Waarom kiezen voor MySQL-replicatie?
Eerst enkele basisprincipes over de replicatietechnologie. MySQL-replicatie is niet ingewikkeld! Het is gemakkelijk te implementeren, te controleren en af te stemmen, aangezien er verschillende bronnen zijn die u kunt gebruiken, waaronder Google. MySQL-replicatie bevat niet veel configuratievariabelen om af te stemmen. De logische fouten van SQL_THREAD en IO_THREAD zijn niet zo moeilijk te begrijpen en op te lossen. MySQL-replicatie is tegenwoordig erg populair en biedt een eenvoudige manier om database High Availability te implementeren. Krachtige functies zoals GTID (Global Transaction Identifier) in plaats van de ouderwetse binaire logpositie, of lossless Semi-Synchronous Replication maken het robuuster.
Zoals we in een eerdere post zagen, is netwerklatentie een grote uitdaging bij het selecteren van een oplossing met hoge beschikbaarheid. Het gebruik van MySQL-replicatie biedt het voordeel dat het niet zo gevoelig is voor latentie. Het implementeert geen op certificeringen gebaseerde replicatie, in tegenstelling tot Galera Cluster die groepscommunicatie en transactiebestellingstechnieken gebruikt om synchrone replicatie te bereiken. Het is dus niet vereist dat alle nodes een schrijfset moeten certificeren, en het is niet nodig om te wachten voor een commit op de andere slave of replica.
Kiezen voor de traditionele MySQL-replicatie met asynchrone Primair-Secundaire benadering biedt u snelheid als het gaat om het afhandelen van transacties vanuit uw master; het hoeft niet te wachten tot de slaven synchroniseren of transacties vastleggen. De opstelling heeft doorgaans een primaire (master) en een of meer secundaire (slaves). Het is dus een gedeeld-niets-systeem, waarbij alle servers standaard een volledige kopie van de gegevens hebben. Natuurlijk zijn er nadelen. Gegevensintegriteit kan een probleem zijn als uw slaven niet kunnen repliceren vanwege SQL- en I/O-threadfouten of crashes. Om problemen met gegevensintegriteit aan te pakken, kunt u er ook voor kiezen om MySQL-replicatie semi-synchroon te implementeren (of verliesvrije semi-sync-replicatie genoemd in MySQL 5.7). Hoe dit werkt, is dat de master moet wachten tot een replica alle gebeurtenissen van de transactie bevestigt. Dit betekent dat het zijn schrijfbewerkingen naar een relaislogboek moet voltooien en naar schijf moet doorspoelen voordat het terugstuurt naar de master met een ACK-antwoord. Als semi-synchrone replicatie is ingeschakeld, moeten threads of sessies in de master wachten op bevestiging van een replica. Zodra het een ACK-antwoord van de replica ontvangt, kan het de transactie doorvoeren. De onderstaande afbeelding laat zien hoe MySQL omgaat met semi-synchrone replicatie.
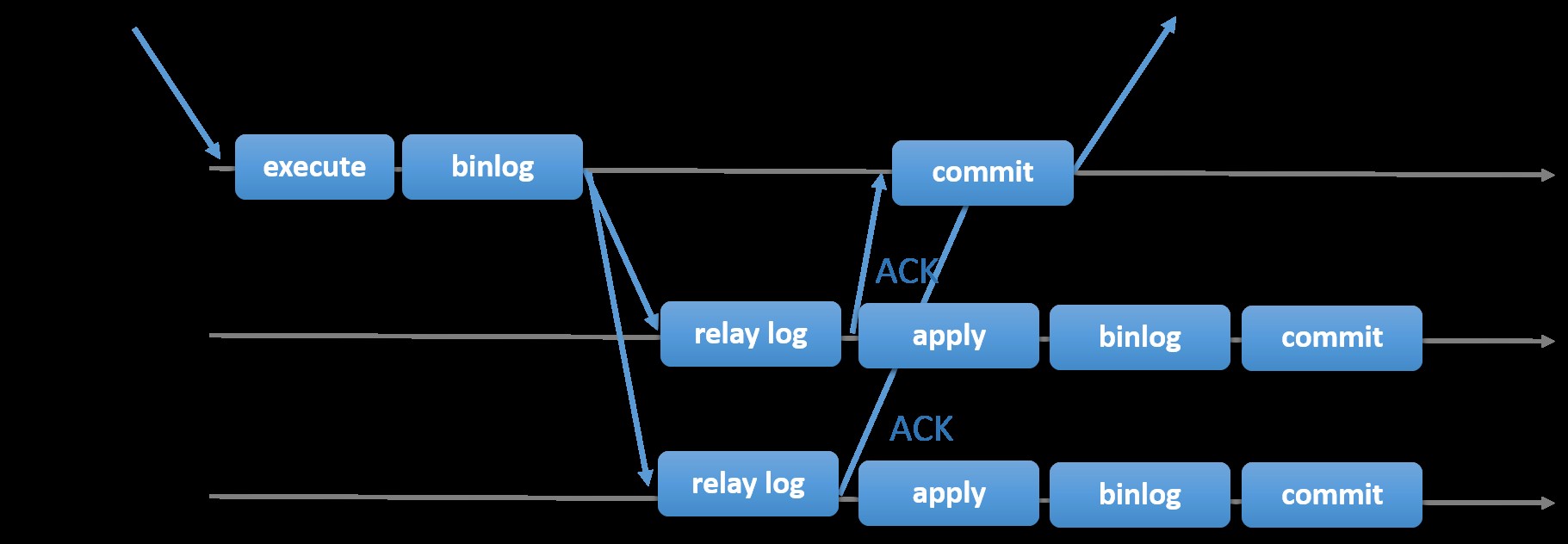 Afbeelding met dank aan MySQL-documentatie
Afbeelding met dank aan MySQL-documentatie Met deze implementatie worden alle vastgelegde transacties al gerepliceerd naar ten minste één slave in het geval van een mastercrash. Hoewel semi-synchroon op zichzelf geen high-availability-oplossing is, is het een onderdeel van uw oplossing. Het is het beste dat u uw behoeften kent en uw semi-sync-implementatie dienovereenkomstig afstemt. Dus als enig gegevensverlies acceptabel is, kunt u in plaats daarvan de traditionele asynchrone replicatie gebruiken.
Op GTID gebaseerde replicatie is nuttig voor de DBA omdat het de taak om een failover uit te voeren vereenvoudigt, vooral wanneer een slave naar een andere master of nieuwe master wordt verwezen. Dit betekent dat met een eenvoudige MASTER_AUTO_POSITION=1 na het instellen van de juiste host- en replicatiereferenties, het begint te repliceren vanaf de master zonder de noodzaak om de juiste binaire log x &y-posities te vinden en te specificeren. Door ondersteuning van parallelle replicatie toe te voegen, worden ook de replicatiethreads gestimuleerd omdat het de snelheid verhoogt om de gebeurtenissen uit het relaislogboek te verwerken.
MySQL-replicatie is dus een uitstekende keuzecomponent boven andere HA-oplossingen als het aan uw behoeften voldoet.
Topologieën voor MySQL-replicatie
MySQL-replicatie implementeren in een multicloud-omgeving met GCP (Google Cloud Platform) en AWS is nog steeds dezelfde aanpak als u on-premises moet repliceren.
Er zijn verschillende topologieën die u kunt instellen en implementeren.
Master met slave-replicatie (enkele replicatie)
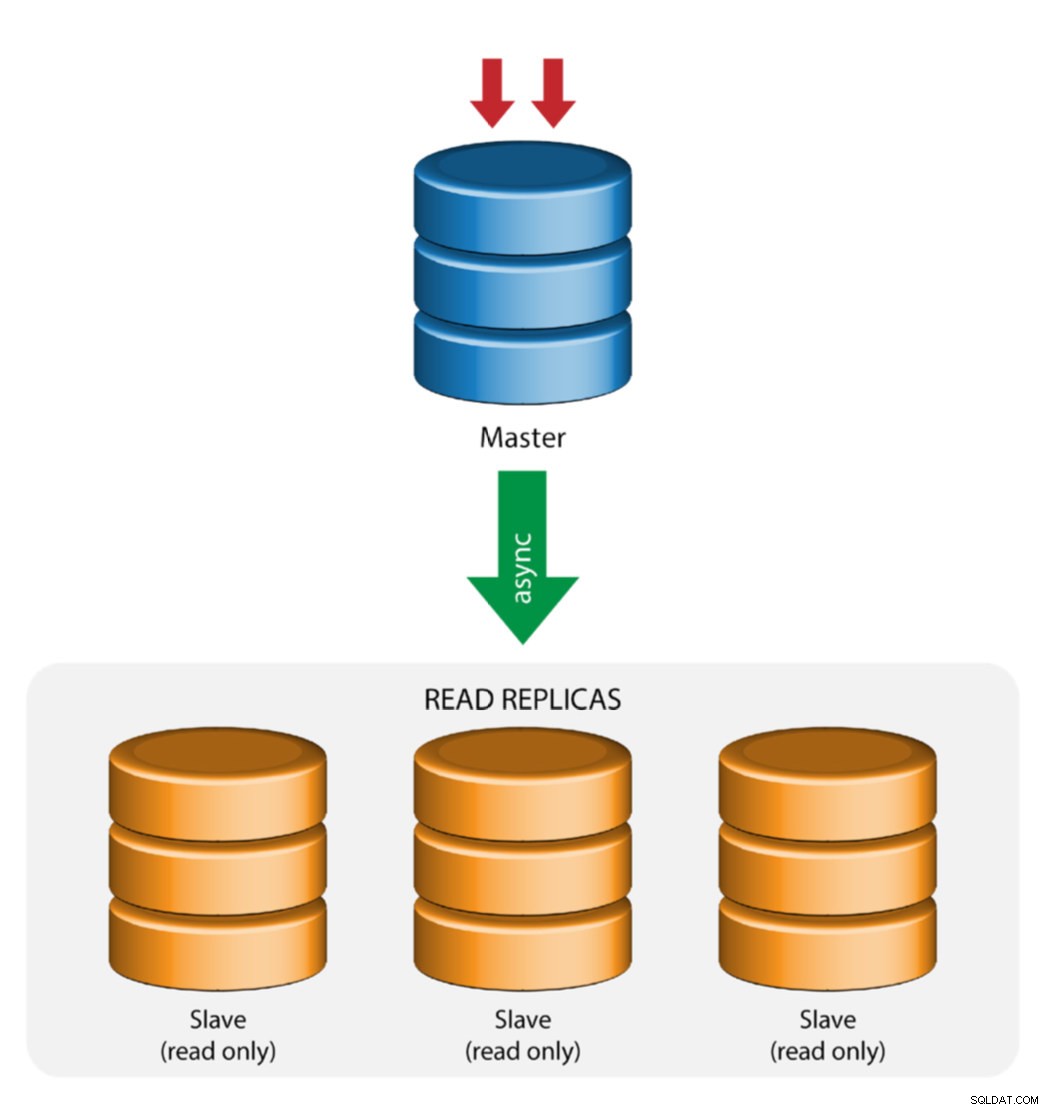
Dit is de meest eenvoudige MySQL-replicatietopologie. Eén master ontvangt schrijfbewerkingen, een of meer slaves repliceren van dezelfde master via asynchrone of semi-synchrone replicatie. Als de aangewezen master uitvalt, moet de meest actuele slave worden gepromoveerd tot nieuwe master. De overige slaves hervatten de replicatie vanaf de nieuwe master.
Master met relaisslaves (ketenreplicatie)
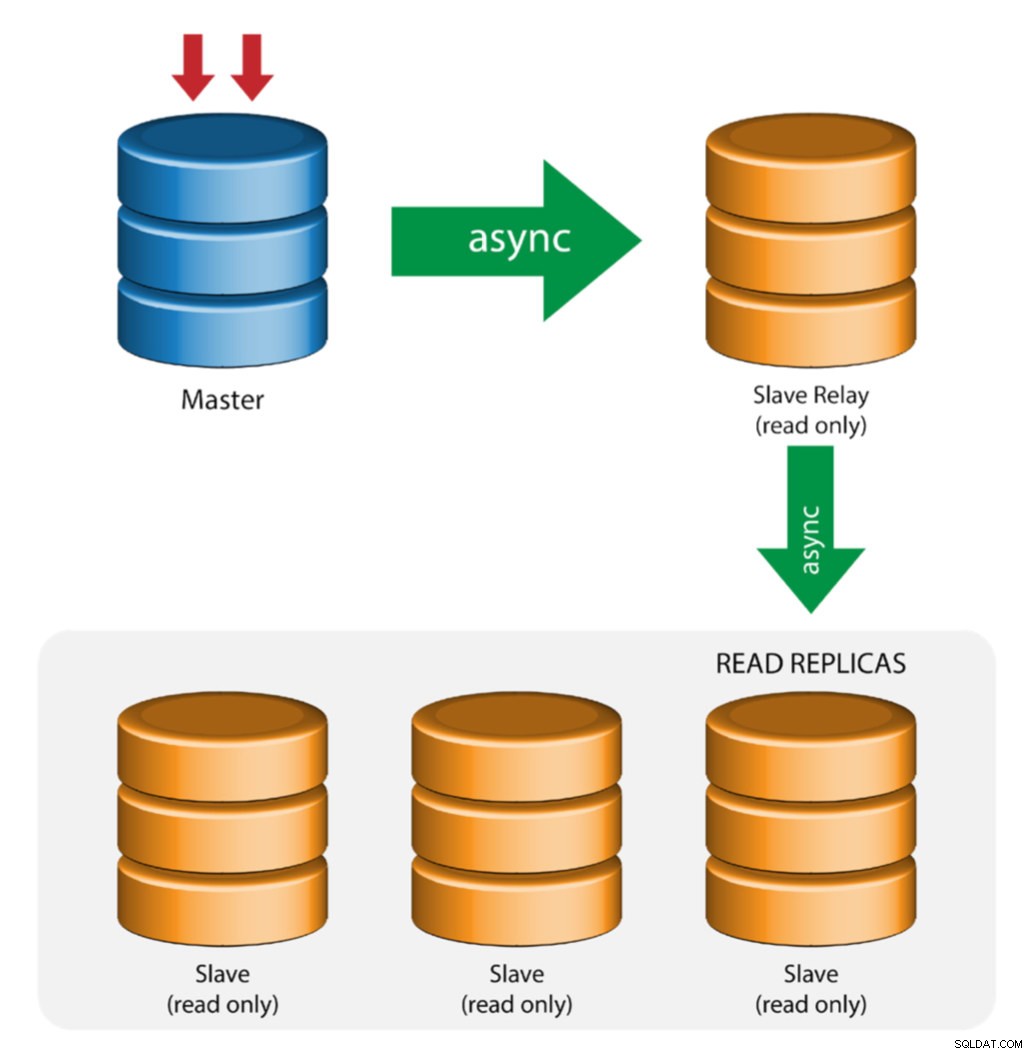
Deze opstelling gebruikt een tussenliggende master om als relais naar de andere slaven in de replicatieketen te fungeren. Wanneer er veel slaves op een master zijn aangesloten, kan de netwerkinterface van de master overbelast raken. Met deze topologie kunnen de leesreplica's de replicatiestroom van de relayserver halen om de masterserver te ontlasten. Op de slave-relayserver moeten binaire logboekregistratie en log_slave_updates zijn ingeschakeld, waarbij updates die door de slave-server van de masterserver worden ontvangen, worden vastgelegd in het eigen binaire logboek van de slave.
Het gebruik van slave-relais heeft zijn problemen:
- log_slave_updates heeft een prestatiefout.
- Replicatievertraging op de slave-relayserver veroorzaakt vertraging op al zijn slaven.
- Rogue-transacties op de slave-relayserver zullen alle slaven infecteren.
- Als een slave-relayserver faalt en u geen GTID gebruikt, stoppen alle slaves met repliceren en moeten ze opnieuw worden geïnitialiseerd.
Master met actieve master (circulaire replicatie)
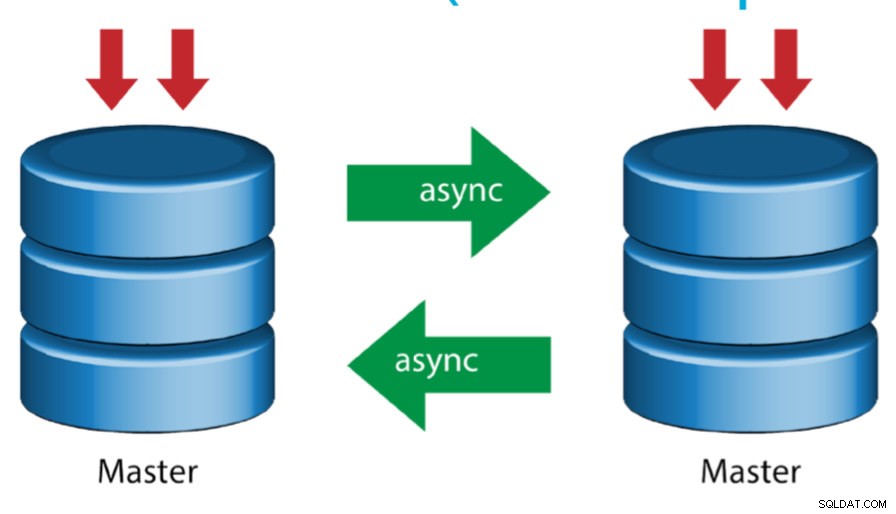
Deze opstelling, ook wel ringtopologie genoemd, vereist twee of meer MySQL-servers die als master fungeren. Alle masters ontvangen schrijfbewerkingen en genereren binlogs met een paar kanttekeningen:
- Je moet op elke server een offset voor automatisch verhogen instellen om botsingen met primaire sleutels te voorkomen.
- Er is geen conflictoplossing.
- MySQL-replicatie ondersteunt momenteel geen vergrendelingsprotocol tussen master en slave om de atomiciteit van een gedistribueerde update over twee verschillende servers te garanderen.
- Algemeen gebruik is om alleen naar één master te schrijven en de andere master fungeert als een hot-standby-knooppunt. Maar als je slaves onder dat niveau hebt, moet je handmatig naar de nieuwe master overschakelen als de aangewezen master faalt.
- ClusterControl ondersteunt deze topologie (we raden niet aan om meerdere schrijvers in een replicatieconfiguratie te gebruiken). Zie deze vorige blog over hoe te implementeren met ClusterControl.
Master met back-upmaster (meerdere replicatie)
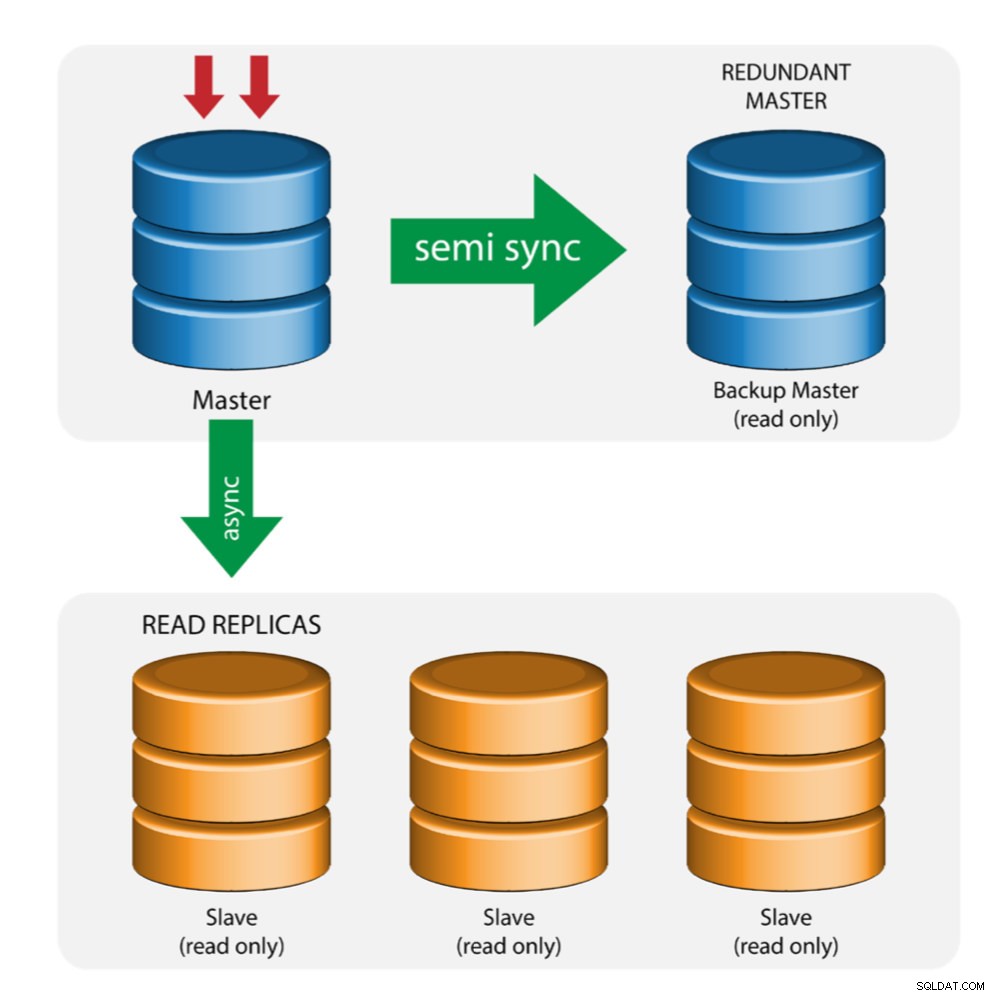
De master pusht wijzigingen naar een back-upmaster en naar een of meer slaven. Semi-synchrone replicatie wordt gebruikt tussen master en back-upmaster. Master stuurt de update naar de back-upmaster en wacht met het vastleggen van de transactie. Back-upmaster krijgt updates, schrijft naar zijn relaislogboek en spoelt naar schijf. De back-upmaster bevestigt vervolgens de ontvangst van de transactie aan de master en gaat verder met het vastleggen van de transactie. Semi-sync-replicatie heeft een impact op de prestaties, maar het risico op gegevensverlies wordt geminimaliseerd.
Deze topologie werkt goed bij het uitvoeren van een masterfailover voor het geval de master uitvalt. De back-upmaster fungeert als een warme standby-server, omdat deze de grootste kans heeft om over actuele gegevens te beschikken in vergelijking met andere slaves.
Meerdere masters naar enkele slave (multi-source replicatie)
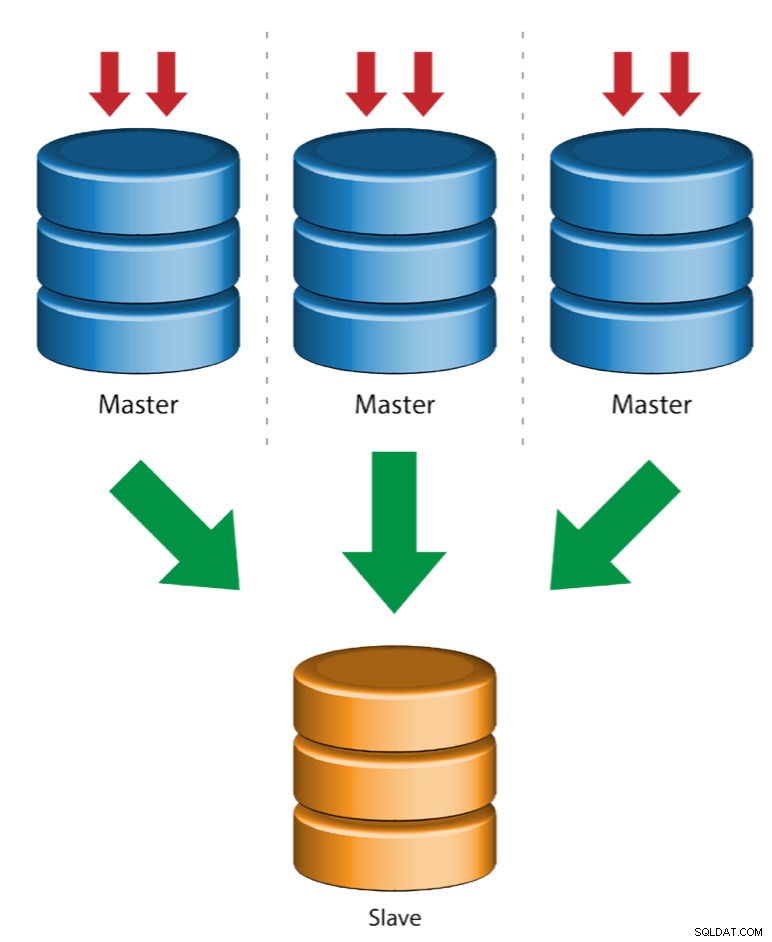
Multi-Source Replication stelt een replicatieslave in staat om gelijktijdig transacties van meerdere bronnen te ontvangen. Multi-source replicatie kan worden gebruikt om een back-up te maken van meerdere servers naar een enkele server, om table shards samen te voegen en om gegevens van meerdere servers te consolideren naar een enkele server.
MySQL en MariaDB hebben verschillende implementaties van multi-source replicatie, waarbij MariaDB GTID met gtid-domain-id moet hebben geconfigureerd om de oorspronkelijke transacties te onderscheiden, terwijl MySQL een afzonderlijk replicatiekanaal gebruikt voor elke master waarvan de slave repliceert. In MySQL kunnen masters in een multi-source replicatietopologie worden geconfigureerd om ofwel global transaction identifier (GTID)-gebaseerde replicatie of binaire log-positie-gebaseerde replicatie te gebruiken.
Meer over MariaDB-replicatie met meerdere bronnen is te vinden in deze blogpost. Raadpleeg de MySQL-documentatie voor MySQL.
Galera met replicatieslave (hybride replicatie)
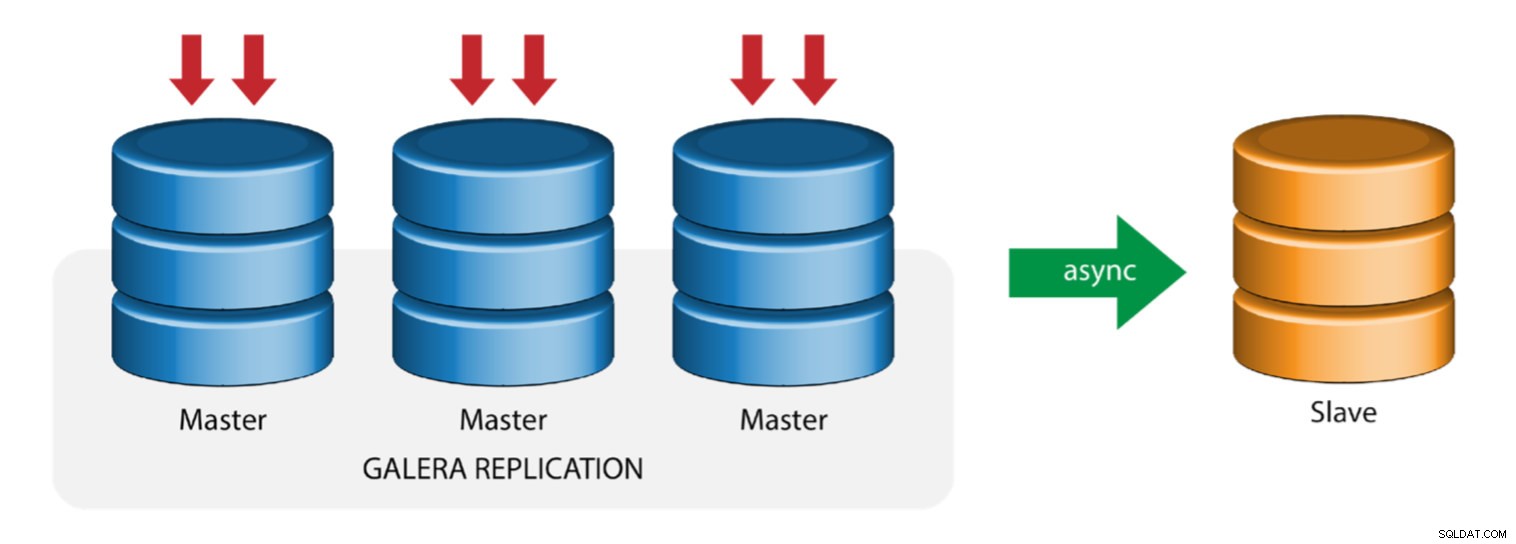
Hybride replicatie is een combinatie van MySQL asynchrone replicatie en vrijwel synchrone replicatie die door Galera wordt geleverd. De implementatie is nu vereenvoudigd met de implementatie van GTID in MySQL-replicatie, waarbij het opzetten en uitvoeren van masterfailover een eenvoudig proces is geworden aan de slave-kant.
Galera-clusterprestaties zijn zo snel als de langzaamste node. Het hebben van een asynchrone replicatieslave kan de impact op het cluster minimaliseren als u langlopende rapportage-/OLAP-query's naar de slaaf verzendt, of als u zware taken uitvoert waarvoor vergrendelingen zoals mysqldump nodig zijn. De slave kan ook dienen als een live back-up voor onsite en offsite noodherstel.
Hybride replicatie wordt ondersteund door ClusterControl en u kunt het rechtstreeks implementeren vanuit de ClusterControl-gebruikersinterface. Lees de blogposts - Hybride replicatie met MySQL 5.6 en Hybride replicatie met MariaDB 10.x voor meer informatie over hoe u dit kunt doen.
GCP- en AWS-platforms voorbereiden
Het "echte" probleem
In deze blog zullen we de "Multiple Replication"-topologie demonstreren en gebruiken waarin instanties op twee verschillende openbare cloudplatforms zullen communiceren met MySQL-replicatie op verschillende regio's en op verschillende beschikbaarheidszones. Dit scenario is gebaseerd op een reëel probleem waarbij een organisatie haar infrastructuur wil ontwerpen op meerdere cloudplatforms voor schaalbaarheid, redundantie, veerkracht/fouttolerantie. Soortgelijke concepten zouden van toepassing zijn op MongoDB of PostgreSQL.
Laten we eens kijken naar een Amerikaanse organisatie, met een overzeese vestiging in Zuidoost-Azië. Ons verkeer is hoog in de Aziatische regio. De latentie moet laag zijn bij het schrijven en lezen, maar tegelijkertijd kan de in de VS gevestigde regio ook records ophalen die afkomstig zijn van het Aziatische verkeer.
De cloudarchitectuurstroom
In deze sectie zal ik het architectonisch ontwerp bespreken. Ten eerste willen we een zeer veilige laag bieden waarvoor onze Google Compute- en AWS EC2-nodes kunnen communiceren, pakketten kunnen updaten of installeren vanaf internet, veilig, zeer beschikbaar in het geval dat een AZ (Availability Zone) uitvalt, kunnen repliceren en communiceren met een ander cloudplatform via een beveiligde laag. Zie de afbeelding hieronder ter illustratie:

Op basis van bovenstaande afbeelding draaien onder het AWS-platform alle nodes in verschillende beschikbaarheidszones. Het heeft een privé en openbaar subnet waarvoor alle rekenknooppunten zich op een privésubnet bevinden. Daarom kan het buiten het internet gaan om zijn systeempakketten op te halen en indien nodig bij te werken. Het heeft een VPN-gateway waarvoor het moet communiceren met GCP in dat kanaal, waarbij het internet wordt omzeild, maar via een veilig en privékanaal. Hetzelfde als GCP, alle rekenknooppunten bevinden zich in verschillende beschikbaarheidszones, gebruiken NAT Gateway om systeempakketten bij te werken wanneer dat nodig is en gebruiken een VPN-verbinding om te communiceren met de AWS-knooppunten die worden gehost in een andere regio, d.w.z. Azië-Pacific (Singapore). Aan de andere kant wordt de in de VS gevestigde regio gehost onder us-east1. Om toegang te krijgen tot de knooppunten, dient één knooppunt in de architectuur als het bastion-knooppunt waarvoor we het als de jump-host zullen gebruiken en ClusterControl zullen installeren. Dit wordt later in deze blog behandeld.
GCP- en AWS-omgevingen instellen
Wanneer u uw eerste GCP-account registreert, biedt Google een standaard VPC-account (Virtual Private Cloud). Daarom is het het beste om een aparte VPC te maken dan de standaard en deze aan uw behoeften aan te passen.
Ons doel hier is om de rekenknooppunten in privésubnetten te plaatsen, anders worden knooppunten niet ingesteld met openbare IPv4. Beide public clouds moeten dus met elkaar kunnen praten. De AWS- en GCP-rekenknooppunten werken met verschillende CIDR's, zoals eerder vermeld. Daarom zijn hier de volgende CIDR:
AWS-rekenknooppunten: 172.21.0.0/16
GCP-rekenknooppunten: 10.142.0.0/20
In deze AWS-configuratie hebben we drie subnetten toegewezen die geen internetgateway maar NAT-gateway hebben; en één subnet met een internetgateway. Elk van deze subnetten wordt afzonderlijk gehost in verschillende Beschikbaarheidszones (AZ).
ap-southeast-1a =172.21.1.0/24
ap-southeast-1b =172.21.8.0/24
ap-southeast-1c =172.21.24.0/24
In GCP wordt het standaardsubnet gebruikt dat is gemaakt in een VPC onder us-east1, namelijk 10.142.0.0/20 CIDR. Dit zijn dus de stappen die u kunt volgen om uw multi-public cloudplatform in te stellen.
-
Voor deze oefening heb ik een VPC gemaakt in de us-east1-regio met het volgende subnet van 10.142.0.0/20. Zie hieronder:

-
Reserveer een statisch IP-adres. Dit is het IP-adres dat we gaan instellen als klantgateway in AWS
-
Aangezien we subnetten hebben (ingericht als subnet-us-east1 ), ga naar GCP -> VPC-netwerk -> VPC-netwerken en selecteer de VPC die je hebt gemaakt en ga naar de Firewall-regels . Voeg in deze sectie de regels toe door uw inkomend en uitgaand verkeer op te geven. Kort gezegd zijn dit de inkomende/uitgaande regels in AWS of uw firewall voor inkomende en uitgaande verbindingen. In deze opstelling heb ik alle TCP-protocollen uit het CIDR-bereik geopend dat is ingesteld in mijn AWS en GCP VPC om het voor deze blog eenvoudiger te maken. Daarom is dit niet de optimale manier voor beveiliging. Zie onderstaande afbeelding:
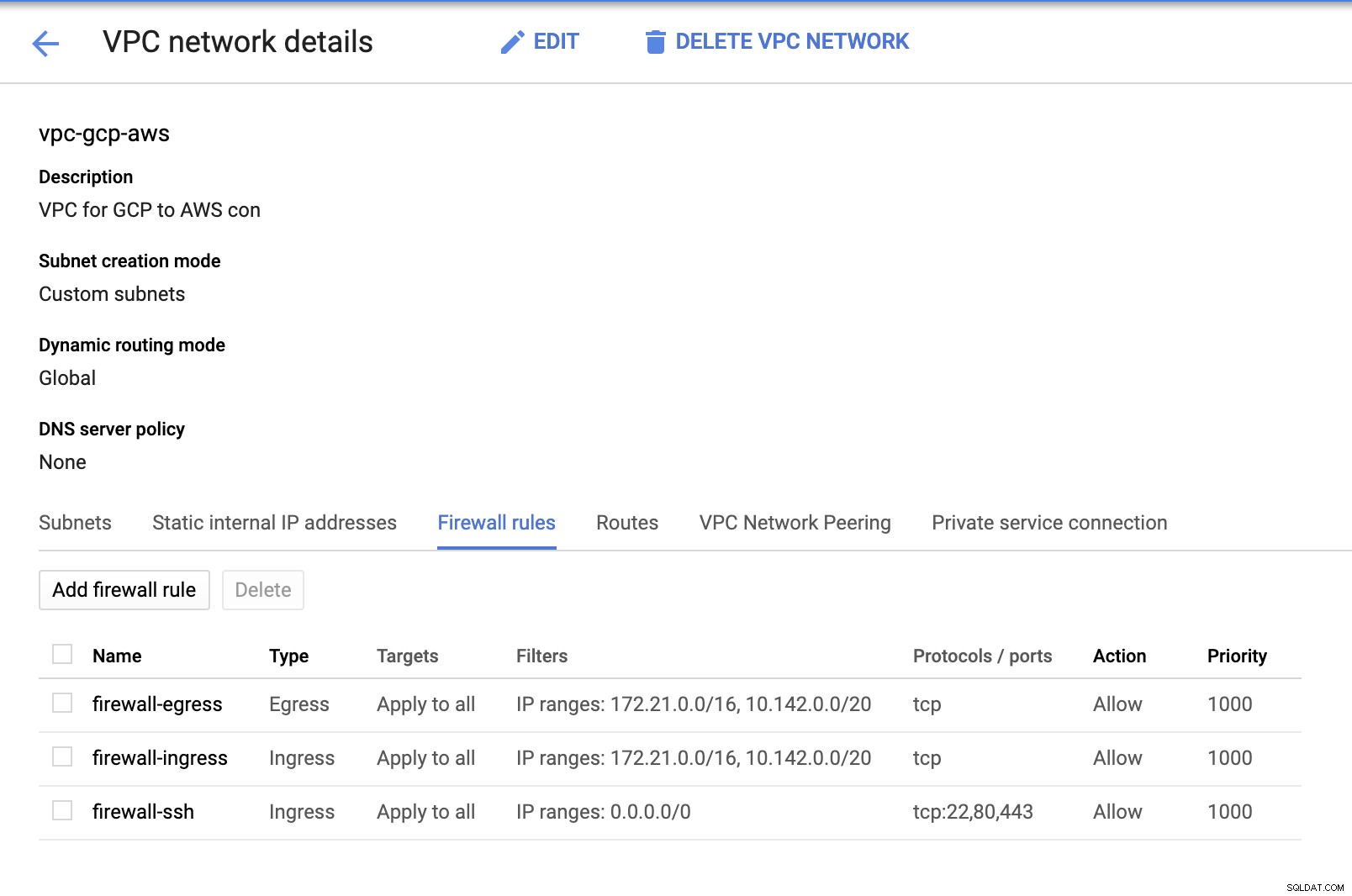
De firewall-ssh hier zal worden gebruikt om ssh, HTTP en HTTPS inkomende verbindingen toe te staan.
-
Schakel nu over naar AWS en maak een VPC aan. Voor deze blog gebruikte ik CIDR (Classless Inter-Domain Routing) 172.21.0.0/16
-
Creëer de subnetten waarvoor u ze moet toewijzen in elke AZ (Availability Zone); en reserveer ten minste één subnet voor een openbaar subnet dat de NAT-gateway zal afhandelen, en de rest is voor EC2-knooppunten.

-
Maak vervolgens uw Routetabel en zorg ervoor dat de "Bestemming" en "Targets" correct zijn ingesteld. Voor deze blog heb ik 2 routetabellen gemaakt. Een die de 3 AZ afhandelt die mijn rekenknooppunten afzonderlijk zullen krijgen en die zonder internetgateway zullen worden toegewezen omdat deze geen openbaar IP-adres hebben. Dan zal de andere de NAT-gateway afhandelen en een internetgateway hebben die zich in het openbare subnet bevindt. Zie onderstaande afbeelding:

en zoals vermeld, laat mijn voorbeeldbestemming voor een privéroute die 3 subnetten afhandelt zien dat ik een NAT Gateway-doel heb plus een Virtual Gateway-doel dat ik later in de inkomende stappen zal noemen.

-
Maak vervolgens een "Internet Gateway" en wijs deze toe aan de VPC die eerder is gemaakt in het gedeelte AWS VPC. Deze internetgateway mag alleen worden ingesteld als bestemming voor het openbare subnet, omdat dit de service is die verbinding met internet moet maken. Het is duidelijk dat de naam staat voor een internet gateway-service.
-
Maak vervolgens een "NAT-gateway" aan. Zorg er bij het maken van een "NAT-gateway" voor dat u uw NAT hebt toegewezen aan een openbaar subnet. De NAT-gateway is uw kanaal om toegang te krijgen tot internet vanaf uw privésubnet of EC2-knooppunten waaraan geen openbare IPv4 is toegewezen. Maak of wijs vervolgens een EIP (Elastic IP) toe, aangezien in AWS alleen rekenknooppunten waaraan openbare IPv4 is toegewezen rechtstreeks verbinding kunnen maken met internet.
-
Nu, onder VPC -> Beveiliging -> Beveiligingsgroepen (SG) , heeft uw gemaakte VPC een standaard SG. Voor deze opstelling heb ik "Inkomende regels" gemaakt met bronnen die zijn toegewezen voor elke CIDR, d.w.z. 10.142.0.0/20 in GCP en 172.21.0.0/16 in AWS. Zie hieronder:

Voor "Uitgaande regels" kunt u dat laten zoals het is, aangezien het toewijzen van regels aan "Inkomende regels" bilateraal is, wat betekent dat het ook wordt geopend voor "Uitgaande regels". Houd er rekening mee dat dit niet de optimale manier is om uw beveiligingsgroep in te stellen; maar om het gemakkelijker te maken voor deze opstelling, heb ik ook een breder bereik van poortbereik en bron gemaakt. Ook dat het protocol specifiek is voor TCP-verbindingen, aangezien we voor deze blog niet met UDP te maken hebben.
Bovendien kunt u uw VPC -> Beveiliging -> Netwerk-ACL's onaangeroerd zolang het geen tcp-verbindingen van de CIDR die in uw bron wordt vermeld, WIJIGT. -
Vervolgens stellen we de VPN-configuratie in die wordt gehost onder het AWS-platform. Onder de VPC -> Klantgateways , maakt u de gateway met behulp van het statische IP-adres dat eerder in de vorige stap is gemaakt. Bekijk de afbeelding hieronder:
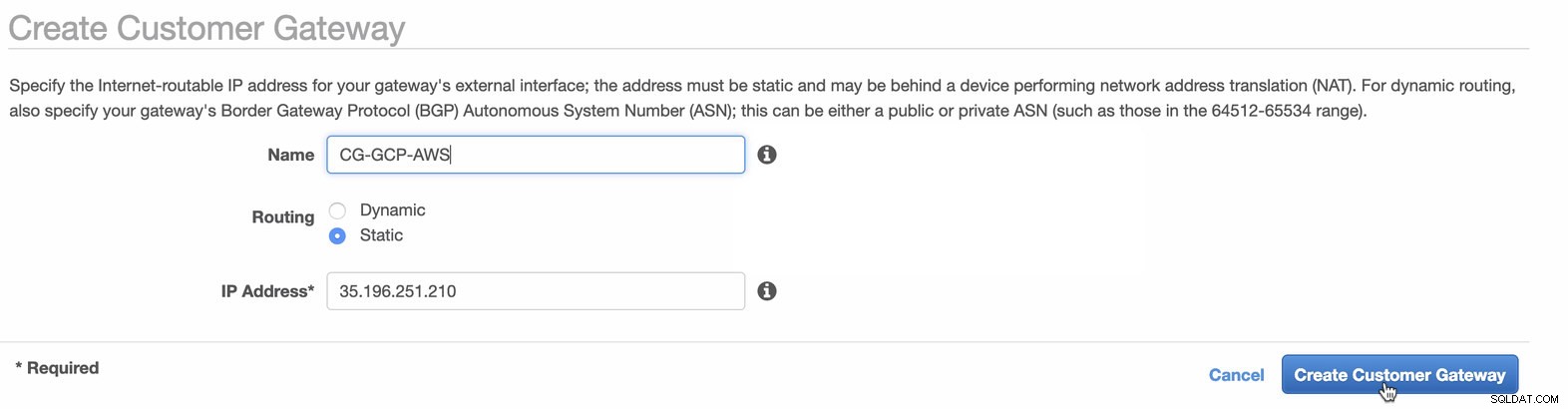
-
Maak vervolgens een Virtual Private Gateway en koppel deze aan de huidige VPC die we eerder in de vorige stap hebben gemaakt. Zie onderstaande afbeelding:

-
Maak nu een VPN-verbinding die wordt gebruikt voor de site-naar-site-verbinding tussen AWS en GCP. Zorg er bij het maken van een VPN-verbinding voor dat je de juiste Virtual Private Gateway en de Customer Gateway hebt geselecteerd die we in de vorige stappen hebben gemaakt. Zie onderstaande afbeelding:
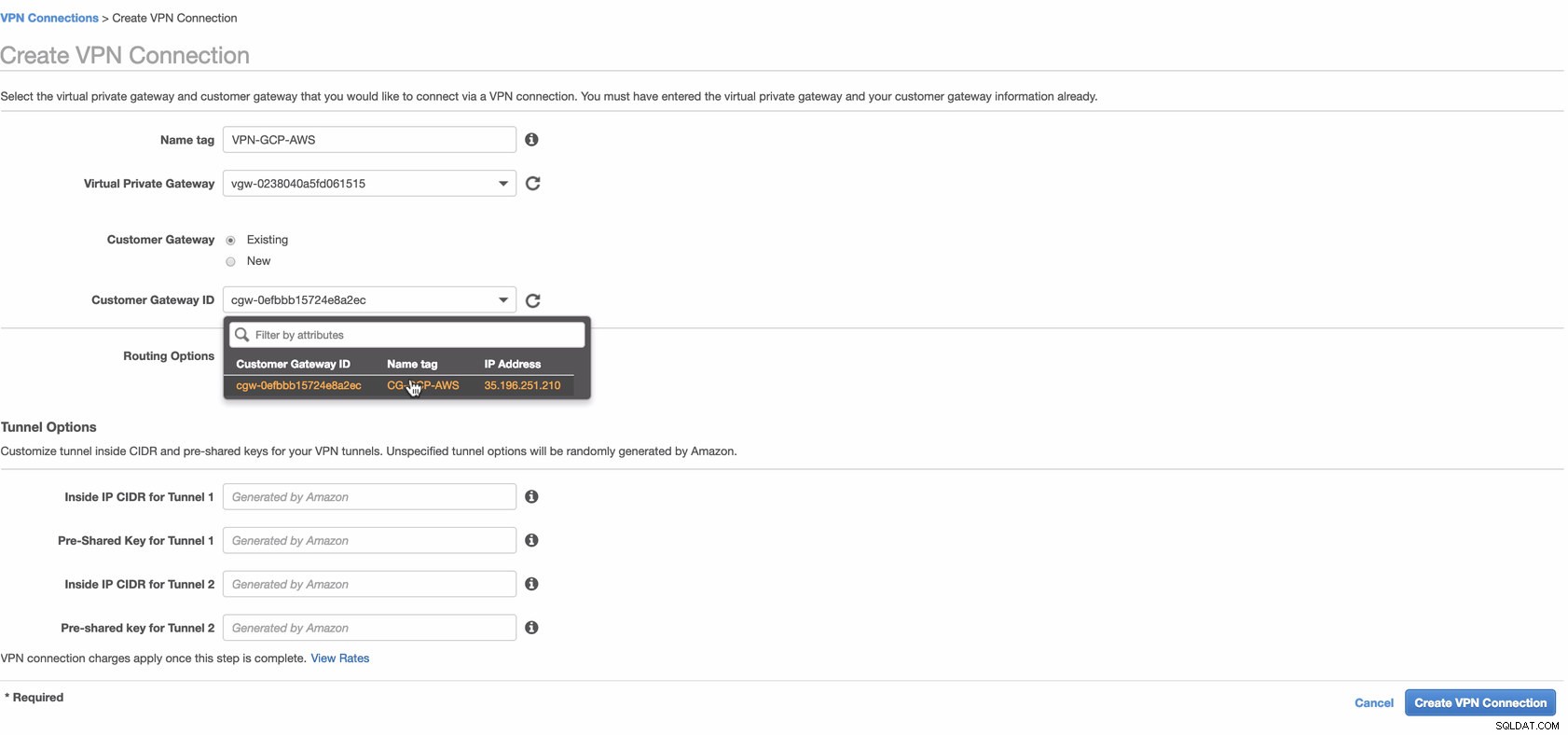
Dit kan even duren terwijl AWS uw VPN-verbinding tot stand brengt. Wanneer uw VPN-verbinding vervolgens is ingericht, vraagt u zich misschien af waarom op het tabblad Tunnel (nadat u uw VPN-verbinding hebt geselecteerd), wordt weergegeven dat het Extern IP-adres is uit de lucht. Dit is normaal omdat er nog geen verbinding tot stand is gebracht met de client. Bekijk de voorbeeldafbeelding hieronder:

Zodra de VPN-verbinding gereed is, selecteert u uw gemaakte VPN-verbinding en downloadt u de configuratie. Het bevat uw inloggegevens die nodig zijn voor de volgende stappen om een site-naar-site VPN-verbinding met de client tot stand te brengen.
Opmerking: Als je je VPN hebt ingesteld waar IPSEC IS UP maar Status is OMLAAG net als de afbeelding hieronder

dit is waarschijnlijk te wijten aan verkeerde waarden die zijn ingesteld voor de specifieke parameters tijdens het instellen van uw BGP-sessie of cloudrouter. Bekijk het hier voor het oplossen van problemen met uw VPN.
-
Aangezien we een VPN-verbinding klaar hebben staan die wordt gehost in AWS, laten we een VPN-verbinding maken in GCP. Laten we nu teruggaan naar GCP en daar de clientverbinding instellen. Ga in GCP naar GCP -> Hybride connectiviteit -> VPN . Zorg ervoor dat je de juiste regio kiest, die op deze blog staat, we gebruiken us-east1 . Selecteer vervolgens het statische IP-adres dat in de vorige stappen is aangemaakt. Zie onderstaande afbeelding:
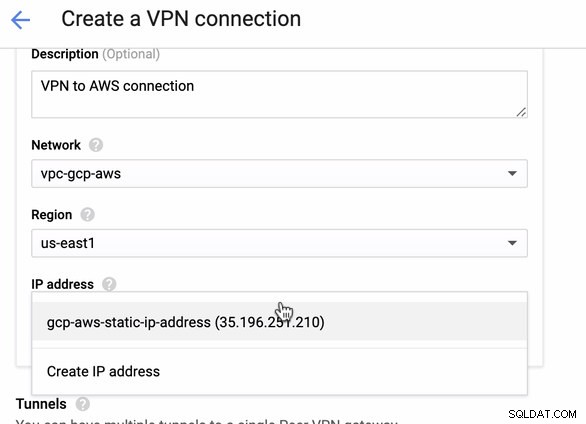
Dan in de Tunnels sectie, dit is waar je moet instellen op basis van de gedownloade inloggegevens van de AWS VPN-verbinding die je eerder hebt gemaakt. Ik raad aan om deze handige gids van Google te bekijken. Een van de tunnels die wordt opgezet, wordt bijvoorbeeld weergegeven in de onderstaande afbeelding:
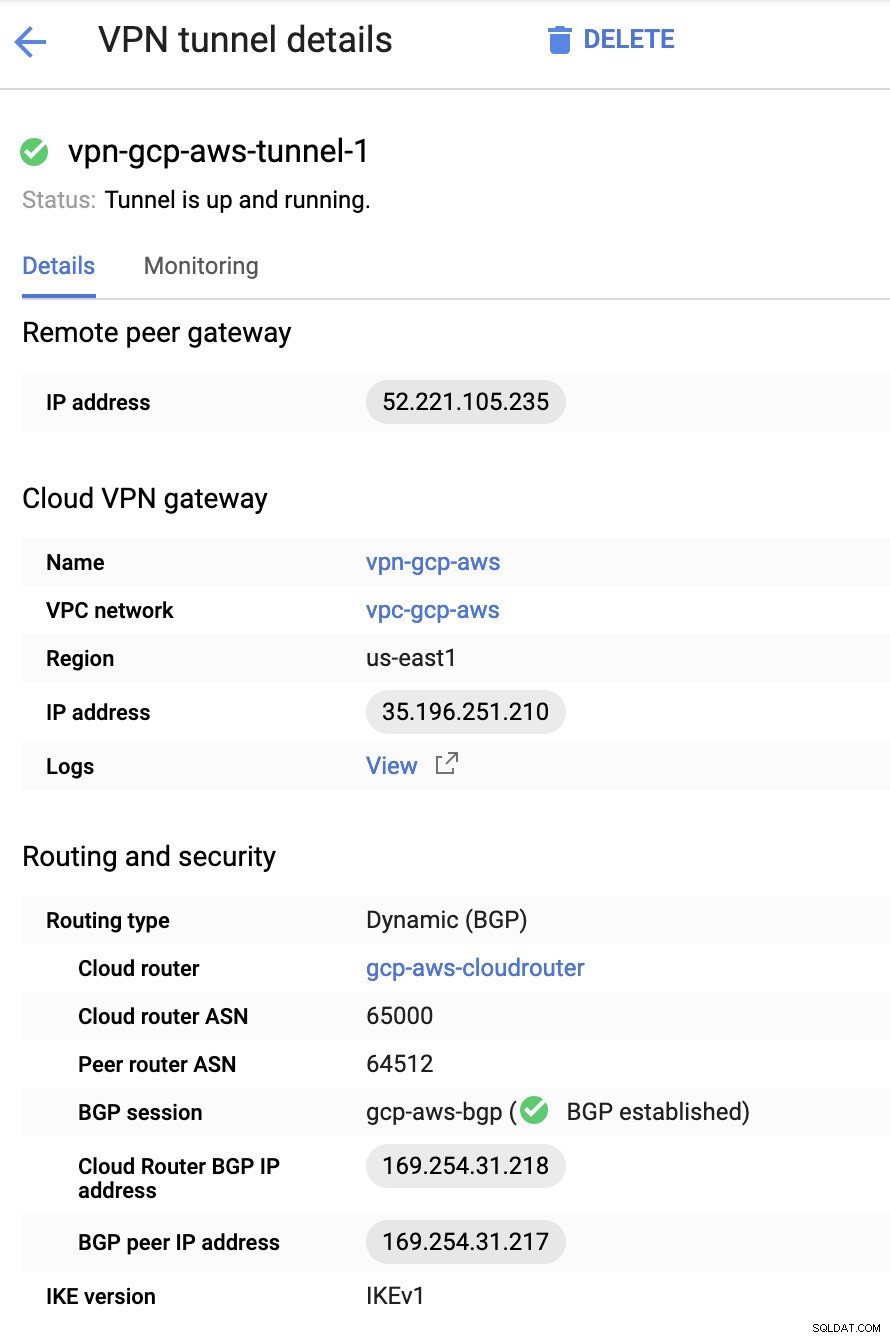
In principe zijn de belangrijkste dingen hier de volgende:
- Remote Peer Gateway:IP-adres - Dit is het IP-adres van de VPN-server vermeld onder Tunneldetails -> Buiten IP-adres . Dit moet niet worden verward met het statische IP-adres dat we onder GCP hebben gemaakt. Dat is de Cloud VPN-gateway -> IP-adres hoewel.
- Cloudrouter ASN - AWS gebruikt standaard 65000. Maar waarschijnlijk haalt u deze informatie uit het gedownloade configuratiebestand.
- Peer router ASN - Dit is de Virtual Private Gateway ASN die te vinden is in het gedownloade configuratiebestand.
- Cloud Router BGP IP-adres - Dit is de Klantgateway gevonden in het gedownloade configuratiebestand.
- BGP-peer IP-adres - Dit is de Virtual Private Gateway gevonden in het gedownloade configuratiebestand.
-
Bekijk het voorbeeldconfiguratiebestand dat ik hieronder heb:
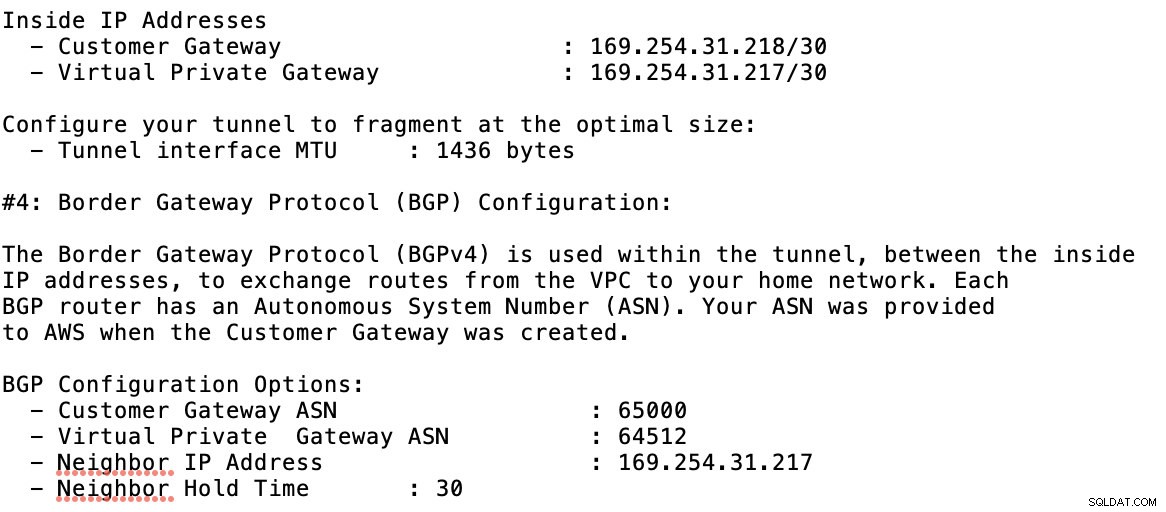
waarvoor u dit moet matchen tijdens het toevoegen van uw Tunnel onder de GCP -> Hybride connectiviteit -> VPN connectiviteit instellen. Zie de afbeelding hieronder waarvoor ik een cloudrouter en een BGP-sessie heb gemaakt tijdens het maken van een voorbeeldtunnel:
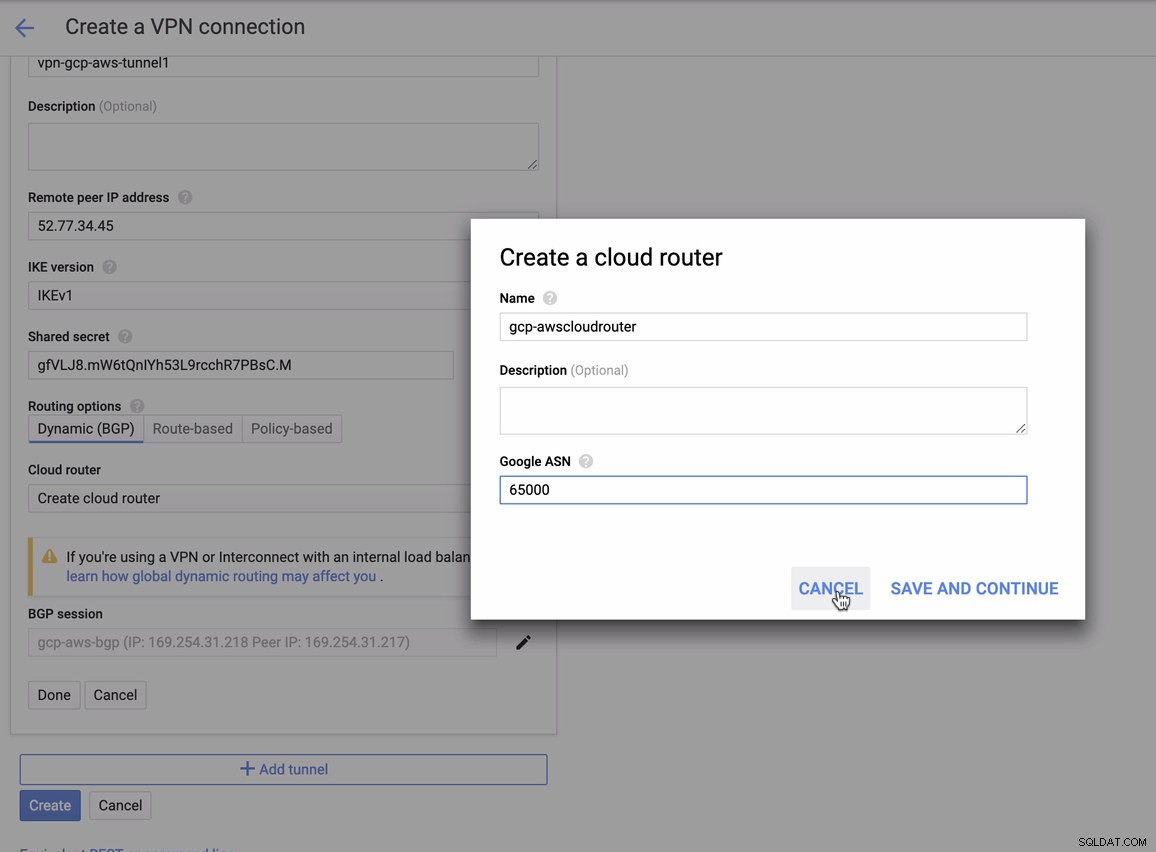
Dan BGP-sessie als,

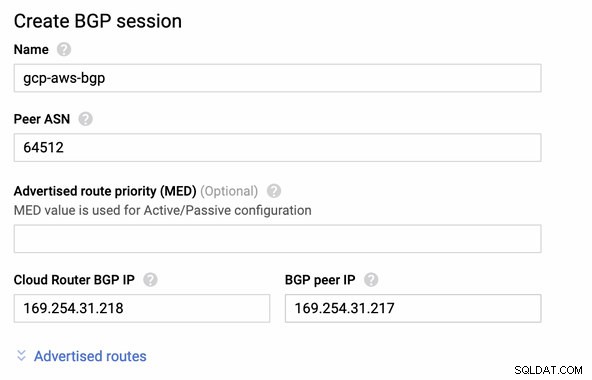
Opmerking: Het gedownloade configuratiebestand bevat een IPSec-configuratietunnel waarvoor ook AWS twee (2) VPN-servers bevat die klaar zijn voor uw verbinding. Je moet ze allebei instellen, zodat je een hoge beschikbare configuratie hebt. Als beide tunnels correct zijn ingesteld, laat de AWS VPN-verbinding onder het tabblad Tunnels zien dat beide Buiten IP-adres zijn op. Zie onderstaande afbeelding:

-
Ten slotte, aangezien we een internetgateway en NAT-gateway hebben gemaakt, moeten de openbare en privésubnetten correct worden ingevuld met de juiste bestemming en Doel zoals opgemerkt in de schermafbeelding van de vorige stappen. Dit kan worden ingesteld door naar Services -> Networking &Content Delivery -> VPC -> Routetabellen te gaan en selecteer de gemaakte routetabellen uit de vorige stappen. Zie de afbeelding hieronder:
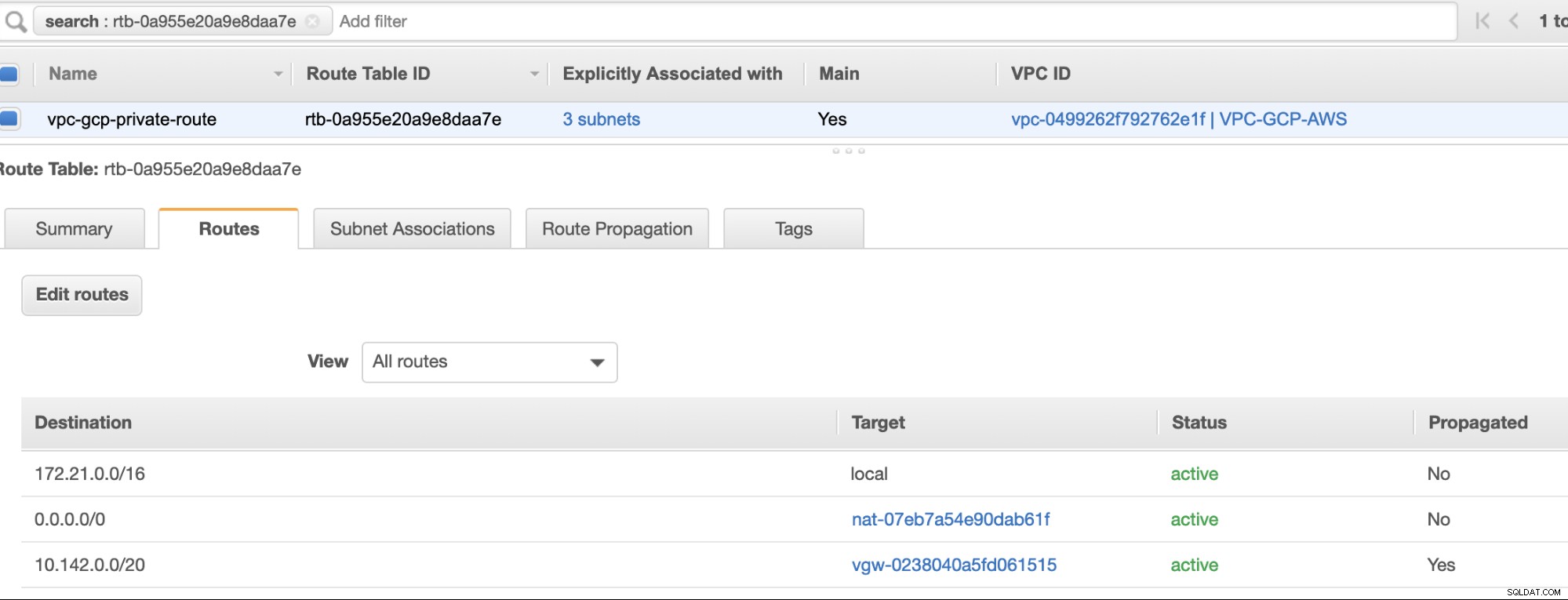
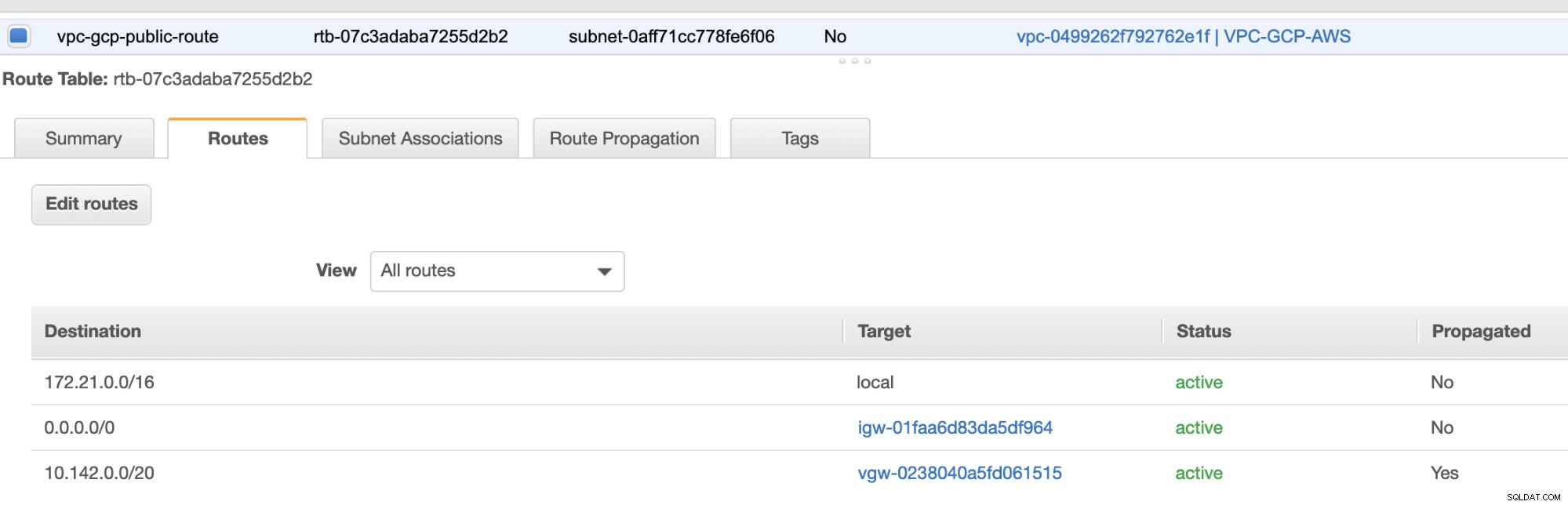
Zoals je hebt opgemerkt, is de igw-01faa6d83da5df964 is de internetgateway die we hebben gemaakt en die wordt gebruikt door de openbare route. Terwijl de privéroutetabel de bestemming en het doel heeft ingesteld op nat-07eb7a54e90dab61f en beide hebben Bestemming ingesteld op 0.0.0.0/0 omdat het vanaf verschillende IPv4-verbindingen is toegestaan. Vergeet ook niet om de Routevoortplanting . in te stellen correct voor de virtuele gateway zoals te zien is in de schermafbeelding die een doel heeft vgw-0238040a5fd061515 . Klik gewoon op Routevoortplanting en stel deze in op Ja, net zoals in de onderstaande schermafbeelding:
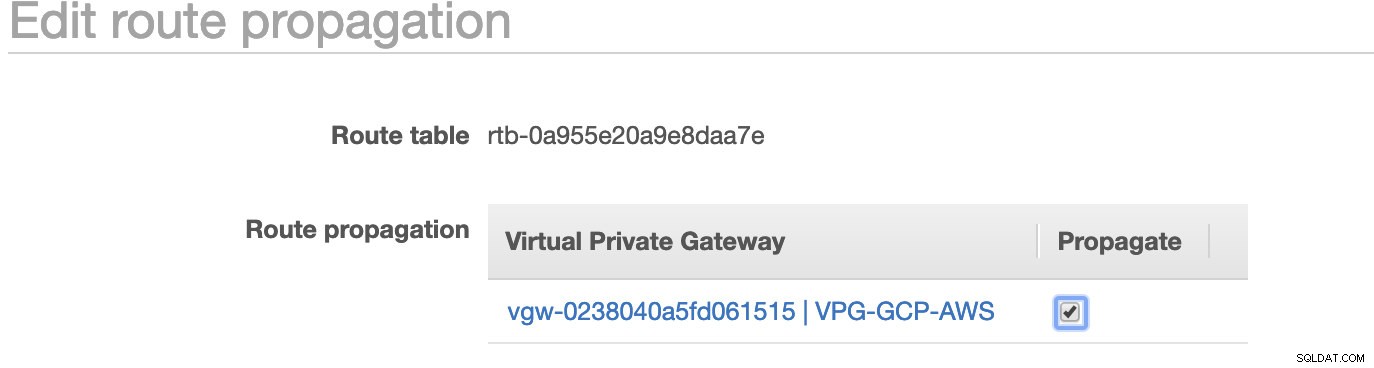
Dit is erg belangrijk, zodat de verbinding van de externe GCP-verbindingen naar de routetabellen in AWS wordt gerouteerd en er geen verder handmatig werk nodig is. Anders kan uw GCP geen verbinding maken met AWS.
Nu onze VPN klaar is, gaan we verder met het opzetten van onze privéknooppunten, inclusief de bastionhost.
De Compute Engine-knooppunten instellen
Het instellen van de Compute Engine/EC2-knooppunten gaat snel en gemakkelijk, aangezien we alle instellingen hebben geïnstalleerd. Ik zal niet op die details ingaan, maar bekijk de screenshots hieronder omdat het de installatie uitlegt.
AWS EC2-knooppunten :

GCP-rekenknooppunten :
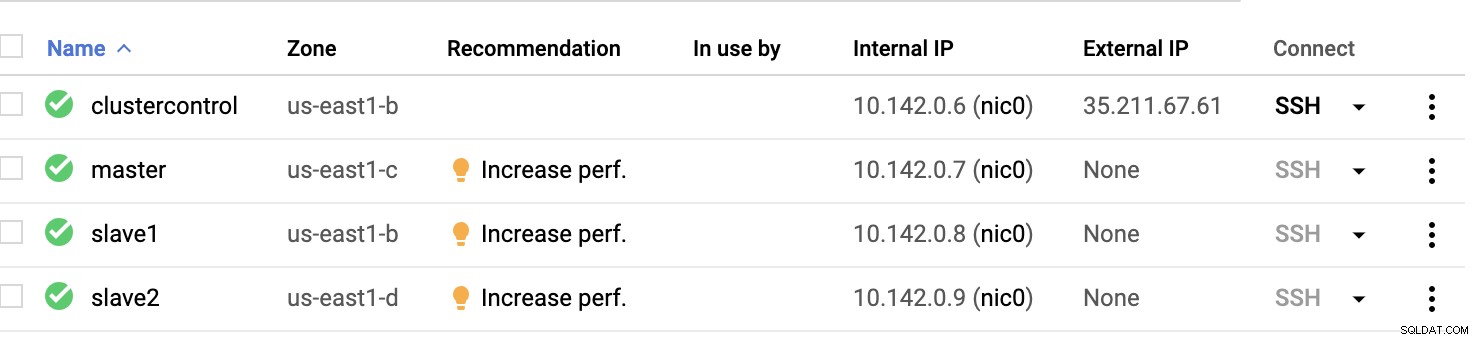
Eigenlijk op deze setup. De host clustercontrole zal de bastion of jump host zijn en waarvoor de ClusterControl zal worden geïnstalleerd. Het is duidelijk dat alle knooppunten hier niet toegankelijk zijn voor internet. Ze hebben geen externe IPv4 toegewezen en knooppunten communiceren via een zeer veilig kanaal met behulp van VPN.
Ten slotte zijn al deze knooppunten van AWS tot GCP ingesteld met één uniforme systeemgebruiker met sudo-toegang, wat nodig is in onze volgende sectie. Bekijk hoe ClusterControl uw leven gemakkelijker kan maken in multicloud en multiregio.
ClusterControl als redding!!!
Het afhandelen van meerdere knooppunten en op verschillende openbare cloudplatforms, plus op een andere "Regio" kan een "echt pijnlijke en ontmoedigende" taak zijn. Hoe monitor je dat effectief? ClusterControl fungeert niet alleen als uw Zwitserse mes, maar ook als uw virtuele DBA. Laten we nu eens kijken hoe ClusterControl uw leven gemakkelijker kan maken.
Een cluster met meerdere replicatie maken met ClusterControl
Laten we nu proberen een MariaDB master-slave-replicatiecluster te maken volgens de "Multiple Replication"-topologie.
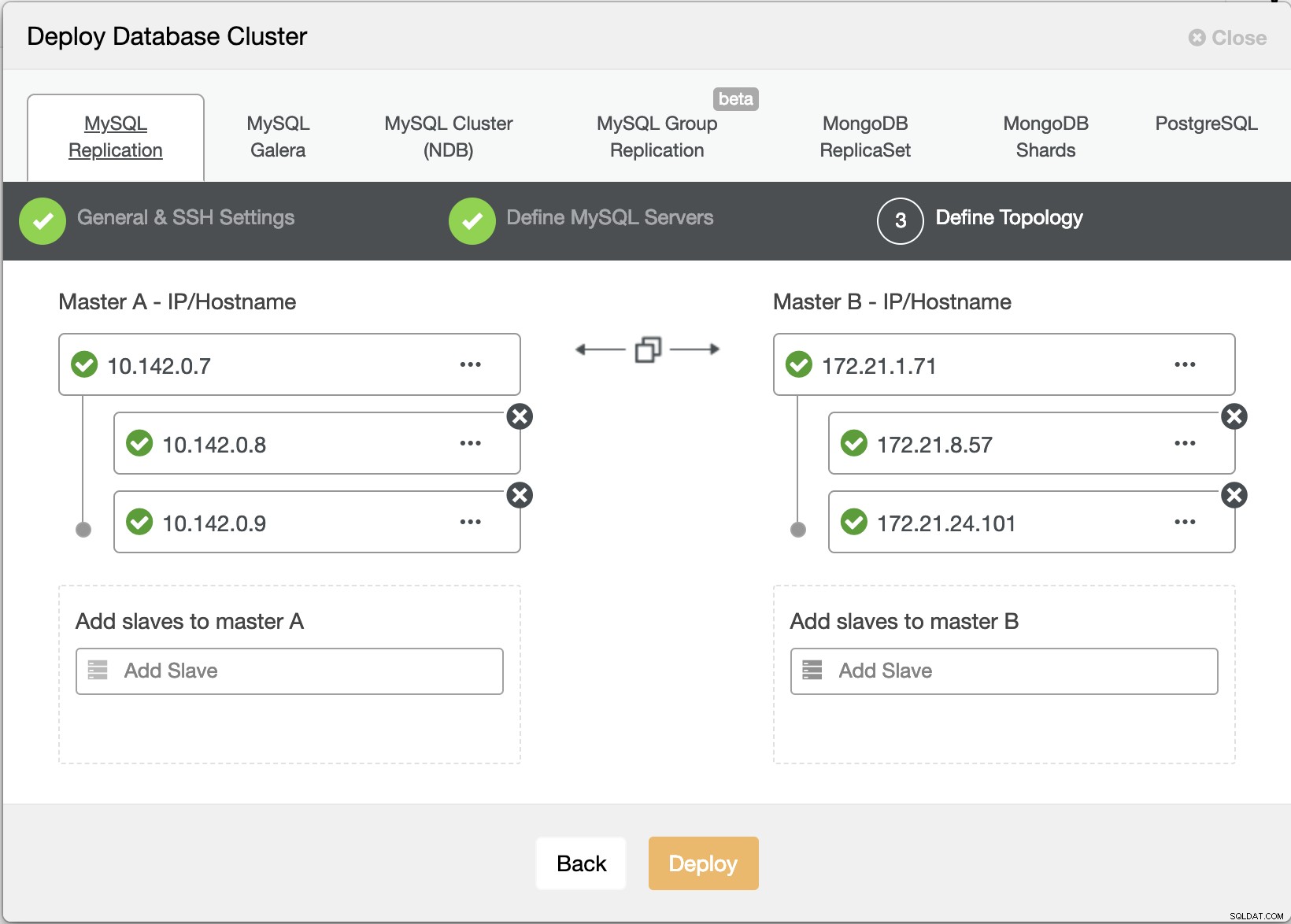 Wizard ClusterControl implementeren
Wizard ClusterControl implementeren Druk op Deploy knop zal pakketten installeren en de knooppunten dienovereenkomstig instellen. Vandaar een logische weergave van hoe de topologie eruit zou zien:
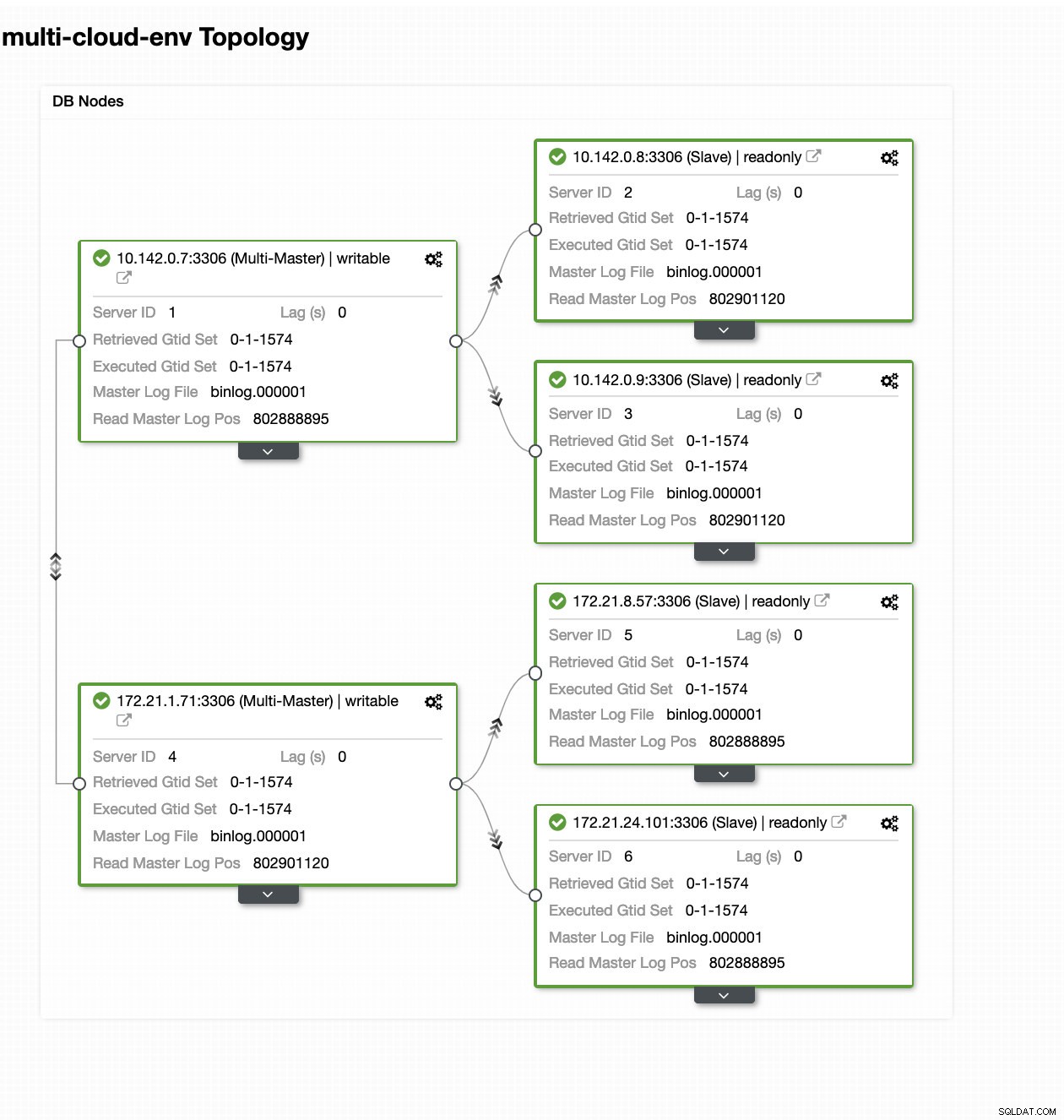 ClusterControl - Topologieweergave
ClusterControl - Topologieweergave De nodes 172.21.0.0/16 bereik IP's repliceren van zijn master die op GCP draait.
Wat als we nu proberen om wat schrijfacties op de master te laden? Eventuele problemen met connectiviteit of latentie kunnen slave-lag veroorzaken, u kunt dit zien met ClusterControl. Zie de onderstaande schermafbeelding:
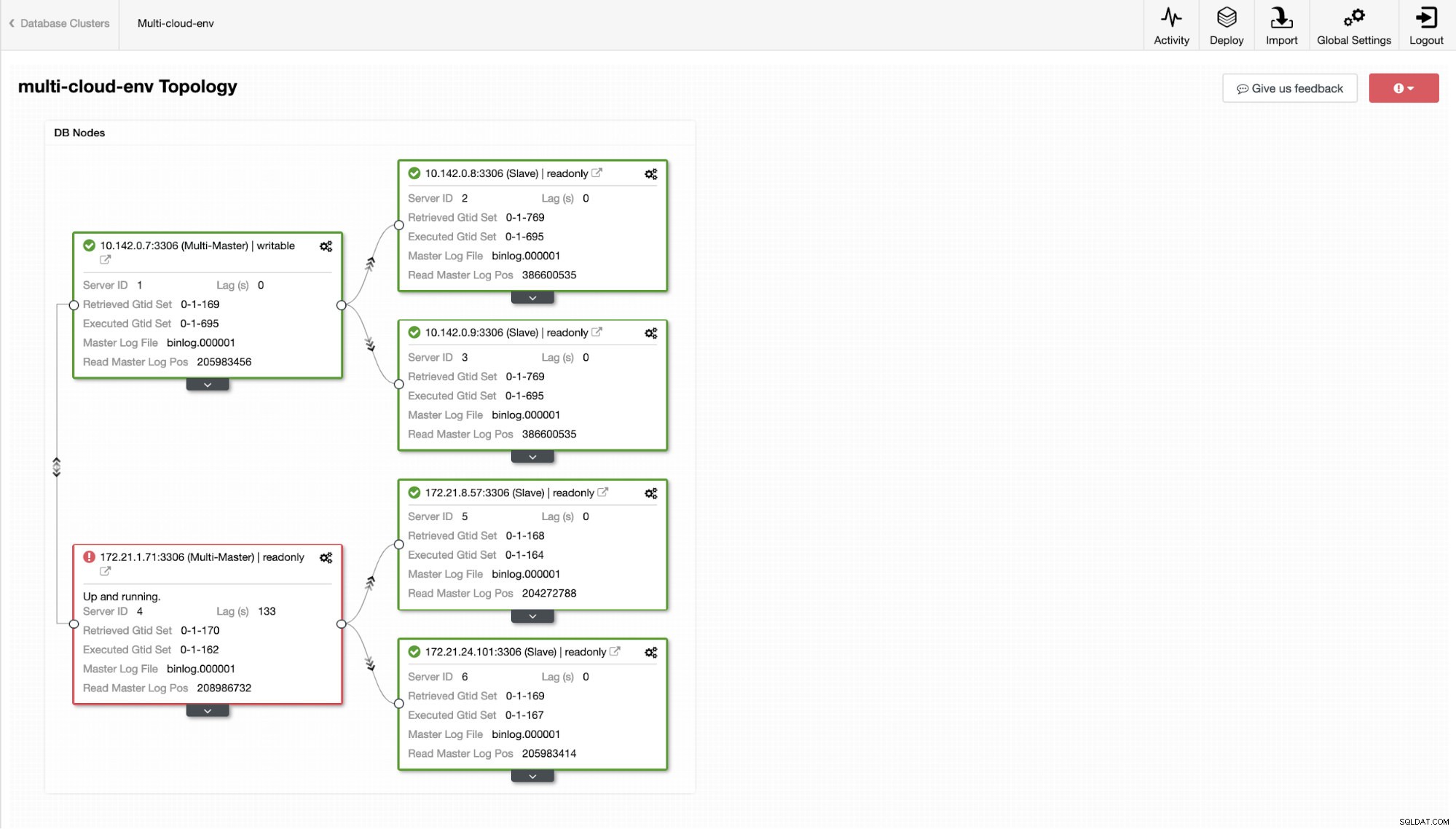
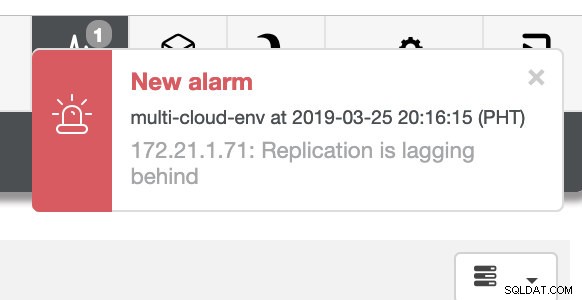
en zoals u in de rechterbovenhoek van de schermafbeelding ziet, wordt deze rood omdat dit aangeeft dat er problemen zijn gedetecteerd. Daarom werd er een alarm verzonden terwijl dit probleem werd gedetecteerd. Zie hieronder:
We moeten ons hierin verdiepen. Voor fijnmazige monitoring hebben we agents ingeschakeld op de database-instanties. Laten we eens kijken naar het dashboard.
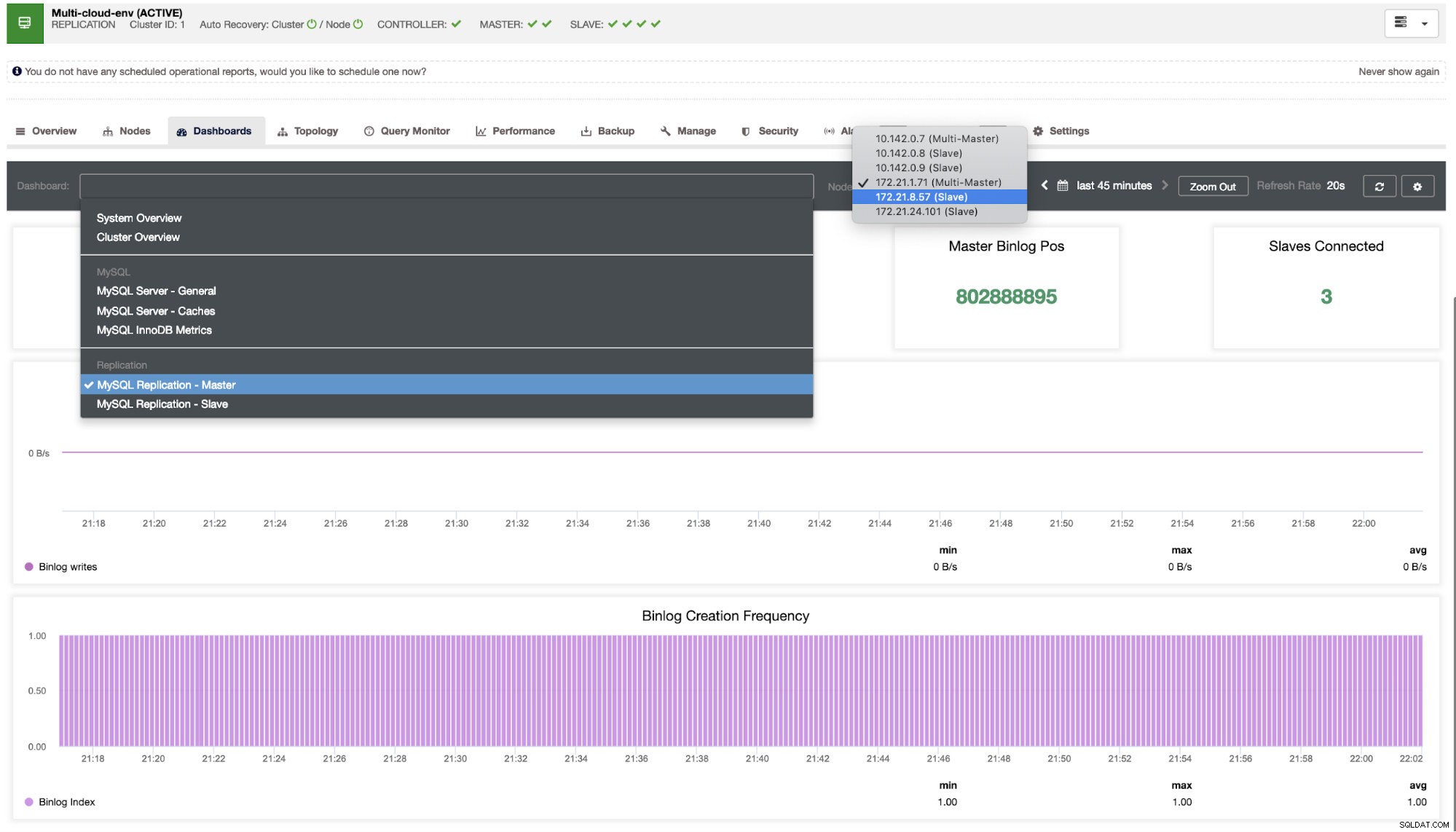
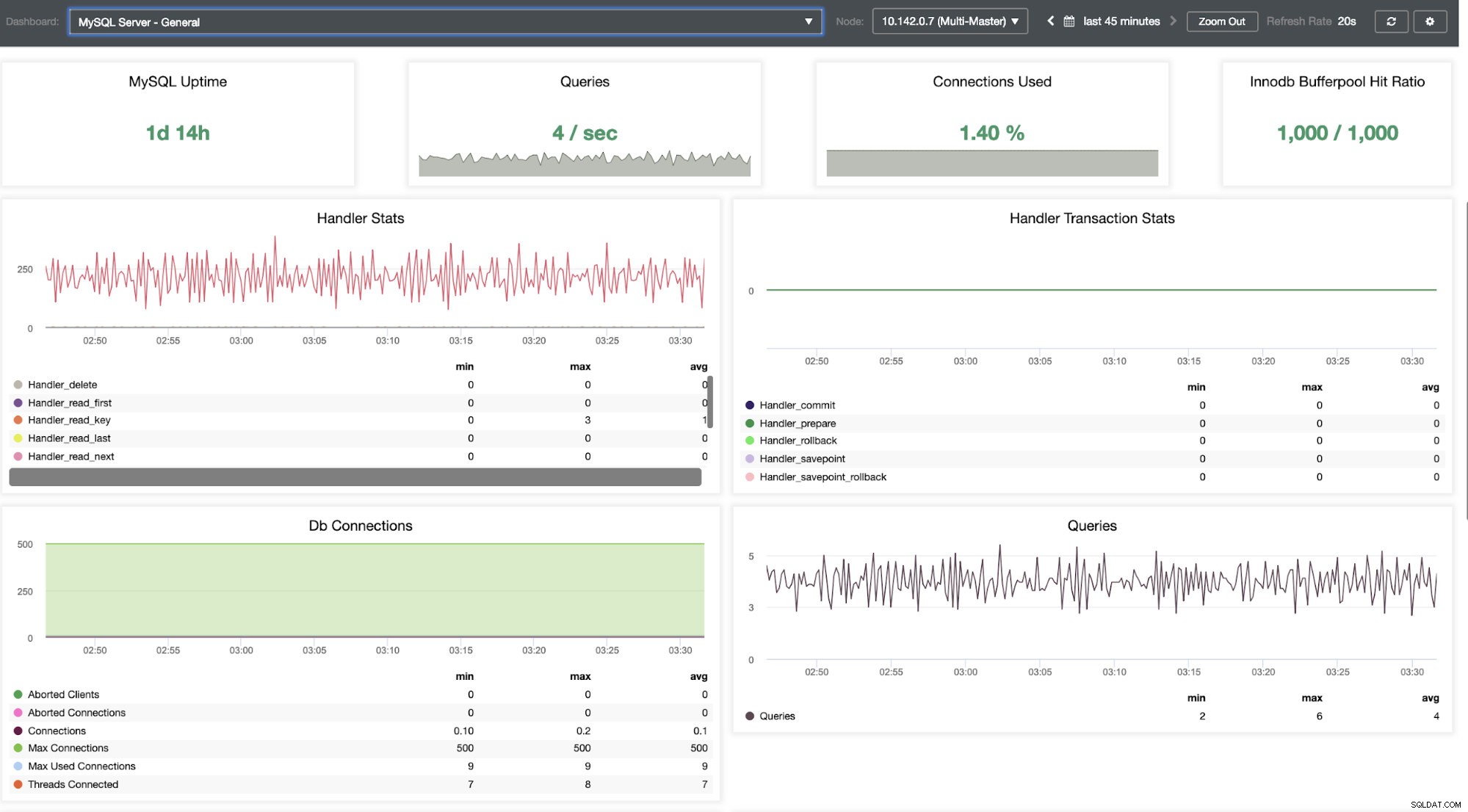
Het biedt een supersoepele ervaring wat betreft het monitoren van uw nodes.
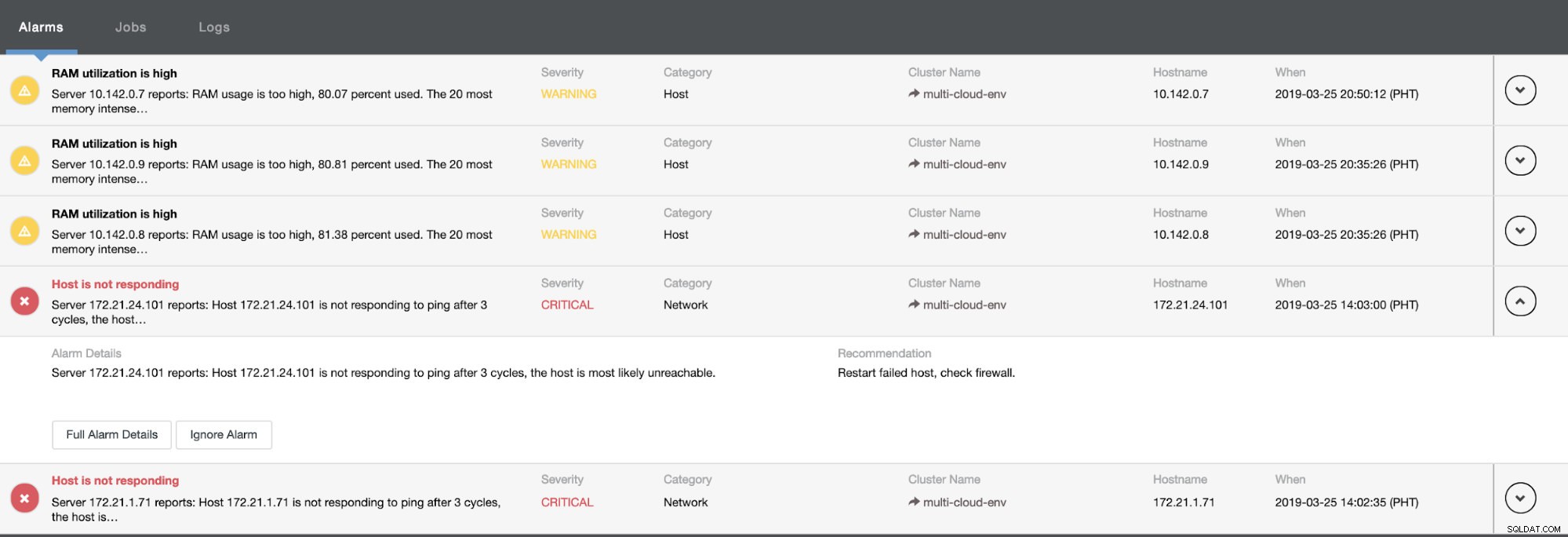
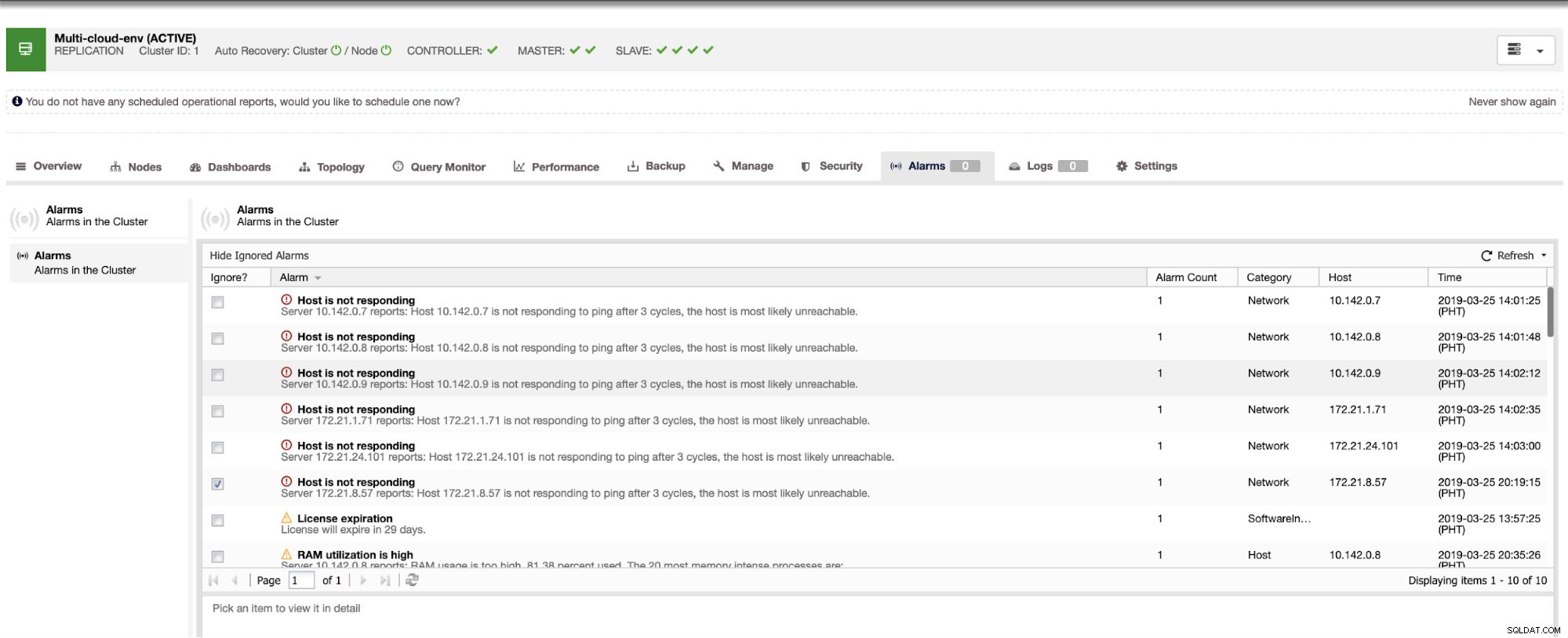
Het vertelt ons dat het gebruik hoog is of dat de host niet reageert. Hoewel dit slechts een ping . was reactie mislukt, kunt u de waarschuwing negeren om te voorkomen dat u deze bombardeert. Daarom kunt u het desgewenst 'negeren' door naar Cluster -> Alarmen in de Clustercontrol te gaan. Zie hieronder:
Fouten beheren en failover uitvoeren
Laten we zeggen dat het us-east1-masterknooppunt is mislukt of een grote revisie vereist vanwege een systeem- of hardware-upgrade. Laten we zeggen dat dit nu de topologie is (zie afbeelding hieronder):
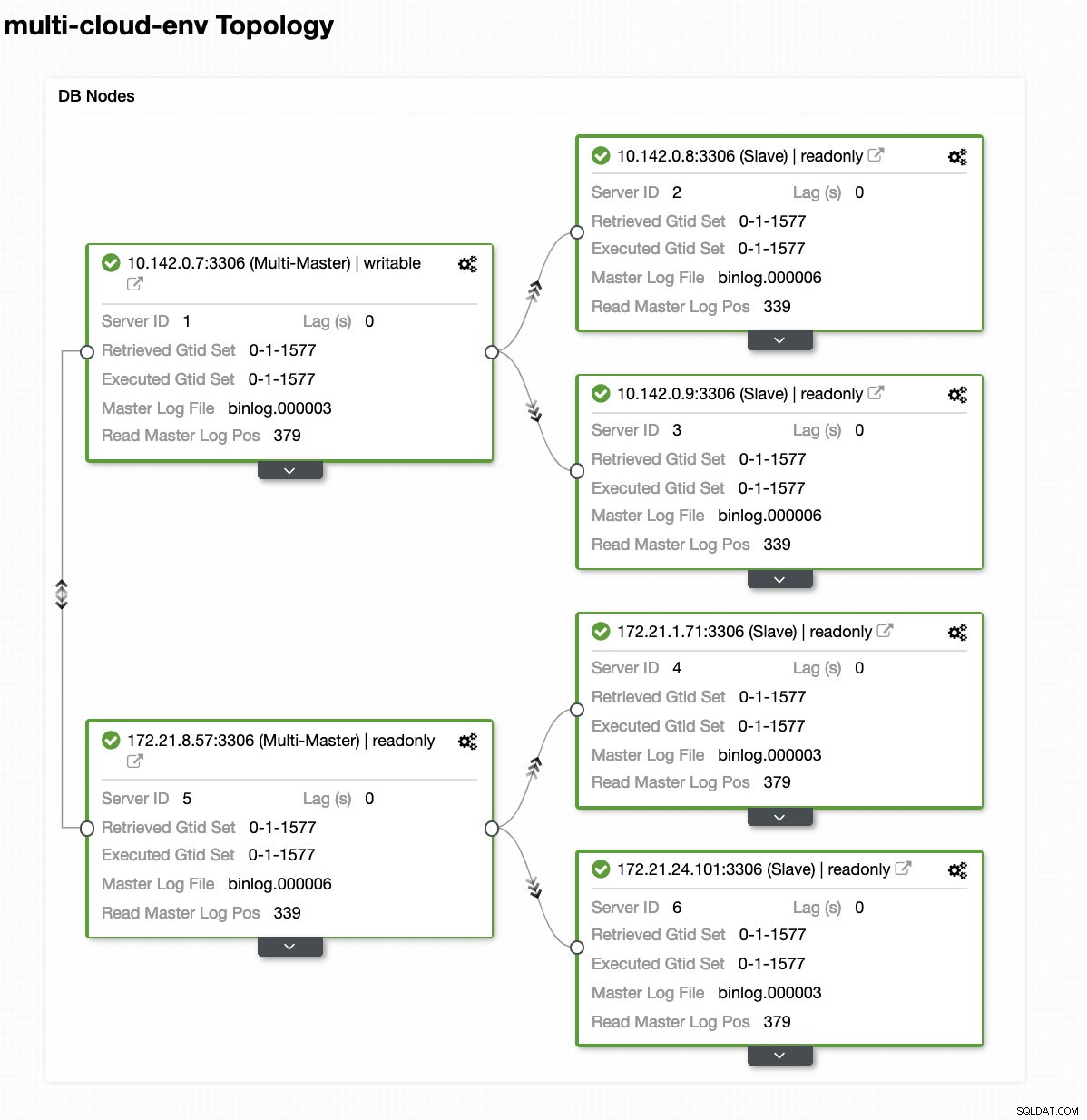
Laten we proberen host 10.142.0.7 af te sluiten, de master onder de regio us-east1. Zie onderstaande screenshots hoe ClusterControl hierop reageert:
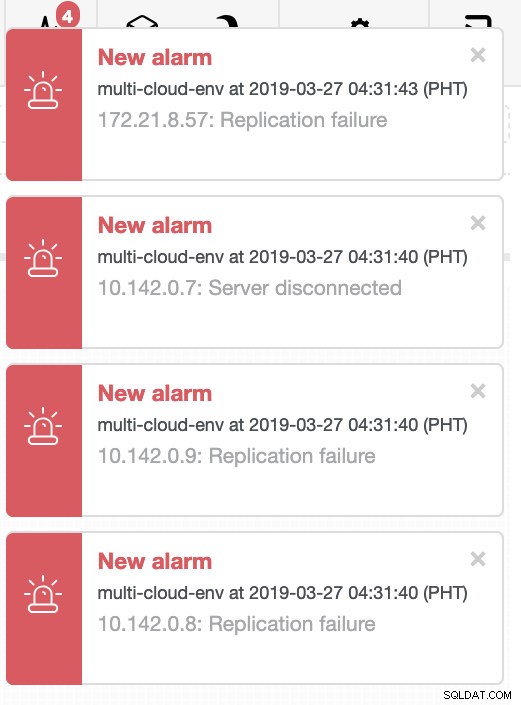
ClusterControl stuurt alarmen zodra het afwijkingen in het cluster detecteert. Vervolgens probeert het een failover uit te voeren naar een nieuwe master door de juiste kandidaat te kiezen (zie onderstaande afbeelding):

Vervolgens zet het de mislukte master opzij die al uit het cluster is gehaald (zie onderstaande afbeelding):
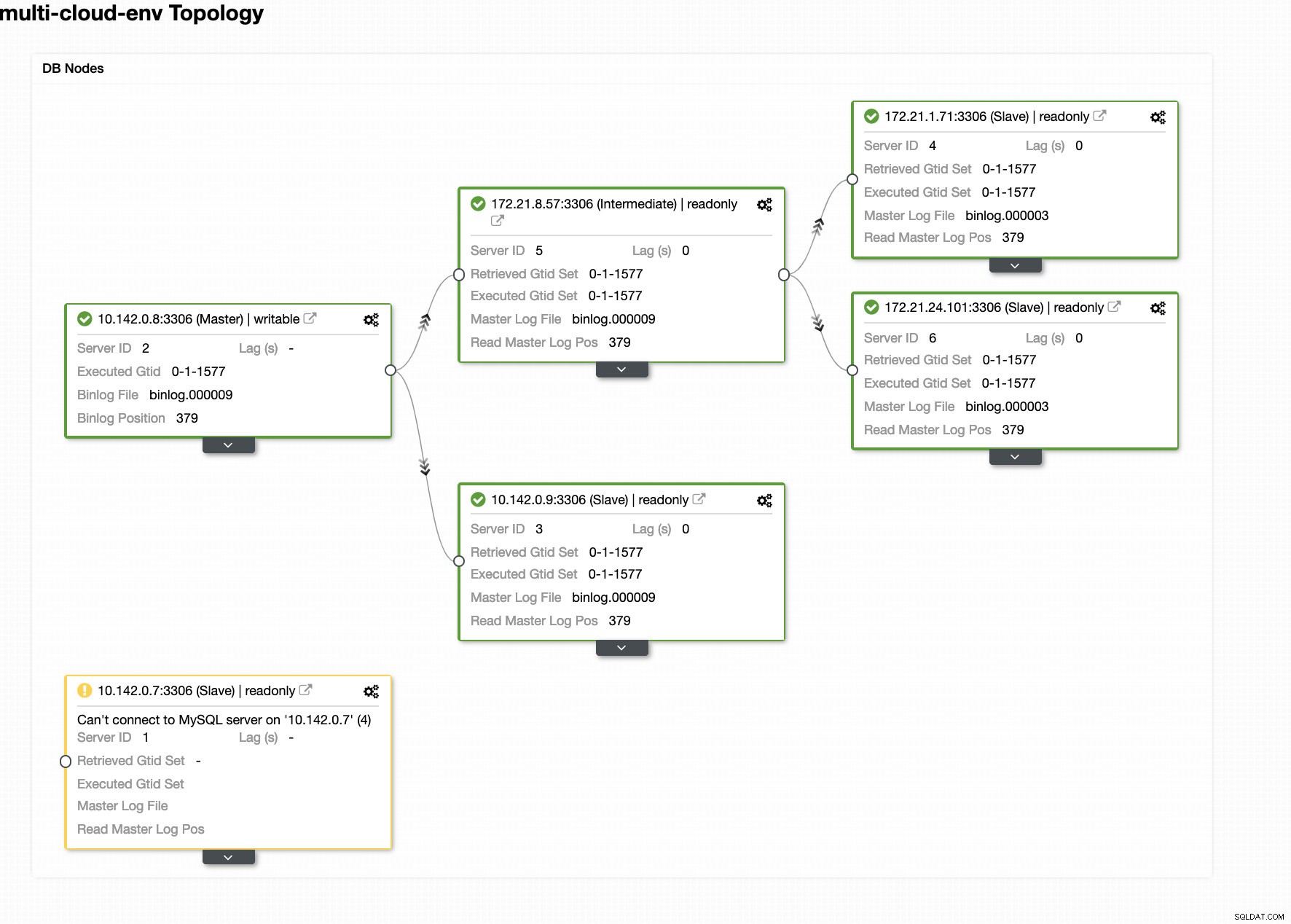
Dit is slechts een glimp van wat ClusterControl kan doen, er zijn andere geweldige functies zoals back-ups, query-monitoring, het implementeren/beheren van load balancers en nog veel meer!
Conclusie
Het beheren van uw MySQL-replicatieconfiguratie in een multicloud kan lastig zijn. Er moet veel zorg worden besteed aan het beveiligen van onze installatie, dus hopelijk geeft deze blog een idee over het definiëren van subnetten en het beschermen van de databaseknooppunten. Na de beveiliging zijn er een aantal zaken die moeten worden beheerd en dit is waar ClusterControl zeer nuttig kan zijn.
Probeer het nu en laat ons weten hoe het gaat. U kunt hier altijd contact met ons opnemen.