfiguratie.
Vereisten voor technologiestack
Een stapel kan worden samengesteld uit Open Source Software-componenten en er zijn een aantal opties beschikbaar - sommige meer geschikt dan andere, afhankelijk van de failover-kenmerken en ook het beschikbare expertiseniveau voor het beheren en onderhouden van de oplossing. Hardware en netwerken zijn ook belangrijke aspecten.
Software
Er zijn veel opties beschikbaar in het open source-ecosysteem die u kunt gebruiken om failover te implementeren. Voor MySQL kunt u profiteren van MHA, MMM, Maxscale/MRM, mysqlfailover of Orchestrator. Deze vorige blog vergelijkt MaxScale met MHA met Maxscale/MRM. PostgreSQL heeft repmgr, Patroni, PostgreSQL Automatic Failover (PAF), pglookout, pgPool-II of stolon. Deze verschillende opties voor hoge beschikbaarheid kwamen eerder aan bod. MongoDB heeft replicasets met ondersteuning voor geautomatiseerde failover.
ClusterControl biedt automatische failover-functionaliteit voor MySQL, MariaDB, PostgreSQL en MongoDB, die we verderop zullen bespreken. Het is de moeite waard om op te merken dat het ook functionaliteit heeft om automatisch kapotte knooppunten of clusters te herstellen.
Hardware
Automatische failover wordt meestal uitgevoerd door een afzonderlijke daemon-server die op zijn eigen hardware is ingesteld - los van de databaseknooppunten. Het bewaakt de status van de databases en gebruikt de informatie om beslissingen te nemen over hoe te reageren in geval van storing.
Commodity-servers kunnen prima werken, tenzij de server een groot aantal instanties controleert. Doorgaans zijn systeemcontroles en gezondheidsanalyse lichtgewicht in termen van verwerking. Als u echter een groot aantal knooppunten moet controleren, is een grote CPU en geheugen een must, vooral wanneer de controles in de wachtrij moeten worden geplaatst terwijl het probeert te pingen en informatie van servers te verzamelen. De knooppunten die worden bewaakt en bewaakt, kunnen soms vastlopen als gevolg van netwerkproblemen, hoge belasting of, in het ergste geval, mogelijk niet beschikbaar zijn vanwege een hardwarefout of een VM-hostcorruptie. Dus de server die de status- en systeemcontroles uitvoert, zal dergelijke blokkades kunnen weerstaan, aangezien de kans groot is dat de verwerking van wachtrijen omhoog kan gaan, aangezien reacties op elk van de bewaakte knooppunten enige tijd kan duren totdat is geverifieerd dat het niet langer beschikbaar is of een time-out is opgetreden bereikt.
Voor cloudgebaseerde omgevingen zijn er services die automatische failover bieden. Amazon RDS gebruikt bijvoorbeeld DRBD om opslag te repliceren naar een stand-byknooppunt. Of als u uw volumes opslaat in EBS, worden deze in meerdere zones gerepliceerd.
Netwerk
Geautomatiseerde failover-software is vaak afhankelijk van agents die zijn ingesteld op de databaseknooppunten. De agent verzamelt informatie lokaal uit de database-instantie en stuurt deze naar de server wanneer daarom wordt gevraagd.
Zorg voor netwerkvereisten voor een goede bandbreedte en een stabiele netwerkverbinding. Er moeten regelmatig controles worden uitgevoerd en gemiste hartslagen vanwege een onstabiel netwerk kunnen ertoe leiden dat de failover-software (ten onrechte) concludeert dat een knooppunt niet werkt.
ClusterControl vereist geen installatie van een agent op de databaseknooppunten, omdat het met regelmatige tussenpozen SSH naar elk databaseknooppunt zal sturen en een aantal controles zal uitvoeren.
Geautomatiseerde failover met ClusterControl
ClusterControl biedt de mogelijkheid om zowel handmatige als geautomatiseerde failovers uit te voeren. Laten we eens kijken hoe dit kan.
Failover in ClusterControl kan worden geconfigureerd om automatisch te zijn of niet. Als u de failover liever handmatig afhandelt, kunt u geautomatiseerd clusterherstel uitschakelen. Wanneer u een handmatige failover uitvoert, kunt u naar Cluster → Topologie . gaan in ClusterControl. Zie de onderstaande schermafbeelding:
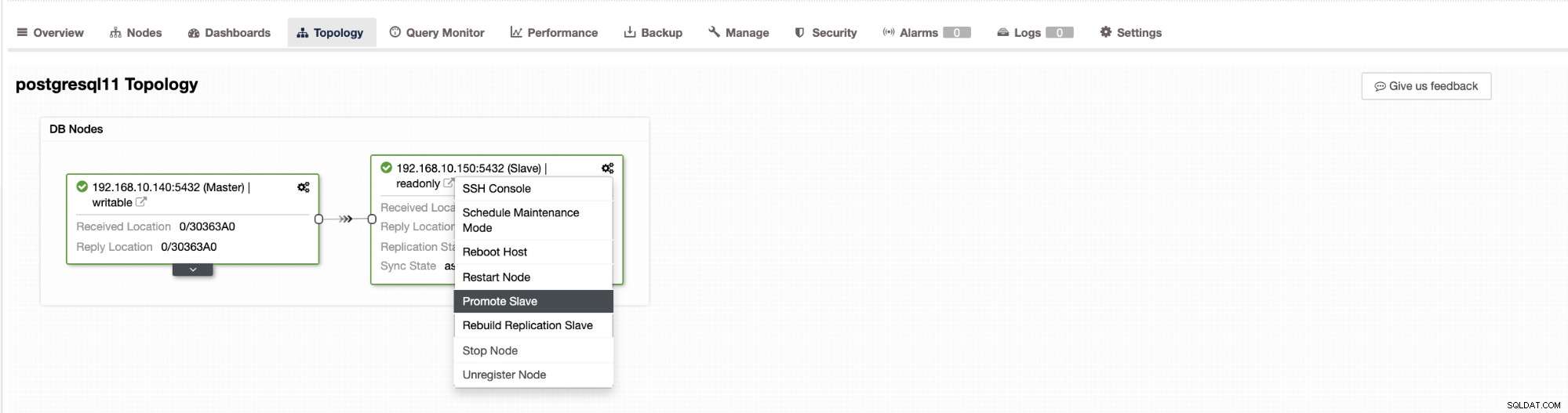
Standaard is clusterherstel ingeschakeld en wordt automatische failover gebruikt. Zodra u wijzigingen aanbrengt in de gebruikersinterface, wordt de runtimeconfiguratie gewijzigd. Als u wilt dat de instelling een herstart van de controller overleeft, zorg er dan voor dat u ook de wijziging in de cmon-configuratie aanbrengt, d.w.z. /etc/cmon.d/cmon_

In MySQL/MariaDB/Percona-server wordt automatische failover gestart door ClusterControl wanneer het detecteert dat er geen host is met read_only vlag uitgeschakeld. Het kan gebeuren omdat master (die read_only . heeft ingesteld op 0) is niet beschikbaar of kan worden geactiveerd door een gebruiker of externe software die deze vlag op de master heeft gewijzigd. Als u handmatige wijzigingen aanbrengt in de databaseknooppunten of als u software hebt die mogelijk knoeit met de read_only-instellingen, moet u automatische failover uitschakelen. De automatische failover van ClusterControl wordt slechts één keer geprobeerd, daarom zal een mislukte failover niet opnieuw worden gevolgd door een volgende failover - niet totdat cmon opnieuw is gestart.
Voor PostgreSQL kiest ClusterControl de meest geavanceerde slaaf, met behulp van hiervoor de pg_current_xlog_location (PostgreSQL 9+) of pg_current_wal_lsn (PostgreSQL 10+), afhankelijk van de versie van onze database. ClusterControl voert ook verschillende controles uit op het failoverproces om enkele veelvoorkomende fouten te voorkomen. Een voorbeeld is dat als we erin slagen om onze oude mislukte master te herstellen, dit "niet . zal zijn " automatisch opnieuw in het cluster worden geïntroduceerd, niet als master of als slave. We moeten dit handmatig doen. Dit voorkomt de mogelijkheid van gegevensverlies of inconsistentie in het geval dat onze slave (die we hebben gepromoot) op dat moment werd vertraagd We willen het probleem mogelijk ook in detail analyseren voordat we het opnieuw introduceren in de replicatie-instellingen, zodat we diagnostische informatie willen behouden.
Als de failover mislukt en er geen verdere pogingen worden ondernomen (dit geldt voor zowel PostgreSQL- als MySQL-gebaseerde clusters), is handmatige tussenkomst vereist om het probleem te analyseren en de bijbehorende acties uit te voeren. Dit is om te voorkomen dat ClusterControl, dat de automatische failover afhandelt, de volgende slave en de volgende probeert te promoten. Er kan een probleem zijn en we willen de zaken niet erger maken door meerdere failovers te proberen.
ClusterControl biedt whitelisting en blacklisting van een set servers die u wilt laten deelnemen aan de failover, of die u wilt uitsluiten als kandidaat.
Voor clusters van het MySQL-type maakt ClusterControl een lijst met slaves die tot master kunnen worden gepromoveerd. Meestal bevat het alle slaves in de topologie, maar de gebruiker heeft er wat extra controle over. Er zijn twee variabelen die u kunt instellen in de cmon-configuratie:
replication_failover_whitelisten
replication_failover_blacklistVoor de configuratievariabele replication_failover_whitelist bevat deze een lijst met IP's of hostnamen van slaves die als potentiële masterkandidaten moeten worden gebruikt. Als deze variabele is ingesteld, worden alleen die hosts in aanmerking genomen. Voor de variabele replication_failover_blacklist bevat deze een lijst met hosts die nooit als een masterkandidaat zullen worden beschouwd. U kunt het gebruiken om slaves weer te geven die worden gebruikt voor back-ups of analytische query's. Als de hardware verschilt tussen slaves, kun je hier de slaves plaatsen die langzamere hardware gebruiken.
replication_failover_whitelist heeft voorrang, wat betekent dat de replication_failover_blacklist wordt genegeerd als replication_failover_whitelist is ingesteld.
Zodra de lijst met slaves die gepromoveerd kunnen worden tot master gereed is, begint ClusterControl hun status te vergelijken, op zoek naar de meest up-to-date slave. Hier verschilt de afhandeling van op MariaDB en MySQL gebaseerde instellingen. Voor MariaDB-setups kiest ClusterControl een slave met de laagste replicatievertraging van alle beschikbare slaves. Voor MySQL-configuraties kiest ClusterControl ook zo'n slave, maar dan controleert het op aanvullende, ontbrekende transacties die op sommige van de resterende slaven hadden kunnen worden uitgevoerd. Als een dergelijke transactie wordt gevonden, verwijdert ClusterControl de masterkandidaat van die host om alle ontbrekende transacties op te halen. U kunt dit proces overslaan en gewoon de meest geavanceerde slave gebruiken door de variabele replication_skip_apply_missing_txs in uw CMON-configuratie in te stellen:
bijv.
replication_skip_apply_missing_txs=1Bekijk hier onze documentatie voor meer informatie met variabelen.
Voorbehoud is dat u dit alleen moet instellen als u weet wat u doet, omdat er mogelijk foutieve transacties zijn. Deze kunnen ertoe leiden dat de replicatie wordt verbroken, evenals inconsistenties in de gegevens in het cluster. Als de foutieve transactie in het verleden heeft plaatsgevonden, is deze mogelijk niet langer beschikbaar in binaire logboeken. In dat geval wordt de replicatie afgebroken omdat slaves de ontbrekende gegevens niet kunnen ophalen. Daarom controleert ClusterControl standaard op foutieve transacties voordat het een masterkandidaat promoveert tot master. Als een dergelijk probleem wordt gedetecteerd, wordt de hoofdschakelaar afgebroken en laat ClusterControl de gebruiker het probleem handmatig oplossen.
Als u er 100% zeker van wilt zijn dat ClusterControl een nieuwe master zal promoten, zelfs als er problemen worden gedetecteerd, kunt u dat doen met de variabele replication_stop_on_error. Zie hieronder:
bijv.
replication_stop_on_error=0Stel deze variabele in in uw cmon-configuratiebestand. Zoals eerder vermeld, kan dit leiden tot problemen met replicatie, aangezien slaves kunnen gaan vragen om een binaire loggebeurtenis die niet meer beschikbaar is. Om dergelijke gevallen aan te pakken, hebben we experimentele ondersteuning toegevoegd voor het herbouwen van slaven. Als u de variabele
. insteltreplication_auto_rebuild_slave=1in de cmon-configuratie en als uw slave is gemarkeerd als down met de volgende fout in MySQL:
Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.'ClusterControl zal proberen de slave opnieuw op te bouwen met behulp van gegevens van de master. Een dergelijke instelling is mogelijk niet altijd geschikt, aangezien het reconstructieproces de master zwaarder zal belasten. Het kan ook zijn dat uw dataset erg groot is en regelmatig opnieuw opbouwen geen optie is - daarom is dit gedrag standaard uitgeschakeld.
Zodra we ervoor hebben gezorgd dat er geen foutieve transactie bestaat en we klaar zijn om te gaan, is er nog een probleem dat we op de een of andere manier moeten oplossen - het kan gebeuren dat alle slaves achterblijven op de master.
Zoals u waarschijnlijk weet, werkt replicatie in MySQL op een vrij eenvoudige manier. De hoofdopslag schrijft in binaire logboeken. De I/O-thread van de slave maakt verbinding met de master en haalt eventuele binaire loggebeurtenissen op die ontbreken. Het slaat ze vervolgens op in de vorm van relaislogboeken. De SQL-thread ontleedt ze en past gebeurtenissen toe. Slave lag is een toestand waarin SQL-thread (of threads) het aantal gebeurtenissen niet aankunnen en ze niet kunnen toepassen zodra ze door de I/O-thread uit de master worden gehaald. Een dergelijke situatie kan zich voordoen, ongeacht het type replicatie dat u gebruikt. Zelfs als u semi-sync-replicatie gebruikt, kan dit alleen garanderen dat alle gebeurtenissen van de master worden opgeslagen op een van de slaves in het relaislogboek. Het zegt niets over het toepassen van die gebeurtenissen op een slaaf.
Het probleem hier is dat als een slaaf wordt gepromoveerd tot master, de relaislogboeken worden gewist. Als een slaaf achterblijft en niet alle transacties heeft toegepast, zullen gegevens verloren gaan - gebeurtenissen die nog niet zijn toegepast uit relaislogboeken, gaan voor altijd verloren.
Er is geen one-size-fits-all manier om deze situatie op te lossen. ClusterControl geeft gebruikers controle over hoe het moet worden gedaan, met behoud van veilige standaardinstellingen. Het wordt gedaan in cmon-configuratie met de volgende instelling:
replication_failover_wait_to_apply_timeout=-1Standaard heeft het een waarde van '-1', wat betekent dat failover niet onmiddellijk plaatsvindt als een masterkandidaat achterblijft, dus het is ingesteld om voor altijd te wachten tenzij de kandidaat de achterstand heeft ingehaald. ClusterControl wacht voor onbepaalde tijd totdat alle ontbrekende transacties uit de relay-logboeken zijn toegepast. Dit is veilig, maar als om de een of andere reden de meest up-to-date slave erg achterblijft, kan het uren duren voordat de failover is voltooid. Aan de andere kant van het spectrum stelt u het in op '0' - dit betekent dat failover onmiddellijk plaatsvindt, ongeacht of de masterkandidaat achterblijft of niet. Je kunt ook de middenweg nemen en deze op een bepaalde waarde instellen. Hiermee wordt een tijd in seconden ingesteld, bijvoorbeeld 30 seconden, dus stel de variabele in op,
replication_failover_wait_to_apply_timeout=30Indien ingesteld op> 0, wacht ClusterControl totdat een hoofdkandidaat ontbrekende transacties uit zijn relaislogboeken toepast totdat de waarde is bereikt (wat in het voorbeeld 30 seconden is). Failover vindt plaats na de gedefinieerde tijd of wanneer de hoofdkandidaat de replicatie inhaalt, afhankelijk van wat zich het eerst voordoet. Dit kan een goede keuze zijn als uw applicatie specifieke vereisten heeft met betrekking tot downtime en u binnen een kort tijdsbestek een nieuwe master moet kiezen.
Voor meer details over hoe ClusterControl werkt met automatische failover in PostgreSQL en MySQL, bekijk onze eerdere blogs getiteld "Failover for PostgreSQL Replication 101" en "Automatic failover of MySQL Replication - New in ClusterControl 1.4".
Conclusie
Geautomatiseerde failover is een waardevolle functie, vooral voor bedrijven die 24/7 operaties met minimale uitvaltijd nodig hebben. Het bedrijf moet bepalen hoeveel controle wordt gegeven aan het automatiseringsproces tijdens ongeplande uitval. Een oplossing met hoge beschikbaarheid zoals ClusterControl biedt een aanpasbaar interactieniveau bij failover-verwerking. Voor sommige organisaties is geautomatiseerde failover misschien geen optie, ook al kan de gebruikersinteractie tijdens de failover tijd kosten en de RTO beïnvloeden. De veronderstelling is dat het te riskant is in het geval dat geautomatiseerde failover niet correct werkt of, erger nog, resulteert in gegevens die in de war raken en gedeeltelijk ontbreken (hoewel je zou kunnen beweren dat een mens ook rampzalige fouten kan maken die tot vergelijkbare gevolgen leiden). Degenen die liever de controle over hun database behouden, kunnen ervoor kiezen om geautomatiseerde failover over te slaan en in plaats daarvan een handmatig proces te gebruiken. Een dergelijk proces kost meer tijd, maar het stelt een ervaren beheerder in staat om de toestand van een systeem te beoordelen en corrigerende maatregelen te nemen op basis van wat er is gebeurd.